基于深度卷積神經(jīng)網(wǎng)絡和條件隨機場模型的PolSAR圖像地物分類方法
2019-08-07 00:42:28李衛(wèi)華秦先祥余旺盛
雷達學報 2019年4期
胡 濤 李衛(wèi)華 秦先祥* 王 鵬 余旺盛 李 軍
①(空軍工程大學信息與導航學院 西安 710077)
②(國防科技大學電子對抗學院 合肥 230037)
1 引言
極化合成孔徑雷達(Polarimetric Synthetic Aperture Radar, PolSAR)是一種先進的遙感信息獲取手段[1]。與單極化相比,它通過測量每個分辨單元在不同收發(fā)極化組合下的散射特性,更完整地記錄了目標后向散射信息,為詳盡分析目標散射特性提供了良好的數(shù)據(jù)支持[2]。PolSAR圖像地物分類的目的在于將圖像劃分成一系列具有特定語義信息的圖像區(qū)域,是PolSAR圖像理解和解譯過程中的重要內容[3]。
傳統(tǒng)的PolSAR圖像地物分類方法主要通過目標分解和統(tǒng)計分布來實現(xiàn)。極化數(shù)據(jù)的目標分解方法有很多,如Cloude分解[4]和Freeman分解等[5]。統(tǒng)計分布模型主要有Wishart分布[6]和K分布[7]等。Lee等人[6]將目標分解和分布模型結合,提出了-Wishart方法,有效提高了地物分類精度。然而,這類方法沒有考慮圖像的上下文信息,易受相干斑噪聲影響,因此很多研究者開始關注利用上下文信息的地物分類方法[3,8]。文獻[3]在融合極化特征的基礎上通過條件隨機場(Conditional Random Field, CRF)模型利用上下文信息,能夠得到區(qū)域一致性好的結果。上述方法利用的特征主要包括基于極化矩陣的組合變換、基于目標分解理論的特征參數(shù)和紋理特征等[9]。這些特征通常是針對具體問題進行設計,對先驗知識的依賴程度較高,在很多情況下其表征能力往往不盡人意。解決該問題的一種常用思路是從PolSAR圖像中提取多種特征向量堆疊成一個高維特征向量用于地物分類,但提取的高維特征往往包含大量冗余不相關信息,將導致部分特征向量的分類能力減弱或喪失[10]。因此,如何提取更具表達性的特征是當前提高圖像地物分類方法性能的關鍵途徑。
目前,深度學習技術在PolSAR圖像處理任務上的應用受到普遍關注,自編碼器[11](Auto Encoders,AE)、深度信念網(wǎng)絡[12](Deep Belief Network, DBN)和卷積神經(jīng)網(wǎng)絡[13](Convolutional Neural Network,CNN)等多種深度神經(jīng)網(wǎng)絡模型相繼用于PolSAR圖像處理,其中CNN在圖像處理中應用最為廣泛。近年來有很多學者將CNN用于PolSAR圖像地物分類[14-16]。由于CNN網(wǎng)絡輸入一般為實數(shù),在考慮相干矩陣各元素的基礎上,文獻[14]將PolSAR圖像的復數(shù)相干矩陣轉換為6維實向量來作為CNN模型的輸入,提升了地物分類精度。文獻[15]將CNN推廣到復數(shù)域,有效利用了PolSAR圖像通道間相干相位差蘊含的豐富信息。盡管上述基于深度學習的方法在地物分類精度上取得了顯著提升,但與基于傳統(tǒng)人工特征的方法相比,這些方法實現(xiàn)地物分類的速度普遍較慢。
