多模態(tài)特征融合與多任務學習的特種視頻分類
2020-05-12 08:35:10吳曉雨顧超男王生進
光學精密工程 2020年5期
吳曉雨,顧超男,王生進
(1.中國傳媒大學 信息與通信工程學院,北京 100024; 2.清華大學 電子工程系,北京 100084)
1 引 言
隨著移動智能手機和互聯(lián)網(wǎng)技術的迅速發(fā)展,網(wǎng)絡上的視頻數(shù)據(jù)量也急劇增加,網(wǎng)絡內(nèi)容安全日漸成為一個重要問題[1]。單靠人工已無法實現(xiàn)對如此龐大的視頻數(shù)據(jù)量進行審查,這使得色情、暴力等不良視頻可能會直接暴露于用戶面前,給用戶帶來視覺和心靈上的負面沖擊。本文中的特種視頻是指暴力視頻。如何有效識別暴力視頻以減少暴力內(nèi)容等有害信息傳播是一個亟需解決的問題。因此,本文以暴力視頻檢測為研究任務,深入探索了其中的關鍵技術和解決方案,旨在提升暴力視頻的智能化檢測性能,以凈化網(wǎng)絡環(huán)境。
“暴力”是一個具有高級語義的抽象概念,包括身體和心理暴力,本文只關注身體暴力視頻識別,沿用文獻[2]對暴力視頻的定義如下:“不允許8歲以下的小孩觀看的包含身體暴力的視頻”。互聯(lián)網(wǎng)的暴力場景視頻畫面上常伴有流血、打斗,聲音上常伴有驚叫、爆炸和槍聲等信息,故目前的暴力視頻識別方法往往利用音視頻信息。基于音視頻信息融合的暴力視頻識別技術主要涉及暴力音視頻各模態(tài)特征提取和模態(tài)間信息有效融合的兩方面問題[3-4]。
在暴力音視頻特征提取方面:卷積神經(jīng)網(wǎng)絡 (Convolutional Neural Network ,CNN)常被用來提取靜態(tài)的圖像特征,如文獻[5]采用RGB幀作為輸入,利用ImagNet數(shù)據(jù)集預訓練的CNN初始化暴力視頻分類的前5層網(wǎng)絡,并對最后3個全連接層重新訓練得到深度特征,實驗結果證明與傳統(tǒng)特征的分類效果相比,深度特征能幫助提升暴力視頻系統(tǒng)識別性能。文獻[6]采用深度學習特征和手工設計特征相結合的方法進一步提高暴力視頻識別能力,并在分析比較了靜態(tài)特征、運動特征、基于梅爾頻率的倒譜系數(shù)MFCC(Mel-Frequency Cepstral Coefficients)音頻特征和基于深度學習的高級語義特征后發(fā)現(xiàn),運動特征對暴力視頻識別有較重要的影響。文獻[7]借鑒了雙流CNN網(wǎng)絡結構[8],以靜態(tài)視頻幀和光流圖作為兩路CNN的輸入提取暴力視頻的特征,并將CNN網(wǎng)絡輸出作為長短時記憶(Long Short-Term Memory,LSTM) 網(wǎng)絡[9]的輸入以分析長時間視頻序列,同時提取并編碼了多種手工設計特征,而后將手工設計的特征和深度學習得到的多種特征進行拼接,并訓練了幾個不同的SVM分類器,最后融合不同分類器的分數(shù)得到最終的決策結果。文獻[10]將相鄰視頻幀的差分圖作為神經(jīng)網(wǎng)絡的輸入,利用了卷積LSTM網(wǎng)絡提取暴力視頻的幀間變化信息和場景語義信息。目前暴力視頻特征提取方法多是粗暴地將經(jīng)典特征描述算子和深度神經(jīng)網(wǎng)絡自動提取特征描述子進行簡單地組合拼接,這無疑會制約暴力視頻檢測算法的計算效率,我們更應該從暴力場景的特點出發(fā)(如暴力場景有的以血腥場面為主,有的以打架場面為主,有的以爆炸著火場面為主),采用有效的音視頻特征提取方法來獲得暴力場景的語義表征。
