基于關聯數據技術的機構知識庫構建與服務
2021-01-12 02:54:54郭衛兵臧莉娟
兵器裝備工程學報 2020年12期
郭衛兵,臧莉娟
(1.南京理工大學圖書館/信息化建設與管理處, 南京 210094;2.南京理工大學科學技術協會, 南京 210094; 3.南京大學信息管理學院,南京 210093)
機構知識庫(Institutional Repository,簡稱IR)是開放存取理念下形成的新型學術出版與交流模式[1],主要用來長期保存和展示本機構的數字化學術資源,以實現多個機構間的學術交流與共享。隨著信息資源的爆炸式增長和信息化平臺的不斷應用,國防科研機構在收集并存儲著各類信息資源的同時,形成大量“信息孤島”,一方面信息系統互聯陷入瓶頸,另一方面信息資源浪費嚴重[2-3]。機構知識庫在世界范圍內的學術研究與實踐發展都非常迅速,但我國的研究起步稍晚,其開放獲取意識不強、缺乏規范、認知不夠,也跟不上信息社會發展的步伐[4]。如何有效的進行知識組織、合理的構建知識庫、避免“信息孤島”和資源浪費、提供給用戶高質量信息服務成為了國防科研機構知識庫建設亟待解決的一個問題。互聯網之父Berners-Lee提出的關聯數據(linked of data),是實現數據網絡(web of data)的關鍵技術,給國防科研機構知識庫的構建和服務提供了一種新的解決思路。
1 關聯數據在國防科研機構知識庫中的應用
關聯數據的基本原理是強調數據的相互關聯、相互聯系,采用RDF數據模型,利用URI命名數據實體,來發布和部署實例數據以及其他各類數據到數據網絡上,用戶可以通過HTTP協議解釋這些數據,并以易于人機理解的語境信息來獲取[5]。關聯數據遵循四項基本原則:1) 使用URI作為Web上資源的唯一標識名稱;2) 任何用戶都可以使用HTTP URI定位并查找到這一資源;3) 當某一URI被訪問時,以RDF標準形式返回有用的信息;4) 盡可能返回指向其他URI的相關鏈接,以便檢索到更多信息[6]。因此,在建設機構知識庫時,可以利用關聯數據的基本原理和基本原則達到知識組織、機構庫構建、資源集成與共享等目的。
1.1 可行性分析
關聯數據支持結構化數據的任意關聯。基于大數據中客觀實體與抽象概念間所蘊藏的豐富關聯關系,關聯數據通過網絡發布的方式實現任意結構化數據的獲取,同時依托語義網技術構建數據資源關聯網絡,實現數據資源語義層面關聯關系,建立數據資源發現機制。眾所周知,資源發現和數據互聯互通對機構知識庫建設尤其重要,而關聯數據的資源發現機制則為國防科研機構知識庫的資源發現和數據互聯互通提供了一種可行的方法。
關聯數據使用發布和鏈接具有語義關系的結構化數據的方式使現有的分散異構的Web數據資源實現語義關聯,解決了現有Web網絡信息的粗粒度與語義性缺失的問題,從而促進傳統Web網絡向共享數據網絡演進[7]。從關聯數據的發展來看,越來越多的機構和組織通過遵循關聯數據發布原則[8],以開放獲取模式發布數據以與其他數據源進行語義關聯。就國防科研機構知識庫而言,其蘊含著大量具有豐富空間屬性的科學概念和學術實體信息,傳統的Web構建方式使得它們分散無序而無法作為一個整體發揮其最大價值;第二,國防科研機構知識庫資源的服務與利用率較低,也由于某些因素不能在網絡公開,無法與網絡資源進行關聯集成。關聯數據的發展目標及其實踐證明了關聯數據能夠有效解決當前國防科研機構知識庫所面臨的問題。
