醫(yī)療大數(shù)據(jù)平臺研究與實踐*
2019-08-15 12:16:54向天雨王惠來
重慶醫(yī)學 2019年14期
關鍵詞:醫(yī)院
龔 軍,孫 喆,向天雨,王惠來△
(1.重慶醫(yī)科大學醫(yī)學數(shù)據(jù)研究院 401331;2.醫(yī)渡云(北京)技術有限公司,北京 100191;3.重慶醫(yī)科大學附屬大學城醫(yī)院信息中心 401331)
隨著信息時代的到來,互聯(lián)網(wǎng)技術、存儲技術、信息技術等在人類生產(chǎn)、生活中大規(guī)模的應用。各行各業(yè)采用的信息系統(tǒng)中產(chǎn)生了海量的數(shù)據(jù),并且仍在急速的增長。據(jù)統(tǒng)計,2006年全球共新產(chǎn)生約180 EB數(shù)據(jù),2011達到了1.8 ZB。而據(jù)互聯(lián)網(wǎng)數(shù)據(jù)中心(IDC)預測,到2020年,全世界數(shù)據(jù)總量將增長44倍,達到40 ZB[1]。大數(shù)據(jù)時代的到來將帶給各行業(yè)新一輪的變革,對各行業(yè)的發(fā)展將是一個新的契機。由于醫(yī)療行業(yè)的特殊性,醫(yī)療機構中保存著大量電子病歷數(shù)據(jù)和電子健康數(shù)據(jù)。但是,由于有關數(shù)據(jù)利用的規(guī)范還不夠標準,相關技術尚欠缺。此外,海量的醫(yī)療數(shù)據(jù)仍儲存在各醫(yī)院的數(shù)據(jù)庫中且各自互不聯(lián)通,數(shù)據(jù)的探索和利用十分困難。區(qū)域醫(yī)療大數(shù)據(jù)平臺的建設能夠解決信息孤島的問題,使區(qū)域內(nèi)的數(shù)據(jù)互聯(lián)互通。基于醫(yī)療大數(shù)據(jù)能夠?qū)φ鎸嵤澜邕M行研究,并從數(shù)據(jù)中挖掘出有價值的信息。
1 區(qū)域醫(yī)療大數(shù)據(jù)平臺的架構
區(qū)域醫(yī)療大數(shù)據(jù)平臺基于Hadoop環(huán)境框架搭建,在大量原始數(shù)據(jù)的基礎上對數(shù)據(jù)進行匯集、整合、清洗、計算及分析與應用,形成大數(shù)據(jù)平臺架構。
1.1醫(yī)療大數(shù)據(jù)平臺基礎架構 醫(yī)療大數(shù)據(jù)平臺基礎架構大致可以分為數(shù)據(jù)采集、數(shù)據(jù)存儲、數(shù)據(jù)處理、數(shù)據(jù)分析、數(shù)據(jù)應用及系統(tǒng)控制。基本思路:大數(shù)據(jù)平臺匯集醫(yī)院的業(yè)務數(shù)據(jù)進行分布式存儲,對業(yè)務數(shù)據(jù)進行脫敏、清洗、結構化、歸一和質(zhì)控等操作,以數(shù)據(jù)需求為維度存入分布式數(shù)據(jù)庫,并在其基礎上構建數(shù)據(jù)分析平臺和管理應用平臺。醫(yī)療的數(shù)據(jù)平臺基礎架構見圖1,從下到上為系統(tǒng)架構線路,各部分為平臺搭建相關系統(tǒng)名稱。