如何對提出的靜態(tài)幀、運動和音頻等多種特征進行有效地信息融合是暴力視頻識別研究中的另一重要內(nèi)容。在暴力音視頻模態(tài)間信息融合方面:目前多路信息融合的技術方法主要有基于決策分數(shù)的后融合方法和基于特征層的前融合方法[11]。決策層的融合指將各模態(tài)的決策結果(如各模態(tài)的分類器給出的分數(shù)) 進行融合[12]。主要的融合方法有基于規(guī)則的方法,如線性權重融合、平均融合、投票決策等。基于分類器學習的融合方法即將各模態(tài)分數(shù)作為特征通過訓練學習得到一個判別函數(shù),如基于 SVM(Support Vector Machine)、貝葉斯決策、logistic 回歸和神經(jīng)網(wǎng)絡等方法。特征層的前融合是指將提取的各視角特征按照某種方法進行的融合,常見的特征融合方法有:(1)直接將特征拼接為一個長的特征向量,一般隨后采用特征編碼方法,如詞包模型(Bag of Word,BOW)、 Fisher向量編碼 (Fisher Vector,F(xiàn)V)方法或者 主成分分析(Principle Component Analysis,PCA)等方法,進行特征降維,最后利用 SVM 或者Softmax分類器得到分類的結果,這種特征融合方法雖實現(xiàn)簡單,但是多模態(tài)數(shù)據(jù)間存在“語義鴻溝”的問題,故將不同含義異質的多種特征直接進行拼接后效果不穩(wěn)定。(2)將多模態(tài)特征經(jīng)過某些變換投影以得到潛在的、 共享的特征子空間[13-14],該方法在融合過程中往往會考慮模態(tài)間的關聯(lián)性,故更為科學。目前已有的暴力音視頻信息融合常采用決策層的融合技術,這主要是因為決策層的信息融合相當于對語義相近的、 處在同一個特征空間的特征(即決策分數(shù))進行融合,融合風險較小且實現(xiàn)也相對容易。但是,決策層融合方法對暴力視頻識別性能的改善作用也是比較有限的,原因在于在進行決策層融合時可利用的只是各模態(tài)決策后的分數(shù),融合信息很有限。較決策層融合相比,特征層的融合方法優(yōu)勢在于同時“看到”了更多的模態(tài)信息, 能更好捕捉各模態(tài)的聯(lián)系,好的特征融合方法能顯著提高視頻分類性能。但該方法難點也在于各特征含義不同、建立具有統(tǒng)一語義表示的特征子空間較難。總的來說,無論是決策層融合還是特征層融合方法,在融合音視頻信息時均沒有考慮音視頻特征語義一致性的問題。多模態(tài)特征之間有時具有語義一致性(以暴力視頻為例,語義一致性可以理解為暴力音視頻特征同時具有暴力場面描述的特點,或同時不具有暴力場景描述的特點) 和信息互補,但有時多模態(tài)間信息是互相干擾的(如著名的“麥格克效應”-McGurk effect),融合它們甚至會有相反的效果。因此要顯式地思考什么時候進行哪些信息的融合,不加任何度量直接地進行模態(tài)間的特征融合有時不僅無法實現(xiàn)模態(tài)間信息互補, 而且還會導致算法性能的下降[15]。
本文針對現(xiàn)有暴力音視頻特征對暴力場景語義描述能力不足、融合音視頻特征時未考慮語義一致性等問題,提出了一種基于音視頻特征多任務學習的端到端暴力視頻識別方法:提取具有時空相關性的音視頻特征方法, 構建具有語義保持的共享的特征子空間,提出了基于暴力音視頻特征語義一致性度量和視頻分類相結合多任務學習的暴力視頻分類模型,實現(xiàn)了暴力音視頻信息的有效融合與互補。在兩個暴力視頻公開數(shù)據(jù)集上的實驗結果表明本文提出方法的有效性。同時該方法也將為類似任務的音視頻特征融合提供了一定的理論參考。
