基于時空聚類的在制品流轉狀態分析
2020-04-24 10:56:04王益聰郭宇黃少華張蓉馮上海
機械制造與自動化 2020年2期
王益聰,郭宇,黃少華,張蓉,馮上海
(1. 南京航空航天大學 機電學院,江蘇 南京 210016;2. 中航工業江西洪都航空工業集團有限公司,江西 南昌 330024)
0 引言
離散制造車間中,制造過程根據產品加工工藝分為多道工序,在制品需要在多個工位間流轉[1]。通過車間實時定位系統,能夠有效獲取在制品實時位置信息。對在制品位置數據的挖掘能夠提取在制品在車間流轉的頻繁時空路徑,通過計算在制品流轉過程中實時數據和挖掘的頻繁路徑的偏差,判斷在制品流轉狀態是否發生異常。
隨著無線通信技術的發展,室內定位技術在車間的應用越來越成熟。文獻[2]提出了一種新的基于射頻識別(radio frequency identification,RFID)和WiFi技術的實時定位系統,實現倉庫的自動化、數字化和智能化管理,大大提高了倉庫運行效率,降低了倉庫管理成本;文獻[3]研究了實時定位技術對生產調度的影響,工藝員可以通過定位系統提供的位置數據流實時跟蹤在制品的生產狀態,進而掌握并合理安排每個工位的加工時間,實現生產資源的動態調度和規劃;文獻[4]將基于RFID技術的實時定位系統應用到半導體制造車間中,研究了在車間生產流程中通過實時定位技術獲取的不同生產過程對象位置信息的價值,表明實時定位的應用提供了更好的可視化水平以及更加高效的生產效率。現代觀測技術、計算機網絡和地理信息系統的快速發展,生成大量時空數據,對時空數據分析方法的研究日益增多。文獻[5]提出了基于時空對象的聚類方法,有助于全面分析時空對象空間位置、屬性特征及其變化特點,為多粒度時空對象分析提供思路;文獻[6]利用個體出行的GPS軌跡數據,在DBSCAN的基礎上提出一種新的時空聚類算法,以時空鄰近條件定義簇間距離,識別GPS軌跡中的停駐點;文獻[7]對船載AIS數據展開時空聚類分析,在DBSCAN算法基礎上提出船載AIS數據時空聚類算法,發現隱含的時空模式,為船舶交通管理提供了一種新途徑。
通過分析發現,實時定位在車間主要應用于制造要素的可視化跟蹤和監控,而缺少對位置數據和制造過程之間潛在關系的挖掘。本文以室內定位技術為基礎,有效獲取離散制造車間在制品實時位置數據,實時計算車間現場在制品流轉狀態偏差,及時發現異常,為制造過程動態優化提供依據。
1 在制品流轉狀態分析
