正典/檔案:文學(xué)場域大型動力學(xué)①
2017-09-07 06:40:20馬克阿爾吉休伊特莎拉阿里森瑪麗莎杰瑪萊恩霍伊舍弗蘭科莫雷蒂漢娜瓦爾塞
山東社會科學(xué) 2017年9期
[美]馬克·阿爾吉-休伊特 [美]莎拉·阿里森 [德]瑪麗莎·杰瑪 [美]萊恩·霍伊舍 [美]弗蘭科·莫雷蒂 [美]漢娜·瓦爾塞 撰 汪 蘅 譯
(斯坦福大學(xué) 英文系,美國 加利福尼亞州斯坦福市 94305)
正典/檔案:文學(xué)場域大型動力學(xué)①
[美]馬克·阿爾吉-休伊特 [美]莎拉·阿里森 [德]瑪麗莎·杰瑪 [美]萊恩·霍伊舍 [美]弗蘭科·莫雷蒂 [美]漢娜·瓦爾塞 撰 汪 蘅 譯
(斯坦福大學(xué) 英文系,美國 加利福尼亞州斯坦福市 94305)
一、社會學(xué)指標(Sociological Metrics)
1.嫁妝與蔬菜
文學(xué)研究數(shù)字化所引進的新事物中,檔案規(guī)模也許最具戲劇性:以前我們研究一二百本19世紀小說,現(xiàn)在我們能夠分析數(shù)千本、數(shù)萬本,以后會有數(shù)十萬本。對于量化文學(xué)史而言這是狂喜的時刻:就像擁有了一部望遠鏡,能讓你看到全新星系。這也是真理的時刻:這樣一來,數(shù)字化天空是否揭示了什么,改變了我們對文學(xué)的認識?
這并非修辭性反問。費爾南·布羅代爾(Fernand Braudel)在其1958年的著名論文中歡呼“計量史學(xué)的降臨”將“打破19世紀史學(xué)的傳統(tǒng)形式,”他提到“人口進程,薪酬變動,利率變化……生產(chǎn)率……貨幣供求”,都是計量史學(xué)的典型材料。②Fernand Braudel, “History and the Social Sciences: The Longue Durée”, in On History, Chicago 1980, p. 29.顯然這些都是可量化項目;同立法、軍事戰(zhàn)役、政治內(nèi)閣、外交等方面的研究相比,也是全新的研究目標。正是這一雙重轉(zhuǎn)移改變了史學(xué)實踐;不僅是量化本身。但是我們這里并沒有材料的轉(zhuǎn)移:最終可能會研究20萬本小說,而不是200本;但依然是小說。新意何在?
199,000本從沒研究過的書——這是標準答案——怎么可能沒有新意?這是文學(xué)史的全新維度。
“我們更了解人們出于聲望的原因交換貨物,而不太了解那些每天都在進行的交換,”在布羅代爾的論文發(fā)表幾年后,安德烈·勒魯瓦—古昂(André Leroi-Gourham)在《手勢與言語》(GestureandSpeech)一書中寫道:“更了解嫁妝錢的流轉(zhuǎn)而不太了解蔬菜的銷售……”③André Leroi-Gourham, Gesture and Speech, 1965, Cambridge 1993, p. 148.嫁妝與蔬菜:完美對照。二者都很重要,但原因相反:嫁妝重要,因為一生只有一次;蔬菜重要,因為我們每天都吃。乍一看,這同200本和20萬本小說極其相似。但只要深入看待這件事,復(fù)雜性就浮現(xiàn)了。例如1814年出版的兩本歷史小說:沃爾特·司各特(Walter Scott)的《威弗萊》(Waverley)和詹姆斯·布魯爾(James Brewer)的《英格蘭的菲爾迪南爵士》(SirFerdinandofEngland)。人們本能地把《威弗萊》同嫁妝的顯赫聯(lián)系起來,把菲爾迪南爵士同不起眼的角色菊苣聯(lián)系起來。事實上司各特的小說既是形式上的偉大突破,也是歐洲人人都看的書:嫁妝和蔬菜,合二為一。但如果是這樣,數(shù)字檔案中那些菲爾迪南爵士又能有何不同?過去我們對其一無所知,現(xiàn)在有所了解。不錯。這有什么要緊嗎?*也許不會。在即將發(fā)表于《美國現(xiàn)代語文季刊》(Modern Language Quarterly,MLQ)特刊的一篇關(guān)于“量表與值”的論文中,詹姆斯·英格利什(James English)令人信服地指出,“根據(jù)‘每部新小說都必須在分析中有同樣價值’這個原則收集的樣本”——也就是說,和我們的“檔案”非常類似的樣本——其實并不很“適合于文學(xué)生產(chǎn)的社會學(xué),這里理解的‘生產(chǎn)’不只是(甚至不主要是)作者對某種文本的生產(chǎn),而是由社會體系產(chǎn)生某種價值,其行為人包括讀者和評論家、編輯和書商、教授和教師,以及文學(xué)的制度機器中所有部件。”這本手冊本來要研究檔案,結(jié)果卻幾乎完全在關(guān)注“某種文本的生產(chǎn)”,這似乎清楚印證了英格利什的論點。另一方面,只要“社會體系”創(chuàng)造“價值”的手段不僅是將價值指定給某些作者或文本,還包括否認其他作者或文本的價值,(“尤其當事關(guān)品味時,所有決定都是否定判斷;品味或許首先就是嫌惡”:布爾迪厄,《區(qū)分》),那么讀者和“文學(xué)的制度機器”里的其他人就會出現(xiàn)在我們的敘事中——但總是只扮演毀滅性角色。
我們用自己的一項研究發(fā)現(xiàn)來闡明問題:萊恩·霍伊舍(Ryan Heuser,本文作者之一)和龍萊克(Long Le-Khac)在《2958本19世紀英國小說的計量文學(xué)史:語義群方法》(“A Quantitative Literary History of 2,958 Nineteenth-Century British Novels: The Semantic Cohort Method”)(圖1.1)中描述了“抽象價值”——“謙遜”、“尊重”、“德行”等詞語——語義場的衰落。2958這個一絲不茍的數(shù)字表明,霍伊舍和萊克認為檔案的寬度是其研究的關(guān)鍵。如果他們研究的是更狹窄陳舊的正典,結(jié)論會否不同?圖1.2提供了答案。不會。正典比檔案先出現(xiàn)15—20年,但歷史軌跡一樣。
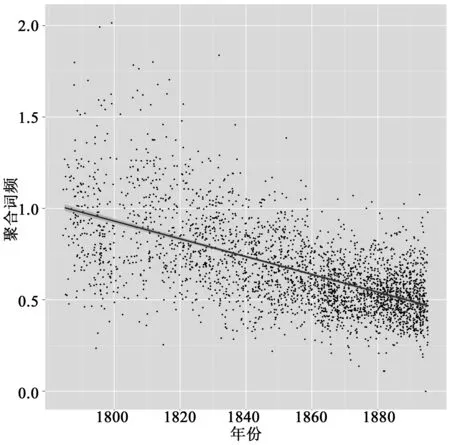
圖1.1 英國小說中的抽象價值,1785—1900Ryan Heuser and Long Le-Khac, "A Quantitative Literary History of 2,958 Nineteenth- Century British Novels: The Semantic Cohort Method", Literary Lab Pamphlet 4, 2012, p. 18.