綜上所述,關聯數據和機構知識庫是相輔相成的,應用關聯數據來構建國防科研機構知識庫并開展相關信息服務是一個有效選擇。
1.2 實現流程
國防科研機構知識庫中應用關聯數據的實現流程[9]如下:
1) 獲取數據網絡中的關聯數據,將獲取到的關聯數據進行映射解析、提取、合并等處理,形成RDF數據庫。之后機構知識庫服務可以通過RDF API或者SPARQL等標準或接口訪問該RDF數據庫。
2) 將機構知識庫中的實體和抽象概念關系發布成關聯數據格式,建立自身的語義關聯關系,并將數字對象間的語義關聯關系擴展至已有的關聯詞表,使其支持基于SPARQL模式的語義查詢和推理擴展。
3) 利用RDF對機構知識庫中的數據進行語義標注并擴展到外部數據源。同時返回關于該數據的盡可能多的相關數據資源的統一視圖。
1.3 應用框架
關聯數據在國防科研機構知識庫中的應用框架包含5個部分,分別是關聯數據訪問器、關聯數據整理器、關聯數據存儲器、關聯數據檢索器和關聯關系構建器[10]。如圖1所示[10-11]:
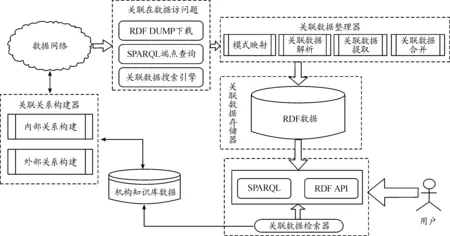
圖1 國防科研機構知識庫關聯數據應用框架示意圖
1) 關聯數據訪問器。從數據網絡中獲取關聯數據,可以通過RDF DUMP下載、SPARQL端點查詢兩種方式從LOD云圖中的數據源中直接獲取。
2) 關聯數據整理器。分析不同來源的數據,進行數據合并、提取、清洗、模式映射、解析等操作,將數據轉換到統一的容器中,形成增值的數據結果。
3) 關聯數據存儲器。主要將整合后的關聯數據以RDF格式保存為RDF數據,并對其進行管理,有臨時性緩存整合后的結果和采用一個永久性的存儲設備保存兩種方式。
4) 關聯數據檢索器。主要提供如SPARQL端點查詢、RDF API等基于RDF數據的標準訪問和調用接口,以便將整合和集成后的關聯數據融合到國防科研機構知識庫應用的服務中。
5) 關聯關系構建器。主要建立國防科研機構知識庫自身數據之間,以及與其他數據源之間的關聯關系。通過關聯關系為機構知識庫數據增值。
2 基于關聯數據的機構知識庫構建
2.1 基本框架
傳統的機構知識庫不具備資源互操作性,其內部數據之間、內部數據與外部數據之間缺乏一定的關聯,給用戶對機構知識庫的利用尤其是異構庫之間的資源集成與共享帶來一定的不便。關聯數據能夠將機構知識庫中的信息資源轉化成語義數據并通過URI標識,利用RDF關聯,通過HTTP協議揭示并獲取,最終實現機構知識庫信息資源的集成與共享[12]。依據關聯數據的基本原理和傳統機構知識庫的構建模式,并遵循上文所敘述的關聯數據在國防科研機構知識庫中的應用框架,筆者概括并總結出基于關聯數據的國防科研機構知識庫構建,如圖2。
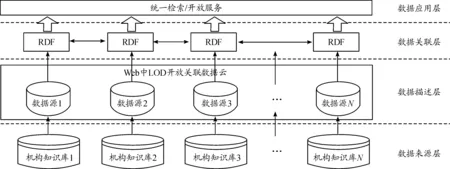