在制品的時空數據是定位系統產生的一連串包含時空信息的位置點組成的集合P={p1,p2,…,pn},每個點包含時空坐標pi=(xi,yi,ti)。通過對在制品時空數據的聚類分析,可以發現一些隱含的流轉模式和規律,獲取在制品流轉過程時空模型,然后通過計算在制品實時位置數據與聚類結果的相似度,來分析在制品流轉狀態,其中在制品流轉狀態集合為{正常,預警,異常}。技術路線如圖1所示。
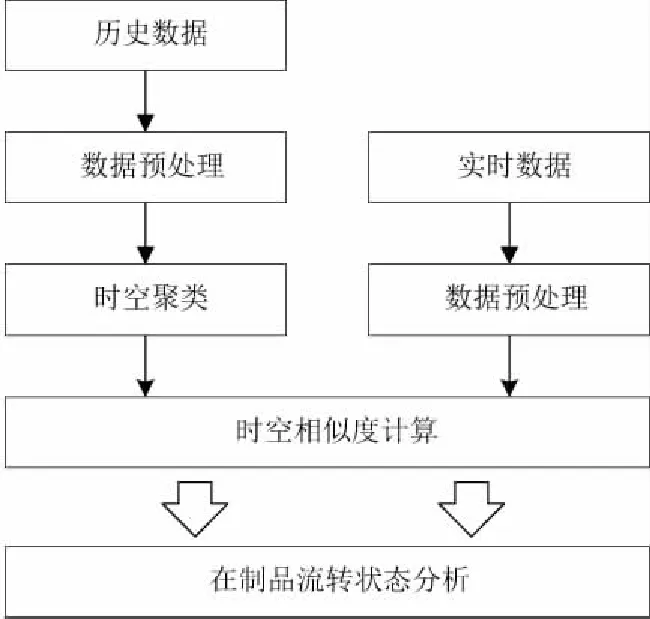
圖1 在制品流轉狀態分析技術路線
2 在制品流轉數據時空聚類方法
2.1 在制品時空軌跡定義
在制品時空軌跡是在空間維度和時間維度上的運動軌跡,表達了在制品空間位置隨時間的變化。時空軌跡由一系列時空記錄組成,每條記錄包括在制品的位置信息和記錄時間。
實時定位系統產生的位置數據記錄主要包括移動目標o、位置數據(x,y)和時間t。對于在制品oi,將其時空軌跡定義為Ti={(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)},如圖2所示。
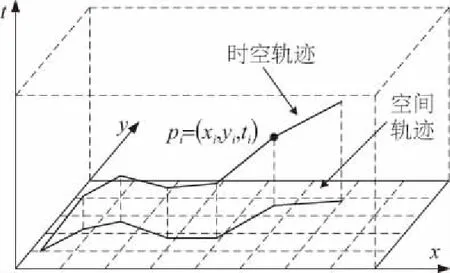
圖2 在制品時空軌跡
在制品時空軌跡包含了豐富的生產過程信息。僅考慮空間軌跡,可以獲取在制品在車間哪些區域、工位間流轉,即在制品工藝路線;結合時間信息,能夠反映在制品在何時到達哪個工位,加工了多長時間等。
2.2 基于網格的在制品時空軌跡聚類算法
網格聚類算法的原理是將數據空間劃分為網格單元,將數據集映射到網格單元中。這種方法的優點是處理速度很快,其處理時間獨立于數據對象數目,只與劃分的單元數目有關,是空間數據處理中常用的將數據離散化的方法[8]。針對離散制造車間位置數據的特點,采用網格聚類算法對在制品時空數據進行處理。
傳統意義上的軌跡通過位置點序列來表達,這給存儲和處理帶來了困難,而網格聚類將軌跡的位置點映射到劃分的網格單元中,極大減小了存儲空間和處理的復雜度。如圖3(a)所示,軌跡由一系列帶有x,y坐標的特征點表達,即{(x1,y1),(x2,y2),…,(xn,yn)}。而在網格表達形式中,同一條軌跡表達如圖3(b)所示,將軌跡按經過的網格單元表達,用網格單元的行列索引號來表示,即{(3,1),(3,2),(3,3),…,(6,8),(6,9)}。網格表達形式具有數據結構簡單、定位存取性能好的特點。時空軌跡則由三維空間網格單元序列來表示。
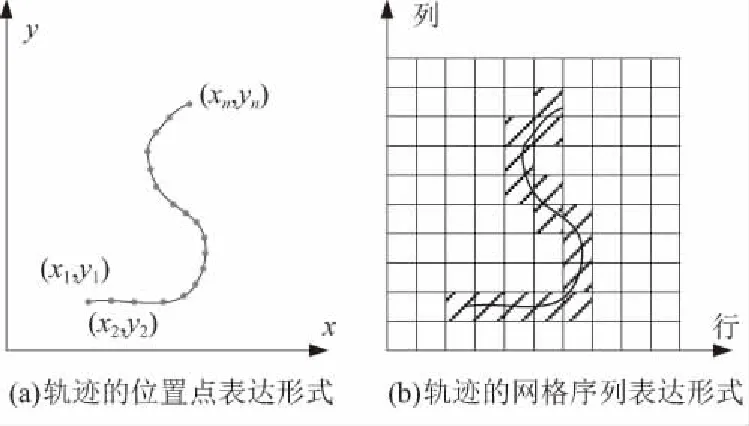
圖3 軌跡的兩種表達形式
網格聚類算法核心思想如下:將數據集的每一個維度劃分成網格單元,掃描所有網格,如果一個網格單元中包含的數據點數超過了給定的密度閾值,則稱該單元是密集的[9]。這些連通的密集單元的最大集合就是簇的定義。算法的相關定義如下:

定義2(網格單元密度) 當1條數據pi∈Gj,即(xi,yi,ti)∈Gj,則稱該條數據屬于網格單元Gj。網格單元Gj中包含的數據總數稱為Gj的網格單元密度density(j)。
定義3(密集網格單元、稀疏網格單元) 設置密度閾值τ,對于1個網格單元Gj,當density(j)>τ時,稱該網格單元為密集網格單元,否則為稀疏網格單元。
(1)
定義6(簇) 數據空間中最大密度相連的網格單元的集合稱為1個簇Ci。
2.3 算法流程
網格聚類算法主要是對車間采集的在制品歷史數據進行分析處理,得到的結果作為在制品流轉狀態實時分析的依據。具體流程如圖4所示。
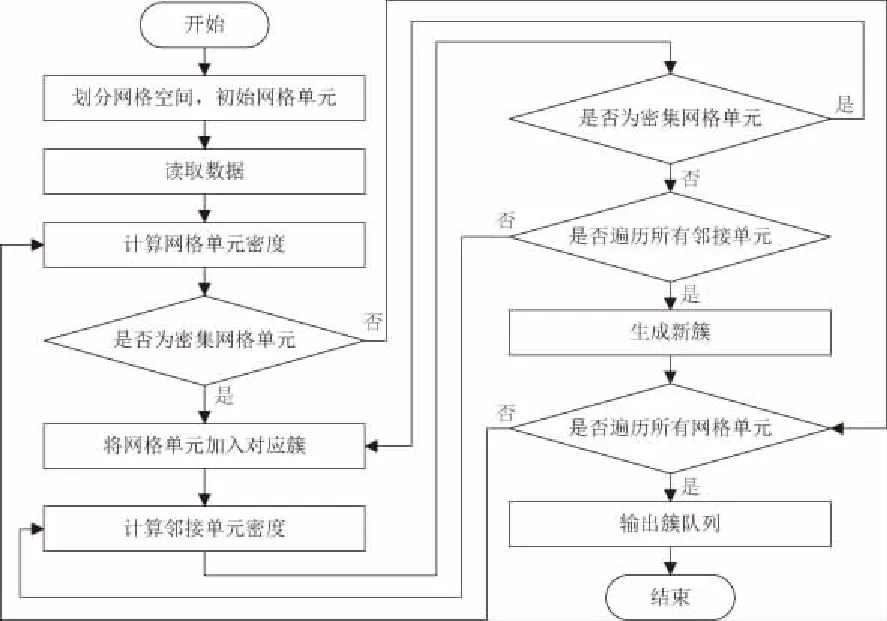
圖4 算法流程圖
算法流程詳細步驟如下:
步驟1:根據車間布局和生產過程的特點,確定數據空間每一維的網格劃分參數λx,λy,λt,初始化網格單元狀態。
步驟2:讀取數據,更新網格單元狀態。
步驟3:根據網格單元密度判斷是否為密集網格單元,若是密集網格單元,則跳至步驟4,否則跳至步驟7。
步驟4:將密集網格單元加入相應的簇中。
步驟5:判斷密集網格單元的鄰接網格是否密集,若是,則跳至步驟4,若否,跳至步驟6。
步驟6:判斷鄰接單元是否遍歷完成,若否,跳至步驟5,若遍歷完成則生成1個簇。
步驟7:判斷網格單元是否遍歷完成,遍歷完成則輸出簇隊列,否則跳至步驟3。
算法輸出的結果是一系列簇C1,C2,…,Cn,每個簇為1個網格序列,對應在制品的時空軌跡。
3 基于改進Hausdorff距離的時空相似度計算
3.1 改進Hausdorff距離
在制品流轉狀態異常檢測是對制造過程中實時采集的數據進行處理,通過計算實時流轉軌跡和聚類結果的相似度來分析在制品的流轉狀態。時空軌跡相似度計算主要依賴于軌跡之間距離的定義以及軌跡之間的匹配程度。Hausdorff距離是描述兩點集之間相似程度的一種度量方法。給定兩點集A={a1,a2,…},B={b1,b2,…},兩個點集之間的Hausdorff距離為:
H(A,B)=max[h(A,B),h(B,A)]
(2)

(3)

(4)
其中:‖a-b‖是點a和b之間的距離度量;H(A,B)稱為雙向Hausdorff距離;h(A,B)稱為點集A到點集B的單向Hausdorff距離;h(B,A)稱為點集B到點集A的單向Hausdorff距離。雙向Hausdorff距離是2個單向Hausdorff距離中的較大者,它度量了2個點集之間的最大不匹配程度[10]。