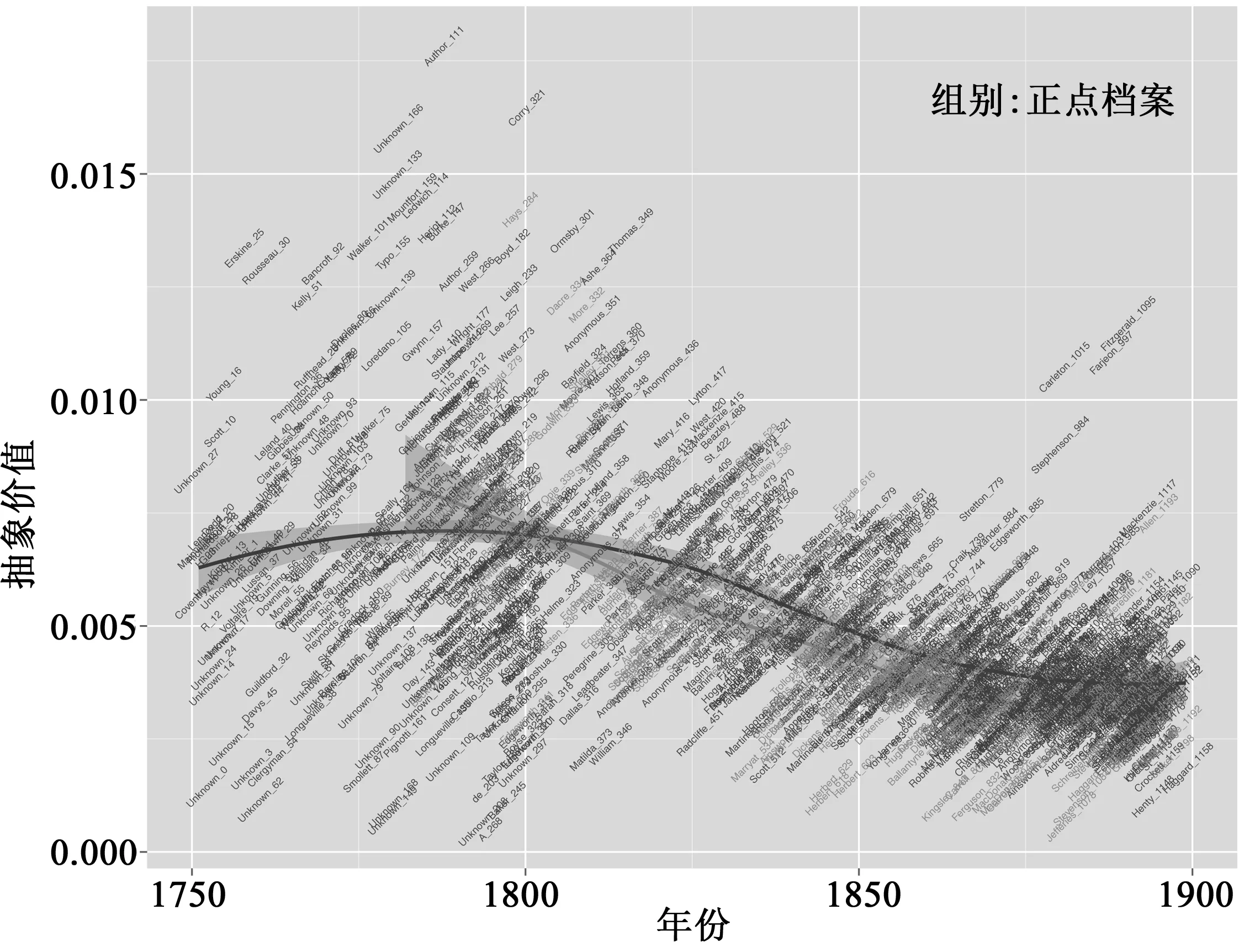
圖1.2 英國小說中的抽象價值、正典與檔案,1750—1900本圖中,正典包括250本小說,原由查德威克-希利19世紀小說文集收錄。我們在以下的第三節(jié)解釋了為何選擇查德威克-希利。
這并不意味著新檔案沒有新信息,而是意味著我們?nèi)砸獙W(xué)習(xí)提出正確的問題。但在此之前,有些情況需要澄清。正典與檔案:這兩個詞是什么意思?
2.檔案偏差(Bias in the Archive)
我們從三個基本概念開始:出版物(the published)、檔案(archive)、語料庫(corpus)。第一個很簡單:所有已出版書籍的總和(已上演的喜劇、已背誦的詩歌,諸如此類)。這些已經(jīng)“公開”的文獻是一切量化工作的基本范圍(雖然其邊界肯定是模糊的,可以包括已經(jīng)寫就但仍放在抽屜里的書,或者被出版商拒絕的書,等等)。檔案則是出版文獻中保存在圖書館等地的部分,正越來越數(shù)字化。語料庫是出于某種原因從檔案中選出的部分,供具體研究項目使用。因此語料庫小于檔案,檔案小于出版物:就像三個俄羅斯套娃,依次套好。但有了數(shù)字技術(shù),這三個層面間的關(guān)系變了:一個項目的語料庫現(xiàn)在(幾乎)可以輕易和檔案一樣大,而檔案本身也變得——至少在當代——(幾乎)和所有出版文獻一樣大。當我們使用“檔案”這個詞時,想到的正是這種三個層面合而為一的潛力;借用《年鑒雜志》的表達法,融合為“完全文學(xué)史”(total history of literature),以前這只是幻想,現(xiàn)在可能很快就會實現(xiàn)。
這是理論上。實際沒那么簡單。以本項目為例,最初語料庫包含約4000本1750年到1880年間的英國小說;18世紀的作品來自ECCO;19世紀作品來自查德威克-希利公司(Chadwyck-Healey)的19世紀小說(Nineteenth Century Fiction)語料庫以及伊利諾伊大學(xué)互聯(lián)網(wǎng)檔案(Internet Archive of the University of Illinois)。*https://archive.org/details/19thcennov. ECCO(18世紀作品在線)是18世紀數(shù)字資料集,分兩部分,建立于英語簡稱目錄(ESTC)基礎(chǔ)上,并將一些英美圖書館作為資料來源;ECCO的第二部分是更新部分,包括原始ECCO發(fā)行時尚未出現(xiàn)的文本或版本。以舊的文學(xué)史標準看,4000本小說是很大的語料庫了;但實際涵蓋的內(nèi)容卻很不均衡。例如1770—1830這個階段,我們有雷文-加賽德-薛維靈(Raven-Garside-Sch?werling)書目(譯注:即牛津大學(xué)出版社TheEnglishNovel1770-1829,ABibliographicalSurveyofProseFictionPublishedintheBritishIsles)大約三分之一條目;但19世紀晚期階段的百分比低得多,只有約10%。不同作品類型情況也不同:我們有阿伯格姆(Adburgham)銀匙小說書目(Silver-Fork Bibliography)的96%,但只有加拉赫(Gallagher)工業(yè)小說的77%,史蒂文斯(Stevens)的司各特之前歷史小說的53%和佩拉齊尼(Perazzini)哥特書目的35%。*Alison Adburgham, Silver Fork Society, London 1983; Catherine Gallagher, The Industrial Reformation of English Fiction, Chicago 1985; Anne H. Stevens, British Historical Fiction Before Scott, London 2010; Federica Perazzini, Il Gotico @ Distanza, Roma 2013.
