基于PLSA和SVM的道岔故障特征提取與診斷方法研究
2018-07-20 09:06:10鐘志旺
鐵道學報 2018年7期
鐘志旺, 唐 濤, 王 峰
(1. 北京交通大學 電子信息工程學院, 北京 100044; 2. 北京交通大學 軌道交通控制與安全國家重點實驗室, 北京 100044)
鐵路道岔是鐵路系統重要的線路連接設備,包括道岔和道岔轉換設備。道岔轉換裝置,一是根據行車需要,按照聯鎖技術條件將分叉線路開通在需要的位置,保證正確的行車路徑;二是道岔轉換到位后期,通過缺口檢查,判斷道岔尖軌與基本軌之間是否達到規定的密切程度,以保證列車通過道岔時的行車安全。道岔轉換設備在室外,受風沙、雨雪、酷暑和嚴寒等自然條件和列車震動、沖擊,鋼軌爬行、橫移等外界因素影響較大,而且使用數量多,在信號設備中,一直是故障率較高的設備。通過統計某鐵路局近4年來的信號設備故障發現,道岔轉換設備故障占所有信號設備故障總數的40%以上。
道岔維護是鐵路基層電務段設備維護的主要工作之一,在設備維護過程中,積累了大量的歷史數據,存儲的格式多樣,但電子數據基本上都是以文本方式記錄或者可以當成文本處理。這些維護數據對道岔故障分析和設備維護決策有重要參考價值。
目前,國內外學者在道岔故障診斷方面進行了研究。文獻[1-5]對道岔關鍵參數監測進行了研究,描述了監測和方法系統的原理及結構。但是,目前對基于故障維護文檔的故障診斷研究相對較少,而故障記錄數據對于道岔故障的研究至關重要。道岔的故障診斷主要由數據特征提取和診斷兩部分組成。
通過調研中國鐵路廣州局集團有限公司(以下簡稱廣州局)以及長沙電務段、廣州電務段、懷化電務段等保存的歷史故障一覽表發現,故障數據錄入缺乏規范性,且不同時間段錄入數據字段設置和語言描述差距較大,導致故障數據可利用價值降低;鐵路局和各站段的故障表中設備類別設置不完全一致,對故障數據的統計和處理帶來一定的難度。針對上述問題,一些學者[6-10]提出基于本體的文檔標準化架構來解決維護過程中出現的信息描述不一致問題,促進了對鐵路維護大數據的規范化管理,但仍然不能對大數據進行有效的分析和處理。