基于粒子群參數優化的同構雙種群蟻群算法
2019-10-18 07:26:10朱宏偉游曉明
測控技術 2019年9期
朱宏偉,游曉明,劉 升
(1.上海工程技術大學 電子電氣工程學院,上海 201620;2.上海工程技術大學 管理學院,上海 201620)
蟻群算法(Ant Colony Optimization,ACO)是一種群智能優化算法。它基于自然界蟻群集體覓食行為,模擬真實蟻群的協作過程。1991年,Dorigo提出螞蟻系統(Ant System,AS)[1]用于解決TSP等復雜難問題。1996年,Dorigo等人為了限制信息素的正反饋作用,提出蟻群系統(Ant Colony System,ACS)[2],通過兩種信息素更新方式,平衡每條邊之間的信息素差異,提高蟻群算法性能。同理,T.Stutzle等人提出了最大-最小螞蟻系統(MAX-MIN Ant System,MMAS)[3],通過限制信息素最大值和最小值,保證算法的多樣性。后來專家學者在這兩者基礎不斷改進[4-7],使算法不斷向前方展。同時還將蟻群算法延展于機器人路徑規劃、調度等一系列優化問題上,使算法向多方向發展[8-9]。
粒子群優化算法(Particle Swarm Optimization,PSO)最早是由Kennedy和Eberhart提出的,最初是模擬鳥群的捕食行為,逐漸發展成為群體智能算法。在尋優過程中,每個潛在的最優解都與粒子運動速度相關,根據粒子的歷史經驗以及鄰居們的經驗來調整其速度大小和方向,朝著最優解的方向逼近。粒子群優化算法已經廣泛應用于連續優化問題和離散優化問題,特別是其天然的實數編碼特點適合于處理實優化問題并可以有效地對系統參數進行優化。
雖然使用粒子群優化的參數會提高解的質量,但是找到全局最優解還有一定的困難,故本文提出一種基于粒子群參數優化的同構雙種群蟻群算法(Homogeneous Dual Ant Colony Algorithm Based on Particle Swarm Optimization,HDAP)來提高找到全局最優解的概率。以ACS作為框架基礎,算法開始時,將螞蟻均分為兩個子種群,分別命名Population1和Population2。Population1引入單位距離信息素路徑構造算子,將距離因素和信息素因子相統一,提高算法遍歷整個地圖的能力。Population2引入粒子群優化算法對蟻群算法中的多個參數進行優化,減小蟻群算法中參數的影響,實現對解空間高效、快速的全面尋優。Population1中由于未使用α和β等參數,與Population2的參數優化形成優勢互補關系,兩個種群相隔一定迭代次數進行協同交流,提高發現全局最優解的概率。仿真實驗表明,針對TSP問題,本文算法提高了解的質量,增強了算法的種群多樣性。
1 相關工作
1.1 基本蟻群算法的TSP問題
以NP-難問題中最常用的TSP問題為例說明基本蟻群算法的模型。
