基因組規(guī)模代謝網絡模型自動化修正
2017-11-01 08:12:40吳曉紅石貴陽
食品與生物技術學報 2017年9期
關鍵詞:模型
吳曉紅, 薛 衛(wèi), 張 梁*, 石貴陽
(1.糧食發(fā)酵工藝與技術國家工程實驗室,江南大學,江蘇 無錫 214122;2.南京農業(yè)大學 信息科學技術學院 江蘇 南京 210095)
基因組規(guī)模代謝網絡模型自動化修正
吳曉紅1, 薛 衛(wèi)2, 張 梁*1, 石貴陽1
(1.糧食發(fā)酵工藝與技術國家工程實驗室,江南大學,江蘇 無錫 214122;2.南京農業(yè)大學 信息科學技術學院 江蘇 南京 210095)
基于KEGG在線數(shù)據(jù)庫以及6個蛋白質區(qū)間預測數(shù)據(jù)庫,對基因組規(guī)模代謝網絡模型進行了自動化修正。作者提出了蛋白質區(qū)間預測結果的權重打分機制,同時利用圖像處理算法確定可信度高的特異性反應。上述修正的研究均在Spathaspora passalidarum NRRL Y-27907基因組規(guī)模代謝網絡精煉過程中得到運用實施,對于提高模型構建效率意義重大。
基因組規(guī)模;代謝網絡;斷點補齊;圖像處理;區(qū)間預測
隨著基因組高通量測序數(shù)據(jù)的涌現(xiàn)以及大量的生物學數(shù)據(jù)的產生,代謝網絡模型構建成為研究生物信息學的熱點之一。代謝網絡構建是一個耗時費力的過程,因此許多自動化構建的工具隨之應運而生。通常這些自動化工具側重關注代謝網絡粗模型的構建如 metaSHARK[1]和 AUTOGRAPH[2],其次關注代謝網絡模型的模擬過程,如CellNetAnalyzer[3]、OptFlux[4]和 COBRA Toolbox[5],只有少量的自動化工具是針對代謝網絡模型的精煉過程。目前能夠提供代謝網絡模型自動化精煉過程的工具有Model SEED、Pathway Tools、RAVEN 和 SuBliMinaL。
代謝網絡的模型構建包括粗模型的構建、模型的精煉、數(shù)學模型的轉換、模型的預測驗證四個過程。一個高質量的代謝網絡模型,應達到模型模擬結果和生物實際生長表型一致,否則要不斷的重復精煉修正過程,直到模擬與表型一致。模型的精煉修正無疑是代謝網絡模型構建過程中最耗時耗力的過程,現(xiàn)有模型精煉工具并不能真正實現(xiàn)真菌代謝網絡模型精煉過程的自動化。模型的精煉過程必須包括漏洞代謝的填補、反應區(qū)間定位等。Model SEED[6]和Pathway Tools[7]只能提供原核生物的代謝網絡模型的精煉自動化過程,不能提供反應區(qū)間的定位。RAVEN[8]和SuBliMinaL[9]是基于Wolf PSORT蛋白質區(qū)間預測數(shù)據(jù)庫實現(xiàn)自動化定位區(qū)間的程序。但是Wolf PSORT[10]只是基于氨基酸組成特征的在線預測數(shù)據(jù)庫。研究表明,基于氨基酸組成、二肽和物理化學三種綜合特征的蛋白質區(qū)間定位預測結果更為準確[11]。
利用作者所在實驗室自動化構建全基因組代謝網絡模型的程序,自動構建了Spathasporapassalidarum NRRL Y-27907全基因組規(guī)模代謝的粗模型。以S.passalidarum NRRL Y-27907的基因組規(guī)模代謝網絡模型的精煉過程為例,以簡單、面向對象的Java語言為基礎,對精煉過程中人工冗雜的斷點補齊的方法進行了研究,提出了一種基于KEGG[12]在線數(shù)據(jù)庫自動化填補漏洞反應的方法,并利用權重打分機制分析,6個真菌蛋白質定位數(shù)據(jù)庫預測S.passalidarum NRRL Y-27907的結果,在保證模型中反應的物種特異性的同時,實現(xiàn)了真菌代謝網絡模型精煉的自動化。