文獻[9]提出將文本挖掘的方法引入鐵路車載設備故障診斷,提供了新的處理思路,但是存在以下缺點:一是完全考慮人工經驗選取故障詞項空間,導致處理效率低并且無法自動遷移到其他鐵路設備;二是采用貝葉斯網絡的診斷方法需要基于有因果結構(一級故障為二級故障的原因)的故障記錄數據,存在較大的局限性,并且在數量較小的樣本上診斷表現效果不理想。
目前有關道岔設備的故障診斷,依然主要依賴于專家經驗,導致維修時間無法保障,從而影響鐵路運營的效率和安全性。另一方面,由于道岔設備的工作環境復雜,負載繁重,使得道岔設備故障模式眾多,為道岔設備故障診斷帶來挑戰。
針對道岔設備故障記錄數據的描述復雜性和難處理性,以及克服文獻[9-10]等提出方法的局限性,本文提出基于分詞算法和主題模型相結合的方法來提取道岔設備故障描述的故障詞項特征和故障主題特征,獲得故障文檔在主題特征空間中的表達[11],從而降低特征維度和算法復雜度。針對小樣本故障模式診斷效果不理想的問題,選取SVM作為故障分類方法,SVM已經被公認為是在小樣本數據上進行學習的最有效模型之一,本文以廣州局現場數據為基礎進行實驗分析。
1 背景
依據道岔轉化系統故障機理進行分析,道岔的故障主要分為電氣故障和機械故障。現場維護記錄表明,道岔故障中機械故障占比約為90%以上。
1.1 道岔設備故障記錄數據
本文將廣州局提供的故障一覽表中的道岔故障分離出來,針對道岔相關的故障進行故障原因分析。表1給出的是故障一覽表中部分例子。
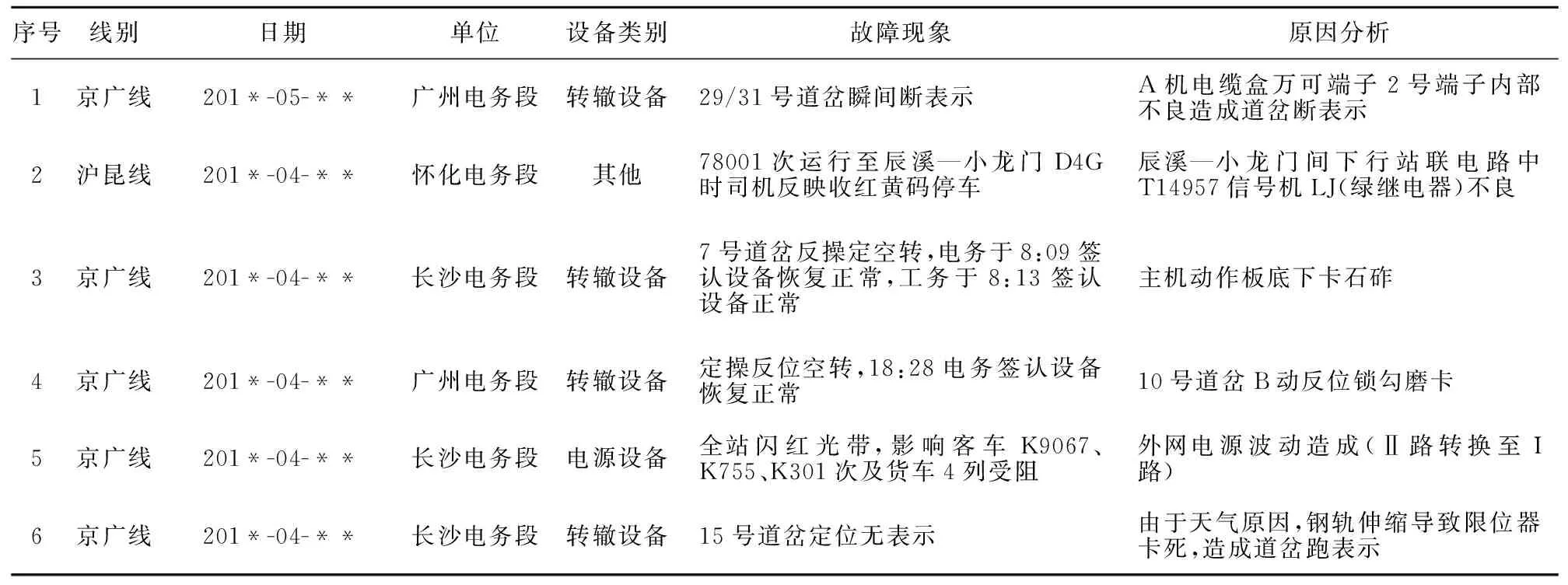
表1 道岔相關故障數據舉例
從表1可知,故障原因包含眾多故障現象描述信息,但由于現場維護人員語言習慣以及維護技能的不同,導致記錄方式口語化和記錄差異性,諸如此類的問題增加了故障診斷算法的復雜性和診斷難度。
由于故障類別是故障診斷模型訓練的數據基礎,因此依據道岔結構組成,結合故障數據信息,將道岔故障分類為12個故障類別,見表2。