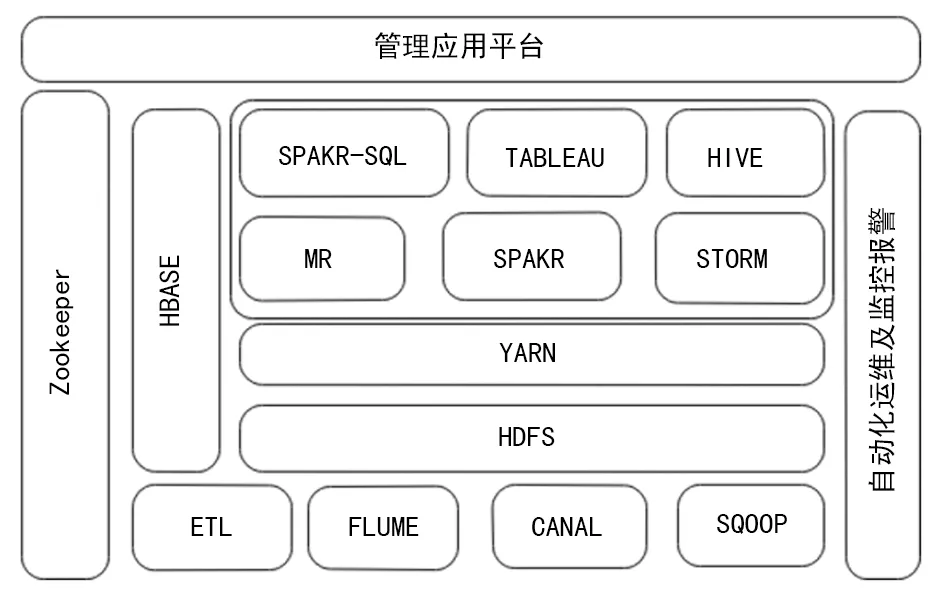
TABLEAU:一種專業(yè)數(shù)據(jù)可視化軟件
圖1醫(yī)療大數(shù)據(jù)平臺基礎架構圖
數(shù)據(jù)采集由ETL、FLUME、CANAL等技術實現(xiàn)。ETL批量采集醫(yī)院離線數(shù)據(jù),F(xiàn)LUME、CANAL采集醫(yī)院的業(yè)務系統(tǒng)實時數(shù)據(jù)。HDFS、HBASE技術相互協(xié)同實現(xiàn)數(shù)據(jù)的存儲功能。在資源管理器YARN和AZKABAN的協(xié)調(diào)下,MR、SPAKR、STORM技術分別對大批量數(shù)據(jù)和實時數(shù)據(jù)進行分布式計算。管理應用平臺通過R、SPAKR-SQL、數(shù)據(jù)挖掘等手段對數(shù)據(jù)進行分析利用。
1.2大數(shù)據(jù)平臺核心技術 大數(shù)據(jù)平臺核心技術圍繞著怎樣處理醫(yī)院的大規(guī)模數(shù)據(jù)展開,由于醫(yī)療行業(yè)的特殊性,區(qū)域醫(yī)療大數(shù)據(jù)平臺的建設將應用傳統(tǒng)的大數(shù)據(jù)技術并在此基礎上進行創(chuàng)新。
1.2.1多源異構數(shù)據(jù)的統(tǒng)一及標準化 目前全國共有上百家HIS系統(tǒng)廠商,由于各廠商運用的技術架構和處理的問題不同,其系統(tǒng)中數(shù)據(jù)標準和結構也多種多樣。大數(shù)據(jù)平臺需要采集HIS框架中的全量數(shù)據(jù)。因此,對多源異構數(shù)據(jù)的采集、匯總、結構化是建立醫(yī)療大數(shù)據(jù)平臺亟待解決的問題。區(qū)域醫(yī)療大數(shù)據(jù)平臺采用多源異構數(shù)據(jù)統(tǒng)一及標準化技術處理這些“結構復雜”的數(shù)據(jù)。
醫(yī)療大數(shù)據(jù)平臺根據(jù)數(shù)據(jù)的標準化程度和用途不用分為原始數(shù)據(jù)層、結構化層、應用層。原始數(shù)據(jù)層是HIS系統(tǒng)直接寫入到Hadoop集群的數(shù)據(jù),結構化層是原始數(shù)據(jù)經(jīng)過結構化、標準化的數(shù)據(jù),應用層是大數(shù)據(jù)平臺根據(jù)某項業(yè)務需求按不同緯度抽取結構化層數(shù)據(jù)而得到的集成數(shù)據(jù)。多源異構數(shù)據(jù)的統(tǒng)一及標準化技術作用于原始數(shù)據(jù)層和結構化層之間。多源異構數(shù)據(jù)的處理框架見圖2。
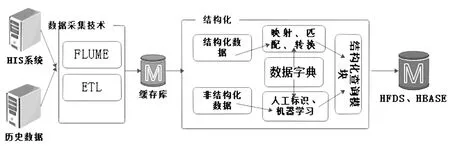
圖2 多源異構數(shù)據(jù)處理框架
