基于改進(jìn)粒子群優(yōu)化BP_Adaboost神經(jīng)網(wǎng)絡(luò)的PM2.5濃度預(yù)測(cè)
2018-05-30 00:57:48李曉理,梅建想,張山
大連理工大學(xué)學(xué)報(bào) 2018年3期
關(guān)鍵詞:模型
李 曉 理, 梅 建 想, 張 山
( 1.北京工業(yè)大學(xué) 信息學(xué)部, 北京 100124;2.計(jì)算智能與智能系統(tǒng)北京市重點(diǎn)實(shí)驗(yàn)室, 北京 100124;3.數(shù)字社區(qū)教育部工程研究中心, 北京 100124 )
0 引 言
隨著工業(yè)化程度不斷加大,廢氣、廢渣排放增加,大氣污染愈發(fā)嚴(yán)重,尤其是顆粒物質(zhì)(PM)污染,這一問(wèn)題已引起國(guó)家相關(guān)部門高度關(guān)注.顆粒物質(zhì)不僅會(huì)影響居民生活、出行,破壞生態(tài)系統(tǒng),而且跟人類健康密切相關(guān).在過(guò)去幾十年間,研究表明,人口每日死亡率增長(zhǎng)和各種疾病癥狀(如哮喘、慢性支氣管炎、肺功能下降等)與大氣中顆粒物質(zhì)濃度有顯著關(guān)系.因此,許多業(yè)界人士對(duì)如何預(yù)測(cè)大氣污染物中PM2.5濃度開(kāi)展了相應(yīng)研究,為居民生活、出行提供決策.最初,統(tǒng)計(jì)學(xué)方法被用于預(yù)測(cè)空氣污染物,Kumar等用自回歸整合移動(dòng)平均模型預(yù)測(cè)印度德里郊區(qū)每日臭氧、一氧化碳、氮氧化物平均濃度[1];Elbayoumi等結(jié)合大氣污染物變量和氣象條件,利用多元線性回歸模型預(yù)測(cè)當(dāng)?shù)厥彝釶M2.5濃度隨著時(shí)間和季節(jié)的變化趨勢(shì)[2].Ishak等利用多元線性回歸、模糊系統(tǒng)和廣義可加模型研究突尼斯當(dāng)?shù)貧v史時(shí)刻PM2.5濃度對(duì)未來(lái)空氣質(zhì)量預(yù)測(cè)的影響[3].同時(shí),Nieto等通過(guò)建立多元自適應(yīng)回歸樣條預(yù)測(cè)模型,分析出了西班牙奧維耶多當(dāng)?shù)貧庀蠓植继卣鱗4].雖然這些回歸模型被應(yīng)用于大氣污染預(yù)測(cè),但是復(fù)雜地形、氣象條件、污染物等多種因素共同影響,導(dǎo)致預(yù)測(cè)模型呈現(xiàn)出高度非線性,增加了PM2.5濃度預(yù)測(cè)難度.因此,傳統(tǒng)回歸模型在用于大氣預(yù)測(cè)中,往往難以滿足允許精度,預(yù)測(cè)性能欠佳.
大量研究表明,相比于傳統(tǒng)統(tǒng)計(jì)學(xué)方法,神經(jīng)網(wǎng)絡(luò)具有良好的非線性逼近、自組織和自學(xué)習(xí)能力,無(wú)須確定輸入和輸出之間函數(shù)關(guān)系,只需通過(guò)對(duì)數(shù)據(jù)樣本進(jìn)行訓(xùn)練,利用訓(xùn)練好的網(wǎng)絡(luò)來(lái)對(duì)輸入數(shù)據(jù)進(jìn)行預(yù)測(cè)[5],可以有效解決建模難題,因此其被廣泛應(yīng)用于大氣污染預(yù)測(cè).孫寶磊等采用MIV方法篩出主要因子,建立BP神經(jīng)模型預(yù)測(cè)昆明地區(qū)日均污染物濃度[6];針對(duì)芬蘭赫爾辛基城區(qū),Kukkonen等建立多種神經(jīng)網(wǎng)絡(luò)模型預(yù)測(cè)PM2.5小時(shí)平均質(zhì)量濃度[7];同樣地,石靈芝等建立BP神經(jīng)網(wǎng)絡(luò)模型預(yù)測(cè)湖南長(zhǎng)沙火車站PM10小時(shí)平均質(zhì)量濃度[8].Elangasinghe等用BP神經(jīng)網(wǎng)絡(luò)結(jié)合k-means聚類算法[9],建立了一個(gè)基于監(jiān)測(cè)站氣象條件和PM2.5、PM10濃度預(yù)測(cè)模型,能夠有效預(yù)測(cè)新西蘭南側(cè)島嶼空氣主要污染指數(shù).由此看出,BP神經(jīng)網(wǎng)絡(luò)模型具有較好預(yù)測(cè)性能,已引起人們廣泛關(guān)注.但是,BP是一類弱預(yù)測(cè)器,存在過(guò)擬合和容易收斂于局部極小點(diǎn)問(wèn)題.因此,模型預(yù)測(cè)精度有待進(jìn)一步提高.
為此本文將BP神經(jīng)網(wǎng)絡(luò)和Adaboost算法結(jié)合,提出一種基于BP_Adaboost神經(jīng)網(wǎng)絡(luò)[10-11]的PM2.5濃度預(yù)測(cè)模型,建模時(shí)考慮影響PM2.5濃度的多種因素,并用灰色關(guān)聯(lián)分析選取影響PM2.5濃度的主要因子作為神經(jīng)網(wǎng)絡(luò)輸入變量;此外,運(yùn)用改進(jìn)粒子群算法來(lái)優(yōu)化神經(jīng)網(wǎng)絡(luò)權(quán)重和閾值,以有效避免陷入局部最優(yōu)解;最后以北京市海淀區(qū)萬(wàn)柳監(jiān)測(cè)站和朝陽(yáng)區(qū)北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)的實(shí)時(shí)數(shù)據(jù)為例,驗(yàn)證模型預(yù)測(cè)性能.
1 改進(jìn)粒子群優(yōu)化BP_Adaboost神經(jīng)網(wǎng)絡(luò)模型建立
1.1 灰色關(guān)聯(lián)分析
灰色系統(tǒng)理論認(rèn)為,含有已知信息或不確定性信息的系統(tǒng),從表面上看,數(shù)據(jù)可能是隨機(jī)的、雜亂無(wú)章的,但是其仍然是有界和有序的,數(shù)據(jù)集內(nèi)會(huì)呈現(xiàn)一定規(guī)律.正如對(duì)天氣預(yù)報(bào)系統(tǒng)而言,大氣中PM2.5濃度受多種因素共同影響,各因素間相互關(guān)系無(wú)法定量分析,還會(huì)在一定范圍內(nèi)波動(dòng),屬于動(dòng)態(tài)變化的.因此,可借助灰色關(guān)聯(lián)分析方法鑒別各因素之間發(fā)展趨勢(shì)的相互依賴程度,找出各因素對(duì)PM2.5濃度的影響程度[12-13],其計(jì)算步驟如下:
步驟1建立原始數(shù)據(jù)矩陣xi
xi=(xi(1)xi(2) …xi(k))
(1)
式中:xi(k)為第i個(gè)因素在第k時(shí)刻的原始數(shù)據(jù);i=1,2,…,7,k=1,2,…,n,n為原始數(shù)據(jù)長(zhǎng)度.
