一種基于神經網絡的微服務模型
2019-03-29 08:11:44劉先莉劉志勤張智慧
西南科技大學學報 2019年1期
劉先莉 楊 雷 劉志勤 張智慧
(西南科技大學計算機科學與技術學院 四川綿陽 621010)
近年來,傳統的企業IT系統正逐步向基于云計算基礎設施的IT系統演進,軟件產品的運行環境發生了深刻的變化,隨之而來的是軟件本身的模型架構和實現在向“云”化和服務化的方向轉型[1]。在傳統的IT行業中,大多數軟件都是由多個獨立系統堆砌組成,這些系統的常見問題是維護成本高、可靠性低和擴展性差。“微服務(Microservice[2])”概念由Lemwis和Fowler在2014年首次定義:一個云應用程序設計模式,意味著應用程序被劃分為較小的獨立服務,每個服務負責實現一個功能。微服務的思想源于與傳統整體式架構(Monolithic Architecture[3])應用的對比。
微服務是“Cloud Native[4]”,它允許在頻繁發布不同服務的同時保持系統其他部分的穩定性和可用性,使得更容易開發、理解和維護單個服務[5],但是當作為一個整體實現時,它也呈現出復雜性。使用微服務時,有時需要向不同的應用服務添加一些代碼,代碼量是重復的;整個應用程序可能只需要部署一小組應用程序服務區域,而微服務模型可能需要構建、測試、部署和運行幾十個單獨的服務,使得操作和維護的成本增加;而作為一個分布式系統,它引入了復雜性、版本控制、網絡延遲等問題。
目前,微服務已經得到良好的應用[6]和對比分析[7],但是并未形成統一的微服務模型方案,針對上述問題,從新的角度研究微服務技術,引入神經網絡模型,提出了一種基于神經網絡的微服務模型。模型結合了神經網絡與微服務,使微服務具備神經元的特性,融入神經網絡的優點。在Web應用的實際開發中驗證了該模型的實用性和有效性。
1 神經網絡
人工神經網絡(Artificial neural network,ANN),簡稱神經網絡(Neural network,NN)或類神經網絡是模擬人腦神經系中對復雜信息的處理機制的一種數學模型[8]。圖1是一個典型的神經網絡結構的示意圖,可以看出,輸入到神經網絡的信息通過輸入層、隱藏層和輸出層的順序傳輸到輸出層,最終得到神經網絡的輸出結果。輸入層和隱藏層都有n個神經元,輸出層有1個神經元。整個網絡的輸入是x1,x2,x3,…,xn,對應傳遞給隱藏層的第1,2,3,…,n個神經元中,隱藏層神經元以一定的方式聚集輸入層的信息,作為每個神經元的輸入,然后通過激勵函數的作用產生輸出信息。隱藏層神經元的激勵函數一般采用非線性函數,隱藏層神經元的輸出被傳輸到輸出層,輸出層輸出作為整個網絡的輸出信息y。神經網絡技術具有諸多優點:
