基于云模式的微機械傳感器個性化推薦算法研究
2021-02-24 10:13:44劉紅英
制造業自動化 2021年12期
劉紅英
(廣州工商學院,廣州 510850)
0 引言
微電子技術不斷提高的背景下,微機械傳感器也取得了較為優秀的成果。目前微機械傳感器被深入研究,截止到目前,微機械傳感器的類型大致分為七種,分別為微機械陀螺、微氣體傳感器、微機械溫度傳感器、微機械壓力傳感器、微加速度傳感器、微流量傳感器和其他微機械傳感器[1]。這些傳感器被廣泛應用到化學以及醫學等行業當中,通過應用到材料、設備等環節上,優化數據傳輸與技術控制效果,具有極大的應用前景。為了進一步掌握微機械傳感器的應用方法,針對微機械傳感器提出不同的個性化推薦算法[2]。這些現有的推薦算法被應用到各大網絡以及設備中,盡管能夠取得一定成果,但在及時性上還不夠完善,需要進一步優化。云模式是將云計算與搜索引擎結合使用的新技術,具有一站式解決問題的綜合能力,針對云模式的特點研究全新的微機械傳感器個性化推薦算法。
1 基于云模式的微機械傳感器個性化推薦算法
1.1 設置特征項標簽
標準的特征項標簽能夠以更加全面的方式表達傳遞信息,能夠讓無線傳感器網絡中的節點之間快速識別,建立不同關聯度的鄰居關系。當微機械傳感器傳輸穩定的數據,也就是常規內容的數據時,設置常規內容與其對應的權重分別為xi和ωi,采用信息加權技術TF-IDF,衡量傳感器中數據的重要程度。其中TF用于描述詞頻,該數值越大越能說明內容出現的次數越多,有較高的重要性;IDF用于描述反文檔頻率,也就是出現次數較少導致詞頻較低的內容。通過上述分析過程,將標簽與TF-IDF方法融合,計算公式為:
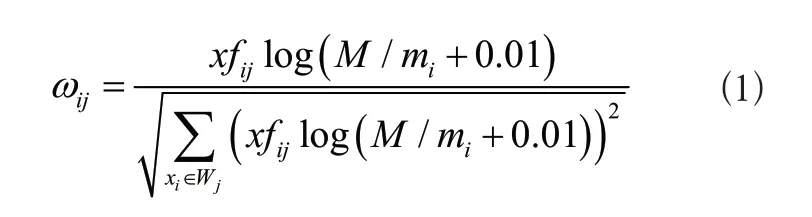
式中:fij表示信息加權函數;M表示總文檔數;mi表示出現特征xi的文檔數;Wj表示文本。設置某一特征項信息的標簽為xj,根據上述公式融合特征項標簽,得到對應的權重為:
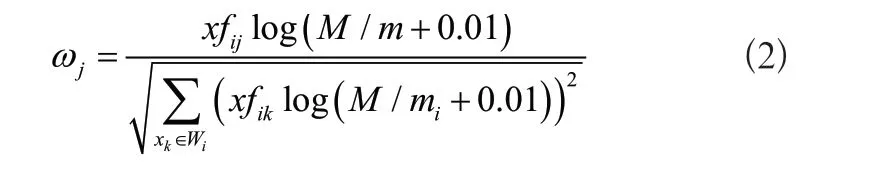
