基于近紅外光譜的摻偽油茶籽油檢測
2020-10-10 06:31:58郭文川朱德寬杜榮宇
農業機械學報 2020年9期
郭文川 朱德寬 張 乾 杜榮宇
(1.西北農林科技大學機械與電子工程學院, 陜西楊凌 712100; 2.農業農村部農業物聯網重點實驗室, 陜西楊凌 712100)
0 引言
油茶籽油富含油酸、亞油酸、亞麻酸等不飽和脂肪酸[1],其脂肪酸組成與橄欖油相似[2]。油茶籽油的優良品質使其市場銷售價格是普通植物油的5~10倍。隨著人們身體健康意識的增強,油茶籽油的市場需求量也逐漸增大。一些不法經營者為了謀取高額利潤,向油茶籽油中摻入廉價的普通植物油,嚴重損害了消費者與合法經營者的正當權益。
目前,用于檢測食用油品質的方法主要有氣相色譜[3]、液相色譜[4]、低場核磁共振[5]、激發矩陣熒光光譜[6]、電子鼻[7]等方法。這些方法需要使用大型昂貴的分析儀器或大量的化學試劑,因而整個檢測過程費時、繁瑣,且成本較高,無法滿足快速鑒別摻偽油茶籽油的要求。近紅外光譜分析技術是一種無損、快速、高效且無污染的現代分析技術,已廣泛應用于多種領域[8-13]。
目前,在應用近紅外光譜技術檢測摻偽油茶籽油方面已有一些研究報道[14-16]。但現有研究的樣本量偏少,而且大多是直接利用全光譜數據建模或將吸收峰附近的光譜作為輸入變量。直接利用全光譜數據建模使得模型輸入變量多、模型復雜,易出現過擬合的現象,同時無關信息的引入有可能降低模型的精度,且不利于經濟實用的檢測儀開發。而直接以油茶籽油光譜吸收峰的位置作為建模變量,則有可能忽略其他光譜處對建模有用的信息[17]。為了開發便攜式摻偽油茶籽油檢測儀,有必要提取對摻偽油茶籽油敏感的特征波長,并分析其對建模效果的影響。本文以多個產地生產的油茶籽油、玉米油、花生油、菜籽油和大豆油為對象,制備摻偽油茶籽油,采用不同方法從全光譜數據中提取對摻偽油茶籽油敏感的特征波長,并基于全光譜數據和提取的特征波長建立識別摻偽油茶籽油的判別模型,對模型的綜合性能進行分析,以期為基于多光譜技術的摻偽油茶籽油檢測儀的研發提供基礎數據。
1 材料與方法
1.1 試驗材料
1.1.1試驗樣本
試驗所用油茶籽油樣品共5個,產地分別為江西省吉安市、江西省玉山市、湖南省永州市祁陽縣、浙江省杭州市和廣西壯族自治區河池市巴馬瑤族自治縣。用作摻偽的植物油為玉米油、花生油、菜籽油和大豆油,每類植物油均來自3個不同產地。故用于摻偽的植物油樣品共計12個。試驗所用油均購于西安市某大型超市,所購置的油茶籽油均符合GB/T 11765—2018。試驗期間,所有樣品均在保質期內。
