基于棧式降噪自編碼器模型的糖尿病預測研究
2017-10-23 03:39:05
福建質量管理 2017年18期
(重慶工商大學智能制造服務國際科技合作基地 重慶 400047)
基于棧式降噪自編碼器模型的糖尿病預測研究
簡恒
(重慶工商大學智能制造服務國際科技合作基地重慶400047)
我國是一個人口大國,與此同時,慢性病患者人數也居世界首位,而糖尿病及其相關并發癥是其中的一個重要組成部分。隨著國民經濟的發展,居民對健康需求日益強烈,因此,把根據人的各項生化指標為依據的糖尿病預測研究放在更加突出的地位就顯得尤為重要。本文在總結前人利用傳統淺層模型進行預測研究的基礎上,針對其模型擬合效果和泛化能力不強的缺點,提出一種基于底層棧式降噪自編碼器和頂層分類神經網絡的預測模型。首先對數據進行清洗并歸一化,在利用自編碼的無監督學習對特征進行識別與重學習,逐層貪婪學習以后,再將將棧式降噪自編碼器接入有監督的神經網絡進行分類預測,最后再利用有監督的學習進行參數的微調。
糖尿病;預測;棧式降噪自編碼器;特征提取;數據預處理
一、引言
基于人的各項生化指標進行糖尿病的特征學習與預測已經成為國內外研究的重點,其中能構建出性能優良的數據模型是預測的關鍵。針對于現在日益陡增的糖尿病生化指標的數據,傳統的淺層模型既不能有效的表達出其深層次的特征,又不能進行精準的預測。例如,決策樹模型雖然理解和解釋起來簡單,且決策樹[1]也可以根據邏輯關系進行構建,但其結果很不穩定,只要數據中一個很小的變化可能就會導致一個完全不同的樹。另外,傳統提取特征的方式大多都是人工提取特征,需要設計特征選擇器或者根據。支持向量機[2]的最終決策函數只由少數的支持向量所確定,計算的復雜性取決于支持向量的數目,而不是樣本空間的維數,但其缺點也十分明顯,它對大規模訓練樣本難以實施,并無法解決多分類的問題。人工神經網絡[3]的非線性擬合能力很強,這使它特別適合于求解內部機制復雜的問題,但其BP(back propagation)算法訓練速度慢,且訓練很有可能會失敗。Logistic回歸算法[4]的計算速度很快,能夠有效的節省硬件資源,但是容易欠擬合,并且分類的精度不高。從特征學習的角度來看,傳統的特征學習都是采用人工提取特征的方法,且特征器需要專家經驗且耗時[5],這樣不僅效率地下,而且還很難排除人為因素的干擾。深度學習作為人工智能技術的重要方法之一,在各個領域都表現出不凡的優勢,例如,計算機視覺、語音識別、自然語言處理等。面對呈指數速度增長的海量數據信息,如何從大數據中提取出對預測結果有效的特征,幫助我們建立模型去擬合原有的數據并進行預測成為該領域中的一大難題。通常人的各項生化指標數據具有不確定性和動態性等特點,且噪聲較多,數據之間且包含較多的非線性關系,對于利用人的各項生化指標數據進行預測未來是否會患有糖尿病一直都是國內外研究的熱點。針對深度學習的優勢,尤其是自編碼器的無監督學習機制,為研究糖尿病預測提供了一種新的思路。
二、棧式降噪自編碼器預測模型
(一)自編碼器

圖1 自編碼器結構
設ω1∈Rm×n、b1∈Rm分別表示輸入層與隱藏層的權值與偏置,ω2∈Rm×n、b2∈Rm分別表示隱藏層與重構可視層的權值與偏置,假設每一個神經元的激活非線性激活函數都是ReLu函數,對于自編碼器在編碼過程中如下所示
解碼過程為:
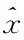
(二)SDAEP模型
對于的人的生化指標數據{(x(1),y(1)),(x(2),y(2)),(x(3),y(3))…},經過棧式降噪自編碼器的學習后,將構建出的有更好特征表達的數據接入神經網絡模型,就構成了糖尿病的預測模型SDAEP(Staked Denoising AutoEncoder based Prediction model)結構如圖3所示
圖3 SDAEP結構
在棧式降噪自編碼器模型中,h1與h2均為自編碼器的隱藏層,h3為自編碼器連接的輸出層帶有sigmoid分類器的神經網絡層。通過棧式化的多層降噪自編碼器的特征學習,將經過處理的數據進行特征提取,獲取了具有更好表達的新的特征,在利用神經網絡的輸出層的分類器對未來這些人是否會患有糖尿病做出預測。
三、SDAEP模型的學習算法
(一)貪婪學習算法