針對圖像地物分類問題,一些學者設計了直接實現(xiàn)光學圖像地物分類的CNN模型,并展現(xiàn)出優(yōu)異的性能[17-19]。考慮到不同類型圖像之間往往存在共性,可認為,一個經(jīng)過大型數(shù)據(jù)量訓練好的CNN的前端網(wǎng)絡可以作為圖像特征提取的有效模型[20]。基于此并考慮到CRF的多特征和上下文信息利用優(yōu)勢,本文提出一種結合預訓練CNN和CRF模型的圖像地物分類方法。首先利用經(jīng)典的CNN模型-VGGNet-16來提取圖像深層次特征,再通過CRF對多特征及上下文信息有效利用來完成圖像的地物分類。
2 深度CRF模型
針對傳統(tǒng)圖像地物分類方法受限于人工特征表征能力不強的問題,本文提出一種基于深度CRF模型的圖像地物分類方法,采用VGG-Net-16提取圖像深度特征,將提取到的特征用于訓練CRF模型,實現(xiàn)圖像地物分類。具體流程如圖1所示,主要包含圖像預處理、深度特征提取和分類3個階段。
2.1 極化SAR圖像預處理
對于PolSAR數(shù)據(jù), 每個像素點用T矩陣的9維向量來表示如式(1)
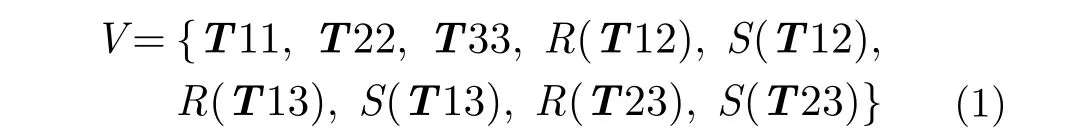

圖1 深度CRF模型流程圖Fig. 1 The flow chart of deep CRF model
2.2 深度特征提取
VGG-Net-16[19]是一種用于實現(xiàn)圖像分類任務的卷積神經(jīng)網(wǎng)絡。其中的“16”表示該模型需要學習參數(shù)的層數(shù)。VGG-Net-16主要由5個卷積層(conv)(共13層)和3個連接層組成。其中,從conv1到conv5每組卷積層分別包含2, 2, 3, 3, 3層卷積,每個卷積層都使用尺寸為3×3的卷積核。在ImageNet數(shù)據(jù)集上訓練后,VGG-Net-16中每個卷積層都可以作為一個特征提取器,提取目標不同層級的特征表達。
VGG-Net-16模型要求輸入圖像尺寸為224×224,因此,需要將其分割為多個不重疊的尺寸為224×224的小圖像,再將這些圖像輸入到VGGNet-16中提取深度特征,其中,VGG-Net-16是在ImageNet數(shù)據(jù)集上已經(jīng)完成預訓練的網(wǎng)絡。當輸入圖像尺寸小于224×224時,需要在輸入數(shù)據(jù)的邊界進行補0操作。將所有小圖像利用VGG-Net-16提取完特征后,由于VGG-Net-16模型中的池化(pooling)操作,會使得提取到的深度特征的尺寸小于輸入圖像。采用的CRF模型需將提取到的特征與輸入圖像每個像素點逐一對應,因此將VGG-Net-16模型中提取到的特征圖采用雙線性插值方法上采樣到原圖像大小,然后將這些特征圖重新拼接,最終得到與實驗圖像同尺寸的多維特征圖,即可認為,為實驗圖像中的每個像素點提取到多維深度特征。在VGG-Net-16前5層提取的特征都是由多張?zhí)卣鲌D組成,故前5層都可作為特征提取層。VGG-Net-16后3層為全連接層,提取到的特征都是1維列向量,不適合作為訓練本文CRF模型的特征。