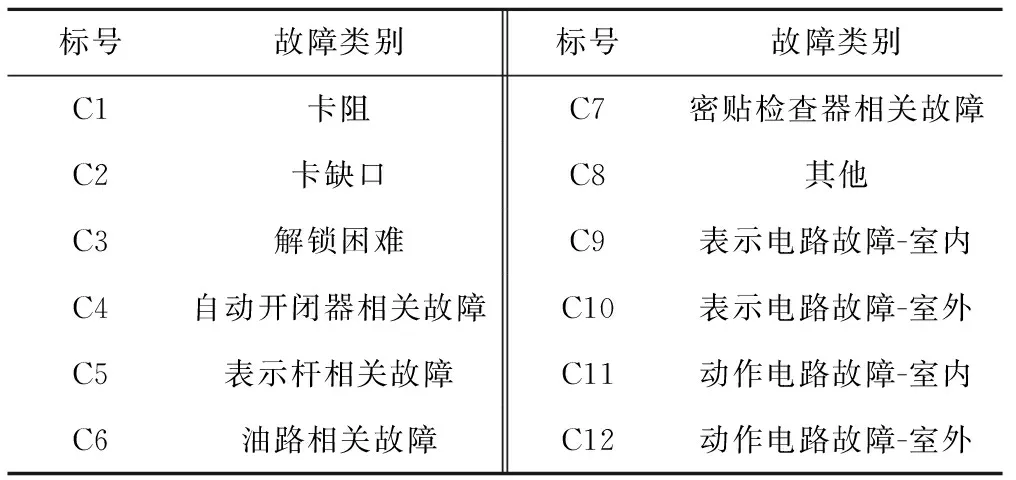
表2 道岔故障類別
1.2 道岔設備故障診斷流程
圖1為道岔轉換系統故障診斷的實現步驟,主要為故障詞項特征提取、故障主題特征提取(語義特征)和故障診斷3部分。其中,故障詞項特征提取主要采用中文分詞手段和“詞袋模型”方法對故障文檔進行表達;由于語義信息的丟失和維度較高,對故障診斷帶來較大挑戰,因此,采用主題模型進行語義特征提取和降維,將故障文檔表達在主題特征空間上;最后,采用支持向量機作為診斷器對道岔轉換系統進行故障診斷。
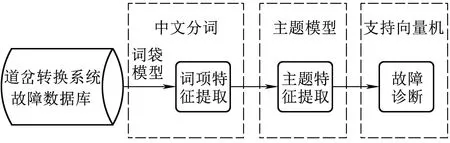
圖1 道岔故障診斷框架
2 基于文本分詞和主題模型的故障特征提取
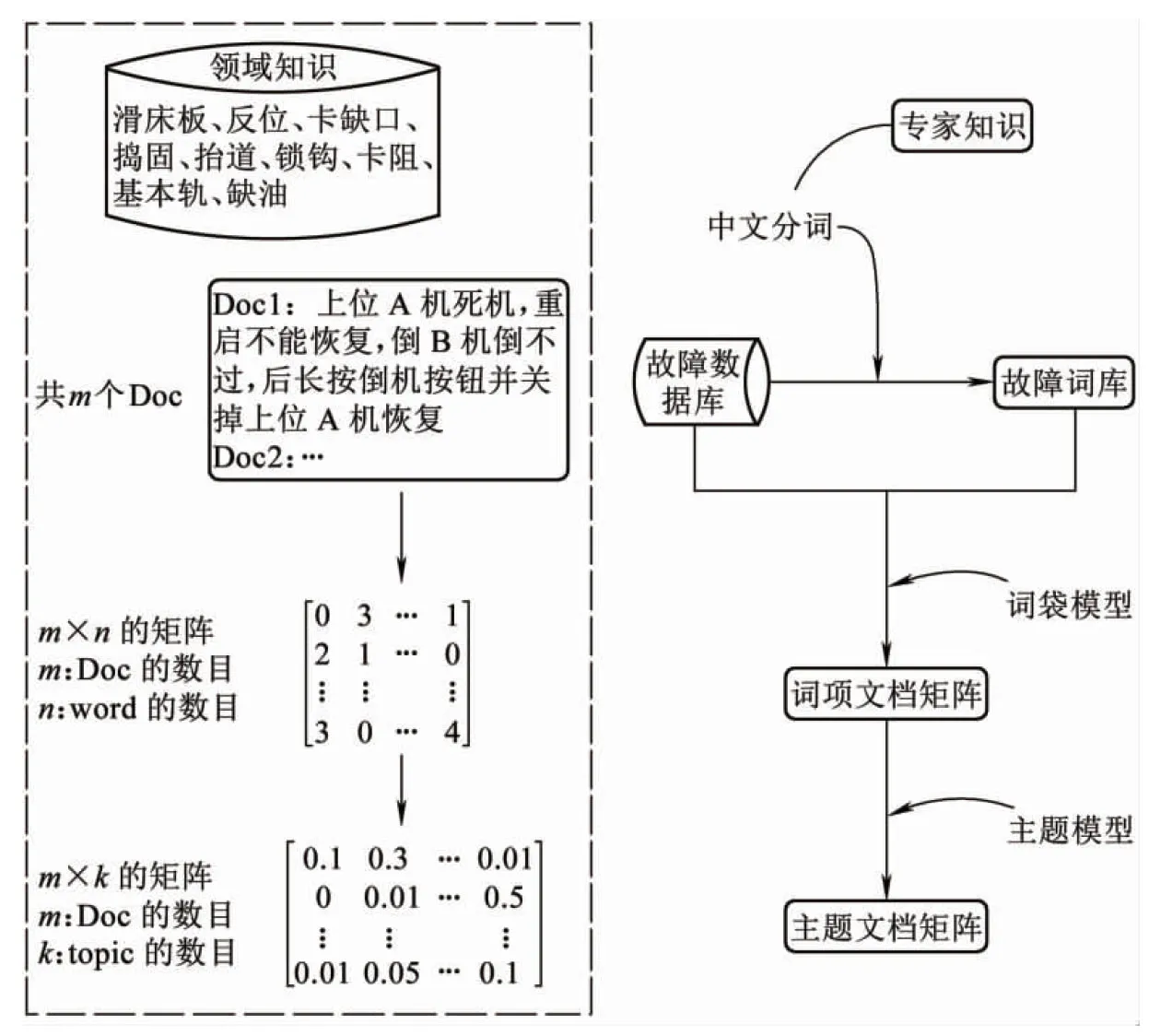
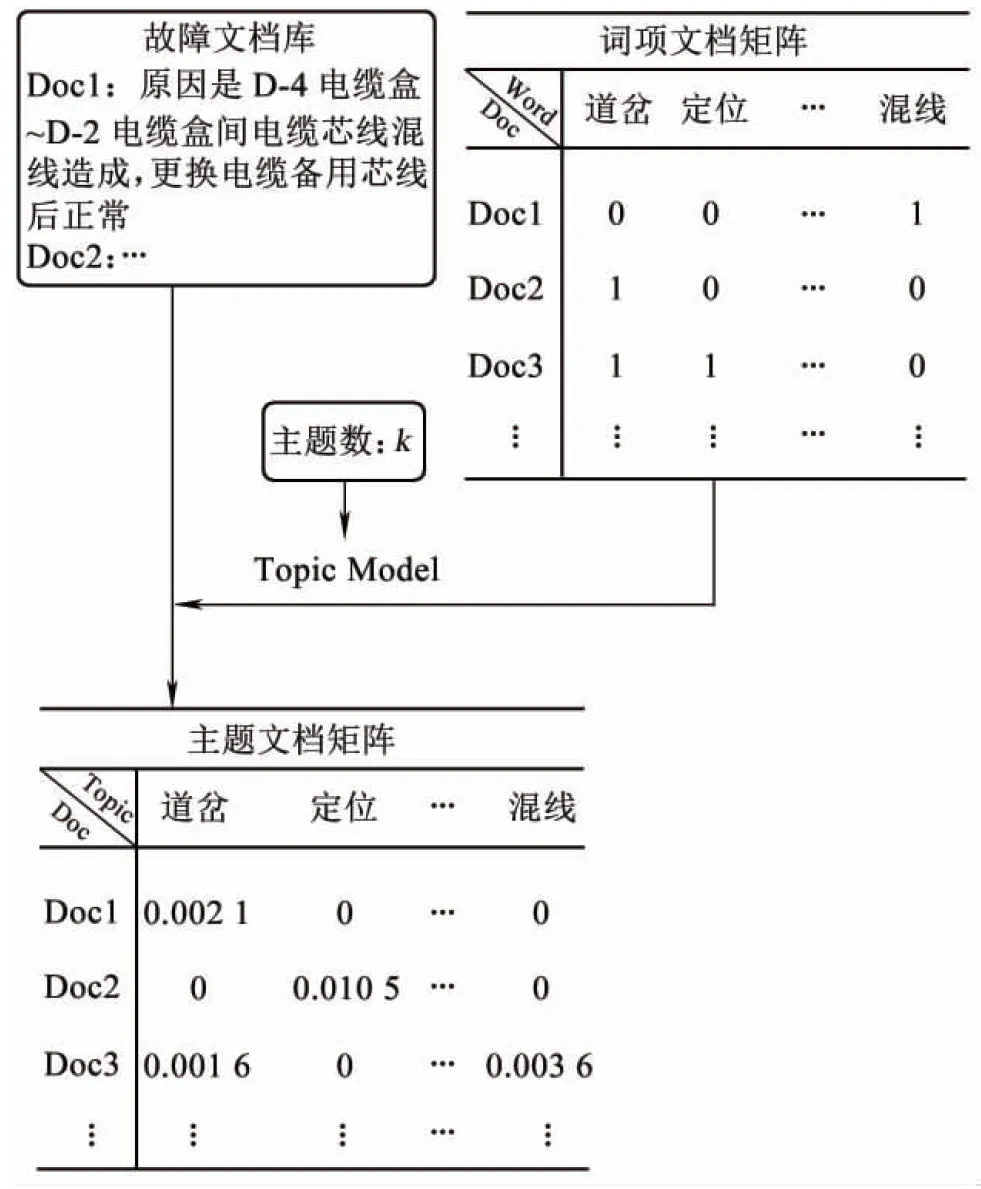
由于故障文本記錄主體(信號工)的差異性,導致故障現象描述的不一致性和復雜性,增加了診斷推理的復雜性。恰當的故障特征能夠降低道岔故障診斷的復雜度,提高診斷效率。在自然語言處理領域,對于以文本形式的原始表達模型為詞項的向量空間模型VSM( Vector Space Model),向量的維度即詞項的數量。此模型的缺點是忽略了詞項的順序和詞項之間的關聯關系,只統計各詞項在文檔中出現的次數。因此,對于道岔設備故障診斷來說,其原始特征即為故障詞項特征。采用VSM模型表達道岔設備故障描述,忽略了故障詞項特征之間的關聯關系,因此,也就降低了后續故障診斷的效率。近些年,一種可以抽取文本庫中隱層主題的方法,主題模型(Topic Model),在諸多領域有著廣泛的應用,如社交網絡、用戶評價、新聞分類、情感分析等。因此,為了克服上述問題并提高特征提取的自動程度以及在故障診斷上的適應度,本文通過文本分詞(Segmentation)[12-13]和主題模型[14-15]對道岔設備的故障記錄進行分割和主題提取,具體步驟見圖2。首先將故障文檔在“詞袋模型”框架下表達為詞項文檔矩陣,實現原始故障特征提取;然后,通過“主題模型”的架構,將故障文檔的“故障詞項特征空間”轉換到“語義特征空間”,進一步實現故障主題特征提取。