很明顯,這些統(tǒng)計學(xué)領(lǐng)域不易把握。和少數(shù)公認經(jīng)典的文本相比,我們的190本哥特小說數(shù)量很大了,因此很容易受到誘惑,要將其簡單(toutcourt)等同于檔案;但它們是否真能代表整個英國哥特風(fēng)格的“總體”(population)?幾乎肯定不能;簡單說,從特定總體中隨機挑選的樣本是有代表性的;但這190本小說肯定不是這樣挑選出來的。這些書基本上來自少數(shù)幾個大圖書館,而圖書館買書不是為了擁有代表性樣本;它們想要自己認為值得保存的書籍。好書。好的標準則很可能和形成正典的標準相似。雖然我們的語料庫比傳統(tǒng)正典大20倍,但其挑選標準完全可能讓語料庫整體上更像正典,而不像檔案。這是個問題。*更復(fù)雜的是,不同作品類型有不同正典/檔案比:盡管書信和銀匙小說的檔案相對較大而正典相對較小,工業(yè)小說和成長小說則相反,二者都吸引了許多維多利亞時代主要作家;而哥特小說和歷史小說這兩個大類則位于兩極之間。這一點上以及許多其他地方,我們還需要更大量的實證證據(jù)。
我們希望結(jié)果可靠,因此生成了一個本領(lǐng)域隨機樣本以供研究:簡單選取507本1750年到1836年間的小說、82本哥特小說、85本司各特前的歷史小說。*最后這組不是隨機樣本:既然安·斯蒂文斯(Anne Stevens)的書目只包括了85部司各特之前的歷史小說,我們決定尋找全部。一共674本小說。在數(shù)字年代這用不了多久。
2014年6月學(xué)年結(jié)束時生成了樣本,接著去自己的數(shù)據(jù)庫中尋找,在雷-加賽德書目中找到了82本哥特小說中的35本、85本歷史小說中的35本,以及507本小說中的145本。7月初,我們將尚未找到的約460本書目名單交給斯坦福圖書館的格倫·沃爾塞(Glen Worthey)和麗貝卡·溫菲爾德(Rebecca Wingfield),他們迅速將其分解為幾個大包。HathiTrust數(shù)字圖書館和Gale數(shù)據(jù)庫(其中的NCCO 和ECCOII)擁有約300種(差不多每家各半)。*HathiTrust是大型研究型圖書館之間的合作項目,一個電子數(shù)據(jù)存儲庫,包括作為谷歌項目和互聯(lián)網(wǎng)檔案一部分的掃描卷冊,以及其他小型本地項目。Gale的NCCO(19世紀作品在線)是19世紀資料的數(shù)字文庫,通常以主要文庫作為資料來源,涵蓋各專業(yè)領(lǐng)域(文學(xué)、科技、攝影等)。到目前為止,NCCO有12個部分,其中一部分包括Corvey小說文庫;NCCO與ECCO不同,并非建立于領(lǐng)域內(nèi)標準書錄基礎(chǔ)上,因此難以預(yù)測新增內(nèi)容。Gale是以營利性企業(yè)方式運營的信息與教育服務(wù)大公司,向圖書館銷售內(nèi)容和服務(wù);出版印刷品(參考書和小說)和電子文庫(ECCO、 NCCO及其他)。其母公司是圣智學(xué)習(xí)集團(Cengage Learning),自身定位為“為全球高等教育和中小學(xué)教育(K-12)、以及職業(yè)和圖書館市場提供教育內(nèi)容、技術(shù)和服務(wù)的領(lǐng)先企業(yè)”。另有30種則收入文集中,或以不同版本存在,或隱藏在略有不同的標題后,或在微縮膠片里,不一而足。大約100種只有印刷本,有10種小說沒有存世版本。8月,我們向Hathi 和Gale發(fā)出請求,希望獲取他們那300本書。斯坦福同這兩家機構(gòu)都有長期財政協(xié)議。只有印刷版本的那100本小說中,大約一半由大英圖書館收藏,幾個月前該館已經(jīng)從其館藏中好意提供了65,000冊數(shù)字圖書給文學(xué)實驗室;不幸的是要找的書全都不在這其中。加州大學(xué)洛杉磯分校(UCLA)和哈佛的特藏有其中的50種左右。他們發(fā)來一系列報價,根據(jù)原版圖書的狀況以及可能極費人力的拍照要求,每本書收費1,000美元到20,000美元不等,價格相當合理。最后,有6本書由歐美論文全文數(shù)據(jù)庫(ProQuest)收藏,盡管他們慷慨給出半價,還是可能花費我們每本書147,000美元或者25,000美元。*這些數(shù)字還應(yīng)加上斯坦福圖書館付給ECCO、 ECCCO II以及NCCO的初始費用:算上常見的慷慨折扣,為這三個文庫大概支付了100萬美元。ProQuest也是營利性企業(yè),提供教育服務(wù),產(chǎn)品包括歷史報刊系列(Historical Newspaper series)、文學(xué)在線(Literature Online)、論文提要(Dissertation Abstract)等,其母公司是劍橋信息集團(Cambridge Information Group)。
記住:這一搜尋過程包括了位于倫敦、劍橋、洛杉磯以及——當然——斯坦福在內(nèi)的許多優(yōu)秀圖書館;出動了文學(xué)實驗室6位研究人員以及Hathi和Gale等地的人員。我們尋找的圖書僅僅兩百年歷史,印數(shù)至少750到1000本,而且位于當時已經(jīng)擁有有效圖書館的地區(qū)。文學(xué)實驗室也有一些研究資金(不過別弄錯,不是那種錢)。換句話說,不能指望更好的資源了。但仍然費時6個月才收到Hathi和Gale的文本,這些文本本來應(yīng)該讓隨機樣本從最初的30%增進到70—80%,*“應(yīng)該讓”,因為從文庫接收一個文本不等同于能夠研讀該文本。許多來自查德威克-希利和ECCO I的資料之前都是磁帶形式發(fā)送的,格式所需的驅(qū)動很難找到,也很難用;更“便利”的數(shù)據(jù)傳送(例如互聯(lián)網(wǎng)數(shù)據(jù)傳送或者外接硬盤)也有本身的問題:莫測的郵件系統(tǒng),怪異的防火墻不兼容,反常的文件協(xié)議要求。(例如,斯坦福圖書館大多數(shù)許可協(xié)議的文本挖掘或圖書館館藏結(jié)構(gòu)的館外分享主題都非常模糊;過去5年以來,圖書館都明確堅持將文本挖掘包括在目前的許可中,但之前的協(xié)議則是灰色地帶)。最后,從無窮盡的磁帶或硬盤中挖掘資料,元數(shù)據(jù)不充分或者不正確,又沒有數(shù)據(jù)庫支持,這是地道的拜占庭式過程。例如,圖書館會用Gale的搜索界面在ECCO數(shù)據(jù)庫中搜尋,并根據(jù)界面指示引用其URL。但是如果圖書館為實驗室找到一份原始文件,他們需要仔細搜尋一兩個硬盤(或磁帶),其中包含數(shù)十萬目錄,目錄名僅僅是系列隨機數(shù)字;而Gale發(fā)送這些原始文件時的元數(shù)據(jù)“清單”包含在大約10個word文檔中,格式看起來要打印似的:兩欄,作者名用黑體,非常基礎(chǔ)的目錄數(shù)據(jù),一個文件ID、ESTC ID,以及一個目錄路徑。這些文件數(shù)量龐大:ECCO II、文學(xué)與語言模塊,作者L-Z(大約是ECCO II發(fā)送內(nèi)容的十分之一)一共2750頁文件。第二,里面的ID數(shù)字不是你在Gale界面上看到的那些,而是看不見的內(nèi)部數(shù)字。因此,盡管實驗室在使用ECCO數(shù)據(jù)庫時費功夫識別過來源,也標注了Gale的官方ID數(shù)字,圖書館仍然不得不根據(jù)作者或者書名重新搜索(re-search)每個條目,以便找到要復(fù)制的文件名:Gale的ID數(shù)字根本沒有包括在文檔清單中。“我的教訓(xùn),”一位全程協(xié)助我們的研究型館員的結(jié)論如下,“是這樣,就算已經(jīng)找到你們需要的文檔,其實仍然還沒有真正找到文檔。”這一數(shù)字很可能會讓許多研究結(jié)果變得可疑,因為幾乎能肯定,缺失的那20—30%距離能想到的所有正典化(canonization)形式都最為遙遠。