步驟2計(jì)算初始化變換矩陣x′i
x′i=(xi(1)/xi(1)xi(2)/xi(1) …
xi(k)/xi(1))=
(x′i(1)x′i(2) …x′i(k))
(2)
步驟3計(jì)算差序列Δoi(k)
Δoi(k)=xi(k)-x′i(k)
(3)
步驟4計(jì)算關(guān)聯(lián)系數(shù)ξoi(k)和灰色關(guān)聯(lián)度γoi
(4)
其中φ為分辨系數(shù),其作用在于提高關(guān)聯(lián)系數(shù)間的差異顯著性,φ∈(0,1),經(jīng)過(guò)多次反復(fù)試驗(yàn)可得,本文中φ取為0.6.
(5)
在灰色關(guān)聯(lián)分析過(guò)程中,以PM10、NO2、CO、O3、SO2的濃度和溫度、相對(duì)濕度為變量,分別得出北京市海淀區(qū)萬(wàn)柳監(jiān)測(cè)站和朝陽(yáng)區(qū)北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)數(shù)據(jù)關(guān)聯(lián)系數(shù)依次為ξo1=(0.982 6 0.872 1 0.745 8 0.722 5 0.898 2 0.927 1
0.931 8),ξo2=(0.972 9 0.884 5 0.752 7 0.710 9 0.872 6 0.942 8 0.930 1).
從上述結(jié)果可以看出,PM10濃度、溫度、相對(duì)濕度、NO2濃度和SO2濃度關(guān)聯(lián)系數(shù)較大,因此,提取出這5個(gè)變量作為影響PM2.5濃度的主要因子.
1.2 BP_Adaboost神經(jīng)網(wǎng)絡(luò)
1.2.1 核心思想 在絕大多數(shù)集成學(xué)習(xí)算法通過(guò)構(gòu)造越來(lái)越復(fù)雜的預(yù)測(cè)器來(lái)提高預(yù)測(cè)精度時(shí),Adaboost卻追求將最簡(jiǎn)單的弱預(yù)測(cè)器組合得到強(qiáng)預(yù)測(cè)器.在訓(xùn)練子預(yù)測(cè)器的方法上,Adaboost提供了重要啟示:打破已有樣本分布,重新采樣使預(yù)測(cè)器更多地關(guān)注難學(xué)習(xí)的樣本.在算法使用上,僅需要指定迭代次數(shù),不需要任何先驗(yàn)知識(shí),一切運(yùn)行過(guò)程中的參數(shù)由算法自適應(yīng)地調(diào)整,因此被評(píng)價(jià)為最接近“拿來(lái)即用”的算法[14].
Adaboost算法是組合多個(gè)弱預(yù)測(cè)器輸出生成強(qiáng)預(yù)測(cè)器[15].首先,從樣本空間中抽取m組作為訓(xùn)練數(shù)據(jù),每組訓(xùn)練數(shù)據(jù)的權(quán)重均初始化為1/m.然后,分別訓(xùn)練弱預(yù)測(cè)器,迭代運(yùn)行T次后,每組訓(xùn)練數(shù)據(jù)權(quán)重依據(jù)預(yù)測(cè)結(jié)果進(jìn)行動(dòng)態(tài)調(diào)整,若預(yù)測(cè)誤差未能達(dá)到允許值將增大其權(quán)重,進(jìn)一步加強(qiáng)學(xué)習(xí).經(jīng)過(guò)反復(fù)迭代后,弱預(yù)測(cè)器將得到一個(gè)預(yù)測(cè)函數(shù)序列f1,f2,…,fT,若預(yù)測(cè)結(jié)果越好其權(quán)重越大,反復(fù)迭代T次,通過(guò)弱預(yù)測(cè)函數(shù)加權(quán)得出強(qiáng)預(yù)測(cè)函數(shù)h(x),實(shí)現(xiàn)數(shù)據(jù)預(yù)測(cè).
1.2.2 算法流程與步驟 基于BP_Adaboost模型的PM2.5濃度預(yù)測(cè)算法流程圖如圖1所示,算法步驟如下.
步驟1數(shù)據(jù)獲取和網(wǎng)絡(luò)初始化.選取m組訓(xùn)練數(shù)據(jù),賦予訓(xùn)練數(shù)據(jù)權(quán)重分布為Dt(i)=1/m,依據(jù)樣本輸入和輸出維數(shù)確定網(wǎng)絡(luò)結(jié)構(gòu),網(wǎng)絡(luò)初始權(quán)重和閾值由改進(jìn)粒子群算法優(yōu)化獲得.
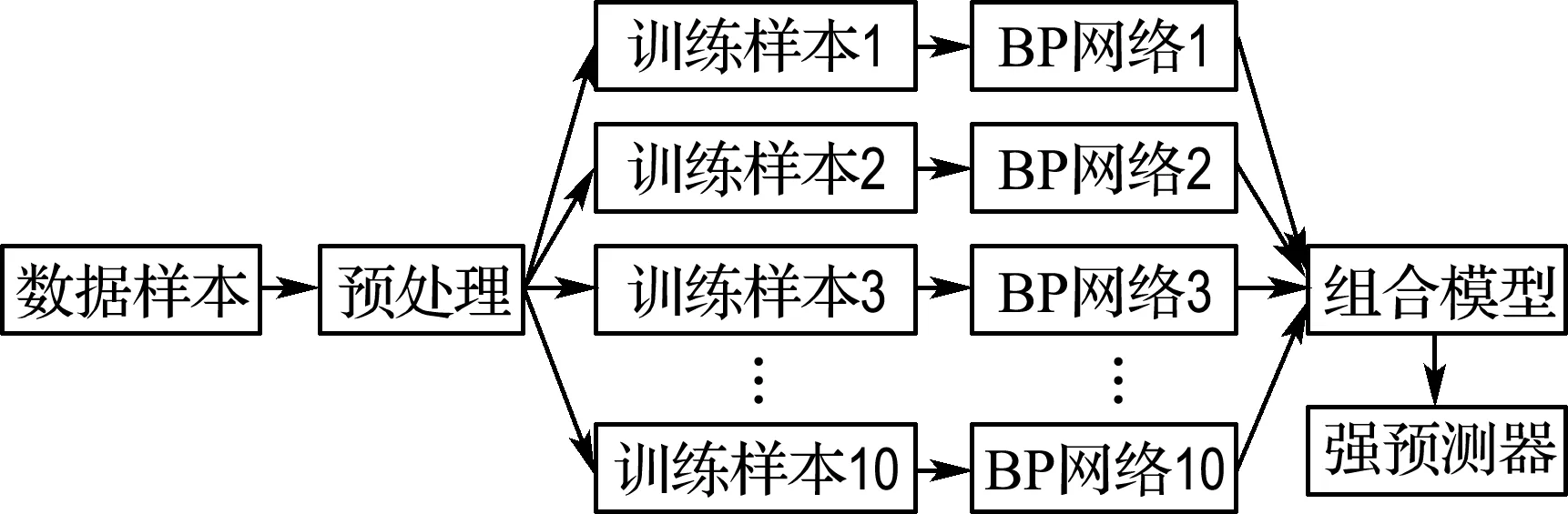
圖1 BP_Adaboost算法結(jié)構(gòu)Fig.1 The structure of BP_Adaboost algorithm
步驟2弱預(yù)測(cè)器.訓(xùn)練第t個(gè)弱預(yù)測(cè)器時(shí)得到預(yù)測(cè)序列g(shù)(t)的預(yù)測(cè)誤差和
(6)
式中:y為期望值.