所謂貪婪學習算法是指,在對問題的求解過程中,總是做出來在當前看來是最好的選擇。即不從整體最優上加以考慮,只做出在當前情況下的最優解。棧式降噪自編碼器預測模型之所以不直接用梯度下降算法訓練是因為隨著隨著神經網絡的層數增加,利用前向傳播到最終的輸出層后,將訓練值與實際值作差在進行反向傳播計算梯度的時候,會導致梯度快速下降,以至于在最初的幾層神經網絡當中,權值的變化會非常的小,使得神經網絡無法訓練。這時我們采用逐層貪婪學習算法,先對前面的DAE的每一層,分別進行無監督的預訓練,等預訓練完成以后再連接分類器進行有監督的訓練,能夠使SDAEP快速達到最優。
(二)棧式降噪自編碼器的學習算法
棧式降噪自編碼器的參數學習采用反向傳播算法,先將處理好的數據輸入到輸入層,經前向傳播得到得到L2,L3,…直到輸出層Lnl的激活值a(2),…,a(nl),再根據自編碼器的整體代價函數計算出訓練值與實際值的差值后,經反向傳播算法計算梯度,回傳到輸出層,逐層微調權值與偏置。假設棧式降噪自編碼器的輸出層為第nl層,輸出的目標值為y,則棧式降噪自編碼器各輸出層和隱藏層各節點的誤差表達式分別為:
δ(nl)=-(y-a(nl)f'(z(nl))
其中,l=nl-1,nl-2,nl-3,…,2,式中f為ReLu激活函數,f'(Z(l))表示第ι層激活函數f(z)對輸入z的導函數值。
利用梯度下降法更新權值和偏置參數,設α為學習率,迭代更新表達式為:
w(l)=w(l)-α[▽w(l)J(W,b;x,y)]
b(l)=b(l)-α[▽b(l)J(W,b;x,y)]
通過不斷的迭代來調整權值w以及偏置b以減小自編碼器整體代價函數的值,以此來優化預測模型。
四、實驗設計與分析
本次實驗的軟件平臺為MATLAB R2015b,數據預處理的實驗平臺為Python3.6,編程實現算法。
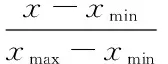
模型的評價標準為均方偏差以及分類準確率
分類準確率=100*(1-error)

為了處分反應模型的效果,以人的生化指標為依據的糖尿病數據集為例,對比了目前在糖尿病預測領域較為常用的BP神經網絡和支持向量機(SVR)模型,如表1所示
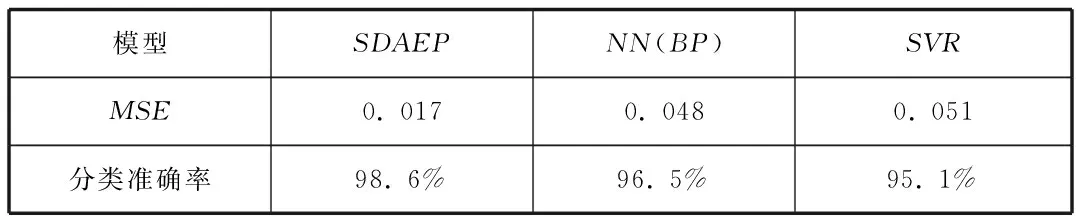
表1 同一數據集下不同模型的預測效果
由此可以見得,SDAEP的預測效果要優于BP神經網絡和支持向量機的,雖然BP神經網絡和支持向量機的分類準確率相差無異,但均方誤差差距較大,且其隨機初始化的權值和偏置也沒有經過無監督預訓練的SDAEP穩定,泛化能力還有待提升,經過上述對比,可以看出SDAEP的預測性能更好。
五、結語
棧式降噪自編碼器預測模型克服了傳統淺層模型泛化能力不強的確定,并對數據的特征進行重學習,使其有了更好的表達,而自編碼其自身獨特的逐層貪婪的學習方法也改進了神經網絡隨機初始化的缺點,比單獨使用反向傳播在通過梯度下降法來微調權值和偏置的神經網絡收斂速度更快,所以棧式降噪自編碼器在對糖尿病的預測領域具有重要的應用研究和推廣價值。
[1]馬瑾,孫穎,劉尚輝.決策樹模型在住院2型糖尿病患者死因預測中的應用[J].中國衛生統計,2013.6,30(3):422-423
[2]洪燁.基于機器學習算法的糖尿病預測模型研究[M].哈爾濱工業大學碩士學位論文,2016.6
[3]郭奕瑞,李玉清,王高帥,劉曉田,張路寧,張紅艷,王炳源,王重建.人工神經網絡模型在2型糖尿病風險預測中的應用[N].鄭州大學學報(醫學版),2014,3,49(2):180-183
[4]曹文哲,應俊,陳廣飛,周丹.基于Logistic回歸和隨機森林算法的2型糖尿病并發視網膜病變風險預測及對比研究[J].2016,03:1674-1633
[5]Martin Langkvist,Lars Karlsson,Amy Loutfi.A review of unsupervised feature learning and deep learning for time-series modeling[J].Pattern Recognition Letters,2014(42):11-24
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年11期)2021-08-22 03:15:16
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
