基于誤差修正的混合模型在風(fēng)速預(yù)測中的應(yīng)用
2019-04-29 05:51:34盛秀梅張仲榮王春媛劉海忠
長春師范大學(xué)學(xué)報 2019年4期
盛秀梅,張仲榮,王春媛,劉海忠
(1.蘭州交通大學(xué)數(shù)理學(xué)院,甘肅蘭州 730070;2.蘭州石化職業(yè)技術(shù)學(xué)院信息處理與控制工程學(xué)院,甘肅蘭州 730060)
1 研究背景
近年來,全球環(huán)境污染問題變得日趨嚴(yán)重。風(fēng)能、太陽能、水能、波浪能、生物能、地?zé)崮堋⒊毕艿刃履茉撮_始受到廣泛關(guān)注,這些新能源不會產(chǎn)生溫室氣體,對氣候變化沒有明顯的影響。在常規(guī)能源告急和全球生態(tài)環(huán)境惡化的雙重壓力下,風(fēng)能作為一種無污染和可再生的新能源有著巨大的發(fā)展?jié)摿Γ词乖诎l(fā)達(dá)國家,風(fēng)能作為一種高效清潔的新能源也日益受到重視。比如,單是德克薩斯州和南達(dá)科他州的風(fēng)能密度就足以供應(yīng)全美國的用電量[1]。然而,風(fēng)力發(fā)電的發(fā)電能力受到自然界風(fēng)源間歇性和隨機(jī)性的困擾,因此,它仍然是一個不可靠的來源,很難被整合到電網(wǎng)系統(tǒng)中。風(fēng)力發(fā)電廠可以通過精確地預(yù)測風(fēng)速的動態(tài)變化來解決這一問題。準(zhǔn)確的短期風(fēng)速預(yù)測可以有效地減少風(fēng)力變化和風(fēng)速突然中斷對常規(guī)動力系統(tǒng)的沖擊而導(dǎo)致的電壓和頻率的波動[2-3]。
目前,風(fēng)速預(yù)測建模方法包括時間序列法[4-5]、人工神經(jīng)網(wǎng)絡(luò)法[6]以及卡爾曼濾波法[7]等。其中,用時間序列法用于預(yù)測時對歷史數(shù)據(jù)有較大的依賴性,只適用于超短期預(yù)測;人工神經(jīng)網(wǎng)絡(luò)方法曾一度成為預(yù)測領(lǐng)域的研究熱點(diǎn),但它至今仍然存在著許多未解決的問題;卡爾曼濾波適用于風(fēng)速的在線預(yù)測,這些方法在用于短期風(fēng)速預(yù)測時的精度較低。