基于集成模型的個人信用風險評估研究
2020-03-24 08:50:31李思瑤
時代金融 2020年5期
李思瑤


摘要:隨著金融科技的快速發展,機器學習在大數據風控領域的應用也越來越成熟,尤其在在線信貸中被廣泛應用。本文從消費金融行業的實際業務出發,提出了一套基于多源數據的子模型框架系統,該系統可以根據不同的數據維度獨立建立,再將模型進行自由組合。研究表明,基于多源數據的子模型系統的評分有效性比單個機器學習評分模型更好。
關鍵詞:風險管理?? 信用評分? 機器學習
一、引言
如今風險管理部門已經成為諸多企業中的重要職能部門之一,為實現企業的經營目標提供有力保障。隨著互聯網的迅猛發展,大數據、數據挖掘和機器學習等新興技術開始出現并在企業的經營決策過程中得到應用。
大數據:作為一項新興技術,目前在IT界較為認可的定義是:在可承受的時間范圍內,無法用傳統數據庫軟件工具進行分析利用的數據集。
(一)大數據在風險管理中的應用
最早應用大數據風險管理的正是風險管理出現最早的保險業。保險業工作人員利用客戶的銀行系統征信數據和在互聯網上產生的涉及人際關系、歷史消費行為、身份特征等方面的數據,通過大數據“畫像”技術,對用戶進行全面的定位,據此來預測用戶的履約能力進而降低信貸風險。
大數據技術成功應用的案例很多,比如CanadianTire公司曾做過的一次將消費者行為和信用風險相掛鉤的突破性調查。通過詳細分析消費者在多家店鋪使用本公司所發行信用卡消費的情況,CanadianTire公司發現延遲交付、信用卡違約都是可以預測的,辦法就是通過研究人們購買的商品種類、品牌以及所光顧的酒吧類型。結果證明,這種預測比傳統的行業預測方法更為精準。金融業工作人員可以利用大數據的優勢,通過將多樣化的數據集引入計算,提高對風險的防范意識并降低風險。
(二)機器學習
機器學習技術并不是剛剛起步,而是隨著電子計算機的出現而出現的一種技術。互聯網的普及讓機器學習以大數據應用技術的全新面目呈現出勃勃生機。簡言之,機器學習就是通過各種算法對海量的歷史數據進行有監督或無監督的學習分析,總結規律,并利用分析結果對未來數據進行預測的一種技術。機器學習目前有很多應用方向,包括風險識別、模式識別、圖像識別、智能決策等。
二、模型簡介
(一)XGBoost算法
XGBoost的目標函數由兩部分構成:一部分用來衡量預測分數和真實分數的差距,另一部分則是正則化項。正則化項同樣包含兩部分:一部分用于控制葉子結點的個數,另一部分用于避免葉子節點的分數過大,防止過擬合。XGBoost還提出了兩種防止過擬合的方法:Shrinkage and Column Subsampling。Shrinkage方法就是在每次迭代中對樹的每個葉子結點的分數乘上一個縮減權重η,這可以使得每一棵樹的影響力不會太大,留下更大的空間給后面生成的樹去優化模型。Column Subsampling類似于隨機森林中的選取部分特征進行建樹。其可分為兩種,一種是按層隨機采樣,在對同一層內每個結點分裂之前,先隨機選擇一部分特征,然后只需要遍歷這部分的特征,來確定最優的分割點。另一種是隨機選擇特征,則建樹前隨機選擇一部分特征然后分裂就只遍歷這些特征。一般情況下前者效果更好。當樣本的第i個特征值缺失時,無法利用該特征進行劃分時,XGBoost的處理思路是將該樣本分別劃分到左結點和右結點,分別計算增益,劃分到增益大的一邊。
(二)LightGBM
