基于知識圖譜的高校數字檔案資源數據知識化實現
2019-10-21 06:41:09李菁黃仁彥徐鴻飛
蘭臺內外 2019年35期
李菁 黃仁彥 徐鴻飛
摘 要:信息技術與經濟的交匯融合使高校檔案數據迅猛增長,數據資源已成為基礎性資源。隨著知識圖譜的研究和應用逐步深入,在檔案專業領域的應用也在進一步的研究和探索中。我們需要充分認識知識圖譜技術的優勢,利用先進的科技進行數據資源管理和利用上的改革創新,構建具高校特色的檔案知識庫模型,提高數據管理和利用效率,更好地為高校的管理和發展服務。
關鍵詞:知識圖譜;檔案知識化;高校檔案
一、引言
隨著計算機及網絡技術的發展,信息的獲取與傳播發生本質變革,推動著互聯網向語義網絡的高速發展,奠定現代信息社會知識構成的基礎。在這一發展過程中,將前沿技術的深耕實踐與檔案資源的整合挖掘和深化利用相結合,為檔案資源知識化提供了新的思路和發展方向。加拿大著名檔案專家特里·庫克(Terry Cook)在1994 年提出,檔案工作者應該“由實體保管員向知識提供者過渡”,需要“從建立數據庫到建立知識庫”。美國在2005年啟動ERA(Electronic Records Archives)項目,主要研究數字檔案資源結構建立,從而進行長期保管;2012年啟動“大數據研究和發展計劃”(Big Data Research and Development Initiative),大力推進從大量的、復雜的數據集合中獲取知識和洞見的能力;在此基礎上,2016年發布“聯邦大數據研發戰略計劃”(The Federal Big Data Research and Development Strategic Plan)對2012年的計劃做了補充和完善,強調通過優化大數據分析和信息提取,提高做出決策和發現的能力。
從美國等國外的數字檔案資源發展路徑來看,最近幾年,利用人工智能和大數據技術,促進資源的知識化,加強信息分析,提高決策能力成為檔案資源的重要研究方向之一。知識圖譜(Knowledge Graph)技術是新興人工智能技術的重要組成部分之一,具有強大的語義處理和開放互聯組織能力,是一種應用十分廣泛的知識化組織和智能應用的工具,或許可以成為將來數字檔案資源知識化的有力工具之一。本文以知識圖譜技術為工具,研究高校數字檔案資源的知識組織和知識服務問題,通過高校檔案資源的知識化,實現對高校教職員工和學生的思想行為常態化管理,及時反饋學校的管理、教學、科研等各項信息,動態了解學生的各種動態及熱點情況,為高校領導提供決策、育人等輔助功能,最終為學校制定科學的管理策略,為維護學校安全穩定提供保障。
二、知識圖譜應用于高校數字檔案資源知識化的可行性
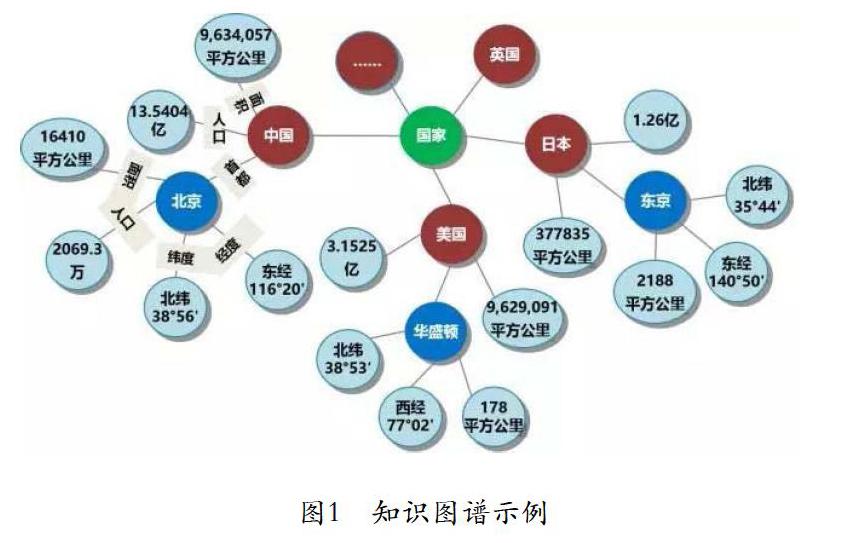
知識圖譜概念由Google公司2012年提出,Google公司的工程師阿米特·辛格(Amit Singhal)是這樣介紹知識圖譜的:“The world is not made of strings , but is made of things”,就是說,知識圖譜實際就是一張巨大的語義網絡圖,由真實世界中存在的各種實體或概念及其關系構成,節點表示實體或概念,邊則由屬性或關系構成。知識圖譜的提出是與互聯網上網絡資源內容呈現爆炸式增長的態勢密不可分的。由于互聯網內容逐步呈現的大數據特點(體量巨大、類型繁多、處理速度快、組織結構松散等),對人們有效獲取信息提出了挑戰。知識圖譜正是在此背景下逐步形成和發展,以“實體(Entity)-關系(Relationship)-實體(Entity)”構成的RDF三元組結構為基礎和核心來描述不同對象(包括屬性)以及他們之間的關系,如圖1。
