數據挖掘技術在電站設備故障分析中的應用
2017-01-21 15:55:21王爽趙會洋
軟件導刊 2016年12期
王爽+趙會洋


摘 要:發電站正常高效運行對保障社會發展和人民生活極其重要。電站運行中產生大量的故障記錄數據,將數據挖掘技術應用于電站設備故障的大數據分析,發現隱藏在數據中的有用信息,有助于電站管理工作改革和設備管理技術創新。根據某發電集團設備故障統計報告,制定了相應的數據分析方案,研究了文本挖掘、關聯分析、聚類分析等多種數據挖掘方法的關鍵技術,詳述了這些技術在電站故障分析中的應用方法及效果。
關鍵詞:電站設備故障;數據挖掘;文本挖掘;關聯規則;聚類
DOIDOI:10.11907/rjdk.162187
中圖分類號:TP319
文獻標識碼:A文章編號:1672-7800(2016)012-0121-03
0 引言
電力大數據的信息挖掘和利用將給電力企業帶來新一輪商業模式轉變和價值創新。文獻[1]~[8]研究了數據挖掘技術在火電廠設備故障診斷、狀態預測方面的應用;文獻[9]~[11]研究了數據挖掘技術在核電廠中的應用,主要用于異常值檢測和抗震性推斷等;文獻[12]~[13]研究了數據挖掘技術在風力發電廠中的應用,主要用于風力、風速的預測;文獻[14]~[15]研究了數據挖掘技術在水電站和太陽能發電中的應用。這些研究的開展多基于電站設備運行的實時數據,雖然研究成果在一定程度上促進了電站的健康高效運行和科學管理,但研究范圍不全面。本文將基于大量的設備故障歷史統計數據,運用文本挖掘、關聯規則、聚類等多種數據挖掘技術展開研究,發現其中隱藏的有用信息,為電站的運行管理提供決策支持。
1 數據分析方案設計與數據預處理
研究所用數據來自某大型發電集團2008-2014年設備運行故障月度報告。報告有word和pdf兩種格式,每份報告主要內容有設備運行故障統計概況、具體案例描述等。案例描述提供了設備故障發生的時間、地點、原因等信息,信息的數據類型有日期、數字、文本等。根據數據源的這些特點,制定了如圖1所示的數據分析方案。
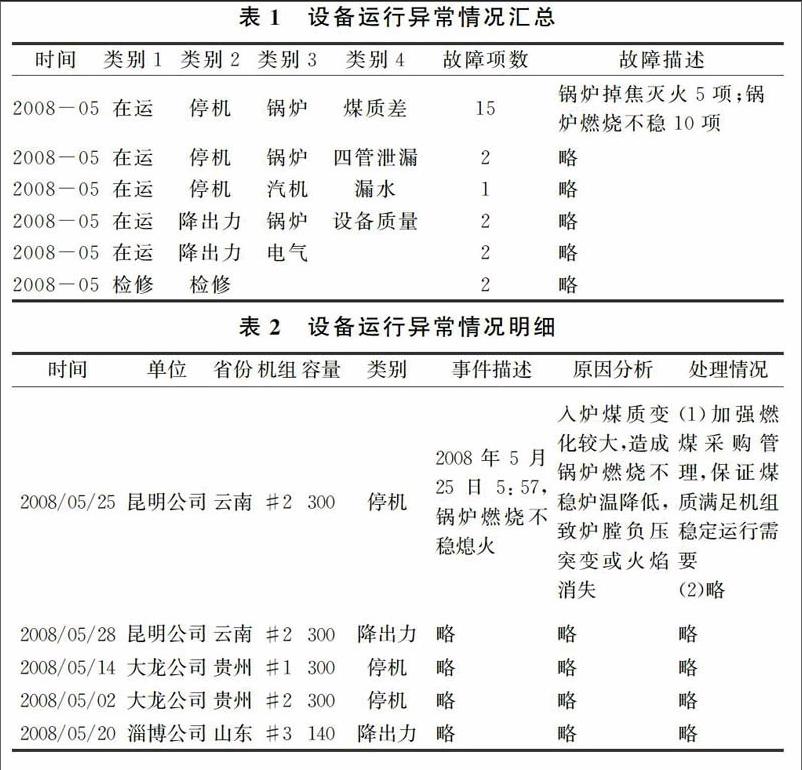
在數據預處理環節,首先要將各種數據源中的有用信息提取出來。數據提取的原則是便于分析且盡可能少地丟失信息,最終將數據整理成兩張Excel表,分別是設備運行故障總表和設備運行故障明細表,它們的結構和樣本數據示例如表1和表2所示。由于數據條目較多,在此僅列出每張表的少數幾條數據。對于文字內容描述較多的字段,僅列出一條較為完整的數據來說明問題,其它條目內容用“略”來代替。表1中的類別1到類別4從粗到細分別描述了設備故障類別,每條樣本數據展現不同類別的故障在特定時間所發生的項數和具體原因描述。表2較為詳細地描述了每臺設備故障發生的時間、單位、省份、機組號、機組容量、類別、事件描述、原因分析和處理情況。
缺失值處理和數據類型處理是數據預處理環節中另外兩個重要工作。缺失值處理方法有刪除含有缺失值的個案和可能值插補缺失值。可能值插補缺失值方法有:均值插補、極大似然估計、多重插補等。根據具體分析任務,由分析目的選擇缺失值處理方法。以表1為例,當分析文字型數據時,由于缺失量較少,采取了刪除含有缺失值個案的方法;當分析故障項數時,采取了同類別均值插補方法。數據類型處理就是根據數據的特征和分析目的確定數據字段類型。以表1為例,時間為日期型,類別1~4為因子型,故障項數為數字型,故障描述為字符型。完成數據預處理環節后,利用多種數據挖掘方法對數據進行隱藏信息挖掘。
2 文本挖掘研究與應用
文本挖掘中最重要的工作就是分詞,分詞算法采用中國科學院計算技術研究所的中文分詞算法ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)。ICTCLAS基于隱馬爾可夫模型HMM(Hidden Markov Model)實現,HMM定義如下:
一個隱馬爾科夫模型是一個三元組(∏,A,B)。其中,∏是初始狀態的概率分布,∏=(πi),πi表示在t=1時刻,狀態為si的概率;
A為狀態轉移矩陣,A=(aij),aij=P(qt+1=sj|qt=si),表示在t時刻、狀態為si的條件下,在t+1時刻狀態是sj的概率;
B為混淆矩陣,B=(bjk),bjk=P(ok|sj),表示在隱含狀態是sj條件下,觀察狀態為ok的概率。
