一種基于無監督學習的空間域圖像融合方法
2020-05-30 03:32:58王淑青蔡穎婧
湖北工業大學學報 2020年2期
王淑青, 蔡穎婧
(1 湖北工業大學湖北省電網智能控制與裝備工程技術研究中心,湖北 武漢 430068;2 湖北工業大學電氣與電子工程學院, 湖北 武漢 430068)
過去的幾十年里出現的多種圖像融合方法可以分為兩類: 變換域方法和空間域方法[1]。最經典的是基于多尺度變換的變換域融合方法(MST)理論,如基于拉普拉斯算子的金字塔(LP)[2]和低通的比率金字塔(RP)[3]以及離散小波變換(DWT)[4],還有雙數復小波變換(DTCWT)[5]、曲波變換(CVT)和非下采樣輪廓波變換(NSCT),以及稀疏表示(SR)和摳圖融合(IMF)[6-8]。這些方法的關鍵在于,可以在選定的變換域中通過分解系數來測量源圖像的活躍度。顯然,變換域的選擇在這些方法中起著至關重要的作用。
近年來,深卷積神經網絡(CNN)在圖像處理方面取得了巨大的成功。一些研究試圖使用大容量深卷積模型來測量活躍度。Liu等[9]首次將卷積神經網絡應用于多聚焦圖像融合。Prabhakar[10]提出了一種基于CNN的無監督曝光融合方法,稱為深度融合。Li和Wu[11]提出了DenseFuse來融合紅外圖像和可見光圖像,采用無監督的編解碼器策略來獲取有用的特征,并按L1-norm融合。受深度融合的啟發,本文以無監督編解碼器的方式訓練網絡,并且將空間頻率作為融合規則來獲得源圖像的活躍度和決策圖,這與關鍵假設一致,即只有在景深范圍內的對象才具有清晰的外觀。
1 圖像融合
首先,在訓練階段,訓練一個自動編碼器網絡來提取高維特征。然后利用融合層在融合階段的深層特征計算出融合層的活躍度。最后,得到了融合兩個多焦點源圖像的決策圖。本文提出的算法只針對融合兩幅源圖像。
1.1 深層特征提取
從DenseFuse得到啟發,在訓練階段舍去融合操作,只使用編碼器和解碼器對輸入圖像進行重構。在編碼器和解碼器的參數確定后,利用空間頻率從編碼器獲得的深層特征中計算活躍度。
編碼器由兩部分(C1和SEDense塊)組成。C1是編碼器網絡中的一個3×3卷積層。DC1、DC2和DC3是SEDense塊中的3×3個卷積層,每層的輸出通過級聯操作連接。為了精確地重建圖像,網絡中不存在池層。擠壓和激勵(SE)塊可以通過自適應重新校準channel-wise特征響應來增強空間編碼,實驗表明了這種結構的影響。解碼器由C2、C3、C4和C5組成,用于重建輸入圖像。為了訓練編碼器和解碼器,將損失函數L最小化,它結合了像素損失LP和結構單線性度(SSIM)損失LSSIM。其中λ是一個常數,體現損失目標的權重
L=λLssim+LP
(1)
像素損失LP表示輸出(O)和輸入(I)之間的歐氏距離。
LP=‖O-I‖2
(2)
SSIM損失Lssim表示O和I之間的結構差異,其中SSIM表示結構相似操作。
Lssm=1-SSIM(O,I)
(3)
1.2 利用深度特征進行空間頻率計算
在本文中,編碼器為圖像中的每個像素提供高維深度特征。但原始的空間頻率是在單通道灰度圖像上計算的。因此對于深層特征,其修改了空間頻率計算方法。設F表示由編碼器塊驅動的深度有限元。F(x,y)表示一個特征向量,(x,y)表示這些向量在圖像中的坐標。本文使用下面的公式計算它的空間頻率,其中RF和CF分別是行向量頻率和列向量頻率。
(4)
(5)
(6)
其中r為核半徑。原始的空間頻率是基于塊的,而本文方法是基于像素的。于是可以比較兩個對應的SF1和SF2的空間頻率,其中SFk中的k是源圖像的索引。
(7)
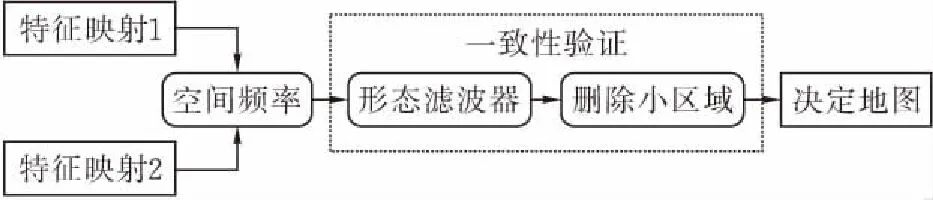
圖 1 詳細的融合策略
1.3 一致性驗證
在連接部分可能有一些小的線或毛刺,并且一些相鄰的區域可能被不適當的決定斷開。于是使用小型磁盤結構元素交替打開和關閉操作符來處理決策映射。這樣既可以消除小的線或毛刺,平滑聚焦區域的連接部分,又將相鄰區域合并為一個整體區域。當圓盤結構的半徑等于空間頻率核半徑時,可以很好地檢測到小直線或毛刺,并能正確地連接相鄰區域。本文采用了與Liu等人相同的小區域去除策略并將小于區域閾值的區域反轉。本文通常將閾值設置為0.01×H×W,其中H和W分別為源圖像的高度和寬度。
在聚焦區域和非聚焦區域之間存在一些不需要的工件。與Nejati,Samavi和Shirani[12]類似,利用有效的保邊濾波、制導濾波提高初始決策圖的質量,它可將制導圖像的結構信息傳遞到輸入圖像的濾波結果中。采用初始融合圖像作為指導圖像來指導初始決策圖的濾波。在這項工作中,實驗設置本地窗口半徑4和正規化參數ε為0.1,引導濾波算法。
1.4 融合
最后,利用所得到的決策圖D,和像素加權平均規則計算融合后的F。
F(x,y)=D(x,y)Img1(x,y)+(1-D(x,y))Img2(x,y)
(8)
輸入圖像表示為預先注冊的Imgk,其中k表示源圖像的索引。融合圖像的代表性可視化如圖2所示。