設螞蟻的數量為m,城市的數量為n,dij(i,j=1,2,…)代表兩兩城市之間的距離,τij(t)代表t時刻i城市和j城市之間的信息素的濃度大小。在ACS算法中,每條邊上的起始濃度都是相同的,記為τ0。
1.1.1 路徑構建
首先每個螞蟻被隨機分配到城市中,然后根據狀態轉移概率尋找下一個要到達的城市。ACS算法中,每只螞蟻從i城市到j城市的選擇方式為
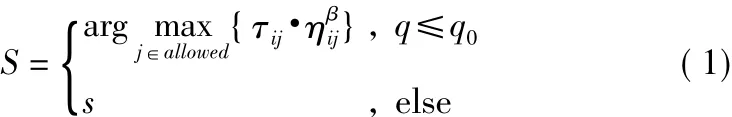
式中,ηij為 i,j城市之間距離的倒數,即 1/dij;q0為一個人為設置的固定值;q為一個隨機生成的隨機數;S為將要被選擇的下一個城市;s為另一種輪盤賭的選擇方式。當不符合上述條件,采用輪盤賭進行路徑構建。
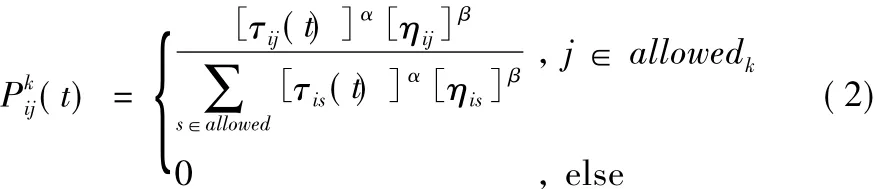
式中,allowed為螞蟻當前可行城市集。
1.1.2 信息素更新
ACS算法中分為全局信息素更新以及局部信息素更新部分。
①全局信息素更新:當所有的螞蟻都完成一次周游以后,算法只允許每一代的最優螞蟻釋放信息素。
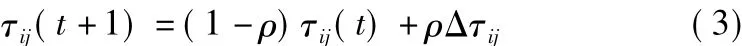
式中,
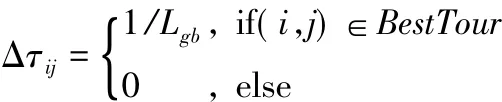
其中,ρ為全局信息素揮發率;Δτij為信息素增量;Lgb為當前最優路徑長度。
②局部信息素更新:當所有的螞蟻都完成一次周游后,算法允許每只螞蟻都對其走過的路徑進行信息素的更新。

全局信息素和局部信息素之間相互配合是ACS算法最重要的特點。
1.2 粒子群算法
粒子群優化算法的基本原理為:一個由m個粒子組成的群體在d維搜索空間中,以一定的速度飛行,每個粒子在搜索時,既考慮自己搜索到的歷史最好點,又考慮群體內其他粒子的歷史最好點,在此基礎上進行位置更新。
設第 i個粒子的位置表示為 xi=(xi1,xi2,…,xid),其速度表示為vi=(vi1,vi2,…,vid),其經歷過的歷史最好點表示為pi=(pi1,pi2,…,pid)。群體內所有粒子所經歷的最好的點表示為Gg=(Gg1,Gg2,…,Gpd)。一般來說,粒子的位置和速度分別根據式(5)和式(6)進行更新。
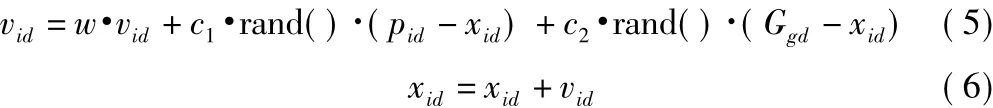
式中,w為慣性權重,其大小決定了粒子對當前速度繼承的多少;c1和c2為學習因子,通常在0~2之間取值;rand()是在[0,1]區間內均勻分布的偽隨機數,即rand()∈U[0,1]。
2 改進的蟻群算法
本文提出一種基于粒子群參數優化的雙種群蟻群算法,通過加強蟻群間的合作,使算法更加符合自然界中螞蟻種群間相互協同、相互競爭的特點,進一步減少種群陷入局部最優的概率,增強解的質量。將送螞蟻均分為兩種類型,命名為Population1和Populatin2,分別按照式(8)和使用粒子群優化的參數ACS進行路徑構建,獨立地進行最優解的搜尋,每隔w次迭代后交流最優解,加強種群之間相互學習,相互合作,從而使每個種群皆獲得更優解。
