基于隨機森林的出租車保有量預測方法研究
2019-01-13 09:47:02趙楠姚寶珍
北方經濟 2019年12期
趙楠 姚寶珍

摘? 要:為了使出租車合理分擔一部分城市出行需求,兼顧運營效率和服務水平,本文提出了基于隨機森林的出租車保有量預測模型。在文中考慮了城市人口、居民消費價格指數、平均等車時間、公交線路總長和網約車保有量等5個影響出租車保有量的相關因素。并且,通過內蒙古通遼市主城區實際數據對模型進行校驗,并得到若干結論。
關鍵詞:出租車保有量? 隨機森林? 網約車? 預測
一、引言
近年來,隨著生活水平的提高和城市交通壓力的增加,出租車需求快速增長。但是由于出租車規模和價格的限制,出租車需求供給矛盾突出。產生這種矛盾現象的主要誘因之一是出租車運力規模:運力規模過剩,雖然使乘客的平均等待時間減少,但出租車空載里程過高,司機的收入大幅下降;相反,運力規模不足,雖然出租車司機的收入有所增加,但乘客的等待時間過長,甚至降低出租車對整個城市交通的分擔率。而“互聯網+”和共享經濟的興起改變了傳統的運輸服務。自網約車合法化后,城市出租車運力得到了一定的補充,但是供需矛盾依然存在。因此,如何在出租車和網約車相互配合模式下,確定出租車的運力規模,是城市交通管理部門的重要課題。
國內外學者針對出租車規模和出租車運價問題做了很多研究。Beesley和Glaiste建模考察了出租車價格以及其服務彈性,同時研究了運力投放問題。研究結論表明,降低價格或者增加運力投放并不一定會降低利潤。Yang等引入多個外生變量和內生變量,建立了乘客需求、出租車利用率和服務水平的聯立方程模型,并以此獲得有用的監管信息,合理做出關于出租車數量、收費結構、服務質量的決策。胡繼華等通過城市出租車的GPS數據,挖掘出租車關于平均運營距離、平均運營時間、平均出行距離等運營信息,給出了一定需求和空載率下的確定出租車合理規模的方法,提出以小時為單位對出租車規模進行分時段控制。宋安和劉琦建立了出租車運力規模綜合評價模型,并在此基礎上提出基于供需平衡的預測方法,從而預測出租車運力規模。但該預測模型有一定的局限性,忽視了乘客等車時間等重要因素。楊英俊和趙祥模討論了影響出租車保有量的相關因素,并通過小波神經網絡對出租車保有量進行預測。Yang等基于GPS跟蹤數據,構建了城市出租車運力規模計算模型。Belletti和Bayen針對Uber和Lyft這類公司,研究了基于響應需求的運力規模優化。
本文選取了城市人口、居民消費價格指數、平均等車時間、公交線路總長和網約車保有量等5個影響出租車保有量的相關因素,通過隨機森林預測方法對出租車保有量進行預測。并以內蒙古通遼市主城區的相關數據為支撐,進行計算和分析。
二、基于隨機森林的出租車保有量預測模型
(一)影響因素選擇
在選擇影響出租車保有量的因素時,應該遵循三個原則,即具有測量性、代表性和可比性。城市出租車系統主要受需求影響。隨著社會經濟的快速發展和城市規模的不斷擴大,出租車需求日益提升,因此體現需求的相關因素尤為重要。另外,出租車作為城市公共交通的補充,其發展與城市公交系統建設密切相關,因而公交相關因素也對出租車規模有影響。綜上考慮,本文將選取城市人口、居民消費價格指數、平均等車時間、公交線路總長和網約車保有量等5個因素作為出租車保有量的主要影響因素。
預測過程如下:首先將以上5個因素的相關數據和出租車保有量數據分為訓練集和測試集,訓練集用于訓練隨機森林模型,生成決策樹;然后將測試集數據輸入到訓練好的隨機森林模型中,進行預測;最后輸出出租車保有量。
(二)隨機森林算法
隨機森林算法是基于Bagging的集成學習算法。該算法基于多棵決策樹構建組合模型對樣本進行分析預測。多數機器學習的方法傾向于在模型訓練時,以經驗風險最小化為原則求解最優模型,泛化能力差。但是隨機森林可以避免過擬合問題。本文將采用隨機森林對出租車保有量進行預測。下面將對隨機森林算法進行簡要說明(具體細節可以參考文獻[7]-[8])。