顯然,要說數(shù)字化讓一切變得唾手可得且廉價——還別說“免費”——就是個神話。我們一點點認識到這一事實,決定從已有的語料庫挑選材料,開始工作:一個包含1,117部著作的數(shù)據(jù)庫,其中263部來自查德威克-希利,854部來自不同檔案來源。最初的結(jié)果將我們迅速引到一個方向;新發(fā)現(xiàn)增添了新勢頭;等到(近乎)隨機的樣本(幾乎)都收集到手,研究工作已十分深入,無法再從零開始。我們呈現(xiàn)的并非理想的研究模式,同時也認識到之前的決定導(dǎo)致研究結(jié)果偏弱。但集體作品有其自身的臨時性,尤其是在某種“組織間隙”式(interstitial)的制度空間中進行的研究,而我們的空間依然如此:等待數(shù)月研究才開始,這能毀掉任何項目。也許以后我們會提前一年派出一名偵察員尋找樣本。或者繼續(xù)拿手頭的資料研究,承認資料的局限和缺陷。臟手勝過空手(Dirty hands are better than empty)。
3.從正典到文學(xué)場域(From the Canon to the Literary Field)
如果選擇檔案是由歷史上的圖書館實踐決定的(哪些小說上架?哪些容易數(shù)字化?),那么選擇正典就事關(guān)批判性判斷——雖然并非由我們自己判斷。本項目中我們最先求助的正典是查德威克-希利19世紀小說集(Nineteenth-Century Fiction Collection),由丹尼·卡林(Danny Karlin)和湯姆·基默爾(Tom Keymer)二人編輯部設(shè)計,*與史蒂凡·霍爾(Stevan Hall)直接交流后得知,編輯們選擇文本沒有限制。包含約250本小說,入選原因是其特別值得珍藏,對學(xué)者尤為可貴,各圖書館會愿意付費獲取電子版本。
19世紀小說集選編于20世紀90年代,其后有新小說加入。推廣材料宣稱本選集“代表了維多利亞時代經(jīng)典的偉大成就,反映了這一時期的標志性作品,”同時還覆蓋了“許多被人忽略或不為人知的作品,其中多已絕版或難以尋覓。”例如從1794年起,選集包括了安·拉德克里夫(Ann Radcliffe)的《尤多爾佛之謎》(MysteriesofUdolpho)和威廉·戈德溫(William Godwin)的《凱萊布·威廉斯》(CalebWilliams),也有簡·奧斯汀(Jane Austen)的《蘇珊太太》(LadySusan,這本很短的小說很可能寫于那段時期前后,但出版于作者身后的1871年)和托馬斯·霍爾克羅夫特(Thomas Holcroft)不同凡響的《休·特雷弗歷險記》(AdventuresofHughTrevor)。前面兩本入選順理成章,另外兩本理由則不太明顯。看起來,選擇250個文本為評論上和歷史上不怎么重要、不為人所知的小說留下了空間:不只是奧斯汀的6部主要作品,還包括《蘇珊太太》;不只是戈德溫,還有霍爾克羅夫特。只要我們認為“正典”意味著精選出相對較少的經(jīng)典化文本以做精細研究,那么查德威克-希利作為當今研究者可即時進入的大型可檢索文集*也就是說,假設(shè)上述研究者所在機構(gòu)擁有必要資源。據(jù)一所大學(xué)的ProQuest代表說,全世界只有“超過600所”大學(xué)訂閱了文學(xué)在線(LION)數(shù)據(jù)庫。就不算是糟糕的代理。
但仍然是代理。我們認識到,對于正典這樣多面且難以捉摸的概念,依賴單一來源是對這一概念的誤解。馬克·阿爾吉-休伊特(Mark Algee-Hewitt,本文作者之一)和馬克·麥克格爾(Mark McGurl)撰寫的《正典與語料庫之間:六種視角看二十世紀小說》(“Between Canon and Corpus: Six Perspectives on 20th-Century Novels”)(文學(xué)實驗室手冊第8期,2015)談到了類似問題,列出了差異很大的群體選出的幾種“20世紀最佳小說”名單,分析了其間不同的接近程度。我們路徑不同,并被這一路徑從查德威克-希利的簡短書目引到兩份很長的作者名單上:《英國人物傳記辭典》(DictionaryofNationalBiography,DNB)中提及的書,以及美國現(xiàn)代語文協(xié)會(MLA)資料庫索引中收錄的20世紀學(xué)術(shù)文章的“基本科目作者”(primary subject author)名單。在一個橫向項目中,我們還添加了最近30年斯坦福博士考試列表里包括的文本。這么做既不是在尋找正典的“正確”定義(以上都不是正典定義),也沒有指望DNB、MLA和斯坦福會彼此認可(他們也沒這么做)。*即使不算斯坦福博士考試的代表性,DNB和MLA以作者為中心的方法也將司各特的《危險城堡》(Castle Dangerous)或者薩克雷(William Thackeray)的《凱瑟琳》(Catherine)放在同《威弗利》和《名利場》(Vanity Fair)同一個平面上,這不可能對頭。但其他標準也有類似的缺陷,或者耗時無數(shù)。相反,不同的測量方式意在復(fù)制正典這個觀念的多重位面:國家文化(DNB)以一種方式下定義,國際學(xué)術(shù)界(MLA)的定義有所不同;正典可以看作是一系列人物(DNB和MLA),或是文本集(博士列表)。具體的選擇依然可疑——當然了!——但我們遵循的標準多樣、明確、可測量。這就是新意。