2.3 CRF模型建立

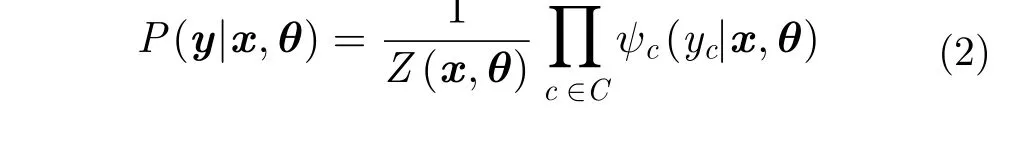
勢函數(shù)階數(shù)的確定與實驗需求緊密相關,階數(shù)越高,可表征越大范圍節(jié)點間的相關性,但模型復雜度也會隨之提升。常用做法是僅定義單位置和雙位置勢函數(shù)[3,24],既可兼顧性能,模型復雜度也不會過高。因此,式(2)可改寫為


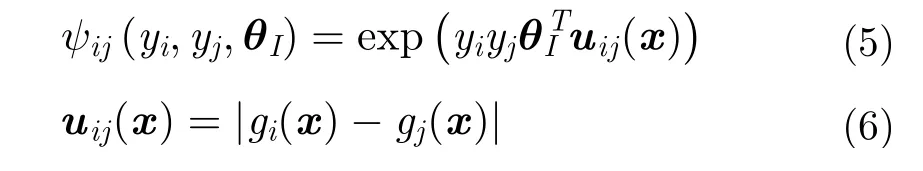
3 實驗設計與結果分析
為驗證本算法有效性,在實驗中主要選取以下與文中方法進行對比:基于Cloude分解和Freeman分解所得特征的CRF分類(簡稱方法1);基于Freeman分解和協(xié)方差矩陣對角線元素所得特征的CRF分類(簡稱方法2);將上述兩種方法中的特征串聯(lián)融合所得特征的CRF分類(簡稱方法3);基于Freeman分解和協(xié)方差矩陣對角線元素所得特征的SVM分類[24](簡稱方法4);一種基于CNN的方法[14](簡稱方法5)。
表1給出了實驗中傳統(tǒng)方法用到的特征類型。本文方法選擇提取VGG-Net-16模型conv5-3層特征進行對比實驗。有關不同卷積層特征對算法性能的影響將在第3.3節(jié)進行分析。本文方法的特征提取在MatConvNet[26]深度學習平臺上完成。參數(shù)估計過程中的最大迭代次數(shù)設置為1000次。分類性能綜合評估指標為總體分類精度(Overall Accuracy,OA)、Kappa系數(shù)[9]、訓練時間和測試時間。為減少相干斑噪聲的影響,本文實驗數(shù)據(jù)經(jīng)過Lee濾波處理[27]。所有實驗在配置為Intel Core i7 2.80 GHz處理器和8 GB內存的計算機上完成。
3.1 基于Flevoland數(shù)據(jù)的實驗結果
第1個實驗數(shù)據(jù)是1989年NASA/JP實驗AIRSAR系統(tǒng)獲得的L波段完整PolSAR圖像的一部分,該數(shù)據(jù)被廣泛用于評估PolSAR圖像地物分類算法性能。圖2(a)為其Pauli RGB合成圖,其尺寸為750×1024像素。包括11類作物,分別為:豆類、森林、油菜籽、裸地、土豆、甜菜、小麥、豌豆、苜蓿、草地和水域。真實地物分布參考圖如圖2(b)所示,空白區(qū)域為未標記類別,選取10%的有標記數(shù)據(jù)用于訓練,所有帶標記的數(shù)據(jù)作為測試數(shù)據(jù)。實驗結果如圖2所示。

表1 傳統(tǒng)方法中用到的特征Tab. 1 The features used in the traditional methods
從圖2可見,本文所提方法相對其他4種基于傳統(tǒng)特征方法明顯錯分較少。方法1對油菜籽和豌豆分類效果較差,方法3對油菜籽和水體的分類效果較差。方法4對土豆的分類效果較差。方法2相較于方法1、方法3和方法4取得了更好的分割效果,其中方法2和方法4采用相同的特征,而利用CRF分類的方法2精度要高于利用SVM分類的方法4,說明CRF模型對多特征和上下文信息的利用有助于提高分類精度。而從目視效果上看,本文方法要優(yōu)于方法2,方法5的分類效果最好。
