對高職院校大數據技術與應用專業課程體系設置的幾點建議
2021-02-24 13:26:50耿學
信息記錄材料 2021年1期
耿 學
(山東工業職業學院 山東 淄博 256414)
1 引言
隨著計算機技術與互聯網技術的發展,數據呈現出爆發式的增長,根據著名咨詢機構互聯網數據中心的預測,人類社會產生的數據以每年50%的速度增長,也就是說,大約每兩年就增加一倍,2020 年全球總共擁有35ZB 的數據量[2]。面對如此巨大的數據量,需要使用新技術對其采集、存儲、處理以及分析,從而得到有價值的數據,這一系列的過程產生了大量的人才需求,高職院校為了培養相關人才紛紛申報了大數據專業,但因大數據專業為新興專業,師資力量儲備不足、教師經驗不足,而大數據涵蓋的知識技術廣、難度大,高職院校學生在校學習時間短等等。如何通過調整課程體系設置,增強大數據技術與應用專業課程之間的關聯性、整合力,促進高職學生就業等是高職院校研究的重點。
2 問題分析
以下通過學情、崗位、技術三個層面分析高職院校大數據技術與應用專業課程設置需綜合考慮的問題。
2.1 學情分析
高職院校學生學制3 年,但在校時間一般2 年,2 年中需要安排基本素質課、專業通識課、專業核心課和專業拓展課,時間有限,安排的課程即有限。但是大數據囊括的技術非常多,難度也大,課程設置時要考慮課程設置的貫通性、整合性。
2.2 就業崗位業務需求分析
通過對各大招聘網站調研,發現面向高職院校招聘的大數據相應崗位主要包括大數據開發、大數據運維、大數據分析與挖掘[1],分別占比67.5%、24%、5%。相應崗位的工作任務和知識技能要求如表1 所示。綜合分析就業崗位、工作任務及知識技能要求,學生應掌握的知識包括:Linux 平臺應用、編程語言Java 及Python 的使用、Hadoop 集群及相關組件的安裝、部署及應用等[3-4]。課程設置時應注意課程之間的銜接性、整體性,避免重復性,例如數據庫學習可以有SQLServer、Oracle、MySQL 等,但是從整體性考慮MySQL 在整個課程體系中使用更廣泛、銜接性更好。

表1 大數據就業崗位表
2.3 大數據技術分析
從大數據分析角度來說,典型的大數據分析過程包括:數據采集與預處理、數據存儲與管理、數據處理與分析、數據可視化;這些分析過程中涵蓋的相關技術既包含底層的操作系統(Linux、Windows)、網絡技術,還包含編程語言(Java、Python、R、Scala、C),包含Hadoop生態體系(HDFS、MapReduce、HBase、Hive、Zookeeper、Pig、Flume、Sqoop、Mahout、Ambari 等)(見圖1 所示)、Spark 生態系統(Spark Core、SparkSQL、SparkStreaming、MLib等)(見圖2 所示),數據采集工具Kettle、可視化技術ECharts 等。面對如此多的技術,如何合理安排課程以銜接人才培養方案,也是需要考慮的內容。

圖1
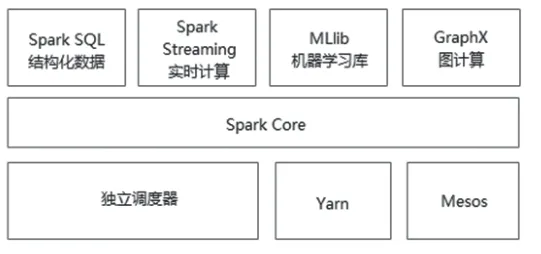
圖2
3 建議
綜上所述,高職大數據技術與應用專業所需掌握的技術多、難度大、時間短,在課程設置方面應注重課程的銜接性、整體性,避免重復性:
3.1 注重課程選擇的系統性,避免課程重復