(a)近聚焦源圖像

(b)遠聚焦源圖像

(c)融合結果圖 2 融合結果的可視化
2 實驗
2.1 實驗設置
在實驗中,使用38對多焦點圖像作為測試集進行評估。由于無監督策略,首先使用MS-COCO訓練編解碼器網絡。該階段以82783幅圖像作為訓練集,每次迭代使用40504幅圖像驗證重建能力。所有的圖像都被調整為256×256,并轉換為灰度圖像。學習率設為1×10-4,每隔2個周期下降0.8倍。設置λ= 3與DenseFuse相同和優化目標函數對權重的網絡層。批次大小和年代分別為48和30。然后利用所獲得的參數對上述測試集進行SF融合。
對該算法的實現源自于公開可用的Pytorch框架。網絡訓練和測試是在一個使用4 NVIDIA 1080Ti GPU和44GB內存的系統上進行的。
2.2 目的圖像融合質量指標
該融合方法是與16個代表圖像融合方法相比,分別為拉普拉斯算子的金字塔(LP),低通的比率金字塔(RP),非抽樣輪廓波變換(NSCT),離散小波變換(DWT), dual-tree復小波變換(DTCWT),稀疏表示(SR),曲波變換(CVT)),引導過濾(GF),多尺度加權梯度(MWG),密集的篩選(DSIFT),空間頻率(SF)的FocusStack,圖像消光融合(IMF),DeepFuse、DenseFuse (add和L1-norm融合策略)和CNN-Fuse。
為了客觀評價不同方法的融合性能,采用了Qg、Qm和Qcb三個融合質量指標。對于上述三個指標,值越大表示融合性能越好。在本文中可以找到一個很好的全面的質量度量調查。為了進行公平的比較,使用了相關出版物中給出的這些度量的默認參數。
2.3 與其他融合方法進行比較
首先比較了基于視覺感知的不同融合方法的性能。本文主要以兩種方式提供了四個例子來說明不同方法之間的差異。
在圖3中,可視化了兩個融合的示例,例如“獅頭像”和“筆記本”圖像及其融合結果。在每張圖像中,聚焦和離焦部分邊界附近的區域被放大并顯示在左上角。在“獅頭像”的結果中,可以看到不同方法對獅頭像的邊界都進行處理。DWT顯示“鋸齒狀”形狀,CVT、DSIFT、SR、DenseFuse、CNN顯示不需要的工件。對于DWT和DenseFuse,左上角屋檐的亮度也有異常的增加。而MWG中相同的區域是失焦的,表明該方法不能很好地檢測出聚焦區域。在“筆記本”的結果中,一排掛鐘位于聚焦和離焦的邊緣,可以看到除了SESF-Fuse外,所有的方法都顯示出平滑和模糊的結果。

圖 3 不同“獅頭像”與“筆記本”的可視化融合結果
為了更好的對比,圖4和圖5分別顯示了從每幅融合圖像中減去第一個源圖像得到的差分圖像,并將每幅差分圖像的值歸一化為0到1的范圍。如果近聚焦區域被完全檢測到,差分圖像將不會顯示出該區域的任何信息。因此,CVT、DSIFT、DWT和DenseFuse-1e3-L1-Norm不能很好地檢測出聚焦區域。SR, MWG和CN在嬰兒邊緣的區域表現的很好,因為仍然可以看到近聚焦區域的輪廓。此外,SESF-Fuse在近聚焦區域的中心或邊緣區域都有良好的性能。在圖5中,近焦點區域是石頭。與上述觀察結果相同,CVT、DSIFT、DWT、NSCT、DenseFuse不能很好地檢測到聚焦區域。除了石頭的邊界區域,MWG和CNN的效果都很好。

