采用深度級聯卷積神經網絡的三維點云識別與分割
2020-05-12 08:35:12黨吉圣
光學精密工程 2020年5期
楊 軍,黨吉圣
(蘭州交通大學 電子與信息工程學院,甘肅 蘭州 730070)
1 引 言
隨著三維建模技術以及深度傳感器的廣泛應用,三維模型的數量呈現出爆炸式增長,三維模型的目標識別和語義分割作為三維模型分析處理的前提和基礎,已成為機器視覺領域的一個重要研究課題。三維目標識別和模型語義分割是通過比較各模型特征描述符之間的相似性和差異性來完成的,因此其關鍵問題是如何提取準確而魯棒的三維特征描述符。傳統方法利用手工設計形狀描述符來提取三維模型的特征,如幾何形狀描述符[1]和熱核簽名描述符[2]等,但是手工設計的特征描述符良莠不齊,嚴重依賴專家經驗,而且泛化能力較差。
近年來,深度學習[3-6]方法在機器視覺領域取得了一定的階段性成果,越來越多的學者開始嘗試采用深度學習方法來進行三維目標識別和模型語義分割,主要方法分為基于多視圖的方法、基于體素的方法和基于點云表示的方法。
基于多視圖的方法。由于三維點云的不規則性,直接從三維點云數據中提取特征有一定的困難。文獻[7]首先對三維模型進行多方位渲染得到二維投影視圖,然后把二維多視圖作為訓練數據輸入到經典的VGG(Visual Geometry Group)[8]中訓練并提取特征,最后通過視圖池化層把視圖特征聚合得到一維的全局特征描述符。該方法雖提高了三維模型識別的準確率,但存在視圖特征冗余和三維模型幾何信息丟失的問題。
基于體素的方法。文獻[9]提出把不規則的點云數據規則化為3D體素網格的形式,然后使用三維卷積神經網絡直接作用于3D體素數據提取特征描述符。文獻[10]將點云數據轉化為二值3D體素矩陣,通過附加正則化項的隨機梯度下降算法提取體素矩陣的特征,以此對模型類別進行預測。文獻[11]把不規則的點云數據體素化為規則的體素數據并進行旋轉擴充以增強網絡的泛化能力,并通過堆疊小卷積核構建深度卷積神經網絡挖掘模型內部隱含信息,提取體素矩陣深層特征。上述算法雖然有效保留了模型的幾何結構信息,但是體素化操作內存消耗嚴重,使捕獲高分辨率信息和細粒度特征變得困難。由于對于低分辨率的模型識別精度不高,文獻[12]提出了空間劃分方法,但仍然缺乏捕捉局部幾何特征的能力。
基于點云表示的方法。該方法可直接利用矩陣運算對點云模型進行仿射變換,避免了把點云轉化為其他規則數據形式的繁雜操作,已廣泛應用于計算機圖形學和機器視覺領域,如室內導航[13]、自動駕駛[14]、機器人[15]以及車載激光雷達[16]等。對于三維目標識別和語義分割,文獻[17]提出的PointNet網絡模型成為把深度學習框架直接作用于原始點云數據的先驅,但PointNet僅關注單個獨立點的特征,沒有考慮局部鄰域信息的重要性。文獻[18]提出了PointNet++網絡,通過劃分局部點云分層提取細粒度特征信息,對三維點云模型識別和語義分割展現出良好的性能。該網絡雖然有效捕獲了點云局部鄰域信息,但是沒有考慮局部鄰域內點與點之間的距離度量,缺乏捕捉上下文細粒度局部幾何信息的能力,導致識別效果不佳。