步驟3計(jì)算預(yù)測(cè)序列權(quán)重.依據(jù)預(yù)測(cè)誤差et計(jì)算權(quán)重at:
(7)
步驟4測(cè)試數(shù)據(jù)權(quán)重調(diào)整.根據(jù)權(quán)重at調(diào)整下一輪訓(xùn)練樣本權(quán)重,如下:
(8)
式中:Bt是歸一化因子,y為期望值.
步驟5強(qiáng)預(yù)測(cè)函數(shù).經(jīng)過(guò)T次迭代,由T組弱預(yù)測(cè)器函數(shù)f(gt,at)生成強(qiáng)預(yù)測(cè)器函數(shù)h(x).
(9)
1.3 改進(jìn)粒子群優(yōu)化BP_Adaboost神經(jīng)網(wǎng)絡(luò)
1.3.1 改進(jìn)粒子群算法 粒子群(particle swarm optimization,PSO)算法是一種模擬生物機(jī)制的全局隨機(jī)搜索算法,其通過(guò)搜索當(dāng)前最優(yōu)值來(lái)找到全局最優(yōu)值[16].首先,對(duì)粒子進(jìn)行初始化,接著經(jīng)過(guò)數(shù)次迭代尋找最優(yōu)解,在此過(guò)程中粒子速度和位置更新公式如下:
vis=ωvis(t+1)+c1r1s(t)(pis-xis(t))+
c2r2s(t)(pgs(t)-xgs(t))
(10)
xis(t+1)=xis(t)+vis(t+1)
(11)
(12)
式中:pis是第i個(gè)粒子所經(jīng)歷過(guò)最好位置,pgs是粒子群中最好位置;學(xué)習(xí)因子c1和c2分別為調(diào)節(jié)粒子飛向自身最好位置和全局最好位置方向的步長(zhǎng),取c1=1.496 2,c2=1.496 2;r1s和r2s為服從[0,1]均勻分布偽隨機(jī)數(shù);vis是粒子速度,其值變化范圍為-10~10;ω為慣性權(quán)重,用來(lái)控制前一速度對(duì)當(dāng)前速度的影響,ω越大,越有利于全局搜索,而ω越小則越有利于精確局部搜索,尋找到最優(yōu)解,因此,采用變化慣性權(quán)重可以有效避免陷入局部最優(yōu)解.為了更好地平衡算法全局和局部搜索能力,避免算法早熟和在全局最優(yōu)解附近產(chǎn)生振蕩現(xiàn)象,本文采用權(quán)重線性遞減PSO算法.其中,ω隨算法迭代次數(shù)變化公式為式(12),t和tmax分別表示當(dāng)前和最大迭代步數(shù),設(shè)定tmax=100,ωmax=0.9,ωmin=0.4,ω在不斷迭代過(guò)程中線性遞減,該算法能夠?qū)ふ业阶顑?yōu)解且具有很好收斂性.由式(10)、(11)和(12)可知,慣性權(quán)重、學(xué)習(xí)因子和隨機(jī)數(shù)共同決定粒子飛行速度,需要調(diào)整參數(shù)較少,避免只依賴經(jīng)驗(yàn)對(duì)ω進(jìn)行調(diào)節(jié).
將粒子群算法全局搜索能力與神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)算法相結(jié)合,既可解決盲目尋優(yōu)問(wèn)題,又能避免發(fā)生局部收斂情況.在運(yùn)用PSO算法時(shí),將粒子群初始位置向量設(shè)為BP_Adaboost神經(jīng)網(wǎng)絡(luò)權(quán)重和閾值,然后用改進(jìn)粒子群算法在整個(gè)粒子群中搜索最優(yōu)位置,使均方誤差最小化,直至滿足算法停止條件.此時(shí),將最優(yōu)位置向量賦給BP_Adaboost 神經(jīng)網(wǎng)絡(luò)權(quán)重和閾值,再訓(xùn)練網(wǎng)絡(luò),直至算法停止.相比于隨機(jī)初始化神經(jīng)網(wǎng)絡(luò)權(quán)重和閾值而言,經(jīng)優(yōu)化后的神經(jīng)網(wǎng)絡(luò)不易陷入局部極小點(diǎn),從而能夠提高算法性能.
1.3.2 基于改進(jìn)粒子群BP_Adaboost神經(jīng)網(wǎng)絡(luò)在搜索空間中,粒子群按事先設(shè)定飛行速度,在不斷搜索和尋優(yōu)過(guò)程中,其根據(jù)個(gè)體和群體飛行經(jīng)驗(yàn)進(jìn)行動(dòng)態(tài)更新,其算法流程圖如圖2所示,其算法步驟如下:
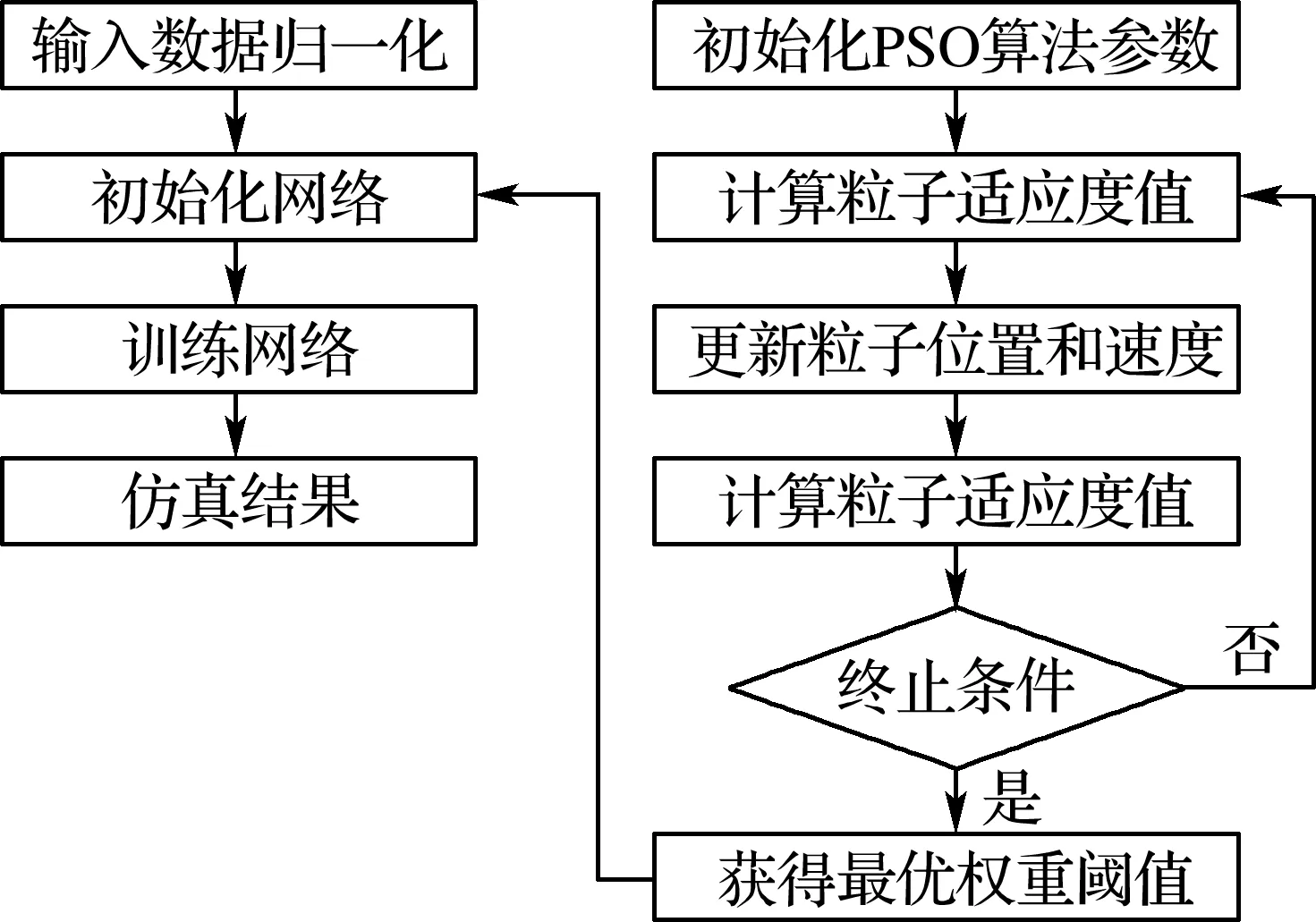
圖2 PSO算法流程圖Fig.2 The flow chart of PSO algorithm
步驟1初始化PSO算法相關(guān)參數(shù).
