細長彈性飛行器飛行動力學并行計算及優化研究
2019-06-21 07:46:34胡斌星李新國常武權
振動與沖擊 2019年11期
胡斌星, 李新國, 常武權
(1.西北工業大學 航天學院,西安 710072; 2.中國運載火箭技術研究院,北京 100076)
隨著對飛行器性能要求的不斷提高,飛行器自重比例逐步減小,彈性結構與其氣動、控制系統的耦合問題愈發嚴重,箭體在飛行過程中振動特性對其動態性能影響較大,對其準確表征逐步成為新一代飛行器設計的核心技術內容之一。由于火箭和導彈的長細比較大,以往常用方法是將箭體簡化為柔性梁分析;即使在有助推器的情況下,仍將助推器也視為一維梁與芯級組成空間梁系,基于特定的小偏差增量模型分析彈性振動對控制系統的影響[1];在新一代高超聲速飛行器的分析中也常以自由梁或懸臂梁建模分析與氣動、推進系統的耦合關系[2]。在設計驗證階段,通常將彈體離散成若干個梁單元或彈簧-質點(站點)模型,以此為基礎建立飛行器模態信息并提前裝訂至仿真計算機;但在實際工程應用中,由于材料、飛行器幾何外形的不規則以及簡化過程模型精度損失等問題的影響,過少的站點數已無法準確表達飛行器自身的彈性特性,而過多的單元數已無法滿足仿真過程的實時性要求。為快速的在仿真過程中獲取較精確的振動特性以便為姿態控制設計、響應分析提供參考,勢必采用并行計算的方法解決[3]。一些文獻提出利用OpenMP(Open Multiple Processing)或MPI(Multi Point Interface)技術提高計算速度,但OpenMP技術從理論上僅能提供當前計算機CPU核心數的最大加速性能,其受線程創建及任務分發的影響較大;而MPI在仿真中由于通信的延遲其實時性并不良好,且兩者維護上存在著較大的不便[4-5]。較之單純的CPU集群運算,GPU(Graphics Processing Unit)的帶寬更高、延遲更低、單位浮點運算的功耗更低,故現有的超級計算機將GPU作為協處理器以提升浮點運算能力。