為此,本文提出了基于深度級聯卷積神經網絡(Deep Cascade Convolutional Neural Network, DCCNN)的三維點云識別與分割方法,能夠有效捕捉點云模型的上下文深層細粒度局部幾何特征,提高了三維目標識別和模型語義分割的精度。主要創新點和貢獻有:(1)通過在DGCNN[19](Dynamic Graph Convolutional Neural Network)中引入殘差學習加深網絡深度,構建深度動態圖卷積神經網絡以充分挖掘點云的深層語義幾何特征。(2)構建深度級聯卷積神經網絡。將深度動態圖卷積神經網絡作為PointNet++[18]的子網絡遞歸地應用于輸入點集的嵌套分區以提取點云模型的深層細粒度幾何特征。(3)針對點云的采樣密度不均勻導致的網絡學習性能下降的問題,提出一種多尺度分組循環神經網絡(Multi Scale Grouping-Recurrent Neural Network, MSG-RNN)編碼策略。通過編碼采樣點的不同尺度的鄰域幾何特征,來提取采樣點的上下文細粒度幾何特征以增強網絡的魯棒性。
2 深度級聯卷積神經網絡
2.1 深度動態圖卷積神經網絡
為了捕捉三維點云的局部幾何特征,DGCNN[19]通過度量相鄰點之間的距離關系,提出了邊緣卷積層(Edge Convolution, EdgeConv)操作,一定程度上提高了網絡識別性能,但網絡深度較淺,無法捕捉更抽象的深層語義特征信息。受文獻[20]啟發,本文在DGCNN的基礎上構建深度動態圖卷積神經網絡(Deep Dynamic Graph Convolutional Neural Network, DDGCNN),以充分挖掘點云的深層語義幾何特征,網絡結構如圖1所示。DDGCNN由6個EdgeConv層、1個MLP層和1個最大池化層構成,EdgeConv層結構如圖1下方子圖所示。DDGCNN的輸入為特征維度為F的k+1個點構成的局部點云X={x1,x2,...,x(k+1)|x(k+1)∈g},采用7個卷積層把點云中的每個點的原始特征映射到高維特征空間,卷積層的各層參數如表1所示。本網絡把前層動態圖的低級特征連接到后層動態圖的高級特征中,避免了梯度消失問題的同時,加深了網絡深度,有助于提取更具有代表性的深層語義特征信息。DDGCNN與DGCNN[19]的不同之處在于:(1)通過殘差學習[21]將來自不同動態圖的不同層次的特征相互連接,避免了梯度消失問題。(2)增加了卷積層的數目,以充分挖掘深層語義幾何特征。(3)去除了空間轉換網絡,減少了網絡參數,降低了過擬合風險。
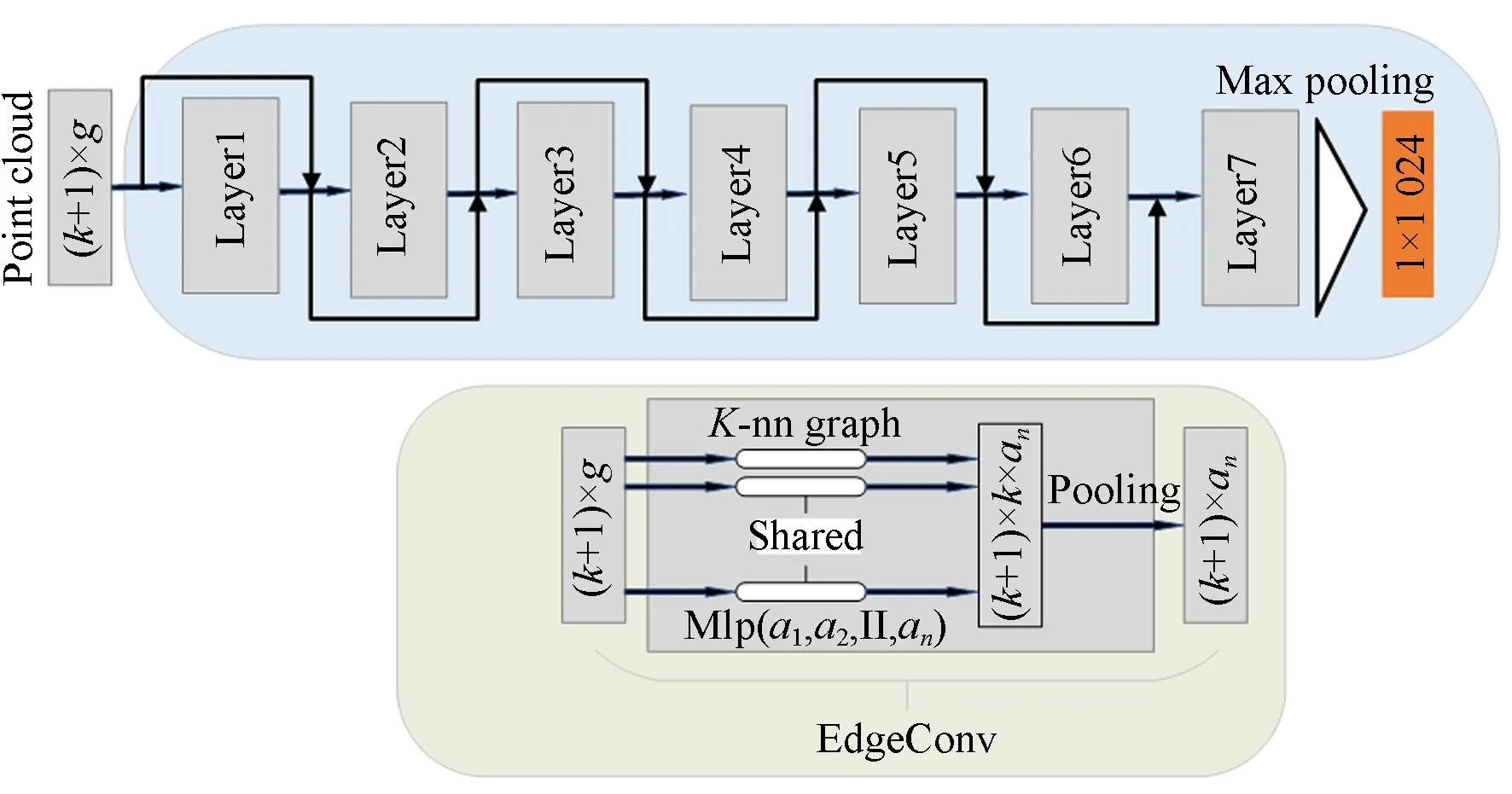
圖1 深度動態圖卷積神經網絡結構Fig.1 Network structure of deep dynamic graph convolutional neural network
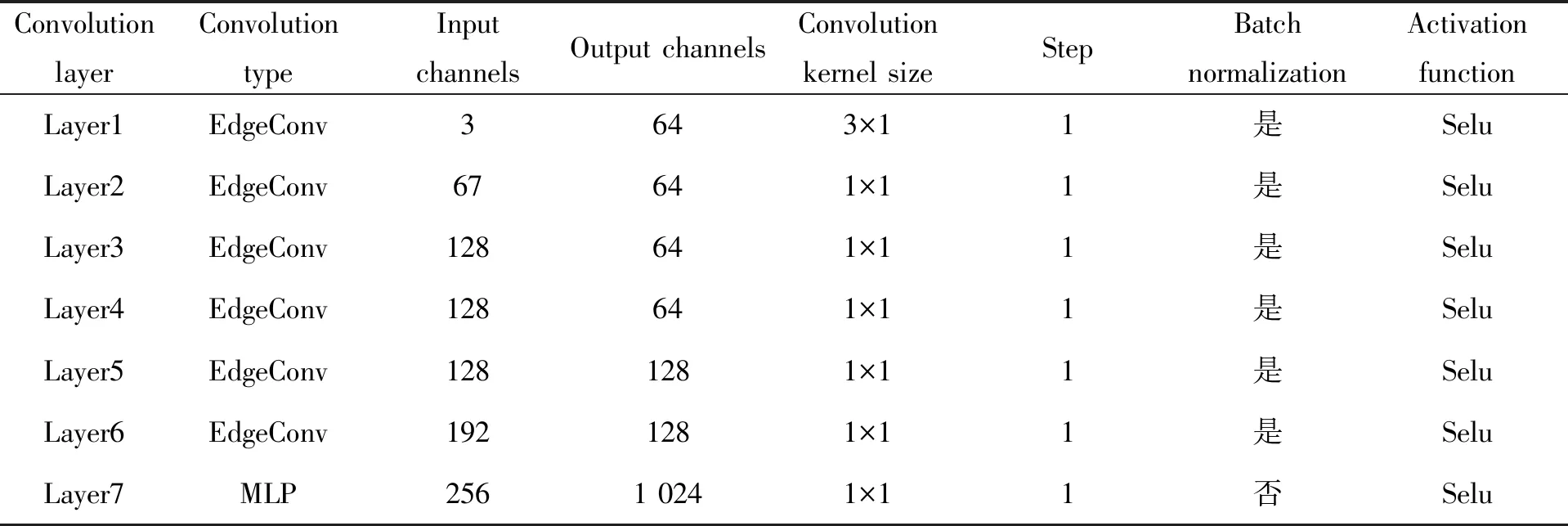
表1 卷積層各層參數Tab.1 Parameters of each convolution layer
