對內存分布式列式數據庫查詢及優化探析
2018-10-26 01:42:20蘇暢
時代農機 2018年8期
蘇 暢
(黑龍江工業學院,黑龍江 雞西 158100)
在數據庫建設過程中,查詢引擎具備十分重要的地位與作用,提升數據庫查詢功能的關鍵在于做好查詢優化工作。以往傳統數據庫的應用過程中存在多種優化查詢方法,但相較傳統數據庫而言,分布式列式數據庫的數據存儲位置、信息讀取方式以及組織結構分布等方面均存在較大差異,查詢優化方式各不相同,這便導致傳統數據查詢優化方式并不適用于分布式分列數據庫。對此,應基于內存分布式列式數據庫的自身特點,不斷優化查詢方式,拓展其查詢范圍,提升系統的運行效果。
1 數據庫查詢技術的應用
(1)關系數據庫。在關系數據庫中,數據之間的內在關系主要以表格的形式體現,其核心內容為表格,描述對象為數據內容,表格中存在多個描述對象,因此關系模型也存在多種內在的描述關系。描述關系模型的過程被稱為關系代數,其主要以表格模型為操作基礎,針對分布式列式數據庫關系進行查詢操作,體現了關系代數的運用。并、交、差、選擇、組合以及投影等均屬于關系代數的操作,對于不同操作模式需要利用不同符號表示,以有效體現出兩個關系主體之間的操作特征。在對分布式列式數據庫進行查詢請求時應通過不同等價代數關系進行表達,其查詢優化工作的基礎便為時間應用、空間應用以及代數關系轉化等。
(2)列式存儲及查詢優化技術。列式數據庫一般通過二維表的模式進行構建,且計算機主要通過連續地址的方式存放模型數據,將描述對象的空間邏輯結構轉換為平面物理存儲模式。不同于傳統的數據庫系統,列式數據庫主要采用列式存儲方式,在存儲完一列之后再存儲下一列。而傳統數據庫則采用行存儲方式,即在存儲完一行之后再存儲下一行。行與列的存儲方式均具備自身的優缺點。為了提升數據的查詢效率,數據存儲方式方面應采用行表順序,而模型構建方面則采用列式方式。除此之外,還可以應用混合索引、行號索引等存儲方式,根據不同的數據庫應用領域進行針對性選擇,從而體現不同的應用優劣勢。
(3)分布式環境查詢優化技術。分布式列式數據庫在數據節點的分布方面存在交互特征,內部分布式環境在進行信息查詢與檢索時也存在較多差異,且查詢工作的關鍵在于節點之間的傳輸成本。在數據查詢過程中,系統會將不同的查詢任務分配至不同的數據節點中,且期間必須考慮數據在網絡中的傳輸成本。同時,查詢優化的關鍵在于執行正確的數據分布策略與查詢任務執行策略,并根據分布式數據庫的結構特點,將數據分散至不同物理節點中,有效提升查詢效果。
(4)數據庫查詢的基本流程。數據庫應用的關鍵內容便是查詢任務的執行,其也更好地體現了數據庫的應用效率。查詢引擎可以有效接收客戶端的用戶查詢請求,并由DC轉化成語言,在分析之后確定查詢計劃,之后在由執行引擎完成查詢工作任務,最終向客戶端反饋查詢結果。一般而言,數據庫查詢流程可以歸納如下:一是客戶端發送查詢語言,請求至DC層面;二是DC將客戶查詢請求發送至QE節點,之后解析查詢語言;三是QE解析查詢請求后執行查詢計劃,并將其發送至主控節點,進行位置提示;四是DC向客戶端告知查詢應用的目標QE節點;五是目標QE節點與客戶端進行鏈接,建立關系;六是計劃節點向其他QE節點發送數據查詢請求;七是QE節點向下層CS發送數據查詢請求;八是CS反饋數據信息,并執行命令;九是根據執行要求匯總不同QE節點計算的數據,計算最終結果;十是向客戶端反饋最終查詢結果,完成全部查詢任務。其具體流程見下圖1所示。