制備樣品時,向每個約20 g油茶籽油樣品中按摻偽質量分數為1%、3%、6%、10%、15%和20%的梯度摻入12個用于摻偽的植物油樣品,共得到360個摻偽油茶籽油樣品。
為了增加純油茶籽油樣本量以保證后續試驗所建模型具有普遍性,按質量分數0~90%間以10%為梯度將5個純油茶籽油樣品兩兩混合,共得到95個不同的純油茶籽油樣品。
1.1.2試驗儀器及軟件
FA2004型電子天平(上海舜宇恒平科學儀器有限公司,精度0.1 mg);MPA型傅里葉變換近紅外光譜儀(德國Bruker公司,配備積分球漫反射附件,波長范圍為833~2 500 nm)。
由MPA型傅里葉變換近紅外光譜儀自帶的光譜分析軟件OPUS 6.5 (德國Bruker公司) 采集光譜數據;由Matlab2016a (美國The MathWork公司)完成光譜數據預處理、樣本劃分、特征波長提取和模型建立。
1.2 近紅外光譜采集
利用傅里葉變換近紅外光譜儀采集樣本的近紅外漫反射光譜。光譜掃描范圍:833~2 500 nm (12 000~4 000 cm-1),掃描次數:32次;光譜分辨率:8 cm-1;采集條件:室溫(23~25℃),以空比色皿為參比。采集光譜時每個樣品測量3次,取平均值作為該樣品的最終光譜。
1.3 光譜預處理
由于受到儀器自身或外界環境的干擾,所采集的近紅外光譜會受到噪聲、基線偏移等與建模無關信息的影響,因此在建模前需要對采集的原始光譜進行預處理。常見的光譜預處理方法有Savitzky-Golay (S-G)平滑、標準正態變量變換(Standard normal variate transformation, SNV)、多元散射校正(Multiple scatter correction, MSC)、一階微分、二階微分等。
S-G平滑法是光譜分析中常用的預處理方法,它是基于最小二乘原理的移動窗口加權平均算法,能有效地提高光譜的平滑性,并降低噪聲的干擾[18]。SNV和MSC法可以消除表面散射、固體顆粒大小和光程變化對近紅外漫反射光譜的影響,達到去噪的效果[19-20]。一階微分、二階微分等導數預處理方法能減少由系統內部引起的隨機噪聲,并能增強處理后信號頻率的分辨率。
1.4 樣品劃分
基于樣本光譜間歐氏距離的Kennard-Stone (K-S)樣本劃分方法,能有效地將光譜差異較大的樣品選入校正集,將其余相近樣品歸入測試集,達到保證校正集樣品具有代表性和均勻性的目的[21]。因而K-S方法被廣泛地用在定性研究中對樣本進行劃分。
1.5 特征波長選擇