2 基于語義一致性的暴力視頻識別方法
本文整體技術路線如圖1所示:首先,以2~4 s短視頻數(shù)據(jù)為處理對象,以分析暴力場景視頻的特點為出發(fā)點,基于P3D+LSTM網(wǎng)絡提取適合暴力場景描述的、具有時空相關特性的視覺語義特征,基于VGGish網(wǎng)絡提取暴力音頻的語義特征;而后在多特征融合過程中,以暴力視頻分類標簽和音視頻語義一致性信息為監(jiān)督信號,自動學習并求取具有語義保持的特征映射的變換矩陣,實現(xiàn)基于暴力音視頻特征語義一致性度量和視頻分類相結合多任務學習的暴力視頻分類。
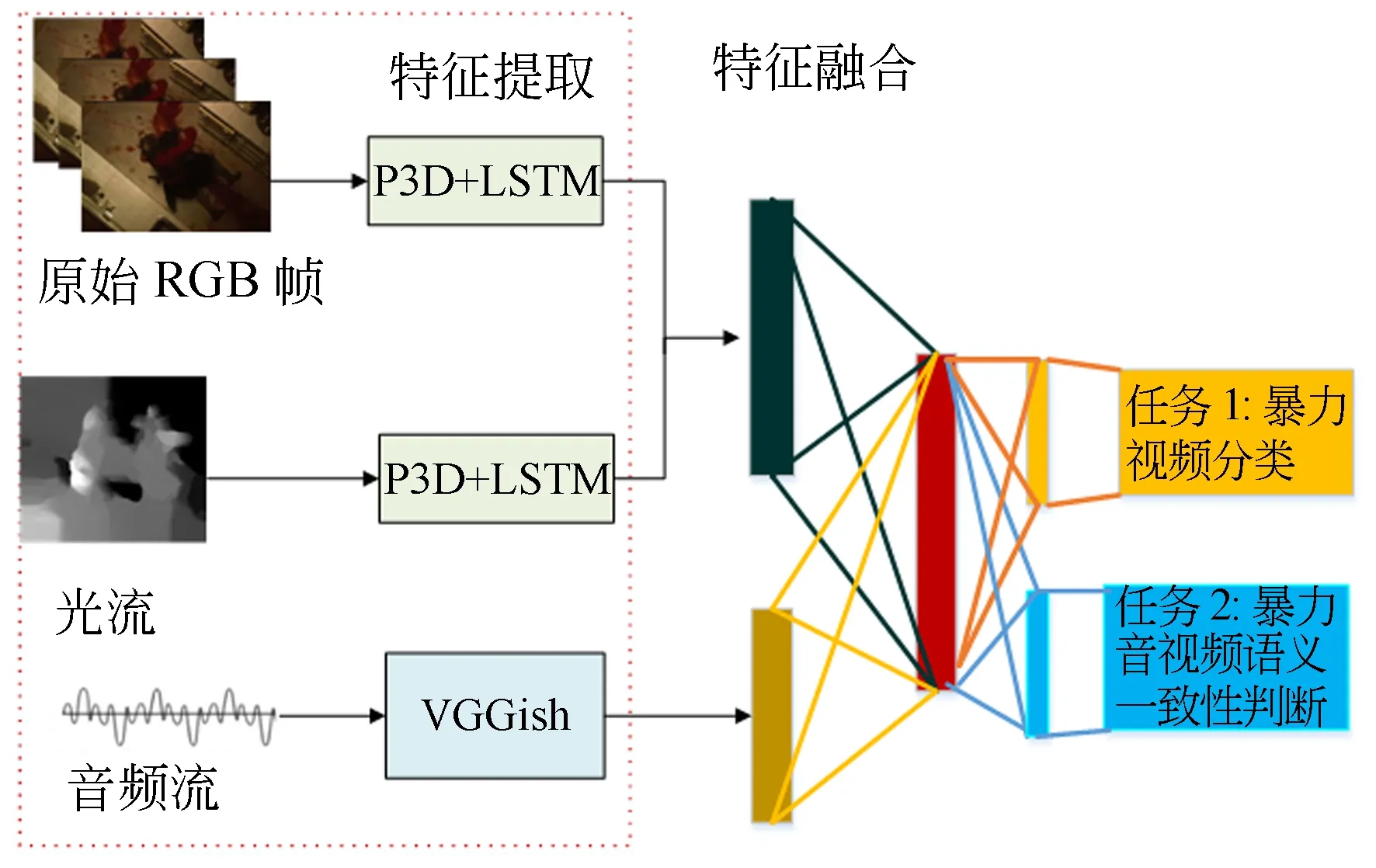
圖1 暴力視頻分類算法框架圖Fig.1 Framework of violent video classification
2.1 暴力音視頻特征提取
暴力類視頻從視覺信息上來講,畫面通常包括物體(槍支、刀、劍等)、場景(血液、死亡等場景)、動作或行為(如打斗、追逐、射擊等)。在音頻信息方面,暴力視頻中經(jīng)常會伴有尖叫、爆炸、槍聲等,故本文利用深度學習算法提取表觀特性和運動信息隨時空變化的視頻語義特征及音頻語義特征,來表征血腥、打架和爆炸等暴力場景。
2.1.1 基于P3D+LSTM的暴力視頻視覺語義特征提取
對于暴力視頻,利用視頻當前幀的前后多幀上下文的信息可以減少基于單幀信息引起的誤判,有助于提高血腥場景檢測的準確度。同時為充分考慮暴力視頻在表觀和運動上的特點,本文參考雙流的框架,分別以原始視頻RGB幀和光流作為輸入,以偽3D(Pseudo-3D,P3D)[16]和長短時記憶LSTM 網(wǎng)絡[9]為網(wǎng)絡結構,提取暴力視頻中表觀特性和運動信息隨時空變化的視覺語義特征。
(1)基于P3D+LSTM網(wǎng)絡提取表觀信息隨時空變化的視頻語義特征
對于血腥的暴力視頻,提取基于原始RGB幀的表觀語義特征是很有必要的。P3D網(wǎng)絡使用了“偽”3D卷積的概念降低網(wǎng)絡參數(shù),即利用拆分的思想把原本3×3×3的卷積拆分成了3×1×1卷積與1×3×3卷積的結合,以16幀的連續(xù)圖像作為網(wǎng)絡輸入單元,提取短時的視頻時空連續(xù)性特征,顯然P3D對于長視頻的處理還存在一些不足,實際中往往將P3D最后一個平均池化層特征作為LSTM的輸入以提取長序列視頻的時空特征。因此,本文以視頻暴力/非暴力標簽信息作為監(jiān)督信號,以暴力視頻原始幀RGB信息作為輸入,基于P3D+LSTM網(wǎng)絡學習并提取表觀信息隨時空變化的512維視頻語義特征fVa。
(2)基于P3D+LSTM網(wǎng)絡提取運動信息隨時空變化的視頻語義特征
對于打斗暴力場景,運動特征對此具有較強的描述能力。目前運動特征的提取主要借助光流Optical flow、改進稠密軌跡iDT(improved Dense Trajectory)算子和幀間差分等方法, iDT計算復雜度較高,幀間差分法雖然計算簡單但是當目標運動較快時無法獲取完整的運動目標。因此,本文選用光流法來表征視頻的運動信息,以光流圖像作為網(wǎng)絡的輸入,基于P3D+LSTM網(wǎng)絡學習并提取運動信息隨時空變化的512維視頻語義特征fVm。