2.2 深度級聯卷積神經網絡
在PointNet++[18]網絡中,集合抽象層中采用PointNet提取分組層的局部特征,然而,PointNet缺乏捕捉局部幾何結構信息的能力。本文將DDGCNN作為PointNet++的子網絡以構建深度級聯卷積神經網絡(Deep Cascade Convolutional Neural Network, DCCNN),該網絡包含了3個集合抽象層,網絡結構如圖2所示。網絡的輸入是大小為N×(C+d)的點云矩陣,其中N為點的數目,d為點的x,y,z3個坐標維度,C為點的特征維度。第1個集合抽象層首先對整個輸入點云采用迭代最遠點采樣算法采樣N1個點,對每個采樣點采用k最近鄰算法搜索距離采樣點最近的k個點構建每個采樣點的k鄰域分組,即得到大小為N1×(k+1)×(C+d)的點云矩陣,然后采用DDGCNN提取每個分組的深層語義幾何特征,得到N1個特征維度為C1的點構成的新點云,再次輸入第2個集合抽象層經過采樣分組得到大小為N2×(k+1)×(C1+d))的點云矩陣,采用DDGCNN提取特征后得到大小為N2×(C2+d)的點云矩陣。對于分類(Classification)任務,將該點云矩陣輸入第3個集合抽象層,以此遞歸抽象整個點云,得到能表示整個點云的一維特征向量C3。然后采用3個全連接層MLP(512,256,R)對全局特征向量進行降維轉換,最后采用Softmax分類器計算分類分數。對于分割(Segmentation)任務,為了獲取每個點的點級別的特征,在網絡中引入兩個插值層[18],通過上采樣將特征從形狀級別傳播到點級別,并采用MLP和Selu促進點特征的提取,最后網絡輸出每個點的預測標簽。
本文采用三維空間中點與點之間的歐氏距離來實現特征傳播,由點o與其k最近鄰點oi的歐幾里得距離插值而成。計算公式如式(1)所示:
(1)
其中:
u(oi)=1/(o-oi)2.
(2)
2.3 密度自適應層
現實生活中,在3D掃描儀生成點云數據時,由于透視效應、徑向密度變化等因素的干擾,采集到的點云的密度在不同區域往往是不均勻的,這種不均勻性增加了點集特征學習的難度。本文構建的DCCNN在采樣分組時是采用單尺度分組(Single Scale Grouping, SSG),在密度均勻的點云數據集上表現良好,而對于密度不均勻的采樣點集的特征學習效果并不理想。為此,本文構建多尺度分組循環神經網絡 (Multi Scale Grouping-Recurrent Neural Network, MSG-RNN) 編碼策略,在輸入點集密度不均勻時能夠自動結合每個采樣點的多個不同尺度的上下文鄰域特征以增強網絡的魯棒性。本文將采用MSG-RNN編碼策略的DCCNN命名為上下文深度級聯卷積神經網絡(Contextual-Deep Cascade Convolutional Neural Network, C-DCCNN)。
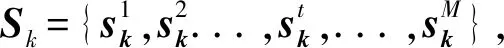
(3)
