基于C4.5算法的農業險種可持續性挖掘研究
2020-03-31 13:26:21宋正陽
安徽農業科學 2020年4期
宋正陽

摘要為了能夠高效地分類出農業保險承保與理賠業務連續數年變化差異大的險種,為相關從業人員深入研究農業保險的實施與創新提供決策支持與目標定位服務,以北京市政策性農業保險數據為依托,通過預先設定評價指標體系,研究經典決策樹C4.5算法篩選目標險種的效果。結果表明,在排除政策影響的情況下,C4.5算法提高了對農業目標險種篩選的效率,可為相關從業人員開展重點險種的改革創新或開發新的服務業務提供參考依據。
關鍵詞農業保險;C4.5算法;可持續性;北京市
中圖分類號F840.66文獻標識碼A
文章編號0517-6611(2020)04-0235-04
doi:10.3969/j.issn.0517-6611.2020.04.068
開放科學(資源服務)標識碼(OSID):
Research on Sustainability Mining of Agricultural Insurance Based on C4.5 Algorithms—Taking Beijings Policy Agricultural Insurance as an Example
SONG Zheng-yang(Agricultural Information Institute of the Chinese Academy of Agricultural Sciences, Key Laboratory of Digital Agricultural Early-warning Technology, MOA, Beijing 100081)
AbstractIn order to effectively classify the different types of insurance in the agricultural insurance underwriting and claims settlement business for several years, to provide decision support and target positioning services for the relevant practitioners in-depth study of the implementation and innovation of agricultural insurance, we studied the effect of classical decision tree C4.5 algorithm in screening target insurance species by setting up an evaluation index system in advance based on Beijing's policy-oriented agricultural insurance data.The results showed that the C4.5 algorithm improved the efficiency of screening agricultural target insurance, and could provide references for relevant practitioners to carry out reform and innovation of key insurance or develop new service business.