將文本挖掘技術應用于電站故障數據挖掘步驟如下:①詞典調整。分詞的依據是詞典,通常詞典中只包含常用詞匯,因此,在對諸如電力專業領域數據進行文本分析時,需要根據分析要求加入一定量的專業詞匯;②分詞。利用ICTCLAS分詞算法對文本字段進行分詞;③詞性過濾。為了突出故障原因,需要去掉一些無關的詞,例如形容詞、數量詞、副詞等;④構建語料庫并處理。構建語料庫后就可以進一步處理,例如去除停用詞、標點符號、數字、空格等;⑤構建詞條文檔矩陣(Term-Document Matrix,TDM)并處理。TDM中列出了每個詞條在文檔中出現的頻次,可以去除頻次較低的詞條項,或進行其它與頻次有關的處理;⑥畫文本特征詞云。通過畫文本特征詞云直觀地展示文本挖掘結果。通過詞云展示,可以從大數據中發現熱點問題。
通過對表1中停機故障的描述字段進行文本挖掘,得到如圖2所示結果。通過圖2的分析結果可以看出,停機異常多是由鍋爐故障引起的,較為重要的原因是液體泄漏和電氣設備跳閘。通過對表1中停機和降出力兩類故障的描述字段對比分析,得到如圖3所示結果。通過對圖3的分析可以看出,停機異常的主要原因是鍋爐和汽機的液體泄漏及電氣保護,而降出力異常多是由風機和煤質差引起的。
3 關聯規則分析與應用
關聯規則是描述數據庫中數據項之間所存在關系的規則,即根據一個事務中某些項的出現可導出另一些項在同一事務中也出現,亦即隱藏在數據間的關聯或相互關系。關聯規則廣泛應用于金融、電子商務等行業。金融行業可以通過關聯規則挖掘出很多與客戶有關的關聯關系,從而為制定營銷策略提供依據。電子購物網站使用關聯規則挖掘,可設置商品促銷組合、進行商品推薦、定向投放廣告等。
關聯規則的代表算法有Apriori、FP-tree等。本文利用Apriori方法,對表1中的不同類別關系進行關聯分析,分析結果如圖4所示。由分析得到:運行設備故障導致停機故障,停機原因主要是鍋爐問題。
4 聚類分析研究與應用
聚類分析是利用科學的度量方法,將一組數據按照相似性和差異性分為幾個類別,目的是使屬于同一類別的數據相似性盡可能大,不同類別數據間的相似性盡可能小。聚類分析應用于許多領域,如商務智能、圖像模式識別、Web搜索和生物學等。將聚類分析方法應用于電站的故障數據分析分類及分析結果如下:
(1)按設備故障的宏觀類型對省份進行聚類。使用的數據字段有表2中的故障類別(停機、降出力、檢修)、省份兩個字段。根據分析結果,電力集團可發現各省份子公司設備故障存在相似之處,并據此制定分類管理政策。實行分類管理,可以節約人力、物力、財力等資源。
(2)按設備故障的宏觀類型對單位進行聚類。使用的數據字段有表2中的故障類別(停機、降出力、檢修)、單位兩個字段。如果兩個發電公司在故障類別上表現出較大的相似性,聚類算法會將它們聚為一類,電力集團可根據故障類別實現更細粒度的管理。
(3)按故障設備的容量對省份或單位進行聚類。使用的數據字段有表2中的容量、單位兩個字段。由于相同容量的發電設備在實現技術、制造單位方面可能存在相似之處,電力集團也可以通過這個分析結果對企業進行分類管理。
根據上述方法(1),使用Centroid聚類算法對數據進行聚類,得到如圖5所示的分析結果。由圖5可知,聚類結果分為7類。其中,內蒙古、黑龍江、山東、四川構成一類,湖北、陜西、云南、貴州、遼寧4個省份的故障發生情況具有較大相似性分為一類,江蘇、山西、寧夏、河北、河南、福建、新疆分為一類,安徽、青海等省份分為一類。
5 結語
數據挖掘技術已經用于電力系統分析并取得了一定的研究成果。在大數據背景下,其應用將更加廣泛和深入。本文從新的數據視角對電站設備故障進行分析,研究了文本挖掘、關聯規則、聚類等數據挖掘技術在電站設備故障分析中的應用,研究結論對電力企業管理決策制定和設備故障技術創新都有一定幫助。下一步將重點進行以下研究工作:①針對數據進行更加深入細致的剖析,發現其中更多的隱藏信息;②引入更豐富的數據挖掘技術應用于電力數據分析中。
參考文獻:
[1] 劉寶玲,何鈞,曾暄.嵌套式數據挖掘技術在電站工況分析中的應用[J].電站系統工程,2014(5):13-15.
[2] 邱鳳翔,司風琪,徐治皋.電站關聯規則的主元分析挖掘方法及傳感器故障檢測[J].中國電機工程學報,2009(5):97-102.
[3] 牛培峰,張澤,王懷寶.基于模糊聚類神經網絡的電站鍋爐故障診斷研究[J].微計算機信息,2010(7):40-42.
[4] ZHENG L K,FENG K,XIAO X Q,et al.Early warning of power plant equipment based on massive real-time data mining technology[J].ICFMM,2014(6):1487-1490.