而自2007年NVIDIA公司正式發布統一計算設備架構(CUDA, Compute Unifed Device Architecture)并行計算技術以來,由于其采用標準C語言擴展的API形式大大降低可開發門檻,通過PCIE總線與CPU連接可以保證一定的實時性,故近年來在有限元的顯式動力學[6]、隱式動力學[7]、結構力學[8]、分子動力學、方面有著廣泛應用,并已成為高性能計算領域的重要分支。Fleischmann等[9]就MPI和OpenMP 及CUDA結合,在矩陣不完全LU分解和子空間迭代法求解特征值問題的加速效果做了非常詳細的對比,驗證了GPU在數值計算方面能取得明顯的性能提升;Cheng等[10]對克里金插值的GPU加速算法做了詳盡闡述,說明了插值計算GPU加速的可能性;李濤等[11]實現了基于線程池的GPU任務并行計算模式,就矩陣運算等一般性的運算做了驗證分析,但并未針對GPU特性實現細粒度的性能優化。在多GPU運算方面,賴劍奇等實現了多GPU的并行可壓縮流求解器,驗證了多GPU良好的可擴展性;Gao等[12-13]也發表了大型稀疏線性系統求解的多GPU解算方案,可上述文獻皆未關注除解算器以外的粗粒度并行問題,僅在有限元法解算中實現了加速,設計適宜實時仿真的多GPU架構并未闡述。因此本文根據以上研究內容,從GPU硬件特點著手,在單臺多GPU的工作站上設計了細長體彈性飛行器彈性模塊異步并發并行計算的架構設計,實現了基于算法的GPU的動態性能優化,首次提出了動態分配線程塊的八叉樹構建及索引方法用以實現多線程快速索引氣動數據,對不同計算規模的性能進行系統分析。對并行程序設計及優化,三維數據快速索引插值方面具有重要指導意義。
1 細長體飛行器振動響應算法分析
為便于說明細長體彈性飛行器振動響應算法的并行實現,在此結合算法分析計算流程,并分析各步驟的計算量及比例,以便決定并行算法設計的重點。如前所述,將全彈體簡化為非均質梁模型,以EJ(x)表示彎曲剛度,m(x)表示線質量,l表示參考長度,q(x,t)表示作用在梁元上的橫向分布外力,忽略梁元的轉動慣性,且在無阻尼的情況下,依據梁的彎曲理論和力矩平衡方程,得到梁的彎曲振動微分方程
(1)