我們也認識到,小說場域的其他特性(feature)也可以進入等式。例如,雷文和加賽德在自己編輯的目錄中列出了1770年到1830年間在英倫三島重印過或者譯成法語和德語的小說;將來的研究也可以設(shè)想類似的數(shù)據(jù)——從印數(shù)(print run)到流通圖書館存本數(shù)及其他。這種情況下,標準也是多樣、明確且可測量的,但和DNB、MLA有較大差異。重印和翻譯測量的是小說通過文學(xué)市場機制對“普通”讀者的吸引力,DNB和MLA則聚焦“專業(yè)”讀者和高等教育機構(gòu)。一個測量的是小說的“流行”,另一個測量的是其“聲望”。*流行度測自19世紀數(shù)據(jù)而聲望度來自20世紀的資料,這自然是個問題。20世紀研究在這方面要更好一些:例如在《成為你自己:接受的來生》(“Becoming Yourself: the Afterlife of Reception”)(文學(xué)實驗室手冊3,2011年)一文中,艾德·芬(Ed Finn)將美國文學(xué)場域中當代作家的地位做成圖表,使用了兩個范疇——“消費”和“對話”,二者都屬于同一時間框架:“消費”來源于亞馬遜網(wǎng)站(amazon.com)的“一起購買”(also bought)數(shù)據(jù),“對話”來自當代評論。有趣的是,“消費”和“對話”同我們的“流行”和“聲望”比較一致;阿爾吉-休伊特和麥克格爾討論的6個“正典”也是一方面圍繞著市場的成功,另一方面圍繞著更“合格”的文化選擇。如果后續(xù)研究嘗試糾正19世紀和20世紀數(shù)據(jù)的偏差,可以擴大聲望指標,納入學(xué)校課本和文集(就像 Martine Jey在法國做的那樣)、獎項[詹姆斯·英格利士,《聲望經(jīng)濟學(xué)》(The Economy of Prestige)]、18世紀和19世紀期刊評論,或者早期小說集,例如巴包德(Barbauld’s)、巴蘭坦(Ballantyne’s)和本特利(Bentley’s)小說集。不過,當然了,那些文集和評論也不能確定應(yīng)該被看作聲望指標,而不僅僅是小說市場發(fā)展中的小小齒輪;在最近一篇有趣的論文中,邁克爾·蓋默(Michael Gamer)說明了兩種可能性,表達為既有進正典的野心,也在商業(yè)市場競爭。(見“A Select Collection: Barbauld, Scott, and the Rise of the (Reprinted) Novel”, in Jillian Heydt-Stevenson and Charlotte Sussman, eds, Recognizing the Romantic Novel, Liverpool 2008.)威廉·圣克萊爾(William St Clair)則對評論的作用表達了毫不含糊的懷疑(“大致上,不論當時還是后世的作家看起來都夸大了評論的影響……我在評論、聲譽和銷量之間看不到什么聯(lián)系”),他也質(zhì)疑了19世紀早期小說聲望的概念:“就浪漫主義時期小說而言,當時并沒有公認的正典。實際上,在大多數(shù)小說都匿名發(fā)表的時代,整個有關(guān)正典的觀念沒什么意義。有一位作者,‘《威弗萊》的作者’,主宰了時代,但直到19世紀20年代中期大家才知道作者是著名詩人沃爾特·司各特爵士。”(見William St Clair, The Reading Nation in the Romantic Period, Cambridge 2004, p. 189.)另一方面,泰德·安德伍德(Ted Underwood)和喬丹·賽勒斯(Jordan Sellers)最近發(fā)表文章《文學(xué)標準變得有多快?》(“How Quickly Do Literary Standards Change?”),令人信服地提出評論與聲譽之間確實存在關(guān)系。(見http://figshare.com/articles/How_Quickly_Do_Literary_Standards_Change_/1418394.)安德伍德和賽勒斯研究詩歌而非小說,從1820年開始調(diào)查,但圣克萊爾的書和我們自己的語料庫到那時多少已經(jīng)終結(jié);目標和時間框架間的不匹配太多,無法直接比較。但我們慢慢接近了可以成功對比和整合獨立研究中各種證據(jù)的時刻。
流行和聲望。項目研究帶著這對概念進入和布爾迪厄開創(chuàng)性的法國文學(xué)場域圖表相同的地帶(圖3.1)。將流行數(shù)據(jù)放在橫軸(經(jīng)濟效益高/低),聲望數(shù)據(jù)沿著縱軸(神圣化高/低),就能提供一幅布爾迪厄圖表的“英國”版本。目前僅僅涵蓋了一種文學(xué)類型和數(shù)十年范圍;但到此時,實證的(empirical)文學(xué)場域繪圖法不再是白日夢(圖3.2)。
在圖3.2中,所有數(shù)字都被沃爾特·司各特不可思議的分數(shù)比下去了:只有兩位小說家在聲望軸上略微高過他(歌德和奧斯汀),而論流行,他一騎絕塵。流行軸上緊隨其后的作家托馬斯·戴(Thomas Day)是盧梭式暢銷書《桑德福和莫頓的歷史》(TheHistoryofSandfordandMerton,1789)的作者,在司各特下7個標準方差。*既然我們不是在測算印數(shù),這個表格實際上低估了司各特的流行度:雖然大多數(shù)同時代小說的第一次印數(shù)都是1000本,但前3部《威弗萊》小說的起始印數(shù)分別是6000、8000和10,000本。不過,一旦把“《威弗萊》的作者”不合比例的結(jié)果從圖表中移除,英國小說的三分格局就十分清楚了(圖3.3)。
我們從靠近水平軸的那一組開始看:流行分值高的作家——均值以上5、8、10、13個標準方差——聲望值卻相當?shù)停炼嘁粌蓚€標準方差,通常只有一個或更少。包括麥肯齊(MacKenzie)的感傷作品《多情的人》(ManofFeeling),以及戴的教育性暢銷書;常帶感傷情緒的哥特作品:拉德克里夫(Radcliffe)、里弗(Reeve)、羅奇(Roch)、赫爾默(Helme)、馬丘林(Maturin);雅各賓(Jacobin)及反雅各賓(anti-Jacobin)小說:夏洛特·斯密斯(Charlotte Smith)、歐佩(Opi);民族傳奇(national tales):埃齊沃思(Edgeworth)、摩根(Morgan);以及歷史小說的新霸權(quán)形式:高爾特(Galt)、讓利斯(Genlis)、賀拉斯·史密斯(Horace Smith)、波特(Porter)、庫珀(Cooper)。在所有文類的意義上說,可稱之為類型空間。“這部”小說就像擁有各種獨特形式的家族般展開,其易于辨認的習(xí)俗(conventions)鋪平了通往市場成功之路。《威弗萊》開頭一章全是各種頭銜典故,就是此種情況的典型癥狀。
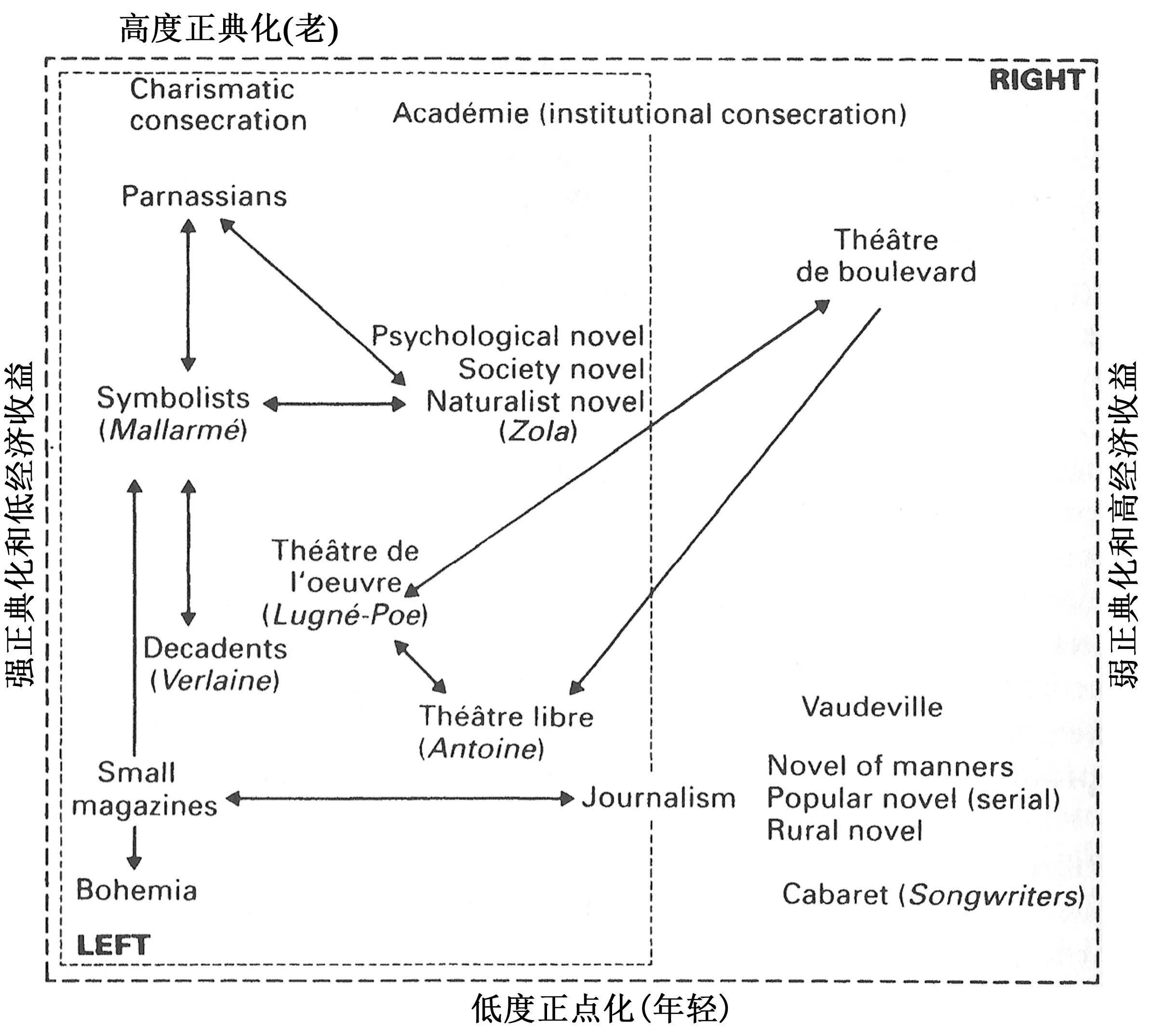
圖3.1 19世紀末期的法國文學(xué)場域布爾迪厄的文學(xué)場域圖雖然含義豐富,但沒有為文學(xué)類型和運動的具體位置提供實證證據(jù)。盡管他的圖表優(yōu)雅且影響廣泛,卻一直沒有成為真正的研究工具而被其他學(xué)者復(fù)制和使用,原因可能就在于圖表缺乏明顯且可測量的標準。圖中難以置信的分布規(guī)律迥異于圖3.2和3.3以及布爾迪厄自己的區(qū)分圖表,可能這規(guī)律性本身就是圖表以思辨為基礎(chǔ)的結(jié)果。Pierre Bourdieu, The Rules of Art: Genesis and Structure of the Literary Field, 1992, Stanford 1996, p.122.