為提高風(fēng)速預(yù)測的精度,各種組合預(yù)測方法得到了廣泛的應(yīng)用[8],其中應(yīng)用較為廣泛的是與神經(jīng)網(wǎng)絡(luò)結(jié)合的混合模型。而基于誤差修正的神經(jīng)網(wǎng)絡(luò)混合模型,更能合理地提高模型的精度[9]。通過對過去幾年文獻(xiàn)的分析可知,不同方法的混合預(yù)測已成為一種趨勢。例如,Li H Z等人提出了一種混合負(fù)荷預(yù)測,該模型結(jié)合果蠅優(yōu)化算法和GRNN算法,證明了該混合模型的有效性[10]。Ghasemi等采用ABC、SVM和ARIMA對電力負(fù)荷進(jìn)行預(yù)測,結(jié)果證明該混合模型有更高的準(zhǔn)確性[11]。Wang等應(yīng)用GA和BP神經(jīng)網(wǎng)絡(luò)對內(nèi)蒙古的風(fēng)速數(shù)據(jù)進(jìn)行預(yù)測,結(jié)果證明該模型不僅提高了預(yù)測精度,而且減小了時間復(fù)雜度[12]。
縱向數(shù)據(jù)選擇方法(LDS)的應(yīng)用,使得選擇的數(shù)據(jù)類型具有相同屬性;利用奇異譜分析(SSA)技術(shù)來處理風(fēng)速數(shù)據(jù)中的異常值和其趨勢、季節(jié)成分,使得原始風(fēng)速數(shù)據(jù)重構(gòu),大大地降低了噪聲對序列的影響;最小二乘支持向量機(jī)(LSSVM)是把標(biāo)準(zhǔn)支持向量機(jī)(SVM)的不等式約束條件改為等式約束條件,在一定程度上,降低了計算復(fù)雜度,提高了計算速度,并且較適合于處理大規(guī)模的非線性擬合數(shù)據(jù)問題[13],并且其泛化能力要優(yōu)于神經(jīng)網(wǎng)絡(luò)模型與單一的時間序列模型。