基于卷積神經網絡的自然場景中數字識別
2017-11-20 11:07:16周成偉
計算機技術與發(fā)展 2017年11期
周成偉
(南京郵電大學 計算機學院,江蘇 南京 210003)
基于卷積神經網絡的自然場景中數字識別
周成偉
(南京郵電大學 計算機學院,江蘇 南京 210003)
從復雜的圖片背景中提取文本信息一直是計算機視覺中的熱點與難點問題。近年來,隨著卷積神經網絡在圖像識別研究的突破性進展,傳統(tǒng)的人工提取圖像特征方式逐漸為深層網絡學習特征方式所取代,而應用卷積神經網絡(CNN)的場景文本識別方法也越來越受到廣泛的關注。為此,提出了自然場景下基于卷積網絡結構的數字識別改進方法。該方法能夠對目標區(qū)域進行檢測,并進行端到端的數字字符識別訓練,數字識別部分提取的特征還可用來初始化目標檢測的網絡部分,以減少特征的重復提取并提高訓練速度。需要處理的圖像輸入無需固定格式,只需輸入原始圖像即可,可減少圖像預處理過程及其對原始圖像數據的不良影響,提高圖像識別的精度。基于谷歌街景數據集(SVHN)與MSRA-TD500、ICDAR 2013數據集的數字字符識別驗證結果表明,該方法的識別效果優(yōu)于其他已有的識別方法。
卷積神經網絡;自然場景;數字識別;端到端
1 概 述
光學字符識別(OCR)[1-2],也就是從掃描文檔中提取文本信息,可以看作是一個已經解決的計算機視覺問題,而不同于掃描文檔的識別,自然場景中的字符識別需要面對復雜的背景和形形色色的噪聲。這就導致類似于人工提取特征的方法[3-4]很難取得好的效果。所以復雜場景下的識別任務一直是計算機視覺領域的一大難題,直到以CNN[5]為代表的深度學習的興起,才取得了突破性進展。
CNN網絡結構中感受野(Receptive field)的概念來源于1962年對貓的視覺皮層細胞的研究[6],1982年Fukushima基于感受野的感念提出了神經認知機(Neocognitron),可以看作是卷積神經網絡的第一個實現網絡。早在1989年,Y. Lecun等就提出了一個五層的卷積神經網絡LeNet[7],完美解決了手寫數字的識別,算是卷積神經網絡由理論走向實際應用的一個開端。但是由于當時訓練樣本的匱乏和計算能力的不足,導致CNN并沒有流行起來,反而是SVM等手工設計特征的方法在小樣本集上取得了較好的效果,從而成為主流。隨著大數據時代的來臨,CNN網絡本身的不斷改進,以及以GPU為主的并行計算的盛行[8-9],到了2012年,Alex Krizhevsky等利用一個八層的深層卷積網絡AlexNet[10]在當年的ImageNet圖像分類競賽中取得了冠軍,并遠超第二名十個百分點,讓CNN再次回到了人們的視線中。
如今,由于在圖像處理中的優(yōu)勢,CNN幾乎成為現在圖像處理領域的主要算法,因此越來越多的研究人員嘗試把CNN用于自然場景下的字符識別中[11-12],取得了很好的效果。以文本識別的子集─數字的識別為研究對象,針對現有的識別方法,提出兩點改進。第一,端到端的訓練過程,自然場景下的文本識別不同于OCR的一個主要方面是增加了一個文本區(qū)域檢測與定位的過程,這樣一個識別任務就分成了區(qū)域檢測和文本識別兩個子任務,類似于物體檢測的過程[13-15],因此,使用一個深層的卷積網絡結構負責提取圖像的特征,區(qū)域檢測和文本識別兩個子任務共享底層網絡結構提取的特征,減少了網絡訓練時間。