(1)自主學習:對復雜和不確定問題具備自我學習能力,在學習過程中進行自我完善和創新;
(2)信息存儲與運算:信息存儲與操作集成為一體,即信息的存儲反映在神經元連接的分布中[9];
(3)信息綜合:能夠很好地協調各種輸入信息的關系,能夠處理各種定量和定性的信息,具有較強的信息綜合能力[10];
(4)自適應:善于聯想、泛化、類比和推廣,任何局部損壞都不會影響整體效果,適應外部變化并保持良好的性能,具有較強的魯棒性和容錯性;
(5)自組織:自適應是基于自組織的實現,依據外部環境的變化進行自組織[11]。
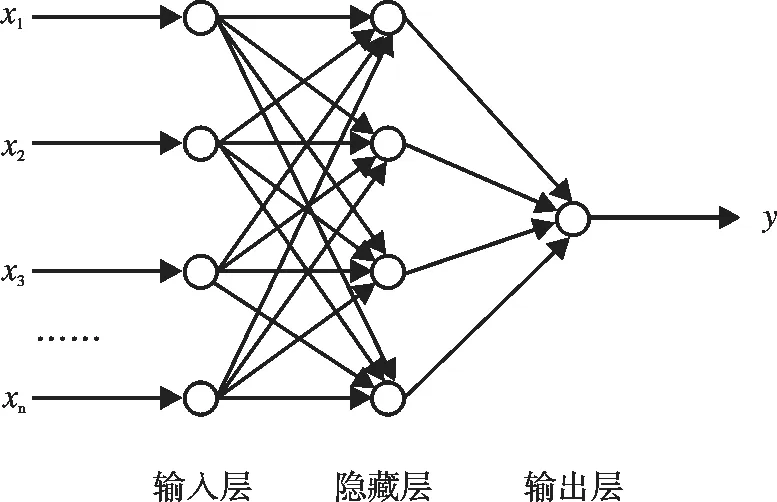
圖1 典型神經網絡結構示意圖Fig.1 Typical neural network structure
2 傳統微服務模型
微服務可以根據業務功能的獨立性來進行劃分[12]。每個單獨的業務功能稱為服務,每個服務對應一個獨立的功能。服務劃分是實現微服務架構的重要一步,良好的劃分和拆分可以使系統達到松耦合和高內聚的效果[13]。微服務的靈活組裝可以滿足上層的各種業務處理需求。在需求分析和微服務架構設計過程中,區域動詞和名詞通常用于劃分微服務。例如,對于電子商務后臺系統,它可以分為發票、訂單、目錄、支付、購物車、交易、庫存、物流、商品等子系統,每個名詞和動詞都可以是微服務。通過結合這些微服務,可以實現購買商品的電子商務平臺用戶的整個業務流程。在此拆分之后,系統具有靈活性、敏捷性和可擴展性的特點,并且形成多個高度自治的微服務。
組合微服務有很多種方法,包括:微服務代理模式、微服務分支模式、微服務異步消息模式、微服務共享數據模式、微服務串聯模式和微服務聚合模式[14]。最常見的是微服務串聯模式,微服務串聯模式結構如圖2所示,類似于一個工作流:第一個負責接收請求并響應服務使用方;連接服務后,它與服務1交互;然后服務1與服務2交互;最后,服務2生成的結果通過服務1和服務序列逐個處理,并返回給服務使用方。