自動化修正的流程見圖1。圖中進程g、進程n、進程o為一個小的流程循環(huán)。進程g中判斷反應包含斷點,則進入進程h,查找該反應在注釋圖譜中對應的坐標,并在進程i中讀取此坐標,在進程j中判斷此坐標是否為特異性反應,如果是,則在進程p中記錄該反應。如果不是,則在進程l中判斷此坐標是否為最后一個坐標,如果是最后一個坐標,則進入進程n,即進入進程g、進程n、進程o該流程循環(huán)。如果不是最后一個坐標,則進入進程m,讀取下一個坐標,判斷此坐標是否為特異性反應,重復此循環(huán)直至將所有的特異性反應都被找出,進入進程q,進行模型修正。在進程r中判斷模型中是否已經包含此反應,若已經包含,則回到進程n,即進入進程g、進程n、進程o該流程循環(huán),檢查下一條反應。若不包含此反應,則進入進程s,將此反應加入到模型中。

圖1 自動補齊斷點流程Fig.1 Process of the auto-refinement of gap
1 自動填補網絡漏洞
采用柴文平[13]等人的方法構建了S.passalidarum NRRL Y-27907代謝網絡粗模型。構建的代謝網絡粗模型需要進一步精細化與修正,最終完成一個高質量的基因組規(guī)模代謝網絡模型。
1.1 代謝網絡漏洞查找
模型導入到裝有COBRA工具包和GLPK線性規(guī)劃器的Matlab中,將模型轉化為計算機可讀的格式 (SBML)才能進行代謝網絡漏洞查找。通過xls2model程序將模型Excel表讀取為計量學S矩陣。S矩陣(828×984)表示該模型由828個代謝物和984個反應組成。同時通過GapFind程序完成代謝漏洞的查找,其中上游漏洞代謝物有為44個,下游漏洞代謝物有128個。
1.2 基于KEGG網絡爬蟲反應
KEGG是代謝網絡構建常用數(shù)據(jù)庫,含有多個在線子數(shù)據(jù)庫,其中REACTION數(shù)據(jù)庫包含迄今為止發(fā)現(xiàn)的所有生化反應。各個子數(shù)據(jù)庫的網頁數(shù)據(jù)格式比較統(tǒng)一明確,方便人們進行遠程服務器訪問。但是,KEGG數(shù)據(jù)庫更新頻繁,各個子數(shù)據(jù)庫不能夠免費下載,需要付費使用。而在基因組代謝網絡斷點補齊過程中,因為數(shù)據(jù)信息量浩大,頻繁訪問遠程服務器比較耗時耗力。因此,實現(xiàn)一種批量在線獲取并存取數(shù)據(jù)的方法意義重大。
1.2.1 方法概述 利用超文本轉移協(xié)議和Java控件HttpClient相結合,實現(xiàn)對網頁中特定信息的抓取KEGG提供物種特異性基因組信息以及所有反應式信息查詢網頁,通過一定的URL(Uniform Resource Locator,統(tǒng)一資源定位符)格式地址發(fā)送HTTP請求并獲取網頁中的基因信息。在漏洞填補的過程中需要訪問大量不同的網絡資源,獲取相關的基因信息,由于數(shù)據(jù)量較大且人工操作比較繁瑣,這里利用Java控件HttpClient實現(xiàn)爬蟲技術,抓去符合特定條件的網絡資源。HttpClient是Apache Jakarta Common下的子項目,可以用來提供高效的、最新的、功能豐富的支持HTTP協(xié)議的客戶端編程工具包,并且它支持HTTP協(xié)議最新的版本和建議。利用HttpClient訪問具體的URL地址,獲取服務器端返回的獲取html內容,html內容由標題、js代碼、正文、相關鏈接、聲明等區(qū)域組成,而有用信息只出現(xiàn)在正文中的各種html標簽標記內,分析html標簽并獲取特定的網頁信息。