1.5.1連續投影算法
基于向量投影分析的連續投影(Successive projections algorithm, SPA)算法能夠在光譜矩陣中充分尋找含有最低限度冗余信息的變量組,使變量之間的共線性達到最小。同時能極大地減少建模所用特征波長的數量,提高建模的速度和效率[22]。
對于定性分析問題,文獻[23]提出提取的波長數量可以由G值確定。G值定義為
(1)
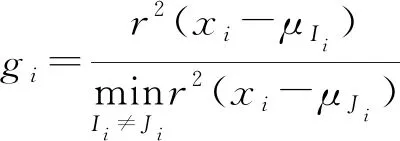
(2)
式中n——總樣品數
xi——SPA選定波長下第i個樣品的吸光度
μIi——第i個樣品所屬類別的平均吸光度
μJi——第i個樣品對應錯誤類別的平均吸光度
r(xi-μIi)——xi與μIi馬氏距離
Ii、Ji——第i個樣品對應的正確、錯誤類別
gi應該盡可能小,即xi應該靠近其真實類別樣本的中心,并且與錯誤類別樣本中心相距較遠。
1.5.2無信息變量消除算法
無信息變量消除(Uninformative variable elimination, UVE)算法通過引入一定數目的隨機變量到光譜矩陣中,建立偏最小二乘回歸(Partial least squares regression, PLS)交互驗證模型,根據各波長穩定性指數,即回歸系數向量的均值與標準偏差的商的絕對值,決定光譜變量是否被選取[24]。
1.5.3競爭性自適應重加權算法
競爭性自適應重加權(Competitive adaptive reweighted sampling, CARS)算法是將每個波長作為一個單獨的個體,利用自適應加權采樣技術篩選出PLS模型中回歸系數絕對值大的波長點,淘汰回歸系數絕對值小的波長點,利用交互驗證選出均方根誤差(Root mean square error of cross validation, RMSECV)最低的波長變量子集作為優選波長變量子集[25]。
1.6 建模方法及評價指標
1.6.1支持向量機
支持向量機(Support vector machine, SVM)是一種以結構風險最小化為基礎思想的有監督學習模式識別算法[26]。該算法將原始數據映射到高維空間以構建最優的分類超平面,然后假設分類器誤差與平行超平面間的距離成反比關系,從而解決常規空間里數據間線性不可分的問題[27]。SVM在解決小樣本、非線性和高維模式識別問題中表現出許多特有的優勢,并在很大程度上克服了“維數災難”和“過學習”等問題。
1.6.2隨機森林