當q(x,t)=0時得到該振動微分方程的通解部分;通過自由梁兩端的邊界條件可得特解;把梁的受迫振動展開成固有振型的級數形式如下
y(x,t)=yc(t)+θ(t)(x-xc)+
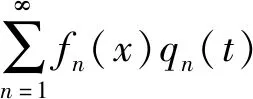
(2)
鑒于單位長度分布外力可表示為乘積q(x,t)=q(t)P(x),把式(2)代入式(1)對x積分變換后得
(3)
式(3)中等式右端廣義力為
式(3)中第一項表示質心運動方程,第二項表示繞橫軸的旋轉運動方程。當給定外力q(t)P(x)時,可以由最后一組方程求得梁彎曲振動的廣義坐標。經推導,可將細長體飛行器的法向和橫向彈性振動方程數值解算步驟歸納為
(4)
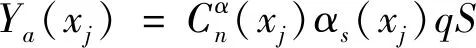
(5)
Qfayi=Ya(xj)×fiy(xj)
(6)
Qfayi+Py+Feiy+Fpy+Fdy
(7)
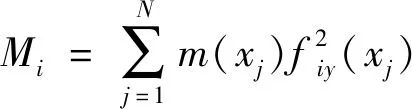
(8)
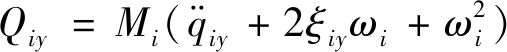
(9)
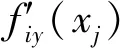

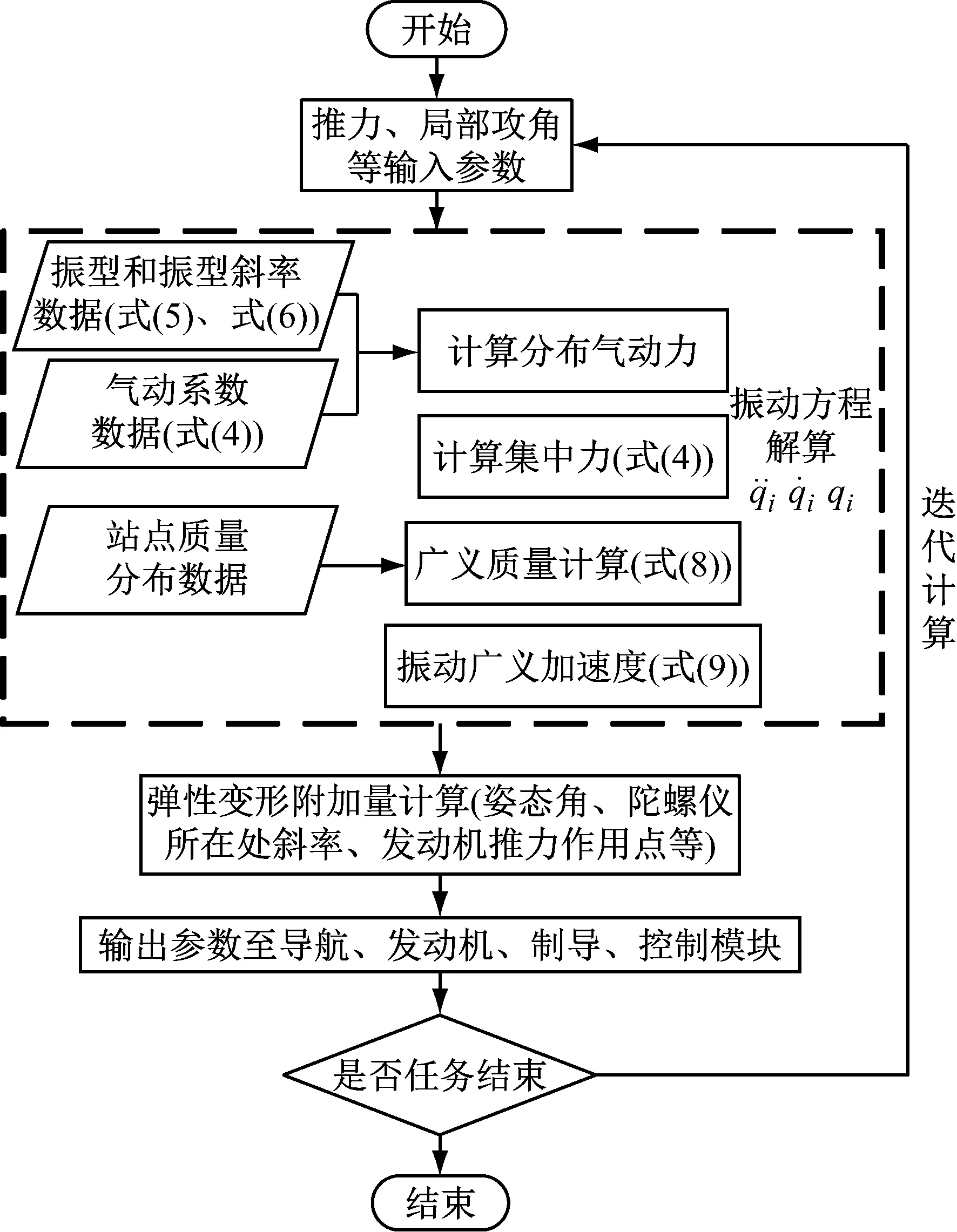
圖1 飛行動力學仿真中彈性模塊計算流程
表1 不同站點數CPU版插值計算耗時及占計算總時長百分比
Tab.1 Interpolation calculation accounts for the total length of calculation using different sites

站點數20080032001280051200CPU耗時/ms1.382.4718.676.9269.4占計算總時長百分比/%6177879195
2 基于CUDA的算法設計及架構優化
2.1 廣義質量的并行算法設計