1.知識圖譜將進一步深化高校數字檔案資源的知識組織。隨著檔案數字化進程的深入,資源數量浩大、形式異構、內容繁雜與高效處理的矛盾逐漸顯現。尤其是高校檔案,紙質檔案數字化基本完成,海量照片、視頻等日益增加,與學校OA系統、教務系統等諸多系統的接口獲取大量數字資源,對數字檔案資源的管理能力和利用能力提出了很高的要求。利用知識圖譜的三元組結構,可以對數字檔案資源進行知識化整理和信息處理,提高檔案利用的查詢速度和效率,解決數據結構復雜問題,最終能構成一個語義化的知識網絡。
2.從技術實現看,知識圖譜已經應用于很多知名度較高的大規模知識庫,是一種比較成熟的工具技術。比如LOD(linked open data)項目中的Freebase大規模知識庫網站,該知識庫網站由Metaweb創建,2010年谷歌收購Metaweb,在Freebase的基礎上建立Google知識圖譜。到2014年,Freebase在知識圖譜里引入6800萬個實體,建立約10億條關系,構造超過24億條三元組。最近幾年,知識圖譜也逐漸深入各個不用的專門行業領域的數據分析和挖掘,其中不乏檔案資源方面的案例。清華大學研發的AMiner學術知識服務平臺,集成了學術大數據融合、專家檔案智能抽取、專家智能搜索等研究成果,在論文文獻搜索以外,提供了針對研究者信息的強大搜索能力。
三、知識圖譜應用于高校數字檔案資源知識化實現的總體設計
1.總體設計目標
利用知識圖譜技術, 對黨群類、行政類、學生類、教學類、科研類、基本建設類、儀器設備類、產品生產類、出版物類、外事類等基礎數據庫以及其他數據資源庫等關系數據庫,運用知識抽取技術對基礎數據進行知識化和融合, 實現對各類實體的抽取、語義組織和關聯, 再借助大數據深度挖掘和融合技術將基礎數據和其他來源數據進行數據融合和數據增值, 構建高校檔案領域的知識圖譜,最終以可視化知識圖譜為核心,構建基于高校檔案數字資源的可視化智能搜索平臺。該平臺可以提供強大的知識索引和校級領導決策分析服務,滿足語義網和知識網絡時代用戶的新需求。
2.數字檔案資源的知識單元化是知識圖譜的實現的基礎。
知識圖譜描述的是真實世界中存在的各種實體或概念及其關系。實體是指具有可區別性且獨立存在的某種事物,如某一個人、某一個城市、某一種商品等等。對高校的數字檔案資源而言,實體應是組成檔案結構和內容的基本要素,是表達一個檔案文件的完整內容的最小單位。知識單元的特點是:第一,知識單元具有唯一性和獨立性,知識單元是每個實體的唯一代表和表示,用于描述共同認可的知識實體。與常用的概念或定義不同,知識單元必須是原始檔案文件中存在的、不可分割的知識表達。第二,知識單元具有共享性。檔案資源從文獻資料的形式轉化為供他人傳遞和利用的知識時,不同知識中的同一實體需要指向同一知識單元。知識單元是知識結構網絡中的一個個節點,通過點和點之間的關系構成了巨大的知識網鏈。
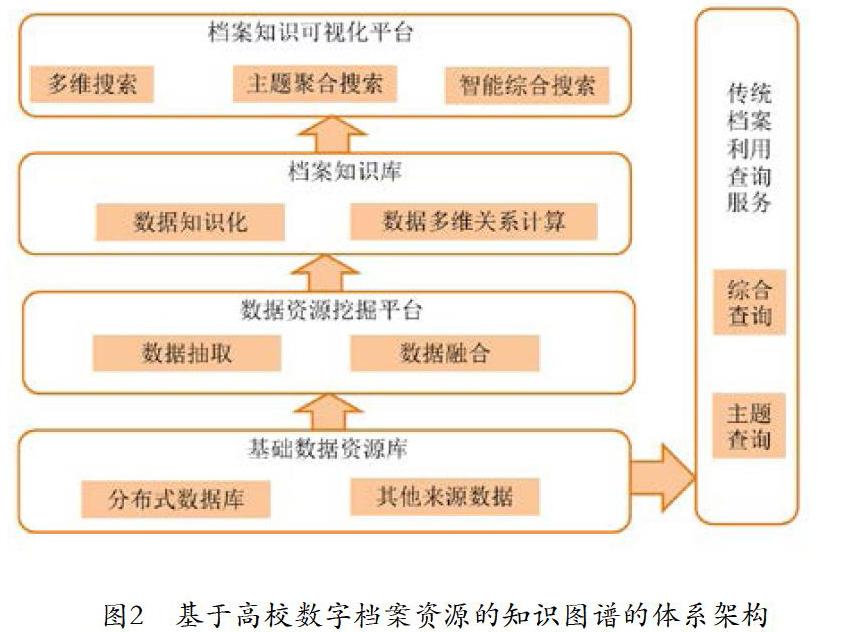
3.知識圖譜實現的總體架構