Key wordsAgricultural insurance;C4.5 algorithm;Sustainability;Beijing
農業保險是對農民生產風險的一種保障,我國農業保險起步較晚,但發展較快,全國各省均針對自身的地域特點開展了不同形式的農業保險業務,開發的險種各有不同,僅北京地區開展過的險種就多達59種(含已停售險種),每個新險種的產生都需要保險公司或科研機構投入大量智力資源來開發完成。一個好的農業險種必須能夠平衡農戶利益與保險公司利益,其效果發揮需要經過市場驗證、(結合政策)調整、再驗證反復進行。保險公司為了提高自己的服務質量,同時符合政府對農業保險實施精細化管理與市場的需求,需要不斷地探索險種的改良與開發。
國內外學者對農業保險新技術或模型[1-3]、農業保險政策或發展模式[4-6]以及保險實施效果或評價進行了研究[7-8] ,但鮮有對歷史險種的績效評價方面的研究。
鑒于此,筆者通過農業保險承保與理賠環節重要節點數據連續若干年的變化趨勢建立一種農業險種的績效評價方法,采用C4.5決策樹算法快速分類農業險種承保與理賠實施效果差異,判斷哪些險種需要創新改革以適應新的市場與政策環境或深度挖掘出新的險種服務,旨在為相關從業人員開展重點險種的改革創新或開發新的服務業務提供參考依據。
1農業險種績效評價
政策性農業保險是以保險公司為依托,政府通過保費補貼扶持,對種植業、養殖業及涉農保險標的物因遭受自然災害和意外事故造成的經濟損失提供的保險。在市場相對成熟的情況下,從險種連續幾年農業保險的實施效果來做判斷,從而反推其他因素影響,得出農業險種的評價結果。
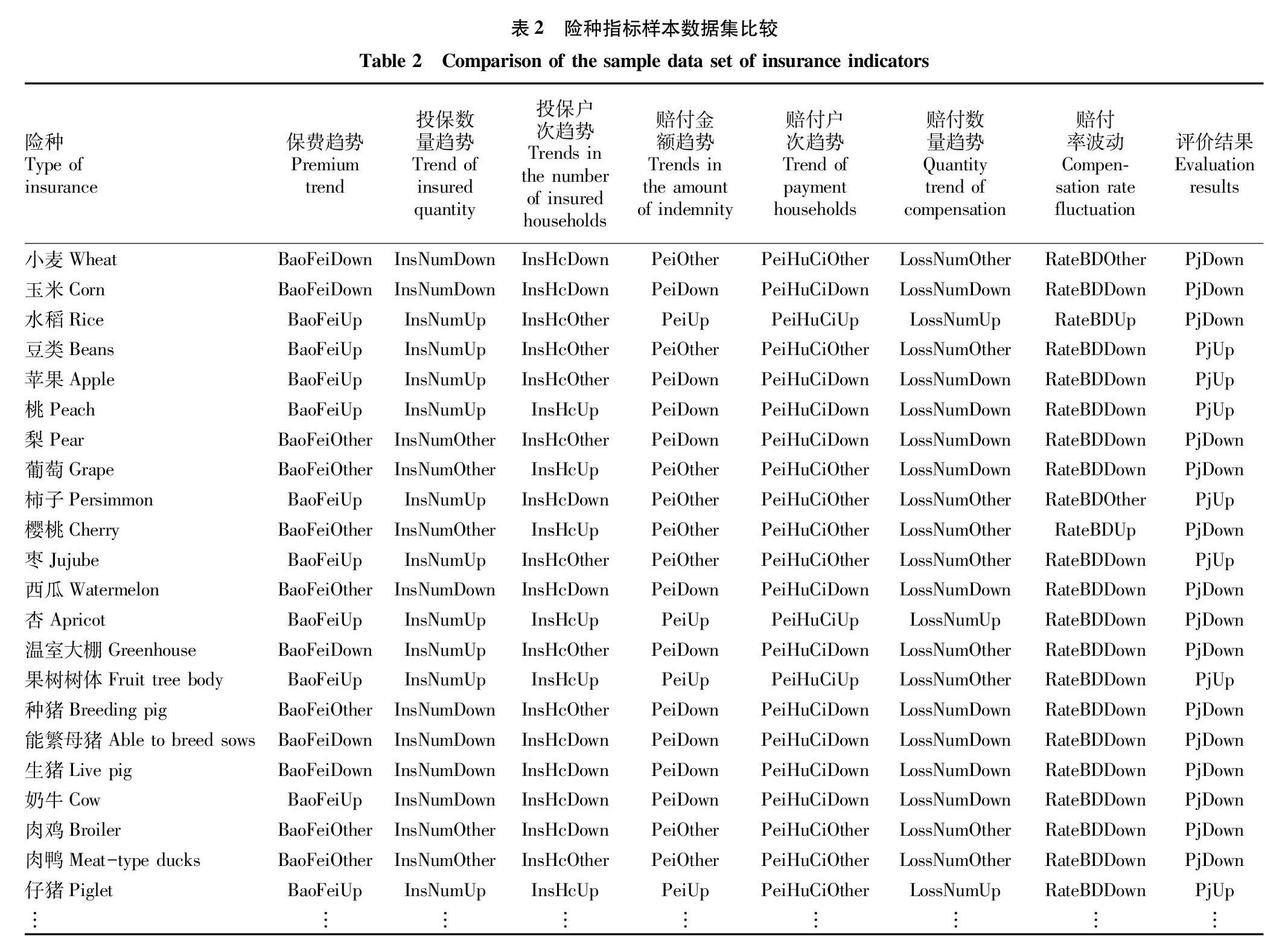
1.1險種實施結果指標選擇以種植業與養殖業為例,每個險種的實施結果均反映在如下幾個方面:①承保環節指標。它包括投保數量,投保戶次,簽單保費。實例中指標樣本數據主要反映的是農業險種的種養規模變化、參與農戶數量變化與總保費的變化。②理賠環節指標。它包括賠付戶次,賠付數量,賠付金額,賠付率。實例中指標樣本數據主要反映的是受災后保險賠付金額變化、受益戶次變化、災損數量變化以及賠付率波動變化。依據上述基礎指標,設定農業險種評價指標(表1)。
由表1可知,設定承保環節指標中有不小于2項是持續增加的,則承保指標為“高”,反之為“底”;同樣,理賠環節中有不小于3項是持續增加(或非<10%)的,則理賠環節指標為“高”,反之為“低”。當承保指標與理賠指標評價結果不一致時(即一個為“高”另一個為“低”),險種評價為需要重點研究險種。
1.2樣本數據集選擇
依托北京市農村金融與風險管理信息平臺,可以獲得北京地區相關完整、準確的政策性農業保險數據。取2016、2017、2018年3年保單與理賠數據為試驗訓練樣本,該數據集包含了北京地區13個區縣和4家集團公司共53個險種的數據,其中承保2.4萬條數據、承保明細25.7萬條數據、理賠11.9萬條數據和理賠明細27.6萬條數據。通過對數據集的歸類計算,依據表1指標描述引出指標結果集,表2列出了部分險種指標樣本數據集。