如上節所述,廣義質量的計算包含兩次長度為N的向量元素相乘和長度為N的向量歸約問題[14]。在本文中每個線程完成元素相乘的工作后,選用交錯配對的歸約算法[15]。交錯配對歸約算法與鄰近配對歸約算法相比,其計算的跨越步長不再是相鄰線程的數據,而是為線程塊大小的一半起始,每次迭代減少一半,因此與鄰近配對歸約算法相比,交錯配對算法每次迭代減少的工作線程不發生變化,使得盡可能的減少了線程束的失速。經測試表明,交錯配對歸約算法較鄰近配對歸約算法,在不同計算規模下有1.34倍~1.69倍的加速比。
2.2 氣動系數插值計算的并行算法設計
針對此類問題,通常用八叉樹描述三維空間的樹狀數據結構:樹中任意節點的子節點數要么為零要么為八,通過增加每個節點指針的數量(由兩個變為八或九個)和每次索引后的計算量(由左右邊界的判斷變為三方向上邊界與中點的判斷)減少索引深度,以達到提高速度的目的。而NVIDIA公司提供了動態并行API(CDP,CUDA Dynamic Parallelism API)并演示了通過遞歸的方式構建四叉樹的示例,故本文以此為模板構建氣動數據表的八叉樹。其GPU內動態創建線程塊的流程圖如圖2所示:在獲取數據表數據大小后確認八叉樹的深度;待滿足建表要求后,將父線程塊一分為八并以線程束為基本單位統計每個子塊內的點數;待線程束完成其計算后將相關數據傳與八個子線程塊,以此遞歸直至不滿足條件為止。
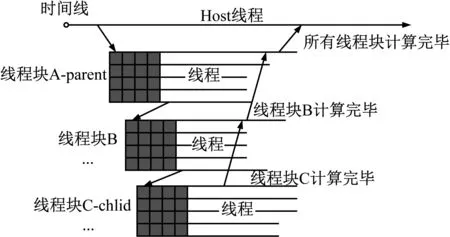
圖2 動態構建線程塊示意圖
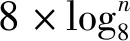
2.3 基于異步消息的并行架構優化
國內外針對多機并行計算時多選用MPI實現數據的交互及同步[18],但在單機多GPU算例中未詳細闡述針對所研究對象的程序架構優化問題。在以上文獻中均使用的同步函數,使得設備在完成任務前不會將控制權交還主機線程,導致主機線程的阻塞。