基于YOLov2模型的道路目標檢測改進算法
2019-02-07 05:32:15宋建國吳岳
軟件導刊 2019年12期
關鍵詞:深度學習
宋建國 吳岳

摘要:針對傳統道路目標檢測算法推薦窗口冗余、魯棒性差、復雜度較高的問題,提出基于YOLOv2模型的道路目標檢測改進算法。相較于傳統的HOG+SVM目標檢測算法,YOLO模型優勢在于提升了檢測速度及準確度,更適用于實時目標檢測。比較YOLO V3與YOLO V2算法,前者在構造神經網絡模型時復雜度較高,故最終選擇YOLO V2算法。針對原算法中選取AnchorBoxes時所采用的K-MEANS算法造成的目標物體框冗余問題,以及原算法對于不規則物體以及遮擋物體檢測效果較差等問題,提出基于YOLO V2模型的一種改進方法,將K-MEANS算法改進為一種DA-DBSCAN算法,通過動態調整參數的方式大大減少了錨點框冗余問題。實驗表明,改進后的模型準確率達到96.76%,召回率達到96.73%,檢測幀數達到37幀/s,能夠滿足實時性要求。
關鍵詞:目標檢測算法;魯棒性;深度學習;不規則;DA-DBSCAN;錨點框
DOI:10.11907/rjd k.191279
中圖分類號:TP312 文獻標識碼:A 文章編號:1672-7800(2019)012-0126-04
0引言
傳統的目標檢測算法大多基于計算機視覺對已經形成的圖像進行多步分析,在卷積網絡問世之前DPM(De-formable Parts Model)是一個可行的目標檢測算法。該算法采用SVM(支持向量機)加HOG(梯度直方圖)對經過處理的圖像提取特征進行分類,但在整個目標檢測過程中,對于區域選擇階段的目標窗口推薦容易造成推薦窗口冗余現象,大多推薦的目標窗口不能利用。后來卷積神經網絡問世,在深度學習領域結合計算機圖像圖形學等多項技術,在目標圖像的復雜特征提取方面有了巨大進步,使得目標檢測的精確率和召回率得到極大提升。
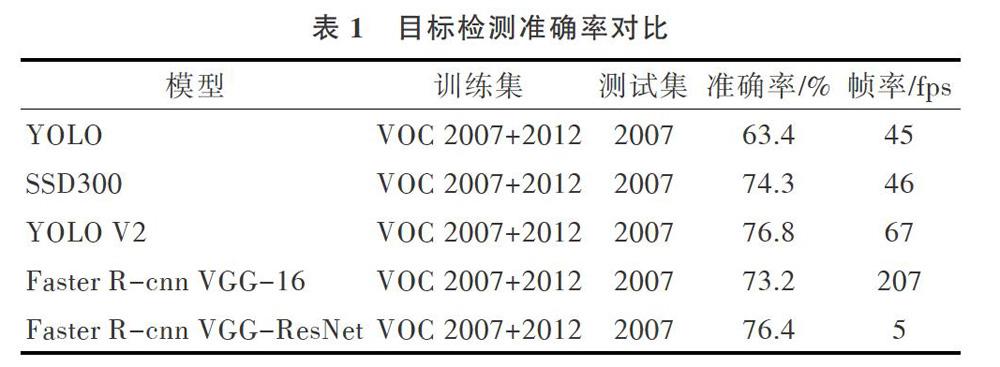
之后產生了一系列目標檢測算法:在CVPR大會上提出的RCNN(Reigions with CNN),通過探索性選擇滑動目標窗口形式,生成有可能包含被檢測物體的目標窗口,并且逐一采取分類器識別方式對所有窗口進行識別,然后通過對候選滑動窗口的處理去除冗余窗口;Fast-Rcnn以及Faster-Rcnn逐漸將提取特征圖的部分與分類部分合二為一,前者將特征圖輸人到一個全連接層中,從而得到相應的回歸判定,后者則將提取特征圖部分融合到神經網絡中,實現了一體化操作。這兩種算法將VOC 2007上的MAP分別提升至70%、73.2%。多模型在相同數據集上的對比表現如表1所示。
DIVVALA等學者提出將回歸思想融合到常規目標檢測過程中,從而形成了YOLO模型。但是YOLO算法同傳統目標檢測算法SSD:一樣具有定位不準確問題。之后在YOLO算法基礎上改進,提出了YOLO V2算法。與傳統的多分類尺度候選框選擇方式不同,YOLO V2使用聚類算法K-means作為Anchor Boxes選擇規則,進一步提升了速度,并且在VOC 2007上的MAP表現達到了前所未有的78.6%。
