深度學習技術及其應用
2020-04-24 14:50:40方蕓馬林梓
電腦知識與技術 2020年5期
方蕓 馬林梓
摘要:該文以深度學習技術的前身機器學習為切入點引出接下來的研究,隨后介紹了深度學習技術的基本概念,并通過圖示來讓晦澀難懂的概念更加簡潔明了;再通過有無監督特征學習兩個方面來探討它未來發展方向及其應用,主要是音、像的識別和自然語言的處理,并在不同的領域分別進行舉例介紹;最后討論了在實踐過程中出現的挑戰以及未來的發展方向。
關鍵詞:深度學習;機器學習;大數據
中圖分類號:TP393 文獻標識碼:A
文章編號:1009-3044(2020)05-0190-04
開放科學(資源服務)標識碼(OSID):
在大數據處理中,數據的計算、存儲和分析是它的核心技術,而對大數據的有效分析就是大數據的價值所在。所以,大數據處理中的最核心、最關鍵的部分就是數據分析。而這些大數據的主要來源之一是互聯網。每分每秒互聯網上都有大量的網頁和數不清的音視頻、圖像等數據產生。現如今,大數據越來越與人們的工作和生活密切相互關聯,已經影響到了人們的方方面面。比如,從淘寶、京東等互聯網上的電子商務交易到航空交通管制,從醫生接觸病人、診斷出什么疾病、并做出可治療方案到警察局接到報警電話出警,再從通過天氣預報來減少災害的破壞到利用人民群眾的舉報來降低犯罪的發生等等,隨處可見大數據的身影。但是目前,由于技術有限,只能分析和利用極少數的數據。這就要求需要研發新的更智能的數據算法技術,在大量無序且復雜的數據中找出規律并發現新的模式,從而提取出新的、有用的知識,來幫助人類做出正確的決策或給出預測。所以,利用深度學習技術和機器學習技術去分析大數據,盡量讓機器代替人工分析數據,而這項技術也獲得了廣泛的應用前景[1]。
1 深度學習技術概述
1.1機器學習的發展階段
要想領會、認識深度學習技術,首先要領會與其前身機器學習的相干的基本知識。作為人工智能領域的一部分,在大多數特定的情況下,可以由機器學習來代替人工智能,機器學習便是經由過程中出現很多分歧的算法,使得大量數據能被機器發現并學習其中的規律,從而對新總結出的數據樣本做出智能辨認或者對將來可能產生的現象做出猜測。1980年前后,機器學習的大概發展階段主要是兩次,劃分是:shallow learning(淺層學習)、deep learning(深度學習)。
1.1.1第一階段:shallow learning
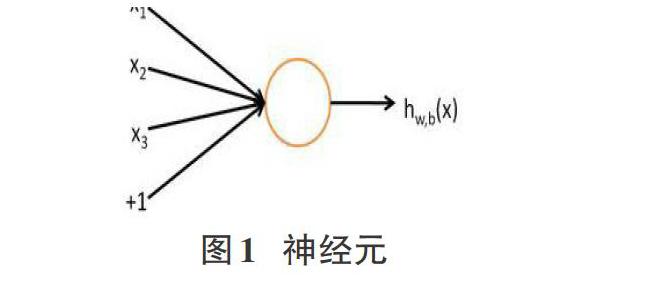
大概1980年前后,一種叫作反向傳播算法作用于人工神經網絡的發現(也叫作BP算法),讓人們對機器學習技術燃起了新的希望。人們從中發現,在大批訓練樣本中,該算法能夠通過運用人工神經網絡模型來學習并從中找出新的規律,從而對將來不可知的事務做出盡量精確的展望。而人工神經網絡又是什么呢?可以先從最簡單的說起,最簡單的人工神經網絡就是由一個神經元組成,如圖1[2]。
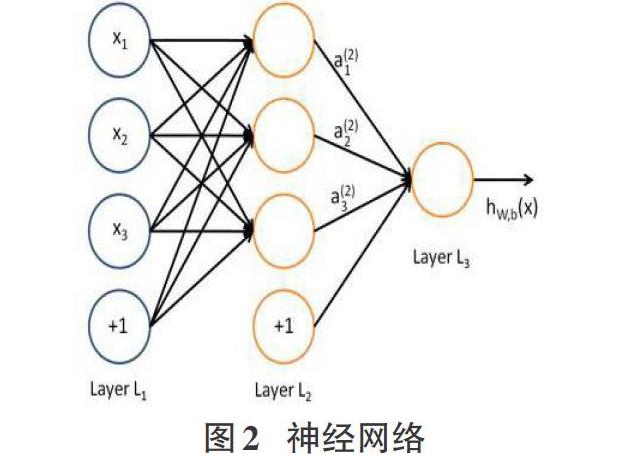
而多個神經元根據某些特定的方法互相結合起來,即這一個的輸入是另一個的輸出,就可以組成基本的人工神經網絡,神經網絡如圖2[2],圖中的圓形代表神經元的輸入內容,最左邊是輸入層。
這類以數據統計為根本的機器學習方法,在很多方面要優越于以前以人工法則為根本的體系。這時的人工神經網絡,因為在多層網絡訓練方面有很多困難,所以實際能被利用的大多數只是僅含有一層隱層節點的淺層學習模型。從1990年開始,提出了很多不同的機器淺層學習模型,比如support vector-machines,簡稱SVM(支撐向量機),以及最大熵方法等等。特別是從2000年開始,由于互聯網絡的發展,人們對大數據的需求變得更加急切,這也使得shallow learning在其互聯網的利用中獲得龐大的樂成。
