基于python的網絡爬蟲系統的設計與實現
2019-11-03 14:07:16蔡振海張靜
電腦知識與技術 2019年23期
蔡振海 張靜


摘要:隨著大數據和人工智能的火熱,編程語言Python的熱度也迅速攀升,在各大編程語言排行榜中位居榜首。越來越多的人想了解和學習Python語言。該文從Python的安裝,常用庫(Requests)的安裝、使用,網頁爬蟲通用代碼框架的構造來介紹Python的特點。使感興趣者更加容易了解和使用Python。
關鍵詞:Python;網頁爬蟲
中圖分類號:TP393? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2019)23-0036-02
開放科學(資源服務)標識碼(OSID):
Design and Implementation of a Web Crawler System Based on Python
CAI Zhen-hai1, ZHANG Jing2
(1.Jiangsu Vocational Institute of Commerce, Nanjing 211100,China; 2. Nanjing Technical Vocational College, Nanjing 211100, China)
Abstract:With the popularity of big data and artificial intelligence, the programming language Python is also rapidly rising, ranking first in the list of major programming languages. More and more people want to know and learn Python. This paper introduces the characteristics of Python from the installation of Python, the installation and use of common libraries (Requests), and the construction of common code framework for web crawlers.Making it easier for interested people to understand and use Python.
Key words: Python; Web crawler
近年來,Python語言迅速崛起,其簡潔、免費、易學習、兼容性好等特點以及其面向對象、函數式編程、過程編程、面向方面編程,受到眾人的喜愛【1】。Python是一種廣泛使用的腳本語言,它自身帶有requests等爬蟲的基礎庫,尤其是Python在人工智能領域的優勢,使得其戰略地位迅速提升【2】。教育部公布的《2019年教育信息化和網絡安全工作要點》透露:今年將啟動中小學生信息素養測評,并推動在中小學階段設置人工智能相關課程,逐步推廣編程教育,也將編制《中國智能教育發展方案》。了解、學習、使用Python語言是成為相關領域人才的必經之路。
1 網頁爬蟲的設計
網頁爬蟲通過一定的規則自動從眾多的網絡資源中爬取所需信息,它通過模仿瀏覽器對網頁的URL地址訪問的方式,不需要人工操作即可獲得所需數據【3】。通過安裝相關軟裝和庫,即可實現簡單的網頁爬蟲功能。
1.1 Python的安裝
目前Python的版本已經更新到3.X,登錄Python官網,根據操作系統選擇相應的版本下載。本文以3.7.2版本為例在Windows操作系統上進行介紹。下載后執行Python安裝可執行文件,選擇安裝目錄,同時一定要記住在安裝界面勾選Add Python 3.7.2 to PATH選項,否則在使用時會報錯。