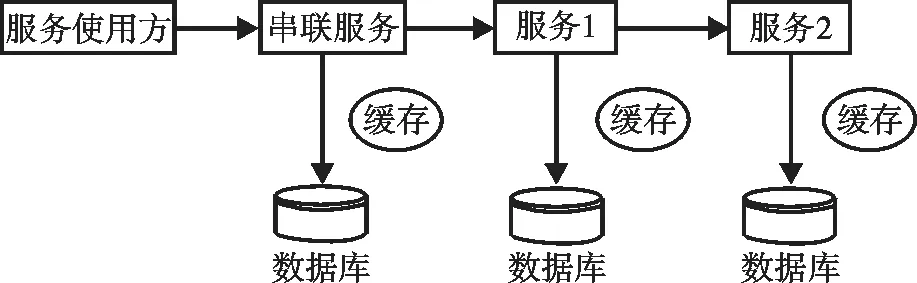
圖2 微服務串聯模式結構示意圖Fig.2 Schematic diagram of microservice serial mode structure
3 基于神經網絡的微服務模型
3.1 模型概述
Web應用中,假設微服務足夠小,將一次數據請求看作一個微服務,將微服務具體化,每個服務都比較簡單,作為神經網絡的輸入數據。在神經網絡中,運算是通過大量的神經元聯結進行的。神經元處理單元可表示不同的對象,將一個微服務看做一個神經元,只關注于一個業務功能。融入神經網絡模型,以達到微服務的靈活組裝的目的進而滿足軟件應用的各種各樣的業務處理需求。神經網絡中處理單元的類型分為三類:(1)輸入單元:把單個微服務數據經過數據預處理得到x1,x2,…,xi,…,xn,將這n個輸入數據作為神經網絡的輸入單元;(2)隱藏單元:隱藏單元由數據庫表分類神經元、請求操作分類神經元、條件數據分類神經元和4個返回數據分類神經元(GET,POST,PUT,DELETE)組成;(3)輸出單元:模型中只有1個輸出單元,輸出微服務的執行結果y。圖3為基于神經網絡的微服務模型結構。
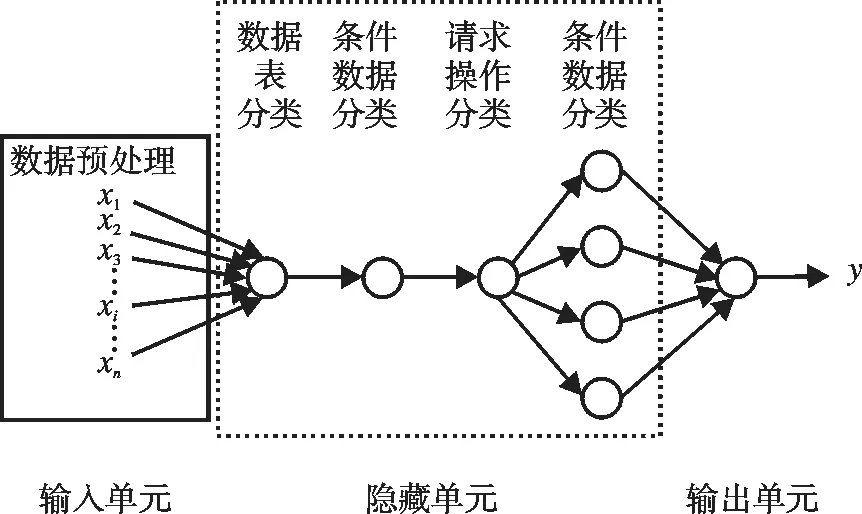
圖3 基于神經網絡的微服務模型結構Fig.3 Microservice model based on Neural network
3.2 微服務數據預處理
由于微服務數據的特殊性和復雜性,與純文本數據相比,它具有一定的結構屬性,與關系模型數據相比,它具有弱的結構屬性。因此,微服務數據是具有半結構化屬性的文本數據。微服務數據的預處理過程如下:
步驟1 分詞劃分。首先要做的數據預處理就是分詞(Word Segmentation)[15],由于微服務數據的特殊性,使用正則匹配來分割英文文本,刪除所有標點符號和空格,只保留字符和數字,用空格分隔。
pattern = ′,|。|/|;|’|′|[|]|<|>|→|:|"|{|}|~|!|@|#|
步驟 2為每個詞創建一個索引。
步驟 3 為每項微服務數據創建一個矩陣,如果詞出現標記為1,否則標記為0。
3.3 搭建神經網絡
神經網絡是由許多神經元的互連形成的,在此基礎上構造了由數據庫表分類神經元、請求操作分類神經元、條件數據分類神經元和返回數據分類神經元組成的鏈鎖式神經網絡,如圖4所示。