故在此可通過粗粒度的CPU和細粒度的GPU兩方面著手實現并行程序的性能優化:前者實則為程序主架構的優化,通過開啟一個有著若干線程的線程池,初始化階段構建一個任務結構體,內含CUDA計算的識別號、所使用的設備號、流指針、主機端數據指針及設備端數據指針,在程序初始化時根據當前所擁有的設備數將計算任務分發給不同的線程,運用異步方式始終保證CPU的控制權,直至GPU運算完成觸發回調函數即可按邏輯進行下一步的計算;而后者則可通過某個計算能力2.x以上的GPU在執行計算時同時進行數據的傳輸,使GPU得執行引擎與存儲引擎可同時工作[19]。
鑒于在本文數值解算過程中彈性振動方程解算模塊解耦為軸法橫三個方向的獨立計算,且沒有相互耦合的中間變量,程序主架構的設計如圖3所示。主線程維護一個先進先出的隊列完成任務分配并追蹤線程池內從線程的任務進度和狀態,而線程池內從線程負責完成實際的GPU函數調用并產生局部解算結果。
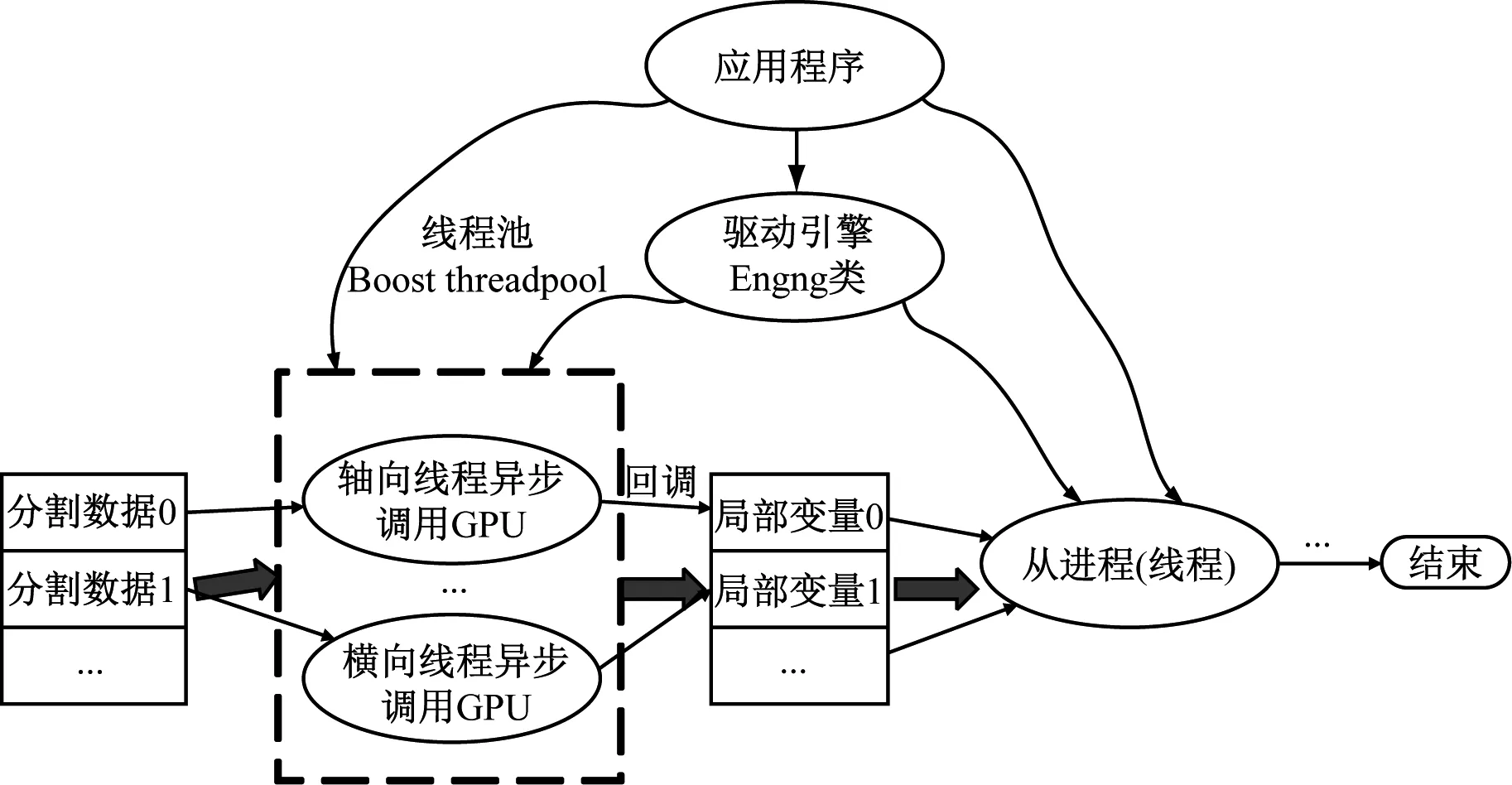
圖3 程序多線程異步架構示意圖
而圖4演示了某個線程內GPU運算的時序對比。GPU采用同步運行時,一旦傳輸數據量較大可能導致GPU設備的空置。若像圖中在初始化階段進行數據分割,即將某一方向中的原始數據劃分為若干個小塊,以流的形式可以實現數據傳輸的隱藏以提高計算效率。同時自Kepler架構后HyperQ技術使得運行多個CPU核或線程在某一GPU上啟動任務,以多個工作隊列的形式提高了GPU的利用率,避免了偽依賴。其偽代碼如下
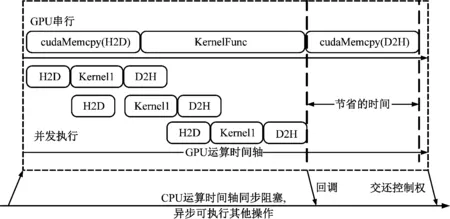
圖4 串行與異步流形式運算時序對比圖
1) CreateStream
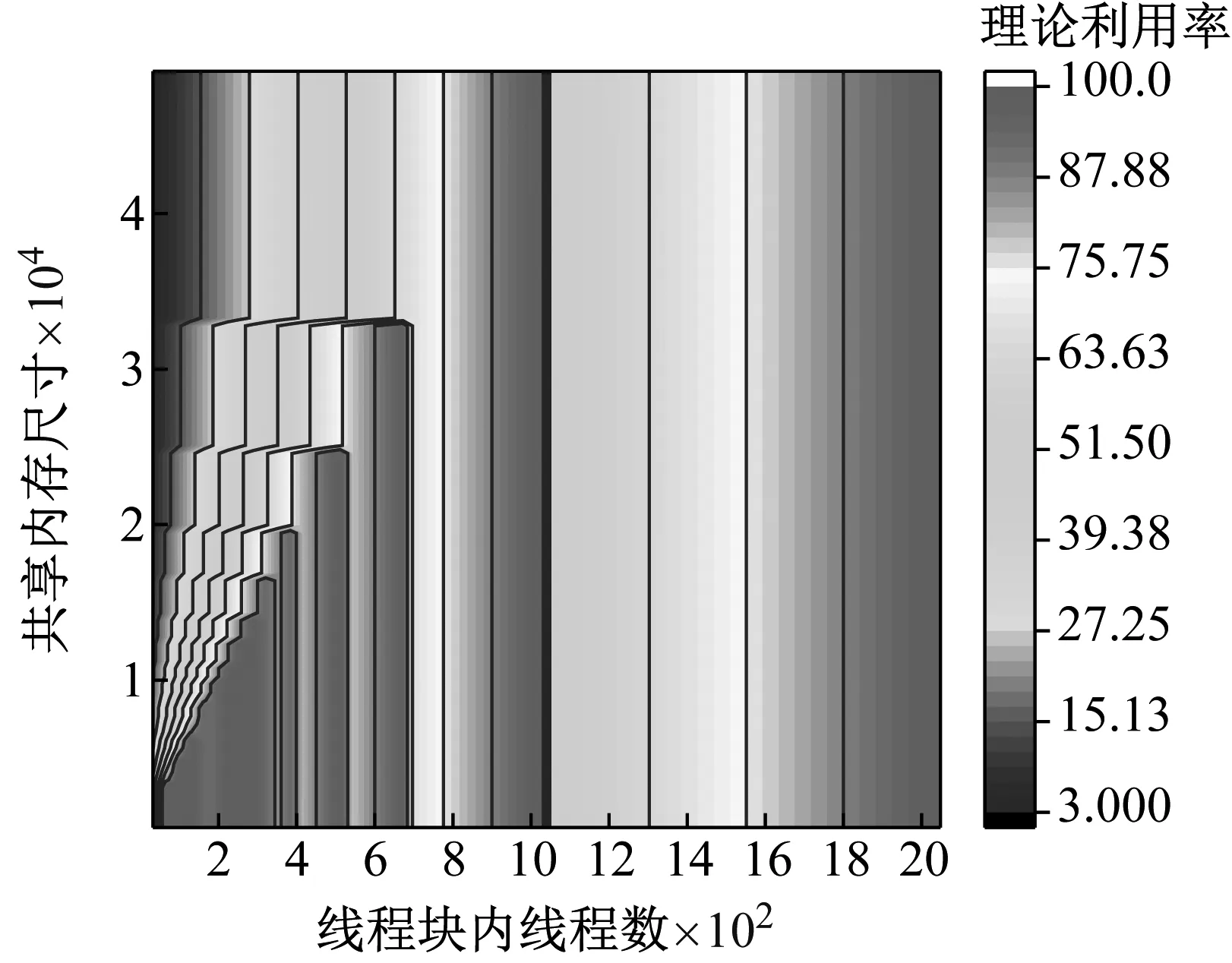
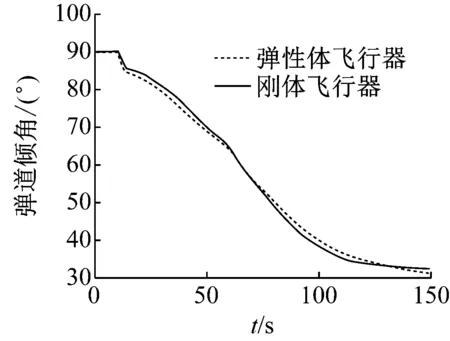
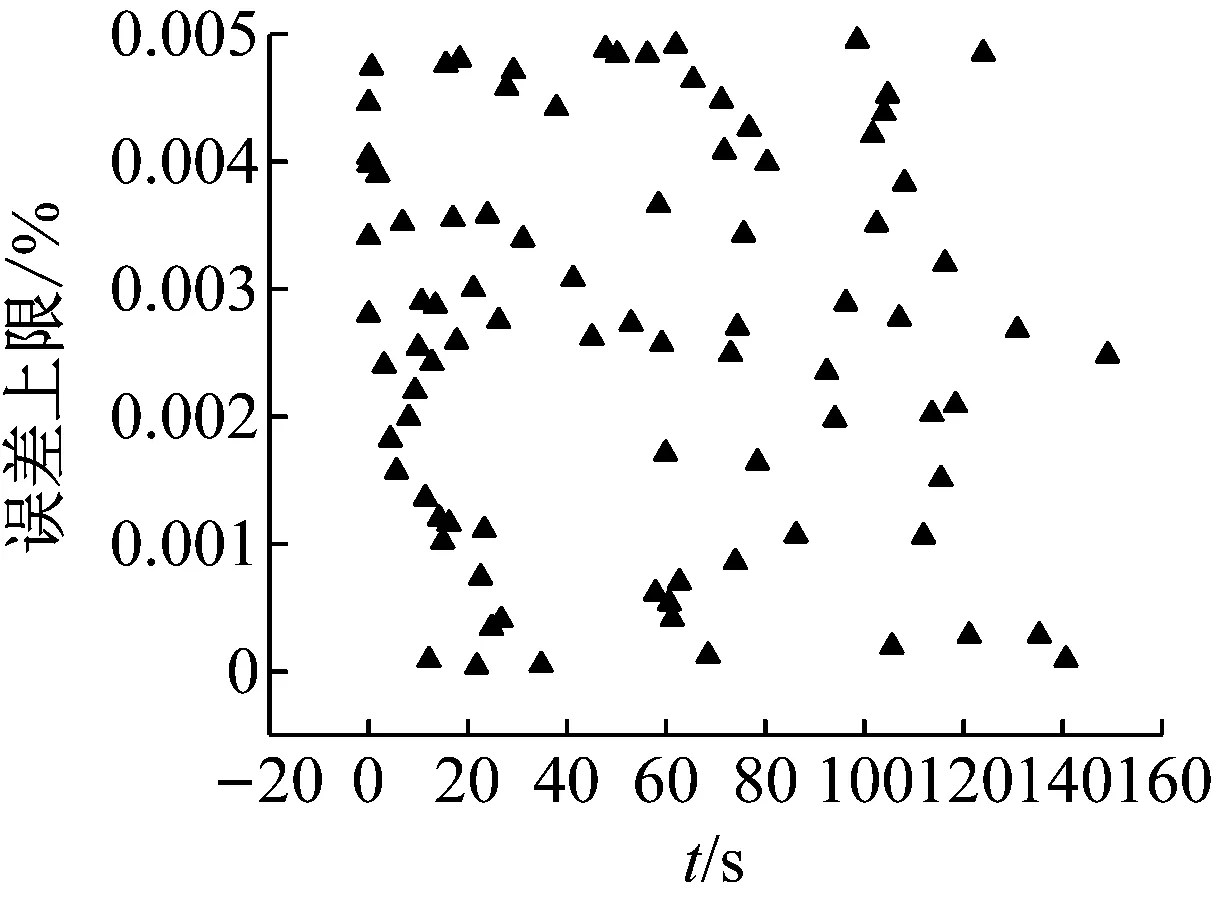
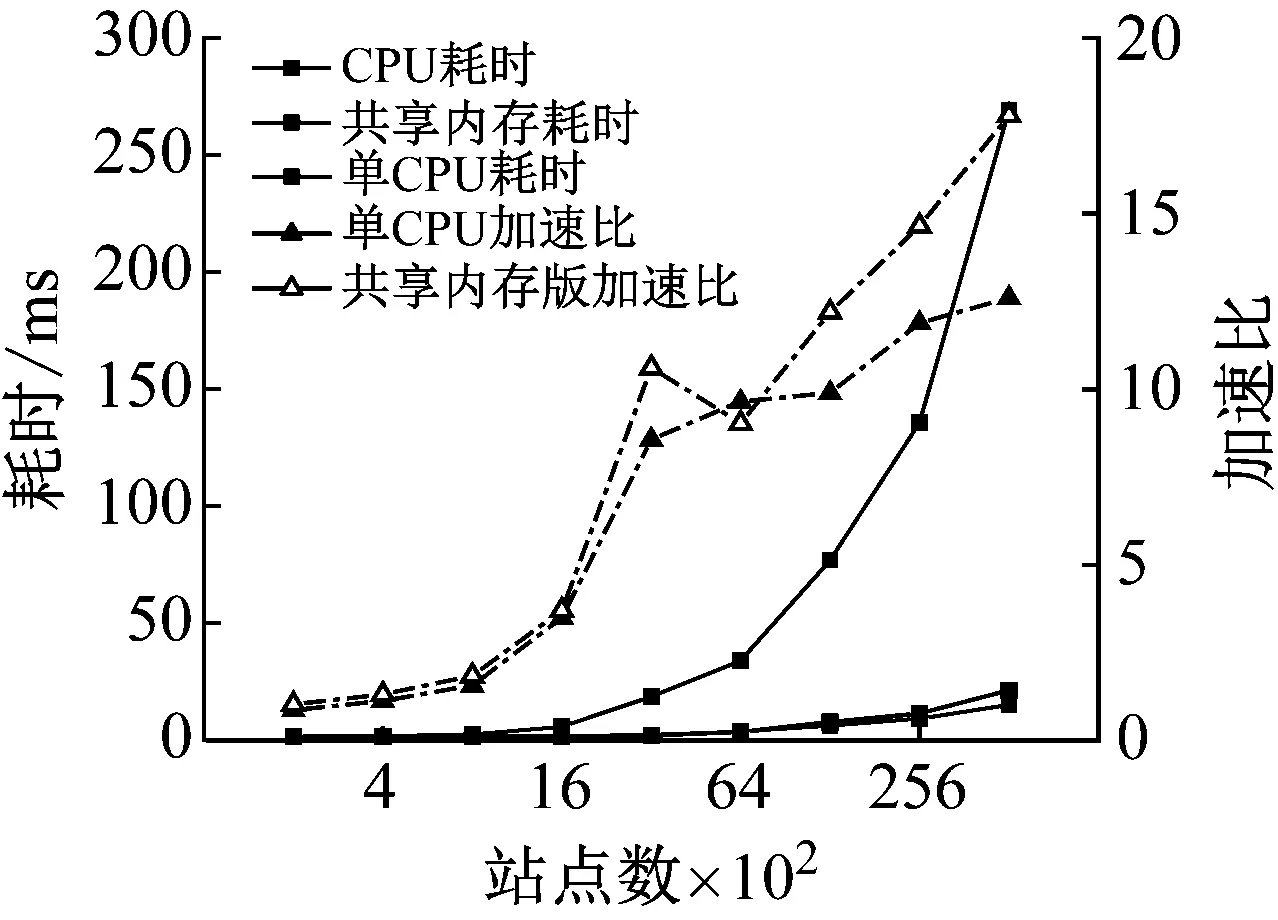
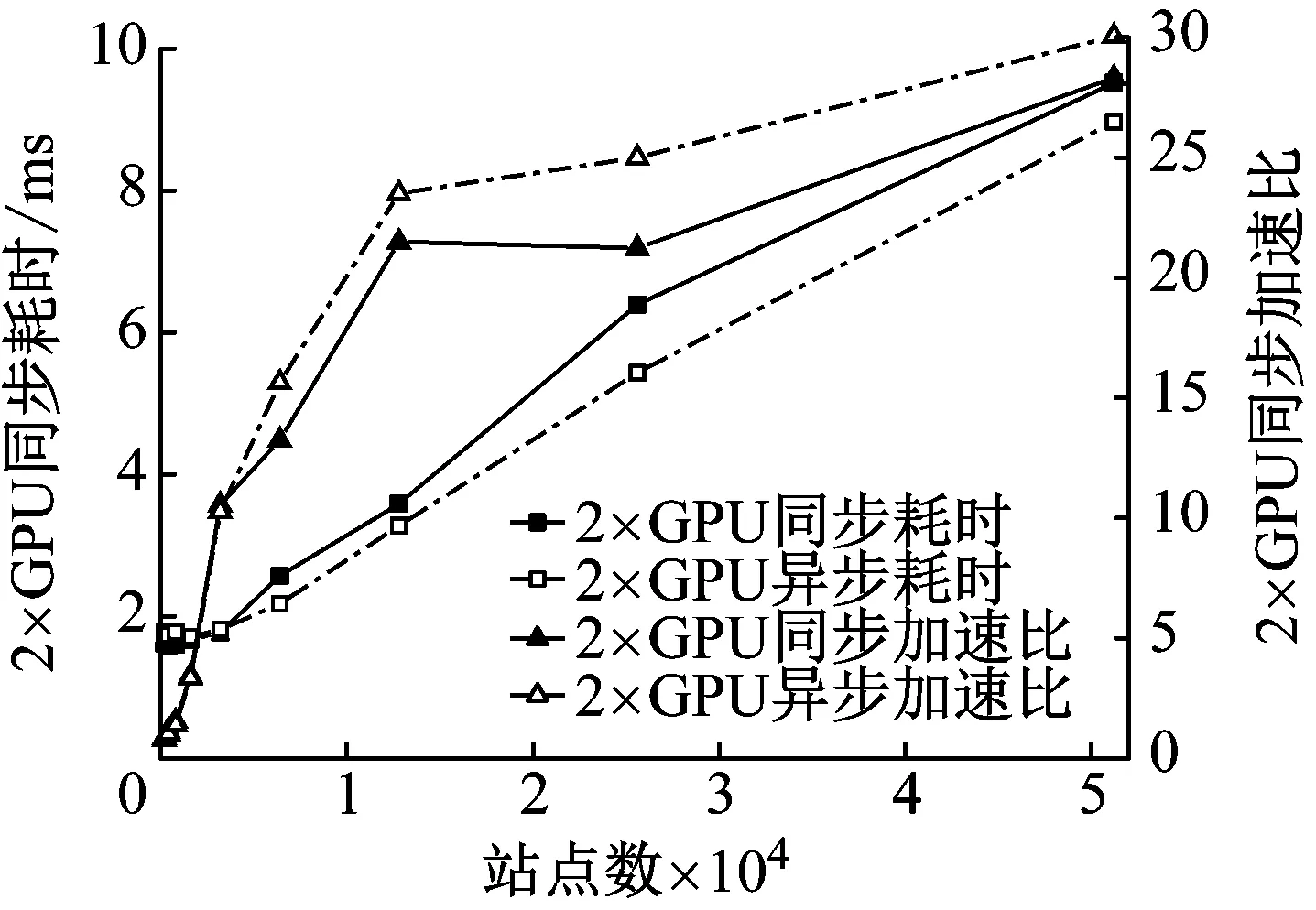