For i=1 to N,N表示決策樹的棵數:
1.從訓練集P中基于Boostrap方法抽取M個樣本;
2.從r屬性中q個屬性
3.選擇最佳屬性j和切分點s
4.建立決策樹Ti
End
輸出所有決策樹集合 ,構成隨機森林。
三、應用實例
(一)數據
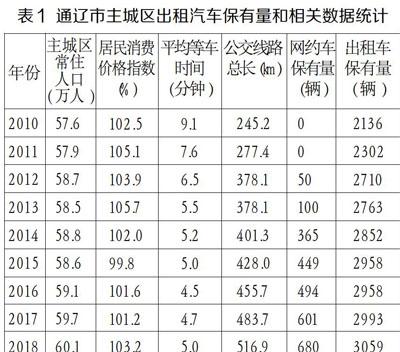
本文以內蒙古通遼市主城區的出租車保有量預測為例,對基于隨機森林的出租車保有量預測模型進行驗證和分析。通遼市位于內蒙古自治區的東部,總面積59535平方公里,城市道路網密度約2.32公里/平方公里,2018年地區生產總值1301.6億元,截止2018年底全市總人口為313.3萬人,其中通遼市主城區常住人口約為60萬人,截止2018年底通遼市主城區出租車保有量為3059輛。通遼市主城區的2010-2018年數據如表1所示,包括了城市常住人口、居民消費價格指數、平均等車時間、公交線路總長、網約車保有量和出租車保有量相關數據。
在計算時,將數據按上半年和下半年進行了細分以增加樣本數量。2010-2015年數據為訓練集,用于隨機森林訓練。2016-2018年數據為測試集,用于檢驗隨機森林預測精度。然后對本文中隨機森林算法的參數進行說明,決策樹的棵數N為50,總屬性r為5,隨機選擇屬性數量q為3。
(二)訓練模型
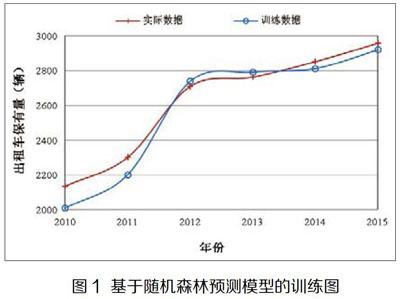
基于隨機森林預測模型的出租車保有量訓練曲線如圖1所示。藍線為實際數據,紅線為訓練數據,2010年到2011年預測數據小于實際數據,2012年到2013年預測數據大于實際數據,2014年到2015年預測數據小于實際數據。雖然出租車保有量數據有一定波動,但是訓練數據可以很好地跟隨實際數據,隨著訓練數據的增加,預測數量與實際數據的擬合度越來越高。通過計算可知,平均絕對誤差百分比為2.52%,R方為0.94,這兩個數據也側面說明了隨機森林的擬合優度。基于隨機森林的出租車保有量預測模型具有較強的識別能力,隨機森林通過平均決策樹,可以降低過擬合問題出現的概率。同時,隨機森林的擬合效果穩定,即使出現了新的數據點,也只是影響一棵決策樹,不會對整體算法受到太大影響。
(三)預測模型
本文用訓練好的預測模型和支持向量機模型對2016-2018年的出租車保有量進行預測,并將兩種預測方法進行對比分析。兩種算法的絕對誤差百分比如圖2所示。隨機森林的平均絕對誤差百分比0.34%,R方為0.93。支持向量機的平均絕對誤差百分比0.64%,R方為0.77。可以看出,隨機森林的預測表現要優于支持向量機。支持向量機的預測效果受其參數的影響,為了獲得較好的結果,通常還需要對其參數進行優化。即使在本文中對參數進行優化后,支持向量機的預測誤差仍大于隨機森林的預測誤差。從計算時間上看,支持向量機訓練的過程較為費時,特別是在非線性核的情況下,計算時間顯著增加。而且數據量增加后,差距也隨之增加。所以和支持向量機相比,隨機森林不僅可以獲得較優的預測值,還可以節約計算的時間。
本文通過隨機森林預測模型,對2020年通遼市主城區出租車保有量進行預測。首先要對2020年通遼市主城區的城市常住人口、居民消費價格指數、平均等車時間、公交線路總長、網約車保有量進行預測。然后將5個影響因素預測值輸入到隨機森林預測模型中,進行出租車保有量預測,預計2020年通遼市主城區的出租車保有量為3156輛。
四、結論
本文構建了基于隨機森林的出租車保有量預測模型,在選擇影響出租車保有量的因素時,主要考慮了需求、公共交通以及網約車等方面,選取城市常住人口、居民消費價格指數、平均等車時間、公交線路總長和網約車保有量等5個因素作為出租車保有量的主要影響因素。基于通遼市主城區數據,先對隨機森林進行訓練,然后用訓練好的模型進行測試。結果表明本文提出的預測方法擬合程度較好且預測精度較高,可以避免過度擬合等問題。該方法可以對城市出租車保有量進行有效的預測,不僅降低管理成本,提高運營效率,增加社會效益,還可以為城市交通客運管理部門確定合理的出租車保有量及類似城市出租車管理都提供了良好的借鑒和參考價值。由于影響出租車保有量的因素比較多,其他城市在應用該預測方法時,可以根據城市的特點,選擇相應的影響因素,以獲得較好的預測結果。