隨機森林(Random forest, RF)是一種用于分類和回歸的機器學習方法。該方法組合多個決策樹算法對相同現象產生重復的預測結果。RF算法對每棵決策樹進行自助法重采樣,使誤差估計的計算能夠基于袋外樣本數據。該算法的優點體現在對數據集中的噪聲有較強的魯棒性,不需要另外預留部分數據做交叉驗證[28]。
1.6.3評價指標
本研究將識別準確率、靈敏度、特異性作為油茶籽油判別模型的評價指標。識別準確率為純油茶籽油樣品和摻偽油茶籽油樣品被正確判別的百分比;靈敏度是指純油茶籽油樣品被正確判別為純油茶籽油的百分比;特異性是指摻偽油茶籽油樣品被正確判別為摻偽油茶籽油的百分比。
2 結果與討論
2.1 光譜分析
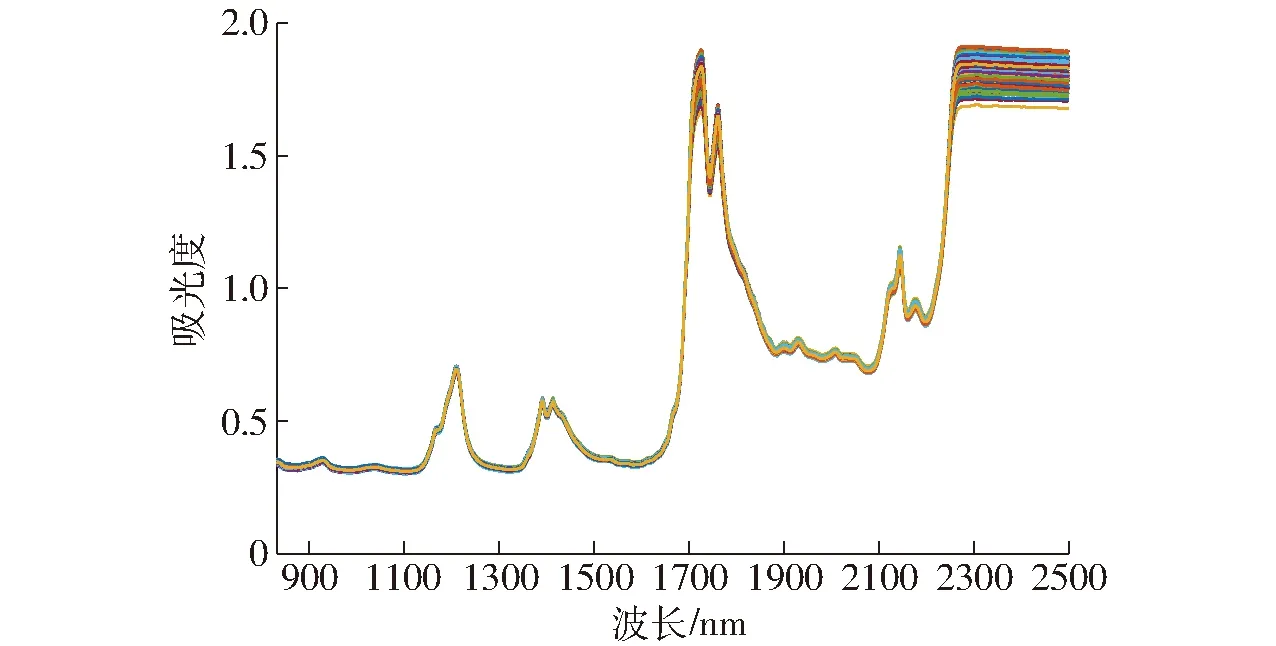
圖1 所有樣品的原始近紅外光譜Fig.1 Original near-infrared spectra of all samples

2.2 光譜預處理和樣本劃分
為了減少無關因素對建模效果的影響,分別用MSC、SNV、S-G平滑、一階微分和二階微分共5種預處理方法對光譜進行預處理,然后使用SVM建立油茶籽油摻偽判別模型。以徑向基函數作為SVM模型的核函數,并根據十折交叉驗證和網格搜索法選擇各模型交叉驗證識別準確率最高時對應的懲罰因子和核參數作為建模參數。具體參數見表1。
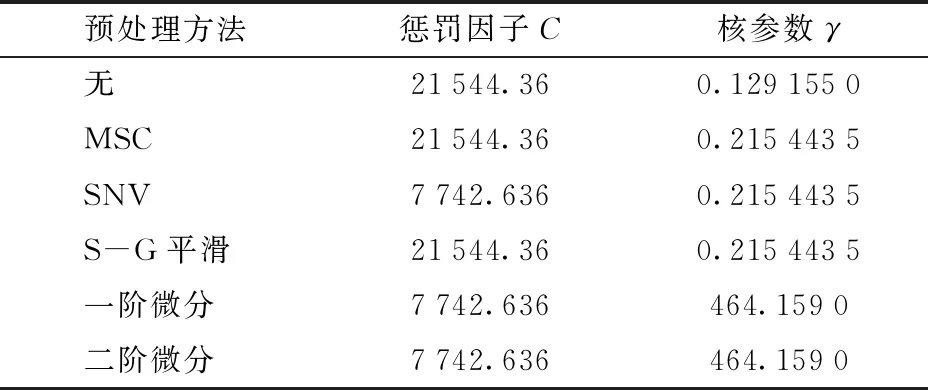
表1 不同預處理方法下SVM建模的參數Tab.1 Determined parameters of SVM models by different pretreatment methods
對比不同預處理方法下校正識別準確率和交叉驗證識別準確率,確定最優的光譜預處理方法。不同預處理方法的建模結果如表2所示。由于MSC預處理方法使得建立的SVM模型具有最高的交叉驗證識別準確率,因此在后續的研究中只對MSC預處理后的光譜進行分析。
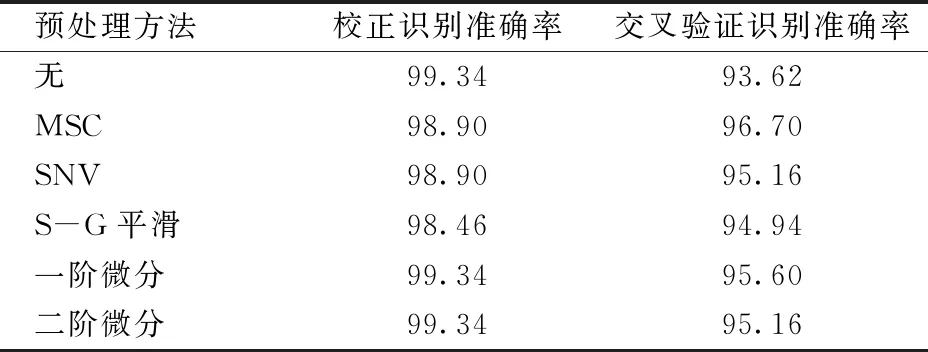
表2 不同預處理方法下SVM建模的預測結果Tab.2 Prediction results of SVM models by different pretreatment methods %
對經MSC處理后的光譜采用K-S法按2∶1的比例分別對360個摻偽油茶籽油和95個純油茶籽油進行樣本劃分,得到校正集樣品304個(240個摻偽油茶籽油和64個純油茶籽油樣品),測試集樣品151個(120個摻偽油茶籽油樣品和31個純油茶籽油樣品)。
2.3 特征波長選擇
2.3.1SPA算法