多源異構數(shù)據(jù)的采集是運用LSA算法和redo-log分析對任意廠商提供的數(shù)據(jù)庫進行內(nèi)容識別。利用在醫(yī)院搭建的前置機將醫(yī)院的電子病歷等數(shù)據(jù)寫入到Hadoop的分布式文件系統(tǒng)(HDFS)中。針對于醫(yī)院產(chǎn)生的實時數(shù)據(jù),利用FLUME系統(tǒng)將數(shù)據(jù)寫入到Hadoop集群。把醫(yī)院多個系統(tǒng)產(chǎn)生的多種數(shù)據(jù)歸一成以下全面覆蓋醫(yī)院各系統(tǒng)、各場景的可擴展的數(shù)據(jù)模型,并對其進行結構化和歸一。醫(yī)院信息系統(tǒng)數(shù)據(jù)匯集圖見圖3,模型重構下面代表醫(yī)院HIS系統(tǒng)及各個子系統(tǒng),模型重構上面代表數(shù)據(jù)的分類及存儲形式。
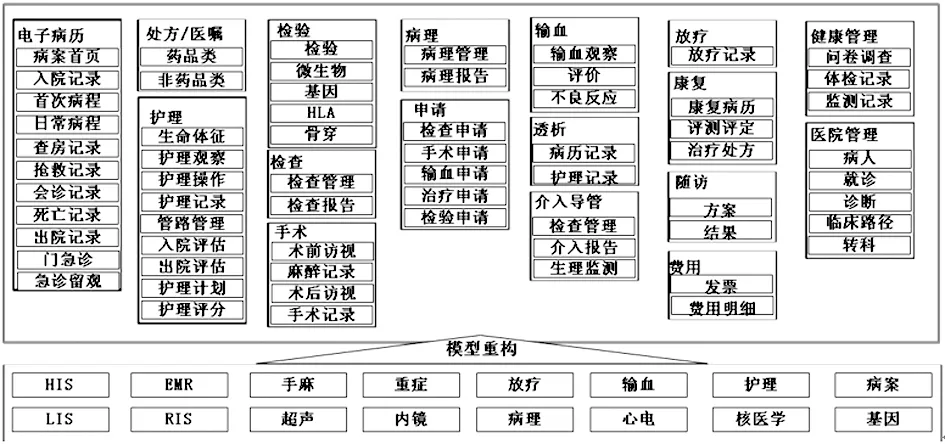
圖3 HIS系統(tǒng)數(shù)據(jù)匯集框架圖
數(shù)據(jù)按其結構化程度分為結構化數(shù)據(jù)、非結構化數(shù)據(jù)和半結構化數(shù)據(jù)。數(shù)據(jù)處理以醫(yī)院為單位,即對每個醫(yī)院都建立一套數(shù)據(jù)抽取的標準。這套標準是專業(yè)的ETL人員結合數(shù)據(jù)字典對該醫(yī)院每個字段建立相應的提取規(guī)則,并經(jīng)過多次質(zhì)控而形成的。數(shù)據(jù)字典來源于國內(nèi)外通用的數(shù)據(jù)標準,如HL7、CDA、衛(wèi)計委電子病歷基本架構與數(shù)據(jù)標準、ICD-9/10等,也有國內(nèi)外專家經(jīng)研究共同決定的標準。
對于結構化的數(shù)據(jù),主要處理“標準化”的問題。如出院記錄中的出院日期,醫(yī)生可能有多種寫法,在數(shù)據(jù)處理階段需要將其映射為標準的日期時間格式。又如出院診斷的胃癌分型,數(shù)據(jù)字典中結合國際標準與權威專家的評估把胃癌分為5個類型,從而把臨床醫(yī)生不標準診斷名稱全部標準化。
非結構化數(shù)據(jù)的處理首先是使其“結構化”。非結構化數(shù)據(jù)是由自然語言構成的文本,如手術經(jīng)過或一訴五史。非結構化數(shù)據(jù)使其結構化采用的技術主要是人工標識加機器學習。從Hadoop集群中采樣部分數(shù)據(jù)作為訓練集,利用人工標識技術將需要在自然語言中獲取的字段標出,機器學習算法對訓練集作分詞、詞性標注、命名實體識別、依存句法分析處理,建立非結構化數(shù)據(jù)結構化處理模型,從而應用于非結構化數(shù)據(jù)的處理。對已經(jīng)結構化的非結構化數(shù)據(jù)同樣可以進行歸一和標準化。其中,人工標識技術是按照電子病歷結構拆分成節(jié)點,對其重要的信息人工進行標注并以KV鍵值形式展現(xiàn)。非結構化數(shù)據(jù)處理流程見圖4。
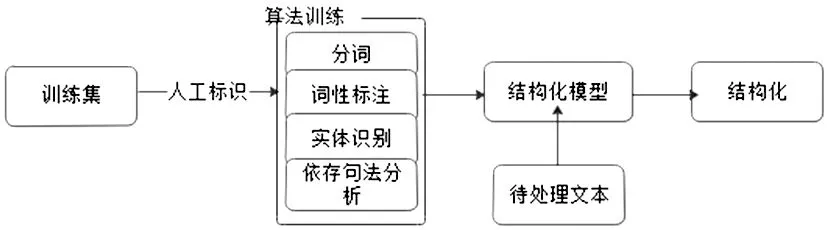
圖4 非結構化語言處理流程