在LSSVM的參數(shù)選擇方面,粒子群優(yōu)化算法(PSO)的加入減少了LSSVM在參數(shù)選擇方面的人為影響以及避免陷入局部最優(yōu)的問題。將PSOLSSVM與時間序列的方法結(jié)合起來建立基于誤差修正的混合預(yù)測模型(PSOLSSVM-ARIMA),可以完整地擬合風(fēng)速數(shù)據(jù)中的非線性部分與線性部分,從而提高風(fēng)速的預(yù)測精度。
2 基于ARIMA修正的混合預(yù)測模型
2.1 模型的建立
在用風(fēng)速的歷史數(shù)據(jù)進(jìn)行預(yù)測時,風(fēng)速的隨機(jī)性與不穩(wěn)定性等特征,會使預(yù)測模型產(chǎn)生較大的誤差。而混合模型則是目前解決這一問題較為重要且前沿的方法,其主要思想就是將不同的模型及其分析理論混合,形成一種新的預(yù)測模型。而誤差修正模型又可以對當(dāng)前的混合預(yù)測模型進(jìn)行補(bǔ)充,即克服了單一方法的局限性,又合理地提高了模型的預(yù)測精度。
本文建立了一種基于誤差修正的混合模型來對風(fēng)速數(shù)據(jù)進(jìn)行預(yù)測,具體流程圖如圖1所示,其中奇異譜分析(SSA)由Colebrook于1978年首先在海洋學(xué)研究中提出的,是研究非線性時間序列的一種方法,它結(jié)合多元統(tǒng)計與概率論的思想去分析時間序列[14],并且提取出代表原序列不同程度的信號,如長期趨勢信號、周期信號、噪聲信號等;最小二乘支持向量機(jī)(LSSVM)是一種遵循結(jié)構(gòu)風(fēng)險最小化(Structural Risk Minimization,SRM)原則的核函數(shù)學(xué)習(xí)機(jī)器,有很強(qiáng)的非線性擬合能力,并被廣泛地用于科學(xué)工程;粒子群優(yōu)化算法PSO(Particle Swarm Optimization)則是由Eberhart和Kennedy博士發(fā)明的一種基于全局優(yōu)化的智能優(yōu)化算法,它主要源于對鳥類捕食行為的模擬[15]。