基于python的文本挖掘應用
2019-09-17 07:59:28程慧玲
青年與社會 2019年20期
關鍵詞:文本挖掘
摘 要:隨著互聯網發展,數據的產生與存儲無處不在,基于用戶的行為數據分析對商家及消費者都具有重要意義。文章主要通過八爪魚實現京東商城小米9用戶評論的抓取,利用python進行文本數據挖掘及分析。通過導入文本數據建立語料庫、并進行中文分詞、詞頻統計、生成詞云過程實現小米9用戶評價的詞頻統計分析,得出用戶對手機評價的側重點,為商城用戶及商家提供一定的決策建議。
關鍵詞:數據挖掘算法;文本挖掘;詞頻統計
在大數據時代,在我們的生活當中,可獲取的大部分信息是以文本形式存儲在文本數據庫中的,如web頁面、新聞文檔、研究論文、電子郵件、數字圖書館和書籍等[4]。由于互聯網的迅速發展,現實世界的文本信息更多的呈現為電子化,文本挖掘也成為信息領域的研究熱點和學習重點。用計算機實現海量文本的識別和分析成為研究重心,文本挖掘技術也被廣泛的應用于許多領域,也突出解決了很多問題。國內很多學者對文本挖掘相關也都提出了各自的見解與不同領域內的應用。羅怡薇,張科偉[1]在其文章基于文本挖掘的網絡熱點輿情分析中,利用python及數據挖掘算法實現校園霸凌熱點問題的詞頻統計分析,得出大眾對于此問題的消極態度。馮麗娜[2]在其文章基于詞頻統計的孔子與顏之推教育思想比較研究中通過對《顏氏家訓》和《論語》的詞頻統計與對比,揭示了二者在教育思想上的異同點。胡翠婷[3]在其文章基于詞頻計量統計的林黛玉性格分析中,通過對《紅樓夢》和林黛玉詩詞的詞頻統計,得出其對林黛玉性格的分析結果,即多愁善感,自卑敏感的性格特點。
一、文本挖掘概念
文本挖掘(Text Mining)是一個從非結構化文本信息中獲取用戶感興趣或者有用的模式的過程。其中被普遍接受和認可的文本挖掘定義為:文本挖掘是指從大量文本數據中抽取事先未知的、可理解的、最終可用的知識的過程,同時運用這些知識更好地組織信息以便將來參考[4]。