1.1.2第二階段:deep learning
2006年,機器學習理論的專家Hinton(加拿大多倫多大學教授)和他的學生Salakhutdinov在《科學》上發表了文章[1],正是這篇文章打開了深度學習在工業和學術界中研發的大門,從文章中可以大概得到兩個重要的信息,首先,很多隱層的不被人們發現的人工神經網絡有著十分優秀的特征學習能力.經過特征學習得到的數據有著更加本質性的刻畫,對于可視化和分類非常有利;其次,在訓練深度神經網絡上,可以使用“layeI-wise pre-training”(逐層初始化)來解決其中的難題,而逐層初始化可以經由無監督學習來實現。同時從文中也可以得到一個重要的論據,那就是之所以深度學習技術可以被研發、被應用,是因為在腦神經系統中,的確存在著異常復雜、繁多的層次結構,從而使得深度學習的實現不再是空話。
所以,在當今這個大數據當家的時代,深度學習技術只能越來越炙手可熱,誰能更快的取得深度學習技術的制高點,誰將更好地適應這個社會。
2 深度學習技術的分類
2.1 深度學習技術的分類簡述
在深度學習中,可以通過有無監督特征學習兩個方面來探討它未來發展方向及其應用,而有無監督特征學習就可以作為深度學習技術的兩個分類的依據,再在不同分類的基礎上,研究它的特點和不同,以便人們更加方便的區分它們,并更加有效地利用它們,使它們在各自的領域發揮不同的功效,更好地為人類服務[3,4]。
2.1.1 無監督特征學習
在深度學習技術的研發中,無監督特征學習方法也稱無監督的貪婪逐層學習方法,是最開始被提出來的中心思想:在深度結構模型中,將低層輸出轉化為高層的輸入,然后無監督地學習一層特征的變換,最后形成的深度模型的初始化權值,就是由通過學習得到的網絡權參數按順序一層一層地碼起來形成的,權參數在初始化時是在一個空間內,而這個空間是比較接近輸入數據的流行空間的,因此在模型訓練過程中,降低了陷入部分最小值問題的概率,這就像在過程中施加了正則化約束。
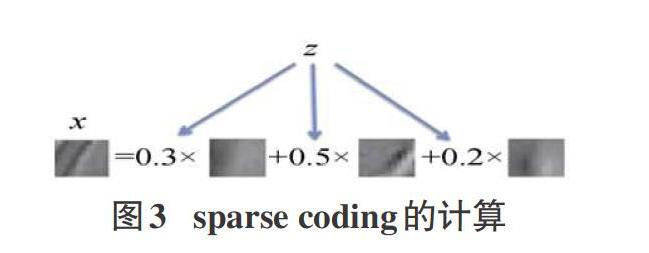
在訓練數據過程中,有標簽的數據數量比較少而無標簽的數據數量較多時,可以采用無監督特征學習方法。而rest-rict-ed Boltzmann machine,簡稱RBM(也就是受限波爾茲曼機)、au-to-encoder,簡稱AE(也就是自編碼模型)和sparse coding(稀疏編碼)就是此中最主要的三個構成模塊。其中sparse coding最為特殊,可以通過圖片來了解它的原理,sparse coding的計算過程如圖3[2]。
2.1.2 有監督特征學習
近年來,以有監督特征為基礎的深度學習技術在計算機視覺的領域中取得了令人驚喜的研究成果,所以越來越多的人認為將深度學習技術從理論研究到實際的大規模應用是應該的。其中最受重視的模型是convolutional neural network,簡稱CNN(也就是深度卷積神經網絡),也是所有深度結構模型最早獲得成功的,其中CNN包含了多階段的Hubel-Wiesel結構,如圖4[4]。
專家LeCun研究的CNN是比較特殊的,該CNN是具有兩種類型的層結構:卷積層和降抽樣層[8]。每一層都有一種拓撲圖結構,例如,每個神經元都對應著輸入圖像上一個固定的坐標,伴隨一個感受野(輸入圖像上影響神經元活動的區域)。在每層的每個位置處,都有很多不同的神經元,每個神經元都有它自己的輸入權值,連接著上層中一個立方體區域的神經元。不同位置的神經元都具有相同的一組權值,但對應著不同位置的立方體區域。
3 深度學習技術的應用
3.1 圖像識別