第二,利用一層特殊的池化層來消除網絡輸入的大小限制,該池化層類似于SPP[16]中的按比例池化方式,由于卷積網絡的最后幾層往往使用全連接層表示各種特征的組合,而全連接層必須是固定大小的,這就導致了網絡的輸入層只能是固定的大小,而固定大小的輸入需要對圖像進行縮放和裁剪,這就破壞了圖像的原始比例,同時降低了識別精度。通過在最后一層卷積層后加上一個按比例的池化層,讓網絡可以接受任意大小的輸入,同時全連接層將獲得經過池化層處理后的固定大小的輸入。
自然場景下的數字識別屬于自然場景下文本識別的范疇,對自然場景下文本識別問題的研究始于20世紀90年代[17],但是直到現在仍然是一個沒有解決的難題。
一般來說,自然環(huán)境下的文本識別任務包含兩部分:文本區(qū)域檢測和字符識別。文本區(qū)域檢測中使用的方法主要包括兩類:滑動窗口[18-19]和連通區(qū)域[20]。滑動窗口通過使用不同大小的子窗口在圖像上不斷位移滑動來獲得可能包含有文本的候選區(qū)域,然后計算出該區(qū)域的特征,用訓練好的分類器對特征進行篩選,判定該區(qū)域是否包含文本[21-22]。連通區(qū)域是一定范圍內具有相似像素值的相鄰像素點組成的像素集合,基于連通區(qū)域的方法從圖像的像素級別來識別文本區(qū)域和非文本區(qū)域,其中典型的算法包括ERs/MSERs[23-24]和SWT[24]。不管是滑動窗口檢測還是連通區(qū)域分析,決定它們性能的關鍵是有一個好的分類器,而分類器中的特征大多用人工的方式設計,例如SIFT、SURF和HOG等。人工設計的特征具有很好的解釋性,但是在面對復雜的背景、多變的字體和各種形變時,就顯得比較呆板,沒法提取出更一般的特征。而且人工方式需要花費大量時間設計特征。
由于人工提取特征存在種種不足,Y. Netzer等[25]提出使用K-mean等無監(jiān)督學習模型自動提取圖像中的特征,用于數字識別,其效果大大優(yōu)于手工提取的方式。隨后CNN在物體檢測上取得了突破性進展,越來越多的研究人員嘗試將CNN用于文本信息的識別問題[26-27]。例如,文獻[28]使用了一個五層的CNN,并且使用多層卷積層的輸出作為全連接的輸入,在門牌號識別的問題上取得了當時最好的精度。李釗等[29]使用CNN提取出的特征進行圖像檢索,并與基于人工提取特征的方法進行對比。Q.Guo等[30]提出將CNN和在語音識別中取得了非常好效果的隱馬爾可夫模型(HMM)結合起來,將CNN輸出的結果作為HMM的轉移概率,將兩種模型巧妙地結合起來。所采用的模型借鑒了前人的研究成果,使用一個深層的CNN模型,但又針對存在問題進行了適當改進。
針對目前自然場景下數字識別系統(tǒng)仍然存在的不足,主要進行兩點改進:定位與識別均利用卷積神經網絡完成,并共享特征,減少訓練時間;可以輸入任意尺寸的圖片作為輸入,減少裁剪、縮放帶來的信息丟失。
2 目標網絡結構