1.2.2數(shù)據(jù)質(zhì)量監(jiān)控與評價技術 醫(yī)療大數(shù)據(jù)平臺匯集醫(yī)院信息系統(tǒng)的全量數(shù)據(jù),涵蓋各個子系統(tǒng),數(shù)據(jù)量多且復雜。由于醫(yī)院的數(shù)據(jù)產(chǎn)生于臨床醫(yī)生及護士的操作,在數(shù)據(jù)科學方面缺少專業(yè)知識及系統(tǒng)自身的問題等一系列因素,導致了大數(shù)據(jù)平臺的數(shù)據(jù)會存在空值、違規(guī)、錯誤等問題。多源異構數(shù)據(jù)統(tǒng)一及結構化技術能解決數(shù)據(jù)的匯集和標準的問題,但無法解決數(shù)據(jù)的完整性、一致性、準確性、穩(wěn)定性等問題。
數(shù)據(jù)質(zhì)量監(jiān)控技術的基本思路是通過數(shù)據(jù)質(zhì)量評價標準和定量定性的分析手段找出數(shù)據(jù)存在的質(zhì)量問題,指導數(shù)據(jù)優(yōu)化的實施。數(shù)據(jù)質(zhì)量控制的基本框架見圖5。

圖5 數(shù)據(jù)質(zhì)量評價技術框架
數(shù)據(jù)質(zhì)量監(jiān)控技術作用于結構化層或者應用層。根據(jù)質(zhì)量評價標準事先設立質(zhì)量控制指標和每個指標的閾值,質(zhì)控結果一旦超過了閾值則會針對該診斷進行報警,具體質(zhì)控指標見圖6。針對每個質(zhì)控指標建立對應的算法,例如:空值率=(字段缺失數(shù)+空值數(shù)量)/應有數(shù)據(jù)量×100%。根據(jù)指標和算法編寫SQL語言,提取HDFS中結構化全量數(shù)據(jù)和應用層數(shù)據(jù),分析結構化字段是否有數(shù)據(jù)缺失、數(shù)據(jù)不準確、信息自相矛盾等問題,匯總生成數(shù)據(jù)質(zhì)量評估報告,反饋給數(shù)據(jù)ETL人員。ETL部門根據(jù)此報告調(diào)整數(shù)據(jù)提取、清洗算法,再次提交質(zhì)控,從而使數(shù)據(jù)的合格率超過設定的閾值。
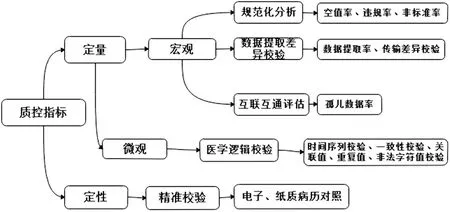
圖6 數(shù)據(jù)質(zhì)量控制指標
1.2.3智能患者索引技術 目前的HIS系統(tǒng)中,醫(yī)院通常把患者掛號時產(chǎn)生的門診號或者住院號當做患者主索引。由于目前每個區(qū)域都有多家不同性質(zhì)的醫(yī)療服務機構,如綜合醫(yī)院、社區(qū)衛(wèi)生服務中心、疾控中心、專科醫(yī)院等,各個醫(yī)院采用不同的HIS系統(tǒng)且都互不聯(lián)通,則產(chǎn)生的患者主索引也會有很大的差異。因此,在建立醫(yī)療大數(shù)據(jù)平臺時,無法根據(jù)現(xiàn)有的技術對數(shù)據(jù)以患者緯度進行統(tǒng)一。