在深度學習技術中最開始被應用的就是圖像領域。在1989年,紐約大學教授Le Cun等人就開始了關于convolutionneural networks,簡稱CNN f卷積神經網絡)的相關研究工作[9]。而CNN這一結構是如何被提出的呢?這多虧了在生物學領域的研究,人們正是在研究生物視覺行為時受到啟發才提出這一結構,特別是通過研究在Hubel-wiesel模型中[10],模仿兩個視覺皮層里的簡單細胞與復雜細胞之間的行為動作時更加驗證了這一結構。在過去的一段時間,CNN僅限在手寫數字等小范圍的領域上,獲得了很好的體驗結果,但在大范圍應用上還沒有得到大家的重視。而這一現象的產生主要是因為,CNN在大范圍圖像應用上還存在著問題,因此在計算機視覺領域上沒有引起軒然大波。
這個低迷狀態直到2012年才有所好轉,在這一年圖像識別技術取得了令人驕傲的大進步,而促進這一進步的正是加拿大多倫多的Hinton教授和他的學生們,他們在世界聞名的機器視覺識別問題上采用更加具有深度的CNN結構模型[3]。該模型的識別流程如圖5。
在該識別模型中,全部像素的輸入都是由機器獨立完成的。隨后在2013年,人們首次在簡單圖片的識別領域中運用了深度學習模型并取得了較大收獲。從已知經驗中可以看出,運用該模型能夠從根本上解決一般模型識別正確率不高的缺點,從而減少了人們再返工的時間,大大節約了人力資源,這樣在線計算的正確率就可以很大程度的提高了[6]。
圖像識別也不僅僅是識別圖像,隨著研究的不斷深入,也可以進行人臉識別、視頻分析以及圖像分類。其中人臉識別技術更加受到人們的追捧,因為人臉識別除了能夠確認人臉之外,還能辨識不同身份的人臉,但由于不同的人有不同的身份,且相同的人由于在不同的場景拍照導致姿勢、光線甚至臉型的變化,使得這一技術的實現更加困難。
綜上所述,在未來深度學習技術一定會在圖像識別領域中占據主要地位,并引領潮流,而以前的相對依賴人工的學習技術就會慢慢地退出時代的舞臺。
3.2 語音識別
在人們開始使用語音識別系統的歷史中,比較容易被人們接受的就是GMM(也就是混合高斯模型),這種模型一直在該領域起著非常重要作用,主要原因就是它有比較容易獲得的區分度訓練技術,有了這一技術的加持,再加上在進行大數據訓練時估計較簡單,所以更容易被人們接受[5]。但人無完人,同時這種模型也存在著許多弊端,比如,它從根本上來說就是一種網絡層比較淺的建模,而網絡層較淺就說明沒有足夠的深度來記錄它的空間分布,雖然這一缺點可以通過區分度訓練來解決一部分,但能起作用的空間還只是很小的一部分。其后,人們又開始運用DNN模型,但同樣有著很大的弊端和不足。
后來,根據這一缺點,微軟首先邁出第一步,比較有前瞻性的研究了以深度神經網絡為基礎的語音識別系統,正是這一研究顛覆性的解決了原有的深度不夠這一缺點。新研發的系統,能夠將原來不連續的語音片段通過描述片段之間的相似性合并起來,從而形成一個新的高維度的片段特征。
在實際應用過程中,這一技術,除了去其糟粕外,還取其精華,與原來的雖然不成熟但也有很多可取之處的語音識別技術相互聯結,不但提高了語音識別的正確率還節省了不必要的開支,正可謂一舉兩得。
可以通過一個表,從三個方面來看看這三種模型的不同之處,如表1。
隨后幾年,谷歌和百度也相繼采用了這一技術進行語音識別,不得不說這兩大龍頭企業非常具有前瞻性,這也對將來其他公司的業務拓展提供了資料。
3.3 自然語言處理(NLP)
在上文中已經了解到深度學習技術在音、像領域的應用,接下來還要介紹它在其他相對陌生的領域的應用,即自然語言的處理(NLP),顧名思義,它主要的研發方向就是通過自然語言使得原本溝通有障礙的人類和計算機之間能實現溝通,而自然語言的范疇也比較廣泛,既包括人類語言也包括計算機語言,同時還注重這兩者與數學之間的聯系,因此涉及范圍較廣。
