辭書編纂系統的漢字處理: 挑戰與解決方案
2020-02-06 03:51:35張永偉
辭書研究 2020年1期
張永偉
摘要:自計算機發明伊始,文字處理就成為計算機技術的核心課題。世界上主要的文字系統包括拼音文字、楔形文字、象形文字等,如何對其進行編碼、顯示、識別,一直是非常棘手的問題,解決方案不勝枚舉。緊隨文字處理技術的是辭書編纂系統,即利用計算機文字處理技術輔助人編纂各類人用辭書。這項研究國內外都已經開展多年,然而漢字處理仍然對辭書編纂系統研發和使用帶來挑戰。文章選擇多個有代表性的辭書編纂系統進行評估分析,指出它們目前存在的問題,同時提出解決方案。
關鍵詞:辭書編纂系統漢字編碼漢字處理挑戰解決方案
一、漢字處理標準
為使計算機能夠處理漢字,必須對漢字進行編碼。在計算機中使用漢字,涉及漢字的輸入、存儲、處理、交換、顯示、輸出等。根據使用目的的不同,漢字的編碼可以分為輸入碼、內碼、交換碼、字形碼等。(閆鴻濱2013)其中,內碼是漢字在計算機內部存儲、處理時使用的代碼,交換碼是用于漢字處理、漢字通信等系統之間信息交換的代碼。二者和漢字處理關系密切,有許多相關的編碼標準。
(一)國家編碼標準對漢字的處理
現行的漢字國家編碼標準有GB/T2312—1980、GB/T13000—2010、GB18030—2005等,以下分別簡稱GB2312、GB13000、GB18030。
GB2312(全稱為《信息交換用漢字編碼字符集·基本集》)于1980年3月9日發布,收錄了6763個簡體漢字,解決了大部分簡體漢字的計算機信息處理問題。《信息交換用漢字編碼字符集》除基本集外,還包括多個輔助集,對漢字簡體罕用字和偶用字,以及簡體字對應的繁體字進行擴展。完整的《信息交換用漢字編碼字符集》共收錄漢字近3萬個,但由于大量簡體字、繁體字字位一致/重疊,簡繁漢字不能共存,極大限制了輔助集的實際應用。此外,GB2312也不兼容任何國際編碼標準。
GB13000于2011年1月10日發布,收錄了世界上多種文字字符。其中,漢字包括中、日、韓(以下簡稱“CJK”)統一漢字擴展A和擴展B等區域,總數超過7萬個。GB18030于2005年11月8日發布,是漢字內碼的國家標準,向下與GB2312所對應的內碼兼容,收錄了GB13000.1—1993的全部CJK統一漢字和我國部分少數民族文字的字符,合計70244個漢字。GB13000和GB18030都參考、兼容同期國際編碼標準,繁體漢字和簡體漢字也分別使用不同字位,解決了國際標準兼容和簡繁漢字共存的問題。
(二)Unicode國際編碼標準對漢字的處理
Unicode編碼(又稱“萬國碼、國際碼、統一碼”)于1991年10月發布1.0.0版,2019年5月7日發布最新版12.1.0版。Unicode是國際編碼標準,在全球廣泛應用。Unicode的編碼體系包含128個組,每個組包含256個平面,每個平面包含256個行,每行包含256個字位。每個字符在編碼空間上的一個字位上進行編碼。Unicode收錄多國語言字符,其中88889個漢字主要在基本多文種平面(0號平面,碼值范圍為0000—FFFF)和表意文字補充平面(2號平面,碼值范圍為20000—2FFFF)進行編碼。更具體地,最常用漢字主要在0號平面的CJK基本區編碼,其他漢字在0號平面的CJK基本區擴展區、擴展A區及2號平面的擴展B—F區等區間進行編碼。
Unicode徹底避免了簡繁漢字無法共存的問題,在被廣泛應用的同時,也被國家標準兼容。例如GB13000、GB18030收錄的漢字范圍均等同于同期Unicode的漢字范圍,是新版Unicode收錄漢字范圍的子集。
(三)漢字編碼與辭書編纂系統的漢字處理
國內銷售的軟件系統都需要參考或執行漢字的國家編碼標準[1]。辭書編纂系統并非獨立存在,也依賴于操作系統、漢字輸入法等其他軟件系統,辭書編纂系統也應該支持國家編碼標準。