lightGBM主要有以下特點:基于Histogram的決策樹算法、帶深度限制的Leaf-wise的葉子生長策略、直方圖做差加速、直接支持類別特征(CategoricalFeature)、Cache命中率優化、基于直方圖的稀疏特征優化、多線程優化。Leaf-wise的方法是從當前所有葉節點中尋找信息增益最多的方向進行分裂,這樣的設計比Leaf-wise方法的預測精度更高而誤差更小。而且為了防止過擬合,LightGBM在分裂的時候對最大深度也進行了限制。
三、集成模型框架設計
傳統銀行評分卡使用的變量較少,一般10個左右的強信息變量,包含三種類型:基本信息、個人信用和貸款人社會關系。與傳統銀行信用卡業務相比,在線信貸由于大多為模型自動決策,而基于傳統評分卡模型的建模方法數據維度較少,在互聯網時代下少數的幾個維度很難對借款用戶進行精準畫像。因此,為了彌補評分卡模型中的信息缺失,將各種維度的數據分別訓練為子模型,再進行融合為最終模型是一種更好的解決方案。
為了提高網絡借貸中的信用風險評估,本文提出一種集成模型框架,基本思想是:首先,根據不同場景、不同客戶群的不同數據,將數據分組后分別訓練子評分模型;然后根據訓練好的模型輸出的結果作為輸入變量進行重新建模,得到最終的信用評估結果。本文中選用根據消費金融公司主要數據源進行分析建模,包括:多頭借貸、高風險特征、運營商信息、銀行卡信息、第三方信用評分、人行征信報告。先將數據源按照這6種維度分別進行子模型訓練,再把訓練得到的6個子模型輸出結果整合成一個6列矩陣(將每個子模型的預測結果轉換為具體分數),再重新利用機器學習融合成新的模型評分。
在該案例中,集成模型框架根據不同的數據來源,構建了6個機器學習子評分模型,子模型的數量和選用的算法都可以自由選擇,而且隨著數據源的豐富還可以不斷的增加子模型的數量。雖然各子模型都能較好的預測用戶的信用風險,但集成模型的預測準確率更高,并且預測效果也更穩定。當面對不同的借貸場景或不同的客群時,模型可用的數據也不同。這時,先將數據根據來源或客群分組,然后自由選擇入模數據,自由選擇模型算法,自由組合入框架的子模型,可以大大提高數據的使用效率且節約數據采購成本。
四、實證分析
實驗數據為2018年1~9月11996筆小額在線貸款數據,壞樣本定義為歷史逾期最長天數不低于90天的客戶,標記為1;好樣本定義為沒有逾期記錄且已經有完整的借款表現期的客戶,標記為0。其中壞樣本共2999個,占比25%,好樣本共8997個,占比75%,Odds=3,表5為本次實驗數據的基本情況。
首先,本實驗將6個子模型所包含的全部超過100個變量全部作為輸入,預測違約概率。為了找到分類效果最佳的模型,本文嘗試了GBDT、Adaboost、RandomForest、LightGBM、XGBoost多種機器學習方法,根據AUC、KS、準確率等評價指標挑選出最佳模型,對比結果見表1。
實驗中,數據集按4:1的比例拆分為訓練集和測試集,表2展示的是各模型在測試集上的表現。可知,在測試集上表現最佳的是LightGBM模型。與其他模型相比,其準確率、AUC、KS的數值都較大,說明該模型區分能力更高。
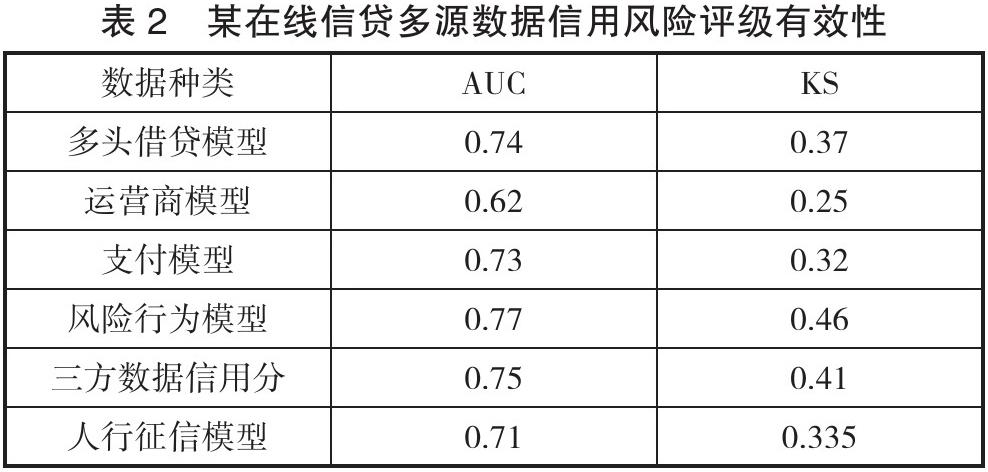
為了驗證組合模型思想模型的有效性,我們對6個子模型分別訓練,并對預測有效性做了分別統計,又將6個子模型的預測概率轉化為具體評分,再把6個評分作為最終的模型輸入變量,重新再利用進行機器學習進行建模,6個子模型的結果如表2所示。