又經過半個多小時的努力,雖然確診是牙了,但卻由于時間過長,息肉幾乎已經把牙包住了,怎么也拿不出來,最終,段主任決定放棄手術。就在那一剎,我和老婆頓覺墜入了冰窖里。
傳統的Hausdorff距離中‖a-b‖多采用歐式距離,而對于時空軌跡點之間的距離需要同時考慮時間和空間,因此給出時空距離的定義。
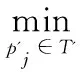
(5)
(6)
結合時間距離和空間距離,定義時空距離為:
DST(pi,T')=DS(pi,T')×DT(pi,T')
(7)
在制品時空軌跡相似度的計算主要是計算實時軌跡和聚類結果之間的Hausdorff距離,因此只計算實時數據到聚類結果的單向Hausdorff距離,最后改進的Hausdorff距離為:
(8)
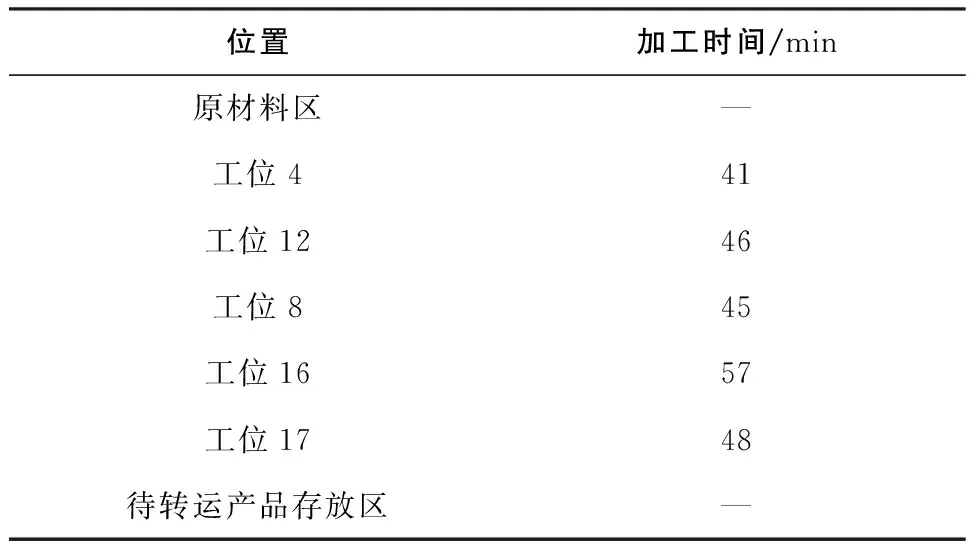
由上面的距離定義可知,改進的Hausdorff距離取值范圍在0~1之間,且Hm(T,T')越小,軌跡T和T'的時空相似度越高。Hm(T,T')≤H1時,在制品流轉為正常狀態;H1 已有的Hausdorff距離計算相似度考察的是兩個無序的集合,而時空軌跡數據是有序的。因此采用基于時間約束的時空相似度計算方法。 圖5 滑動時間窗模式 以某機加車間為例,車間部署了UWB室內定位系統,通過定位標簽實時獲取在制品等制造要素的位置信息,在Intellij IDEA平臺進行了實驗。車間尺寸為92m×44m,共有1個原材料區、1個待轉運產品存放區和20個加工工位。原材料區和待轉運產品存放區尺寸約為20m×10m,各工位尺寸約為10m×10m,其中每個工位包含緩沖區(約10m×2m)和加工區(約10m×8m)。物料從原材料區粘貼定位標簽,并配送到各加工工位,加工完成的產品運送到待轉運產品存放區。車間布局如圖6所示。 圖6 車間布局 車間正常生產過程中采集到的每條位置數據包括:ID、采集時間和坐標信息,數據采集頻率為4Hz。由于原始采集的數據中時間記錄為絕對時間,無法直接對時間進行劃分。在對原始數據進行聚類之前,先進行預處理:將在制品離開原材料區的時刻記為t0,則處理后的數據為(ID,x,y,t-t0)。 車間采用的UWB定位系統動態定位誤差90%的情況下<30cm,約99%的情況下定位誤差<60cm。同時考慮加工區、緩沖區和通道等區域的尺寸,避免同一網格跨越不同功能區域,設置車間空間網格劃分粒度為0.5m×0.5m。為保證一定的實時性以及盡可能降低算法復雜度,設置時間維度網格步長λ=1min。