表2給出了定量評估數(shù)據(jù),可見本文所提方法取得了高于傳統(tǒng)方法的總體分類精度0.905和Kappa系數(shù)0.890,所有類別的分類精度都在0.8以上,大部分在0.9以上。并且在苜蓿、小麥、甜菜、油菜籽、豌豆和草地均取得了高于傳統(tǒng)方法的分類精度。此外,從表2可見,與方法5相比,本文所提方法的總體分類精度稍低,這可能是由于本方法所用的特征提取模型是預訓練模型,對總體分類精度存在一定程度的影響,但本方法需訓練的參數(shù)少于方法5,訓練時間和測試時間都遠比方法5短,說明本文所提方法具有更高的實時性。

圖2 Flevoland數(shù)據(jù)分類結果對比圖Fig. 2 Comparison of Flevoland data classification results
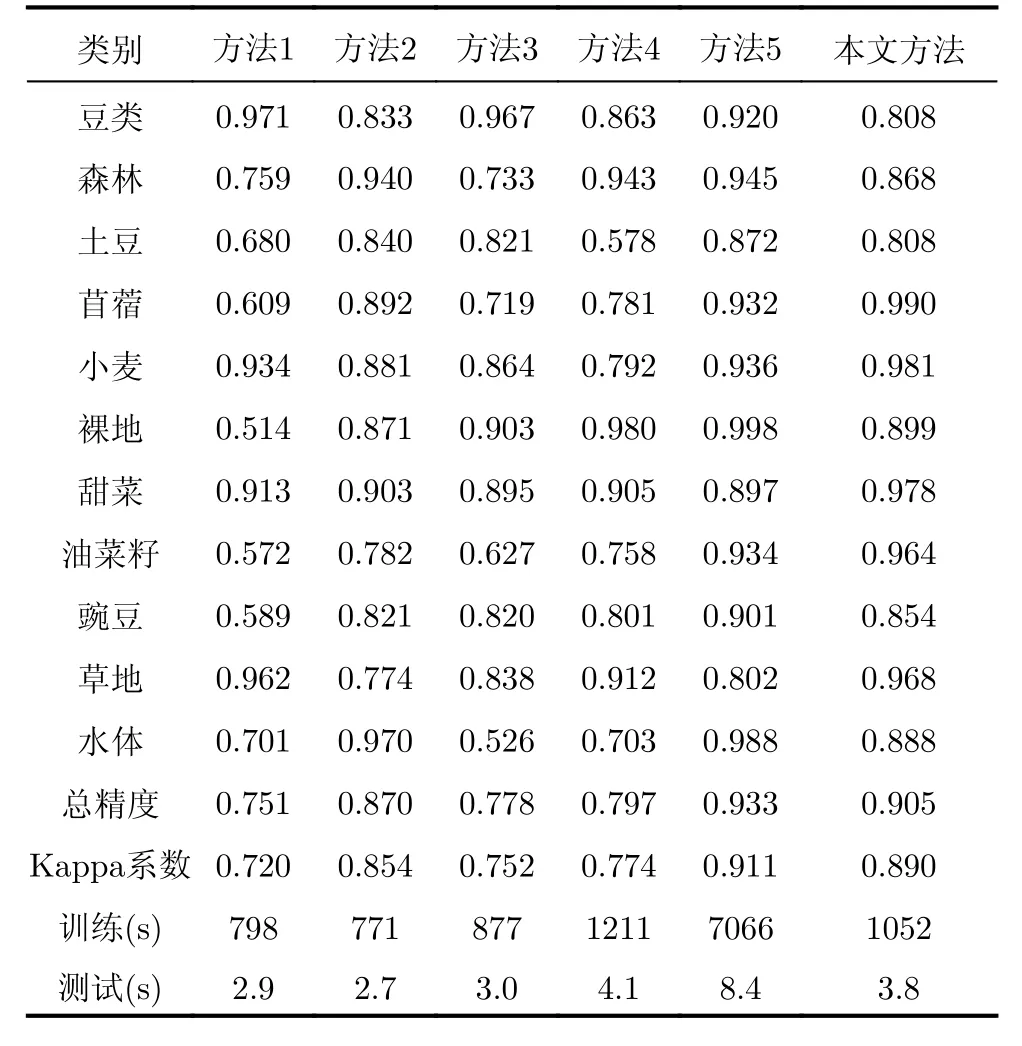
表2 Flevoland數(shù)據(jù)分類精度Tab. 2 The classification accuracy of Flevoland data
3.2 基于Oberpfaffenhofen數(shù)據(jù)的實驗結果
為進一步驗證本文所提方法提取深度特征的有效性,在Oberpfaffenhofen數(shù)據(jù)下將本文方法與3種基于傳統(tǒng)特征和CRF模型的方法進行對比。圖3(a)為Oberpfaffenhofen數(shù)據(jù)Pauli RGB合成圖,圖像的大小為1300×1200像素。真實地物分布參考圖如圖3(b)所示。包括3類語義類別:建筑區(qū)域、林地和開放區(qū)域。空白區(qū)域為未標記類別,實驗中選取10%的有標記數(shù)據(jù)用于訓練,所有帶標記的數(shù)據(jù)作為測試數(shù)據(jù)。實驗結果如圖3所示。
從圖3可見,本文所提方法整體效果優(yōu)于其他3種對比方法。對于開放區(qū)域,本文方法最好,由于開放區(qū)域的散射機制與建筑區(qū)域相對接近,其余3種方法一定程度上都將其錯分為建筑區(qū)域,如圖中三角形區(qū)域所示。本文方法由于提取的是圖像不同層次的抽象特征,有效地避免了這種現(xiàn)象。對于建筑區(qū)域,本文同樣得到最好的分割效果,其余3種方法均不同程度將該區(qū)域錯分為林地或開放區(qū)域,如圖中橢圓區(qū)域所示。對于林地區(qū)域,3種方法均取得較好結果,其中方法3的效果最差,可能是由于融合的高維特征存在一定冗余,對該類別的區(qū)分性低于其他特征。
本文計算了各個方法中每類地物分類的準確率,并用總體分類精度和Kappa系數(shù)進行綜合評估,如表3所示。從表中可見,本文方法取得了最高的分類精度0.903和Kappa系數(shù)0.834,并且在建筑和開放區(qū)域上的分類精度均為最高。
從上面兩個實驗結果可見,將多組特征串聯(lián)所得高維特征的表征能力可能低于低維特征的表征能力。例如,在第1個實驗中,方法3的性能要低于方法1,在第2個實驗中,方法3的性能要低于方法2。說明提取的高維特征包含了冗余信息,導致了部分特征向量的分類能力減弱。而本文所提方法在兩組實驗中均取得了最優(yōu)的分類結果,說明CNN特征相對于傳統(tǒng)特征具有更強的表征能力,利用CNN特征可以有效提升分類性能。