[5] BAO A,PAN W G,WANG W H,et al.Advances in data mining and applications in power plants[J].ICEESD,2011(10):347-487.
[6] JIN T,FU Z G.Application of data mining in power plant unburned carbon in fly ash modeling[J].FSKD,2010(8):2761-2765.
[7] YANG P.Fault diagnosis system for boilers in thermal power plant by data mining[J].Journal of Information and Computational Science,2006(3):117-127.
[8] ZENG D L,YANG T T,CHENG X,et al.Application of data mining method in real-time optimal load dispatching of power plant[J].Zhongguo Dianji Gongcheng Xuebao,2010,30(4):109-114.
[9] LIU D P,ZHENG K T,YAN Q Q,et al.Application of data stream outlier mining techniques in steam generator safety early warning system of nuclear power plant[J].ICMTMA,2013(1):287-290.
[10] MU Y,XIA H,LIU Y K.Study on fault diagnosis technology for nuclear power plants based on time series data mining[J].Hedongli Gongcheng,2011,32(5):45-48.
[11] SHU Y F.Inference of power plant quake-proof information based on interactive data mining approach[J].Advanced Engineering Informatics,2007,21(3):257-267.
[12] OZKAN M B,KK D,TERCIYANLI F,et al.A data mining-based wind power forecasting method:results for wind power plants in Turkey[J].DaWaK,2013(8):268-276.
[13] COLAK I,SAGIROGLU S,DEMIRTAS M,et al.A data mining approach:analyzing wind speed and insolation period data in Turkey for installations of wind and solar power plants[J].Energy Conversion and Management,2013,65(1):185-197.
[14] OHANA I,BEZERRA U H,VIEIRA J P A.Data-mining experiments on a hydroelectric power plant[J].IET Generation,Transmission and Distribution,2012,6(5):395-403.
[15] MACIEJEWSKI H,VALENZUELA L,BERENGUEL M,et al.Analyzing solar power plant performance through data mining[J].Journal of Solar Energy Engineering,2008,130(4):0445031-0445033.
(責任編輯:杜能鋼)
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
語文教學之友(2016年5期)2016-06-15 12:15:44
電腦知識與技術(2016年5期)2016-04-14 13:51:02
信息通信技術(2015年6期)2015-12-26 01:16:46
中國中醫藥圖書情報(2015年3期)2015-09-09 20:49:23
