基于大數(shù)據(jù)分析的網(wǎng)絡(luò)資源缺失信息碎片智能識(shí)別方法
2019-11-07 02:49:58李田英
李田英
基于大數(shù)據(jù)分析的網(wǎng)絡(luò)資源缺失信息碎片智能識(shí)別方法
李田英
商丘醫(yī)學(xué)高等專科學(xué)校現(xiàn)代教育技術(shù)中心, 河南 商丘 476100
針對(duì)傳統(tǒng)網(wǎng)絡(luò)資源缺失信息碎片識(shí)別方法中識(shí)別準(zhǔn)確度較低、完成時(shí)間較長(zhǎng)、能量消耗較大等問題,提出一種基于大數(shù)據(jù)分析的網(wǎng)絡(luò)資源缺失信息碎片識(shí)別方法。通過對(duì)網(wǎng)絡(luò)資源信息分析,利用非線性時(shí)間序列對(duì)網(wǎng)絡(luò)資源不完整信息進(jìn)行相空間重建,引入關(guān)聯(lián)維數(shù)對(duì)網(wǎng)絡(luò)資源不完整信息特征提取;考慮到不完整信息特征中缺失信息碎片對(duì)信息類別的貢獻(xiàn)度,利用信息熵來衡量缺失信息碎片之間的差異,利用以BP神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)的集成分類器對(duì)缺失信息碎片分類,完成缺失信息碎片識(shí)別。結(jié)果表明,所提方法識(shí)別準(zhǔn)確度較高、完成時(shí)間較短、能量消耗較小。
大數(shù)據(jù)分析; 網(wǎng)絡(luò)資源; 缺失信息; 智能識(shí)別
計(jì)算機(jī)網(wǎng)絡(luò)技術(shù)的快速發(fā)展,大量的網(wǎng)絡(luò)資源迅速增長(zhǎng),大數(shù)據(jù)分析技術(shù)應(yīng)運(yùn)而生,成為網(wǎng)絡(luò)資源獲取、處理、分析或可視化的有效手段[1]。從網(wǎng)絡(luò)資源大數(shù)據(jù)中發(fā)現(xiàn),實(shí)際應(yīng)用的大部分?jǐn)?shù)據(jù)分布是不完整的,在進(jìn)行不完整網(wǎng)絡(luò)資源信息識(shí)別時(shí),常會(huì)遇到信息碎片問題,這些信息碎片通常被放置在網(wǎng)絡(luò)存儲(chǔ)介質(zhì)的隱蔽位置,且內(nèi)部信息已遭到損壞[2,3],現(xiàn)階段應(yīng)用的碎片智能識(shí)別方法普遍存在著識(shí)別準(zhǔn)確度較低、完成時(shí)間較長(zhǎng)、能量消耗較大等問題。在此背景下,如何有效提高網(wǎng)絡(luò)資源信息缺失信息識(shí)別精度和效率,成為當(dāng)今社會(huì)亟待解決的問題[4,5]。文獻(xiàn)[6]提出一種基于譜回歸特征降維后神經(jīng)網(wǎng)絡(luò)資源信息的識(shí)別方法。該方法對(duì)網(wǎng)絡(luò)資源信息進(jìn)行特征提取,將提取后的結(jié)果進(jìn)行降維處理,把降維后的網(wǎng)絡(luò)資源信息輸入到BP神經(jīng)網(wǎng)絡(luò)分類器中進(jìn)行識(shí)別。該方法具有較高的識(shí)別準(zhǔn)確度,但是識(shí)別完成時(shí)間較長(zhǎng)。文獻(xiàn)[7]提出一種基于含缺失信息屬性值的數(shù)據(jù)識(shí)別方法。該方法根據(jù)不同缺失信息屬性設(shè)計(jì)出不同的檢測(cè)方法,利用相應(yīng)的檢測(cè)方法對(duì)缺失信息進(jìn)行修復(fù)和補(bǔ)充,完成對(duì)缺失信息有效識(shí)別。該方法識(shí)別完成時(shí)間較短,但是識(shí)別準(zhǔn)確度較低。針對(duì)上述問題,提出一種基于大數(shù)據(jù)分析的網(wǎng)絡(luò)資源缺失信息碎片識(shí)別方法。實(shí)驗(yàn)結(jié)果表明,所提方法識(shí)別準(zhǔn)確度較高、完成時(shí)間較短、能量消耗較小。
1 方法
1.1 網(wǎng)絡(luò)資源不完整信息特征提取
通過對(duì)網(wǎng)絡(luò)資源信息進(jìn)行分析,利用非線性時(shí)間序列對(duì)網(wǎng)絡(luò)資源不完整信息進(jìn)行相空間重建,引入關(guān)聯(lián)維數(shù)對(duì)網(wǎng)絡(luò)資源不完整信息特征進(jìn)行提取,具體過程如下所述:
網(wǎng)絡(luò)資源不完整信息一般都是沒有明顯規(guī)律和順序的,利用關(guān)聯(lián)維數(shù)對(duì)其進(jìn)行分析,實(shí)現(xiàn)網(wǎng)絡(luò)資源不完整信息特征提取。