圖2 基于關聯數據的國防科研機構知識庫構建框圖
圖3的構建框架按照數據源從采集、處理到應用的過程可以分為數據來源層、數據描述層、數據關聯層和數據應用層等4個層次。數據來源層即各機構知識庫的結構化數據及文本型數據;數據描述層即針對各機構知識庫的信息資源用RDF來描述、按照“關聯數據四項基本原則”發布到網絡或內網上;數據關聯層即通過不同來源的資源內部可能存在特定的關聯關系將其建立鏈接,形成一個數據的網絡;數據應用層主要是建立關聯數據基礎上的Web應用,包括數據瀏覽、統一檢索、Web接口等。
傳統的機構知識庫構建模式有自主模式和聯盟模式[13]兩種,自主模式是指獨立機構以下屬部門為基本單位構建屬于該機構的機構知識庫,該構建模式構建單位顆粒度小,不便多機構間的數據共享。聯盟模式指多個機構合作構建機構知識庫,通過分布采集數據提供統一的檢索入口或界面,或通過集中存儲數據來實現多機構間的資源共享,但該模式構建主體不明確,不利于機構品牌的建立。基于關聯數據的機構知識庫構建模式將上述兩種構建模式有效集合起來,既保證了本機構的品牌建設,又能夠很好的實現多個機構之間的資源共享。
2.2 關鍵技術
通過上述分析,關聯數據在國防科研機構知識庫構建方面的關鍵技術總結如下:
1) 利用關聯數據技術將機構知識庫中的數據發布成語義層面的關聯數據格式。由于傳統機構知識庫無法對信息資源進行有效的語義描述,信息資源當中的實體與抽象概念也無法被外部資源開放獲取[14],因此要實現機構知識庫的開放關聯,就要將其數據以關聯數據形式予以發布。關聯數據的發布涉及到數據URI命名、詞匯集創建、數據RDF描述、發布模式、發布工具等問題。
2) 利用關聯數據技術對機構知識庫進行語義標注。要實現機構知識庫中關聯數據的關聯訪問,就需要對機構知識庫中的數據進行語義標注,具體操作就是依據機構知識庫中實體和抽象概念間的各類關聯關系,利用RDF在機構知識庫內部和外部創建各種類型的RDF語義鏈接,從而利用RDF鏈接機制擴展到外部數據源,進而實現數據網絡中各機構知識庫數據的相互關聯。
3) 主要涉及到的語義網三大核心技術:RDF、OWL和SAPRQL。RDF (Resource Description Framework)資源描述框架是描述網絡資源的 W3C 標準,本質上是一種數據模型,它專門用于表達關于Web資源的元數據,比如網頁的標題、作者、創建日期、詳細內容等,Web上不同的被RDF描述的資源便可以建立起特定的語義關聯[15]。OWL(Ontology Language)是W3C開發的一種網絡本體語言,用于對本體進行語義描述,其目的是為了更好地開發語義網[17],它強化了數據網絡中機構知識庫數據之間的語義關聯性,更方便基于關聯數據的語義關聯。SPARQL(Simple Protocol and RDF Query Language)是為RDF開發的一種查詢語言和數據獲取協議[16],用于查詢任何以RDF表示的信息資源,其目標就是可以像SQL檢索關系數據庫一樣檢索語義Web,現在SPARQL語言可以對不同類型的RDF資源進行集成檢索。
2.3 系統設計