2.1 故障詞項特征提取算法
對于原始故障詞項特征的生成,通過中文分詞技術對故障文檔進行自動處理而實現。近年來,中文分詞技術已經有了較大發展,出現了眾多的算法。主要包括以下4類:基于字符串匹配的分詞方法、基于理解的分詞方法、基于統計的分詞方法和基于語義的分詞方法[12-13]。中文分詞算法的核心思想是給定文檔記錄(輸入文字串)后,采用分詞算法對文檔進行分割和過濾處理,進而依據算法輸出最優的分詞結果,即中文詞項、其他類別字符串或單詞。分詞算法模塊的流程結構見圖3。
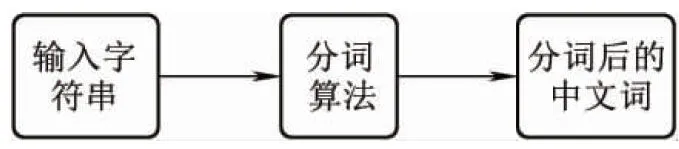
本文采用NLPIR漢語分詞算法(又名ICTCLAS)對故障進行分詞處理。由于一般通用的分詞工具并不包含特定領域的專業詞匯。分詞工具對道岔的故障現象描述記錄進行分詞,結果不理想。
在鐵路信號領域中的一些詞匯,如基本軌、滑床板、頂鐵等有其特定含義,并攜帶重要的故障類別信息,分詞過程中應當作為一個詞項處理。因此,我們通過在分詞過程中將領域專家知識,即領域特定詞庫,添加到分詞匹配詞庫中,可以獲得較為理想的效果。對于道岔轉換系統的特定詞匯見表3。

表3 道岔設備故障專業詞匯舉例
對故障文檔進行中文分詞后,便可以得到道岔轉換設備故障詞典。在VSM模型的假設下,可以將故障文檔表達在詞項空間上。詞項文檔矩陣的生成見圖4。
2.2 基于PLSA主題模型的故障主題特征提取
由于“故障詞項特征空間”未考慮詞項順序和關聯性,無法表達文本語義,因此不能較好地解決同義詞和一詞多義問題,增加了后續故障診斷的復雜性。近幾年,主題模型技術PLSA( Probability Latent Semantic Analysis) 得到較快發展[14-15],它通過詞項貢獻,挖掘語義上的關聯性,能夠將文檔由詞項特征空間變換到主題特征空間上,從而解決上述問題。因此,本文采用主題模型算法進行故障語義特征提取。