有效預測出租車保有量還可以有效提高經濟效益和社會效益,發揮出租車行業作為準公共交通的作用:
(一)較為準確地預測出租車保有量能夠提前對運輸資源進行高效合理分配,方便群眾出行,提高服務質量,平衡供給和需求,有利于提高運營者的經濟效益,同時也降低了出行者的等待時間,實現社會福利的提升。
(二)隨著生活水平的提高,居民對出租車的運力需求隨之增加。出租車和網約車形成了相互配合的良好運營關系,為城市出行增加運力,擴大社會就業,有效幫扶困難群體,促進就業和經濟雙增長。
(三)出租車是城市精神文明的一個流動服務窗口,其運營秩序的好壞、服務質量的優劣,體現了一個城市的管理水平和文明程度,直接關系到城市的聲譽和整體形象,甚至代表著當地政府的形象和市民的整體素質。城市出租車保有量的確定在樹立城市形象等方面發揮著重要作用。
(四)隨著城鄉一體化進程的推進,城鄉公共服務一體化也逐步布局,均衡配置城鄉公共運力資源有利于促進城鄉要素平等交換和公共資源合理安排,從而帶動城鄉經濟發展。做好地區出租汽車客運的發展規劃和總量控制,可以防止盲目發展無序競爭,確保道路旅客運輸市場健康發展和社會穩定。
參考文獻:
[1] Beesley, M. E., Glaister, S. Information for regulation: the case of taxi[J]. The Economic Journal, 1983, 93.
[2] Yang, H., Lau, Y. W., Wong, S. C., Lo, H. K. A macroscopic taxi model for passenger demand, taxi utilization and level of services[J]. Transportation, 2000, 27(3).
[3] 胡繼華, 謝海瑩. 基于浮動車數據的出租車規模確定方法[J]. 交通標準化, 2011,(18).
[4] 宋安, 劉琦. 出租車保有量評價與預測[J]. 交通科學與經濟, 2010, (3).
[5] 楊英俊, 趙祥模. 基于小波神經網絡的出租車保有量預測模型[J]. 公路交通科技, 2012, 8(29).
[6] Yang, Y., Yuan, Z., Fu, X., Wang, Y., Sun, D. Optimization Model of Taxi Fleet Size Based on GPS Tracking Data[J]. Sustainability, 2019, 11(3).
[7] Belletti, F., Bayen, A. M. Privacy-preserving MaaS fleet management[J]. Transportation Research Part C: Emerging Technologies, 2018,(94).
[8] Liaw, A., Wiener, M. Classification and regression by random Forest. R news, 2002, 2(3).
[9] Pal, M. Random forest classifier for remote sensing classification. International Journal of Remote Sensing, 2005, 26(1).
(作者單位:1.通遼市交通科學研究所;2.大連理工大學)