國外辭書編纂系統聲明支持國家標準的比較少,但幾乎全都聲明支持Unicode標準。通過對國家標準和Unicode標準的收字對比得知,如果一個編纂系統,完全支持Unicode標準,則它也完全可以支持現行國家標準所編碼的漢字。甚至,支持Unicode標準的辭書編纂系統可以比只支持國家標準的編纂系統處理更多的漢字。
辭書編纂系統對漢字處理水平直接反映了漢字編碼標準執行情況,但辭書編纂系統不僅僅是執行、使用各種漢字編碼標準的一般軟件系統,它是運用漢字編碼標準最充分的系統之一,是檢驗漢字編碼標準科學性、完備性最好的窗口之一。
二、國外五大系統概況
國外辭書編纂系統有許多,無法一一分析。本文選擇了5款具有代表性的國外辭書編纂系統,分別從系統研發單位、用戶群體、影響力、是否免費、編纂辭書種類、體系架構[2],以及特色功能等方面進行介紹。選擇這5款國外辭書編纂系統主要出于以下幾點考慮:
(1)選擇影響力大、用戶多、具有代表性的系統,同時兼顧系統功能設計及技術實現的多樣性。
(2)慎選長期沒有更新,疑似停止開發維護的辭書編纂系統。例如Glossword、Matapuna、MyVocabtionary、DictionarySystem等系統。此類系統一般都免費、開源,并且功能相對較少。
(3)不選尚未獲取系統副本或試用賬號的商用辭書編纂系統。例如IDMDPS、ABBYYLingvoContent、Lexonomy等系統。
(4)同一組織參與開發的,只選擇最有影響力的辭書編纂系統。例如FLEx、LexiquePro[3]和WeSay系統都由同一組織開發或參與開發[4],本文只選擇FLEx系統。
(5)不選完全沒有考慮支持漢語、漢字的辭書編纂系統。例如愛沙尼亞語辭書編纂系統EELex、捷克Symfonie公司開發的LEXIK系統等。EELex系統正在支持的單語、雙語辭書有50余個,沒有一個和漢語辭書有關。
此外,還有一些辭書編纂系統,除有關文獻外,找不到更多的系統信息,這類系統也不在本文選擇之列。例如荷蘭詞典研究所研發的INLDWS系統(Tiberiusetal2014)。
(一)TLex系統
TLex(又稱TshwaneLex)系統由南非TshwaneDJe公司研發,是商用軟件,被全球多家出版社、政府組織及個人采用,包括牛津大學出版社、培生朗文公司、加拿大司法部、馬來西亞語言與文化學院等。TLex可以編纂單語或多語辭書。TLex系統是一個專業、功能豐富、國際化、使用方便的辭書編纂系統,支持語料庫查詢,高級顯示樣式,條目字段自由定制,實時預覽,自動編號,自動索引,自動交叉引用,有多種輸出、排版、出版接口,支持團隊協作,支持XML、Unicode等各類工業標準。
TLex是C/S架構系統,同時也是單機版架構系統。不選擇任何遠程服務器(局域網或互聯網)的情況下,用戶也可以在本地打開/創建辭書項目,此時TLex可以作為功能獨立的單機版系統使用。
(二)FLEx系統
FLEx(FieldWorksLanguageExplorer的簡稱)系統開放源碼,允許任何人免費下載使用。FLEx在全球范圍內擁有廣泛的用戶群體。到目前為止,已經有270種語言的辭書借助FLEx輔助編纂。FLEx可以編纂單語或多語辭書,尤其適用于編纂少數民族語言辭書。FLEx包括詞庫、文本與詞、語法、筆記本、列表等五大功能模塊,支持語料庫自動分析、檢索,支持高級顯示樣式、條目字段自由定制、實時預覽、自動編號、自動正/逆向索引、自動交叉引用、語義領域列表、批量編輯操作,支持多種格式的辭書輸出。此外,SIL國際開發了辭書開發過程(DDPWebsite2017),成為一種新的辭書創建方法。FLEx系統也是辭書開發過程的一個典型實現。
與TLex系統類似,FLEx系統也是C/S架構系統兼單機版系統,用戶既可以在遠程服務器上創建、編纂辭書,也可以只在本地創建、編纂。
(三)Termbases系統
Termbases系統由愛沙尼亞WerkdataO公司設計開發,主要用于編纂術語辭書,但其開放的功能設計完全可以用于編纂普通的單語或多語辭書。Termbases系統采用當前主流Web開發技術開發,界面簡潔、操作友好、瀏覽器兼容性強。Termbases系統實現了多種格式的導入、導出,條目屬性字段自由定制,交叉引用等辭書編纂系統的核心功能。此外,Termbases系統還支持自定義主題分類樹,允許條目在該主題分類樹下有效組織。但是,Termbases系統未提供詳細的用戶操作手冊,更適用于具有熟練計算機操作技能的個人或小團隊編纂小型辭書使用。