假設(shè),不完整網(wǎng)絡(luò)資源信息一維時(shí)間序列為{1,2,…,q},利用下式給出不完整信息重建的相空間表達(dá)式:

式中,代表網(wǎng)絡(luò)資源信息重建時(shí)延,代表網(wǎng)絡(luò)資源信息維數(shù)。
關(guān)聯(lián)維數(shù)是不完整網(wǎng)絡(luò)資源信息在多維空間中疏密程度的表現(xiàn),代表網(wǎng)絡(luò)資源不完整信息樣本之間的關(guān)聯(lián)程度。對(duì)網(wǎng)絡(luò)資源不完整信息進(jìn)行相空間重構(gòu),得到一個(gè)相空間矢量,將網(wǎng)絡(luò)資源不完整信息的任意兩個(gè)矢量的最大分量看作成兩者之間的距離,利用公式(2)對(duì)其進(jìn)行描述:
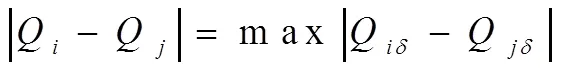
假設(shè)兩者之間的距離低于設(shè)定正整數(shù)的矢量被叫作關(guān)聯(lián)矢量,不完整網(wǎng)絡(luò)資源信息重建相空間中存在著個(gè)信息點(diǎn),獲取不完整信息相關(guān)矢量對(duì)數(shù),將所有存在相關(guān)矢量對(duì)數(shù)的這種情況當(dāng)作關(guān)聯(lián)積分:
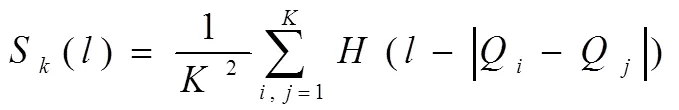
式中,代表Heaviside函數(shù),利用公式(4)給出該函數(shù)的表達(dá)式:

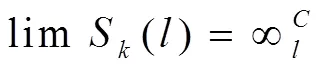
式中,代表不完整網(wǎng)絡(luò)資源信息關(guān)聯(lián)維數(shù)。選擇合理的,使可以用來表示網(wǎng)絡(luò)資源不完整信息混沌吸引子的相似結(jié)構(gòu),則近似值為:
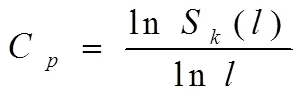
標(biāo)準(zhǔn)差是網(wǎng)絡(luò)資源不完整信息樣本點(diǎn)的分散程度。當(dāng)不完整網(wǎng)絡(luò)資源信息樣本在標(biāo)準(zhǔn)差較大的情況下,不同的資源信息樣本與實(shí)際值差別較大,則在空間中分布不集中,相應(yīng)的關(guān)聯(lián)維數(shù)不高。結(jié)合此特性利用下式對(duì)網(wǎng)絡(luò)資源不完整信息特征進(jìn)行提取:
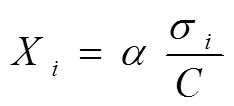
1.2 基于集成分類器的缺失信息碎片識(shí)別
以網(wǎng)絡(luò)資源不完整信息特征提取為依據(jù),考慮到不完整信息特征中樣本缺失信息對(duì)信息類別的貢獻(xiàn)度,利用信息熵來衡量缺失信息之間的差異,以BP神經(jīng)網(wǎng)絡(luò)為基礎(chǔ)的集成分類器對(duì)缺失信息進(jìn)行分類,完成識(shí)別。具體過程如下:根據(jù)不完整信息特征中樣本缺失信息集進(jìn)行劃分,得到多個(gè)互相之間沒有任何關(guān)系的缺失信息子集,為了更大限度的利用原始的網(wǎng)絡(luò)資源信息,需要把缺失信息樣本存入相對(duì)應(yīng)的網(wǎng)絡(luò)資源信息中。
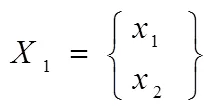
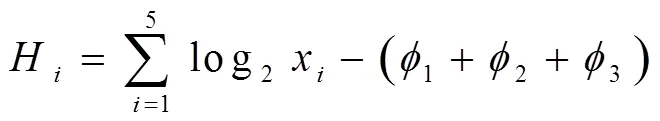
其中,碎片子集1的缺失信息為1,2中缺失信息集為2,3中缺失信息集為3。在此基礎(chǔ)上,根據(jù)信息熵計(jì)算網(wǎng)絡(luò)資源信息權(quán)值為:

利用網(wǎng)絡(luò)資源信息權(quán)值的集成結(jié)果實(shí)現(xiàn)對(duì)網(wǎng)絡(luò)資源缺失信息碎片進(jìn)行分類識(shí)別。
2 仿真實(shí)驗(yàn)與結(jié)果分析
為了驗(yàn)證所提基于大數(shù)據(jù)分析的網(wǎng)絡(luò)資源缺失信息碎片識(shí)別方法的綜合性能,設(shè)計(jì)如下實(shí)驗(yàn)。實(shí)驗(yàn)操作系統(tǒng)為Windows7,內(nèi)存48 g。為保證實(shí)驗(yàn)結(jié)果的有效性,將所提方法(方法1)與基于譜回歸特征降維后神經(jīng)網(wǎng)絡(luò)資源信息的識(shí)別方法(方法2)和基于含缺失信息屬性值的數(shù)據(jù)識(shí)別方法(方法3)。對(duì)比3種方法的識(shí)別準(zhǔn)確度(%)實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表1所示。