其中:f為一個非線性激活函數,實驗中采用LSTM單元。ht-1為編碼上一個鄰域的幾何特征時的隱藏層狀態。在RNN編碼采樣點的第t個鄰域的特征向量時,編碼器的輸出vt如公式(4)所示:
vt=Waht,
(4)

圖3 MSG-RNN策略Fig.3 MSG-RNN strategy
3 實驗結果與分析
3.1 實驗數據集
對于三維目標識別任務,選擇ModelNet40[22]和ModelNet10[22]兩個標準數據集進行實驗。ModelNet40共有40個類別的12 311個CAD模型,其中9 843個模型用于網絡訓練,2 468個模型用于網絡測試。ModelNet10共有10個類別的4 899個CAD模型,3 991個用于訓練,908個用于測試。對于三維模型語義分割任務,分別采用部件語義分割數據集ShapeNet Part[23]、室內場景語義分割數據集S3DIS[24]和戶外自動駕駛場景語義分割數據集vKITTI[27]進行實驗。ShapeNet Part數據集包含16個類別的16 881個CAD模型,共有50個部件語義標簽。S3DIS是一個室內大規模點云數據集,包含6個室內區域,共272個房間,其中所有點標注為木板(Board)、書柜(Bookcase)、椅子(Chair)、天花板(Ceiling)和橫梁(Beam)等13個語義類別。vKITTI是一個自動駕駛實際場景的戶外大規模點云數據集,分為6個不同的城市場景,其中所有點標注為自動駕駛場景中的汽車(Car)、樹木(Tree)、建筑物(Building)、馬路(Road)、交通燈(Traffic Light)和行人(Pole)等13個語義類別。
3.2 參數設置
實驗采用基于動量的隨機梯度下降 (Stochastic Gradient Descent, SGD) 優化算法,動量因子為0.9,初始學習率為0.001,學習率衰減指數為0.7,衰減速度為200 000。采用Adam算法來更新SGD的步長,網絡參數初始化采用Xavier優化器,批處理歸一化的衰減率初始值為0.5,最終值為0.99。激活函數采用Selu以緩解梯度消失,增加網絡非線性擬合能力。為了防止過擬合,在全連接層采用Dropout_Selu函數[26],除最后一層外,所有層都包含批處理規范化。
3.3 三維目標識別實驗結果分析
為了探究本文構建的DDGCNN和C-DCCNN的有效性,分別在ModelNet40數據集上對DGCNN(BASELINE)[19],DDGCNN和C-DCCNN三個網絡進行訓練并測試,實驗結果如表2所示。DGCNN(BASELINE)為去除空間轉換網絡的DGCNN。可以看出,在DGCNN(BASELINE)中引入殘差學習構建的DDGCNN的識別準確率比DGCNN(BASELINE)提高了0.2%,驗證了DDGCNN能夠有效捕獲深層語義幾何特征的能力。在PointNet++網絡中嵌入DDGCNN構建的C-DCCNN的識別準確率比DDGCNN高出0.5%,因為C-DCCNN采用分層特征學習策略能夠捕捉細粒度局部幾何特征,同時MSG-RNN在編碼多尺度特征向量時可以有效結合上下文信息。
表2 不同算法的三維模型識別準確率比較