安裝成功后,打開命令提示符窗口,輸入Python后回車,當界面顯示Python版本號,則表明Python安裝成功。
1.2 requests的安裝
為了爬取網頁內容,需要安裝requests庫。以管理員身份運行命令提示符窗口,輸入PiP install requests后回車,系統會執行安裝requests庫操作,當出現Successfully installed requests-2.21.0時,表示requests庫安裝成功。在使用時,需要輸入import requests引入該庫。
1.3 網頁的爬取
安裝好Python和requests庫后,就可以實現簡單的網頁爬取功能。本文主要使用requests庫中的一個非常重要的get()方法。該方法能構造一個向服務器請求資源的Request對象,并將響應對象返回,該對象是ResPonse類型。我們可以通過響應的對象所攜帶的數值來判斷請求是否成功,若值為200,則表明請求成功,否則表示失敗,當然也能通過返回的具體的數值來判斷失敗的原因。在使用get()方法時,需要向其傳遞參數,最重要的就是URL參數,即:所要爬取的網頁的鏈接。該方法還有其他可選參數,可根據實際情況進行選擇。
若要顯示所爬取網頁的信息,需要用到ResPonse的text屬性,該屬性是HTTP響應內容的字符串形式,即:get()方法中傳入的參數URL所對應的頁面。在進行網絡連接時,通常會出現異常,通過raise_for_status()進行異常處理。同時為了正確顯示網頁內容,還需對網頁編碼進行修改,以免發生亂碼情況。網頁爬取的偽代碼如下:
1 導庫,將需要使用的requests庫引入
2 確定需要爬取的網頁URL
3 requests.get(URL)——>Result? ?//將爬取的對象返回
4 異常處理
5 utf-8——Result.encoding? ? ?//采用utf-8編碼,避免出現亂碼
6 打印網頁內容
1.4 網頁爬蟲的具體實現
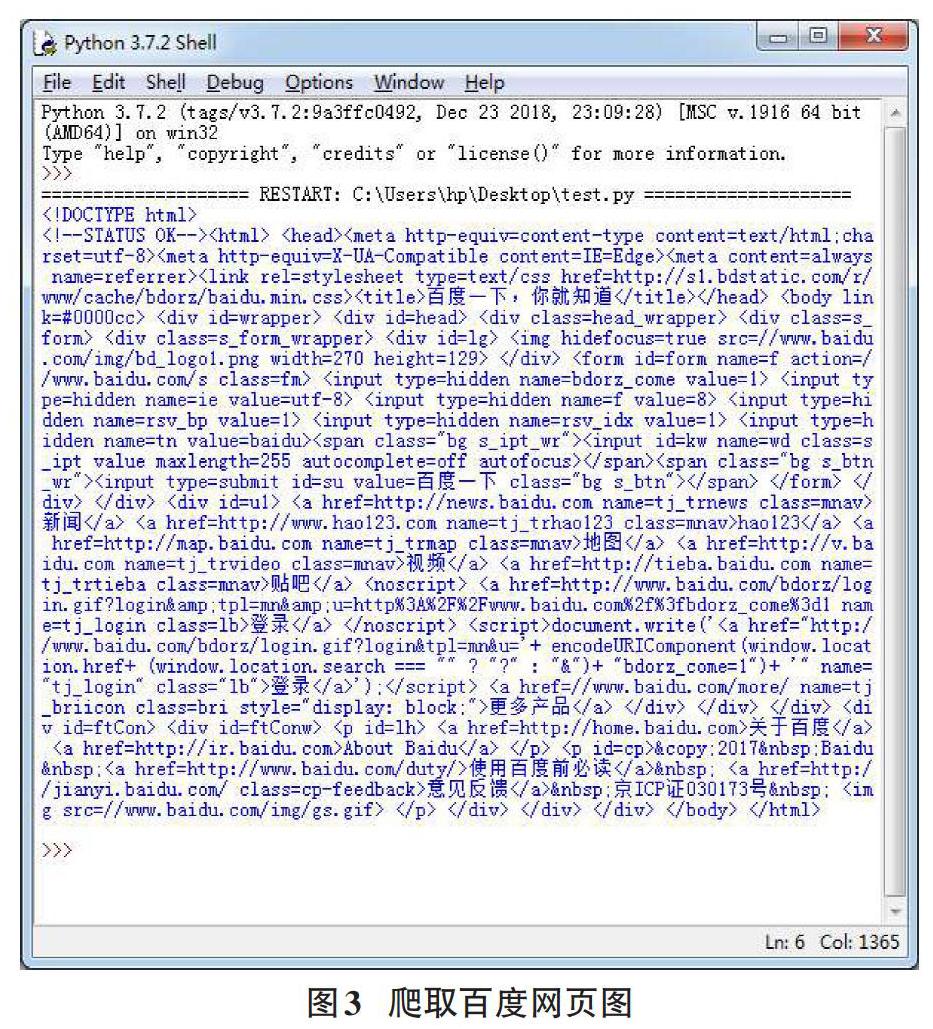
首先定義帶參的頁面爬取函數,該函數通過requests庫的get()函數爬取所需頁面內容,同時在該函數中做了異常處理,防止程序出現意外情況。并將編碼方式設為可輸出中午形式的utf-8形式。其次主函數中將結果進行打印輸出。具體代碼和如結果如下圖所示:
2 結束語
本文通過對Python及requests庫的安裝和使用完成了簡單網頁的爬取功能的實現,通過對實際頁面爬取的操作,加深了對Python的理解,提升了學習Python的興趣。本文只是簡單的實現了頁面的爬取,對于Python強大的數據爬取功能將會在后期的文章中進行詳細介紹。
參考文獻:
[1] 仇明. 基于Python的圖片爬蟲的程序設計[J]. 工業技術與職業教育, 2019(3).
[2] 賈棋然. 基于Python專用型網絡爬蟲的設計及實現[J]. 電腦知識與技術, 2017(12).
[3] 李琳. 基于Python的網絡爬蟲系統的設計與實現[J]. 信息通信, 2017(9).
【通聯編輯:唐一東】
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
西安航空學院學報(2022年2期)2022-07-04 07:45:42
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
南風窗(2016年19期)2016-09-21 16:51:29
南風窗(2016年19期)2016-09-21 04:56:22
電腦愛好者(2011年11期)2011-06-22 08:20:18