在視覺通道模型訓練階段,表觀流和光流這兩路3D網(wǎng)絡模型的初始化參數(shù)來自于Kinetics 400數(shù)據(jù)集[17]的預訓練模型。參數(shù)的設置如下:P3D訓練模型初始學習率設為0.000 01,且以gamma=0.1的幅度每5 000次對學習率進行一次調整;訓練時batch_size設置為4;最大迭代次數(shù)max_iter=30 000;梯度影響因子momentum設置為0.9;當P3D網(wǎng)絡提取的最后一個平均池化層特征被發(fā)送到LSTM時,batch_size被設置為64,最大epoch設置為55,初始學習率設置為0.000 1。
2.1.2 基于VGGish網(wǎng)絡的暴力視頻音頻語義特征提取
暴力視頻在音頻信息中經(jīng)常會伴有尖叫、爆炸、槍聲等,因此暴力視頻智能化識別的研究不能僅考慮視覺方面的信息,音頻信息同樣也對暴力視頻的識別提供指示性幫助。這里假定處理的視頻存在音頻流信息。本文首先提取音頻log-Mels梅爾譜圖,而后將梅爾譜圖送入VGGish網(wǎng)絡[18],通過學習尖叫、爆炸、槍聲的暴力音頻數(shù)據(jù)使得網(wǎng)絡學習到暴力音頻的音效特征,獲得128維暴力音頻語義特征fA,以此輔助暴力視頻的檢測。這里不選擇P3D網(wǎng)絡進行暴力音頻語義特征提取的原因在于,輸入圖像log-mel譜圖雖然是一幅圖,但是和自然圖像空間位置信息的含義截然不同,因此并不適合提取音頻語義特征。
訓練采用的音頻數(shù)據(jù)均是從原始暴力視頻中利用ffmpeg工具分離出來的,而后將音頻數(shù)據(jù)經(jīng)過如下預處理:所有音頻數(shù)據(jù)被重新采樣到16KHz的單聲道形式,對音頻的分幀采用了窗口大小為25 ms、窗口跳距為10 ms以及周期Hann窗口的短時傅里葉變換的幅度,而后映射得到穩(wěn)定的log-Mels譜。然后這些特征被以0.96 s的時長組幀,且不會出現(xiàn)幀的重疊,其中每一幀都包含64個Mel頻帶,時長為10 ms,即總共96 frame。將提取96×64×1的音頻數(shù)據(jù)送入VGGish網(wǎng)絡提取暴力音頻語義特征。
在音頻特征提取模型訓練過程中,網(wǎng)絡是基于VGGish網(wǎng)絡在Audioset數(shù)據(jù)集上預訓練模型進行微調訓練的。此外,在訓練過程中對訓練音頻數(shù)據(jù)進行擴充處理,每段音頻再按照1 s的時間間隔截斷擴充成10個,batch_size設置為16,epoch設置為60,初始學習率0.000 01。
2.2 基于語義一致性的多特征融合與暴力視頻識別
合理的特征融合方法相比決策層融合往往可以獲得更高的性能提升。特征層融合常將多種特征投影變換到一個共享的特征子空間上,但是如何求取變換矩陣以構建合理的特征子空間是該方法的核心。在對多種特征進行融合時,只有將具有相同語義的特征進行融合處理才能充分利用各類特征之間的信息互補性。但現(xiàn)有的研究方法只是單純地基于視頻標簽來對特征融合層進行訓練[19],沒有考慮到各種特征之間可能存在語義不一致的情況,這導致在多特征融合過程中可能會出現(xiàn)特征信息相互“敵對”的問題,使得該類方法在本就數(shù)量有限的暴力視頻訓練數(shù)據(jù)集上會更容易出現(xiàn)過擬合現(xiàn)象,影響了暴力視頻分類系統(tǒng)的泛化能力。