基于高校數字檔案資源的知識圖譜的體系架構如圖2所示,以檔案數據和其他來源數據作為知識圖譜的數據基礎,利用大數據挖掘各項技術,完成對數字檔案資源的抽取和知識原型的分析。同時通過對檔案資源的知識化網絡構建,完成檔案資源知識圖譜庫的構建,實現從檔案文件檢索到檔案知識檢索的方式轉變,優化海量檔案資源的檢索,真正實現檔案資源實體關聯導航。
四、知識圖譜應用于高校數字檔案資源知識化的體系構成
1.數據資源平臺
主要采用基礎數據資源庫和檔案知識庫的雙庫設計來實現數據資源平臺的搭建,兩庫協同作業,以基礎數據資源庫為數據資源,以知識庫為利用服務的數據來源,充分挖掘檔案文件的內容關聯,提高檔案資源的利用效率。
目前高校檔案館已基本完成檔案數字化,數字資源的數量龐大,同時每年新增的數字檔案資源和其他非結構化數字資源也在不斷遞增,因此,首先需要保證大數據平臺下的數據的可靠性和準確性。為保證數字檔案資源的質量,保證來源數據的安全可靠,需要按規范采集和組織檔案數據資源,為檔案工作人員進行檔案的加工處理和利用檢索提供有力的數據支撐,通過對這些海量的結構、非結構或半結構化數據的標準化存儲和管理,實現數據管理的高容錯性和擴展性,使數據得到高效利用。
當今語義網和知識經濟的大背景下,檔案信息以內容和形式特征為基本組織模式已經不能適應檔案資源搜索的新需求,因此,用最便捷的方式提供信息和知識的高校檔案知識庫是本平臺的另一個十分重要的數據資源庫。檔案知識化的整個過程就是對檔案數字資源的知識提煉過程,通過對知識層面的概念和邏輯關系的提煉,知識庫提供給用戶的不是單獨的檔案文件的內容,而是一個完整、結構化的知識鏈網,有利于對檔案的準確定位,提高檔案利用的效率。檔案知識庫以知識的特點和結構為存儲方式,可以為用戶提供便捷的知識搜索和發現,并且通過檔案知識庫和基礎數據資源庫的互聯和數據傳輸,充分挖掘檔案的內在價值,為檔案的利用提供精準、智能和高效的服務。
2.檔案數據資源挖掘平臺
對于檔案數據資源的挖掘,主要目標是要對基礎數據資源庫進行信息抽取、信息融合和加強,確定數字檔案資源這一專門領域的大量的實體、實體屬性和實體之間的關系,并在此基礎上形成本體化的知識表達,構成高校檔案這一特定領域的知識模型。通過模型的構建,可以有效地對檔案資源進行開發,深度挖掘語義本體的組織結構和關系,為用戶提供準確有效的知識或信息。本平臺主要采用基于本體模型的知識單元分析技術,按照知識組織的規則和要求,解析檔案資源中的各類實體(知識單元),并發掘蘊藏其中各類隱性因子,將數字檔案資源中的知識關系更加顯化,實現知識的聚合,使檔案知識的層次結構更加清晰,從而為檔案資源的智能化搜索建立全面的“知識網”基礎。
在檔案數據資源挖掘中引入知識提取等大數據挖掘技術,能快速定位檔案資源搜索目標。而知識模型可以通過檔案資源實體和之間的關系為實際應用中的推理提供基本規則和依據,實現信息瀏覽及檢索等功能。通過知識模型,還可以“通過計算概念之間的相關度,來量化概念間的語義距離,以選取最相近的概念;或者在語義模型中預先定義的一些關系上進行推理檢索”。通過各個檔案本體的顯性和隱性聯系和關聯,將教職員工和學生的多維信息進行聚合,全面展現多視角全方位的個人“畫像”信息資源,從大數據的角度對行為信息進行挖掘處理和分析,通過探究校園行為規律,準確掌握思想行為動向,為學校的管理提供決策和依據。
3.檔案數據資源可視化平臺