Termbases系統是B/S架構系統,用戶需要連接互聯網使用。
(四)DEBWrite系統
DEB(DictionaryEditorandBrowser)系統是為捷克科學院捷克語研究所開發的一套通用辭書編纂平臺,由多個子程序組成。DEBWrite系統是DEB系統中相對獨立的一個部分,主要用于輔助辭書編纂。DEBWrite系統可免費注冊使用,采用開放標準研發。DEBWrite系統已被多個辭書項目采用,例如捷克布爾諾理工大學開發的《美術術語詞典》(Rambousek&Hork2015)、捷克國家民俗文化研究所開發的《捷克語英語民族學術語詞典》等。DEBWrite系統可以用于編纂單語或者多語辭書。
DEBWrite系統是B/S架構系統,可以快速創建、發布辭書。系統用戶分為管理員、編纂人員和普通用戶三種角色。DEBWrite系統支持條目字段自由定制、基于多模板的多樣式實時預覽、自動交叉引用,支持團隊協作,支持XML、Unicode等各類工業標準。除此之外,DEBWrite系統還支持圖片、音頻、視頻等多媒體附件的上傳與預覽。所以,借助DEBWrite系統可以輔助編纂多媒體辭書,這是DEBWrite系統的特點之一。
(五)Lacslann系統
Lacslann系統由愛爾蘭都柏林城市大學研發,旨在實現可以處理任意結構化數據集的通用的數據處理平臺。借助Lacslann系統,可以編纂管理地名數據庫、參考文獻數據庫、圖書目錄等,當然也可以編纂單語辭書、多語辭書等。例如,愛爾蘭國家術語數據庫就是借助Lacslann系統編纂管理。
Lacslann系統是B/S架構系統,采用微軟ASP.NET、C#等技術開發,系統穩定、兼容性好。Lacslann系統支持條目字段自由定制、自動交叉引用,支持團隊協作,支持XML、Unicode等各類工業標準。Lacslann系統允許定義多個線性分組,針對每個分組定義不同的條目字段及不同的字段屬性,每個條目都只能在一個分組下管理。Lacslann系統提供了強大的檢索功能,除支持針對整個條目內容的普通字符串檢索外,還支持針對條目每個自定義字段構建復合查詢條件的高級檢索,這對辭書版本修訂、專項核查等工作尤為有用。
三、國外五大系統的漢字處理功能與特點
(一)漢字錄入、存儲與顯示
TLex、FLEx、Termbases、DEBWrite、Lacslann等系統均支持Unicode標準,但未說明具體支持Unicode標準的哪個版本,或者說支持Unicode標準哪些平面、哪些區間的漢字。許多辭書編纂系統開發時都會選擇UTF8字符編碼表(Unicode標準的一種編碼方案),存儲0號平面字符會比存儲2號平面字符使用更少的存儲空間,但缺點是系統不能直接支持2號平面的漢字。除Unicode標準明確編碼的漢字外,還存在許多Unicode標準尚未編碼的漢字,下面分別討論。
1.Unicode標準明確編碼的漢字
TLex系統的預覽區無法同時顯示分屬不同字庫的漢字。FLEx系統支持0號平面漢字和2號平面漢字的錄入、存儲、檢索。但由于只支持一種字體,所以在條目編纂、列表、檢索、顯示等界面都無法同時顯示分屬不同字庫的漢字。由于Unicode支持的漢字數量超過單個字體文件所能編碼的字符個數,無法同時顯示分屬不同字庫的漢字意味著系統無法同時顯示Unicode標準的所有漢字。
Termbases系統支持0號平面漢字,不支持2號平面漢字。保存條目時,Termbases系統自動刪除第一個2號平面漢字及其之后的所有字符。例如保存條目“白豚”(其中“”是2號平面漢字,“白、豚”都是0號平面漢字),則實際只可以成功保存“白”,“”及其后面的“豚”均被自動刪除。DEBWrite系統支持0號平面漢字,對2號平面漢字的支持同樣存在缺陷。使用DEBWrite系統編纂條目時,條目一旦保存,重新編輯或者進入條目列表界面時系統就只能顯示這些漢字的HTML轉義形式,例如“”顯示為“𬶨”。DEBWrite系統無法保存包含HTML轉義字符的條目,只有將“𬶨”這樣的HTML轉義字符再改回漢字“”才可以再次保存。此外,DEBWrite系統條目的搜索、導入、導出等功能對2號平面漢字的支持也都存在類似問題。