在過去的歷史長河中,雖然以人工神經網絡為基礎的NLP模型一直存在,但由于研發的力度不夠,使得人們只能一直應用存在弊端的以統計為基礎的自然語言處理模型。隨后,緊接著有許多學者漸漸意識到人工神經網絡的重要性,開始轉移了研究方向。直到2003年,Bengio(加拿大蒙特利爾大學教授)和他的同事首次提出用非線性神經網絡代替原來的處理模型。而真正開始研究將深度學習技術應用于自然語言處理的是在2008年,在美國NEC研究所,Collobert研究員和Weston研究員為了有效解決原始模型不能完成詞性標注、程序分塊命名實體識別和語義角色標注等在NLP領域經常出現的問題,他們采用了通過嵌入多層的一維卷積結構的方法。在該方法中值得一提的是,不論是一個模型完成一個任務還是完成不同任務,正確率都較高。
同時自然語言處理大體上分為英文和中文兩大方向,這兩個方向的研究領域都有不同。 從整體上來看,深度學習技術在自然語言處理領域上不像音、像領域那樣有較大的成績,但我堅信在這一領域還有很大的發展空間,心急吃不了熱豆腐,同樣任何有價值的研究成果都不會因為時間的長短而止步不前。
3.4 搜索廣告的收益預估
眾所周知,搜索引擎收益的主要方式是通過用戶搜索廣告從而收費來獲得,而計費方式也有很多,其中最常用的就是cost per click,簡稱CPC(即按點擊付費)。所以需要通過一個比率,在按點擊付費這一方式下,來預估收益,這個比率就是clikthrough rate,簡稱CTR(即廣告點擊率),也就是人們點擊的廣告的次數與該廣告被檢索閱讀的次數的比率[11]。而這個比率越是精準,就越說明某個廣告的點擊次數多,從而說明收益越高。
而一般情況下,都是通過機器學習技術來預測得到廣告的點擊率,但這就會導致點擊率的準確性不是很高,所以提高點擊率的準確性是當務之急,這既可以提升用戶的體驗同時也可以為搜索公司和廣告商帶來高額的收益。
一開始,許多搜索引擎公司大都以邏輯回歸模型(簡稱LR)進行預估,但直到2012年才發現,LR模型由于自身結構扁平的原因,使得對模型的分析和特征識別的效果大打折扣,人們這才知道廣告點擊率預估的準確性與模型的結構有著很大的關系[12]。為了解決這一問題,百度公司首次提出將DNN技術應用到于廣告搜索領域,但在實施過程中卻遭遇了許多問題和挑戰,比如就目前的機器計算水平而言,還不能輸入像1011這么高級別的特征廣告,只能人為地將高級別特征數降低到一定水平,最后被DNN技術分析和學習[13]。而現在使用的廣告搜索引擎正是來源于上述所描述的DNN技術,這也為廣大網友提供了便利。
但是,DNN技術在該應用領域的影響還沒有達到最大,在不久的將來,可以將DNN與遷移學習結合,這會大大提高點擊率的正確性;同時還可以將不同的廣告線聯系在一起,這樣不管再有多少不同的廣告,數據之間都可以互通,可以大大節省計算的時間。相信以后的DNN技術在搜索廣告領域中還會有更大的進步。
4 實踐過程中出現的挑戰
4.1 理論問題
通過這么多年研究,不論已知的函數多么復雜且難以表達,都可以找到一個深度學習技術的模型將它表示出來[14],但僅僅只是表示出來,還做不到完全可學習化,參數越復雜,過程越困難,也就是說必須要知道原始函數的復雜程度;另一方面,還需要更強大的計算能力幫助完成學習過程。對于這兩方面的理論研究還有著巨大的研究空間。
4.2 模型問題
隨著理論方面的更深入研究,在模型問題上也遇到了困難。首先,需要更強大的模型來處理,這個新型模型不但包含原來模型的基本功能,還要在原來基礎上表現出更強大的學習能力。
其次,在不同的應用領域都需要不同的參數模型,這給日常建模造成了很大的麻煩,每次建模都需要重新定義參數,但這些模型也有一個共同點,那就是它們都是基于CNN理論的,所以能否找到一個通用的模型,不管應用在哪個領域都可以直接使用。
4.3 實際問題