2.1 單位距離信息素算子
本文提出一種改進的路徑構建策略,即單位距離路徑構造算子(Unit Distance of Path Constructor,UD-PC),將距離因素與信息素因子相結合,增加種群的多樣性。本文的路徑構建公式如下:
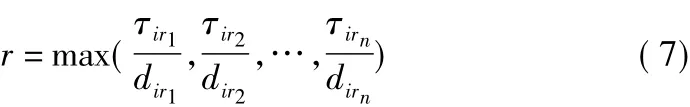
式中,τirn為i城市到 rn城市之間的信息素;dirn為i城市到rn城市之間的距離值。
式(7)與式(1)對比可知,式(1)中由于ηij的β的次方使距離因素對路徑構建影響較多,減少了信息素的引導的作用,而式(7)則很好地平衡了這兩個因素,其減少了距離因子在路徑構建中的權重,增加其他城市被選擇的概率,跳出局部最優。
Population1采用式(8)進行路徑構建,增強算法搜索整個地圖的能力,同時增加算法多樣性,使算法更易跳出局部最優,找到最優解。
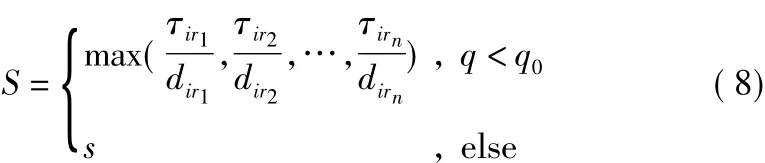
式中,s為輪盤賭選擇方式;q0為一固定常數;q為一個隨機數。
2.2 粒子群對于蟻群算法參數的優化
本文提出一種使用粒子群算法優化蟻群算法參數的方法,將ACS中β、q0和ρ放在三維空間坐標系中,進一步優化這3個參數,提升了算法的性能。
設一個三維坐標xi=(xi0,xi1,xi2)來對應一組β、q0和ρ參數,用于表現粒子的位置。同時,與位置相對應的,每個粒子在解空間中的移動有3個方向的速度,記為 vi=(vi0,vi1,vi2)。
算法開始,初始化粒子P0,P1,…,PN的位置參數xi=(xi0,xi1,xi2) ,一個粒子對應一組三維坐標,即參數β、q0和ρ,并將每個粒子所對應的參數值反饋回蟻群算法。蟻群根據不同的參數的值,進行TSP最優解的尋找。每個粒子當前找到的最優粒子位置為Pi,整個種群當前所找到的最優粒子位置為Gg,按照式(5)和式(6)更新粒子的速度和位置。
Population2克服了蟻群算法參數的影響,減少了大量盲目的實驗,實現了對搜索空間高效、快速的全面尋優。
2.3 交流策略
根據文獻[10]和文獻[11],使用粒子群優化的參數雖然可以找出全局最優解,但是概率偏低,故本文采用兩個種群協同交流的策略,提高了算法多樣性,同時提高了獲得全局最優解的概率。在本算法中,Population1未使用α和β等參數和Population2的參數優化形成路徑構造算子之間的互補關系,每隔w次迭代后,兩個種群進行交互學習,即比較每個種群中的當前最優解,將其中最好的解保存下來,同時替換掉另一個種群中相對較差的最優解,從而促使兩個種群向更好的解的方向發展。式(9)描述了兩個種群的學習機制。

2.4 改進算法(HDAP)偽代碼
用HDAP算法解決TSP問題的代碼如下。
1.Procedure HDAP()
