面向產出導向的大學英語教育新模式的構建*
2019-09-03 07:22:34余麗
計算機與數字工程 2019年8期
余 麗
(渭南職業技術學院基礎課部 渭南 714023)
1 引言
產出導向理論的前身是“輸出驅動假設”和“輸出驅動的輸入使能假設”。作為外語教學的“局部”理論,產出導向理論在“輸出假設”和語言學習的社會文化視角的基礎上,運用了SLA理論的研究成果[1~4]。本文提出了新的基于語料庫的產出驅動型教學理念,以提高大學英語單詞教學效果。
作為語言學教學的補充工具,語料庫可以提供豐富而真實的英語資料,充分保證學習者有充足的真實語料輸入,并提供真實的詞匯,幫助學生積極探索具有重要前提的目標詞的深層意義[5]。語料庫可以被廣泛使用的一個重要原因是它可以提供關聯搜索。與傳統的英語教學方法相比,使用語料庫練習英語的優勢在于擺脫了孤立學習詞匯的傳統方法。通過使用語料庫提供的關聯搜索學習單詞搭配和上下文語義,可以節省花在詞匯深度知識上的學習時間,并且可以快速掌握大量的詞匯信息[6~8]。通過對相同語境下同義詞挖掘等手段可以提高學習目標詞的速度,并為掌握相關詞匯和詞匯學習奠定良好的基礎。從而提高學生的詞匯知識水平和詞匯應用能力。
大學英語實踐訓練必須以英語語境為實際,必須精心運用大量的英語培訓教材,在實踐中可以獲得更理想的教學效果[9]。因此,高質量、大規模、多元化的語料庫對于推動大學教學的研究與應用具有重要意義。根據不同的標準,語料庫分類也各不相同。原始語料庫采用僅由手動注釋的文本數據集的形式。隨著信息能力的提高,研究人員建立了一個大規模的信息語料庫,通過信息收集和處理大規模的語料庫數據,將語料庫的語料從文本格式擴展到大學英語教學。大規模的信息語料庫可以廣泛應用于大學英語教學。隨著現代信息多媒體技術的發展,人們對英語活動性質的認識逐漸增強,出現了多語種語料庫。多模式語料庫是音頻、視頻和文本語料庫等信息的集合[10~11]。研究人員可以通過多種方式處理、檢索和統計相關研究的語料庫。本文從詞匯知識的深度入手,將基于語料庫的數據驅動學習方法與大學英語課堂教學實踐相結合,探索如何利用產出導向語料庫方法促進大學生詞匯深度的掌握,激發大學生自主學習英語的興趣。
2 基于信息技術的大學英語教學模式
2.1 大學英語實踐教學原則
大學英語實踐教學過程包括五個方面:教學語料庫文檔預處理;基于語料庫的詞表掃描;動態規劃方法以找到基于詞頻的最大分詞組合;利用隱馬爾可夫模型實現未注冊大學英語單詞的預測;以及教學效果的評估[12~13]。教學建模過程的具體內容如下。
用動態規劃方法找出最大概率路徑。根據已經形成的語料庫和要教學的句子的有向無環圖(DAG),基于語料庫的教學模式首先找到語料庫中單詞的不同組合的頻率,然后使用基于詞典的反向最大匹配原理來找到最大概率路徑按照動態規劃方法從待教學的句子的右側進行計算,最后得到分割組合的最大概率。對于大學英語的教學,句子長度為n,字符串組合為C=C1C2C3Cn,輸出字符串為S=S1S2S3Sm,其中m≤n。對于一個特定的字符串C,將會有與該任務對應的各種分詞程序S,并且應該從最大值的S概率中找到教學結果,并且這是最有可能的單詞所構成的大學英語教學句子。
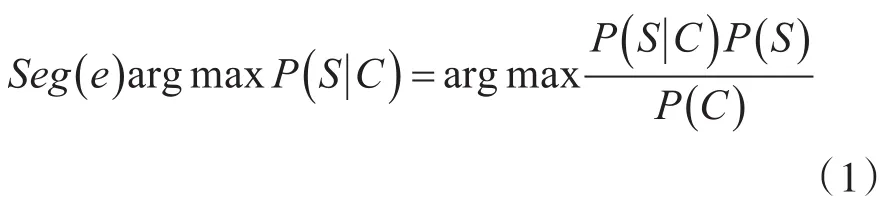
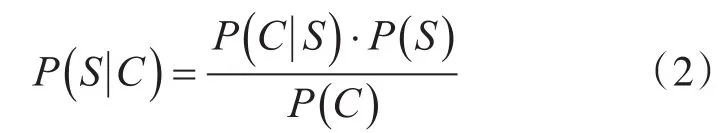
假定每個單詞之間的概率是上下文無關的,那么S概率是


這里,N是語料庫中單詞的總數。在求解動態規劃的過程中,并未預先生成所有可能的方案Si,并且具有最大值并且獲得,然后通過回溯方法直接輸出Si。
節點Ni的最大概率稱為節點Ni的概率:

其中,英語教學節點的末尾是Ni,它被稱為Sj和 Ni前體詞。這里,prev(Ni)是節點i的緊前詞集。StartNode(Wj)是Wj的起始節點,也是節點i的緊前節點。因此,在JIEBA教學中,對于n的長度,最后一個單詞是Sm,在教學英語教學句子的教學中,得到 P(Noden)=1:
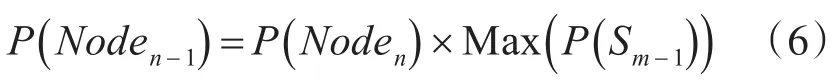
依此類推,可以得出最大的分割概率P(S)。
2.2 構建英語教學語料庫
通過對大學英語教學的分析,處理和分割,以前綴樹為思想構建了基于大學英語教學的語料庫。前綴樹是一個多樹結構,它具有三個基本屬性:1)根節點不包含任何字符,并且除根節點外的每個子節點都包含單個字符。2)從根節點到其他節點,連接經過該路徑的字符,即該節點對應的字符串。3)每個節點的所有句子都包含不同的字符。前綴樹的核心思想是使用字符串的公共前綴來減少字符串之間不必要的比較以提高查詢效率。基于前綴樹構建字典的優點是插入和查詢效率很高,并且都具有O(n)的復雜度,其中n是要插入或查詢的字符串的長度。同時,前綴樹中的不同關鍵字不會造成任何沖突,并且前綴樹可以按照字典順序對關鍵字進行排序。
大學英語語料庫是以前綴樹為代表的關鍵詞。它突出了大學英語語料庫的兩個特點。一個是它們具有獨立的中文詞匯的特點,另一個是大學英語的特點。在語料庫中,大學英語教學關鍵字存儲在路徑中,而不是節點。另外,如果同一路徑前綴部分的結構中有兩個公共前綴關鍵字,則是大學英語教學語料庫。通過對大學英語教學的統計和處理,完成了基于詞頻和詞性的大學英語教學語料庫建設,為后續基于語料庫教學模式的改進提供了有力的數據支持。本文認為基于前綴樹的字典構造方法可以提高插入的效率,并可以刪除和查詢英文字典,因為它可以擴展到其他教學英語字典的建設項目中。
2.3 基于語料庫方法的大學英語教學實踐步驟
通過語料庫在大學英語教學中的實驗,對英語教學存在的主要問題進行了以下研究:
1)英語教學利用現有的教學體系進行漢語教學。一方面,字典的教學沒有被黃金標準所證實,這帶來了錯誤的教學問題。另一方面,詞典的數據量超過30萬字,對大學英語教學沒有多大用處。一些大學英語培訓教學詞匯和語料庫從未出現,后續預測效果不好,整體識別效果約為86%。
2)在將該詞典引入產出導向語料庫詞典之后,盡管整體識別效果僅略微提高,但使用詞典模型的教學時間增加,并且HMM模型具有與預測未記錄詞相同的效果。
3)通過修改JIEBA的教學模式,采用基于英語教學詞典的方法,消除了HMM模型的引入,增加了模型初始化時間,略微提高了整體識別效果。但是,模型訓練時間過長,并沒有大學英語教學的共性。
針對以上問題,本文提出了一種新的大學英語教學方法,這是對JIEBA方法的改進,是一種基于概率英語模型的詞典教學方法。對于大學英語教學而言,一方面,大學英語教學的運行時間和準確性都優于JIEBA大學英語教學方法。另一方面,大學英語教學方法的實驗證明,運用英語概率統計模型和英語詞典教學可以提高英語教學效率的準確性。因此,它具有大學英語教學方法的普及性和普遍性。
本文采用標注語料庫和大學英語培訓庫的兩個語料庫數據集進行培訓。基于JIEBA的大學英語教學建模過程如圖1所示。
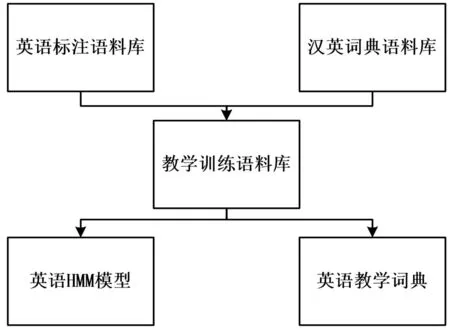
圖1 基于產出導向語料庫與訓練語料庫的實踐步驟
基于產出導向語料庫的教學模式的方法是將英語模型與英語詞典結合應用于大學英語語料庫教學。大學英語教學建模過程的具體內容是,在大學英語語料庫預處理教學時,首先判斷它是否是注冊詞匯。如果是注冊詞匯,則使用大學英語詞典詞將地圖掃描,并用DAG語句進入大學英語教學,從而實現初步的塊教學。然后,動態規劃方法可以計算塊的部分的最大概率來實現詞典中的教學。對于未注冊的詞匯,我們使用具有漢語識別能力的HMM模型進行預測。本文認為這種教學模式的方法可以擴展到大學英語其他教學模式。