區(qū)域醫(yī)療大數(shù)據(jù)平臺在利用Hadoop技術實現(xiàn)區(qū)域內(nèi)患者數(shù)據(jù)互聯(lián)的基礎上,對醫(yī)院的全量數(shù)據(jù)進行組織梳理,提取完整的患者信息,根據(jù)數(shù)據(jù)間的業(yè)務關系,以患者為維度將區(qū)域內(nèi)患者的數(shù)據(jù)形成一個整體,從而形成患者完整的就診檔案,通過主索引可以檢索出患者在各個地方的就診記錄。
智能患者主索引技術能讓醫(yī)院內(nèi)部仍舊使用住院和掛號時自動生成的住院號和門診號作為患者就診的唯一標識,在各醫(yī)院之間使用社保卡和身份證號碼作為識別患者身份的唯一標識。門診號和就診卡號能夠保證醫(yī)院作為醫(yī)療數(shù)據(jù)平臺的一個數(shù)據(jù)節(jié)點高效的運行,在互聯(lián)互通的基礎上保持自己的獨立性。區(qū)域醫(yī)療大數(shù)據(jù)平臺的控制中心提取出各個醫(yī)院HIS系統(tǒng)的患者身份信息(身份證號、社保卡號、地址等)建立患者索引,關聯(lián)患者在醫(yī)院的就診數(shù)據(jù)。其中,提取患者多種身份信息是為了保證無論患者采用什么方式掛號就診,系統(tǒng)都能采集到該患者的就診數(shù)據(jù)。智能患者索引架構圖見圖7。

EMPI:患者主索引
圖7智能患者索引技術圖
1.2.4大數(shù)據(jù)的分析技術 大數(shù)據(jù)分析技術是區(qū)域醫(yī)療大數(shù)據(jù)平臺建設的關鍵技術,是挖掘隱藏在海量數(shù)據(jù)中的知識達到數(shù)據(jù)價值化的重要手段。大數(shù)據(jù)分析技術基本思路:醫(yī)院、科研工作平臺及數(shù)據(jù)質(zhì)控平臺產(chǎn)生數(shù)據(jù)查詢和分析需求,使用數(shù)據(jù)分析引擎提取目標數(shù)據(jù),基于需求分析數(shù)據(jù)。
數(shù)據(jù)應用平臺與數(shù)據(jù)管理平臺和數(shù)據(jù)存儲框架之間搭建應用程序接口,將數(shù)據(jù)提取指令傳遞給管理平臺,經(jīng)分析后制訂數(shù)據(jù)提取任務,以同步和異步的提取方式提取目標數(shù)據(jù)。數(shù)據(jù)遷移路線:數(shù)據(jù)抽取器抽取HDFS數(shù)據(jù)為目標數(shù)據(jù)層,目標數(shù)據(jù)層由OLAP映射模塊轉(zhuǎn)化為OLAP數(shù)據(jù)層,OLAP數(shù)據(jù)層通過預計數(shù)等方式轉(zhuǎn)化為KYLIN數(shù)據(jù)立方體存入HBASE。OLAP數(shù)據(jù)層數(shù)據(jù)支持通過Spark進行離線異步查詢,KYLIN層數(shù)據(jù)支持在線同步查詢。數(shù)據(jù)分析技術支持除常規(guī)的統(tǒng)計分析外,還可以為數(shù)據(jù)挖掘、模式識別、機器學習、并行處理等先進大數(shù)據(jù)應用提供數(shù)據(jù)支持和平臺支持,從而得到更深層次的知識和領域信息。大數(shù)據(jù)平臺中數(shù)據(jù)分析的框架見圖8。

各部分:數(shù)據(jù)分析平臺的組成模塊