2.Begin:
3.Initialize the parameters and the pheromone
4.Divide m into part #m as ants’number
5. for iter1←1 to T do
6. #Algorithm:Population1
6. for i←1 to m1 do#m as ants’number
7. for j←2 to n do#n as cities’number
8. Unit Distance of Path Constructor
9. end-for
10. end-for
11. Update pheromones
12. #Algorithm:Population2
13. Initialize parameters of P0,P1…PN
14. for i←1 to m2 do#m as ants’number
15. Transfer parameters of PSO to ACO
16. for j←2 to n do#n as cities’number
17. Construct ant solutions
18. Calulation GgandPi
19. Update viand xi
20. end-for
21. Update pheromones
22. end-for
23. if(mod(T,w)= =0) #T is the current iter
24. Collaborative communication
25. end-if
26. end-for
2.5 時間復雜度
通過分析上述算法流程,HDAP時間復雜度為 O((m1×(n-1)+m2×(n-1))×T),由于 m1+m2=m,故HDAP算法最大時間復雜度為O(m×n×T),ACS最 大 時 間 復 雜 度O(m×n×T)。由此可以看出,所提出的HDAP蟻群算法雖然產生了部分計算負擔,但是沒有改變算法的最大時間復雜度。
3 實驗分析
本實驗在Matlab R2014a的環境下仿真運行。為了檢測改進算法的有效性,選取eil51、eil76、KroA100、KroA150、KroB150等TSP算例來進行算法驗證,并與ACS、MMAS等經典ACO算法以及多個多種群算法相對比,結果顯示所提出的HDAP有著更好的實驗結果。同時eil51、eil76、KroA100都比較容易找到最優解,從熵值看出改進的HDAP算法的多樣性有著明顯的提升。
3.1 eil51問題的實驗分析
在eil51問題上,Population1和Population2的公共參數為:螞蟻數量m=50,信息素作用度α=1,最大迭代次數iter=2000。非公共參數為:Population1的實驗參數,包括局部揮發率ζ=0.1,全局揮發率ρ=0.4,參數q0=0.8;Population2實驗參數取值范圍,包括β=[2,10],q0=[0.5,0.9],ρ=[0.2,0.7]。