圖2 基于多任務學習的暴力音視頻特征融合Fig.2 Violent audio-visual features fusion based on multitask learning
因此,本文提出了結合暴力音視頻特征語義一致性度量的多模態(tài)融合方法,技術路線圖如圖2所示,實現(xiàn)了基于音視頻特征多任務學習的暴力視頻分類方法。在視覺通道上,我們通過構建并訓練基于全連接的特征融合層的網(wǎng)絡結構,將隨時空變化的512維的表觀語義特征fVa和512維運動語義特征fVm特征投影到512維的視覺特征融合空間,使得視覺特征從1 024維降為512維,這樣不僅實現(xiàn)了表觀和運動特征的融合,更為重要的是減少了視覺特征的維度,降低后續(xù)建立音視頻共享特征子空間的技術難度。在音視頻特征融合方面,構建2個全連接特征融合層,相當于分別求取視覺特征變換矩陣WV和音頻特征變換矩陣WA,將視覺通道512維特征φV和音頻通道128維特征φA,經(jīng)過公式(1)各自矩陣變換得到音視頻共享特征子空間,從而得到的融合后512維音視頻特征φ′=(φV′,φA′)。其中融合后的特征維度通過反復實驗選取,公式(1)中參數(shù)(WV,bV,WA,bA)由模型訓練得到。
φV′=WVφV+bV
φA′=WAφA+bA.
(1)
本文提出的多模態(tài)特征融合方法創(chuàng)新在于:在學習特征融合層參數(shù)的模型訓練階段,不僅考慮了暴力視頻的分類任務,還引入了音視頻語義一致性任務進行協(xié)調反饋,兩個任務并行學習訓練且共享已學到的特征參數(shù)。因此暴力視頻分類網(wǎng)絡的損失函數(shù)由兩部分組成:一是暴力分類的二值交叉熵損失函數(shù),二是增添語義一致性分類的損失函數(shù)。具體的損失函數(shù)公式如(2):
Loss=Lclassification+λLcorrespondence
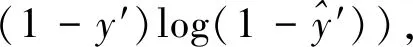
(2)
這里,增加語義一致性度量的交叉熵損失函數(shù)作用是在音視頻特征映射到共享的特征子空間過程中,增加了一致性的約束條件,更好地保持音視頻模態(tài)間及各模態(tài)內(nèi)部特征數(shù)據(jù)的語義信息,引導網(wǎng)絡學習到具有語義保持的音視頻融合特征。相比于直接計算融合音視頻特征的相似性距離,語義一致性任務的損失函數(shù)從語義保持為目標,較大程度實現(xiàn)了模態(tài)間“求同存異”,而相似性距離過多強調了多模態(tài)特征相似性,弱化了其差異互補性,但過于相似的多特征則失去了互補性。從另一個角度來看,語義一致性度量損失函數(shù)相當于對暴力分類損失函數(shù)增加了正則項,在暴力視頻數(shù)據(jù)集由于內(nèi)容的敏感性構建過程比較困難的情況下,一定程度上降低了算法對暴力視頻訓練數(shù)據(jù)的要求,提升了暴力視頻算法的泛化能力。
需要說明的是,本文僅在網(wǎng)絡模型訓練階段,增加語義一致性度量的任務,采用基于音視頻特征多任務學習方法方法訓練得到更為有效的特征融合層參數(shù)。當訓練結束暴力視頻分類的整個網(wǎng)絡模型參數(shù)固定后,在測試階段,對測試的視頻僅進行任務1即視頻是否為暴力的判別。
3 實驗結果及分析
3.1 Violent Flow數(shù)據(jù)集實驗結果及分析
3.1.1 數(shù)據(jù)集描述及評價指標