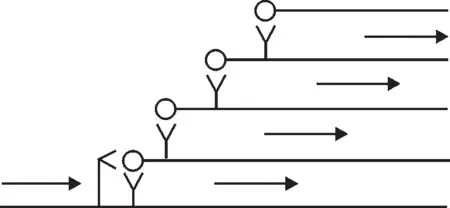
圖4 鏈鎖式神經網絡Fig.4 Chain-locked neural network
神經元按照鎖鏈結構依次進行計算處理,鏈鎖式神經網絡可以使神經元在空間上增強或擴大作用范圍。各類微服務神經元的功能如下:
(1)數據庫表分類神經元:確定微服務作用的數據庫表,數據庫表分類神經元結構如圖5所示。對于數據庫表采用One-Hot編碼向量的表示形式。One-Hot編碼即獨熱編碼,又稱一位有效編碼,它使用N位狀態寄存器編碼N個狀態,每個狀態由其自己的寄存器位編碼,其中只有一個在任何時候都有效,這解決了分類器不能很好地處理屬性數據的問題,并且在一定程度上也起到了擴展特征的作用。對每個數據庫表編號,針對每個數據庫表建立n維的向量,向量的每個維度表示一個表。式(2)中h表示一個數據庫表的向量表示。然后確定神經元的連接權值(w)和內部偏差值(θ),然后輸入經過數據預處理的數據x1,x2,…,xi,…,xn,輸出結果y由式(1)函數計算得到。
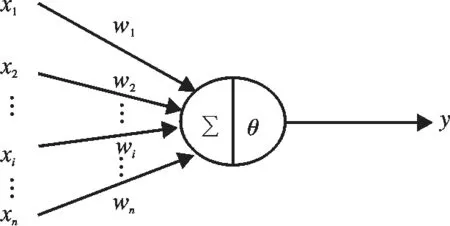
圖5 數據庫表分類神經元Fig.5 Database table classification neuron
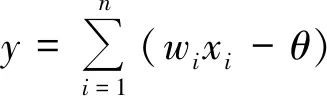
(1)
(2)
(2)條件數據分類神經元:確定微服務請求的條件數據,微服務請求參數主要以“‘參數名稱’:‘參數值’”形式傳遞條件數據參數。
(3)請求操作分類神經元:確定微服務的請求操作類型,請求方法是請求一定的Web頁面的程序或用于特定的URL[16]。請求操作分類如下:
① GET:用于請求特定已被識別的資源,經服務器端解析并返回響應實體主體;
② POST:將數據提交到指定的資源來處理請求,數據包含在請求主體中,到達傳輸實體主體的作用;
③ PUT:用從客戶端傳遞到服務器的數據替換指定的最新內容,然后保存在指定的位置;
④ DELETE:請求服務器刪除指定的資源。
(4)返回數據分類神經元:根據神經元(3)請求操作分類神經元的執行結果選擇GET,POST,PUT,DELETE 4種不同返回數據分類神經元進行分類,得到微服務要求的返回數據。
4 模型的實踐分析
4.1 實驗方案