圖 4 不同融合方法下“嬰兒”的融合結果

圖 5 不同融合方法下“海”的融合效果
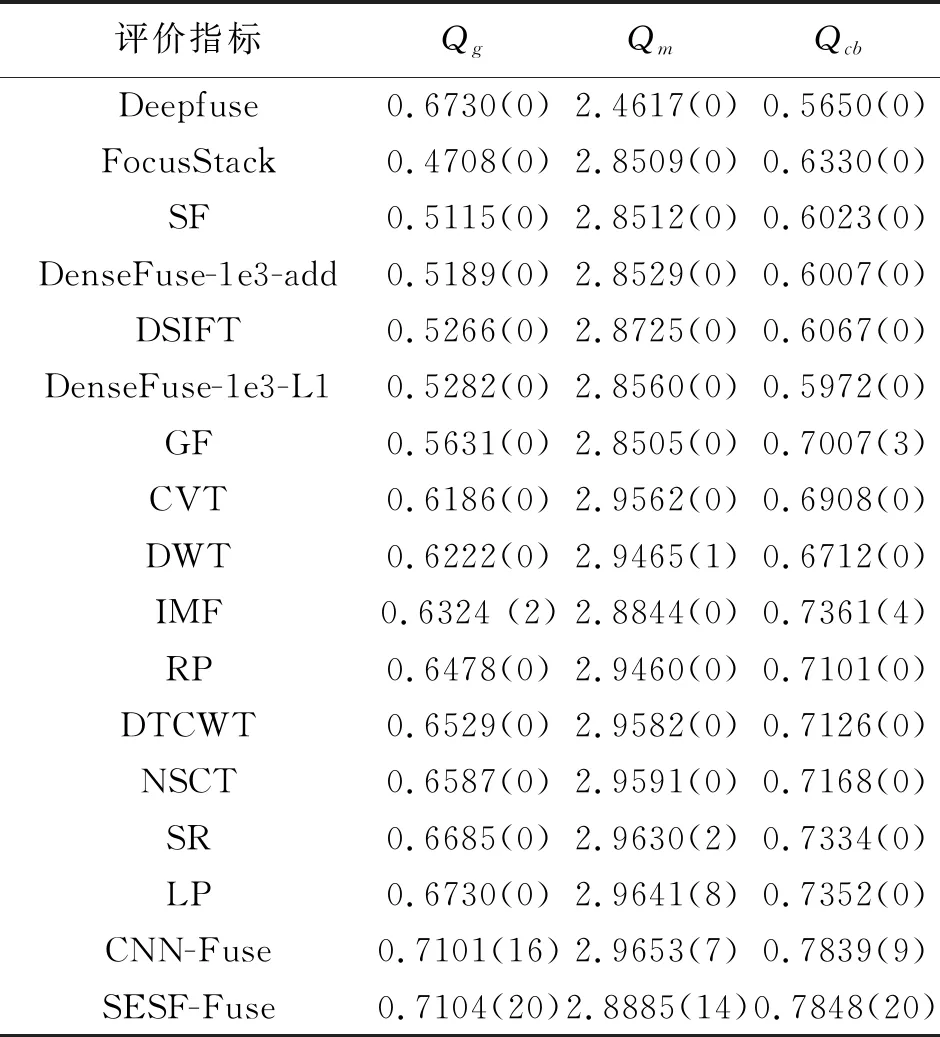
表1 與其他融合方法的比較
表1列出了使用上述三個指標的不同融合方法的目標性能。可以看到,基于CNN的方法和所提出的方法在Qg和Qcb融合指標的平均得分上明顯優于其他15種方法。對于Qg指標,CN- Fuse和SESF-Fuse的性能相當。然而,CNN-Fuse是一種監督方法,需要生成不同模糊程度的合成圖像來訓練一個兩類圖像分類網絡。相比之下,本方法只需要訓練一個不需要生成合成圖像數據的無監督模型。對于Qm度量,SESF-Fuse的平均核比LP小,但是,所提出的方法的第一個數達到了最大值,這意味著它比其他方法具有更強的魯棒性。
綜合考慮以上主觀視覺質量與客觀評價指標的比較,提出的基于SESF - Fuse的融合方法總體上優于其他方法,在多焦點圖像融合中表現出了最先進的性能。
3 結論
本文提出了一種無監督深度學習模型來解決多焦點圖像融合問題。首先訓練一個無監督的編解碼器網絡來獲取輸入圖像的深層特征,然后利用這些特征和空間頻率計算活躍度和決策圖進行圖像融合。實驗結果表明,與現有的融合方法相比,該方法在客觀和主觀評價方面均取得了較好的融合性能。證明了無監督學習與傳統圖像處理算法相結合的可行性。另外同樣的策略也適用于其他圖像融合任務,如多曝光融合、紅外融合和醫學圖像融合。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
人大建設(2020年4期)2020-09-21 03:39:12
現代出版(2020年3期)2020-06-20 07:10:34
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