2決策樹算法
2.1C4.5算法
決策樹算法作為一種分類算法,目標就是將具有p維特征的n個樣本分到c個類別中去,它是判斷給定樣本與某種屬性相關聯的決策過程的一種表示方法, 該方法廣泛應用于數據挖掘和機器學習等領域,用來解決與分類相關的問題,目前比較經典的決策樹生成算法有ID3、C4.5和CART樹3種。
決策樹C4.5 算法是構造農險險種績效評價決策樹,該算法的輸入是一張關系表,由若干不同的屬性及若干數據元組(稱為訓練樣本數據集 ) 組成。該算法采用信息熵的方法,比較各個判定對象屬性的信息增益率的大小,選擇信息增益率最大的屬性進行分類,遞歸生成一個判定樹。
2.2算法描述
參考表2的數據樣本數據集中,取屬性集中D={保費趨勢,投保數量趨勢,投保戶次趨勢,賠付金額趨勢,賠付戶次趨勢,賠付數量趨勢,賠付率波動},評價結果集類別有P={PjUp,PjDown}。
2.2.1計算類別信息熵。
信息增益實際上是ID3算法中用來進行屬性選擇度量的。它選擇具有最高信息增益的屬性來作為節點N的分裂屬性。該屬性使結果劃分中的元組分類所需信息量最小。對D中的元組分類所需的期望信息為下式:
Info(D)=-mi=1pilog2(p2)(1)
式中,m指結果集中元素不同類別個數(實例中m為2),pi為第i個結果集類別元素在樣本數據集中的個數與樣本數據集總行數的比值,例如表中“評價結果”共計y個,其中PjUp有x個,則pi=x/y,Info(D)又稱為熵。
2.2.2計算每個屬性的信息熵。
現在假定按照屬性A劃分D中的元組,且屬性A將D劃分成v個不同的類。在該劃分之后,為了得到準確的分類還需要的信息由下面的式子度量:
InfoA(D)=yj=1|Dj||D|×Info(Dj)(2)
式中A為D的屬性分類,比如“保費趨勢”,y為“保費趨勢”值中不同分類(BaoFeiUp,BaoFeiDown,BaoFeiOther)個數(這里為3),Dj為每個不同分類元素在樣本數據集中的個數(例BaoFeiUp的總個數),D為樣本集總行數 ,Info(Dj)為樣本數據集中單獨提取出某一個分類組成的表的熵(例如,只取樣本數據集—表2中含BaoFeiUp的數據行,組成的新表求熵)。
2.2.3計算信息增益。
信息增益定義為原來的信息需求(即僅基于類比例)與新需求(即對A劃分之后得到的)之間的差,即:
Gain(A)=Info(D)-InfoA(D)(3)
2.2.4計算屬性分裂信息度量。
用分裂信息度量來考慮某種屬性進行分裂時分支的數量信息和尺寸信息,把這些信息稱為屬性的“內在信息”。信息增益率等于信息增益/內在信息,會導致屬性的重要性隨著內在信息的增大而減小(也就是說,如果這個屬性本身不確定性就很大,那我就越不傾向于選取它),這樣算是對單純用信息增益有所補償。
HA(D)=-yj=1|Dj||D|×log2(|Dj||D|)(4)
2.2.5計算信息增益率。信息增益率定義:
IGF(A)=Gain(A)/H(A)(5)
選擇具有最大增益率的屬性作為分裂屬性[3,9-10]。
3實例分析
總結上節所述算法流程如下:
While(當前節點非葉子結點)
(1)計算當前節點的類別信息熵Info(D)(以類別取值計算);
(2)計算當前節點各個屬性的信息熵Info(Ai)(以屬性取值下的類別取值計算);