2) While i 3) cudaHostAlloc && cudamalloc 4) cudaMemcpyAsync(H2D) 5) interpolate<< 6) cudaMemcpyAsync(D2H) 7) cudaStreamAddCallback(stream,callbackfunc, data,flag) 8)i++, return 3) 上述第1)步首先依照任務結構體內的流指針創建流對象,并得到計算設備其內部的各種硬件參數;第2)步~第8)步依照給定的流對象完成內存拷貝、核函數計算、函數回調等待數據回傳的過程。其中第5)步的第三個模板參數即低訪問延遲的共享內存的大小,在核函數內通過extern __shared__關鍵詞動態分配共享內存空間,以起到節省每個流多處理器(SM,Streaming Multiprocessors)上寶貴的一級緩存空間,防止核函數調用失敗。鑒于本文所用最大的三維氣動插值表不超過1 200個數據點,因此可通過將線性化的氣動數據表放入共享內存中以實現讀取氣動數據的加速。 為使程序在任意復雜度的數值算法中保證高性能的通適性,需考慮第5)步內前兩個參數對硬件的利用率有影響:一個流多處理器在線程數、線程塊數及寄存器數方面皆有硬件限制,具體參數因GPU計算能力不同而異。在計算模式和算法已定的情況下,每個線程內的寄存器使用數量即已確定,而所需分配共享內存的大小直接取決于氣動數據表的大小,故最為影響流多處理器理論效率的即為核函數的第二個參數,即每個線程塊內的線程數。依照參考文獻[20]建立流多處理器利用率和共享內存大小、線程塊內線程束的函數,在程序初始化階段依照該函數關系建立效率索引表,如圖5所示為單線程使用25個寄存器的情況下每個流多處理器的理論效率索引圖。故在程序中可依照算法和氣動數據表的大小決定參數2,以期實現利用率的最大化及核函數的動態參數優化。 本文建立單臺計算機、多GPU并行求解器,模擬細長體彈性飛行器飛行過程進行仿真,并對單GPU及多GPU并行的性能及拓展性進行對比。因本文重點為加速計算的方法研究,暫選用某型飛行器的氣動數據,但鑒于數據敏感且不失一般性,計算時每個時步較上一個時步在氣動系數的各個維度上均添加一個隨機量。