3 基于信息技術的大學英語教學模式的驗證
3.1 英語教學方法評估
本文選擇國際計算語言學英語處理協會SIGHAN標準作為教學效果的評估,并用Perl腳本進行測試。SIGHAN標準的三個評估因子包括:準確率、召回率和F值[14]。

Ccorrec表示所有準確提取的候選關鍵字,Cextract表示提取的關鍵字總數。Cstandard是所有手動注釋的標準關鍵字答案總數。P=Presison表示準確率,r=Recall表示召回率。
3.2 英語教學法的驗證結果
本文的實驗環境是Windows10和Anaconda平臺,基于產出導向語料庫方法是基于Python語言實現的,并且用該語言實現了不同的教學對比實驗方法。本文的數據包括基于詞典教學方法、基于閱讀英語詞典的教學方法、基于產出導向語料庫的字典教學方法等15種大學英語教學方法。表1顯示了四種給定方法的教學效果。圖2顯示了不同模型的教學結果。

表1 不同模式的大學英語自動教學效果對比
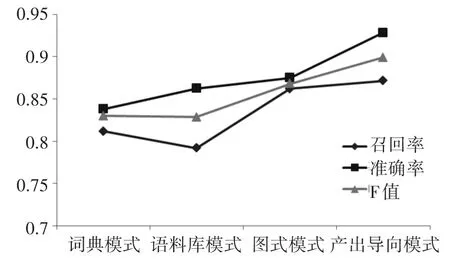
圖2 大學英語不同模式的教學效果
本文的測試程序是選擇8個大學英語教學與培訓語料庫,并將包含訓練語料的訓練語料詞典和另外7個語料庫一起作為測試語料庫,并將未注冊詞(OOV)的概率設定為15.2%。不同方法的測試結果如圖3所示。
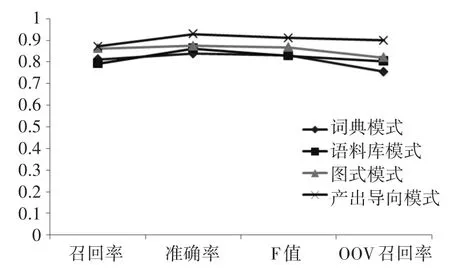
圖3 基于語料庫的大學英語教學效果對比
實驗結果表明,基于產出導向語料庫的方法在大學英語教學中的召回率、準確率、F值或OOV回憶率方面優于其他的方法。其中,產出導向語料庫方法的準確率為93.5%,OOV預測回憶率為90.7%,模型訓練速度為其他方法的十分之一。這說明該方法適用于大學英語教學實踐,結果更加準確,實驗發現使用英語模型和詞典可以使英語教學更加準確地教學,因此可以擴展到其他英語翻譯。
4 結語
本文研究了基于產出導向語料庫和信息技術相結合的大學英語教學模式。研究表明,通過基于產出導向語料庫和信息技術相結合的教學方法來提高大學生的詞匯知識、單詞運用能力、課堂教學效果和以及單詞的語境意義的理解是有效和可行的。學生可以通過上下文語境來總結目標單詞的靈活運用。基于產出導向理論的語料庫和信息技術相結合的英語教學方法優于傳統的英語教學方法。通過問卷調查表明,面向產出導向的教學方法有調動學生積極的英語學習態度。在大學英語詞匯教學中,引入面向產出導向的信息英語培訓教學方法,提高了大學生的英語學習能力和詞匯應用水平。同時,他們也將學生的被動學習轉變為主動學習。在教師激勵的指導下,學生一目了然地觀察豐富的語料和語境,找到自己對歸納詞匯的用法,探索英語學習的規律,提高大學生英語學習的自主性和積極性。
猜你喜歡
中學生天地(A版)(2022年6期)2022-07-14 12:39:26
大學(2021年2期)2021-06-11 01:13:12
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
海峽姐妹(2020年12期)2021-01-18 05:53:08
山東醫藥(2020年34期)2020-12-09 01:22:24
甘肅教育(2020年17期)2020-10-28 09:02:48
甘肅教育(2020年6期)2020-09-11 07:45:28
民主與法制(2020年16期)2020-08-24 06:54:50
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
瘋狂英語(雙語世界)(2016年4期)2016-06-05 08:37:12