式中:xfij代表標簽xj被使用的次數;M表示總數據量;m表示觸發過標簽的數據量;Wi表示標簽集合。標簽的權重取值范圍在[0,1]內,當標簽被頻繁觸發,說明傳感器傳輸過大量同類內容,對于該標簽下的數據相當熟悉。但在整個網絡大環境中,傳感器還會面對即時性的信息,此類信息傳感器接觸的相對較少,甚至有的沒有接觸過,那么無線傳感器網絡中的節點,對于此類數據沒有對應的鄰居關系,無法接收鄰居消息,增大鄰居發現延遲,所以針對即時數據也需要計算對應的權重,加快對所有節點的喚醒速度,快速建立鄰居關系從而減少推薦延遲[3]。根據傳感器產生的瀏覽行為,針對收藏頁面、保存頁面、打印頁面、停留時間四項內容建立行為函數,公式為:
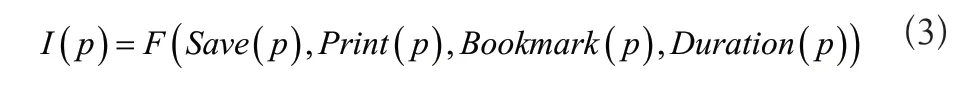
公式中:p表示傳感器接觸過的網絡頁面;其他函數與上述四項內容按順序一一對應。當這些函數的值為0時,說明沒有對該頁面執行數據記錄,反之則記錄了該頁面的數據。結合以上公式,得到特征項xj的權重為:
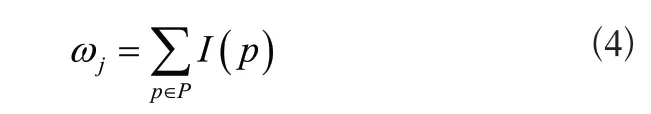
公式中:P表示包含特征項xj的頁面集合。將權重標簽的大小控制在[0,1]內,歸一化處理后的特征項標簽對應的權重為:
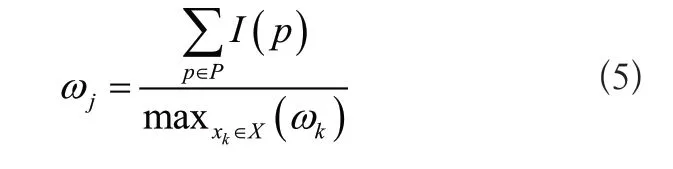
公式中:X表示特征項的集合。通過上述方法對穩定性數據與即時性數據建立標簽,讓傳感器通信范圍內的節點間快速建立鄰居關系,從而為個性化推薦提供更大的主動性。
1.2 云計算模式融合與實時更新標簽
無線傳感器網絡執行龐大的數據傳輸工作,盡管設置了不同的特征項標簽,也還是會影響節點之間建立鄰居關系的速度,利用云計算模式融合同屬性標簽并實時更新。已知云數據信息交互過程中,每一個簇頭節點具備初始數據感知能力,根據標簽實施分派,而后通過數據采集、相鄰節點身份認證、多通道通信等步驟實現數據的傳輸工作。假設簇頭節點的信息導碼通過下列公式獲得:
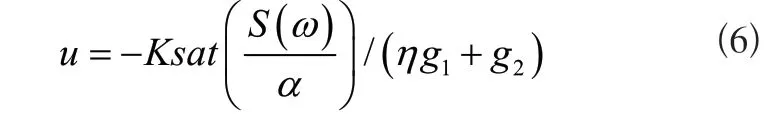
