面向智能化軟件開發的開源生態大數據探析
2021-02-11 06:15:34程平遠
無線互聯科技 2021年24期
王 崢,程平遠
(南陽職業學院,河南 南陽 474500)
1 軟件工程開源生態大數據概述
1.1 軟件工程開源生態的大數據體系
通常情況下可將軟件社區分為兩大部分,即開發社區和應用社區,與軟件工程相關的內容都可以被涵蓋其中。而軟件工程的主體部分可以是多種文本形式的,也就具有更為豐富的語義。在構建軟件工程開源生態的大數據體系時,一定要充分考慮到開發的具體環節、軟件的鏡像和應用、開發制品、問題咨詢以及應用過程等因素,并且能夠覆蓋GitHub,Docker Hub和Apache等多種類型的主流開源社區,使相關人員對軟件工程進行實驗和研究工作時,能夠以此為依據從全局的角度去考慮各類問題。在所構建的軟件工程開源生態的大數據體系中,主要總結并概括了3種數據的具體類型:開發數據、應用數據和交付數據。
1.2 軟件工程開源生態大數據的采集處理框架
研究中所構建的大數據采集處理框架具有模式多樣以及增量式的顯著優勢,而對于各種類型的軟件數據都能夠高效地完成收集、分析、處理和整合等工作。在研究中主要以定向采集、有效感知、增量檢測和多元關聯等先進技術為基礎,有針對性地設置了分布式爬蟲,可以直接下載相應的數據包,并且也能夠獲取到局域應用程序接口和網頁爬蟲的相關信息數據。在下載數據包時,很多軟件社區不僅會壓縮并且保存以往獲得的歷史數據,還會將數據存儲的地址提供給軟件工程的開發者;而針對網頁爬蟲中存在的信息數據,開發者應先針對具體的格式和實際特點進行深入研究,在充分考慮到網頁爬蟲常用的匹配方式的基礎上獲取數據信息。在實際工作中,經常會遇到重復爬行和效率偏低的問題,通常所采用的處理方式是應用分布式的網絡爬蟲技術,并行處理相關的信息數據從而提升工作中的實際爬取效率(見圖1)。
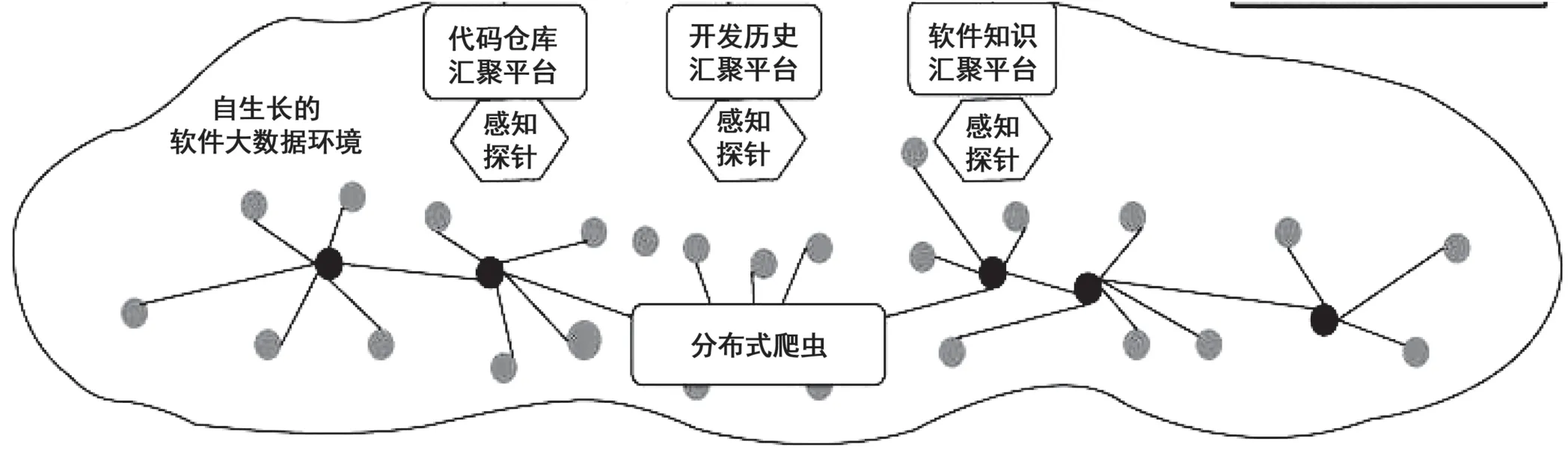
圖1 軟件工程開源生態大數據的采集處理框架
1.3 軟件工程開源生態大數據的匯聚及共享
軟件工程的開源生態大數據還具有多樣化、大規模以及較強異構性的特點。為了構建一個更為全面并且科學的軟件工程大數據的匯聚和共享平臺,在實際工作中應嚴格遵循以實際需求獲取、開放共享、平臺匯聚以及分類存儲的原則。在這種模式下,一般情況下都建議采用非結構化存儲和結構化存儲兩種相結合的方式。對于本地數據應添加一個檢索功能,在確定本地數據的查詢、控制以及共享等功能的基本單位時建議提供相應的知識描述模塊。為更好地表述出不同表之間的邏輯關聯關系,這一平臺還應具備知識描述和檢索的功能。平臺應將統一的訪問門戶提供給使用者,且在實時跟蹤使用者使用需求的基礎上不斷改進和完善動態數據。數據資源的接口應具有全面性和統一性,讓使用者能夠迅速找到自身所需要的數據信息。在實際工作中可將平臺放置在阿里云和UCloud上,在共享平臺直接存儲那些規模較小的數據,而對于那些較大規模的數據信息建議讓共享單位對其進行單獨管理[1]。
2 基于軟件工程開源生態大數據的智能化軟件開發
2.1 以數據開發為基礎的軟件知識圖譜構造