在所采用的系統(tǒng)中,CNN網絡以一個任意大小的彩色圖片(RBG三色維度)作為輸入,輸出所有字符區(qū)域的位置和標識,其中網絡的底層特征的提取采用一個四層的卷積神經網絡。第一層的卷積層使用大小為7×7的卷積濾波器,卷積步幅為2,該層共有48個卷積濾波器,輸出48個任意大小的特征圖。獲得卷積層的輸出后,使用BN(Batch Normalization)[31]進行歸一化處理,然后使用ReLU作為非線性激活函數,最后連接一個窗口大小為3×3的Max pooling層,采樣步幅為2。第二層的卷積層使用大小為5×5的卷積濾波器,卷積步幅為2,該層使用96個卷積濾波器,輸出96個任意大小的特征圖,隨后采用和第一層一樣的處理策略。第三層的卷積層使用大小為3×3的卷積濾波器,卷積步幅為1,并設置pad為1,使輸入圖的維度等于輸出圖,該層共使用96個卷積濾波器,輸出96個任意大小的特征圖。第四層的卷積層使用大小為3×3的卷積濾波器,卷積步幅為1,設置pad為1,使用48個卷積濾波器,使用ReLU作為激活函數。
通過上述的四層卷積操作,獲得了一組原始特征,這個特征可以看作是一個48通道的圖像,然后使用滑動窗口策略在這個特征圖上提取可能的文本區(qū)域,對每一個提取出的可能文本區(qū)域使用一個池化層,將輸出的大小固定到7×7的范圍,隨后將結果輸入一個三層的全連接網絡并使用Sigmoid作為二分類函數判斷區(qū)域是否包含數字。其中第一層全連接網絡1 000個節(jié)點,第二層11個節(jié)點,第三層1個節(jié)點;第二層全連接網絡使用Softmax函數作為數字分類器,判別過程和識別過程共享前兩層提取的特征組合。
整體網絡結構如圖1所示。
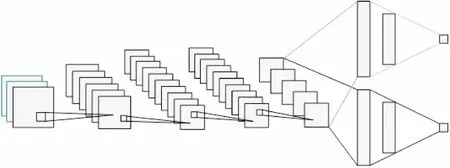
圖1 一個五層的卷積網絡連接兩個共享 卷積特征圖的全連接網絡
3 歸一化處理
3.1BatchNormalization
選用BN算法訓練網絡,用于解決隨機梯度下降法(SGD)訓練網絡時需要人工調參的缺點,例如學習率、初始權重、權重衰減系數、Dropout比率等。BN可以當作卷積操作和激活函數之間的單獨一層,將卷積輸出的d維數據x=(x1x2…xd)歸一化至均值0、方差1,然后輸入激活函數。
(1)
其中,k為一個訓練批次中包含的樣本個數。
最后引入兩個可學習參數γ、β,使歸一化后的數據保持原有的特征分布。
(2)
3.2按比例的池化
為了最終獲得尺寸固定的特征并傳入全連接層進
行分類,在使用滑動窗口獲得尺度不同的子窗口后,接上一層特殊的池化層,因為所針對的是數字的識別任務,除了關鍵特征外對圖像的分辨率并不敏感,所以采用Max pooling將任意大小的子窗口按比例壓縮到一個7×7的范圍。
3.3目標函數(LossFunction)
整個CNN結構中包括一個輸入和三個輸出,分別是:判斷候選區(qū)域是否是文本的輸出O1,識別選定區(qū)域中的數字產生的輸出O2,用于定位文本區(qū)域產生的位置信息O3。其中O3包含四個參數ox、oy、ow、oh,分別代表區(qū)域左上角的橫坐標、縱坐標、區(qū)域寬、區(qū)域高。
O1和O2屬于分類問題的輸出,O3為回歸問題的輸出,最后的目標函數為三者的聯合函數:
L=LO1+LO2+LO3
(3)
4 實 驗
4.1數據集