眾所周知,最開始只能在小范圍圖像數據領域應用深度學習技術,但隨著研究的不斷深入,在大范圍數據領域也可以應用這一技術了,但是兩個領域的最后處理結果幾乎可以說是大不相同,這多虧了現代硬件設施比如CPU、內存等質量的提高,以及在平時訓練中采取的其他線性或非線性的函數方法等[15]。
但是在最終處理結果上,由深度學習技術處理得到的結果與人類大腦處理得到的結果還是存在著很大差距,所以,還必須進一步去研究怎樣改變機器固化的結構模型,并提高它們對數據處理能力的準確性。而隨著數據量的持續增加,深度學習技術也不能故步不前,它們需要采用比原來更加繁雜、成熟的模型,通過提高自身的計算能力更加準確地提取數據中的信息去適應環境的變換。而做出這一改變最根本的就是,如何通過異步的更新模式將原本需要自身攜帶序列的學習算法,改進成可以利用CPU處理的并行學習算法,這將會大大提高計算的準確性。另外,大量的超參數在進行訓練時也是必不可少的,而至今為止還沒有明確的指導方法來告訴我們怎樣選擇超參數,所以在無形中增加了難度。最后,目前為止所有取得的成果都還沒有強大的理論基礎,還需要繼續研究和發展。
5 結論與展望
深度學習技術為人工智能的研究開啟了新的篇章,不僅受到了學術界的關注,也引起了商業等社會各界的重視,大大改變了人們的生活方式,為人們的生活提供了便利。同時它的應用領域也從音、像領域擴大到了自言語言處理領域。最后,雖然在研究過程中還存在著問題和挑戰,相信我們一定可以解決,使深度學習技術的研究更加進步。
參考文獻:
[1]余濱.深度學習:開啟大數據時代的鑰匙[D].廈門:廈門大學,2014:5-6.
[2]敖道敢.無監督特征學習結合神經網絡應用于圖像識別[Dl.廣州:華南理工大學,2014:16-17.
[3]余凱.深度學習的昨天、今天和明天[J].計算機研究與發展,2013,5(1):3-5.
[4]李晨曉.基于深度學習的浮式儲油卸油裝置安全狀態分類方法[D].天津:天津大學,2014:7-8.
[5]其米克·巴特西.基于深度神經網絡的維吾爾語語音識別[Dl.新疆:新疆大學,2015:3-4.
[6]王強.面向大數據處理的圖搜索與深度學習算法并行優化技術研究[D].長沙:國防科學技術大學,2013:5-6.
[7]雷振元.公務員應該掌握社會學基本知識[J].福州黨校學報,2009,2(1):13-15.
[8] Yos hua Bengio. Learning Deep Architectures for Al[M]. New York: now publishers Inc, 1988: 15-16.
[9]張志強.基于特征學習的廣告點擊率預估技術研究[J].計算機學報,2016,5 (1):12-15.
[10]張志浩.基于深度學習的在線廣告點擊率預估系統的設計與實現[D].南京:南京大學,2015:5-6.
[11]李思琴.基于深度學習的搜索廣告點擊率預測方法研究[Dl.哈爾濱:哈爾濱大學,2015:13-16.
[12]毛勇華.深度學習應用技術研究叨.計算機應用研究, 2016,33(1):12-15.
[13]張馭宇.面向深度學習的分布式優化算法研究[D].北京:中國科學院大學,2015:113-116.
[14]梁軍.基于深度學習的文本特征表示及分類應用[D].鄭州:鄭州大學,2016:3-6.
[15]和淵.用信息技術支持深度學習[J].當代教育家,2016(10):26-28.
【通聯編輯:唐一東】
收稿日期:2019 -11-15
作者簡介:方蕓(1962-),女,本科,高級實驗師,研究方向為計算機應用,實驗室管理。
猜你喜歡
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
科學與財富(2016年28期)2016-10-14 21:19:17
科技視界(2016年20期)2016-09-29 10:53:22