Tab.2 Comparison of the accuracy of 3D models recognition among different algorithms

(%)
為了驗證本文算法的優越性,在ModelNet40和ModelNet10數據集上分別與其他先進方法進行了對比實驗,結果如表3所示。可以看出,本文算法的識別準確率明顯優于其他主流算法。原因在于本文算法通過構建DDGCNN能夠有效提取點云模型的深層語義幾何特征,并采用分層特征學習策略充分挖掘了三維模型的上下文細粒度深層幾何特征。此外,表4比較了本文算法與PointNet算法在ModelNet40數據集上各類別模型的識別準確率。對于測試集中的40類點云模型,其中有27類本文算法的識別準確率高于PointNet算法,有11類本文算法與PointNet算法的識別準確率相同,只有2類本文算法的識別準確率低于PointNet算法,充分證明了本文算法的優越性。從表中還可以看出,本文算法以及PointNet算法對花盆(Flower pot)這一類別的模型識別準確率最低,而且遠低于其他類模型,原因在于花盆(Flower pot)類部分模型只包含花盆(Flower pot),而部分模型同時包含了花盆(Flower pot)和植物(Plant),因此與植物(Plant)類造成了混淆,所以難以識別。圖4給出了在ModelNet40測試集上測試得到的幾種典型的誤分類模型實例。圖中從第1列到第4列分別為真實值、預測值、真實值與預測值的共同結構、標簽信息。可以看出,錯誤預測的模型和真實的模型之間均具有相同的局部結構。例如在圖4第1行中,真實的標簽是花盆(Flower pot),而本文算法預測為花瓶(Vase),預測錯誤的原因在于它們的共同局部結構瓶嘴。在圖4第2行中,真實的標簽是花盆(Flower pot),而本文算法預測為植物(Plant),造成預測錯誤的原因在于花盆(Flower pot)類部分模型里有植物(Plant)。所以,本文算法對于如何排除干擾的局部特征,只關注顯著結構特征,還需要進一步提高。
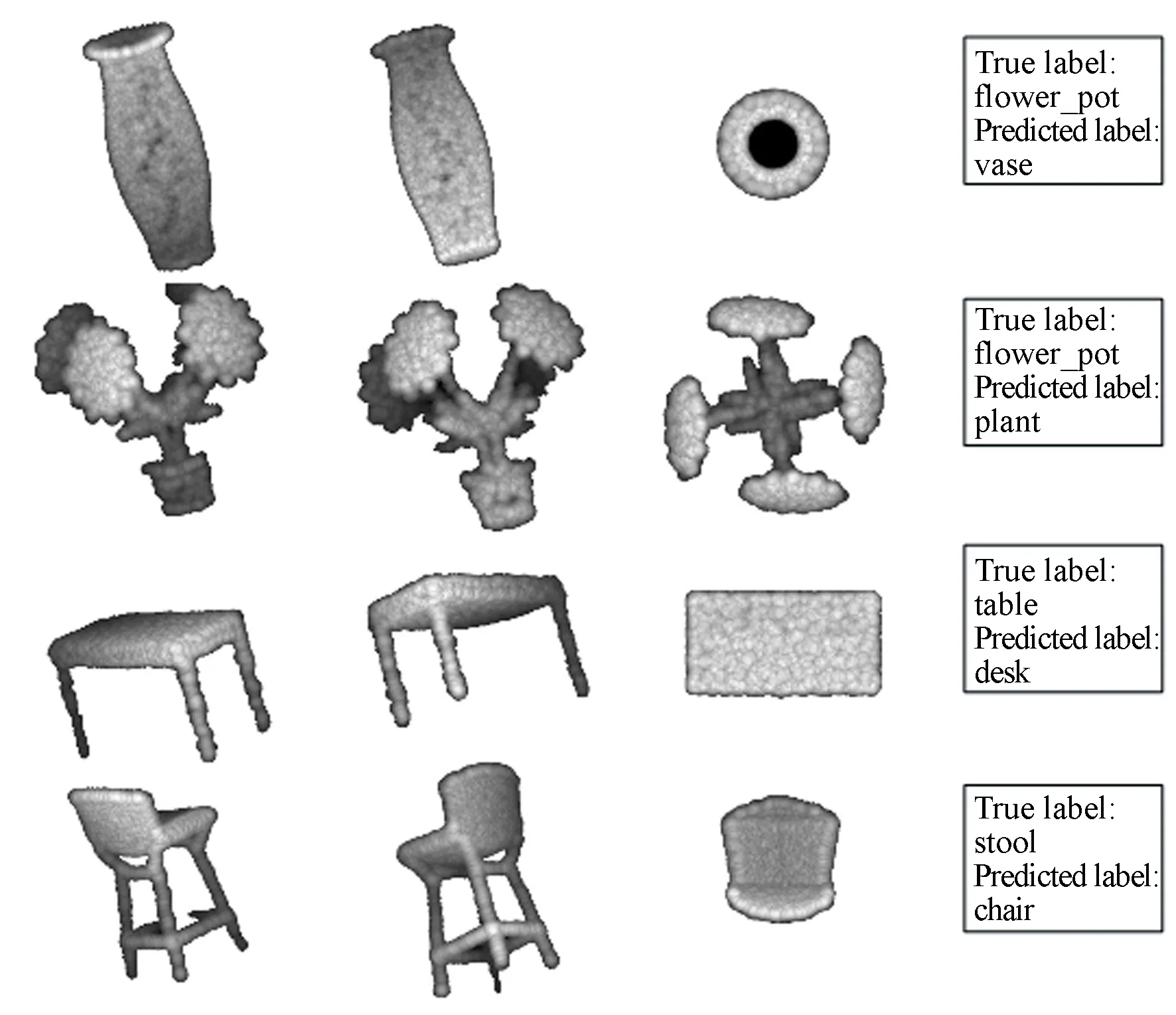
圖4 錯誤預測的點云模型實例Fig.4 Examples of mispredicted point cloud models
圖5和圖6分別給出了本文算法在ModelNet40數據集上模型識別準確率、訓練誤差與迭代次數的統計結果,其中,橫坐標均為訓練迭代次數,圖5縱坐標為識別準確率,圖6縱坐標為訓練誤差(彩圖見期刊電子版)。陰影線表示原始迭代數據,橙色曲線表示經過平滑后的迭代結果。由圖可見,在訓練初期,隨著迭代次數的增加,識別準確率逐漸提高,訓練誤差呈下降趨勢,因為網絡訓練過程中不斷優化參數,由卷積層學習到的特征對數據集中模型的描述準確度不斷提高。當迭代次數達到40 000次時,識別準確率和訓練誤差趨于穩定,網絡趨于收斂,說明網絡中的參數已達到最優。圖5和圖6充分驗證了本文網絡具有在訓練過程中能夠不斷提取三維模型的有效特征的能力。