步驟2計(jì)算每個(gè)粒子適應(yīng)度值.
步驟3比較每個(gè)粒子當(dāng)前和歷史最好位置的適應(yīng)度值,若較好,則把它視為當(dāng)前最好位置.
步驟4比較每個(gè)粒子當(dāng)前和全局最好位置的適應(yīng)度值,若較好,則把它視為當(dāng)前全局最好位置.
步驟5根據(jù)式(10)、(11)和(12)對(duì)速度和位置進(jìn)行更新.
步驟6如果滿足終止條件,則輸出最優(yōu)個(gè)體,并賦給BP_Adaboost神經(jīng)網(wǎng)絡(luò),否則返回到步驟2.
步驟7訓(xùn)練已構(gòu)建好的BP_Adaboost神經(jīng)網(wǎng)絡(luò),進(jìn)行仿真實(shí)驗(yàn).
2 PM2.5實(shí)驗(yàn)數(shù)據(jù)分析和預(yù)測(cè)
北京作為中國(guó)首都,近些年來(lái),由于人流量較大,工業(yè)化程度不斷加大以及周邊城市的影響,市內(nèi)空氣污染嚴(yán)重.在北京市內(nèi),有35個(gè)監(jiān)測(cè)站,包括23個(gè)環(huán)境評(píng)估點(diǎn)和1個(gè)郊區(qū)控制點(diǎn),負(fù)責(zé)監(jiān)測(cè)城市空氣質(zhì)量.同時(shí),6個(gè)邊界地區(qū)監(jiān)測(cè)點(diǎn)用來(lái)反映周邊城市對(duì)北京市環(huán)境的影響.在二環(huán)、三環(huán)以及四環(huán)主干道路口設(shè)置5個(gè)交通監(jiān)測(cè)點(diǎn),用來(lái)反映交通流量信息.本文選取了北京市海淀區(qū)萬(wàn)柳監(jiān)測(cè)站和朝陽(yáng)區(qū)北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)數(shù)據(jù)作為實(shí)驗(yàn)研究對(duì)象,該數(shù)據(jù)分別來(lái)自于城市空氣項(xiàng)目[17]和空氣質(zhì)量傳感網(wǎng)絡(luò)監(jiān)測(cè)儀,后者性能指標(biāo)、外觀和數(shù)據(jù)界面如圖3所示.大量研究表明,PM2.5主要化學(xué)成分很復(fù)雜,含有碳物質(zhì)(有機(jī)碳、元素碳)、硫酸鹽、硝酸鹽、銨鹽等[18],而且各物質(zhì)在大氣中還存在復(fù)雜物理和化學(xué)變化,因此,可以得出PM2.5濃度與大氣污染物變量和氣象條件相關(guān).

(a) 性能指標(biāo)
由于影響PM2.5濃度因素很多,如氣象條件、大氣污染物濃度、交通流量、工業(yè)排放廢氣和廢物等,考慮到監(jiān)測(cè)站數(shù)據(jù)樣本的重要性和有效性,選取北京市海淀區(qū)萬(wàn)柳監(jiān)測(cè)站(2014-11-01~2014-11-25)和朝陽(yáng)區(qū)北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)(2017-07-07~2017-08-06)每小時(shí)監(jiān)測(cè)數(shù)據(jù)進(jìn)行實(shí)驗(yàn),如圖4和5所示.此外,為了研究?jī)蓚€(gè)監(jiān)測(cè)站在1 d內(nèi)6種大氣污染物濃度變化所呈現(xiàn)規(guī)律,以萬(wàn)柳監(jiān)測(cè)站(2014-11-08)和北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)(2017-07-20)數(shù)據(jù)為例進(jìn)行分析,如圖6和7所示.
從圖4和5可以看出,PM2.5濃度與PM10濃度呈現(xiàn)出一致變化,具有很強(qiáng)相關(guān)性,而與溫度和相對(duì)濕度有著負(fù)相關(guān)的變化趨勢(shì).此外,在夏季期間,多種污染物濃度較低,尤其是NO2和SO2濃度較低,空氣質(zhì)量較好,而在冬季多種污染物濃度相對(duì)較高.在不同季節(jié),PM2.5濃度差異性顯著,一般地,冬季PM2.5濃度相對(duì)較高,主要來(lái)源于燃煤量急劇增加,導(dǎo)致大量顆粒性物質(zhì)被排放到大氣中,而且在冬季溫度和相對(duì)濕度較低,大氣結(jié)構(gòu)穩(wěn)定,導(dǎo)致污染物累積易形成污染事件.
從圖6和7可以看出,1 d當(dāng)中各污染物濃度呈現(xiàn)兩頭高中間低的變化趨勢(shì),即凌晨和夜間污染物濃度較高,其他時(shí)間段相對(duì)較低,這與溫度和相對(duì)濕度有著直接關(guān)系.在凌晨和夜間,溫度和相對(duì)濕度較低,不利于各種污染物擴(kuò)散,導(dǎo)致污染物不斷累積.但是,隨著溫度升高和相對(duì)濕度變大,污染物消散加速,污染物濃度會(huì)降低.