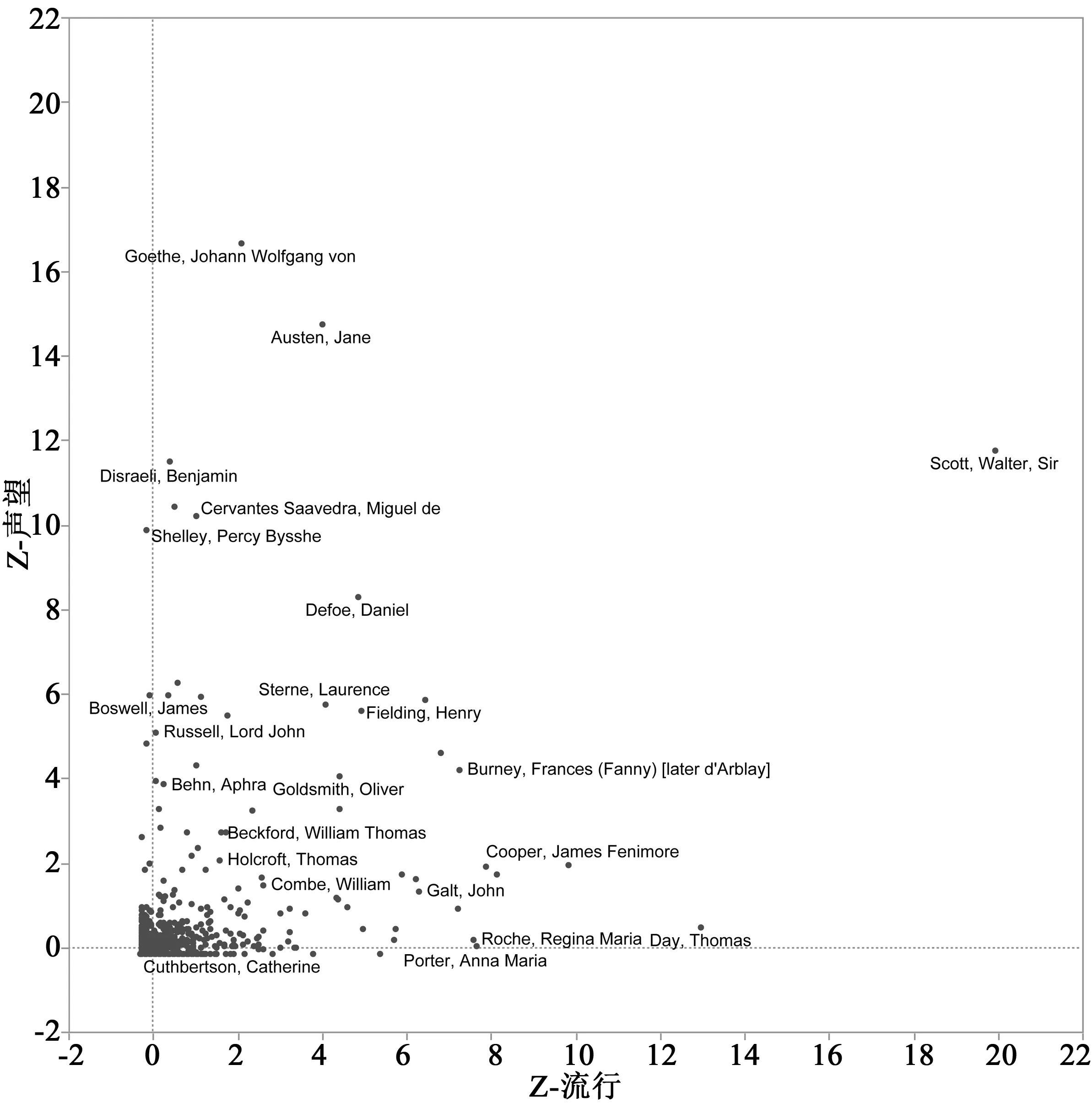
圖3.2 英國小說場域,1770—1830流行軸結(jié)果的基礎(chǔ)是重印數(shù)(在英倫三島)和翻譯數(shù)(譯為法語和德語);聲望軸結(jié)果的基礎(chǔ)是MLA書目中作為“基本科目作家”被提及的次數(shù)以及DNB條目的長度。作家的位置取決于他們在場域均值以上標準方差的數(shù)量,例如約翰·高爾特(John Galt)在流行軸均值以上7.5個標準方差,聲望軸均值以上1個標準方差;另一個極端是波西·雪萊(Percy Shelley),他位于聲望均值以上10個標準方差,卻略低于場域的流行均值。
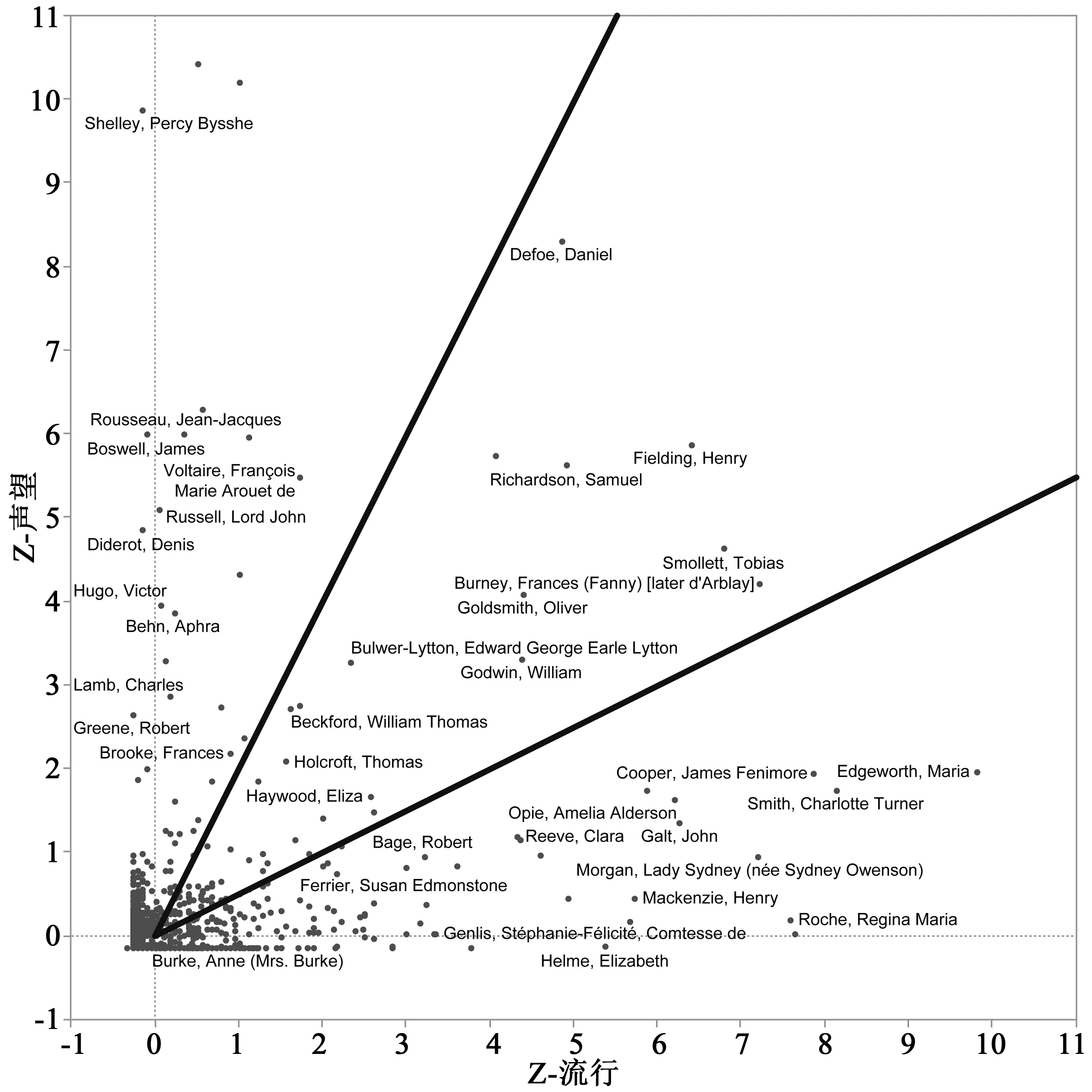
圖3.3 英國小說場域的三個區(qū)域,1770—1830 圖中三個區(qū)域表現(xiàn)了流行和聲望之間的多變關(guān)系。靠近縱軸的區(qū)域,其聲望分值至少是流行分值的兩倍;靠近橫軸的區(qū)域是其鏡像,流行值至少是聲望值的兩倍;中央?yún)^(qū)域兩套測量值趨于平衡。 目前,文學(xué)實驗室正在寬得多的時間范圍內(nèi)研究流行與聲望,項目由J.D.·波特(J.D.Porter)領(lǐng)導(dǎo)。數(shù)據(jù)由算法和米卡·西格爾(Micah Siegel)帶領(lǐng)的本科研究者同時收集。
從這一區(qū)域“朝上”移動到圖表中央,就進入了非常困難的領(lǐng)域。如果誰能理由充分地直接說:“這里就是正典”,那必然如此了:笛福(Defoe)、理查森(Richardson)、菲爾丁(Fielding)、斯特恩(Sterne)、戈德斯密(Goldsmith)、斯摩萊特(Smollett)、伯尼(Burney)、戈德溫……都聚集在完美平衡的區(qū)域里(比流行均值高4—7個標準方差,比聲望均值高3—8個標準方差),在這里,公式化小說的廣大讀者和高雅文化的認可無縫連接。看著這片中央?yún)^(qū)域,你就“看到”了正典形成的過程,即兩種同時發(fā)生的過程的結(jié)合:流行值隨著時間過去沿著水平軸緩慢縮水——在這方面,大多數(shù)18世紀的巨人都遠遠低于羅奇、波特、夏洛特·斯密斯和歐佩)——但聲望值則沿著縱軸上升。*在流行度縮減方面,奧斯汀及其同代人提供了完美的案例研究:如圖3.2所示,大約25位作者(其中三分之一來自18世紀)在圖表覆蓋的60年中比奧斯汀更流行。等19世紀小說目錄更可靠時,我們就能看到一兩代之后有多少人依然比她流行(19世紀30年代和40年代的初始結(jié)果顯示:除了司各特,再無旁人)。很明顯,成為經(jīng)典作家的道路不止一條,*司各特一夜成名且廣受歡迎,這與奧斯汀慢得多的節(jié)奏不同。另外一些作家,因為作品的最初讀者[卡羅爾(Carroll)]或類型[拉德克里夫,多伊爾(Doyle)]的緣故,長期受限于某種定位,地位曖昧,司各特跟他們也不同。當然了,還有一切正典通論的復(fù)仇女神——《白鯨》(Moby Dick)。但圖表的主要內(nèi)涵在于正典并非布爾迪厄的自治文學(xué)場域公式的“經(jīng)濟世界的調(diào)轉(zhuǎn)”(the economic world reversed);正典——至少這個正典——作者最初成功后過了兩三代人,其商業(yè)出版商依然期待盈利。聲望這方面也不見得與流行度相對立;此處看來反而是從流行中獲得的聲望,從經(jīng)濟回報中“提取”出更無形但更持久的事物。*雖然我們的結(jié)果和布爾迪厄的法國文學(xué)場域理念完全不同,但也未必證明了他論點有誤,我們只研究了小說(完全沒有涉及詩歌、戲劇、雜志等),所研究的國家和時代也不同。說實話,我們需要許多不同文化和時代的實證的文學(xué)場域地圖(復(fù)數(shù)),才能讓“文學(xué)場域”(單數(shù))成為可靠的歷史概念。