圖3 Oberpfaffenhofen數(shù)據(jù)分類結果對比圖Fig. 3 Comparison of Oberpfaffenhofendata classification results

表3 Oberpfaffenhofen數(shù)據(jù)分類精度Tab. 3 The classification accuracy of Oberpfaffenhofen data
3.3 VGG模型特征層選擇
為了比較VGG-Net-16模型中哪一層特征更具表達力,以便選擇合適的特征提取層,提取conv5-3,conv4-3, conv3-3, conv2-2和conv1-2層特征進行實驗并做精度評價,在Oberpfaffenhofen數(shù)據(jù)集下進行測試的結果如圖4所示。實驗中,采取同樣的方式將實驗數(shù)據(jù)分割成多個尺寸為224×224的不重疊的圖像,再輸入到VGG-Net-16模型中提取特征。特征提取在MatConvNet深度學習平臺上完成。VGG-Net-16前5層中,每層提取的特征都是由多張?zhí)卣鲌D組成,如conv2-2層的特征為128張尺寸為112×112的特征圖,插值到輸入圖像大小后,得到128張尺寸為224×224的特征圖,相當于對輸入圖像的每一個像素點提取一個128維的特征向量。

圖4 不同層特征分類精度對比圖Fig. 4 Accuracy comparison results of different layer classification results
從圖4的分類結果精度對比圖可見:在Oberpfaffenhofen數(shù)據(jù)下,隨著卷積層層數(shù)深度增加,分類精度呈上升趨勢,在conv5-3層達到最高。這是因為VGG-Net-16模型中更深層特征更抽象,具有更高層次的語義信息。此外,conv1層特征對應的分類精度遠低于其他幾層特征對應的分類精度,甚至低于一些利用傳統(tǒng)特征的方法,這是因為第1層提取的特征都是些低級特征,如邊緣、角點等。因此,在本文所提方法中,VGG-Net-16模型特征提取層選擇conv5-3層。由于Oberpfaffenhofen數(shù)據(jù)與Flevoland數(shù)據(jù)中的圖像存在一定共性,因此不再針對Flevoland數(shù)據(jù)進行不同層特征精度比較,同樣選擇conv5-3層作為特征提取層。
4 結論
本文提出一種基于深度卷積神經(jīng)網(wǎng)絡和條件隨機場的PolSAR圖像地物分類方法。本方法利用卷積神經(jīng)網(wǎng)絡提取深度特征,再通過條件隨機場對多特征及上下文信息有效利用來實現(xiàn)PolSAR圖像地物分類。實驗結果表明,在利用VGG-Net-16模型提取特征進行圖像地物分類時,conv5-3層為最有效的特征提取層。此外,與3種利用傳統(tǒng)經(jīng)典特征的方法相比,本文得到了精度最高的分割結果,說明了本文所提方法的有效性。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