Lacslann系統兼容性較好,可以完美支持0號平面漢字和2號平面漢字。
2.Unicode標準未明確編碼的漢字
漢語辭書中會收錄一些Unicode標準未明確編碼的漢字。例如《新華字典》第11版收錄了37個Unicode9.0標準沒有明確編碼的漢字,Unicode標準更新到12.1.0版時,CJK擴展F區新收錄了其中的17個,還有20個漢字尚未編碼,例如“、、、”等。TLex、FLEx、Termbases、DEBWrite、Lacslann等系統均沒有對Unicode標準未明確編碼的漢字的錄入、編輯、存儲、檢索、顯示、導入、導出等給出解決方案。
(二)漢字樣式設置
許多辭書編纂系統都支持條目樣式的設置,如字體、字號、顏色、加框等。對于整個條目字段,TLex、FLEx、DEBWrite等系統均支持復雜的樣式設置;Lacslann系統只支持簡單的樣式設置,包括字體顏色、字號、字形、字體粗細四種;Termbases系統不支持任何樣式設置。為整個條目字段設置樣式可以滿足大部分國外辭書條目的顯示需求。
為了正常顯示分屬不同字庫的漢字組成的多字條目,需要為一個條目字段設置不同的字體。此外,漢語有兒化現象,許多辭書使用小字號[5]的“兒”表示,例如“挨個兒、爆肚兒、板兒寸、豆瓣兒醬”等。這些都要求為同一條目字段設置不同的漢字樣式。TLex、FLEx、Termbases、Lacslann等系統均不支持為同一字段內的不同漢字設置不同的樣式。DEBWrite系統使用XSLT配置條目顯示模板,可以為同一字段設置不同漢字樣式。
(三)漢語條目輔助注音
標注條目讀音是漢語辭書的通常做法。條目讀音和是否輕重讀,是否可以插入其他成分,是否是專有名詞,是否兩讀等密切相關,條目讀音無法完全依賴系統自動標注,但編纂系統可以給出候選建議,供編纂人員參考。
TLex、FLEx、Termbases、DEBWrite、Lacslann等系統均不支持漢語條目自動注音。
(四)漢語條目自動排序
漢字的讀音、筆畫數、筆順、部件都可以作為漢語條目排序的參考依據。漢語條目的排序方式比字母文字語言條目的排序方式要多,算法也更加復雜。
TLex系統支持極為豐富的條目排序方式,包括漢字偏旁部首/筆畫數排序(先按漢字偏旁部首排序,偏旁部首排序相同的,再按筆畫數排序)、漢字拼音排序等。但是,TLex系統排序所需的漢字偏旁部首、筆畫數、拼音等資源無法修改和補充。如果辭書收錄的詞目用字超出系統內置資源范圍,條目將無法正常排序。除上述內置排序方式外,TLex系統還支持編寫腳本語言定制個性化的排序方式。
FLEx系統支持四種排序方式,其中參照某種語言排序規則的排序方式支持簡體中文,但它既不是單純的通過筆畫數和筆順排序,也不是完全的音序排序,漢語條目排序時會出現錯誤。FLEx系統還提供了兩種自定義的排序方式,均無法通過編寫少量規則實現條目自動排序。《彝漢英常用詞詞匯》是借助FLEx系統編纂的三語辭書,它對條目的漢語排序最終是通過編寫計算機后處理腳本輔助實現的。(Walters2009)
Termbases系統支持按照概念對條目進行分組,支持對條目每個字段的正序排序或逆序排序。DEBWrite系統同Termbases系統一樣,支持對某個字段的正序排序或逆序排序,但均未針對漢語條目排序進行任何優化。Lacslann系統只提供系統默認的唯一一種排序方式,不支持單一字段的正向、逆向排序。
(五)漢語條目內容自動檢查
條目內容需符合漢語語言文字規范標準,符合辭書選詞立目、釋義、配例的一般規律,針對辭書編纂目的及用戶群體特點進行有針對的規范、約定,避免各種類型的錯誤與問題。辭書編纂系統應該可以替代或輔助人工進行編纂內容的檢查。