本文中系統設計的主要目標是對國防科研機構知識庫進行語義擴展以期實現異構庫間的資源集成與共享服務。系統結構如圖3所示。
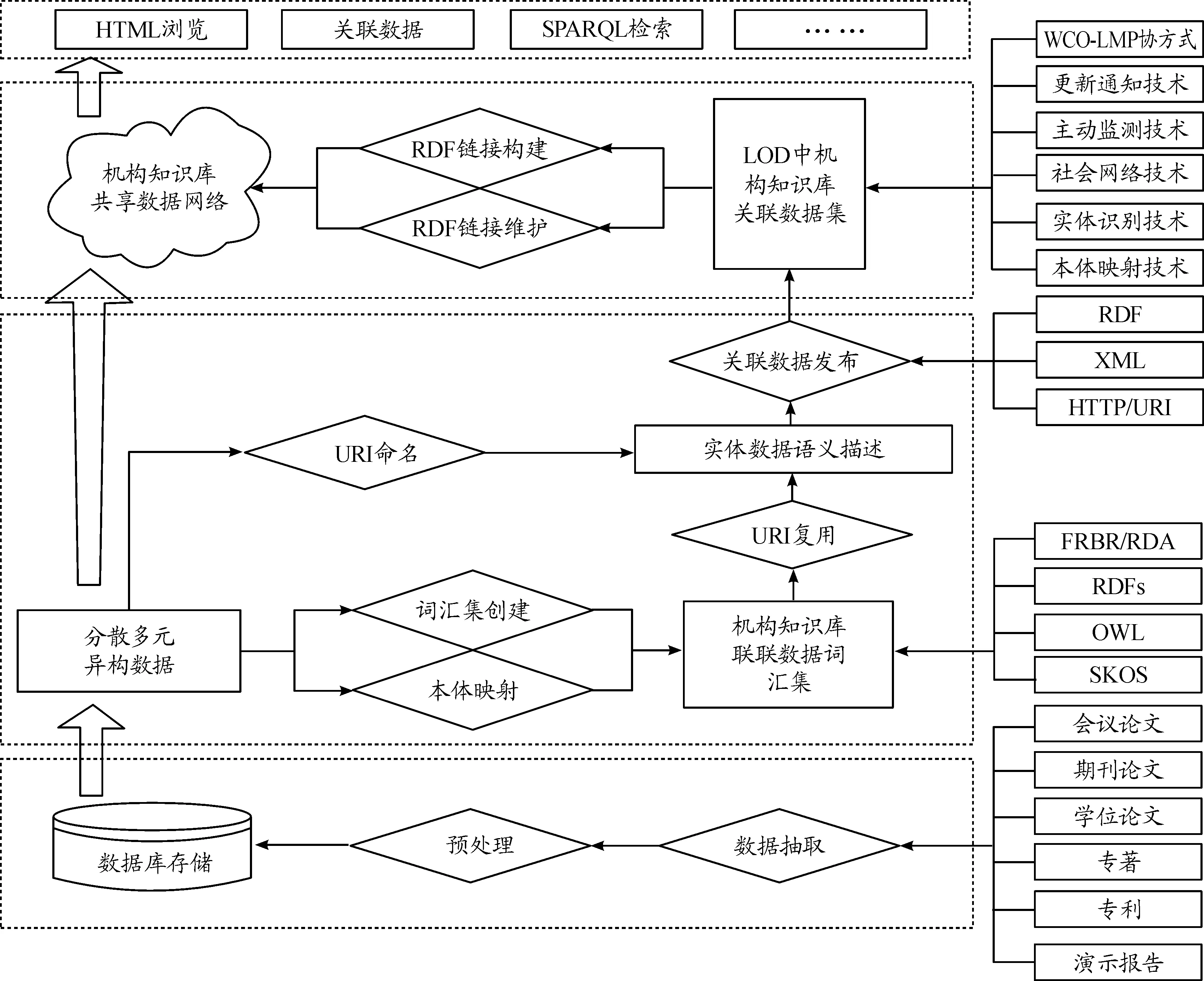
圖3 系統結構圖
1) 實體關系的抽取和添加約束
國防科研機構知識庫內的數據來源于機構內的各個部門,每個部門又可以分為多個子部門和專題,就其內容類型來說,又包括了專著、期刊論文、會議論文、學位論文、專利、演示報告、工作文檔等多種數據集,這些數據與作者、學科主題等核心實體有著直接聯系。如部門及其子部門的上下級關系、作者與部門的從屬關系、作者與學科主題的歸屬關系、作者間的合作關系等,可為這些實體及關系添加約束。在底層數據庫設計時,可將該隱形約束轉化為外鍵關聯條件。
2) 關聯數據詞匯集的創建
國防科研機構知識庫內的數據包括了各類實體和抽象概念,以及它們之間的顯性或隱性關聯關系。使用RDF+OWL對這些要素予以描述是關聯數據構建的一個重要環節,即使用計算機可以理解的語言來描述資源的相關陳述。關聯數據構建的四項基本原則之一就是盡可能的復用已有的關聯詞表或模型,數字圖書館領域常用以對象描述的DC、SKOS、FOAF、ISWC、VCARD等元數據標準均已實現了全面的關聯數據化,可用作復用關聯詞表。機構知識庫的關聯數據源需根據已有的類和屬性來選擇,可用的關聯數據源有DB Ontology、DBLP Bibliography等。D2R能夠建立關聯詞表和關聯數據源之間的詞匯映射關系,構建符合機構知識庫的語義映射模式,形成詞表映射和語義擴展方案。在程序中完成對實體數據的RDF語義標注和關聯后,關聯數據詞匯集創建完成,此時該數據集可關聯至外部數據源。從其他學者的經驗來看,機構知識庫各實體和抽象概念等數據對象應使用以“http://”+“本機構知識庫的域名”開頭的URI進行命名,這樣可以保證該URI標識能夠被任何遵循HTTP協議的應用程序所解析。
3) 關聯數據集的發布
國防科研機構知識庫需根據數據特點與機構知識庫應用需求的特點,進行抽取實體、映射RDF等操作,實現機構知識庫中各實體與抽象概念的語義描述與之間的關聯,這樣國防科研機構知識庫的信息資源就成為具有語義揭示功能的網絡化數據集。在此基礎上,選擇合理的靜態RDF文件,利用關聯數據存儲器,在線生成RDF數據的關聯數據發布模式,再利用描述RDF數據集的VOID詞表、D2R Server等關聯數據發布工具,將RDF關聯數據集發布到LOD云或內部共享網絡中,這是實現國防科研機構知識庫數據關聯發現和開放共享的關鍵一步。
4) 構建共享數據網絡
構建關聯數據網絡首先必須選擇已經在LOD網絡中發布的合適的機構知識庫開放關聯數據集并與其構建鏈接關系,從而保證國防科研機構知識庫本身數據能夠與其他機構知識庫已發布的關聯數據實現關聯與共享。根據國防科研機構知識庫中各實體和抽象概念數據及其之間的各種關聯關系,利用RDF三元組構建和維護不同機構知識庫數據集之間的RDF鏈接,進而利用這樣的RDF語義鏈接創建多源異構機構知識庫的復雜數據網絡以實現各機構知識庫數據的開放共享、語義關聯和重用。RDF構建就是機構知識庫數據集內部與外部創建各種類型的語義鏈接,RDF維護就是對已經構建的RDF鏈接進行修改和刪除操作,保證數據的準確性,構建和維護RDF鏈接可以是人工或自動來進行。