為驗證基于神經網絡的微服務模型的實用性,根據微服務的分類屬性,根據數據庫在(material,problem,member)3類表中選取1 000項微服務數據進行實驗研究,基于神經網絡的微服務模型流程圖如圖6所示。首先對數據進行預處理,然后根據鏈鎖式神經元依次對數據進行分類處理,進而分類出微服務作用的數據庫表,依次分類出微服務條件數據,然后對請求操作進行分類,得出結果進入GET,POST,PUT,DELETE 4組不同返回數據分類的神經元中,最后執行得到結果。實驗分別基于神經網絡的微服務模型與傳統Web應用開發模型開發相同功能的Web應用,將對PC端和手機端進行測試,從數據響應時間進行對比與分析。實驗中使用的PC端和手機端的詳細測試配置見表1。
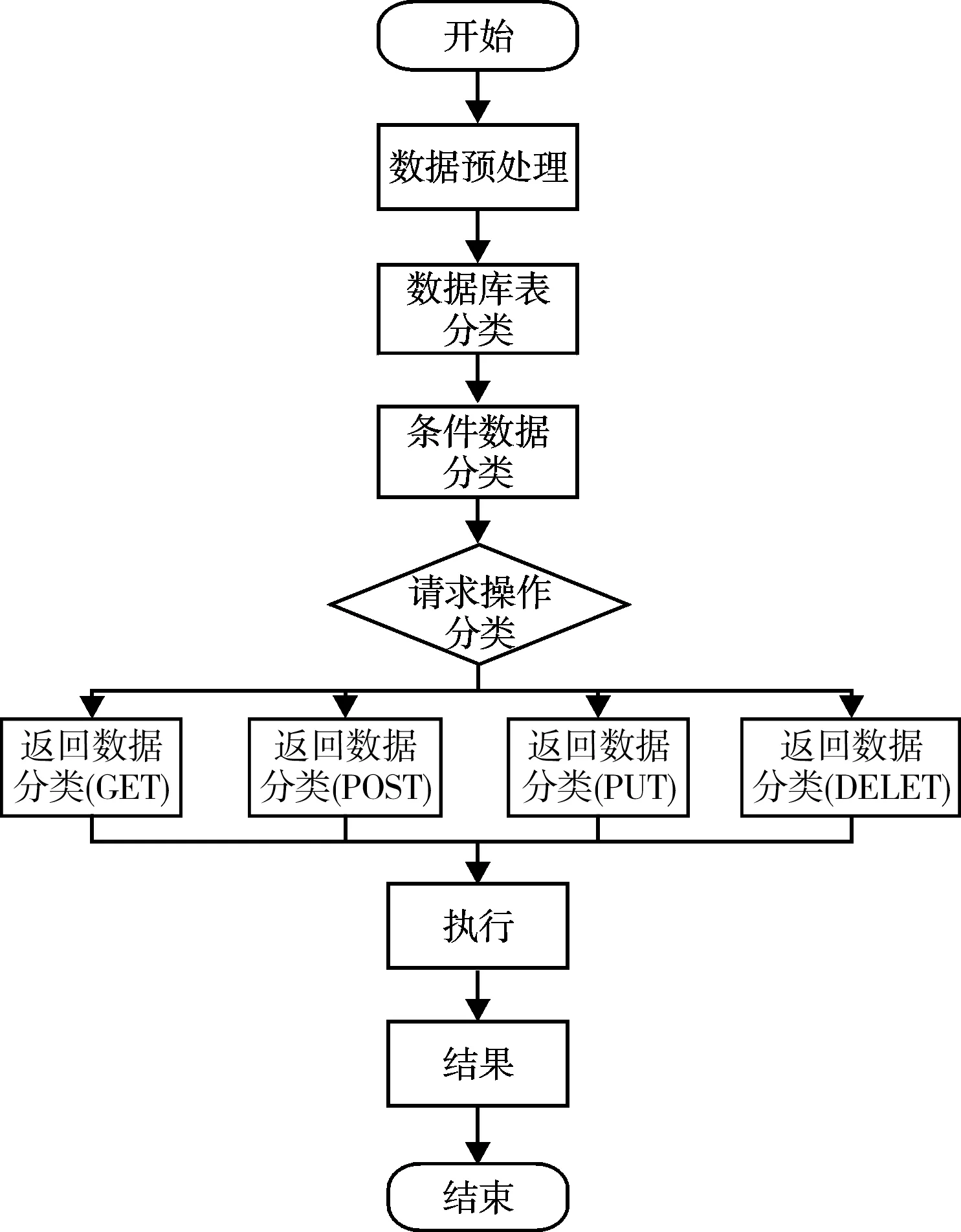
圖6 基于神經網絡的微服務模型流程圖Fig.6 Flow chart of microservice model based on neural network

項目PC端手機端品牌聯想(LENOVO)OPPO型號昭陽ES2-80R7Plusm系統版本Windows10專業版64位Android5.1.1RAM8 GB3 GBROM1 TB32 GB瀏覽器Google Chrome66.0.3359.181Google Chrome68.0.3440.70
4.2 實驗結果分析
實驗中根據對基于神經網絡的微服務模型和傳統的Web應用開發模型的對比測試得到以下結果。在驗證過程中,實現了個人受助詳情(help_ask_detail)頁面(PC端和手機端瀏覽器的運行效果界面圖略)。實驗過程中采用本地JSON格式數據,文字和圖片信息均保留在本地,以排除網絡等因素對Web應用性能表現的影響。采用2.1節提出的方法對1 000 項微服務數據進行數據預處理,對數據庫采取One-Hot編碼(material:[ 1 0 0 ],problem:[ 0 1 0 ],member:[ 0 0 1 ])。數據庫表分類神經元、條件數據分類神經元、請求操作分類神經元、返回數據分類神經元及最終執行結果都能達到100%準確率,實驗結果如表2所示,說明所建立的基于神經網絡的微服務模型具有良好的泛化能力。