公式中:K表示簇頭總數;sat表示階段函數;S(ω)表示權重為ω的Sink節點;α表示鄰居標簽的特征相似度;η表示信息流特征;g1、g2分別表示穩定和即時數據數量。假設定量論域是精準的,則任意一個連通的云數據可通過G=(V,E,S)描述,其中V表示全部節點的總和;E表示期望、熵等參數的全局定義;S表示Sink節點[4]。整合云數據特征項,通過提取云數據的熵融合特征、分區預處理熵融合特征,實現云計算模式對海量標簽的融合。定義信息數據節點的信息為(ai,bi),以空間采樣分簇重構的方式得到X的空間結構,式為:
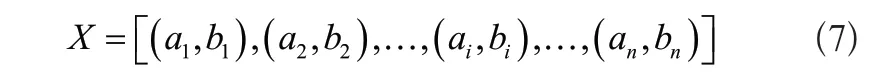
按照間隔粒度劃分空間結構,針對分區特征集提取同一類節點的信息熵,式為:
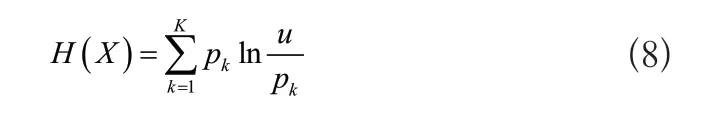
通過上述公式得到信息熵,實現對標簽的融合。同樣根據空間結構對特征進行混合匹配,從而達到實時更顯標簽的目的。云計算模式構建的簇頭相異粒度數據矩陣為:
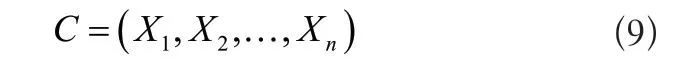
綜合云自身的特殊性以及數據的相似性,以模糊計算為原則,設置標簽匹配模式,實時更新標簽,幫助鄰居節點之間快速識別與關聯。式為:

通過上述融合與匹配過程,實時更新特征項標簽,加快節點之間建立關聯,強化對節點的喚醒操作。
1.3 考慮時序性的個性化推薦
在獲得實時標簽的基礎上,利用聚類技術按照位置的遠近處理標簽,將位置近的標簽和位置遠的標簽劃分到不同的簇中,這樣在個性化推薦過程中能縮減項目搜索范圍,在考慮時序性的條件下,能改進算法的推薦效率。聚類過程如圖1所示。
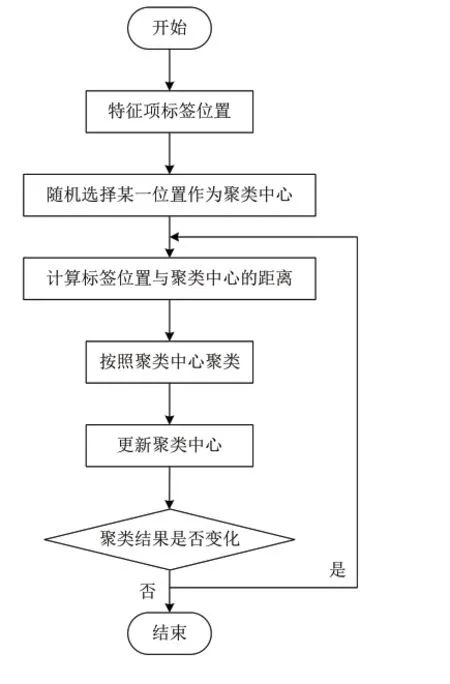
圖1 聚類流程
根據實時標簽的聚類結果,將BP模型與RNN模型融合使用,解決個性化推薦過程中產生的時間序列問題。假設用戶行為在短期內發生頻繁變化,此時的特征項標簽也隨之改變,利用反向傳播算法(BP)在接收輸入數據與產生輸出數據之間,根據一定程度的誤差反向傳播,更新網絡內部的各種參數,該誤差值為:
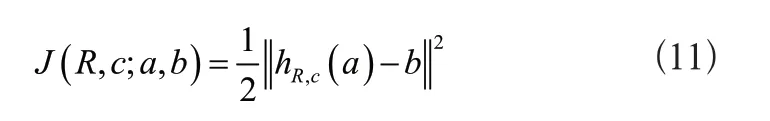