每組參數不同,ACO算法都進行了連續20次測試,采用控制變量的方法,逐漸改變β的值,來觀察其對實驗的影響。設到算法所找到的最優長度為Lbest,算法20次實驗的平均路徑長度為Lave。
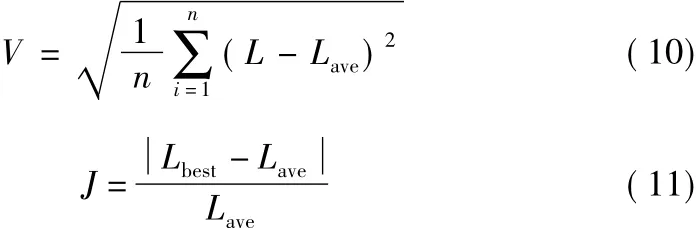
式中,n為實驗次數;V為與平均解的誤差;J為誤差率。
式(10)與式(11)可以共同反映每個ACO算法的穩定性,波動情況以及找到最優解的概率。標準差可以反映20次試驗每一次找出的解與平均值的線性程度,標準差越大,這個算法的波動程度就越大。而J可以反映出最優值和平均值的離散的關系,用于判斷每個ACO算法找出最優值的概率,概率與數值J大小成反比,即J的值越大,算法找到最優解的概率就相對越小。
eil51實例的實驗結果如表1。表1顯示了不同的β取值對最優解、標準差V、誤差率J等實驗結果的影響。從表1可以看出,β從2開始依次變化到5,ACS算法平均長度的結果變化類似于一個二次函數。而粒子群優化得到的參數β為4.2311,證明了粒子群優化算法的有效性。同時由于Population1增加了螞蟻探索整個TSP測試集的能力,提高了解的質量,從算法開始到結束,熵值都一直處于略微上升的狀態,表明算法的多樣性提升明顯,使算法容易跳出局部最優。圖1為某次路徑長度為426(最優解)時的熵值。
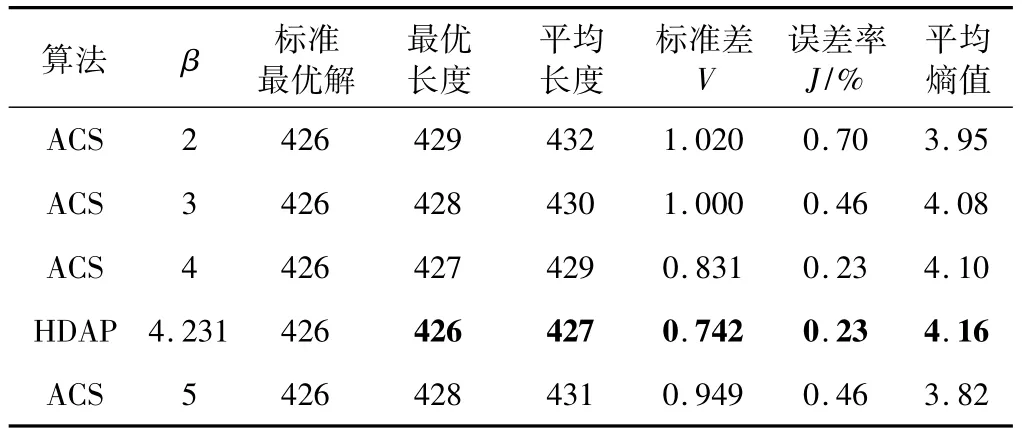
表1 不同β對ACO路徑長度的影響
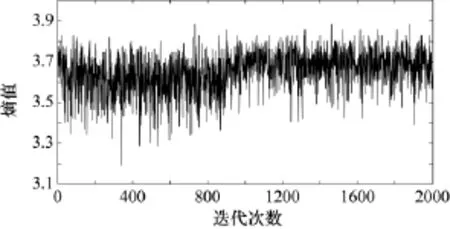
圖1 HDAP多樣性分析
3.2 中大規模TSP問題分析
下面針對 ch130、KroB150、KroA150等中大規模TSP問題進行實驗仿真。每種算法都進行了20次的仿真實驗,平均長度四舍五入,具體比較結果如表2所示。
下面舉例說明3種ACO算法的收斂情況。圖3為KroB150測試集的3種算法的最優解迭代變化。由圖可看出,ACS算法收斂的速度最快,在第216代時,相比較其他兩種算法,其結果最優,但同時陷入局部最優,而無法跳出;MMAS和HDAP收斂速度相對較慢,MMAS算法在1737和2000次迭代陷入局部最優后,通過信息素的重新初始化,跳出局部最優,但依然沒有找到全局最優解。由于HDAP的兩個種群之間的學習交流策略,共同處理最優解的尋找,其收斂的速度要更優于MMAS,在1737次迭代中跳出局部最優,同時找到全局最優解。
表 2 反映了在 eil76、KroA100、ch130、KroB150、KroA150等大規模測試集上,3種ACO算法的最優長度、最差長度、平均長度、標準差V等一系列數據比較分析。從仿真實驗結果可以看出,HDAP各方面的實驗結果都是優于其他兩種ACO算法的,尤其是最優解、平均解、平均熵值等方面提升更加明顯。結合3.1節中的實驗分析,表明HDAP無論在小規模和大規模TSP問題上,都有著比較優的實驗結果。