使用Street View House Numbers(SVHN)數據集進行預訓練,并利用從ICDAR 2013數據集、MSRA-TD500和谷歌街景中收集的包含數字的樣本進行微調。SVHN是由Yuval Netzer等從谷歌街景中收集整理的一套數據集,其中包括30 000張訓練樣本,10 000張測試樣本,但是因為針對的問題不同,該數據集主要針對識別任務,所有樣本都是經過裁剪的,已經將大部分背景通過人工分離了出去,如圖2所示。這和實驗目的有所不同,所以采用了該數據集作預訓練處理,由于目前基于自然場景下的字符識別任務多以英文文本為主,但是像ICDAR等數據集中仍舊包含很多數字樣本,整理了ICDAR 2013數據集和MSRA-TD500數據集中所有數字符號樣本,并從谷歌街景中收集了一部分樣本,組成一個5 000張訓練樣本的數據集,如圖3所示。

圖2 SVHN數據集中的訓練樣本

圖3 ICDAR 2013和MSRA-TD500數據集中的訓練樣本
4.2訓練過程
卷積網絡的訓練主要分為兩部分:預訓練和微調。模型采用了多個任務共享底層特征的結構,分類、判斷、定位三個操作都是基于前面四個卷積層提取的特征。這四層的卷積操作也可以看作是一個消除背景,強化字符區(qū)域的過程,使用SVHN數據集預訓練前四個卷積層,讓網絡獲得對數字字符特征敏感的初始值,用于初始化網絡。微調部分就是用包含復雜背景的數據集對網絡進行端到端訓練,使網絡得到準確的三個輸出。
4.3實驗結果
系統(tǒng)在預訓練的過程中使用四層卷積網絡和兩層全連接網絡,在SVHN數據集下的結果如圖4所示。整體效果優(yōu)于基于人工特征提取的方法。然后將整個網絡進行微調后,在MSRA-TD500數據集上的數字識別子集中獲得的結果見表1,在ICDAR 2013的子集中獲得的結果見表2。在所整理的數據集上,F度量為78.34%,均優(yōu)于類似的英文文本識別的任務。
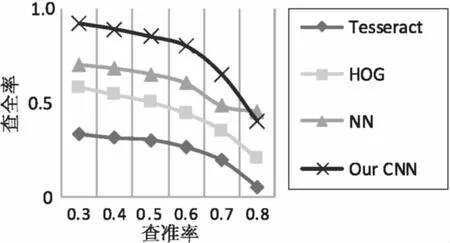
圖4 預訓練中在SVHN數據集上的P-R曲線 表1 在MSRA-TD500數據集中的實驗結果對比
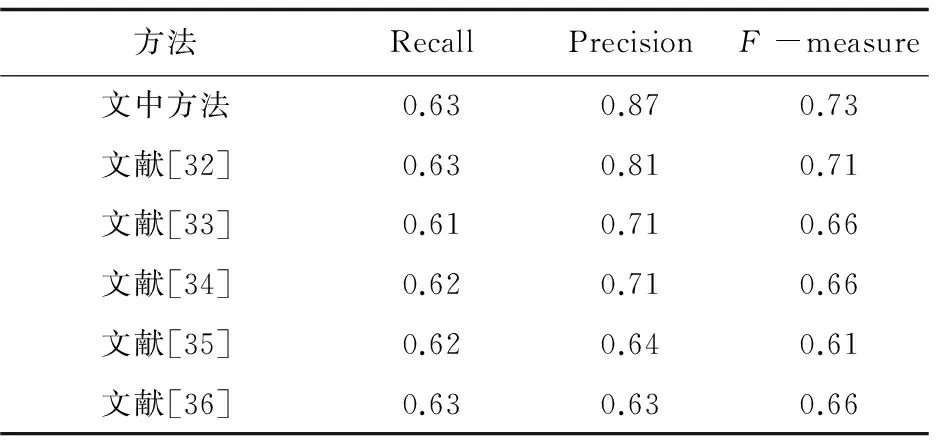
方法RecallPrecisionF-measure文中方法0.630.870.73文獻[32]0.630.810.71文獻[33]0.610.710.66文獻[34]0.620.710.66文獻[35]0.620.640.61文獻[36]0.630.630.66
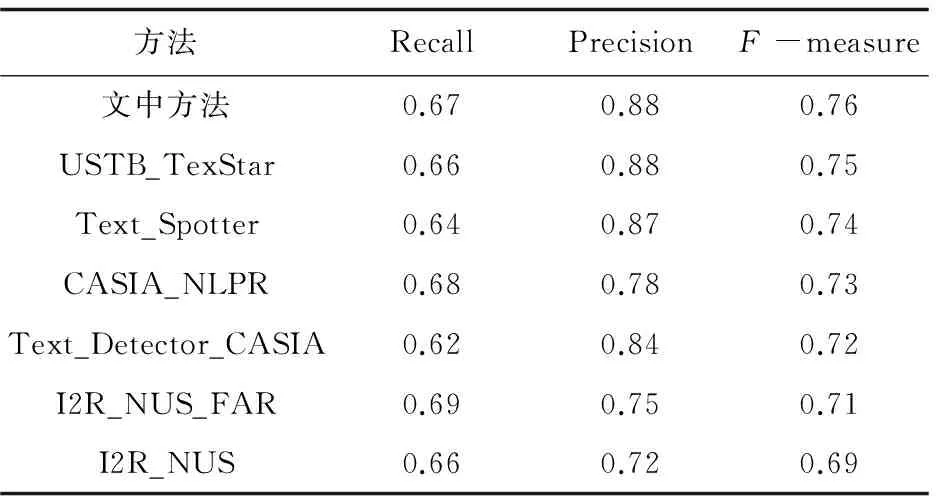
表2 在ICDAR 2013數據集上的實驗結果對比
5 結束語
設計了一個用于自然場景下數字識別的端到端卷積神經網絡,將復雜的檢測定位和識別任務融合到了一個卷積網絡中,多個任務共享底層的特征,減少了重復計算,同時避免了繁瑣的人工特征提取,并且獲得了很好的識別效果。但是整個網絡中仍然有值得繼續(xù)研究的地方,比如網絡的最終輸出有三個,其中兩個輸出是分類問題,是否可以將兩個輸出合并為一個多分類問題,共享底層特征的同時也共享高層的特征組合;所采用的模型最終的輸出結果是單個數字字符,后續(xù)工作可以在得到字符標識的基礎上用基于聚類的算法將結果以字符串的形式輸出等。
[1] Nagy G.At the frontiers of OCR[J].Proceedings of the IEEE,1992,80(7):1093-1100.