針對軟件工程中存在的主要問題,應先建立更為全面的軟件缺陷知識圖譜,而這一圖譜則要在科學運用主題模型LDA和文本相似度算法的基礎上來更有針對性地抽取關系并識別實體,其并不支持所有數據源的知識擴展工作,缺陷報告的數據以及源代碼數據對其有重要的影響。社區平臺中的工作人員應對所構建的CWE KG模塊進行有效編輯,與軟件弱點有較強關聯的各類文檔數據對其會產生直接影響。為保證軟件開發過程中的在線問答效果,筆者有針對性地建立了HDSKG模塊。同樣,為了更好地識別實體并抽取關系,筆者采用了基于規則和依賴解析的方式,這一模式必須具備所收集到的在線問答數據作為支持,其擴展性也會受到一定限制。以數據開發為基礎的軟件工程開源生態大數據所提煉出的軟件知識圖譜,語義更為豐富、規模更大并且所涵蓋的內容更廣泛,且具備有效查詢、搜索和儲存知識圖譜的功能,以此為基礎進行數據分析、融合和深度挖掘等工作。在數據分析的工作中,圖譜可與Word文檔、郵件列表日志、PDF文檔、網頁文檔、軟件源代碼和各類系統的版本記錄等多種類型的軟件工程數據相融合,同時具備更高的智能化程度,能夠及時地補全各類有較強關聯性的軟件數據以及整合出更易于被理解和接受的數據知識。
2.2 基于缺陷與社區問答數據的軟件代碼缺陷智能定位與修復技術
在軟件工程開源生態大數據中,相關的開發數據和應用數據作用十分關鍵,在實際的研究工作中一定要重點關注基于缺陷和社區問答數據的軟件代碼缺陷的智能定位與修復技術。軟件缺陷出現的概率與代碼的實際規模呈現出正比例關系。同時,缺陷報告文本附著的元數據以及缺陷報告與關聯代碼之間的密切關聯性都是其自身的顯著特點。在實際工作中所構建的文本主題模型應不僅能起到有效的監督作用,還能明確具體預測和訓練方法。這一方法比傳統更具修復能力,無論是實時的數據還是歷史數據都能夠將其有效修復,還能夠將語義相似度和文本相似度這兩大內容緊密結合,缺陷智能定位的精度更高。在實際所采用的開源項目包含著多個子項目,如JDT,PDE和Platform等子項目,在進行相同內容的工作時,這些子項目對信息數據的預測準確度得到了較大提高。由于缺陷定位的精準性會受到缺陷報告中文本附加信息影響,研究人員提出了L2SS+模型簇的概念,并對多個數據集合進行了實驗工作,從實驗中也更為明確了所構建的產品模塊信息是能夠直接影響到缺陷定位的準確性的,在同類工作中其準確率提高了20%左右[2]。
2.3 基于上下文感知的軟件問答資源推薦技術
研究人員為了更好地認知并掌握軟件工程開源生態大數據中交付數據和應用數據,在工作中還可以根據對上下文的感知情況來更有針對性地推薦軟件的問答資源,這一研究內容在軟件問答推薦領域中都具有前瞻性。以往也有一些研究感知考慮到上下文的感知情況,但其主要還是考慮代碼本身的關鍵詞,對于其中的語義內容以及存在于系統中的大量問答知識都沒有被充分地考慮到,本系統研究人員主要采用的方法是將代碼上下文中的關鍵詞抽取出來并借助于檢索功能來縮小問答數據的實際集合,使每一個問答數據與上下文之間的關聯性能夠被計算出來,在整體排序各類計算結果后,直接推薦給軟件工程的開發者。
3 結語
通過以上的論述,本文對軟件工程開源生態大數據概述及基于軟件工程開源生態大數據的智能化軟件開發兩個方面的內容進行了詳細分析和探討,對其大數據的體系以及框架中的各類功能進行了深入研究和探索,并對其知識圖譜構造、缺陷智能定位與修復以及問答資源推薦等關鍵技術進行了闡述,在對面向智能化軟件開發的各類開源生態大數據的研究工作中具有很強的實際應用價值。
猜你喜歡
保健醫苑(2021年7期)2021-08-13 08:48:02
甘肅教育(2020年8期)2020-06-11 06:10:02
學生天地(2020年36期)2020-06-09 03:12:30
小學科學(學生版)(2020年5期)2020-05-25 07:11:32
小學科學(學生版)(2020年4期)2020-05-21 07:30:46
小學科學(學生版)(2020年3期)2020-03-25 13:31:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