檔案數據資源可視化平臺是借助圖形、圖像處理、計算機視覺等技術,將知識模型等語義概念通過圖像或者圖形的方式在計算機、手機等終端的頁面上展現的過程。檔案知識模型的可視化可以提供清晰的溝通方式,使用戶可以能夠更快地理解和處理相關信息,提高檔案資源的服務效率和精確性,同時,隨著時間的變化,知識的實時信息也隨之變化,使信息能得到更快的傳遞和識別;通過收集到的行為習慣的數據信息,可以提供一些管理和監控的關鍵性指標,可以使學校的管理人員更容易發現各種大數據集的變化趨勢。
五、結論
在當今大數據的背景下,隨著技術發展的不斷深化,對檔案數據資源進行大數據管理和深度挖掘將成為檔案學的發展方向之一。通過知識圖譜構建、知識融合、可視化等大數據技術的引入,為高校檔案信息資源的科學管理,以及檔案數據精細化的進一步發展提供了可能。通過知識抽取,將檔案資源從傳統檔案的文件級數據粒度降低到數據級,構建結構化的語義模型,從而來描述高校檔案領域中的概念及其相互關系。高校檔案資源的知識化,能實現知識的快速響應,及時跟進個人檔案資源的變化,能提供對個人習慣和方式精準推理和分析,提高檔案的利用效率和服務水平,為高校教學、科研等業務的有效管理提供有力保障,同時也能為領導決策和管理提供全面深入的數據支持。
參考文獻:
[1]Terry Cook. Electronic Records,Paper Minds:The Revolution in Information Management and Archives in the Post-Custodial and Post-Modernist Era[J].Archives and Manuscripts,1994
[2]Electronic Records Archives.[EB/OL].[2019-8-22].http://www.archives.gov/era/.
[3]The Federal Big Data Research And Development Strategic Plan.[EB/OL].[2019-8-22].https://obamawhitehouse.archives.gov/sites/default/files/microsites/ostp/NSTC/bigdatardstrategicplan-nitrd_final-051916.pdf.
[4] Tang J, Zhang J, Yao L M, et al. AMiner: Extraction and Mining of Academic Social Networks[C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD2008). 2008
[5]楊茜雅.中國聯通電子檔案數據挖掘與智能利用的研究[J].檔案學通訊,2018
基金項目:本文系上海市檔案局科技項目《基于知識圖譜的高校數字檔案資源數據挖掘實現研究》(項目編號:滬檔科1914)的研究成果之一。
作者簡介:李菁(1975-),女,漢族,浙江平湖人,館員,碩士,單位:上海師范大學檔案館,研究方向:數字檔案管理,聲像檔案管理;黃仁彥(1982-),男,漢族,上海人,工程師,碩士,單位:上海師范大學檔案館,研究方向:檔案管理;徐鴻飛(1985-),男,漢族,山東人,工程師,碩士,單位:上海師范大學檔案館,研究方向:檔案管理。