1.2.2 漏洞填補算法實現(xiàn)
1)獲取注釋圖譜:提交物種基因組蛋白質序列至KAAS自動注釋服務器,獲取注釋信息,下載html和text格式。
2)查找包含斷點的注釋圖譜:根據(jù)Matlab軟件中GapFind程序返回的漏洞代謝物列表,在代謝網絡模型Excel格式中確定代謝物的反應途徑,依據(jù)KASS注釋返回的途徑圖譜找到包含漏洞代謝物的所有反應。
注釋返回的KEGG代謝途徑為包含糖代謝等在內的110個途徑。查找包含斷點的代謝圖譜的流程見圖2。具體思路和偽代碼步驟如下:
A:獲取斷點化合物所對應的Subsystem信息,記為sub。
B:向注釋查詢網頁URL地址發(fā)送HTTP請求。
C:如果服務器端響應代碼為HTTPStatus.SC_OK則正常響應,否則繼續(xù)請求,獲取html正文內容。
D:分析html內容,設i為行號,由第一行開始遍歷標簽對中的每一行,
For i from 1 to n
{
if(該行中第二個標簽中的內容與sub相等)
{
提取對應的第一個標簽中的內容,記為KO;
}
else
忽略該行,遍歷下一行;
}
E:根據(jù)D中的KO號得到滿足條件圖譜的URL地址,向URL地址發(fā)送HTTP請求得到服務器端響應的網頁圖片記為T1,T1即為整個網絡結構圖,其中綠色酶號表示包含斷點的特異性反應。
F:點擊T1左上角途徑方框,進去包含所有反應頁面page1,網頁中每一個EC號對應圖譜中的一個具體反應,它的URL地址指向具體的反應方程式。
G:獲取page1中所有EC號對應的反應,設ec_num為每一個EC號,從第一個開始

EC_K_Break.txt保存包含斷點化合物的EC,K號的信息。3)查找EC_K_Break.txt中每個K對應的坐標根據(jù)K號獲取其在T1中對應的坐標,判斷特異性反應。


圖2 斷點代謝途徑定位Fig.2 Orientation of gap metabolic pathway
1.3 判斷特異性反應
KEGG所有的反應都包含在通路數(shù)據(jù)庫(PATHWAY database)中,PATHWAY 圖譜上有顏色標記的酶號是指這個物種特定的基因或酶,只有有顏色標記的酶號表示的反應才是具有該物種特異性的反應,也才能添加到代謝網絡模型中。在代謝網絡模型中添加非特異性的反應會改變整個代謝途徑和代謝物流量,進而使模型模擬的結果偏離實驗數(shù)據(jù),影響模型的準確性和可信度。
構建代謝網絡模型需要提取代謝途徑中的特異性反應,圖中特異性反應對應的酶號所在的方形框有顏色標記。因此通過網絡爬蟲技術獲得方形框的位置列表,定位到某酶號所在的方形框后需要選取框內的像素點,讀取其顏色值,如果顏色分量RGB均為0或255,則沒有顏色標記,反之則有。代謝網絡特異性反應獲取流程見圖3。
基本思路為:
根據(jù)得到的position坐標讀取T1對應點的RGB色彩值。
Picture(Key:酶號;Value:代謝網絡圖中所有方形框的坐標向量集{V1,V2,……,Vn})
For i from 1 to n
{
If(某酶號所在的方形框)
{
沿方形框的長邊內側逐一選取像素點,讀取其顏色值;
If顏色分量RGB均為0或255 then沒有顏色標記
else有顏色標記;
If有顏色標記then該酶號對應的是特異性反應
do將反應加入菌的代謝網絡模型中;
else舍棄該酶號對應的反應。
}}
反應式漏洞填補