將該算法提取的最小波長數設定為1,最大數設定為30,計算不同特征波長數下的G,結果如圖2所示。由圖2可見,當特征波長數小于9時,隨著波長數的增加,G迅速減小,但當波長數量大于9時,G逐漸增大。以G最小處的波長數作為最佳波長數。因此本文以9個特征波長作為輸入的特征變量,該9個特征波長分別是1 163.64、1 235.16、1 382.72、1 419.82、1 458.97、1 633.64、1 733.02、1 756.50、1 896.56 nm。
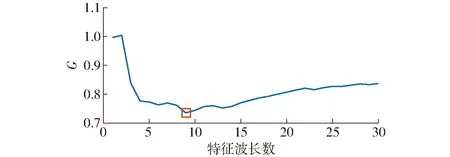
圖2 不同特征波長數的G變化曲線Fig.2 Calculated G values at different numbers of characteristic wavelengths
2.3.2UVE算法
基于UVE算法的摻偽油茶籽油特征波長選取結果如圖3所示。其中,豎線左側為全光譜1 178個波長的穩定性指數分布曲線,右側為相同數量的隨機變量穩定性指數分布曲線。以隨機變量穩定性指數最大絕對值的99%作為變量篩選的閾值,即穩定性指數在兩條水平虛線以外的特征波長被選中。利用UVE算法共選擇出207個特征波長,其分布如圖4所示。
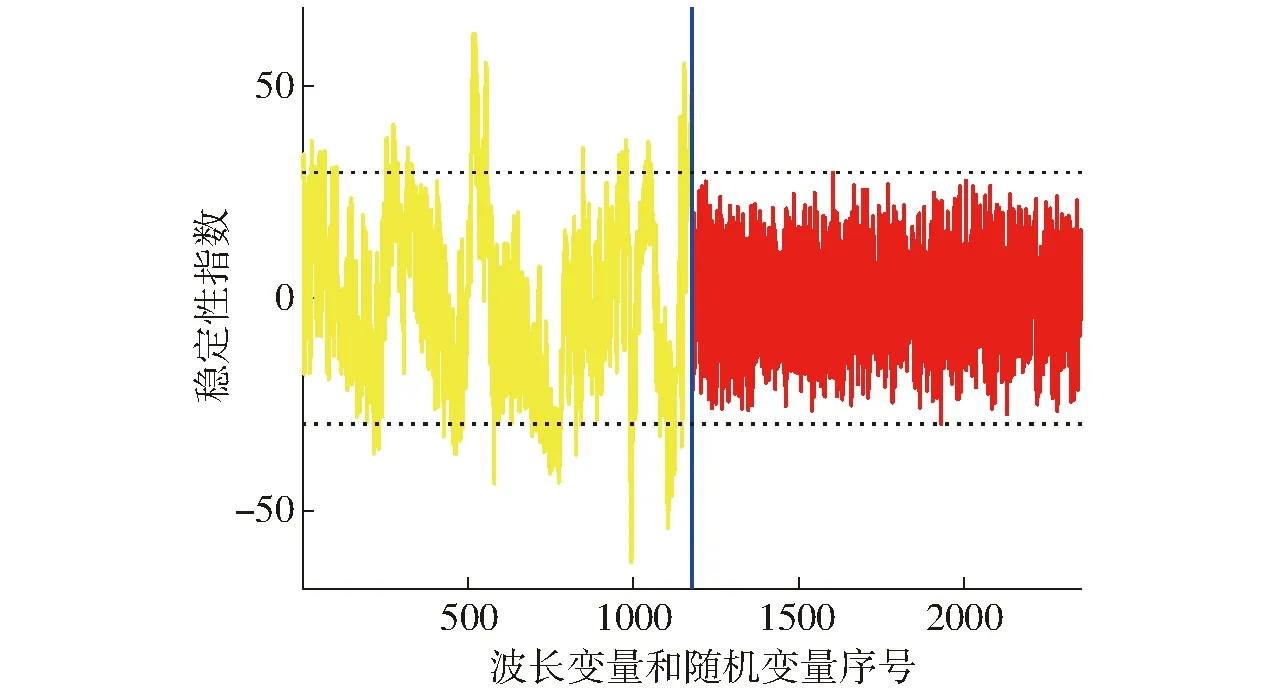
圖3 各波長變量和隨機變量下的穩定性指數Fig.3 Stability indices at different wavelength variables and random variables
2.3.3CARS算法
圖5為應用CARS算法篩選特征波長過程中特征波長數、RMSECV以及回歸系數隨運行次數的變化圖。由圖5可見,當運行次數從1次增加到28次,特征波長數從迅速下降到緩慢下降,RMSECV逐步降低,表明在1~28次篩選過程中淘汰了較多無關變量,模型精度逐步提高。當運行次數大于28次時,隨著運行次數的增加,RMSECV緩慢或快速增大,模型精度下降。在運行次數為28次時,RMSECV降到最低,此時有35個波長變量被保留下來。因此以該35個波長為特征波長,其分布如圖6所示。
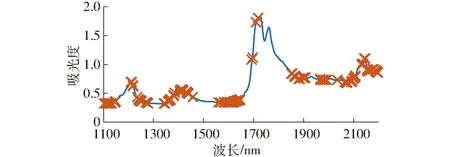
圖4 基于UVE算法篩選的特征波長Fig.4 Selected characteristic wavelengths by using UVE algorithm
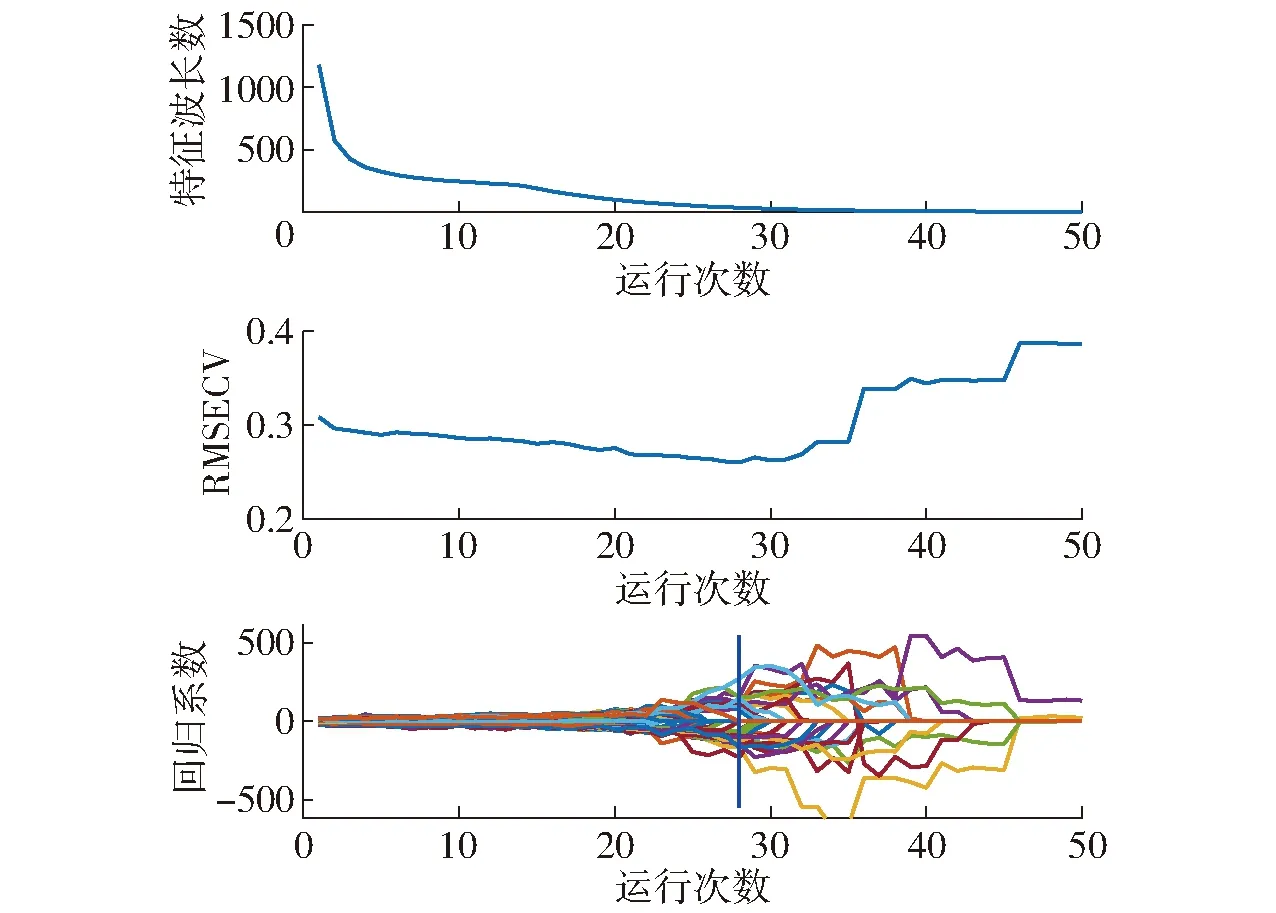