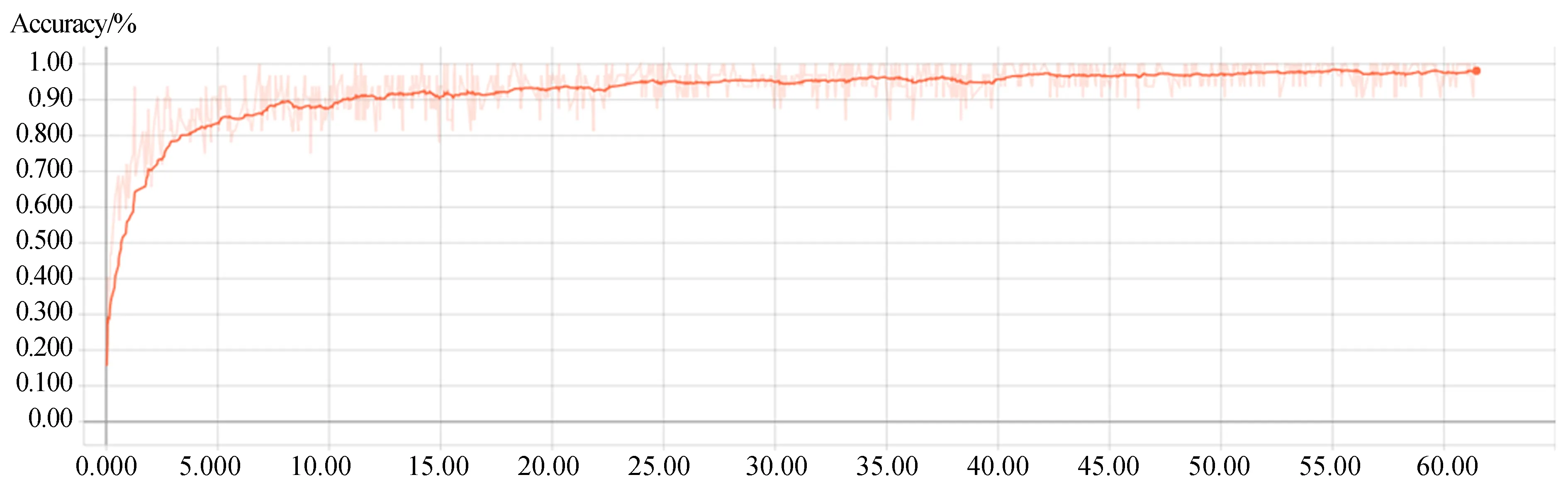
圖5 迭代次數與模型識別準確率的統計結果Fig.5 Statistical results of iteration times and model recognition accuracy
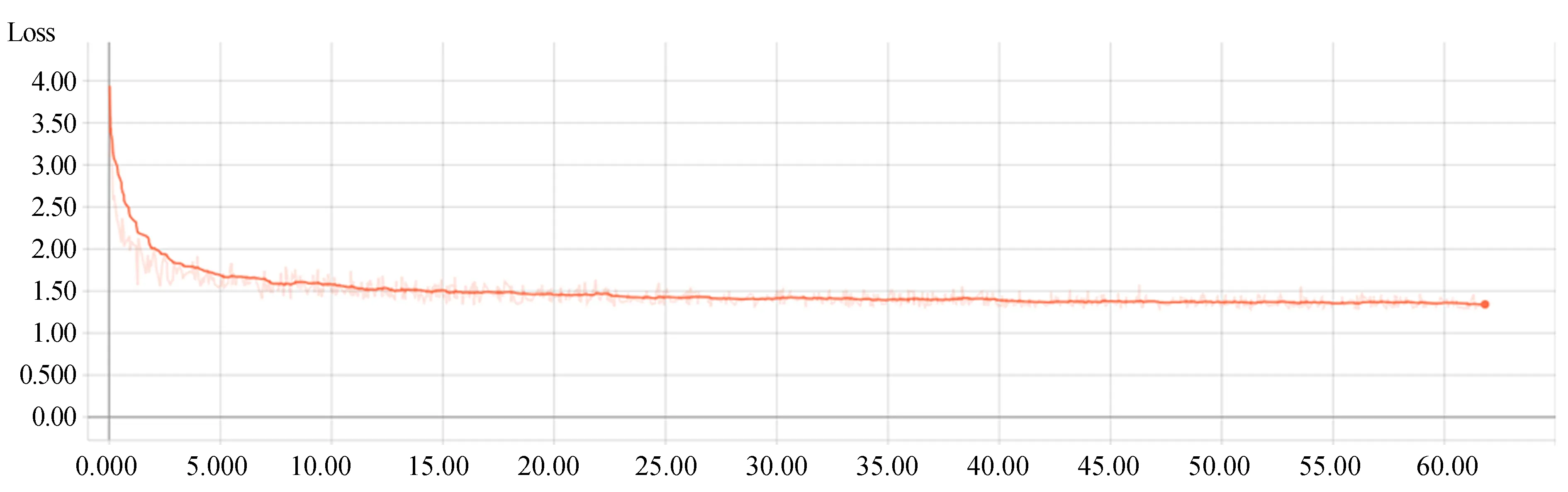
圖6 迭代次數與訓練誤差的統計結果Fig.6 Statistical results of iteration times and training error
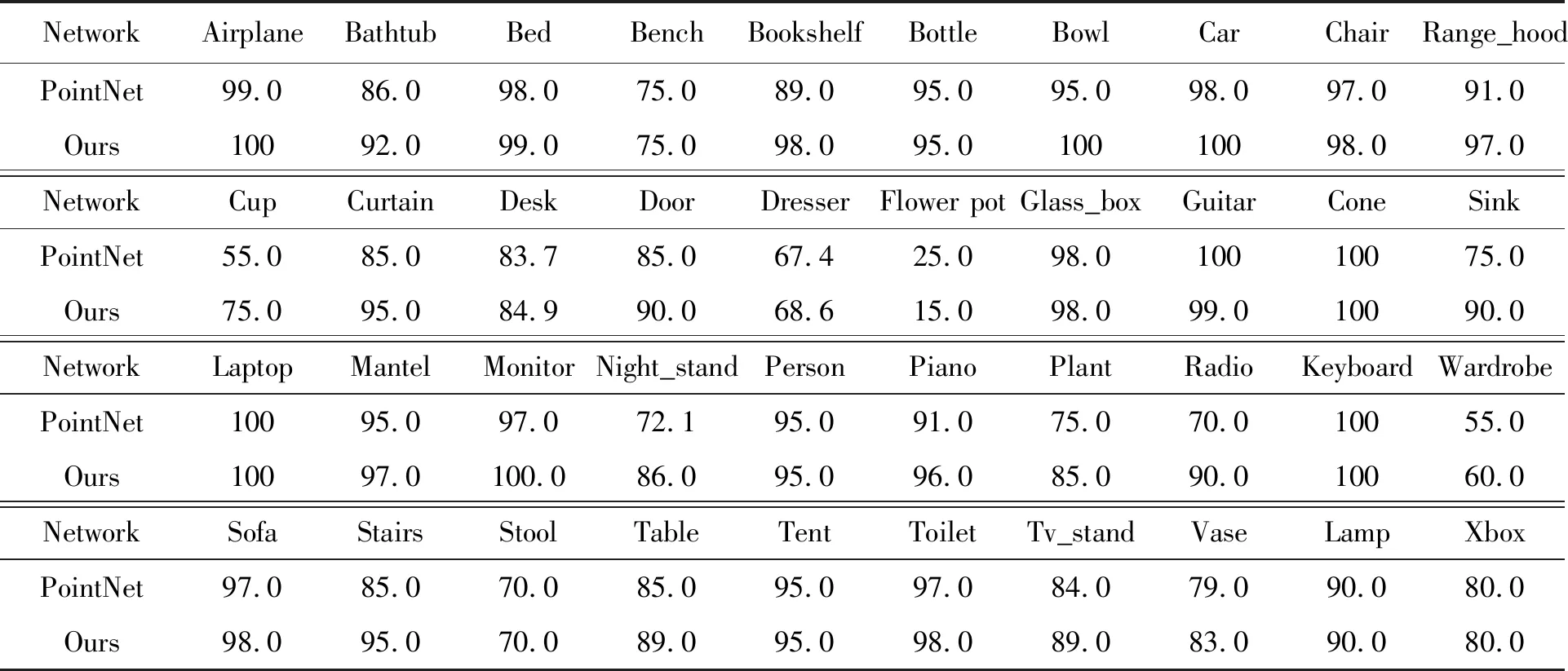
表4 ModelNet40數據集上每一類識別準確率的對比Tab.4 Comparison of per-class accuracy of object recognition on ModelNet40 dataset (%)
與此同時,為了繼續探究本算法對于稀疏點云的魯棒性,采用不同密度的數據集進行實驗。由于ModelNet40數據集中的三維模型都是密度均勻的,為了得到密度不均勻的數據集,對數據集中的三維點云模型做以下預處理:首先采用隨機輸入丟棄策略以隨機概率對輸入點進行隨機丟棄,即對輸入的點云模型,以p(p≤1)的比例選擇待丟棄點集,對于待丟棄點集中的每個點以概率q進行丟棄,為了避免空集,設置p=0.90,以此得到具有不同密度的點云模型,如圖7左側所示。分別將訓練好的網絡模型在密度不同的數據集進行測試,實驗結果如圖7右側所示。其中,DP表示訓練期間的輸入點隨機丟棄策略,SSG為每層集合抽象層中使用單一尺度分組的DCCNN網絡。可以看出,隨著點數的減少,SSG的識別準確率明顯下降,原因在于SSG采用DDGCNN提取點云的局部深層幾何特征,點數的減少破壞了局部幾何結構。PointNet在點數減少時網絡穩健性強于SSG,因為它專注于全局特征而不是精細局部細節,然而點數的減少也使其識別準確率明顯下降。PointNet+DP(在訓練期間采用輸入點隨機丟棄策略的PointNet)網絡魯棒性明顯優于PointNet,因為在訓練期間隨機輸入丟棄策略可以增強網絡學習稀疏點云特征的能力。SSG+DP(在訓練期間采用輸入點隨機丟棄策略的SSG)在測試期間點數從1 024減少到256時,識別準確率下降不到3%,原因在于隨機輸入丟棄策略增強了網絡的魯棒性,但隨著點數減少到128時識別準確率明顯下降。本文提出的密度自適應層MSG-RNN+DP(在訓練期間采用輸入點隨機丟棄策略和多尺度分組RNN編碼策略)對于點云密度變化非常穩健,從1 024個點減少到256個點時,MSG-RNN+DP的識別準確率下降不到1%。與其他方法相比,MSG-RNN+DP幾乎在所有點云采樣密度上都實現了最佳性能,展現了最好的魯棒性。
3.4 三維模型語義分割實驗結果分析
與三維目標識別相比,三維模型語義分割需要更精細地識別每個點的語義類別,所以是一項更具挑戰性的任務。為了進一步分析本文算法處理三維點云細粒度任務的能力,在ShapeNet Part數據集上進行了語義分割實驗,并與其他主流算法進行了對比,評價指標為文獻[17]中采用的交并比(Intersection-over-Union, IoU),實驗結果如表5和表6所示。