遍歷new_rec.TXT中每一個反應,查看模型中是否存在,存在則不處理,否則添加。
A:讀取new_rec.TXT中每行反應記為new_rec,i為行號
For i from 1 to n
{
if(模型中不包含 new_rec)
{
將new_rec添加到模型中;
}
else
忽略該反應,查找下一條反應;}

圖3 特異性反應獲取流程Fig.3 Process of getting the pecificreaction
2 獲取反應區(qū)間定位
細胞是生命活動的基本單位,它由執(zhí)行不同機體功能的稱為亞細胞的各部分組成,如細胞膜、細胞核、線粒體、高爾基體、內質網等。亞細胞功能是由位于其中的蛋白質執(zhí)行的,蛋白質所在的亞細胞稱為蛋白質的亞細胞位置[14]。蛋白質必須轉運到其應在的亞細胞位置上才能正確行使其功能,否則就會出現(xiàn)機體功能紊亂,正確合理的蛋白區(qū)間定位是高質量模型構建的基礎,見表1。

表1 真菌蛋白質亞細胞預測數(shù)據(jù)庫Table 1 Database for subcellular localization of fungal proteins
確定一條蛋白質的亞細胞位置稱為蛋白質亞細胞定位[15]。蛋白質亞細胞定位的傳統(tǒng)方法是通過生物化學實驗,如射線晶體衍射電子顯微鏡核磁共振等方法進行測定[16]。實驗方法精確度高,但費時耗力代價昂貴,而且對難于結晶的蛋白質來說,實驗方法不再有效。借助于先進高效的計算機自動化數(shù)據(jù)處理技術,出現(xiàn)了一些蛋白質定位預測網站。結合Spathasporapassalidarum NRRL Y-27907的生理生化性質和蛋白質特征提取方法、算法和準確性等,選取了6個真菌生物蛋白質區(qū)間預測網站,自動化提取分析網站的預測結果,在權重打分機制的基礎上得到最佳的蛋白質定位區(qū)間。這6個網站是基于蛋白質的氨基酸組成、偽氨基酸組成、二肽、生物化學特征或是四種特征的綜合。
2.1 區(qū)間定位算法實現(xiàn)
A:對每條反應獲取對應的KO號。
B:將A中的KO號在KASS注釋結果中查找基因號,并在本地下載Spathasporapassalidarum NRRL Y-27907蛋白質序列庫提取其對應的蛋白質序列。
C:將蛋白質序列提交到對應網站的表單中,獲取返回的定位信息。
D:獲取定位區(qū)間的信息并填入反應式中。
在獲取具體反應的區(qū)間信息過程中,需要將反應所對應的蛋白質序列提交到網頁的表單中,提交后返回具體的區(qū)間定位信息,此處會遇到兩個問題:1)表單提交過程中不支持大量蛋白質序列自動提交。由于模型中蛋白質序列數(shù)量較大,在有的網站中獲取定位信息時不支持大量序列的一次性提交而只能分別提交單個序列獲得定位信息,在提交過程中任務量大且人工耗費時間長。2)大量蛋白質序列提交耗費時間長,在網站中提交多個序列后等待服務器端反饋的定位信息耗費時間太長,甚至會發(fā)生無響應等問題,見圖4。
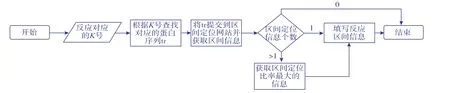
圖4 反應亞細胞定位流程Fig.4 Process of subcellular localization
HttpClient支持訪問特定的URL地址,獲取服務器端返回的html信息,并且能夠分析html中form表單中的信息,實現(xiàn)內容的自動提交。由于涉及到的定位頁面所有的表單提交方式都是POST提交,利用HttpClient中的PostMethod方法實現(xiàn)post提交。表單中的元素賦值過程:獲取表單中需要賦值的元素標簽,以蛋白質序列元素賦值標簽為例,標簽為