同時,比較了3種算法的J(式(11))的值,3種蟻群算法在不同的測試集中誤差率的變化曲線如圖3所示。J值越小,說明算法的穩定性越高,其解的質量也相對較高。由圖3的實驗結果可以看出HDAP在多個測試集中的誤差率J都要小于ACS和MMAS算法,說明HDAP在3種算法中有著最高的穩定性。
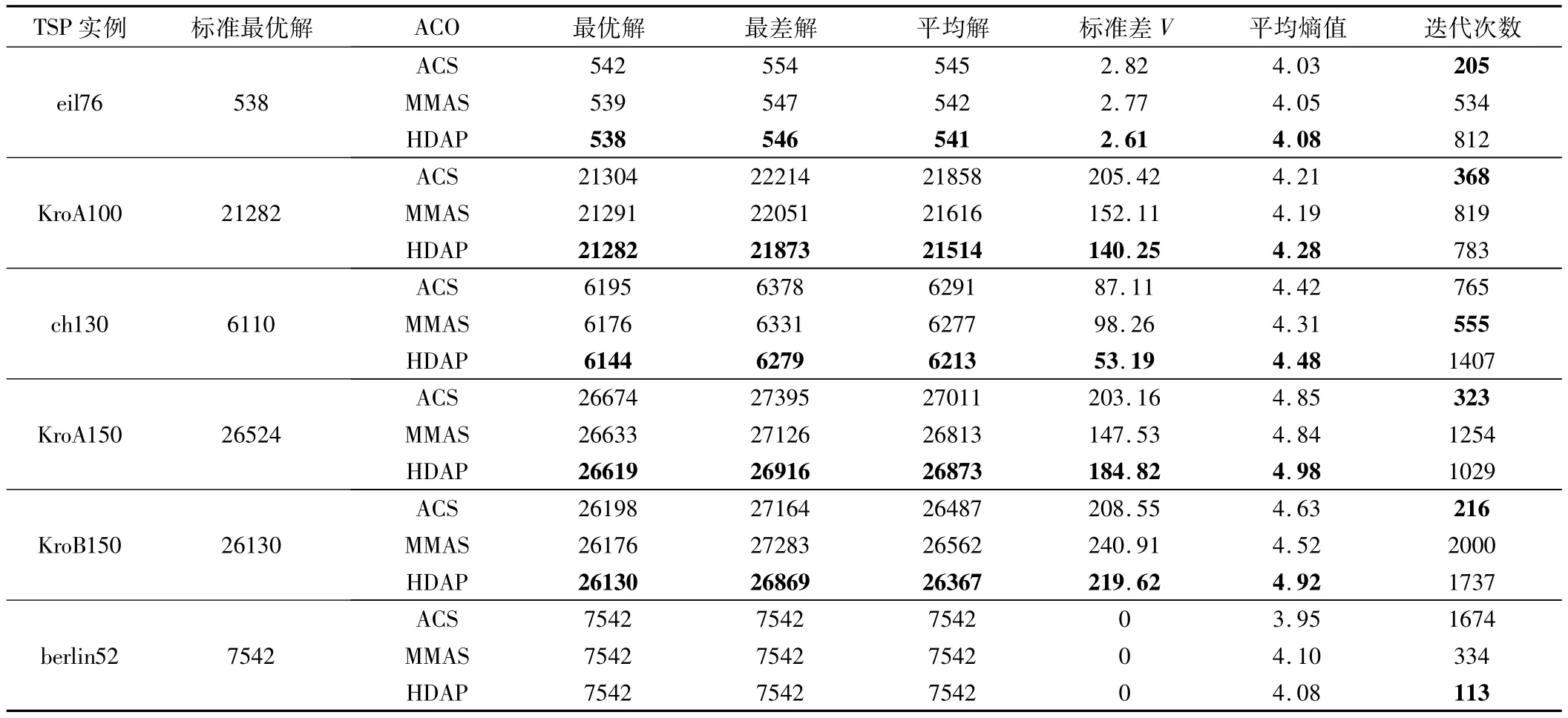
表2 不同算法性能對比
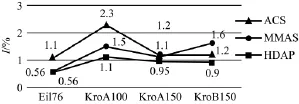
圖3 不同TSP測試集誤差率分析
由表2和圖3可知,改進的HDAP算法提升是比較明顯的。為了證明本文算法的優越性,與一些其他多種群蟻群算法也進行了比較分析,如表3所示。其中HHACO算法的數據都來自于文獻[12](SCI),AHMACAS算法中數據來自于文獻[13](CSCD),HMACSF算法中數據來自于文獻[14](CSCD)。從表3可以看出,在與其他多種群蟻群算法對比中,本文算法有著一定的優勢,特別是在eil51和eil76測試集上,HDAP找到的最優解要好于其他3種多種群算法。
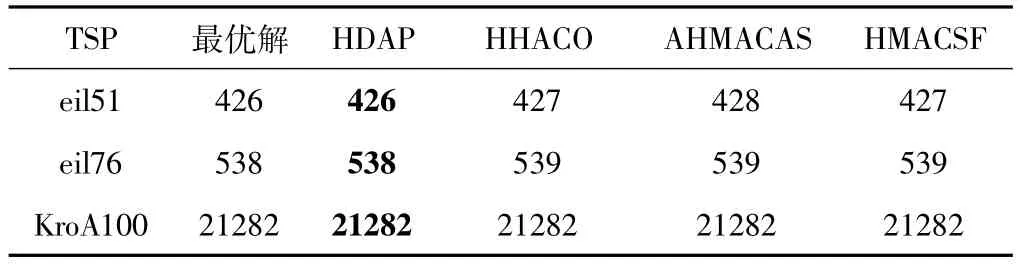
表3 多種群之間的對比
3.3 HDAP的最優解仿真圖
圖4給出了HDAP的最優解仿真圖。
3.4 收斂速度對比
為了更加直觀地對比各個算法的性能,在幾個TSP實例中選取不同規模的城市,如 eil51、eil76、ch130、KroA150,用于比較算法的收斂速度,如圖5所示。從圖中可以看出,HDAP無論在小規模還是在中大規模的問題上,最優解都要好于其他兩種算法,且收斂速度要優于MMAS。
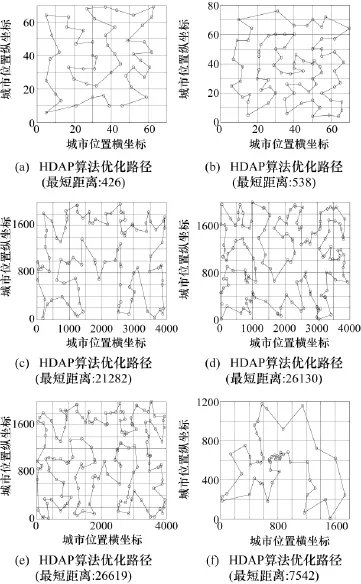
圖4 HDAP的最優解仿真圖
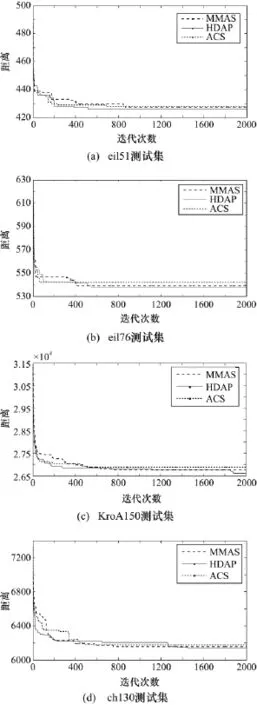
圖5 不同測試集的收斂速度
4 結束語
提出一種基于粒子群參數優化的同構雙種群蟻群算法,將螞蟻均分為兩個子種群,即 Population1和Population2。Population1引入單位距離信息素路徑構造算子,將距離因素和信息素因相統一,增加算法遍歷整個地圖的能力,增加算法多樣性。Population2引入粒子群優化算法對蟻群算法中的多個參數進行優化,克服了蟻群算法參數的影響,實現了對搜索空間高效、快速的全面尋優。Population1中由于未使用α和β等參數,與Population2的參數優化形成優勢互補關系,兩個種群相隔w次迭代進行協同交流,提高發現全局最優解的概率。接下來,將繼續研究如何在更大的測試集中找出最優解和使算法更快的收斂。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