[2] Mori S,Suen C Y,Yamamoto K.Historical review of OCR research and development[J].Proceedings of the IEEE,1992,80(7):1029-1058.
[3] Campos T E D,Babu B R,Varma M.Character recognition in natural images[M]//Software reuse and reverse engineering in practice.[s.l.]:Chapman & Hall,1992:273-280.
[4] Epshtein B,Ofek E,Wexler Y.Detecting text in natural scenes with stroke width transform[C]//Computer vision and pattern recognition.[s.l.]:IEEE,2010:2963-2970.
[5] 焦李成,楊淑媛,劉 芳,等.神經網絡七十年:回顧與展望[J].計算機學報,2016,39(8):1697-1716.
[6] Mishra A,Alahari K,Jawahar C V.Top-down and bottom-up cues for scene text recognition[C]//IEEE conference on computer vision and pattern recognition.[s.l.]:IEEE,2012:2687-2694.
[7] Lecun Y,Boser B,Denker J S,et al.Backpropagation applied to handwritten zip code recognition[J].Neural Computation,1989,1(4):541-551.
[8] 余 凱,賈 磊,陳雨強,等.深度學習的昨天、今天和明天[J].計算機研究與發(fā)展,2013,50(9):1799-1804.
[9] 劉建偉,劉 媛,羅雄麟.深度學習研究進展[J].計算機應用研究,2014,31(7):1921-1930.
[10] Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C]//Proceedings of international conference on neural information processing systems.[s.l.]:[s.n.],2012:1097-1105.
[11] Wang T,Wu D J,Coates A,et al.End-to-end text recognition with convolutional neural networks[C]//21st international conference on pattern recognition.[s.l.]:IEEE,2012:3304-3308.
[12] 黃 攀.基于深度學習的自然場景文字識別[D].杭州:浙江大學,2016.
[13] Ren S,He K,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[14] 黃凱奇,任偉強,譚鐵牛.圖像物體分類與檢測算法綜述[J].計算機學報,2014,37(6):1225-1240.
[15] 鄧宗平,趙啟軍,陳 虎.基于深度學習的人臉姿態(tài)分類方法[J].計算機技術與發(fā)展,2016,26(7):11-13.
[16] He K,Zhang X,Ren S,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[17] Ohya J,Shio A,Akamatsu S.Recognizing characters in scene images[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1994,16(2):214-220.
[18] Wang Q,Lu Y,Sun S.Text detection in nature scene images using two-stage nontext filtering[C]//13th international conference on document analysis and recognition.[s.l.]:IEEE,2015:106-110.
[19] Gouk H G R,Blake A M.Fast sliding window classification with convolutional neural networks[C]//Proceedings of the 29th international conference on image and vision computing.New Zealand:ACM,2014:114-118.
[20] Ye Q,Doermann D.Text detection and recognition in imagery:a survey[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(7):1480-1500.
[21] Zhang Z,Shen W,Yao C,et al.Symmetry-based text line detection in natural scenes[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.[s.l.]:IEEE,2015:2558-2567.
[22] Jaderberg M,Vedaldi A,Zisserman A.Deep features for text spotting[C]//European conference on computer vision.[s.l.]:Springer International Publishing,2014:512-528.