作為一種重要的優(yōu)化工具,粒子群優(yōu)化算法已經(jīng)被成功地用于神經(jīng)網(wǎng)絡(luò)的參數(shù)訓(xùn)練[16];而用于誤差修正的ARIMA模型又稱為求和自回歸移動平均(autoregressive integrated moving average)模型,是一種基于時間序列的預(yù)測模型,適用于短期和超短期預(yù)測,并且預(yù)測精度較高[17]。
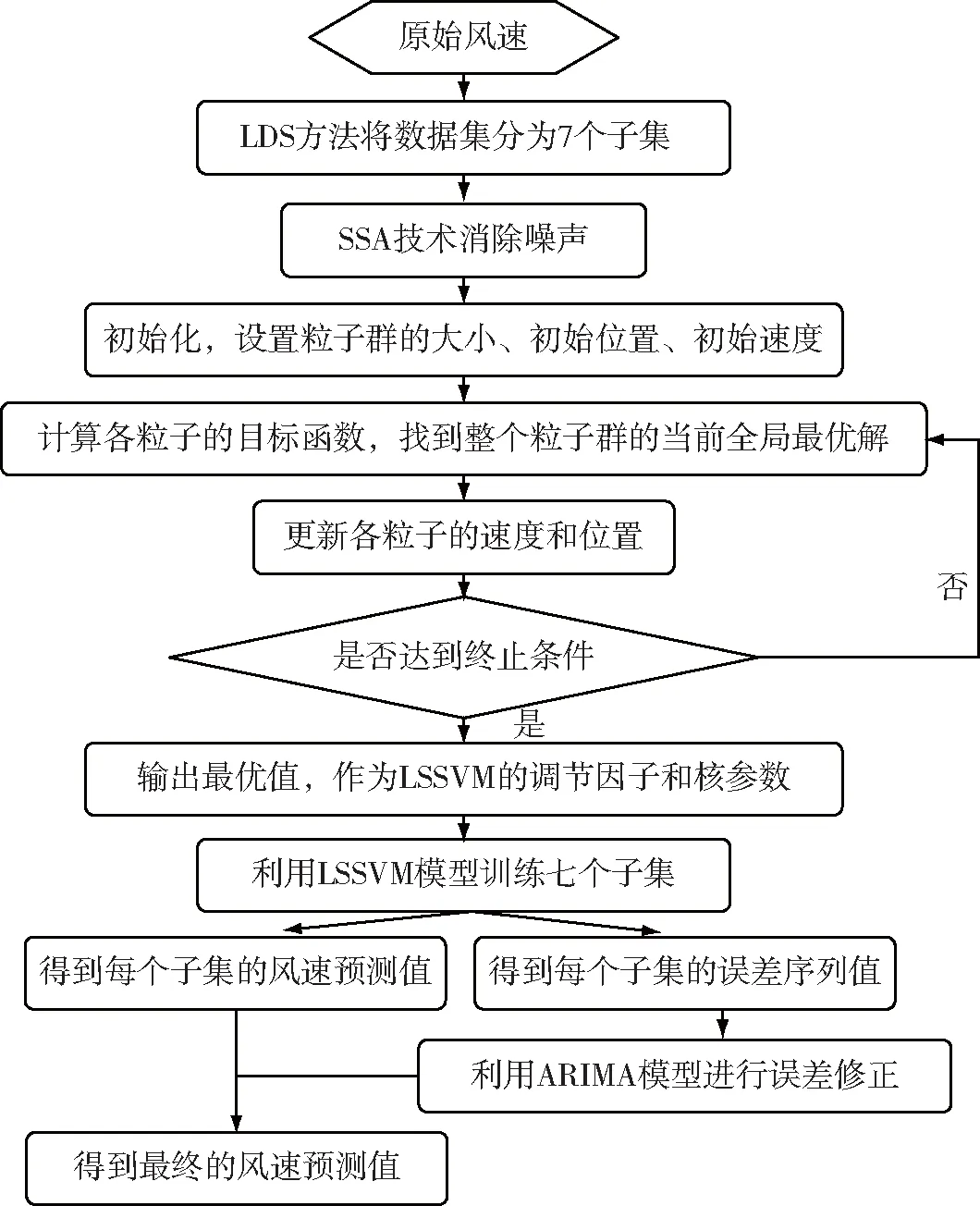
圖1 基于ARIMA修正的混合模型流程圖
文中建立混合模型的具體步驟如下:
步驟1 利用縱向數(shù)據(jù)選擇方法(LDS),選擇合適的數(shù)據(jù)類型;
步驟2 利用SSA-PSOLSSVM模型對每個子集序列進(jìn)行預(yù)測,并得到誤差序列;
步驟3 利用ARIMA模型進(jìn)行誤差修正;
步驟4 獲得最終的風(fēng)速預(yù)測值,并進(jìn)行結(jié)果分析。
2.2 模型的應(yīng)用與仿真結(jié)果
為了驗證文中方法的可行性,選擇了西班牙Sotavento Galicia風(fēng)場2016年2月和2017年2月的風(fēng)速數(shù)據(jù)進(jìn)行分析,其中數(shù)據(jù)間隔為1小時,數(shù)據(jù)樣本總量為1368(圖2)。其中,選取1032個數(shù)據(jù)作為訓(xùn)練集,選取336個數(shù)據(jù)作為測試集。
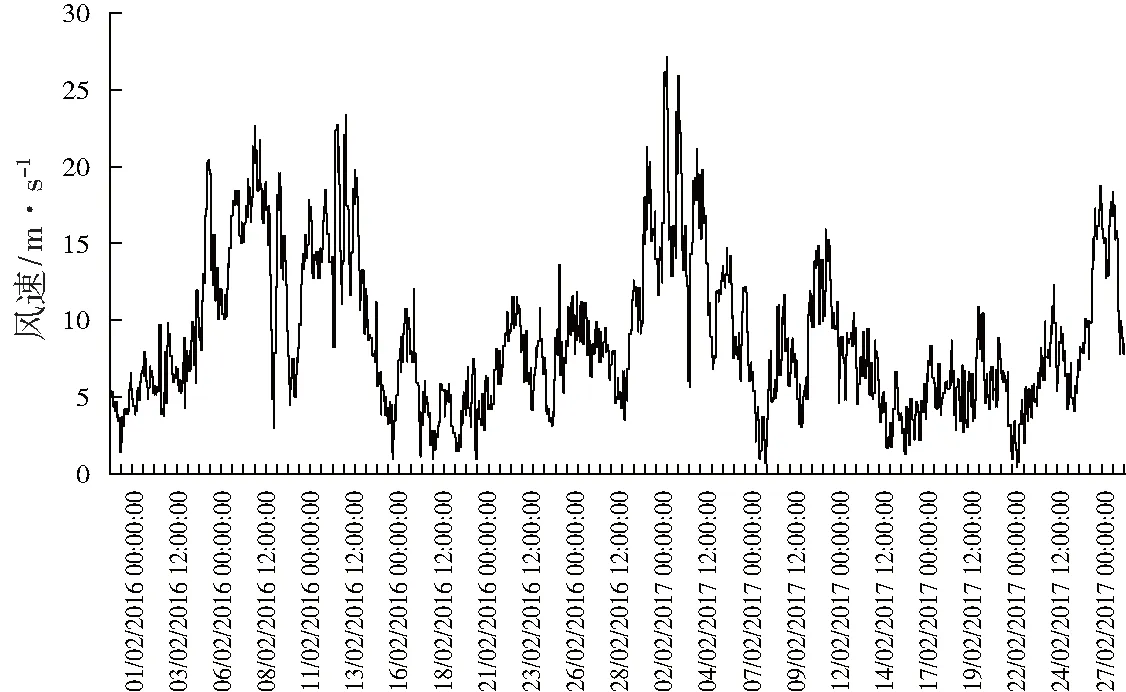
圖2 歷史風(fēng)速數(shù)據(jù)圖
為了提高模型的性能,采用LDS方法將原始數(shù)據(jù)集進(jìn)行劃分,即將這兩個月的數(shù)據(jù)按照星期數(shù)劃分成7個子集(從周一到周日,如圖3所示),這確保了數(shù)據(jù)結(jié)構(gòu)具有相同的屬性。