2.2.1 PLSA算法
PLSA的核心思想[14-15]是將詞項之間復雜的關系(共現數據對——即文檔d∈D={d1,d2,…,dN}中出現故障詞項對wi,wj∈W={w1,w2,…,wM}的頻率)用中間隱藏變量z∈Z={z1,z2,…,zK}的形式表達,也就是所謂的語義聯系模型, 該模型可以表示為故障詞項與故障文檔的聯合分布概率。
( 1 )
繼而對PLSA模型進行參數估計,采用極大似然估計來求取
( 2 )
式中:f(di,wj)為故障詞項wj在故障文檔di中出現的次數。
對于模型的擬合,在含有隱藏變量的模型中,極大似然估計的標準過程是期望極大(EM)算法,EM算法可以描述為以下兩個步驟的交替:
E-步, 利用當前所估計的參數值對隱藏變量的后驗概率進行計算。
M-步, 基于上述后驗概率, 對參數值進行更新。
對于PLSA模型, 通過貝葉斯公式可以得到隱藏變量的后驗概率為
( 3 )
對式( 2 )進行極大化,對參數P(zk|di)及P(wj|zk)進行重新估計, 從而得到新的參數值為
( 4 )
通過對式( 3 )、式( 4 )的迭代,收斂后即可得到參數的估計值。
2.2.2 道岔設備故障主題特征提取
根據PLSA的原理和道岔相關故障的特點,對道岔故障文本數據進行特征提取的流程見圖1。道岔故障文本特征提取流程為:
Step1故障追蹤記錄文檔獲取。
Step2詞項空間向量模型建立。經過文本分詞并進行去停用詞之后,得到原始故障詞項特征,在詞項空間中表達故障文本。
Step3利用主題模型。選擇合適的主題數量,建立主題模型,將故障文本通過主題模型空間表達。
在使用PLSA算法進行故障主題特征挖掘的過程中,首先要給定主題特征的數目k。采用拇指規則和打分算法來確定,即通過設定一定的步長改變k值進行測試,選取文檔似然值達到最優的k值作為最終的主題數。一般來說,主題特征在一定程度上攜帶了原文檔表達的語義。表4為廣州局道岔的故障記錄由主題模型特征提取后得到的結果。