表1 不同方法識(shí)別準(zhǔn)確度對(duì)比
分析表1可知,3種方法都隨著網(wǎng)絡(luò)資源缺失信息數(shù)量的不斷增加,識(shí)別準(zhǔn)確度會(huì)有不同程度的降低。當(dāng)缺失信息數(shù)量為5個(gè)時(shí),方法2和方法3的識(shí)別準(zhǔn)確度與所提方法識(shí)別準(zhǔn)確度之間分別相差1.86%和3.66%。當(dāng)缺失信息數(shù)量為35個(gè)時(shí),方法2和方法3的識(shí)別準(zhǔn)確度與所提方法識(shí)別準(zhǔn)確度之間分別相差1.70%和4.21%。但所提方法的識(shí)別準(zhǔn)確度最高,一直保持在99%以上。對(duì)3種方法進(jìn)行網(wǎng)絡(luò)資源缺失信息識(shí)別完成時(shí)間比較,結(jié)果如圖1所示。

圖1 不同方法識(shí)別完成時(shí)間對(duì)比圖
分析圖1可知,隨著缺失信息數(shù)量增加,3種方法識(shí)別完成的時(shí)間增減增加。當(dāng)網(wǎng)絡(luò)資源缺失信息數(shù)量從0個(gè)增加到400個(gè)時(shí),所提方法識(shí)別完成時(shí)間一直在33 s~37 s之間浮動(dòng),方法2的識(shí)別完成時(shí)間一直在35 s~50 s之間浮動(dòng),方法3的識(shí)別完成時(shí)間一直在44 s~58 s之間浮動(dòng)。相比之下所提方法的識(shí)別完成時(shí)間最短。對(duì)比3種方法進(jìn)行缺失信息識(shí)別的能量消耗情況如表2所示。

表2 不同方法識(shí)別能量消耗對(duì)比
表2可知,隨著網(wǎng)絡(luò)資源缺失信息數(shù)量的不斷增加,3種方法的識(shí)別能量消耗也隨之增加。當(dāng)缺失信息數(shù)量從8個(gè)增加到48個(gè)時(shí),識(shí)別能量消耗相差414 J;方法2識(shí)別能量消耗相差529 J;方法3識(shí)別能量消耗相差821 J。實(shí)驗(yàn)結(jié)果表明,所提方法識(shí)別能量消耗最低,具有一定的應(yīng)用價(jià)值。
3 結(jié)語
針對(duì)網(wǎng)絡(luò)資源中存在的信息碎片缺失的問題,提出一種基于大數(shù)據(jù)分析的網(wǎng)絡(luò)資源缺失信息碎片識(shí)別方法。該方法與傳統(tǒng)方法相比較,具有較高的識(shí)別準(zhǔn)確度,并且識(shí)別的完成時(shí)間相對(duì)較短,能量消耗較小,可廣泛應(yīng)用于各個(gè)領(lǐng)域。
[1] 王志鵬,王星,田元榮,等.基于壓縮感知的輻射源信號(hào)數(shù)據(jù)級(jí)融合識(shí)別方法[J].兵工學(xué)報(bào),2017,38(8):1547-1554
[2] 王鋒,武龍,吳東升,等.脈沖風(fēng)洞天平短時(shí)振蕩測(cè)力數(shù)據(jù)穩(wěn)態(tài)值提取的優(yōu)化識(shí)別方法[J].振動(dòng)與沖擊,2018,37(8):153-157
[3] 邱建青,杜春霖,周婷,等.多變量數(shù)據(jù)缺失機(jī)制的識(shí)別方法[J].中國(guó)衛(wèi)生統(tǒng)計(jì),2017,34(6):1002-1005
[4] 陶江玥,劉麗娟,龐勇,等.基于機(jī)載激光雷達(dá)和高光譜數(shù)據(jù)的樹種識(shí)別方法[J].浙江農(nóng)林大學(xué)學(xué)報(bào),2018,35(2):314-323
[5] 陳虹君,羅福強(qiáng),趙力衡,等.大數(shù)據(jù)下網(wǎng)絡(luò)資源信息丟失優(yōu)化識(shí)別仿真[J].計(jì)算機(jī)仿真,2017,34(9):358-361
[6] 鄔戰(zhàn)軍,牛敏,許冰,等.基于譜回歸特征降維與后向傳播神經(jīng)網(wǎng)絡(luò)的識(shí)別方法研究[J].電子與信息學(xué)報(bào),2016,38(4):978-984
[7] 高科,刁興春,曹建軍.含缺失屬性值的問題數(shù)據(jù)檢測(cè)與修復(fù)[J].計(jì)算機(jī)工程與設(shè)計(jì),2016,37(3):643-649