筆者在利用YOLO V2模型進行目標檢測時發現,其對不規則目標的識別準確度不高,并且在出現物體半遮擋情況下并不能正確識別目標物。為此,提出用DA-DB-SCAN算法替代K-means進行候選框篩選,并對神經網絡結構進行調整,使其更適合道路目標實時檢測。
1YoLo V2算法
1.1算法結構
相較于Faster-Rcnn以及YOLO V1,YOLO V2采取了一系列調優算法。從整個網絡訓練速度看,YOLO V2采用了Batch Normalization(批量歸一化)處理,在每次完成網絡卷積后,將特征數據進行歸一化處理,這樣一是提高了整體網絡的訓練速度,二是去除了一部分的離群數據。為了獲取更準確的目標框信息,在YOLO V2模型的末尾全連接層替換為錨點框對檢測目標進行預測。
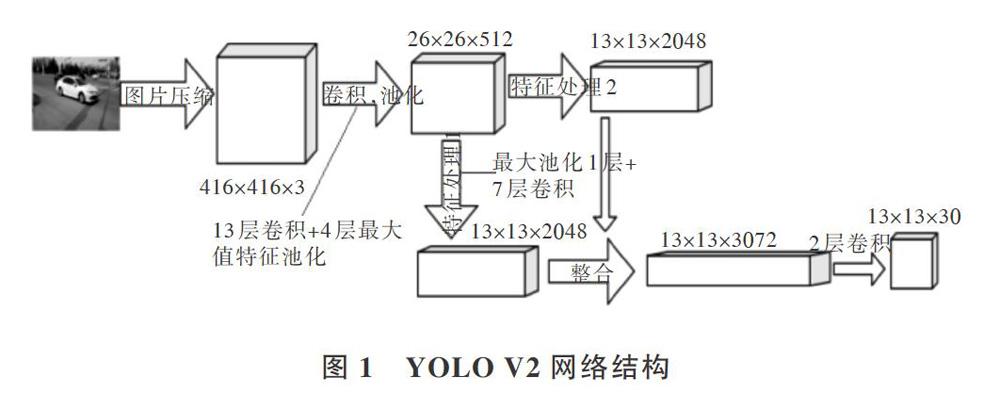
本文實驗網絡結構如圖1所示。首先將圖片通過Normalization統一到YOLO V2網絡模型中,統一圖片輸入大小。經過模型中定義好的13層卷積并采用Maxpool池化策略進行4次池化,然后將提取出來的特征圖再次進行卷積與池化,最終對經過處理后的整合結果進行卷積操作,生成13"13*3072的特征圖。
1.2模型評價方法
物體檢測主要判斷是否檢測到物體以及檢測到的物體是否被正確分類,所以可劃分為一個廣義的二分類問題,最終達到以較高的準確率檢測出目標物體并能夠正確對檢測出來的目標進行分類的目的。在此采取觀察模型訓練時的召回率與準確率判定模型優劣,做出以下定義:①正確檢測出物體且正確分類:TrueObject;②正確檢測出物體但分類錯誤TrueFObject;③不是正確目標物體但被檢測出為目標并分類:FalseObject;④目標是具體目標物但并沒有被檢測出來:FalseFObject,以此定義評價模型優劣的準確率以及召回率計算表達式見式(1)、式(2)。
2DA-DBSCAN算法
2.1算法分析
在YOLO V2模型中將原有YOLO模型和Faster-Rcnn中的候選框選擇策略,由傳統的人工定制多尺度候選框選擇策略改良為使用K-Means算法,該方法在去除無關候選框時效果顯著,能將同一張特征圖上的同類目標以更加準確的效果聚為一類,但同時也帶來算法自身的弊端:首先對不同特征圖的超參數K值選擇計算量較大,其次由算法本身帶來的不規則物體識別效果較差,并且在目標前存在遮擋物時無法正確識別目標。
傳統DBSCAN算法雖然能夠解決不規則物體識別和聚類數量超參數選擇問題,但是隨之而來的超參數調節問題增加了模型復雜度,對此提出改進算法:Mimarogli提出基于位向量的分類切割方法,縮短原有算法的執行時間;Zhou分析了算法中兩個超參數(Eps,MinPts)的手動設置問題,發現兩者的排列符合數學中數理特征,能通過某種算法自適應地確定全局變量;Liu提出一種依據維度的相對排序坐標,將核心對象外的鄰域點作為種子拓展聚類,從而減少同一特征的查詢次數,提高聚類精度,降低對特征環境以及閾值的依賴性;Kellner提出了一種基于網點的DBSCAN算法,解決了輸人參數問題。
綜上所述,本文提出的DA-DBSCAN(Dynamic Adjust-ment-DBSCAN,動態調整-DBSCAN)算法在目標聚類上避免了K-Means算法帶來的不規則物體無法正確識別問題,并能動態依據特征數據調整超參數Eps和MinPts,從而節省大量人工調參的時間消耗,在存在遮擋物時識別效果較原有算法有小幅提升,提升了目標檢測的召回率和準確率。