圖5 基于CARS算法篩選特征波長的過程Fig.5 Process of selecting characteristic wavelengths by using CARS algorithm
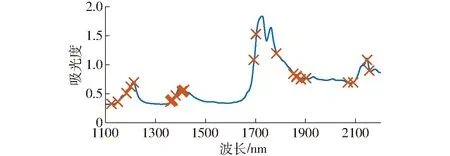
圖6 基于CARS算法篩選的特征波長Fig.6 Selected characteristic wavelengths by using CARS algorithm
從利用SPA、UVE和CARS算法提取的特征波長看,特征波長數明顯少于全光譜(1 100~2 200 nm)下的1 178個波長,分別僅是全光譜下波長數的0.936 9%、17.57%和2.971%。這說明提取特征波長對于簡化模型、提高運算速度有很重要的作用。此外,從提取的特征波長看,除了吸收峰或吸收峰附近的波長外,吸收峰之間的一些波長也是對摻偽油茶籽油敏感的特征波長。
2.4 建模結果及建模方法比較
2.4.1建模參數的選擇和設定
以徑向基函數作為SVM模型的核函數。根據十折交叉驗證和網格搜索法選取懲罰因子C和核參數γ。建立RF模型時,以不同特征波長提取方法下預測準確率最高時的決策樹個數作為RF模型的決策樹數量。確定的參數見表3。
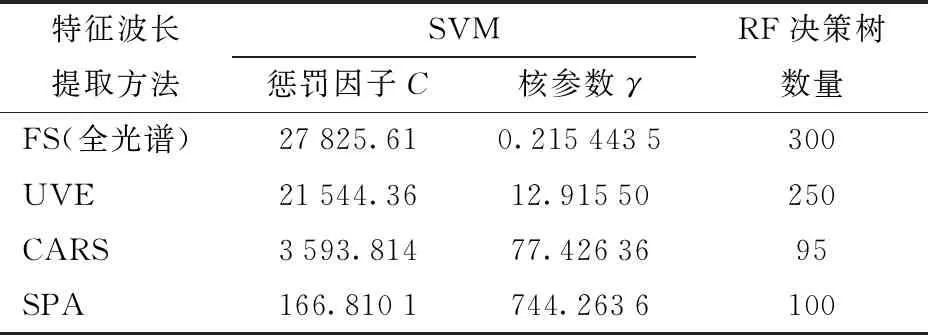
表3 不同特征波長提取方法確定的SVM和RF模型的參數Tab.3 Determined parameters of SVM and RF models by different methods of characteristic wavelength selection
2.4.2SVM模型建模結果
以不同方法所提取的特征波長作為建模輸入變量時,所建立的SVM模型對校正集和測試集的純油茶籽油和摻偽油茶籽油的判別結果見表4。由表4可以看出,基于SPA、UVE和CARS所提取的特征波長建立的SVM模型(SPA-SVM、UVE-SVM和CARS-SVM)對測試集的識別準確率分別為96.03%、96.69%和96.69%,均高于基于全光譜建立的SVM模型(FS-SVM)對測試集94.70%的識別準確率。在靈敏度方面,SPA-SVM的靈敏度與FS-SVM相同,均為96.77%,UVE-SVM和CARS-SVM的靈敏度最高,達到100%,說明UVE和CARS提高了SVM模型對純油茶籽油樣本的識別能力。在特異性方面,SPA-SVM、UVE-SVM和CARS-SVM的特異性均為95.83%,高于FS-SVM的94.17%,說明3種特征波長提取方法均提高了SVM模型對摻偽油茶籽油樣本的識別能力。