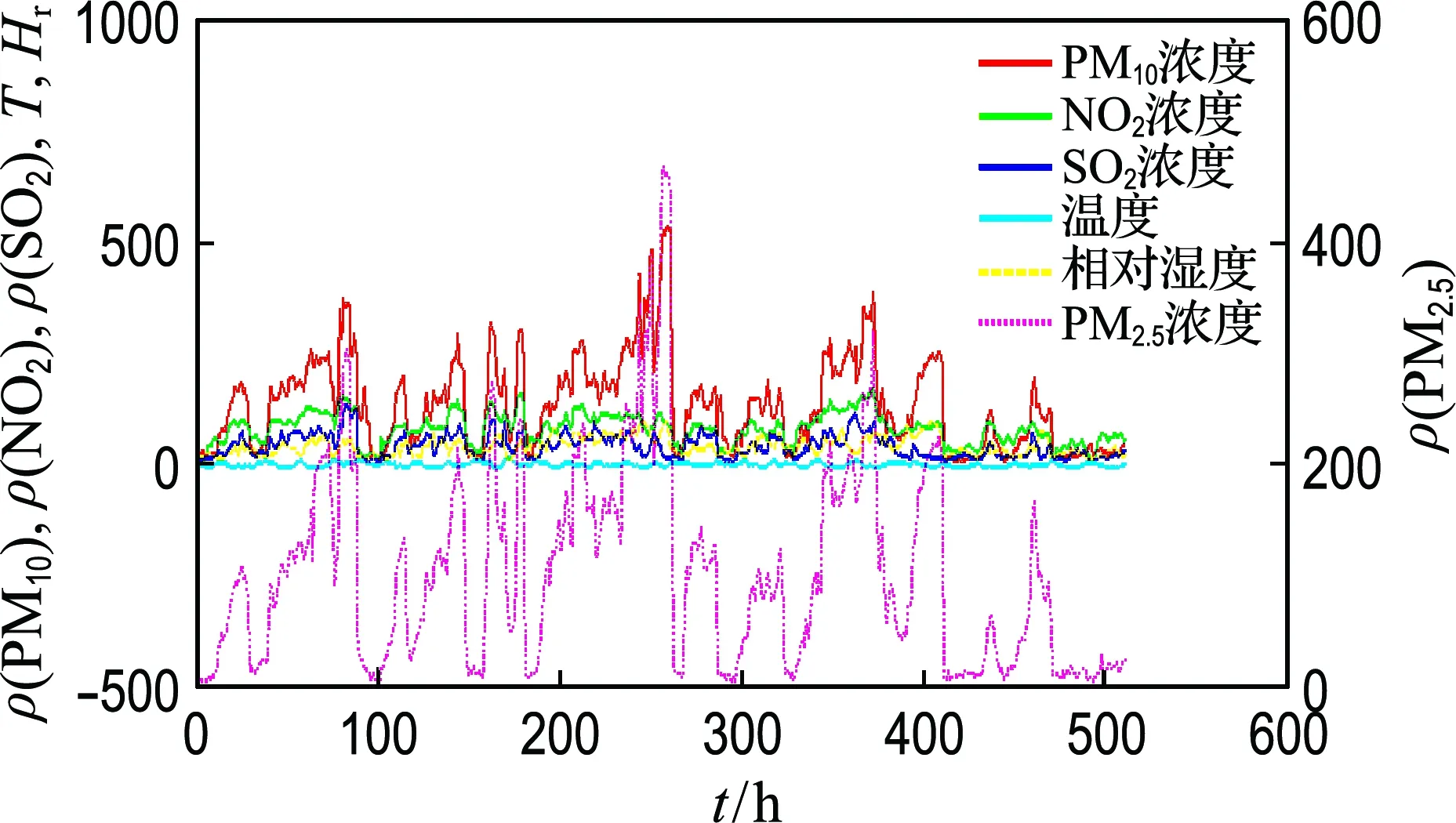
圖4 萬(wàn)柳監(jiān)測(cè)站2014-11-01~2014-11-25數(shù)據(jù)Fig.4 The data from November 1 to November 25, 2014 at Wanliu station
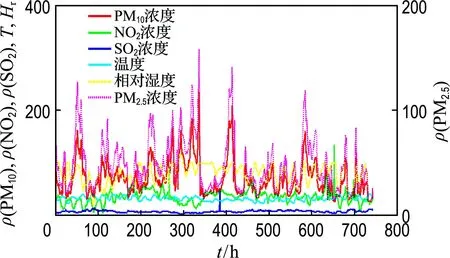
圖5 北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)2017-07-07~ 2017-08-06數(shù)據(jù)Fig.5 The data from July 7 to August 6, 2017 at Beijing University of Technology point
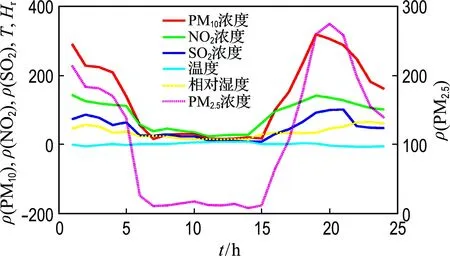
圖6 萬(wàn)柳監(jiān)測(cè)站2014-11-08數(shù)據(jù)Fig.6 The data on November 8, 2014 at Wanliu station
此外,上述這些數(shù)據(jù)是每間隔1 h監(jiān)測(cè)的,為了消除各數(shù)據(jù)之間量綱差異性,對(duì)于該神經(jīng)網(wǎng)絡(luò)的訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù),皆采用最大最小法進(jìn)行歸一化:
(13)
式中:xmin為數(shù)據(jù)序列最小值,xmax為數(shù)據(jù)序列最大值,xnorm∈[0,1].
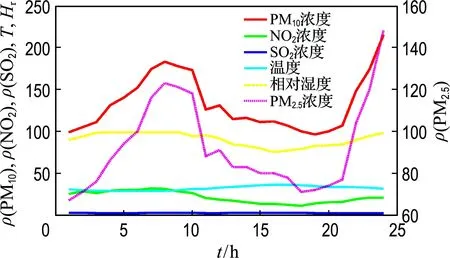
圖7 北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)2017-07-20數(shù)據(jù)Fig.7 The data on July 20, 2017 at Beijing University of Technology point
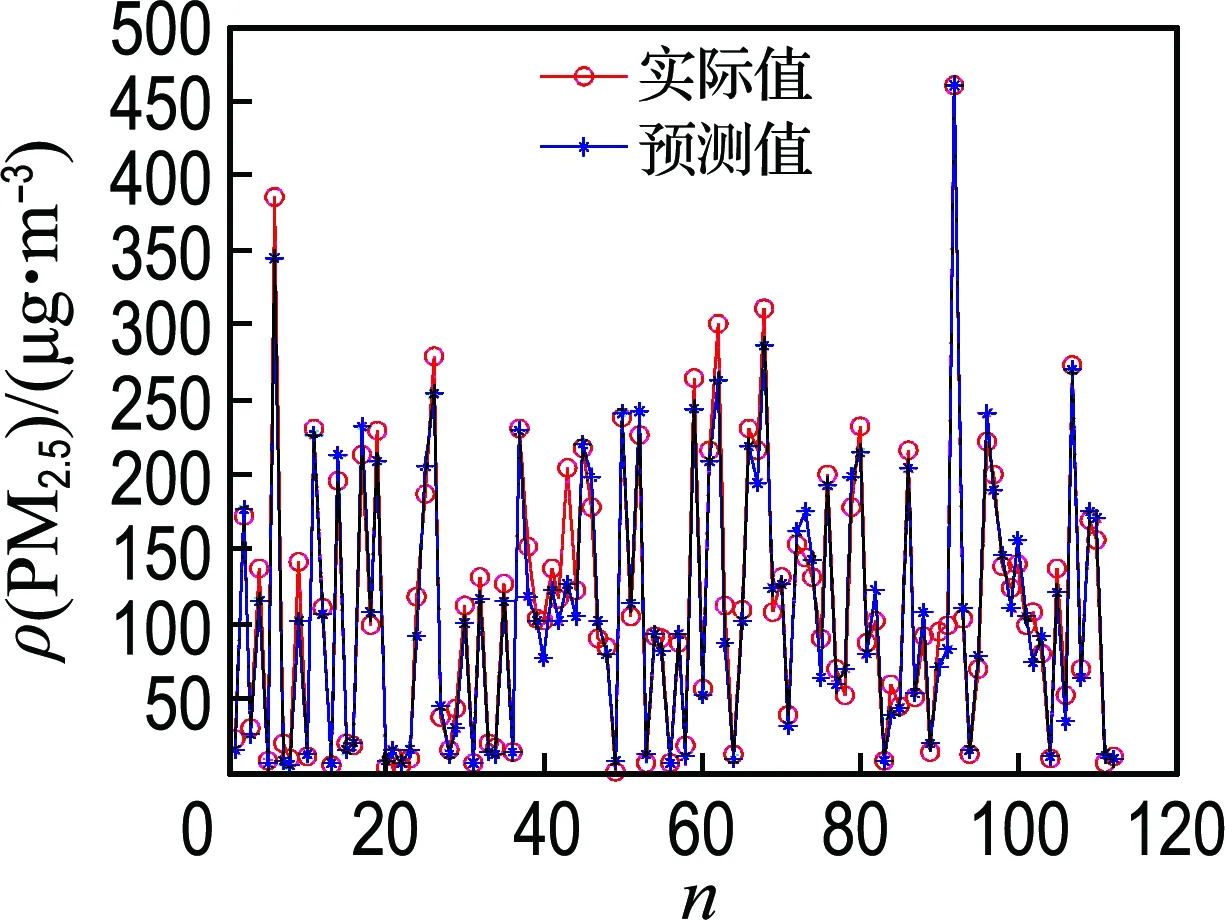
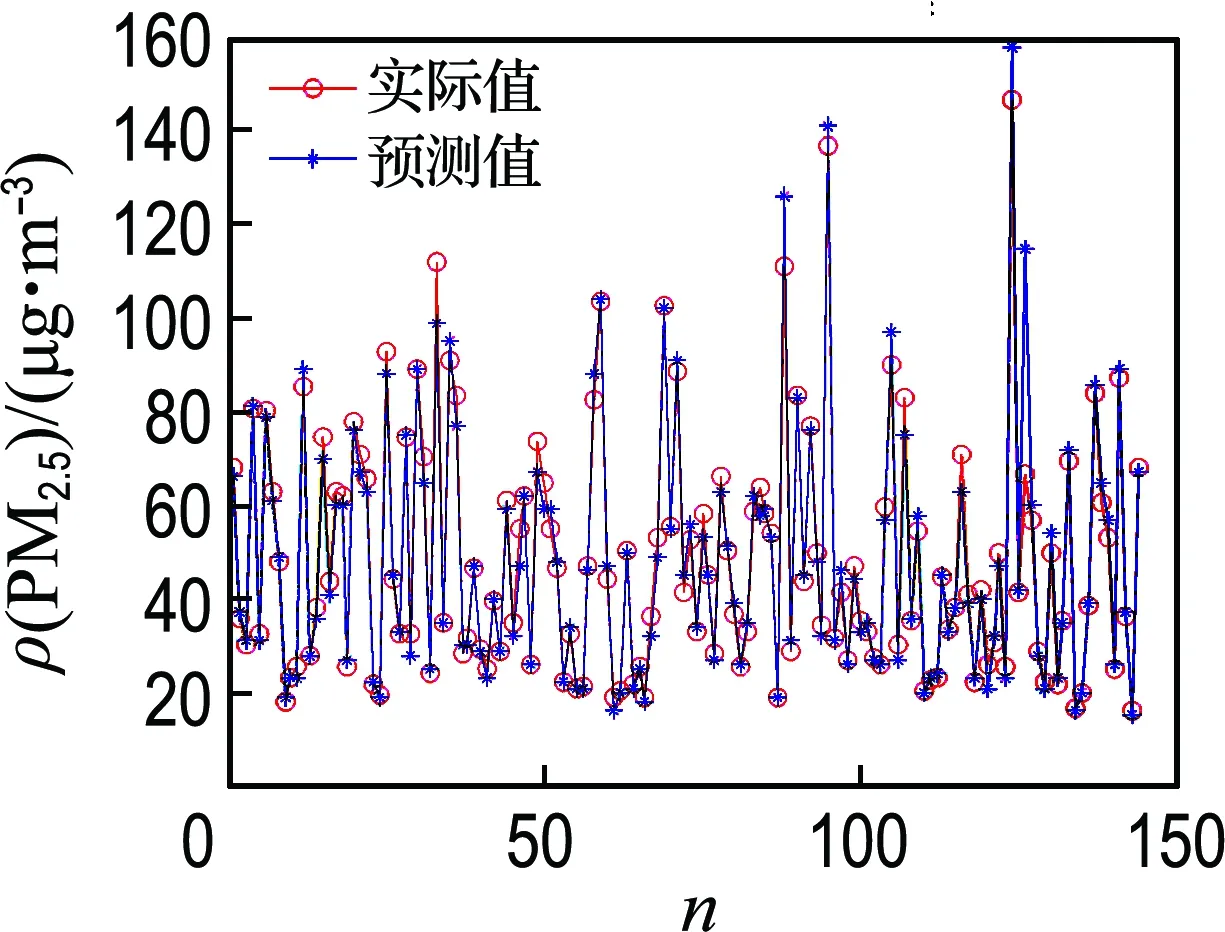
在本次實(shí)驗(yàn)中,由灰色關(guān)聯(lián)分析結(jié)果知,下一個(gè)小時(shí)PM2.5濃度與當(dāng)前時(shí)刻PM10濃度、溫度、相對(duì)濕度、NO2濃度和SO2濃度關(guān)聯(lián)系數(shù)較大,故選取當(dāng)前時(shí)刻PM10濃度、NO2濃度、SO2濃度、溫度和相對(duì)濕度作為該神經(jīng)網(wǎng)絡(luò)輸入變量,大氣中下一個(gè)小時(shí)PM2.5濃度作為輸出變量.