表5 不同算法在ShapeNet Part數據集上平均交并比的比較
Tab.5 Comparison of mIoU of different algorithms on ShapeNet Part dataset (%)

AlgorithmsAccuracyKd-Net[12]82.3PointNet[17]83.7PointNet++[18]85.1DGCNN [19]85.1Ours85.6
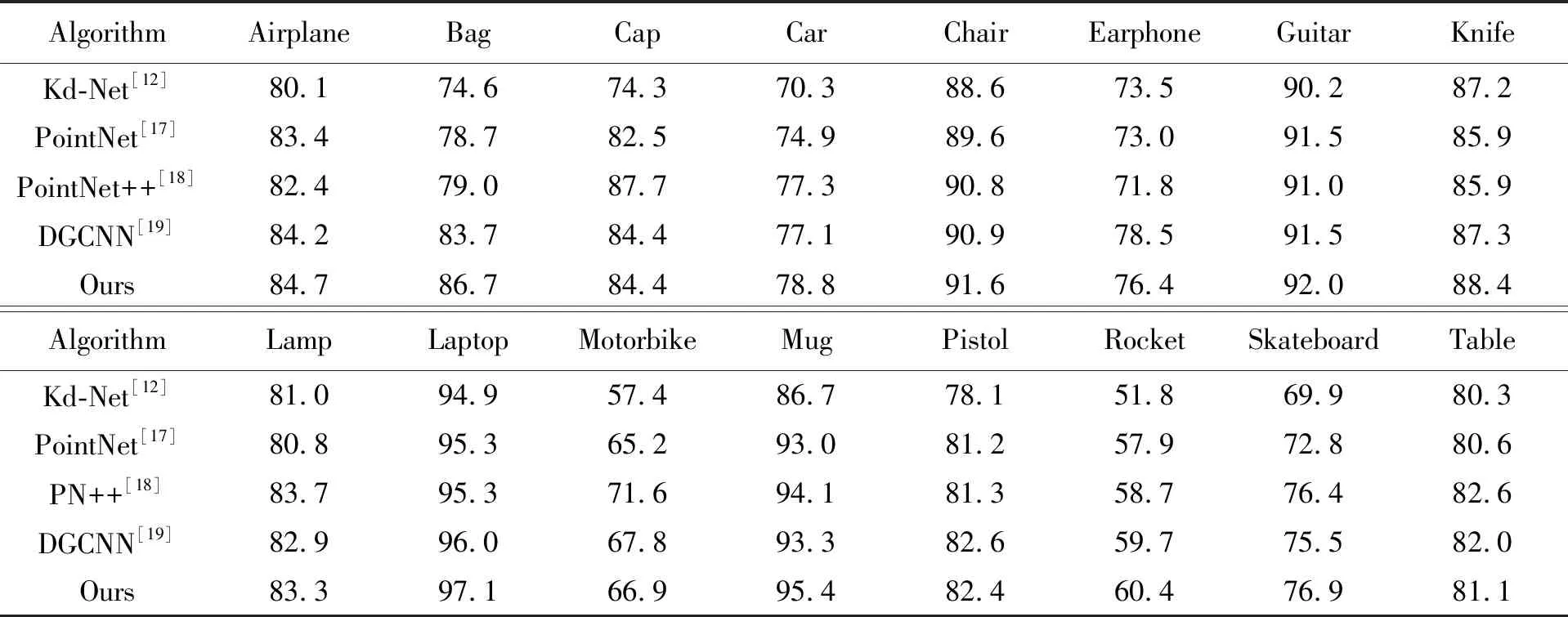
表6 不同算法在ShapeNet Part數據集上的各類別的交并比的比較Tab.6 Comparison of IoU of each category of different algorithms on ShapeNet Part dataset (%)
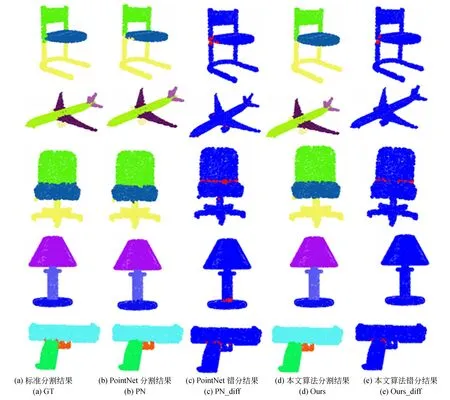
圖8 ShapeNet Part數據集上語義分割模型可視化Fig.8 Visualization of semantic segmentation models on ShapeNet Part dataset
可以看出,本文算法以85.6%的mIoU獲得了最好的語義分割性能。圖8所示為C-DCCNN和PointNet在ShapeNet Part數據集上的語義分割可視化效果圖,在第3列和第5列的錯分結果可視化中,藍色表示預測正確,紅色表示預測錯誤(彩圖見期刊電子版)。與PointNet相比,本算法的語義分割結果與標準分割結果高度一致,尤其細粒度細節處的分割準確率明顯提升,如臺燈(Lamp)柱身的底端、手槍(Pistol)的握柄處等,進一步驗證了本文算法具有能夠捕獲點云深層細粒度幾何特征的能力。
為了驗證本文算法同樣適用于大規模點云場景分析,在三維室內場景語義分割數據集S3DIS和戶外自動駕駛實際場景的語義分割數據集vKITTI上分別對C-DCCNN進行了訓練和測試,并與主流算法進行了對比,實驗結果如表7和表8所示。可以看出,本文算法的分割準確率均優于其他主流算法。除了定量分析外,圖9和圖10分別展示了定性的語義分割模型可視化效果圖。從圖9中可以看出,C-DCCNN能夠糾正PointNet預測錯誤的點,獲得更準確的分割結果,并且挖掘了PointNet所遺漏的細粒度細節信息。例如,椅子(Chair)的腿在很大程度上得到了保留,門(Door)的預測也比PointNet更準確。事實上,門(Door)和墻(Wall)在幾何形狀上極其相似,但是本文算法有效結合了門的上下文位置信息(門框的特征),可以更好地預測門(Door)這一類別,進一步證明了MSG-RNN編碼策略能夠有效結合上下文幾何信息的能力。從圖10中可以看出,本文算法整體分割錯誤率相比于PointNet有所減少,尤其對于馬路(Road)和地帶(Terrain)這兩類語義的分割準確性提高最為明顯。