表4 道岔系統故障記錄表中故障主題特征的提取結果
表4表明,語義特征T1與“尖軌卡物”這一故障模式相關,特征T2代表“空轉”的故障模式,特征T3與“接點接觸不良”的故障模式相關等。文檔在故障主題特征空間上的表達過程見圖5。
3 基于支持向量機的道岔設備故障診斷
支持向量機已在很多領域有了廣泛應用,取得了良好的效果。道岔轉換系統的故障模式具有種類多,各模式分布不均衡,而且一些故障模式樣本數量十分有限的特點。對于學習算法,支持向量機在小樣本數據上具有較大優勢,能夠僅僅依賴少數的支持向量進行診斷決策。因此,本文采用支持向量機進行道岔設備故障診斷。
3.1 支持向量機
支持向量機[16-18]是在統計學習理論基礎上發展起來的機器學習方法,是結構風險最小化原理的實現。
SVM本質上是一個分割超平面,是分類優化問題的一種解決方案。其算法如下:
假設數據集為(x1,y1),(x2,y2),…,(xp,yp),x∈Rp,y∈{1,-1}。
對于原始的優化問題,可表述為
s.t.yi(wTφ(xi)+b)≥1-ξiξi≥0
( 5 )
式中:C為懲罰因子,C≥0。
通過拉格朗日乘子法以及KKT (Karush-Kuhn-Tucker )條件,可以得到其對偶優化問題
minLd(α)=
( 6 )
式中:αi、βi為拉格朗日乘子;φ(xi)Tφ(xj)=K(xi,xj)為核函數。
進而,為求解拉格朗日乘子,轉化為一個標準二次最優化問題
s.tyTα=0 0≤αi≤Ci=1,2,…,p
( 7 )
式中:α=[α1,α2,…,αp]T,y=[y1,y2,…,yp]T,e=[1,1,…,1]T,Qij=yiyjφ(xi)Tφ(xj)=yiyjK(xi,xj)。
可求得ω*和b*的最優解為
( 8 )
式中:Nsv為支持向量的個數(拉格朗日乘子不等于0)。
3.2 基于支持向量機的道岔轉換系統故障診斷