在實(shí)驗(yàn)過(guò)程中,選取萬(wàn)柳監(jiān)測(cè)站(2014-11-01~2014-11-25)總共512個(gè)冬季數(shù)據(jù)樣本和北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)(2017-07-07~2017-08-06)總共744個(gè)夏季數(shù)據(jù)樣本,再分別從中隨機(jī)選取400個(gè)和600個(gè)數(shù)據(jù)樣本訓(xùn)練神經(jīng)網(wǎng)絡(luò),其網(wǎng)絡(luò)訓(xùn)練誤差曲線如圖8(c)、9(c)所示,確定其權(quán)重和閾值,使其收斂,并能夠滿足在不同季節(jié)數(shù)據(jù)樣本下預(yù)測(cè)大氣中PM2.5濃度的要求.經(jīng)過(guò)多次重復(fù)實(shí)驗(yàn),選取訓(xùn)練誤差最小,最終確定BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)為5-6-1,BP_Adaboost神經(jīng)網(wǎng)絡(luò)由10個(gè)BP神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練生成.待神經(jīng)網(wǎng)絡(luò)訓(xùn)練完成后,為了驗(yàn)證其預(yù)測(cè)性能,再分別用剩余112個(gè)和144個(gè)數(shù)據(jù)樣本來(lái)測(cè)試網(wǎng)絡(luò),從而實(shí)現(xiàn)提前1 h預(yù)測(cè)大氣中PM2.5濃度的功能.
(a) 模型預(yù)測(cè)結(jié)果
(a) 模型預(yù)測(cè)結(jié)果
3 結(jié)果和討論
3.1 性能指標(biāo)
在本文中,選取3種不同算法進(jìn)行對(duì)比,為了衡量其預(yù)測(cè)性能,定義3種統(tǒng)計(jì)指標(biāo)用來(lái)評(píng)估,依次為均方根誤差(erms)、平均絕對(duì)百分比誤差(emap)、相關(guān)系數(shù)(R2),其計(jì)算公式如下:
(14)
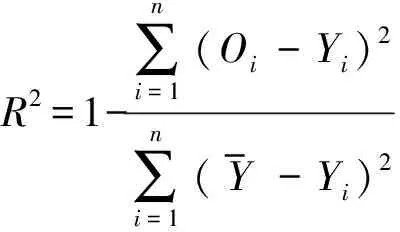
(15)
(16)
式中:Oi為PM2.5濃度在第i時(shí)刻實(shí)際值,Yi為同一時(shí)刻模型預(yù)測(cè)值,
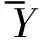
Y-
為模型預(yù)測(cè)輸出平均值.erms反映模型預(yù)測(cè)輸出值穩(wěn)定性,emap反映模型預(yù)測(cè)輸出值偏離PM2.5濃度實(shí)際值程度,兩者值皆越小,性能越好;R2反映PM2.5濃度實(shí)際值與模型預(yù)測(cè)輸出值相關(guān)聯(lián)程度,其值越接近1,性能越好.