公式中:J表示損失函數,用來描述誤差;R表示隱藏層;c表示神經元的偏置。循環神經網絡(RNN)具有可多次交互數據的能力,可以根據交互次數設置網絡空間層次,每一空間層代表一次交互過程。將二者融合使用,建立混合推薦模型。已知網絡的輸入是實際值,輸出是預測值,輸入向量的長度等于項目總數,所以讓BP與RNN分享相同的輸出層,合并輸出層后產生單一結果。則存在:
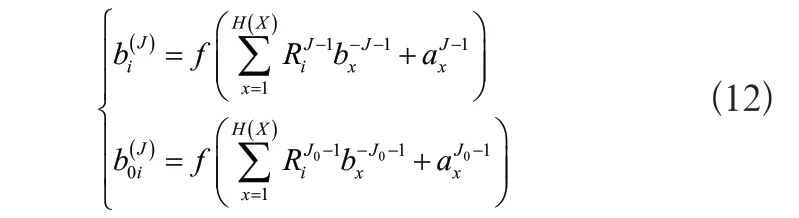
式中:b(J)i、b(J)0i分別表示合并輸出層和隨機輸出層的產出結果[5]。假設RNN的單元數為E,則傳感器推薦某一內容的概率為:
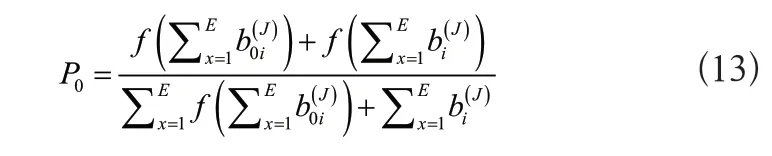
上述公式無需手動操作,而是通過神經網絡訓練實現,通過網絡層對數據的不斷采集、更新、匹配,實現微機械傳感器的個性化推薦工作。
2 測試與分析
2.1 測試環境
本次測試選用的設備配置Intel Pentium 4處理器,操作系統為Windows XP,包括200G硬盤和4G內存。利用Java語言模擬實現,將帶有微機械傳感器的設備與互聯網平臺之間建立連接,檢查網絡是否穩定。利用SimPy設計一個針對離散事件的仿真框架,該軟件以生成器為基礎模擬實體,也就是將微機械傳感器的節點看作生成器,仿真個性化推薦操作。
2.2 評價標準
根據推薦質量評價結果,判斷本文算法是否具有實用性;根據響應時間評價結果,判斷本文算法是否在短時間內能喚醒網絡通信節點;根據平均發現延遲評價結果,判斷本文算法是否能夠快速建立鄰居關系;根據節點能耗評價結果,判斷本文算法是否能夠主動喚醒更多節點,將額外能量開銷降至最低。推薦質量的評價將平均絕對偏差MAE作為衡量指標,所得的值越小越能說明算法具有較高的推薦質量。該值的計算公式為:
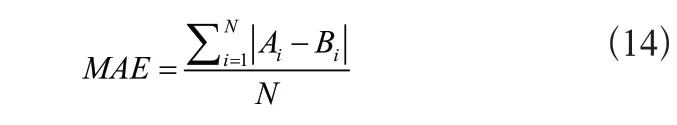
式中:Ai、Bi分別表示用戶評分的預測集合和實際集合。響應時間用RT表示,也就是目標發出推薦請求與傳感器產生推薦的時刻差值,計算式為:

式中:t1表示發出推薦請求的時刻;t2表示產生推薦結果的時刻。平均發現延遲用RTT表示,計算公式如下:
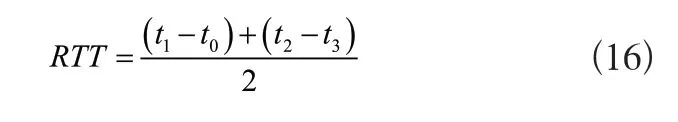
式中:t0、t3表示客戶端的發包與收包時間;t1、t2表示節點的發包與收包時間。設置每個節點平均能耗為E,則式為:

公式中:k為常數;d表示一跳的距離;i表示節點數,且i>2。測試設置2個對照組,分別為協同推薦算法和混合推薦算法。以對比測試的方法比較三組方法在四組指標上的評價差異,根據測試結果比較不同算法的性能。
2.3 云模式的應用
本文方法根據推薦者、被推薦者和推薦目標三項參數,在特征項標簽的基礎上,利用云計算模式融合與實時更新標簽,如圖2所示。
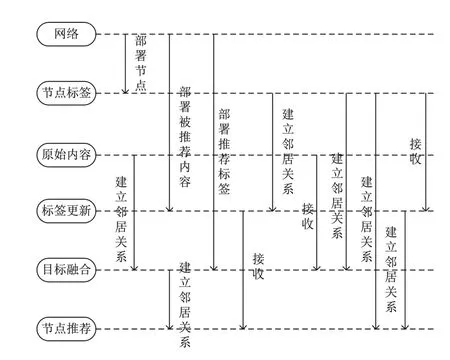
圖2 云模式的應用
在融合同類型標簽的基礎上,通過實時更新標簽獲取實時數據,保證標簽都是不重疊的。本文研究的算法在此基礎上推薦個性化數據。
2.4 結果與分析
2.4.1 推薦質量測試
將本文算法與兩組傳統算法分別應用到同一型號的設備中,已知設備的微機械傳感器型號相同。利用該設備查詢信息,利用式(14)評價三組算法的推薦質量,結果如圖3所示。
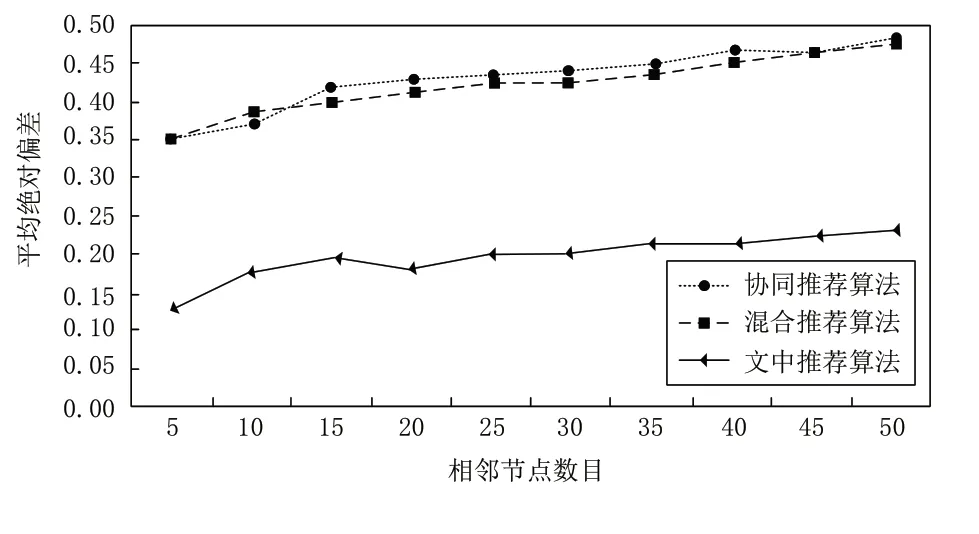
圖3 推薦質量測試結果
根據上圖顯示的結果可知,三組方法的平均絕對偏差MAE均處于0.5以下,但本文算法的評價結果比兩組算法分別低了0.21和0.19,說明本文算法的個性化推薦質量更高。
2.4.2 響應時間測試
根據式(15)計算三組算法的響應時間,結果如圖4所示。
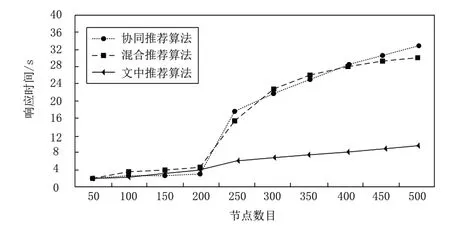
圖4 響應時間測試結果
根據圖4顯示的結果可知,本文算法的響應時間RT最短,面對500個通信網絡節點時,平均響應時間比協同推薦算法和混合推薦算法分別減少了24.1s和19.8s,說明本文算法在短時間內,能快速喚醒更多傳感器網絡通信節點。
2.4.3 延遲對比
已知傳感器網絡的能量有限,通常情況下的網絡節點會隨時進入睡眠狀態,比較三組算法的平均發現延遲,根據式(16)得到的結果,繪制圖5所示的實驗結果。