FLEx系統在設置其文字系統時,可以設置合法字符、部分標點符號用法等。借助合法字符的設置可以自動檢查條目注解中是否包含不合法漢字,從而避免收錄表外字。借助標點符號用法的設置可以自動檢查漢語標點符號的部分錯誤用法,如括號是否匹配、單雙引號是否交替使用、同類括號是否嵌套等。除此之外,FLEx系統沒有更多針對漢語辭書的編纂內容自動檢查。
TLex、Termbases、DEBWrite、Lacslann等系統均不支持漢語條目內容的自動檢查。
四、國內五個系統的逆向局部檢測
國內研發的辭書編纂系統與國外辭書編纂系統相比更加封閉,難以獲取,但公開的辭書查詢系統很多。從技術的角度而言,辭書查詢系統和辭書編纂系統都涉及漢字的輸入、存儲、查詢、顯示等操作,是辭書編纂系統的重要組成部分和用戶使用辭書的接口。因此,對國內辭書查詢系統的分析可視為對國內辭書編纂系統的逆向局部分析。
(一)國內系統選擇
上海海笛數字出版科技有限公司(以下簡稱“海笛”)研制了諸多語種、上百款詞典及語言學習類手機數字產品,包括商務印書館的《新華字典》《新華大字典》,上海辭書出版社的《現代漢語規范字典》等權威辭書,在手機版辭書查詢系統方面具有代表性。
同方知網公司研制發行了《中國工具書網絡出版總庫》(以下簡稱《工具書庫》),集成了120余家出版社的9000余部工具書。此外,同方知網還采用同類技術制作了《商務印書館·精品工具書數據庫》《漢語大詞典》和《康熙字典》(知網版)等辭書庫,在網絡版辭書查詢系統方面具有代表性。
本文選擇海笛和同方知網兩家國內公司研制的5款具有代表性的辭書查詢產品進行分析,分別是海笛研制的《現代漢語規范字典》《新華大字典》《商務國際·現代漢語詞典》手機版,以及同方知網研制的《工具書庫》中的《學生新華字典》和《現代漢語大詞典》網絡版。
(二)測試漢字的選擇
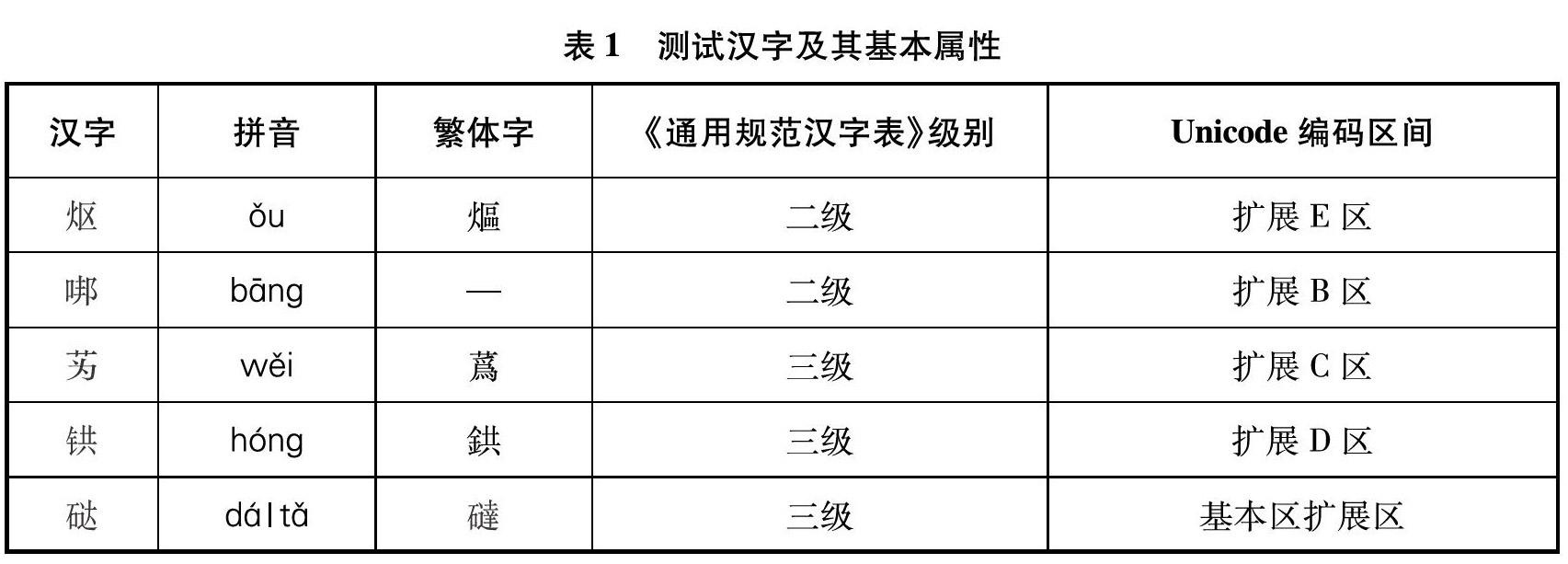
本文選擇測試漢字如表1所示:
測試漢字均源自《通用規范漢字表》(2013年國務院公布),包括2個二級字、3個三級字,均是Unicode擴展區間漢字,且分布于不同區間,是具有代表性且計算機不容易處理的漢字。
(三)國內辭書檢索系統對測試漢字的處理
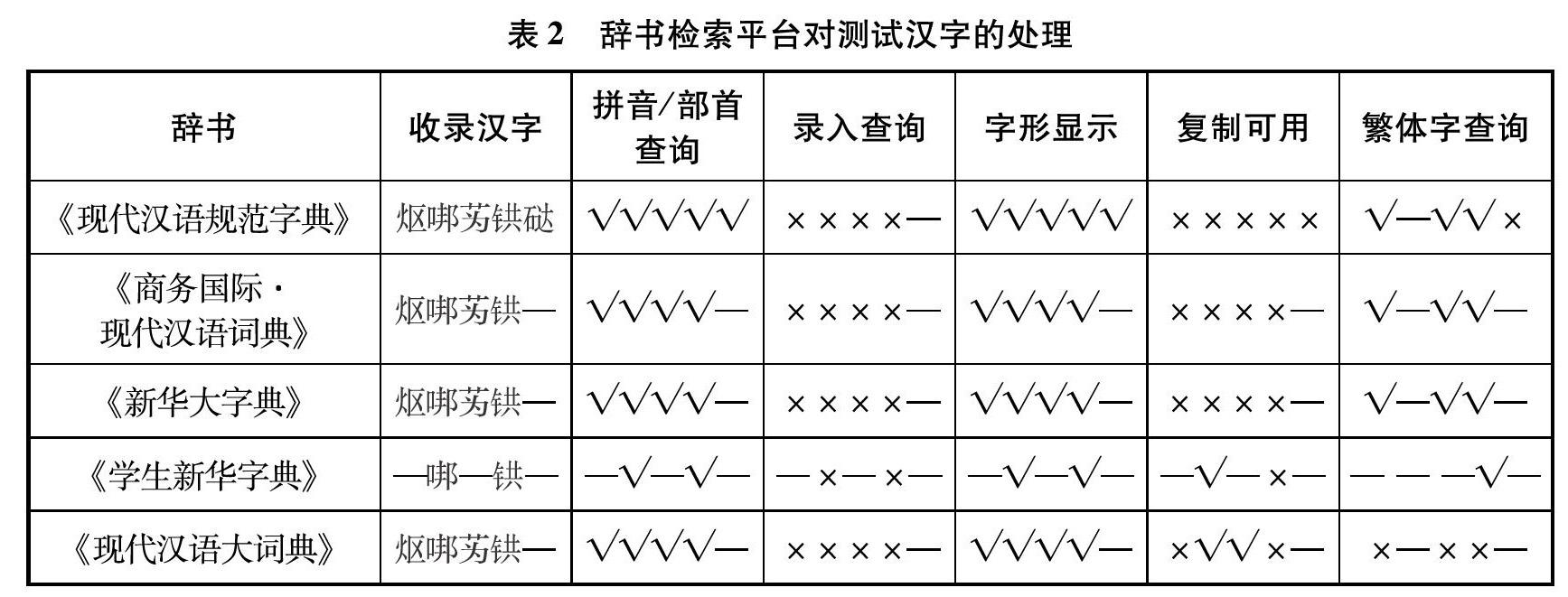
本文選擇收錄漢字、拼音/部首查詢、錄入查詢、字形顯示、復制可用、繁體字查詢等6個方面進行分析,處理結果如表2所示。其中,收錄漢字指辭書是否收錄該漢字;拼音/部首查詢指辭書是否可以通過拼音檢索或者部首檢索的方式查詢到該漢字;錄入查詢指在搜索框中直接輸入漢字,觀察是否可以得到正確的查詢結果;字形顯示指系統是否可以正確顯示所查漢字字形;復制可用指是否可以復制查詢出來的漢字并在辭書系統之外使用;繁體字查詢指是否可以通過查詢漢字對應的繁體字間接地查詢到該漢字。
通過表2不難看出,海笛公司研制的3款辭書產品在拼音/部首查詢、字形顯示、繁體字查詢方面處理得很好,但這5個測試漢字均無法錄入查詢,查詢結果也無法復制到系統之外使用。經過分析,海笛對5個測試漢字分別自定義編碼,同一漢字在不同辭書中的編碼也不相同。例如“”在3款辭書中的編碼分別是“ED79”“E1D1”“F52D”,“”在3款辭書中的編碼分別是“F346”“E026”“F4E2”。相同漢字在不同辭書中使用不同編碼,導致這些漢字在不同辭書之間也無法直接查詢參考。
同方知網研制的《工具書庫》可以通過拼音/部首檢索查詢到測試漢字并準確顯示漢字字形,但均無法通過直接錄入查詢到任意測試漢字,也無法通過查詢繁體字間接找到測試漢字。《工具書庫》中存在部分測試漢字未使用Unicode已有編碼,而采用了自定義編碼。比如《學生新華字典》中的“”編碼為“EC52”,《現代漢語大詞典》中的“”編碼為“E243”。自定義編碼的測試漢字可以顯示正確的字形,且在不同辭書間自定義編碼一致,但無法復制到辭書系統外部使用。
通過以上對國內兩大電子辭書產品研制公司的辭書查詢系統或者辭書產品的分析不難看出,國內辭書查詢系統對漢字的處理存在許多不足,國內辭書編纂系統應該也存在類似的不足。