3.2 預(yù)測(cè)結(jié)果
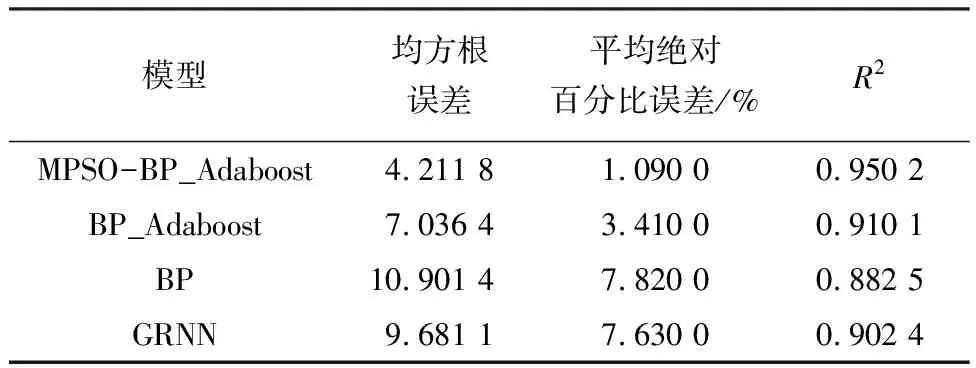
針對(duì)萬(wàn)柳監(jiān)測(cè)站和北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)每小時(shí)監(jiān)測(cè)數(shù)據(jù),運(yùn)用改進(jìn)粒子群優(yōu)化BP_Adaboost神經(jīng)網(wǎng)絡(luò)(MPSO-BP_Adaboost)建模進(jìn)行仿真實(shí)驗(yàn),其預(yù)測(cè)結(jié)果如圖8和9所示.此外,將本文中所采用預(yù)測(cè)模型和BP_Adaboost、BP、廣義回歸神經(jīng)網(wǎng)絡(luò)(GRNN)3種預(yù)測(cè)模型進(jìn)行對(duì)比,其性能指標(biāo)見(jiàn)表1和2.
從圖8和9可以看出,針對(duì)萬(wàn)柳監(jiān)測(cè)站和北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn),采用改進(jìn)粒子群優(yōu)化BP_Adaboost神經(jīng)網(wǎng)絡(luò)建模來(lái)對(duì)大氣中未來(lái)1 h PM2.5濃度進(jìn)行預(yù)測(cè),預(yù)測(cè)輸出值和期望輸出值基本相吻合,能夠達(dá)到高精度預(yù)測(cè)的效果.在某些時(shí)間點(diǎn)預(yù)測(cè)時(shí),可能由于外部環(huán)境突變、一些人為因素和神經(jīng)網(wǎng)絡(luò)自身性能等原因,存在預(yù)測(cè)誤差,但是,網(wǎng)絡(luò)輸出相對(duì)誤差只是在一個(gè)較小范圍內(nèi)波動(dòng),在大氣預(yù)測(cè)應(yīng)用方面可以接受,因此,BP_Adaboost 神經(jīng)網(wǎng)絡(luò)能夠很好實(shí)現(xiàn)預(yù)測(cè)功能.
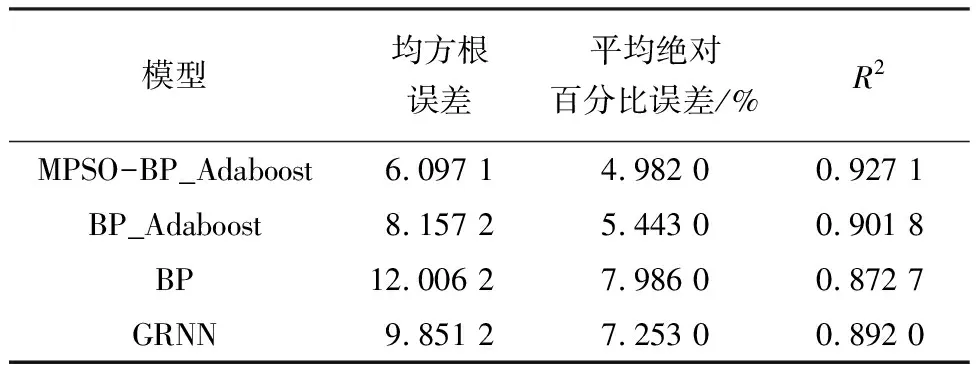
表1 萬(wàn)柳監(jiān)測(cè)站4種預(yù)測(cè)模型性能指標(biāo)對(duì)比
表2 北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)4種預(yù)測(cè)模型性能指標(biāo)對(duì)比
Tab.2 The performance index contrast of four kinds of prediction models at Beijing University of Technology point
模型均方根誤差平均絕對(duì)百分比誤差/%R2MPSO-BP_Adaboost4.211 81.090 00.950 2BP_Adaboost7.036 43.410 00.910 1BP10.901 47.820 00.882 5GRNN9.681 17.630 00.902 4
從表1和2來(lái)看,針對(duì)兩個(gè)監(jiān)測(cè)站點(diǎn)數(shù)據(jù)樣本,實(shí)驗(yàn)結(jié)果略微不同,主要由于萬(wàn)柳監(jiān)測(cè)站數(shù)據(jù)樣本數(shù)值變化范圍較大,加大了預(yù)測(cè)難度.為了保證模型有較高預(yù)測(cè)精度,在數(shù)據(jù)樣本具有真實(shí)性和可靠性前提下,數(shù)據(jù)樣本量應(yīng)該盡可能大,包含不同條件下數(shù)據(jù)樣本信息,使模型訓(xùn)練充分,提高其泛化能力.此外,基于本文實(shí)驗(yàn)部分所述建立的MPSO-BP_Adaboost、BP_Adaboost、BP和GRNN 4種預(yù)測(cè)模型,都具有有效性和可靠性.但是,MPSO-BP_Adaboost預(yù)測(cè)模型相比于其他3種預(yù)測(cè)模型而言,均方根誤差和平均絕對(duì)百分比誤差均是最小,R2為最大,這表明改進(jìn)粒子群優(yōu)化BP_Adaboost在用于預(yù)測(cè)大氣中PM2.5濃度時(shí),模型性能要優(yōu)于另外3種預(yù)測(cè)模型,從而能夠更好地實(shí)現(xiàn)預(yù)測(cè)大氣中PM2.5濃度的目標(biāo),為人們出行提供參考.