前面所述,大數據專業涉及技術廣、選擇性也多,所以課程設置時要根據人才培養定位總體把握,避免出現課程重復的情況,例如,數據庫課程開設的是SQLServer,而在Hadoop 學習時更多是使用Linux 平臺,在Linux 平臺上連接數據庫優選MySQL,這樣就造成了課程之間的脫節、重復。
大數據專業的人才定位是大數據開發、運維、分析與挖掘,那么面對Java、C 語言、C++、Scala、Python、R 語言等大數據中常用的編程語言,如何進行選擇?根據學生學習時間及相近課程最少化原則,Java 及Python 是最好的選擇,Hadoop 是Java 語言開發,若要使用其核心組件HDFS 及MapReduce 進行大數據存儲及處理,掌握Java 語言更方便,開發的程序也更穩定;進行大數據開發必須要掌握一門web開發技術,那目前比較流行的是PHP 和JavaWeb,JavaWeb 和Java 是一個體系,開設JavaWeb,學生學習既可以達到深化的目的又可以形成整體的知識架構,而PHP 是新課程,學生學習會有抵觸的心理,而且構建的知識會比較零散。此外,選擇性比較多的還有數據庫,數據庫有SQLServer、MySQL、Oracle,SQLServer 早期產品只適用于Windows,Oracle 是收費軟件,MySQL 開源免費,MySQL 無論是在Java Web 保存數據還是在Hive 元數據存儲方面都更勝一籌。
3.2 注重課程之間的銜接性,避免知識斷層
第一學期可開設計算機文化基礎、網絡技術、Java 程序設計課程,培養學生大數據平臺搭建以及數據處理的專業基礎知識技能;第二學期可開設大數據概論、MySQL 數據庫、Linux 操作系統以及HTML 等課程,培養學生平臺應用以及數據存儲專業知識技能;第三學期進入專業核心課程學習,開設Python、數據清洗、JavaScript、Hadoop大數據技術與應用等,培養學生的大數據采集、清洗、分析、展示各階段的專業技能;第四學期進入專業知識拔高以及綜合運用階段,可開設Spark 編程提高大數據處理速度,開設Hbase 進行大數據查詢等,見表2 所示。
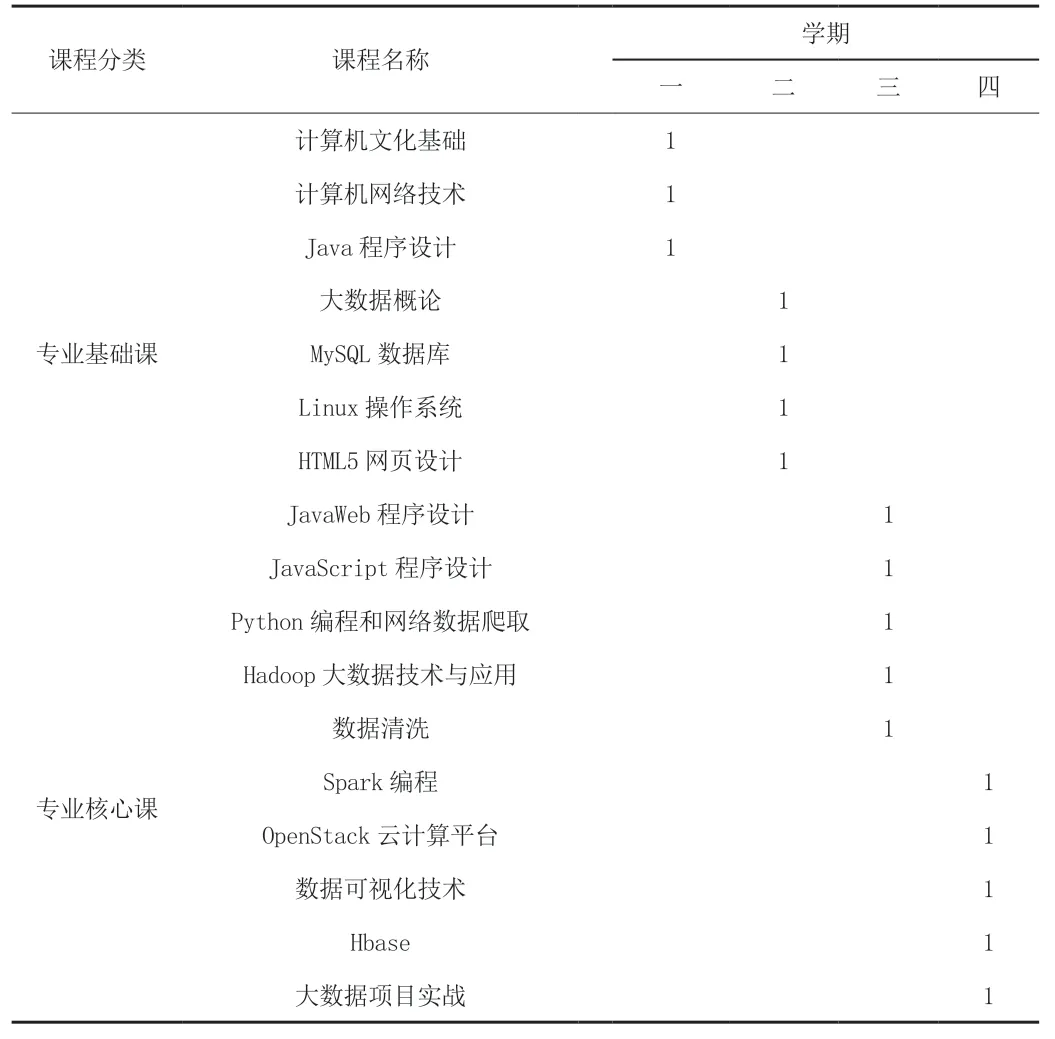
表2 大數據技術與應用專業課程設置
3.3 注重課程的整體性,避免課程覆蓋多而雜
Hadoop 生態系統和Spark 生態系統包含諸多組件,數據采集有爬蟲、flume 采集等,但教學中不能就每個技術逐個詳細講解,所以課程設置時要綜合考慮就業崗位知識技能需求以及課程之間的貫通性。
4 結語
大數據技術與應用專業作為新興專業,其在專業課程設置方面應該經過充分的調研論證,以知識點為抓手,以應用為目的,強化課程體系的整合建設,推動高職院校的辦學能力。
猜你喜歡
少先隊活動(2021年4期)2021-07-23 01:46:22
活力(2019年21期)2019-04-01 12:18:24
輔導員(2017年18期)2017-10-16 01:14:48
中國法學教育研究(2017年2期)2017-05-30 02:28:38
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
浙江理工大學學報(自然科學版)(2015年8期)2015-03-01 02:54:39
中國教育技術裝備(2015年6期)2015-03-01 02:36:27
江蘇第二師范學院學報(2014年2期)2014-04-16 03:10:09
都市快軌交通(2014年4期)2014-02-27 08:35:05