An Intelligent Identification Method for Missing Information Fragments of Network Resources Based on Big Data Analysis
LI Tian-ying
476100,
Aiming at the traditional network resource missing information fragment identification method, there are generally problems such as low recognition accuracy, long completion time and large energy consumption. This paper proposes a method for identifying missing information fragments of network resources based on information entropy and integrated classification. By analyzing the network resource information, the nonlinear spatial time series is used to reconstruct the incomplete information of the network resources, and the correlation dimension is introduced to extract the incomplete information features of the network resources, taking into account the information of the missing information in the incomplete information features. The contribution of categories, using information entropy to measure the difference between missing information, the BP neural network-based integrated classifier classifies the missing information and completes the identification. The experimental results show that the proposed method has higher recognition accuracy, shorter completion time and less energy consumption.
Big data analysis; network resource; missing information; intelligent identification
TP311.13
A
1000-2324(2019)05-0870-03
10.3969/j.issn.1000-2324.2019.05.029
2018-09-25
2018-10-08
2015年河南省醫(yī)學(xué)教育研究項(xiàng)目:依托網(wǎng)絡(luò)專題教育社區(qū)的醫(yī)學(xué)超聲診斷技術(shù)教學(xué)模式改革的探索(Wjlx2015170)
李田英(1982-),女,碩士,講師,主要研究方向?yàn)橛?jì)算機(jī)科學(xué)與技術(shù)及網(wǎng)絡(luò)安全. E-mail:lty_1218@126.com
猜你喜歡
當(dāng)代陜西(2021年17期)2021-11-06 03:21:36
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
中華手工(2017年2期)2017-06-06 23:00:31
讀者(2017年5期)2017-02-15 18:04:18
中國(guó)教育技術(shù)裝備(2016年15期)2016-03-01 02:46:18
新教育時(shí)代電子雜志(學(xué)生版)(2015年31期)2015-12-20 08:29:22
中外會(huì)展(2014年4期)2014-11-27 07:46:46
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:25
當(dāng)代修辭學(xué)(2011年2期)2011-01-23 06:39:12
祝您健康(1987年3期)1987-12-30 09:52:32