利用奇異譜分析(SSA)分別對7個子集(其中周一有216個數(shù)據(jù),剩余6個子集有192個數(shù)據(jù))的數(shù)據(jù)進(jìn)行重構(gòu),在這里所選擇的窗口長度L=90,獲得7組消除噪聲影響的風(fēng)速數(shù)據(jù)集;再利用LSSVM模型對每個風(fēng)速數(shù)據(jù)的子集進(jìn)行訓(xùn)練預(yù)測,并通過粒子群優(yōu)化算法(PSO)得到最小二乘支持向量機(jī)(LSSVM)的調(diào)節(jié)因子c和核參數(shù)σ2。PSOLSSVM模型將每個子集的前144個(周一為168個)數(shù)據(jù)作為其訓(xùn)練集,后48個數(shù)據(jù)作為測試集(圖4即為7個測試集的預(yù)測值與真實(shí)值結(jié)果對比圖)。將7個子集所得到誤差項按照時間順序形成一條新的殘差序列。
由圖4可以看出,當(dāng)風(fēng)速出現(xiàn)波動的時候,其風(fēng)速的預(yù)測值與真實(shí)值偏差較大,其擬合效果并不是很好,因此,為了使模型的預(yù)測值具有更高精度,可采用ARIMA模型對預(yù)測模型的誤差進(jìn)行修正。
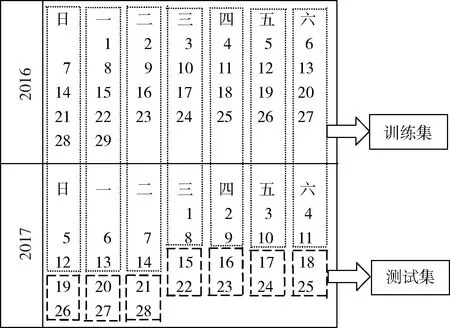
圖3 LDS方法選擇數(shù)據(jù)的形式
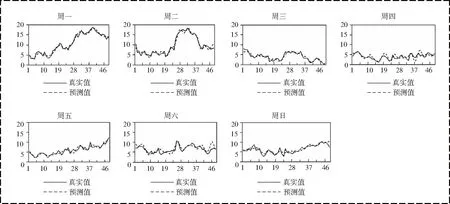
圖4 7個測試集的預(yù)測風(fēng)速與真實(shí)風(fēng)速對比
首先,在EVIEWS軟件中利用單位根檢驗(ADF)對所獲得的誤差數(shù)據(jù)進(jìn)行平穩(wěn)性檢驗,得到表1所示的結(jié)果。由表1可知,ADF檢驗的t檢驗值小于各顯著性水平的測試臨界值,并且其大于t檢驗值的概率遠(yuǎn)遠(yuǎn)小于各顯著性水平的值,因此,可以得到序列不存在單位根,即誤差序列平穩(wěn)。

表1 誤差序列單位根檢驗結(jié)果