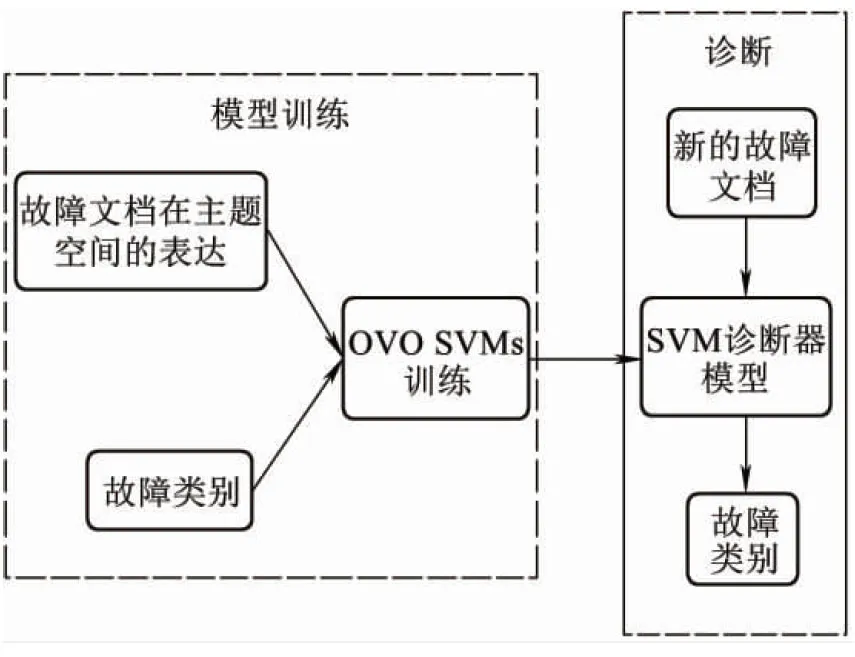
在特征提取階段,將故障文檔表達在故障主題特征空間上,得到主題文檔矩陣。SVMs診斷器的訓練和診斷過程見圖6。主題文檔矩陣和故障文檔對應的故障類別標簽作為模型訓練數據,輸入一對一多分類策略下的(OVO SVMs)模型進行訓練,得到最終的SVM診斷器模型。對于新故障的產生,首先將故障現象描述文檔在主題特征空間下表示,進而輸入到訓練好的SVM診斷器模型進行故障診斷,即可得到所發生故障的模式,從而實現道岔轉換系統的故障診斷。
4 實驗結果
本文通過兩個實驗對所提出的道岔設備故障特征提取和故障診斷算法的有效性和準確性進行驗證。主要包括故障主題特征提取算法的驗證和故障診斷算法的驗證。
4.1 實驗數據
利用廣州局現場故障追蹤記錄作為故障文檔庫。采用廣州局對道岔維護過程中積累的道岔相關的1 500多條故障記錄,其中,1 000條用于模型訓練,剩余數據用于測試。數據的各類別故障樣本情況,見表5。
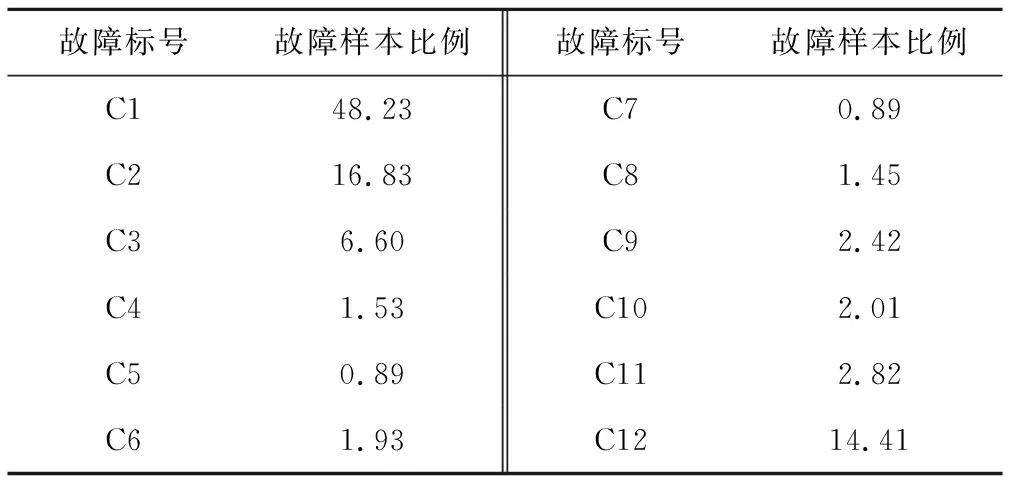
表5 道岔故障類別及數據組成 %
4.2 評價指標
對于分類效果的評價,采用F1-score和準確率兩種指標[19]。其中,F1-score中的1代表“精度”(precision)和“召回率”(recall)采用權重相同,也就是式( 9 )中的β=1。對于多類分類器的評估,F1-score算法如下:
算法1多類分類器的F1-score評估方法
Lineno=
(1) for每個故障模式Cido
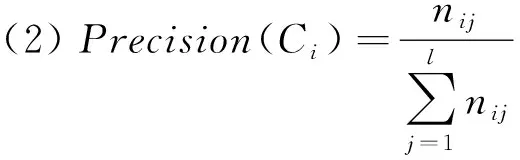
(3) end for
(4)F-score←通過式( 9 )計算所有故障類別的F-score值。
( 9 )
式中:l是類別總數。令β=1,可得F1-score值。
4.3 特征提取的實驗分析