受計算資源限制,算例平臺硬件采用主頻3.4的Intel E3 1230V5,兩片英偉達GTX1060 3G顯卡;編程環境為VS2017下的MSVC14.0編譯器及CUDA 9.0的NVCC編譯器。時間統計時采用CUDA自帶的cudaEvenet_t計時,其精度為0.5 μs;考慮彈性模塊與其他模塊的數據耦合關系,以計算最頻繁的控制周期為實時性判定準則,在此選用10 ms為限。 圖5 流多處理器利用率索引示意圖 程序的正確性及快速性是衡量程序性能的重要指標。選用某型細長體飛行器的攻角作為標準,模擬起飛時刻至第一級分離過程彈性模塊的計算流程,如圖6所示,剛體飛行器與彈性體飛行器的彈道傾角變化總體一致且相差不大。其原因是在傳統剛體飛行器的彈道仿真中,由于控制系統的魯棒性,在有一定偏差條件下仍能夠滿足飛行姿態的穩定并保證對標準彈道的跟蹤,故彈性變形引起的各附加量輸出至指導控制計算機后對整體彈道的影響不大。而如圖7所示,通過傳統CPU與GPU運算結果對比,可認為CPU與GPU的運算結果并無二致。 由圖8可知,單GPU情況下在站點數較少時加速效果并不明顯,因為計算均需通過低速的PCI-E總線傳輸計算數據,且啟動的線程數不足以隱藏數據傳輸和核函數啟動的時間開銷,即異構架構帶來額外的通信及函數啟動時間無法抵消多核運算帶來的性能提升。但盡管選用常規的Geforce卡,其沒有ECC顯存且每個流多處理器內的雙精度計算單元比例更少,采用CUDA技術的雙精度計算的求解時間在單元個數較多時仍能保證較好的加速比,經優化后在站點數25 000個左右時能保證仿真計算的實時性;隨站點數的增加,加速比達到13左右且斜率下降趨于穩定。而當氣動數據表較小足以放入共享內存中時,同理在站點數較少加速效果不明顯,隨著站點數的增加,計算由I/O密集型轉向計算密集型,加速效果逐漸明顯;與常規從全局顯存讀取數據的加速比不同,在站點數3 000左右有一個下跌的趨勢,其原因可能是多線程訪問共享內存導致的訪存沖突進而影響了運算效率。 