圖8醫(yī)療大數(shù)據(jù)分析平臺整體架構
2 區(qū)域醫(yī)療大數(shù)據(jù)平臺實踐
2.1重慶醫(yī)科大學醫(yī)療大數(shù)據(jù)平臺建設概況 截至2018年9月,重慶醫(yī)科大學與醫(yī)渡云(北京)技術有限公司合作建立的重慶醫(yī)科大學醫(yī)療大數(shù)據(jù)平臺已經(jīng)成功上線,共匯集了重慶醫(yī)科大學附屬大學城醫(yī)院、重慶醫(yī)科大學附屬兒童醫(yī)院、重慶醫(yī)科大學附屬第二醫(yī)院、重慶醫(yī)科大學附屬永川醫(yī)院等多家醫(yī)院數(shù)據(jù)。涵蓋18 049 608例患者就診數(shù)據(jù),36 109 970人次的就診數(shù)據(jù),時間跨度為1999-2018年。重慶醫(yī)科大學醫(yī)療大數(shù)據(jù)平臺匯集其附屬醫(yī)院業(yè)務數(shù)據(jù),開發(fā)ETL數(shù)據(jù)平臺對所有數(shù)據(jù)進行處理和質(zhì)控,通過查找國內(nèi)外權威的醫(yī)學知識和政策法規(guī)建立知識庫和標準庫。基于分布式數(shù)據(jù)庫建立索引庫,提升數(shù)據(jù)查詢效率。在分布式數(shù)據(jù)庫的基礎上建立數(shù)據(jù)應用平臺,探索數(shù)據(jù)的應用。重慶醫(yī)科大學醫(yī)療大數(shù)據(jù)平臺已經(jīng)運用到醫(yī)院管理、績效評價、醫(yī)學科研等多方面,其中,基于大數(shù)據(jù)平臺建立的重慶醫(yī)科大學科研數(shù)據(jù)平臺也已投入使用,基于此數(shù)據(jù)已發(fā)表高質(zhì)量科研論文多篇。重慶醫(yī)科大學醫(yī)療大數(shù)據(jù)平臺架構圖見圖9。
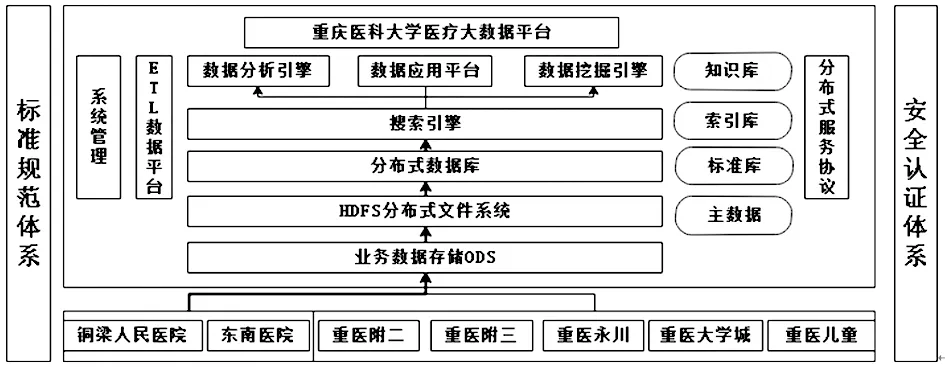
圖9 重慶醫(yī)科大學醫(yī)療大數(shù)據(jù)平臺架構圖
2.2醫(yī)院管理 醫(yī)療大數(shù)據(jù)平臺匯集某地區(qū)內(nèi)大部分醫(yī)院的診療數(shù)據(jù),由控制平臺全面管理、協(xié)調(diào)和控制。原衛(wèi)計委等相關部門根據(jù)大數(shù)據(jù)平臺匯集的數(shù)據(jù),通過各項指標宏觀地掌握該地區(qū)的醫(yī)療情況,據(jù)此有針對性地制訂政策進行調(diào)控。各醫(yī)院根據(jù)大數(shù)據(jù)平臺處理后的數(shù)據(jù)進行可視化分析,改進醫(yī)院的醫(yī)療服務質(zhì)量。