公開的暴力視頻數(shù)據(jù)集The Violent Flow數(shù)據(jù)集[20]是一個群體暴力數(shù)據(jù)集,參與暴力事件的人數(shù)非常多。這個數(shù)據(jù)集中的大部分視頻都是從足球比賽中發(fā)生的暴力事件中收集的。這個數(shù)據(jù)集中共有246個視頻,其中暴力視頻和非暴力視頻各123個。
Violent Flow庫上的評測指標采用的準確率(Accuary)即:
(3)
其中:TP(True Positive-被正確分類的正例)TN(True Negative-被正確分類的負例),F(xiàn)P(False positive -假正例)和FN(False Negative-假負例)。
3.1.2 實驗結果
The Violent Flow數(shù)據(jù)集中視頻的音頻信息非原始音頻信息,而多是后配上的沒有意義的背景音樂。因此,本文只驗證了以視頻RGB幀和光流為網(wǎng)絡輸入,基于P3D+LSTM的視覺特征提取的有效性。從表1的實驗結果可以看到基于P3D+LSTM提取表觀和運動隨時空變化的語義特征較其他方法更好地表述了暴力視頻的特征,相比于已有方法取得了較好的實驗結果。
表1 在Violent Flow數(shù)據(jù)集上的實驗結果比較
Tab.1 Result comparison between other algorithms and our algorithm on Violent Flow dataset
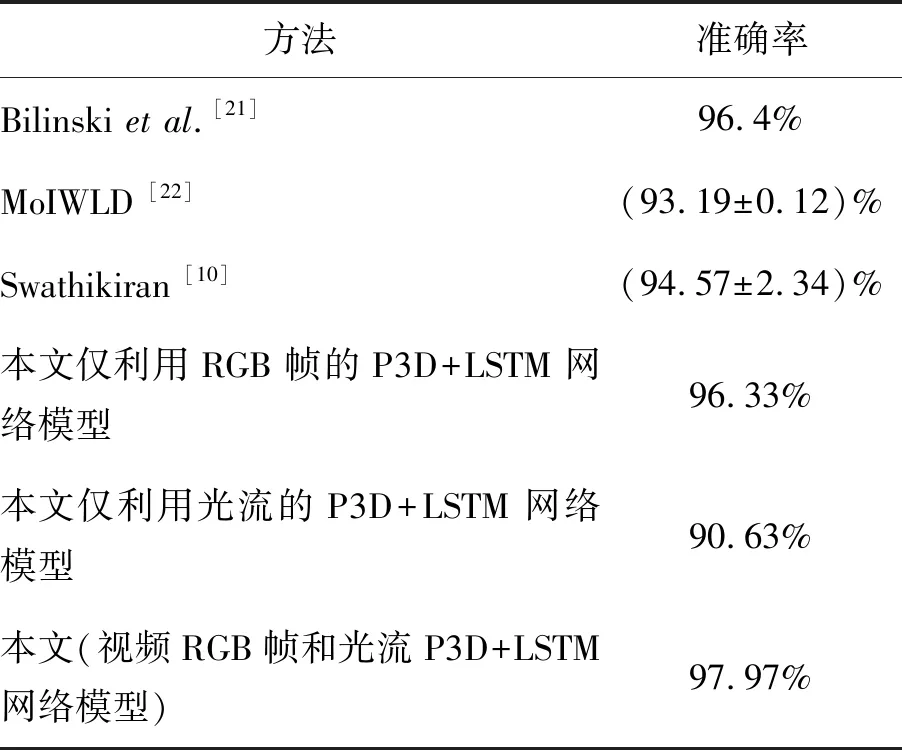
方法準確率Bilinski et al.[21]96.4%MoIWLD [22](93.19±0.12)%Swathikiran [10](94.57±2.34)%本文僅利用RGB幀的P3D+LSTM網(wǎng)絡模型96.33%本文僅利用光流的P3D+LSTM網(wǎng)絡模型90.63%本文(視頻RGB幀和光流P3D+LSTM網(wǎng)絡模型)97.97%
3.2 MediaEval VSD 2015數(shù)據(jù)集實驗結果及分析
3.2.1 數(shù)據(jù)集描述及評價指標
MediaEval VSD(Violent Scenes Detection) 2015[23]暴力視頻公開數(shù)據(jù)集,是由歐洲MediaEval 2015 暴力視頻檢測競賽組織方提供的。該數(shù)據(jù)集來自于199部電影,由10 900個短視頻組成,其中訓練集6 144個短視頻(暴力272個,非暴力5 872個),測試集4 756個短視頻(暴力230個,非暴力4 526個)。本文在此基礎上對訓練數(shù)據(jù)增加了語義一致性標簽。
雖然MediaEval VSD 2015數(shù)據(jù)集由上萬個視頻數(shù)據(jù),但是暴力視頻所占的比例不足5%。在暴力視頻和非暴力視頻樣例比例嚴重不均衡的情況下,使用準確率作為評價指標將無法充分衡量暴力視頻分類性能,因此Media VSD 2015官方采用了平均正確率AP(Average Precision),并提供了AP的計算工具。
3.2.2 實驗結果
本文首先在MediaEval VSD 2015數(shù)據(jù)集上開展了基于單模態(tài)、雙模態(tài)及多模態(tài)的對比實驗,具體實驗結果見表2。由這些實驗數(shù)據(jù)可以看出,本文提出的基于構建共享特征空間的前融合多特征融合方法分類準確率優(yōu)于單特征通道和雙通道融合的分類結果。