圖3.3“高聲望”區(qū)域情況則不同,明顯由外國作家(塞萬提斯、伏爾泰、狄德羅、盧梭、歌德、席勒、雨果……)主宰,或者那些雖然寫過至少一部甚至好幾部小說,卻很難被看作“職業(yè)”小說家的英國作者。其中有百科全書式的人物塞繆爾·約翰遜(Samuel Johnson)以及差不多同樣多才多藝的賀拉斯·沃波爾(Horace Walpole);詩人,例如波西·雪萊(Percy Shelley),以及稍往下一些的托馬斯·“安那克里昂”·摩爾(Thomas “Anacreon” Moor)以及詹姆斯·霍格(James Hogg);身兼小說家及政治家的迪斯累利(Disraeli)和純粹的政治家羅素爵士(Lord Russell),他在1822年出版了不可思議的《阿羅卡的修女》(NunofArrouca);散文家,如詹姆斯·鮑斯韋爾(James Boswell)和查爾斯·蘭姆(Charles Lamb)。聲望值更低一些的區(qū)域有音樂家兼劇作家查爾斯·迪布丁(Charles Dibdin),劇作家兼演員夏洛特·西波爾·查爾凱(Charlotte Cibber Chalke),經(jīng)濟學(xué)家兼游記作家亞瑟·楊(Aurhur Young)。在少數(shù)純粹的小說家當中,政治的影響特別有力:除了羅素和迪斯累利,還有《千禧圣殿》(MillenniumHall)和《戴斯蒙》(Desmond)的作者才女莎拉·司各特(Sarah Scott),瑪麗·雪萊(Mary Shelley)和漢娜·莫爾(Hannah More)——她的小說《卡勒布尋妻記》(CoelebsinSearchofaWife)據(jù)說是維多利亞女王唯一完全贊同的小說。
有了聲望/流行圖,本項目的第一部分自然得出結(jié)論。和最初的意向相反,我們遠遠沒有形成檔案,*在圖3.2-3.3中,其分界點是場域平均值以上2或3個標準方差,其中所有高聲望值作者和位于中間位置的作者,以及大約一半位于高流行度位置的作者都能看成正典作者。如果下降得“更低”,場域的三分格局還能存在一會兒,然后就消失了。接下來發(fā)生了什么,這是很令人著迷的問題——等著下一個研究。但對正典概念的操作化(operationalization)既令人驚訝也讓人滿意:它將正典概念落到實處,將其還原為更簡單的流行和聲望因素——或者更直白地說,市場和學(xué)校的因素。這些新坐標中,正典依然可見,但失去了概念自治(conceptual autonomy),成了相反力量遭遇的偶然結(jié)果。如果想要更多地了解正典,這些力量值得進一步研究。*或者更精確地說:如果想把正典的概念分解為兩個根本因素:流行度和聲譽度。這里,值得比較一下本項目最初的認知論選擇,以及阿爾吉-休伊特和麥克格爾的《正典與語料庫之間》(“Between Canon and Corpus”)。主要區(qū)別不在于研究文本(《正典與語料庫之間》)還是作者(正典/檔案)——這一點很容易理解——而在于其中一個分析建立在網(wǎng)絡(luò)基礎(chǔ)上,而另一個建立在笛卡爾式的圖表基礎(chǔ)上。網(wǎng)絡(luò)在調(diào)研獨立的節(jié)點(圖3中的超級正典集群,《憤怒的葡萄》突出的中心地位,暢銷書和其他組別的分離)之間的關(guān)系方面更勝一籌,但無法將節(jié)點同網(wǎng)絡(luò)外的任何事物聯(lián)系起來。而笛卡爾式圖表,就本身而言,將“外界”嵌入了自己的坐標(就像這里的流行度和聲望度),但不可避免地放松了數(shù)據(jù)點之間的關(guān)系(在圖表中不存在網(wǎng)絡(luò)邊緣和集群測量的等價物)。顯然,這并不是說哪種策略“優(yōu)于”另一種,而是不同研究項目針對系統(tǒng)不同方面展開調(diào)查,并選擇了相應(yīng)的分析方法。未來的研究可以輕易地將印數(shù)和流通圖書館存本數(shù)加入流行指標,將課本選段或者非虛構(gòu)檔案中的記載加入聲望指標。*不用說,有些測量可能不連續(xù)、難以獲得(例如印數(shù)),而其他數(shù)據(jù)(例如課本)測量則可能要等晚得多的時候才會開始。