網格聚類的關鍵參數密度閾值τ對聚類結果影響較大,實驗結果表明,τ值偏大會導致本屬于同一個簇的網格被分到兩個簇,容易丟失在制品流轉過程信息;τ值偏小會將不同簇的網格聚到一起,同時會受到異常數據和稀疏數據的影響,導致聚類結果失真,同時增加了算法的時間復雜度。對于不同的參數τ取值,算法的正確率和運行時間如圖7所示。 圖7 不同參數下算法正確率和運行時間 從圖中可以看出,在密度閾值設置為80和90時,算法正確率為100%,而算法運行時間隨著密度閾值的增大而減小。綜合考慮算法正確率和運行時間,設置密度閾值τ=90,對在制品歷史軌跡數據進行聚類。部分聚類結果如表1所示。 表1 算法結果 表中列出了在制品停留時間較長的網格,結合車間幾何空間和語義空間,聚類結果可以解釋為在制品的加工路線詳細信息,如表2所示。 表2 在制品加工路線 在制品流轉軌跡時空相似度計算過程中,設置時間間隔tgap=5min,即每5min更新一次相似度計算結果。根據車間布局以及在制品加工用時,取在制品流轉狀態變化臨界值H1=0.19,H2=0.42。采用某在制品加工過程中采集的數據作為模擬實時數據輸入,改進Hausdorff距離計算結果如圖8所示。 圖8 計算結果 從圖中的計算結果可以發現,在制品流轉狀態在160min之前處于正常狀態,165min時改進Hausdorff距離增大,進入預警狀態,185min時進入異常狀態,改進Hausdorff距離在200min開始趨于穩定。結合車間實際情況,工位16的機床在165min左右時發生故障,導致在制品在工位16的緩存區停留時間過長,同時,機床在195min左右恢復正常。由此證明了本文提出方法的有效性。 離散制造車間在制造過程中難免發生異常情況,如設備故障、物料配送異常、人員離崗等,一旦無法及時發現并處理車間生產異常,將直接影響車間制造活動的正常運行。而通過結合在制品的實時位置數據對在制品流轉狀態偏差進行實時分析,能夠對在制品流轉過程中發生的異常進行有效預警,有助于制造過程的正常運行。 實時定位技術在離散制造車間應用越來越廣泛,因此產生了大量的位置數據。本文在離散制造車間實時位置數據的基礎上對在制品流轉狀態分析展開研究。通過位置大數據處理方法建立在制品流轉的時空軌跡模型,以此為依據,結合制造過程中實時位置數據計算流轉狀態偏差。最后,以某機加車間為例進行了驗證,結果表明本文提出的方法可以有效分析在制品流轉狀態。3.2 基于時間約束的時空相似度計算

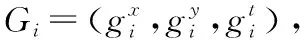
4 案例分析




5 結語