2.2算法實現
由于特征密度測量數據單一,本聚類中主要是聚類密度差異較小的目標物,故定義距離公式如下:
式(3)中Distrbutionn×n是一個對稱陣,內部是每個目標元素i與目標元素j之間的距離。根據矩陣中的距離數據繪制K-DIST分布圖,從而反映本特征圖中目標之間的距離變化。本文實驗的K-DIST圖如圖2所示。
從圖2可以看出,大部分數據落在相對集中的距離分組中,可通過數理統計中的方法識別出距離急劇下降位置的數值大小,幫助判定出半徑參數Eps。隨后對特征數據進行高斯曲線擬合,同時使用SSE和RMSE作為曲線擬合的評價參數,經過多次試驗將RMSE調整至1附近,這時對數據的擬合更加準確。多項式擬合曲線如下:
2.3算法分析
通過高斯函數曲線擬合的方式可以更好地去除離群的特征值,更大程度上排除一些不包含實際目標物的An-chor Boxes,并通過將密度積累算法DBSCAN與統計學中的曲線模型相結合的方式,基于數理統計通過動態調節方式計算出最適合每一張特征圖的全局最優超參數Eps和Mint'ts。
3模型實驗
為驗證相關模型的可行性,本文使用多種不同算法模型進行召回率與準確率比對,最終展示模型效果。
3.1實驗數據與結果
本文采用標準數據集加實況道路視頻采集的1583張圖片自制數據集庫,隨機選取其中1215張作為訓練集,剩下的368張作為測試集,經過縮放輸入,對改進后的YO-LO V2模型進行效果監測,人工數據集參數如表2所示,實驗效果如圖3所示。
3.2實驗分析
將訓練集中的數據導人到改良后的YOLO V2模型中進行訓練,在大約經過25h的訓練下,迭代110000次后得到最終的目標檢測模型,采用驗證集的368張實時圖片進行驗證,同時對于兩種傳統目標檢測算法在相同的硬件情況下進行訓練,使用相同的驗證集進行驗證,最終對3種算法模型進行評價對比,結果如表3所示。
Faster-RCNN算法是在R-CNN算法之后經一系列優化算法改進后形成的,是目前效果較好且經典的目標檢測算法,具有極強的代表性。本文將改良后的YOLO V2算法與原算法以及Faster R-CNN進行效果對比,如圖4、圖5所示。從圖4、圖5可以看出,3種算法準確率都在一個較高數值上,但是在召回率方面,改良后的YOLO V2算法體現出DA-DBSCAN算法的優勢,對遮擋物體以及不規則物體的召回率較高,達到了96.73%。在實時性方面,改良后的算法模型在每秒檢測幀數上比Faster R-CNN效果好,并且遠高于傳統的DPM算法效果,達到了37幀,s,足以滿足實時性要求。從圖3(d)、圖3(e)中可以看出,經過改良后的YOLO V2算法對不規則目標如車內的人以及遮擋目標的檢測效果方面有所上升,與原模型相比在目標召回率上有所提升,且在執行速度上略有提高。
4結語
本文針對原YOLO V2模型對小物體、不規則物體、遮擋物體檢測效率低的問題,對原有算法進行改良,通過更改原模型中的目標特征圖錨點框選擇策略,提升目標物檢測的準確度和召回率,對特殊物體做到不漏檢。后續將應用到無人設備,與多種傳感器組合,進一步提升現有物體檢測設備的準確度,開發出更加快速、精準的目標識別算法并應用于實際。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