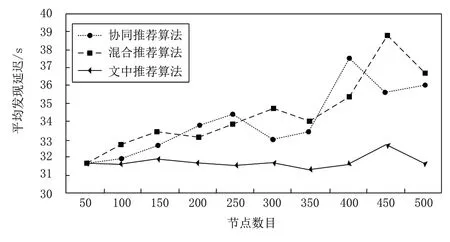
圖5 平均延遲測試結果
根據上述評價結果可知,在同樣的測試條件下,隨著節點數量的增加,本文算法的平均發現延遲RTT穩定在31~33s之間,協同推薦算法和混合推薦算法的平均發現延遲,分別在31~38s和31~40s之間,說明本文算法在快速響應的基礎上,將通信節點之間迅速建立鄰居關系,能夠以最快速度進入到工作狀態。
2.4.4 能耗對比
利用式(17)評價節點能耗并繪制實驗圖,如圖6所示。
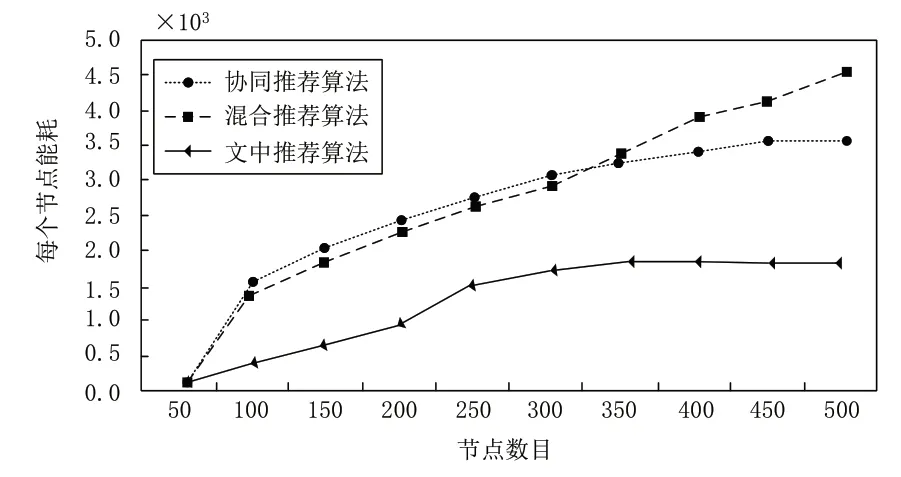
圖6 節點能耗測試結果
根據圖6顯示的評價結果可知,面對越來越多的節點數目,本文算法能夠將節點能耗E始終控制在2.0×103以下,而協同推薦算法和混合推薦算法的節點能耗,隨著節點數目的增加而逐漸增多,說明本文方法能夠用最小的能耗喚醒更多的節點,將額外能量開銷降至最低。
3 結語
隨著互聯網、互聯網技術的飛速發展,網絡資源變得更加復雜、多樣,如何從海量的數據中快速獲取目標信息,滿足不同使用用戶的需求,是現階段研究的重點問題。面對信息過載這一現狀,本文算法以推薦的及時性為研究目標,利用更多智能技術實現了對現有推薦算法的優化。但此次研究還存在不足,這種算法的及時性能得到提升,但對于推薦數據的準確性還有待驗證。今后在時間充沛的情況下,可以評價推薦內容的準確性,完善該算法的其他性能。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
當代工人(2020年8期)2020-05-25 09:07:38
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小溪流(畫刊)(2017年12期)2018-01-10 16:07:29
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
科技知識動漫(2016年8期)2016-07-29 20:40:09