文本挖掘的主要用途是從原本未經處理的文本中提取出未知有用的知識,但是文本挖掘也是一項非常困難的工作,因為它必須處理那些本來就模糊而且非結構化的文本數據,所以它是一個多學科結合的領域,包括了信息技術、數據庫技術、文本分析、統計學、數據可視化、模式識別、機器學習、深度學習以及數據挖掘與數據分析等技術[4,5]。文本挖掘是從數據挖掘發展而來的,因此其定義與我們所知的數據挖掘定義相類似。文本挖掘技術不同于數據挖掘技術,一些數據挖掘技術也不能應用到文本挖掘中,即使可用,也需要建立在對文本集的預處理的基礎之上。
二、文本挖掘詞頻統計過程
(一)建立語料庫
語料庫是我們要分析的所有文檔的集合。在日常工作中我們對文章的管理,先是一篇篇的文章不斷的積累,我們存了大量的文章之后,會對文章信息進行一些歸類的工作,一般體現于建立不同的文件夾來保存不同類別的文章。同樣的,我們把我們需要分析的文文章件,讀取到內存變量中,然后在內存變量中使用不同的數據結構,對這些文文章件進行存儲,以便進行下一步的分析。
(二)中文分詞與去除停頓詞
將漢字序列分成一個一個的單詞,利用jieba數據包進行分詞,使用默認的數據庫對文字句段進行分詞。在分詞過程中有些停頓詞是無實際意義的,比如的,得,地以及一些助詞代詞等,需要將其去除以提高詞頻統計結果的正確性。
(三)詞頻統計與分析
詞頻,即詞語在文檔中出現的次數,通過詞語或關鍵字在文檔中出現的次數統計可分析出用戶一定的情感傾向。
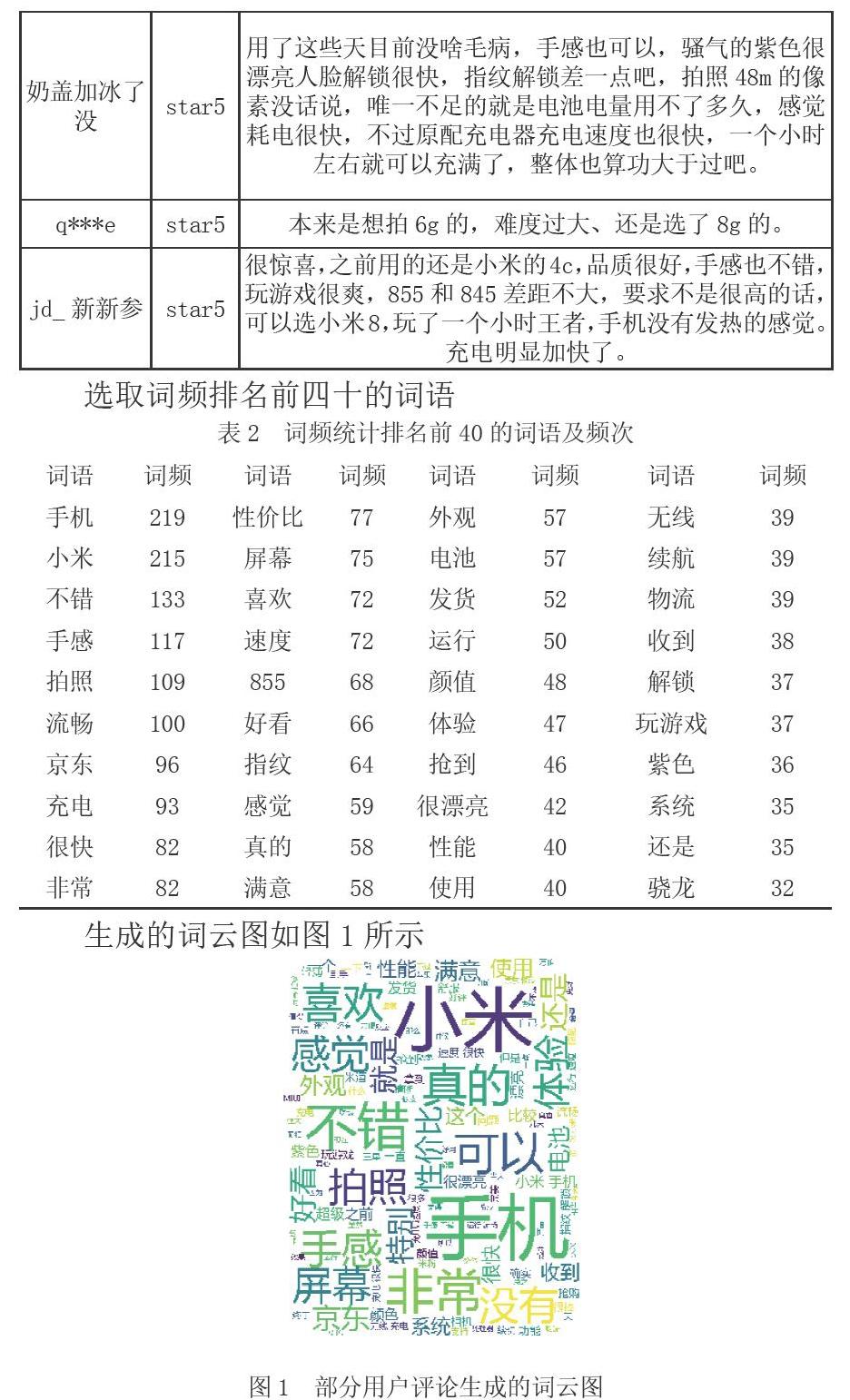
(四)生成詞云
利用wordcloud和matplotlib實現詞云的可視化過程。
三、文本挖掘在小米9用戶評論中的應用
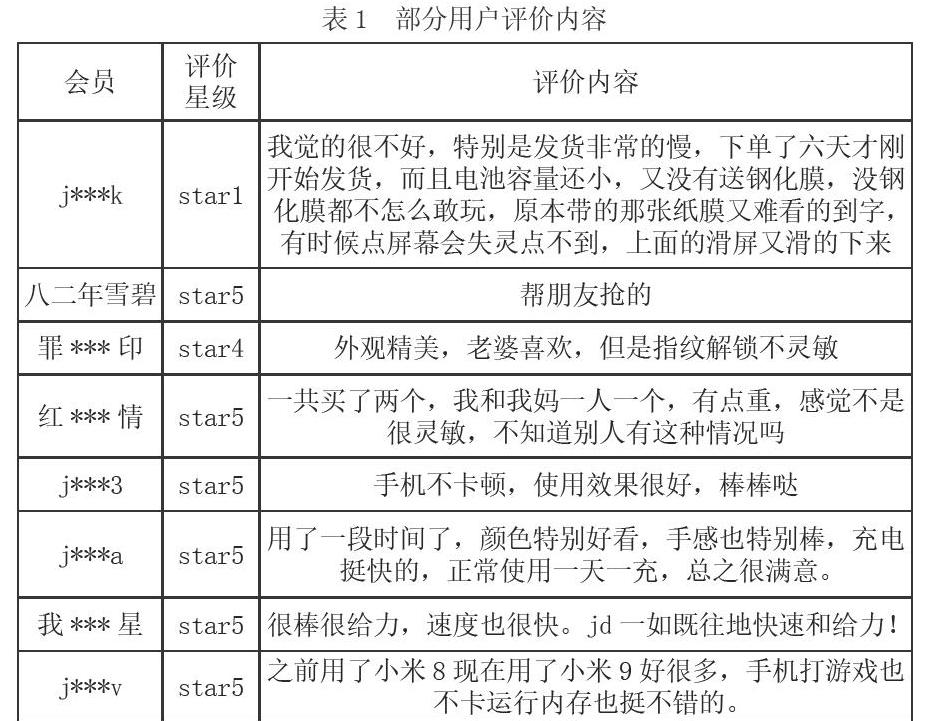
文章利用八爪魚抓取了京東商城上小米9二月到四月間的520條商品評論,并利用python進行了數據處理過程。
(一)數據抓取通過八爪魚抓取商城米9用戶評論,保存到本地excel表當中。
(二)數據清理將抓取的數據進行清理,去除掉不用的數據列,填充空缺數據條。
(三)python編寫代碼實現數據的處理與分析過程,包括讀取文本數據,進行結巴分詞,詞頻統計和生成詞云的過程。