五、改進方案
以下分別從系統研制者和使用者兩個視角給出更好處理漢字的解決方案。前者有助于編纂系統的改進,后者有助于辭書編纂人員選擇合適的編纂系統或者使用現有編纂系統時可以更好地處理漢字。
(一)支持漢字錄入、存儲與顯示
編纂系統初研或改版時,應選擇支持Unicode標準2號平面字符的開發語言、開發框架及數據庫等產品。
對于Unicode標準尚未編碼的漢字,編纂系統應該在自定義編碼區為這類漢字定義編碼,同時要保證系統內這些編碼的唯一性。此外,編纂系統還需要維護這類漢字的字模字庫(也可以是某種漢字描述語言描述的漢字信息)、字形結構、讀音、偏旁部首、筆畫數等信息。借助這些信息,編纂系統才可以支持這類漢字的查詢、輸入、處理及顯示等功能。此外,要加強與Unicode標準相關組織及表意文字小組的溝通,提供相關漢字信息,促成漢字被Unicode正式編碼。
對于Unicode標準已經編碼的漢字,也依然有許多漢字缺少輸入法、漢字字庫的支持。對于這類漢字,編纂系統可以采取與Unicode標準尚未編碼漢字類似的方式處理。只有這樣,本文第四節介紹的國內辭書產品的輸入查詢和漢字復制到系統外使用的問題才可以得到解決。
如果編纂系統無法改用支持Unicode標準2號平面漢字的技術,也可以使用漢字的HTML轉義形式。此時,編纂系統在處理漢字時需要準確識別2號平面漢字,并進行漢字與其HTML轉義形式的互相轉換。當Unicode標準發布新版本時,許多原Unicode標準未編碼的漢字被編碼。編纂系統應該不斷跟進Unicode標準編碼漢字的變化,做好與新編碼漢字的編碼轉換。
在漢字的輸入問題上,編纂系統應該提供單獨的漢字輸入模塊,用于輸入普通漢字輸入法無法輸入的漢字及Unicode標準尚未收錄的漢字。在漢字的顯示問題上,編纂系統應該可以為缺少字模字庫支持的漢字提供字模字庫,或者字形圖像,保證不同用戶在編纂、預覽、導出等階段看到的漢字字形完全一致。
對于編纂人員而言,選擇編纂系統時,辭書條目用字范圍(如是否需要收錄2號平面漢字),不同類型、不同Unicode平面漢字是否可以被輸入和顯示都應該是考慮因素。
(二)支持漢字樣式設置
為了顯示條目一個字段中分屬不同字庫的漢字,也為了正確顯示諸如兒化這樣的漢字格式,編纂系統應該可以支持為同一字段的內容設置不同的樣式,已定義的樣式應該可以復用在其他字段內容上。也就是說,樣式的最小應用單位不應該是條目字段,而應該是條目字段的某段文本內容。系統應該支持多種樣式,例如字體、字號、字重、加框、加圈、顏色等。
編纂人員選擇編纂系統時,首先需要確定辭書條目用字是否分屬不同字體文件。如果是,則只能選擇和DEBWrite一樣的系統。如果使用TLex、FLEx、Termbases、Lacslann等系統,就需要增加額外標記來標識不同樣式。例如,可以使用〈兒〉表示小字號的“兒”,使用“挨個〈兒〉”表示“挨個兒”。這種方案的缺點是會影響條目預覽的直觀效果。
(三)支持漢語條目自動注音
編纂系統應該可以根據詞目、詞性等信息自動注音。對于包含多音字的,應該可以給出候選讀音列表,并按音序或概率排列,也可以將其他辭書中的詞目讀音列為參考。有的辭書,如《新華字典》會同時對字頭標注拼音和注音,為簡化編纂人員工作、保證拼音與注音的一致性,編纂系統還應該支持拼音與注音的自動轉換。
需要指出,系統自動標注拼音時,應遵循《漢語拼音方案》(1958年由第一屆全國人民代表大會第五次會議批準頒布)、《漢語拼音正詞法基本規則》(2012年由國家質量監督檢驗檢疫總局、國家標準化管理委員會發布)等漢語拼音有關規范標準。辭書另行規定的,也要提供相應的擴展接口支持。
(四)支持漢語條目自動排序
編纂系統應該支持音序排序、部首排序和筆畫排序等多種排序方式。為實現這些排序方式,編纂系統應該管理每個漢字的讀音、部首部件、筆畫數、筆順等信息。編纂人員可以隨時修改上述信息,修改結果也可以及時反饋在排序結果上,不再需要人工干預。對于多字條目,編纂系統應該支持多字條目組成漢字及其讀音的自動切分、對齊,這是漢語條目自動排序的基礎。