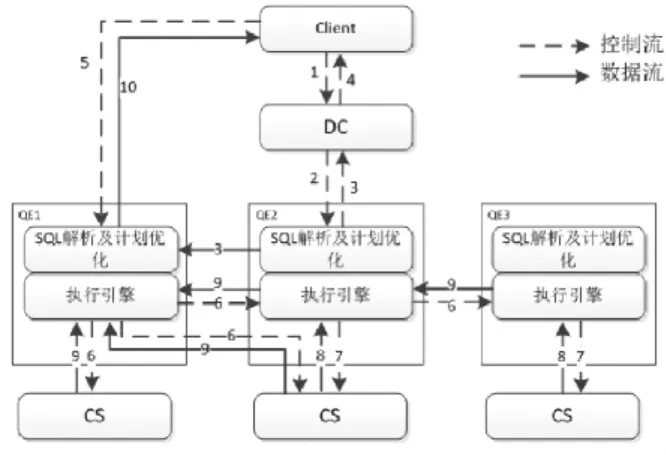
圖1 數據庫查詢基本流程
2 內存分布式列式數據庫查詢優化
(1)查詢優化的基本流程。數據查詢工作開始于查詢任務執行命令,之后經過層層數據的傳輸與轉化形成最終的物理操作計劃。且其流程可以分為語法解析階段、預處理階段、根據規則執行轉化階段、查詢并計算代價階段以及確定最優查詢路徑階段。首先是語法解析階段,此階段主要語法分析查詢語言,并將語言分解為具有代表意義的詞匯,之后對不同詞匯進行語法分析,確定不同單詞之間的語言邏輯關系。在此階段需要篩選不符合語法規則的查詢語言,確保執行階段的查詢語言負荷規則,從而有效完成后期的查詢任務。其次是預處理階段,主要預先處理語法樹中的表達方式,減少執行階段的工作量。在此階段中主要整理去除多余的詞匯前后綴,并通過語法樹的預處理遍歷,形成具有邏輯執行價值的初始查詢計劃。再次是執行計劃優化階段,主要適當調整上階段的查詢計劃,通過關系代數模型完成技術操作,并通過計劃調整減少執行任務量的工作目標,在提升查詢工作效率的基礎上,確定最優的查詢應用與計劃方案。最后是物理優化,其主要利用不同的優化選擇方式生成最優選擇價值的空間。
(2)查詢優化設計。一是設計查詢引擎,解析與優化查詢語言的語句,并執行查詢任務。期間主要由查詢優化與任務執行優化等兩方面進行,且其彼此保持獨立,而任務執行優化則可以由計劃解析、執行、緩存管理等方面進行,從而有效提升優化效率。二是數據存儲與分布方案,數據庫的基本功能為數據存儲,其也屬于查詢優化的工作基礎。在查詢優化方面應選擇Group-Key列式存儲方式,確保數據之間的關聯性,通過扁平化的集成模式體現不同數據間的交互特點,提高查詢效率。
(3)算法細節優化。不同節點的數據計算也影響著最終的查詢效率,應重視優化算法細節,從而有效提升不同QE節點的計算效率,本系統中應采用遺傳算法與貪心算法。
(4)查詢任務樹設計。查詢語法樹結構直接影響著查詢優化目標,因此應由語法樹結構以及樹的不同節點完成任務樹的設計工作,通過合理調整系統結構提高信息的處理效率。
3 實現查詢優化
實現查詢優化應以數據查詢流程為基礎,主要分為邏輯計劃優化、預處理模塊優化、規則優化以及物理優化等過程。邏輯計劃數據結構對應一顆語法樹,且將查詢任務分解為不同模塊,通過分解信息與查詢模塊的匹配實現查詢任務的無歧義檢索。預處理主要去除冗余部分,實現預期的工作目標。規則優化確保查詢服務契合邏輯計劃,確保無論數據發生怎樣變化,其均可以在語法樹結構中體現邏輯關系。物理優化主要根據系統的狀態進行查詢計算,通過調用邏輯計劃,形成最優路徑。在查詢優化策略過程中需要合理的想象,要在考慮非查詢任務的基礎上,滿足實際的查詢任務工作需求,結合使用列式存儲與應用模型關系,確保關系代數的優化操作拓展至數據庫建設與實際應用過程中,從而達到預期的查詢優化設計結果。
4 結語
隨著計算機硬件技術的快速發展,內存的使用效率與使用量也得到進一步提升,作為提高數據庫應用效率的關鍵因素,查詢優化可以促使分布式列式數據庫得到更好發展,從而有效推動數據庫應用技術的發展與不斷進步。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