(四)分析用戶對米9的總體評價。由數據分析結果及生成的可視化詞云可知,用戶的主要情感傾向是小米手機不錯,這與小米的一貫品牌形象相符,追求性價比。其中除去手機、小米關鍵詞不錯是詞頻統計中最高的,這是對小米的總體評價。其次就是手感,拍照,和流暢,這是對小米9的具體評價,即小米9的手感不錯,拍照也清晰,機身也很流暢。但其中也存在一些頻次較低的中性詞語,比如電量,解鎖等名詞性或動詞性詞匯,無確定其形容詞或副詞的連接描述,所以不能確定其表達的精確意思。存在的客戶抱怨主要是其發貨速度和小米的饑餓營銷,讓用戶等待時間較長。
四、結語
通過八爪魚和python實現計算機對用戶評論的文本抓取與分析,并分析出用戶的產品偏好及情感評價,對產品的研發有一定的指導意義,對其他用戶購買手機具有一定的參考意義。文章的不足之處:采集的樣本數據520條,數據量較少,存在一定的結論偏差;詞頻統計與可視化過程只能大體判斷整體用戶的情感傾向,而不能具體到每位用戶的情感傾向,仍需深入研究。
參考文獻
[1] 羅怡薇,張科偉.基于文本挖掘的網絡熱點輿情分析[J].內蒙古科技與經濟,2018(11):18-19.
[2] 馮麗娜.基于詞頻統計的孔子與顏之推教育思想比較研究[J].圖書館雜志,2018(10):70-78.
[3] 胡翠婷.基于詞頻計量統計的林黛玉性格分析[J].現代語文,2019(02):86-92.
[4] 徐奇釗.基于文本挖掘的文本情緒分類[D].云南財經大學,2016.
[5] 潘若愚.基于詞頻統計分析國內外文本挖掘的研究熱點[A].第十二屆(2017)中國管理學年會[C]2017(10).
作者簡介:程慧玲(1997- ),女,漢族,安徽合肥人,就讀于安徽理工大學,研究方向:管理科學與工程。
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識與技術(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國中醫藥圖書情報(2016年4期)2016-10-20 23:35:25
湖南師范大學學報·自然科學版(2016年3期)2016-06-25 06:47:25
語文教學之友(2016年5期)2016-06-15 12:15:44