其次,對誤差序列進(jìn)行相關(guān)性檢查,并得到誤差序列的相關(guān)性分析圖(圖5)。而在相關(guān)性分析中,當(dāng)P<0.05時,表示拒絕原假設(shè),即序列相關(guān);相反地,當(dāng)P>0.05時,接受原假設(shè),序列不相關(guān)。圖4中所有的P<0.05,因此,誤差序列相關(guān)。由圖4自相關(guān)部分可以看到,第4個數(shù)已明顯收斂到2倍的置信區(qū)間內(nèi),由偏自相關(guān)部分可以看到,第3個數(shù)明顯收斂到2倍的置信區(qū)間內(nèi),因此,p,q在[1,4]之間選值,結(jié)合最小信息準(zhǔn)則(AIC),可確定誤差序列采用ARIMA(1,0,1)模型進(jìn)行修正。
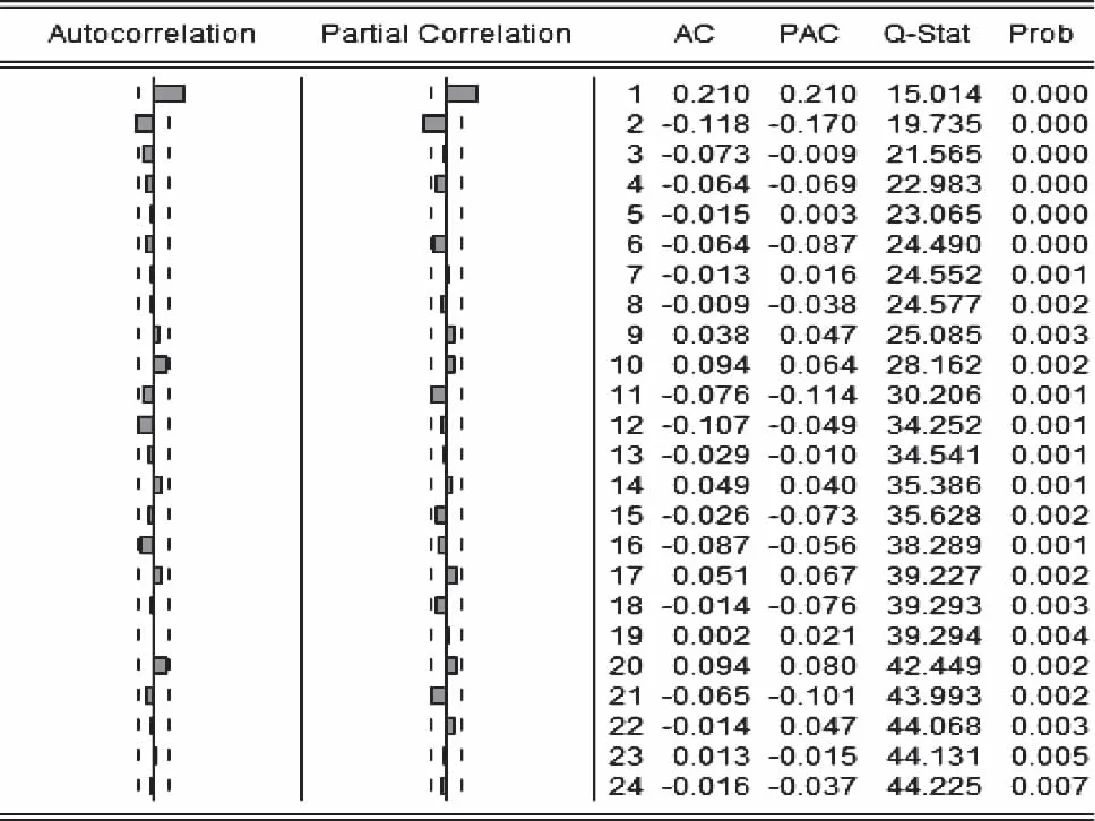
圖5 誤差序列的相關(guān)性分析圖
模型的參數(shù)確定結(jié)果如表2所示。從表2中可以看出參數(shù)的P值,即大于t檢驗值的概率值均小于0.05,因此,模型參數(shù)均顯著。最后,進(jìn)行檢驗發(fā)現(xiàn)殘差序列為白噪聲序列,因此,所選用的誤差修正模型是合理的。

表2 模型參數(shù)顯著性
將混合模型與誤差修正模型所得到的預(yù)測值結(jié)合,得到最終的風(fēng)速預(yù)測結(jié)果(圖6)。由圖6可以清晰地看出,經(jīng)過誤差修正后的風(fēng)速預(yù)測值更接近于其真實(shí)值。
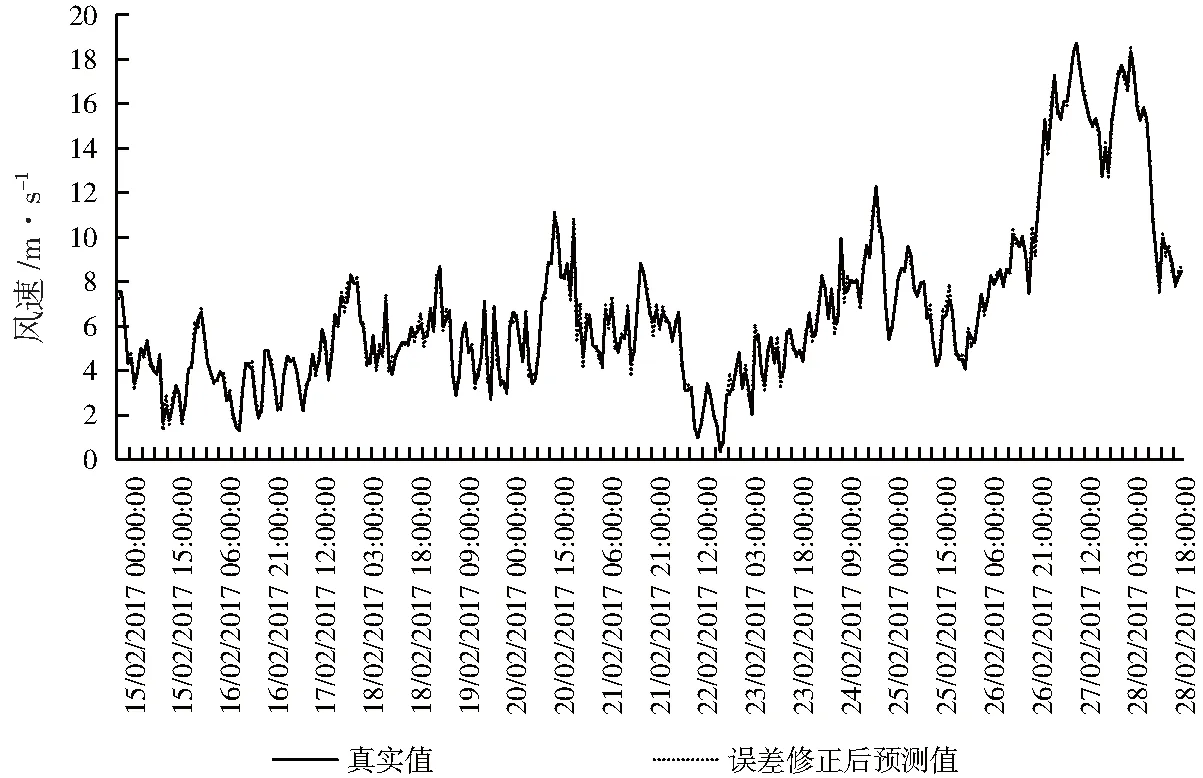
圖6 經(jīng)過ARIMA修正后的預(yù)測值與真實(shí)值
本文采用了平均絕對誤差(MAE)、平均絕對百分比誤差(MAPE)、標(biāo)準(zhǔn)化的均方誤差(NMSE)以及均方根誤差(RMSE)四種評價指標(biāo)評價混合模型在風(fēng)速預(yù)測中的準(zhǔn)確性,其具體公式如下:

(1)
(2)
(3)
(4)
(5)