4 結(jié) 語(yǔ)
本文運(yùn)用改進(jìn)粒子群優(yōu)化BP_Adaboost神經(jīng)網(wǎng)絡(luò)來(lái)預(yù)測(cè)北京市海淀區(qū)萬(wàn)柳監(jiān)測(cè)站和朝陽(yáng)區(qū)北京工業(yè)大學(xué)監(jiān)測(cè)點(diǎn)下一個(gè)小時(shí)PM2.5濃度.根據(jù)站點(diǎn)監(jiān)測(cè)數(shù)據(jù)和神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)輸出結(jié)果,得出如下結(jié)論:(1)影響大氣中PM2.5濃度有多種因素,相互之間可能存在強(qiáng)耦合,利用灰色關(guān)聯(lián)分析找出對(duì)PM2.5濃度影響較大的因子,并用于BP_Adaboost神經(jīng)網(wǎng)絡(luò)建模,可以有效縮短建模時(shí)間和更精確建模.(2)BP_Adaboost神經(jīng)網(wǎng)絡(luò)是強(qiáng)分類預(yù)測(cè)器,相比于其他神經(jīng)網(wǎng)絡(luò),在大氣預(yù)測(cè)方面,更利于加強(qiáng)神經(jīng)網(wǎng)絡(luò)泛化能力和提高預(yù)測(cè)模型精度.(3)采用改進(jìn)粒子群優(yōu)化BP_Adaboost神經(jīng)網(wǎng)絡(luò),可以有效避免神經(jīng)網(wǎng)絡(luò)在訓(xùn)練時(shí)陷入局部最優(yōu)解,進(jìn)一步改善預(yù)測(cè)模型性能.在本文中,未能從理論角度去證明改進(jìn)粒子群算法可以避免陷入局部最優(yōu)解,這將在以后研究中予以考慮.其次,只做了短期預(yù)測(cè),在未來(lái)工作中,將嘗試去做長(zhǎng)期預(yù)測(cè),使之更具有實(shí)用行和可靠性.最后,由于BP神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)只能憑借試湊法來(lái)確定,將考慮用PSO算法去優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)[19-20],解決這一難題并應(yīng)用于大氣中其他污染物濃度預(yù)測(cè).
[1] KUMAR U, JAIN V K. ARIMA forecasting of ambient air pollutants (O3, NO, NO2and CO) [J].StochasticEnvironmentalResearchandRiskAssessment, 2010,24(5):751-760.
[2] ELBAYOUMI M, RAMLI N A, YUSOFA N F F M,etal. Multivariate methods for indoor PM10and PM2.5modelling in naturally ventilated schools buildings [J].AtmosphericEnvironment, 2014,94(8):11-21.
[3] ISHAK A B, MOSLAH Z. Analysis and prediction of PM10concentration levels in Tunisia using statistical learning approaches [J].EnvironmentalandEcologicalStatistics, 2016,23(3):1-22.
[4] NIETO P, ANTN J, VILN J,etal. Air quality modeling in the Oviedo urban area (NW Spain) by using multivariate adaptive regression splines [J].EnvironmentalScienceandPollutionResearch, 2015,22(9):6642-6659.
[5] MOUSTRIS K P, ZIOMAS I C, PALIATSOS A G. 3-Day-ahead forecasting of regional pollution index for the pollutants NO2, CO, SO2, and O3using artificial neural networks in Athens, Greece [J].WaterAirandSoilPollution, 2010,209(1/4):29-43.
[6] 孫寶磊,孫 暠,張朝能,等. 基于BP神經(jīng)網(wǎng)絡(luò)的大氣污染物濃度預(yù)測(cè)[J]. 環(huán)境科學(xué)學(xué)報(bào), 2016,37(5):1864-1871.
SUN Baolei, SUN Hao, ZHANG Chaoneng,etal. Forecast of air pollutant concentration by BP neural network [J].ActaScientiaeCircumstantiae, 2016,37(5):1864-1871. (in Chinese)
[7] KUKKONEN J, PARTANEN L, KARPPINEN A,etal. Extensive evaluation of neural network models for the prediction of NO2and PM10concentrations, compared with a deterministic modelling system and measurements in central Helsinki [J].AtmosphereEnvironment, 2003,37(4):4539-4550.
[8] 石靈芝,鄧啟紅,路 嬋,等. 基于BP人工神經(jīng)網(wǎng)絡(luò)大氣顆粒物 PM10濃度預(yù)測(cè)[J]. 中南大學(xué)學(xué)報(bào)(自然科學(xué)版), 2012,43(5):1969-1974.
SHI Lingzhi, DENG Qihong, LU Chan,etal. Prediction of PM10mass concentrations based on BP artificial neural network [J].JournalofCentralSouthUniversity(ScienceandTechnology), 2012,43(5):1969-1974. (in Chinese)
[9] ELANGASINGHE M A, SINGHAL N, DIRKS K N,etal. Complex time series analysis of PM10and PM2.5for a coastal site using artificial neural network modelling andk-means clustering [J].AtmosphericEnvironment, 2014,94(1):106-116.
[10] 李 航. 統(tǒng)計(jì)學(xué)習(xí)方法[M]. 北京:清華大學(xué)出版社, 2012.
LI Hang.StatisticalLearningMethods[M]. Beijing: Tsinghua University Press, 2012. (in Chinese)
[11] GAO Yun, WEI Xin, ZHUANG Wenqin,etal. QoE prediction for IPTV based on BP_adaboost neural networks [C] //201713thInternationalWirelessCommunicationsandMobileComputingConference(IWCMC). Valencia: IEEE, 2017:32-37.
[12] TSAI M S, HSU F Y. Application of grey correlation analysis in evolutionary programming for distribution system feeder reconfiguration [J].IEEETransactionsonPowerSystems, 2010,25(2):1126-1133.
[13] 羅慶成,徐國(guó)新. 灰色關(guān)聯(lián)分析與應(yīng)用[M]. 南京:江蘇科學(xué)技術(shù)出版社, 1989:110-125.
LUO Qingcheng, XU Guoxin.TheAnalysisApplicationofGreyCorrelation[M]. Nanjing: Jiangsu Science and Technology Publishing House, 1989:110-125. (in Chinese)
[14] HASTIE T, TIBSHIRANI R, FRIEDMAN J.TheElementsofStatisticalLearning[M]. New York: Springer, 2001:337-384.
[15] 王小川,史 峰. MATLAB神經(jīng)網(wǎng)絡(luò)43個(gè)案例分析[M]. 北京:北京航空航天大學(xué)出版社, 2013:115-126.
WANG Xiaochuan, SHI Feng.TheAnalysisof43NeuralNetworkCasesUsingMATLAB[M]. Beijing: Beijing University of Aeronautics and Astronautics Press, 2013:115-126. (in Chinese)
[16] 錢 鋒. 粒子群算法及其工業(yè)應(yīng)用[M]. 北京:科學(xué)出版社, 2013:120-156.
QIAN Feng.ParticlesSwarmOptimizationandItsIndustrialApplication[M]. Beijing: Science Press, 2013:120-156. (in Chinese)
[17] ZHENG Yu, CAPRA L, WOLFSON O,etal. Urban computing:concepts, methodologies, and applications [J].ACMTransactionsonIntelligentSystemsandTechnology, 2014,5(3):112-118.
[18] 曹軍驥. PM2.5與環(huán)境[M]. 北京:科學(xué)出版社, 2014.
CAO Junji.PM2.5andtheEnvironmentinChina[M]. Beijing: Science Press, 2014. (in Chinese)
[19] WU Jiansheng, JIN Long. Study on the meteorological factor prediction model using the learning algorithm of neural ensemble based on PSO algorithm [J].JournalofTropicalMeteorology, 2009,15(1):83-88.
[20] SHEIKHAN M, SHA′BANI A A. PSO-optimized modular neural network trained by OWO-HWO algorithm for fault location in analog circuits [J].NeuralComputingandApplications, 2013,23(2):519-530.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