所建立的SVM模型對不同摻偽質量分數油茶籽油的識別準確率如表5所示。表5說明FS-SVM、UVE-SVM和CARS-SVM對摻偽質量分數為3%以上的油茶籽油樣本的識別準確率達到100%,UVE-SVM和CARS-SVM對摻偽質量分數為1%的油茶籽油樣本的識別準確率為73.68%,高于FS-SVM的63.16%,說明UVE和CARS提高了SVM模型對摻偽質量分數為1%的油茶籽油樣本的識別能力。而SPA方法雖然使SVM模型對摻偽質量分數為1%的油茶籽油樣本的識別準確率提高到78.95%,但對摻偽質量分數為3%的油茶籽油樣本的識別準確率卻下降到96.43%,說明SPA方法在減少波長輸入的同時也刪去了對SVM建模有用的信息。
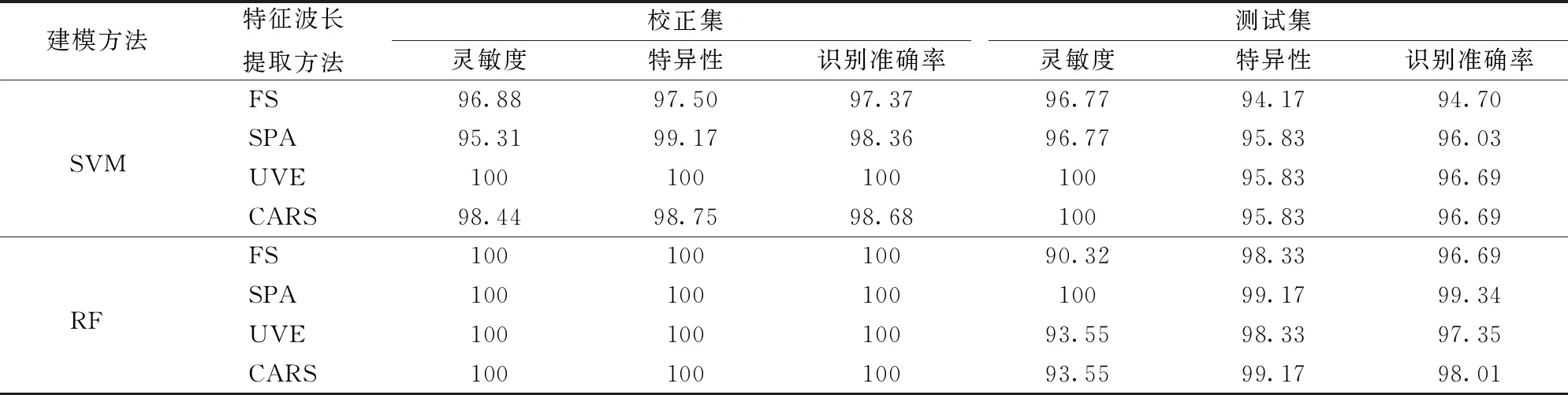
表4 不同特征波長提取方法下SVM和RF模型對純油菜籽油和摻偽油茶籽油的識別結果Tab.4 Identification results of SVM and RF models for pure and adulterated oil-tea camellia seed oil by using different characteristic wavelength selecting methods %
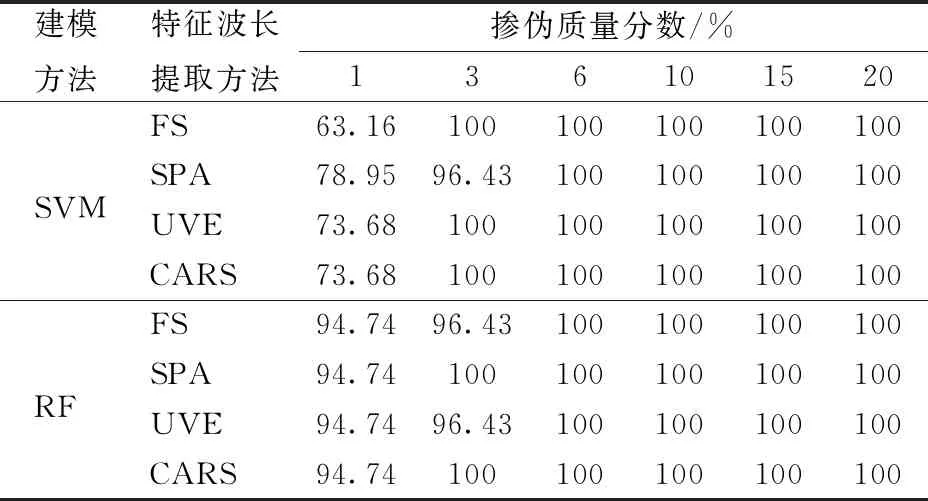
表5 不同模型對不同摻偽質量分數油茶籽油的識別準確率Tab.5 Identification accuracy of different models for adulterated oil-tea camellia seed oil at different mass fractions %
2.4.3RF模型建模結果
不同特征波長提取方法下,基于所提取的特征變量建立的RF模型對校正集和測試集中純油茶籽油和摻偽油茶籽油的判別結果見表4。由表4可見,基于SPA、UVE和CARS所提取的特征波長建立的RF模型(SPA-RF、UVE-RF和CARS-RF)的識別準確率分別為99.34%、97.35%和98.01%,均高于基于全光譜所建立的RF模型(FS-RF)。在靈敏度上,SPA-RF、UVE-RF和CARS-RF的靈敏度分別為100%、93.55%和93.55%,高于FS-RF的90.32%,說明3種特征波長提取方法均提高了RF模型對純油茶籽油的識別能力。在特異性上,UVE-RF與FS-RF的特異性相等,為98.33%,SPA-RF和CARS-RF的特異性均為99.17%,說明利用SPA和CARS特征波長提取方法提高了RF模型對摻偽油茶籽油的識別能力。