圖6 彈性體與剛形體彈道傾角對比 Fig.6 Comparison of trajectory inclination angle between rigid and elastic vehicle 圖7 CPU與GPU運算誤差結果對比 Fig.7 Comparison of error results between CPU and GPU 圖8 不同站點數CPU與GPU計算結果對比 Fig.8 Comparison of the calculate results between CPU and GPU with different scales 圖9 不同站點數多GPU同/異步架構耗時對比 Fig.9 Time consuming comparison of multi GPU synchronous/asynchronous architecture with different scales 而異步較之于同步設計、多GPU較之于單GPU在數據規模較小時差異不大,甚至效率更低,如圖9所示。其原因是多GPU情況需要進行數據分割和開啟額外的顯卡資源。此時異步操作更需要線程同步等待,加速比更為不理想;隨站點數的增加,多GPU加速比提升更快,加速效果更明顯,直至50 000個站點時也未出現加速比趨于平緩的趨勢,其原因是數據分割時間所占總時長百分比愈來愈小,并行部分的傳輸較計算操作在程序中所占比例逐步減少得到充分的延遲隱藏,使得流多處理器效率更高,也從側面映證該方案適宜求解大規模的數值運算。 (1) 基于CUDA技術實現了細長體飛行器彈性模塊的快速求解方法設計,在多GPU環境下取截斷模態40階,可保證至少1 200個站點的彈性飛行器的實時仿真計算。 (2) 針對GPU架構提出了動態并行分配線程塊的八叉樹的氣動系數索引方法,優化了雙線性插值的索引步驟,效果較好。 (3) 設計了單機多GPU的異步并行架構,并仿真說明多GPU并行能夠進一步顯著提高計算效率,證明了所建并行架構的擴展性與快速性。在此研究基礎之上,開展針對超過三維的插值表優化索引模式研究,對多機協同計算做進一步的可拓展性分析。3 數值算例分析
3.1 測試平臺
3.2 計算精度及效率分析
4 結 論