與PSOLSSVM、LSSVM、ARIMA以及GM(1,1)模型預(yù)測的風(fēng)速結(jié)果進(jìn)行對比,由于測試集數(shù)據(jù)量較大,為了更加顯著地顯示各模型的預(yù)測效果,隨機(jī)對比了各模型在2017年2月20日的風(fēng)速預(yù)測值(圖6)。從圖6可以看出,LSSA_PSOLSSVM_ARIMA模型的預(yù)測結(jié)果更接近當(dāng)天的風(fēng)速真實(shí)值,而單一的LSSVM模型和GM(1,1)模型的預(yù)測效果較差,其中GM(1,1)模型的預(yù)測結(jié)果是一條直線,而單一的LSSVM模型的預(yù)測結(jié)果雖然有趨勢,但其預(yù)測值與真實(shí)值之間有較大的偏離,ARIMA模型和PSOLSSVM模型的預(yù)測結(jié)果接近于真實(shí)值,但仍沒有LSSA_PSOLSSVM_ARIMA模型預(yù)測效果好。
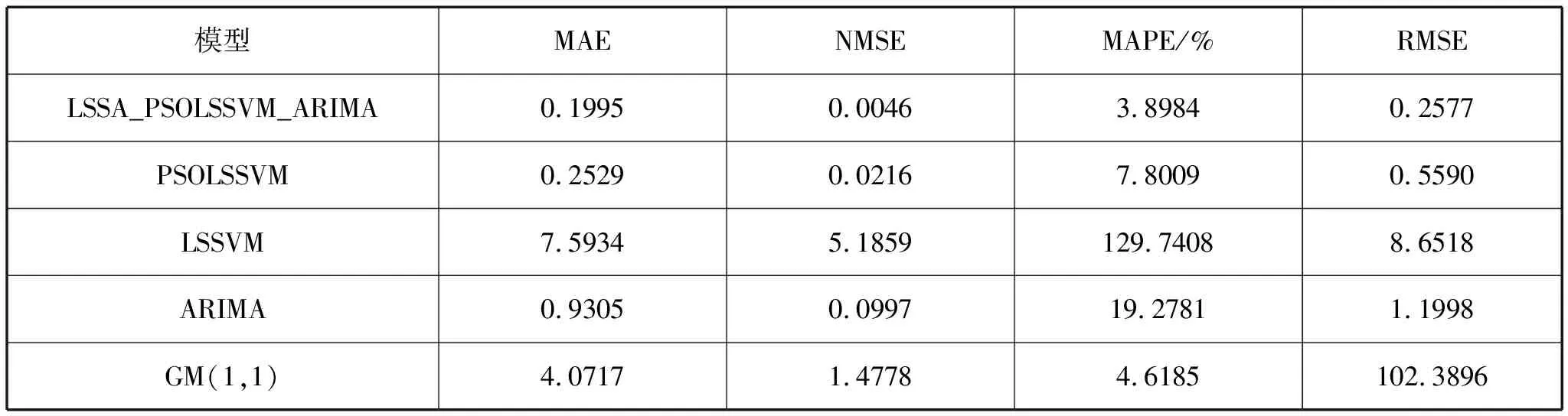
將各模型評價指標(biāo)(MAE、NMSE、MAPE、RMSE)的對比結(jié)果列于表3,由表3數(shù)據(jù)可知,LSSA_PSOLSSVM_ARIMA模型的4個評價指標(biāo)值在表3中都是最小值,因此,該模型相對表中其它預(yù)測模型有更高的精度。其中,單一的LSSVM模型和GM(1,1)模型的預(yù)測精度較低,PSOLSSVM模型和ARIMA模型的預(yù)測精度高于單一的LSSVM模型和GM(1,1)模型的預(yù)測精度,但低于LSSA_PSOLSSVM_ARIMA模型的預(yù)測精度。
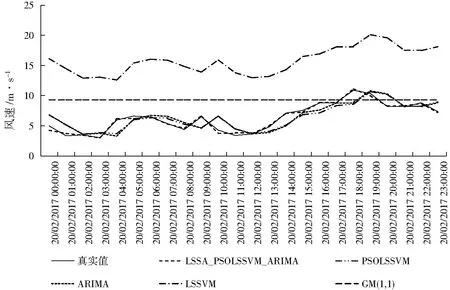
圖7 2017年2月20日的風(fēng)速預(yù)測結(jié)果對比圖
模型MAENMSEMAPE/%RMSELSSA_PSOLSSVM_ARIMA0.19950.00463.89840.2577PSOLSSVM0.25290.02167.80090.5590LSSVM7.59345.1859129.74088.6518ARIMA0.93050.099719.27811.1998GM(1,1)4.07171.47784.6185102.3896
3 結(jié)論