如果編纂人員需要在編纂過程中實時查看排序結果,則應該優選TLex、FLEx等部分支持漢語條目排序的編纂系統。使用本文介紹的5款辭書編纂系統編完辭書后,通過編寫后處理腳本的方式來排序條目、驗證排序結果都是非常必要的。
(五)支持漢語條目內容自動檢查
編纂系統應該依據語言文字國家規范標準、行業規范對條目內容進行自動檢查。例如,自動檢查辭書中使用的標點符號是否符合《標點符號用法》(2011年由國家質量監督檢驗檢疫總局、國家標準化管理委員會發布)、《夾用英文的中文文本的標點符號用法(草案)》(2014年由國家語言文字工作委員會發布),用字是否使用了漢字的舊字形、是否落實了《通用規范漢字表》,用詞是否使用了《第一批異形詞整理表》(2001年由教育部、國家語言文字工作委員會發布)中規定的不推薦詞形,等等。除落實規范標準外,辭書還可能有特殊的檢查需求。例如,編纂中小學學生使用的辭書時,注解用詞需參考中小學教學大綱和中小學學習詞表。目前,受制于語言信息處理技術的限制,基于字符匹配的條目內容自動檢查是可行的,更深層的句法、語義、語用等自動檢查還難以實用化,這也是條目內容自動檢查的發展方向。
為實現編纂內容的自動檢查,編纂系統需維護漢語各類規范標準、字表、詞表、教學大綱等語言資源,同時還要支持這些資源的動態更新。
六、結語
漢字數量巨大,編碼標準不斷修訂,屬性多樣,自動化算法復雜,這些特點對辭書編纂系統提出了更高的要求和更大的挑戰。許多國外辭書編纂系統旨在支持多國語言辭書的編纂,在漢字處理上存在許多不足。通過國內辭書查詢系統的逆向局部檢測發現國內辭書編纂系統在漢字處理問題上也存在類似的不足。為更好地支持漢語辭書編纂與應用,這些辭書編纂系統、查詢系統需進一步優化漢字處理。辭書編纂人員可以結合所編辭書收字、收詞、體例要求選擇最合適的辭書編纂系統,也可以采用多種變通方法彌補系統在漢字處理方面的不足。
附注
[1]GB2312,GB13000曾經都是強制性的或者部分強制性的,自2017年3月20日起,都轉化為推薦性標準,不再強制執行。GB18030中的單字節編碼部分、雙字節編碼部分和四字節編碼部分的CJK統一漢字擴展A區部分為強制性,其余為推薦性的。對于CJK統一漢字擴展BF區的漢字如何處理,國家標準并未給出強制規定。
[2]體系架構指編纂系統是單機版架構、C/S(Client/Server,客戶端服務器)架構、還是B/S(Browser-Server,瀏覽器服務器)架構。其中,單機版架構的系統可以獨立安裝在用戶個人電腦里,無需連網就可以使用系統全部功能。C/S架構的系統安裝在用戶個人電腦里,有部分功能必須借助互聯網才能實現。B/S架構的系統不需要在用戶個人電腦里安裝任何軟件,用戶只需通過通用瀏覽器就可以使用系統的全部功能,全部數據存儲在服務器端。C/S架構和B/S架構的系統更適用于團隊協作和編纂更大規模的辭書。
[3]LexiquePro系統的漢語名稱為辭書寶。
[4]FLEx由SIL國際(SIL最初是SummerInstituteofLinguistics的簡稱,現在SIL稱為SIL國際,被大家所熟知)開發,LexiquePro系統由SIL馬里開發,WeSay系統由Payap軟件開發組織、SIL巴布亞新幾內亞以及SIL國際合作開發。
[5]這里的小字號是相對于條目中其他正常的漢字字號而言的。
[6]海詞研制了20多個語種詞典及80多個行業詞典的手機程序,包括商務印書館的《新華字典》《新華大字典》,上海辭書出版社的《現代漢語規范字典》等權威辭書,在基于手機程序的辭書出版方面具有代表性。
[7]同方知網公司研制發行了《中國工具書網絡出版總庫》(簡稱《知網工具書庫》),集成了近200家知名出版社的近7000冊工具書。此外,同方知網還采用同類技術制作了《商務印書館·精品工具書數據庫》《漢語大詞典》和《康熙字典》知網版等辭書庫,在網絡電子圖辭書出版方面具有代表性。
參考文獻
1.華燁,李亮.國際計算機輔助詞典編纂系統管窺.辭書研究,2012(5).