目前基于大數(shù)據(jù)平臺開發(fā)的醫(yī)院管理平臺在重慶醫(yī)科大學附屬醫(yī)院已成功上線并進行了應用,涵蓋醫(yī)院運行管理、DRGs績效管理、醫(yī)院等級評審、醫(yī)院機構對比等功能。大數(shù)據(jù)平臺采集電子病歷中病案首頁和費用信息,以DRGs相關指標對數(shù)據(jù)進行篩選并進行標準化,建立DRGs的數(shù)據(jù)集市,通過數(shù)據(jù)集市對費用中的住院總費用、檢查檢驗費、手術費、床位費等和出院診斷中的主要診斷、次要診斷、并發(fā)癥、手術操作等進行關聯(lián)性分析,從而建立DRGs費用庫。醫(yī)院管理人員就可以基于DRGs費用庫對各科室進行績效評價,科室也可以據(jù)此對醫(yī)生進行績效評價。目前,基于大數(shù)據(jù)的DRG績效評價正在重慶醫(yī)科大學附屬大學城醫(yī)院初步應用。
2.3科研應用 目前,重慶醫(yī)科大學基于醫(yī)療大數(shù)據(jù)的科研平臺已成功上線,具有“數(shù)據(jù)概覽”“病歷搜索”“知識全庫”“我的科研”等功能。數(shù)據(jù)概覽能對整個大數(shù)據(jù)平臺的數(shù)據(jù)進行全局的展示。病歷搜索對35 721 967份病歷進行搜索,以患者或病歷為維度進行展示。“我的科研”功能支持創(chuàng)建科研項目,按項目要求設置篩選條件,并支持導出數(shù)據(jù)。知識全庫主要匯集國內(nèi)外相關的醫(yī)學文獻,以中文核心期刊和Pubmed為主。重慶醫(yī)科大學目前正與國家不良反應監(jiān)測中心開展藥物不良反應主動監(jiān)測的項目,基于此平臺的數(shù)據(jù)在藥源性肝損傷和單種藥的不良反應研究上已經(jīng)取得成果。
3 小 結
隨著大數(shù)據(jù)時代的到來及信息技術在醫(yī)療行業(yè)的應用,各個醫(yī)院積累了大量的數(shù)據(jù),但僅針對一家醫(yī)院的數(shù)據(jù)進行研究不能稱之為大數(shù)據(jù),醫(yī)療行業(yè)需整合區(qū)域所有的醫(yī)療信息,以更多的數(shù)據(jù)反映更加真實的醫(yī)療情況。大數(shù)據(jù)平臺只是進行數(shù)據(jù)分析與應用的工具,要想充分利用這些數(shù)據(jù),需要對數(shù)據(jù)進行分析、挖掘和深層次的算法研究和利用人工智能技術,才能為醫(yī)療行業(yè)提供有價值的決策和科學研究,充分發(fā)揮數(shù)據(jù)的價值。最終讓醫(yī)療行業(yè)向效率高、技術強、費用低的方向發(fā)展。
猜你喜歡
兒童繪本(2018年10期)2018-07-04 16:39:12
中國衛(wèi)生(2016年10期)2016-11-13 01:07:44
中國衛(wèi)生(2016年3期)2016-11-12 13:23:36
中國衛(wèi)生(2016年3期)2016-11-12 13:23:20
中國衛(wèi)生(2016年2期)2016-11-12 13:22:26
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
中國衛(wèi)生(2015年8期)2015-11-12 13:15:20
中國衛(wèi)生(2014年11期)2014-11-12 13:11:28
中國衛(wèi)生(2014年8期)2014-11-12 13:00:54
中國衛(wèi)生(2014年7期)2014-11-10 02:33:12