針對基于神經網絡的微服務模型和傳統的Web應用開發模型進行對比測試,采用兩種模型開發相同功能的Web應用,在PC端和手機端瀏覽器運行100項、500項和1 000項的微服務數據請求進行測試。圖7和圖8是數據響應時間統計的對比分析,數據響應時間反映了在不同的微服務模型下針對于相同數據源,微服務數據執行完成所需要的響應時間越短,速度越快,帶給用戶的體驗感越好。從圖中可以看出,兩種模型得到的結果表明所建立的基于神經網絡的微服務模型具有一定的實用性和有效性。

表2 實驗結果Table 2 Experimental result
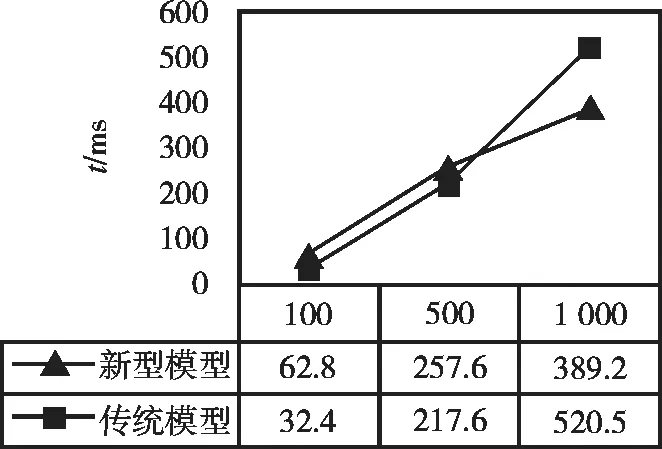
圖7 PC端數據響應時間統計Fig.7 Response time statistics of PC-side data
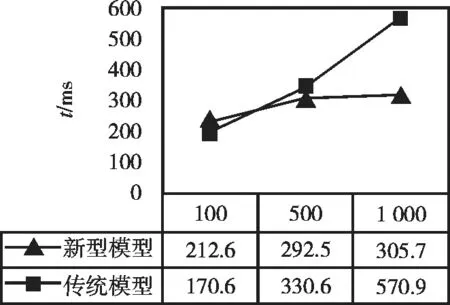
圖8 手機端數據響應時間統計Fig.8 Response Time Statistics of Mobile Data
5 結束語
通過將微服務技術和神經網絡模型相結合,設計并提出了一種基于神經網絡的微服務模型。模型將微服務定義為神經元,且將微服務具體化,把一次數據請求看作一個微服務,作為神經網絡的輸入數據,微服務既作為輸入單元也作為處理單元。實驗采取對1 000項微服務數據進行數據預處理,并對數據庫表采取One-Hot編碼,經過由數據庫表分類神經元、請求操作分類神經元、條件數據分類神經元和返回數據分類神經元組成的鏈鎖式神經網絡模型處理后,得到微服務的執行結果。實驗結果表明該模型通過將微服務處理過程神經網絡化,使得Web應用開發過程變得更加靈活,具有一定的實用價值。未來的研究思路是通過融合神經網絡信息綜合能力、自我學習能力、信息存儲與運算和自組織能力等優點,繼續優化此模型,并進一步實現微服務擴展、合并、解體等功能,以提高Web應用的開發效率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
今日農業(2019年12期)2019-08-15 00:56:32
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商周刊(2017年9期)2017-08-22 02:57:56
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