3 基于關聯數據的國防科研機構知識庫服務模式
關聯數據實現了Web上存儲資源、通信資源、軟件資源、知識資源等資源的鏈接和連通[18],其在國防科研機構知識庫上的應用為用戶提供了新的服務模式。主要表現如下。
1) 資源檢索和發現
傳統的機構知識庫在資源檢索方面存在一些不足,如不同形式的作者、不同機構或部門的檢全率不高、檢索結果無法進行語義擴展等。基于關聯數據技術的國防科研機構知識庫采用規范文檔和詞表提供擴展檢索服務,如同義詞擴展檢索、上下位詞擴展檢索、語義擴展檢索等,有效地解決了上述不足。
傳統的機構知識庫在信息的創建、管理、傳遞和共享方面也存在明顯不足,基于關聯數據技術的國防科研機構知識庫則提供了資源的發現和導航服務。關聯數據豐富了機構知識庫現有元數據,并擴展到外部關聯數據源,提供了外部相關資源的關聯訪問,加強了國防科研機構知識庫與其他相關資源的鏈接。
2) 資源集成與共享
傳統的機構知識庫跨機構合作和共享數據能力弱,基于關聯數據技術的機構知識庫以LOD中機構知識庫關聯數據集為基礎,利用RDF鏈接構建了機構知識庫共享數據網絡,提供了更強的跨機構合作和資源共享能力,也為第三方提供了便利的底層數據存取方式。 即只要某機構知識庫創建了關聯數據集并發布至LOD中,便可共享LOD中其他機構知識庫的關聯數據,同時第三方也可方便地存取該關聯數據。
3) 知識處理和挖掘
關聯數據與生俱來的關聯特性使得關聯數據自出現起就與知識組織、知識處理等方面有著密不可分的關系。關聯數據為機構知識庫中的結構化數據進行了語義標注,也使基于關聯數據技術的國防科研機構知識庫變得適合進行數據挖掘。
4 結論
1) 關聯數據的應用有助于解決國防科研機構知識庫的“信息孤島”和資源浪費問題。發布于LOD云中的機構知識庫可以與其他資源建立關聯,成為數據網絡的一份子。
2) 本文依據關聯數據的四項基本原則構建了基于關聯數據技術的國防科研機構知識庫的應用框架和基本框架,能夠利用關聯數據的資源發現機制,通過機構知識庫關聯數據詞匯集的創建、關聯數據集的發布和數據網絡的構建等系列操作,實現國防科研機構知識庫數據資源的資源集成與開放共享。
3) 期望通過本文的研究對我國國防科研機構知識庫的建設和服務提供參考與借鑒。本文所設計的應用框架和系統結構可能還存在需要完善的地方,另外對于服務模式尤其是知識挖掘部分也未進行詳細的探討。這兩個方面都將是后續研究的重點。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
當代陜西(2021年17期)2021-11-06 03:21:36
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
資源再生(2017年3期)2017-06-01 12:20:59
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