從表2可以看出,6個機器學習評分模型中,風險行為數據與某第三方信用評分模型的預測效果最好,這也說明網絡借貸業務往往面臨較高的信用風險。最后,將6個子模型的預測結果作為輸入變量融合成一個集成機器學習模型,對比結果見表3。
從表3的試驗對比可以看出,將子模型的預測結果作為輸入重新構建的機器學習模型,可以獲得比直接進行全變量輸入更好的預測精度,其中最優算法LightGBM的預測KS值從65.45上升到了66.28,且其他算法的預測精度也有了一定的提升。
表4展示了在LightGBM模型下測試集樣本的通過率和誤放率的情況。模型在預設概率為0.45~0.50的條件下(即只有當某個客戶被預測為壞人的概率大于0.45時才通過篩選),KS0.663,通過率最高可達67.40%,而其對應的誤放率很低,為6.70%。這說明通過LightGBM模型篩選的客群能夠保證較高的質量。
五、結論
本文通過嘗試GBDT、Adboost、RandomForest、LightGBM、XGBoost多種機器學習方法,根據多種評價指標篩選對比,得出如下結論:
第一,對大數據而言,機器學習方法能夠更好地探索數據的內在結構,形成的分類模型也更加精準。在本文嘗試的幾種機器學習方法中,XGBoost、LightGBM模型的分類效果最好。
第二,基于多源數據的子模型框架可以根據不同的數據維度獨立建模,每個子模型可以用不同的方法進行訓練,且訓練的好的子模型也可以進行自由的組合。本研究只是簡單的將子模型再重新進行了一次利用LightGBM算法的重新組合就獲得了比直接進行全變量建模方式。實際上,子模型還能通過傳統評分卡建模的方式構建評分卡模型,使得機器學習算法也能獲得很好的解釋效果,或者利用決策樹方法,將子模型構建為一個基于決策樹方法的策略集也是一個非常有價值的研究方向。
參考文獻:
[1]Chen T,He T,Benesty M . xgboost: Extreme Gradient Boosting[J]. 2016.
[2]Jerome H. Friedman. Greedy Function Approximation: A Gradient Boosting Machine[J]. The Annals of Statistics,2001,29(5):1189-1232.
[3]王春峰,萬海暉,張維.《商業銀行信用風險評估及其實證研究》[J].《管理科學學報》,1998第1期.
[4]李旭升,郭春香,郭耀煌.《擴展的樹增強樸素貝葉斯網絡信用評估模型》[J].《系統工程理論與實踐》,2008年第6期.
[5]涂艷,王翔宇.基于機器學習的P2P網絡借貸違約風險預警研究——來自“拍拍貸”的借貸交易證據[J].統計與信息論壇,2018,33(6):75-82.
作者系蘭州財經大學金融學院2019級碩士研究生
猜你喜歡
世界最新醫學信息文摘(2021年12期)2021-06-09 08:37:56
商周刊(2018年23期)2018-11-26 01:22:28
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科學與財富(2016年28期)2016-10-14 21:19:17
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
中國衛生標準管理(2015年1期)2016-01-14 03:41:26
無錫職業技術學院學報(2014年2期)2014-02-28 17:53:16
中國工程咨詢(2014年8期)2014-02-16 06:31:00