表2 不同模態(tài)在MediaEval VSD 2015數(shù)據(jù)集結果比較Tab.2 Comparison based on different modalities on MediaEval VSD 2015 dataset
具體來說,(1)在基于單模態(tài)的暴力視頻分類中:僅基于視覺通道特征(視頻RGB幀)的暴力視頻分類方法的AP值最高為28.32%,而僅基于提取的音頻特征的暴力視頻分類方法的AP值最低為14.16%。這說明在MediaEval VSD 2015暴力視頻公開庫中,對于暴力視頻分類的任務來說,特征貢獻率最大的是視覺通道的表觀語義特征,其次是運動語義特征,最小貢獻的是音頻特征。這也是可以理解的,僅利用音頻信息有時不足以做出是否暴力的判別,比如含有爆炸聲和尖叫聲的音頻也可能是節(jié)日的歡慶,這時必須結合視覺信息或者附以情感分析才可能做出更準確的判斷。(2)在基于雙模態(tài)前融合的暴力視頻分類方法中,基于RGB幀和運動光流兩路特征前融合方法的AP值達到了36.93%,基于光流和音頻兩路特征前融合方法的AP值達到了31.41%,基于RGB和音頻兩路特征前融合方法的AP值達到了29.46%。任何兩路的融合結果都比單一特征分類結果要好,即使音頻對暴力視頻分類貢獻最小,但加入音頻特征仍然有助于提升暴力視頻分類性能,這充分表明了表觀、運動和音頻三種特征,在暴力視頻分類中具有彼此互補性。(3)在RGB、光流和音頻三種特征的多模態(tài)融合中,我們首先比較了決策層后融合和特征層前融合的實驗結果:后融合的暴力視頻分類方法是將RGB這路的P3D + LSTM網(wǎng)絡輸出的分類分數(shù)、光流這路P3D + LSTM網(wǎng)絡輸出的分類分數(shù)和音頻這路VGGish網(wǎng)絡輸出的分類分數(shù)作為特征,送入高斯核SVM分類器學習分類器參數(shù),該方法的AP值是38.12%;而在未加入語義一致性下基于特征層的前融合方法分類準確率為38.65%,這進一步說明了后融合方法丟失了各特征之間的關系,結果不如特征層的前融合方法;最后,加入語義一致性度量的前融合的暴力視頻分類AP值提升至39.76%,這說明了增加音視頻語義一致性度量約束的多任務特征前融合方法構建了較好的特征子空間,使得融合后的特征更為有效地實現(xiàn)暴力音視頻信息互補性。
表3 在MediaEval VSD 2015數(shù)據(jù)集不同方法實驗結果比較
Tab.3 Comparison based on different methods on MediaEval VSD 2015 dataset

方法AP/%Fudan-Huawei [7]29.59Esra et al. [24] 29.47MIC-TJU [5]28.48本文方法39.76
表3給出了在MediaEval VSD 2015暴力視頻公開庫上,已有公開方法和本文提出的方法的對比實驗結果。從表3可以看出本文方法比其他方法AP值高了10.17%,充分說明了本方法的有效性。本文算法性能提升的原因主要得益于選取適合的深度學習方法構建了暴力視頻多模態(tài)特征提取網(wǎng)絡模型,更有效地提取了具有時空連續(xù)性的暴力視頻的表觀、運動和音頻語義特征,獲得了對暴力視頻的有效表征。同時,本文提出了基于語義一致性度量和視頻分類的多任務學習損失函數(shù),構建了語義保持的多特征融合的特征共享子空間,進一步提升了暴力視頻分類性能。