原因在于地帶(Terrain)和馬路(Road)在幾何形狀上極其相似,區別在于地帶(Terrain)中有樹木(Tree),馬路(Road)中沒有樹木(Tree),單純提取馬路(Road)和地帶(Terrain)的幾何特征很難區分這兩類語義,需結合其上下文信息。由此進一步驗證了本文算法具有提取上下文細粒度局部幾何特征的能力。然而,本文算法對于同時存在上下文信息車(Car)的地帶(Terrain)和馬路(Road)識別混淆,可見本文算法對鄰域上下文信息缺乏自適應篩選能力。
表7 S3DIS數據集上不同算法的分割準確率對比
Tab.7 Comparison of segmentation accuracy of different algorithms on S3DIS dataset (%)
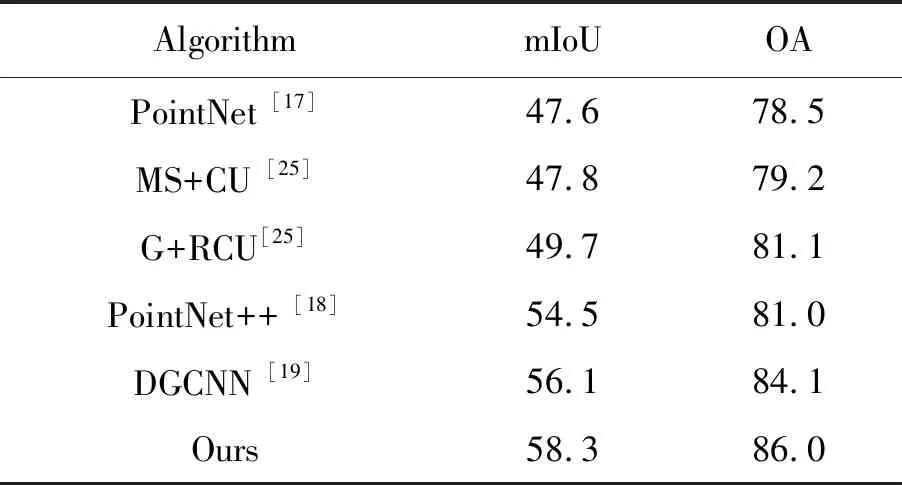
AlgorithmmIoUOAPointNet [17]47.678.5MS+CU [25]47.879.2G+RCU [25]49.781.1PointNet++ [18]54.581.0DGCNN [19]56.184.1Ours58.386.0
表8 vKITTI數據集上不同算法的分割準確率對比
Tab.8 Comparison of segmentation accuracy of different algorithms on vKITTI dataset (%)
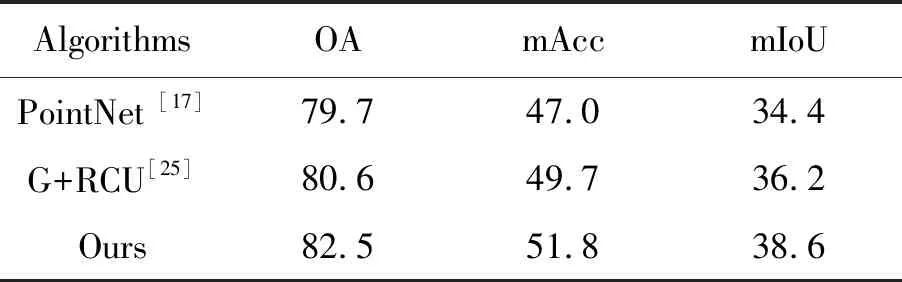
AlgorithmsOAmAccmIoUPointNet [17]79.747.034.4G+RCU [25]80.649.736.2Ours82.551.838.6


圖9 S3DIS數據集上語義分割模型可視化Fig.9 Visualization of semantic segmentation models on S3DIS dataset
4 結 論
本文提出了一種基于深度級聯卷積神經網絡的三維目標識別和模型語義分割方法。通過構建深度動態圖卷積神經網絡作為深度級聯卷積神經網絡的子網絡,對輸入點集進行分層學習以捕捉點云的深層隱含細粒度幾何特征。為了提高在非均勻采樣點云上的特征學習能力,構建了MSG-RNN密度自適應層編碼策略,可以根據局部點云密度利用RNN編碼器自適應地聚合不同尺度的上下文幾何信息,增強了網絡的魯棒性。實驗結果表明,本文算法在三維目標識別數據集ModelNet40和ModelNet10上的識別準確率分別為91.9%,94.3%,在模型語義分割數據集ShapeNet Part,S3DIS,vKITTI上的mIoU分別為85.6%,58.3%,38.6%。在三維點云目標識別準確率、語義分割準確率和網絡魯棒性上都優于其他主流算法。實驗中發現,本文算法對如何忽略次要干擾局部特征,只關注顯著局部特征還存在改進的空間,這也是今后要繼續研究的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