由于風(fēng)速數(shù)據(jù)的季節(jié)性和不確定性,使得風(fēng)速時間序列具有復(fù)雜的非線性性和不穩(wěn)定性。本文首先采用縱向數(shù)據(jù)選擇方法(LDS)選擇合適的數(shù)據(jù)類型;然后利用奇異譜分析(SSA)技術(shù)剔除風(fēng)速時間序列中的噪聲與季節(jié)性,從而加強(qiáng)最小二乘支持向量機(jī)(LSSVM)的預(yù)測性能;同時,利用通過粒子群優(yōu)化算法優(yōu)化最小二乘支持向量機(jī)(LSSVM)的最優(yōu)調(diào)節(jié)因子c和核參數(shù)σ2,將風(fēng)速數(shù)據(jù)輸入該模型進(jìn)行模擬預(yù)測,并得到相應(yīng)的誤差序列;最后,利用ARIMA模型對所得到的誤差序列進(jìn)行修正,并結(jié)合PSOLSSVM的預(yù)測結(jié)果,得到最終的風(fēng)速預(yù)測數(shù)據(jù)。利用西班牙Sotavento Galicia風(fēng)場的風(fēng)速數(shù)據(jù)來驗證混合模型的性能,結(jié)果發(fā)現(xiàn)本文提出的基于誤差修正的混合模型相比較于其它單一的預(yù)測模型具有更高的精度。除此之外,該方法也可以應(yīng)用于股票指數(shù)、航空運(yùn)輸、意外死亡等方面的預(yù)測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
電機(jī)與控制應(yīng)用(2021年12期)2021-02-28 07:55:52
海洋通報(2020年5期)2021-01-14 09:26:54
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
西南交通大學(xué)學(xué)報(2016年4期)2016-06-15 20:29:37
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
電測與儀表(2015年8期)2015-04-09 11:50:06
電機(jī)與控制應(yīng)用(2015年7期)2015-03-01 03:50:15