3.2.3 可視化實驗結果
圖3給出了MediaEval VSD 2015公開數(shù)據(jù)集中部分視頻的序列幀。圖3(a)顯示了真實標簽為暴力的ACCEDE02119視頻的32,64,96,128和160 frame。該視頻視覺通道上有明顯打斗動作,音頻通道含有痛苦的叫喊聲,音視頻均具有明顯的暴力特征,算法經(jīng)過多種特征提取和融合正確預測了該視頻為暴力視頻。圖3(b)顯示了真實標簽為暴力的MEDIAEVAL00397視頻的32,64,96,128和160 frame,該視頻僅有流血場面較少,音頻中有槍聲信息。若利用未考慮語義一致性的前融合方法,該視頻將被誤判為非暴力,而采用提出的語義一致性度量的前融合方法可正確分類為暴力視頻。圖3(c)顯示了真實標簽為非暴力的ACCEDE09670視頻的32,64,96,128和160 frame,該視頻畫面較昏暗,昏暗的燈光和流血有一定相似性,蒙面丟瓶的動作和打架出拳的動作有一定相似性,音頻信息比較舒緩正常具有明顯非暴力的特點。若利用未考慮語義一致性的前融合方法,該視頻將被誤判為暴力視頻,而采用提出的語義一致性度量的前融合方法,可正確分類為非暴力視頻。圖3(d)顯示了真實標簽為非暴力的ACCEDE00591視頻的32,64,96,128和160 frame,音視頻均沒有明顯的暴力特征,算法經(jīng)過多種特征提取和融合正確判別了該視頻為非暴力視頻。

圖3 MediaEval VSD 2015公開數(shù)據(jù)集中部分視頻的序列幀F(xiàn)ig.3 Video sequences from MediaEval VSD 2015 dataset
4 結 論
針對暴力音視頻特征融合時未考慮語義一致性的問題,本文提出了一種基于音視頻特征多任務學習的端到端暴力視頻分類方法。首先提取暴力視頻在單幀圖像、運動信息及音頻方面的多種特征,即采用P3D+LSTM網(wǎng)絡提取具有時空特征的表觀和運動的語義特征,基于VGGish網(wǎng)絡獲得暴力視頻音頻語義特征,而后在融合暴力音視頻特征中,以構建具有語義保持的共享特征子空間為出發(fā)點,提出了基于語義一致性度量及多任務學習的特征融合方法,形成了以判斷暴力視頻分類和音視頻語義一致性兩種任務共同學習的暴力視頻分類框架。最后,提出的算法在兩個公開暴力視頻數(shù)據(jù)集進行了測試,均取得較好的實驗結果,其中在MediaEval VSD 2015數(shù)據(jù)集上平均正確率達到了39.76%,優(yōu)于已有暴力視頻判別算法。實驗結果充分證明了本文提出的暴力視頻多特征融合及分類算法的有效性。
目前的暴力視頻分類主要依靠從有限的標注訓練數(shù)據(jù)中獲得的暴力視頻特征,但是該方法學習到的特征和知識受限于訓練數(shù)據(jù)規(guī)模和分布,下一步將考慮構建暴力視頻的知識圖譜,將知識圖譜的外部先驗信息嵌入到深度模型的網(wǎng)絡結構中,探索外部知識和標注數(shù)據(jù)信息的有效融合,進一步提升暴力視頻分類性能。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
湖北經(jīng)濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
大連民族大學學報(2015年2期)2015-02-27 08:28:11
計算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