所建立的RF模型對不同摻偽質量分數油茶籽油的識別準確率見表5。由表5可見,不管是基于全光譜,還是基于不同方法所提取的特征波長,所建立的RF模型對摻偽質量分數為1%的摻偽油茶籽油的識別準確率均為94.74%。當摻偽質量分數為3%時,SPA-RF和CARS-RF的識別準確率為100%,高于FS-RF和UVE-RF 96.43%的識別準確率。結果表明,全光譜中含有對RF模型冗余的信息,而SPA和CARS方法比UVE方法能有效地從全光譜中提取出對摻偽油茶籽油敏感的特征波長。
2.4.4結果比較
當對SVM和RF模型性能進行比較時,由表4可知,除SPA外,測試集其他特征波長提取方法下所建SVM模型的靈敏度均高于RF模型的靈敏度,說明SVM模型對純油茶籽油的識別能力更強。而RF模型的特異性均高于SVM模型的特異性,說明RF模型對摻偽油茶籽油的識別能力更強。
由表5可知,RF模型對摻偽質量分數為1%的摻偽油茶籽油的識別準確率(94.74%)明顯高于SVM模型的最高識別準確率78.95%。而當摻偽質量分數在3%以上時,兩種模型的判別能力基本相當。
在所建立的8種摻偽油茶籽油判別模型中,測試集SPA-RF的識別準確率、靈敏度和特異性均最高,分別為99.34%、100%和99.17%(表4),且該模型對摻偽質量分數為1%和3%及以上的摻偽油茶籽油的識別準確率分別為94.74%和100%(表5)。此外,該模型的輸入波長數只有9個,對于簡化模型,降低運算時間和便攜式摻偽油茶籽油檢測儀的開發具有重要的意義。
3 結論
(1)研究了SPA、UVE和CARS 3種特征波長選擇方法下SVM和RF模型對不同摻偽質量分數(0~20%)油茶籽油的識別能力。結果表明,這3種特征波長提取方法均可提高所建模型對油茶籽油的識別準確率、靈敏度和特異性,SVM模型具有較高的靈敏度,而RF模型具有良好的特異性。
(2)在所建立的8個模型中,SPA-RF模型具有最佳識別能力,其識別準確率、靈敏度、特異性分別為99.34%、100%和99.17%,對摻偽質量分數為1%的摻偽油茶籽油識別準確率達94.74%,對摻偽質量分數為3%及以上的摻偽油茶籽油的識別準確率達到100%。本研究為基于多光譜技術開發便攜式摻偽油茶籽油檢測儀提供了基礎數據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