2.亢世勇,王興隆,謝曉艷.我國計算機輔助詞典編纂系統初步調查研究.辭書研究,2012(3).
3.李開編著.現代詞典學教程.南京:南京大學出版社,1990.
4.閆鴻濱主編.計算機科學技術概論.北京:清華大學出版社,2013:44.
5.張效祥主編.計算機科學技術百科全書(第2版).北京:清華大學出版社,2005.
6.中國標準出版社.信息交換用漢字編碼字符集·基本集.北京:中國標準出版社,1981.
7.中國社會科學院語言研究所詞典編輯室編.現代漢語詞典(第7版).北京:商務印書館,2016.
8.中國社會科學院語言研究所編.新華字典(第11版).北京:商務印書館,2011.
9.RambousekA,HorkA.DEBWrite:FreeCustomizableWeb-basedDictionaryWritingSystem.ElectronicLexicographyinthe21stCentury:LinkingLexicalDataintheDigitalAge.ProceedingsoftheeLex2015Conference.Trojina,InstituteforAppliedSloveneStudies/LexicalComputingLtd.,2015.
10.TiberiusC,NiestadtJ,SchoonheimT.TheINLDictionaryWritingSystem.SlovencˇinaEmpiricˇneAplikativneinInterdisciplinarneRaziskave,2014,2(2).
11.WaltersD.FromDatabasetoPublication:ToolsforTypesettingaThree-languageDictionary.SILForumforLanguageFieldwork.2009(3).
12.GB13000.1—1993.信息技術通用多八位編碼字符集(UCS)第一部分:體系結構與基本多文種平面.
13.GB18030—2000.信息技術信息交換用漢字編碼字符集·基本集的擴充.
14.GB18030—2005.信息技術中文編碼字符集.
15.GB/T13000—2010.信息技術通用多八位編碼字符集(UCS).
16.GB/T2312—1980.信息交換用漢字編碼字符集·基本集.
17.ABBYYLingvoContent系統網站.http:∥www.abbyy.cz/products/smb_enterprise/dictionary_writing_system/(accessed:16/03/2017).
18.DDPWebsite.DicationaryDevelopmentProcess.http:∥www.sil.org/dictionaries-lexicography/dictionary-development-process(accessed:01/01/2020).
19.DEBWrite系統網站.https:∥abulafia.fi.muni.cz:9050/(accessed:24/03/2017).
20.DEB系統網站.http:∥deb.fi.muni.cz/(accessed:23/03/2017).
21.DictionarySystem系統網站.http:∥dictionary-system.hvalur.org/(accessed:07/04/2017).
22.EELex系統網站.http:∥eelex.eki.ee/(accessed:15/03/2017).
23.FLEx系統網站.http:∥fieldworks.sil.org/(accessed:15/03/2017).
24.Glossword系統網站.http:∥glossword.biz/(accessed:17/04/2017).
25.IDMDPS系統網站.http:∥www.idmgroup.com/(accessed:18/03/2017).
26.Lacslann系統網站.http:∥lxln.prettydata.eu/(accessed:25/03/2017).
27.LEXIK系統網站.http:∥www.lex-ik.cz/(accessed:16/04/2017).
28.LexiquePro系統網站.http:∥www.lexiquepro.com/(accessed:04/03/2017).
29.Lexonomy系統網站.http:∥www.lexonomy.eu/(accessed:16/04/2017).
30.Matapuna系統網站.https:∥sourceforge.net/projects/matapuna/(accessed:06/04/2017).
31.MyVocabtionary系統網站.https:∥sourceforge.net/projects/phpvocabtionary/(accessed:06/04/2017).
32.Termbases系統網站.http:∥www.termbases.eu/(accessed:01/04/2017).
33.TLex系統網站.http:∥tshwanedje.com/cn/(accessed:14/03/2017).
34.WeSay系統網站.http:∥wesay.palaso.org/(accessed:15/03/2017).
(中國社會科學院語言研究所/辭書編纂研究中心北京100732)
(責任編輯 郎晶晶)
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
當代陜西(2019年8期)2019-05-09 02:22:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