為了驗證特征提取的合理性,通過比較診斷器分別在兩種特征空間上(故障主題特征空間和故障詞項特征空間)的效果進行評估。實驗結果見圖7。
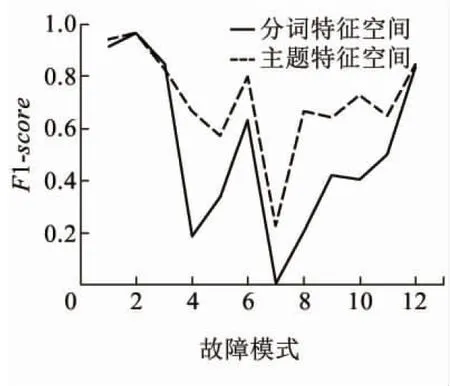
圖7給出了各故障模式的F1-score值,表明故障主題特征相對于故障詞項特征具有明顯優勢,診斷效果更為理想,主要表現為故障樣本數量較少的故障模式效果更佳,驗證了故障主題特征提升了小類樣本的可分性,從而降低了誤報率。另外,本文從整體準確率的角度驗證了所提出的故障特征提取算法的效果。其中,SVM診斷器在故障詞項特征空間以及故障主題特征空間上的診斷準確率分別為86.06%和90.11%,表明故障主題特征空間更有利于道岔設備故障診斷任務。
4.4 故障診斷算法的實驗分析
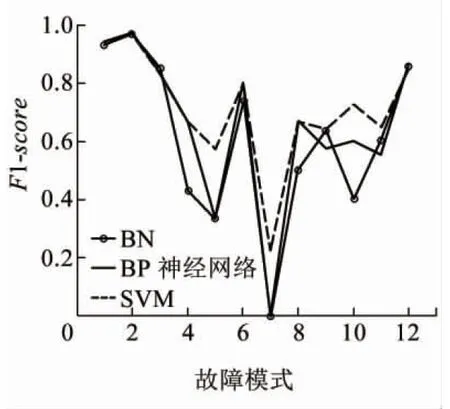
為了驗證所采用診斷算法的可行性,與其他兩類故障診斷分類算法進行對比,即貝葉斯網絡算法BN以及BP神經網絡算法(選用故障主題特征空間)。圖8給出了三種診斷器的效果,表明本文采用的算法較神經網絡算法和貝葉斯網絡算法,對于小樣本故障模式的診斷效果誤報率更低。然而,BP神經網絡和BN算法在提高小類樣本的診斷效果同時,在樣本其他故障模式的診斷效果略低于SVM算法,例如故障模式C5和C9。其次,本文從整體診斷準確率的角度驗證了SVM診斷器對于道岔設備故障診斷的效果。三種算法的診斷準確率分別為:BN算法為89.14%,BP神經網絡算法為88.98%,SVM算法為90.11%。
5 結束語
通過分詞算法對故障文檔進行分詞,自動提取道岔領域故障詞庫,即詞項空間;通過向量空間模型將文檔表達在詞項空間中;在此基礎上,通過主題模型PLSA方法進行故障主題特征提取,進而將故障文檔表達在主題特征空間中,為診斷準備基礎;通過構造SVM診斷器實現道岔設備故障診斷。通過現場的實際數據驗證,說明提出算法對道岔故障診斷有良好的效果。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