[23] Matas J,Chum O,Urban M,et al.Robust wide-baseline stereo from maximally stable extremal regions[J].Image and Vision Computing,2004,22(10):761-767.
[24] Nistér D,Stewénius H.Linear time maximally stable extremal regions[C]//European conference on computer vision.Berlin:Springer,2008:183-196.
[25] Netzer Y,Wang T,Coaters A,et al.Reading digits in natural images with unsupervised feature learning[C]//NIPS workshop on deep learning & unsupervised feature learning.[s.l.]:[s.n.],2010:1-9.
[26] 金連文,鐘卓耀,楊 釗,等.深度學習在手寫漢字識別中的應用綜述[J].自動化學報,2016,42(8):1125-1141.
[27] 陳浩翔,蔡建明,劉鏗然,等.手寫數字深度特征學習與識別[J].計算機技術與發(fā)展,2016,26(7):19-23.
[28] Sermanet P,Chintala S,Lecun Y.Convolutional neural networks applied to house numbers digit classification[C]//21st international conference on pattern recognition.[s.l.]:IEEE,2012:3288-3291.
[29] 李 釗,盧 葦,邢薇薇,等.CNN視覺特征的圖像檢索[J].北京郵電大學學報,2015,38:103-106.
[30] Guo Q,Lei J,Tu D,et al.Reading numbers in natural scene images with convolutional neural networks[C]//International conference on security,pattern analysis,and cybernetics.[s.l.]:IEEE,2014:48-53.
[31] Ioffe S,Szegedy C.Batch normalization:accelerating deep network training by reducing internal covariate shift[C]//International conference on machine learning.[s.l.]:[s.n.],2015:448-456.
[32] Yin X C,Yin X W,Huang Kaizhu,et al.Robust text detection in natural scene images[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(5):970-983.
[33] Yin X C,Pei W Y,Zhang J,et al.Multi-orientation scene text detection with adaptive clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1930-1937.
[34] Kang L,Li Y,Doermann D.Orientation robust textline detection in natural images[C]//Proceedings of computer vision and pattern recognition.[s.l.]:[s.n.],2014.
[35] Yao C,Bai X,Liu W Y.Detecting texts of arbitrary orientations in natural images[C]//Proceedings of computer vision and pattern recognition.[s.l.]:[s.n.],2012.
[36] Yao C,Bai X,Liu W Y.A unified framework for multi-oriented text detection and recognition[J].IEEE Transactions on Image Processing,2014,23(11):4737-4749.
RecognitionofNumbersinNaturalScenewithConvolutionalNeuralNetwork
ZHOU Cheng-wei
(College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Extracting text information from a complex background image has been a hot topic and difficulty in computer vision.With the breakthrough of Convolutional Neural Network (CNN) in image recognition in recent years,the field of computer vision has gradually abandoned the way of extracting image features by manual methods,instead of using the deep network to automatically learn features.Using of scene text recognition of CNN is paid more and more attention.Therefore,an improved number recognition method of network structure convolution in natural scenes is proposed.It achieves the goal area detection and digital character recognition end-to-end training,and recognized feature can be used to initialize the network portion of target detection so as to reduce duplication feature extraction and improve the training speed.The image input needs to be processed does not require a fixed format but original image,which reduces the poor influence of image preprocessing on its original image data and improves the recognition accuracy.It is showed in the verification based on SVHN,MSRA-TD500 as well as the ICDAR 2013 that it is superior to other recognition methods in recognition performance.
convolutional neural network;natural scene;number recognition;end to end
2016-08-21
2016-11-28 < class="emphasis_bold">網絡出版時間
時間:2017-07-19
教育部專項研究項目(2013116)
周成偉(1991-),男,碩士研究生,研究方向為圖像處理、機器學習。
http://kns.cnki.net/kcms/detail/61.1450.TP.20170719.1108.010.html
TP301
A
1673-629X(2017)11-0101-05
10.3969/j.issn.1673-629X.2017.11.022
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
小學教學參考(2015年20期)2016-01-15 08:44:38
電測與儀表(2015年5期)2015-04-09 11:30:52
語文知識(2014年1期)2014-02-28 21:59:13