(3)計算各個屬性的信息增益Gain(Ai)=Info(D)-Info(Ai);
(4)計算各個屬性的分類信息度量H(Ai)(以屬性取值計算);
(5)計算各個屬性的信息增益率IGR(Ai)=Gain(Ai)/H(Ai)。
End While
依據表2數據集,通過以上算法流程執行第1次循環得到結果見表3。
算法取信息增益率IGR(A)值最大(0.026 93)的指標項“投保數量趨勢”作為初始分裂屬性。如此循環執行C4.5算法,不斷分裂,直至所有節點均為葉子節點(圖1)。
通過對表2數據集(共計8個分類,424個屬性值)執行決策樹算法,可以最少分裂2次、最多分裂4次找到葉子結點(結點屬性值對應所有結果值均相同),時間可以忽略,算法可以很快依據評價指標分類出需要重點研究的農險險種,符合預期目標。
4結論
決策樹方法只需要預先確定樣本數據集,然后依賴數據學習得到決策樹,并用定量規則方式表達所獲取的知識,應用于農業保險險種可持續發展性評價,即只需要選取合適的險種指標基礎數據(相應指標的保險業務數據)并依據評價規則計算得到分類結果。依據農業保險業務發展情況對保費趨勢、投保數量趨勢、投保戶次趨勢、賠付金額趨勢、賠付戶次趨勢、賠付數量趨勢以及賠付率波動屬性設定評價方法,通過采用決策樹C4.5算法進行險種業務發展情況的快速結果分類處理,該方法不僅可以有效避免主觀判斷和經驗知識的不足,且有利于隨著保險業務的推進快速更新評價數據,為有效分類出重點農業險種研究對象、開展可持續性研究提供了一種思路和方法。但其應用有一定局限性,即農業保險受“政策”影響較大,并非完全市場運營機制,這在政策性農業保險發展初始期難以避免。隨著我國社會經濟的不斷發展,農業保險發展日漸成熟,“政策”對農業保險市場的影響將逐漸淡化。加之保險業務發展評價方法的不斷完善,決策樹算法的逐步改進將對數據的分析結果更趨于高效性與合理性。
參考文獻
[1]李飛,齊林.基于決策樹C4.5算法的大數據保險業模型研究[J].財政與金融, 2017(2):71-73.
[2] 司巧梅.基于決策樹的農業氣象災害等級預測模型[J].安徽農業科學,2010,38(9):4925-4927.
[3] 紀思琪,吳芳,李乃祥.基于決策樹的蔬菜病害靜態預警模型[J].天津農學院學報,2017,24(2):77-80.
[4] 曹波.新疆農業保險運行效率評價:基于五個試點地區的實證分析[D].烏魯木齊:新疆農業大學,2016.
[5] 庹國柱.試論農業保險創新及其深化[J].農村金融研究,2018(6):9-13.
[6] 高岑.國外典型農業再保險發展模式分析及其啟示[J].農村經濟與科技, 2019,30(2):212-214.
[7] 趙紅.我國農業保險標準化績效評價研究[D].濟南:山東大學,2015.
[8] 林樂芬,李遠孝.高效種植農業保險績效評價及影響因素分析:以江蘇省為例[J].煙臺大學學報(哲學社會科學版), 2018,31(5):98-109.
[9] 馬偉杰.基于C4.5決策樹算法的網絡學習行為研究[J].科學導刊,2016(23):150-151.
[10] 任周橋,劉耀林,焦利民.基于決策樹的土地適宜性評價[J].國土資源科技管理,2007,24(3):21-25.
猜你喜歡
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