不過,如果文學(xué)場域的觀念確定有助于理解不同時代和國家,那么依靠迥然不同的歷史指標也就不可避免;不要指望——空想的——資料同質(zhì)性,我們應(yīng)該學(xué)著讓異質(zhì)的數(shù)據(jù)在概念上可以互相比較。每增加一項,就能更好地理解正典的復(fù)合性——對其歷史本質(zhì)也會更了解。1770—1830年間的正典(我們猜測之后七八十年內(nèi)也是一樣)是歐洲資產(chǎn)階級幸福時代的產(chǎn)物,當時,必不可少的成功和教育還被看作是互相兼容的,對于資產(chǎn)階級這個歷史上首次在學(xué)校和市場都如魚得水的統(tǒng)治階級也是合適的。讓這些19世紀正典的雙重本質(zhì)直覺“可見”,就是這些初始部分的成果。*《正典與語料庫之間》顯示從那時起變化很大:在20世紀,正典都被描述為“即使不是藝術(shù)和商業(yè)價值間的系統(tǒng)性矛盾,也是系統(tǒng)性差異”。圖3.3的“正典”區(qū)域卻恰恰缺乏這種差異/矛盾。
二、形態(tài)學(xué)特征(Morphological Features)
4.測量冗余(Measuring redundancy )
以上圖表與布爾迪厄的圖表有諸多不同,但與他的主要方法論前提亦有相同之處:其基礎(chǔ)是社會學(xué)而非文學(xué)的。*“我建議,所謂正典形成的問題”,約翰·基洛利(John Guillory)以同樣的風(fēng)格寫道,“最好理解為文化資本的構(gòu)成和分配問題,或者更具體而言,是如何得到文學(xué)生產(chǎn)和消費手段的問題。” John Guillory, Cultural Capital: The Problem of Literary Canon Formation, Chicago 1995, p. ix.要制作圖3.3,不需要翻開哪怕一本小說。但作為文學(xué)史家,我們想要翻開小說,看其社會命運——流行,聲望,都有或都無……——是否與其形態(tài)學(xué)特征有關(guān)聯(lián)。因此,在制作文學(xué)場域圖表時,我們也關(guān)注了查德威克-希利以及更大檔案樣本的內(nèi)部結(jié)構(gòu)。第一步包括測量語料庫的冗余量和信息量。有個廣為接受的觀點認為讀者更喜歡信息豐富的文本,不喜歡冗長文本,所以前者會持續(xù)重印而后者注定消亡,我們想要驗證這個觀點。馬克·阿爾吉-休伊特從信息論里得到線索,改進了香農(nóng)的信息負荷測量(Shannon’s measure of information load),通過評估詞對詞轉(zhuǎn)換(word-to-word transition)的可預(yù)見性來確定文本的信息內(nèi)容,并在給定可能的轉(zhuǎn)換范圍后,以此測量了“二階冗余”(second order redundancy)(單詞層面上的可預(yù)測性)。 例如,既然“the”跟在“of”后面的情況遠遠多于“no”在“of”后面,那么“of no”這個組合就難以預(yù)料得多,因此比“of the”更有信息量。*整個手冊中,我們幾乎是交替使用“冗余”(redundancy)和“重復(fù)”(repetition),將其與“信息”和“多樣性”對照;雖然這是簡單化了,但我們不認為會影響這一研究的水準,也不會影響研究結(jié)果的類型。類似的,信息與冗余間的關(guān)系市場被說成是“熵”;我們選擇了不同的定義,以盡量能夠比較這一研究的不同方面。圖4.1和4.2總結(jié)了阿爾吉-休伊特的研究。
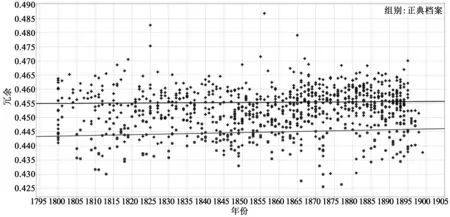
圖4.1 測量冗余度,1800—1900上面的十字表示檔案小說,下面的十字表示正典小說。
圖4.2尤為令人震驚:查德威克-希利文集四分之三的內(nèi)容要比檔案四分之三內(nèi)容更少冗余,這是比預(yù)計中強得多的分離(separation)。不過我們并不完全滿意。對比很清楚,但只是確認了常見觀點:被遺忘的作者語言更冗余;如果一直沒人讀他們的作品,那說明他們不值得讀。反過來說,我們依然喜歡讀奧斯汀,因為她是信息的典范,細看圖4.3就完全清楚。
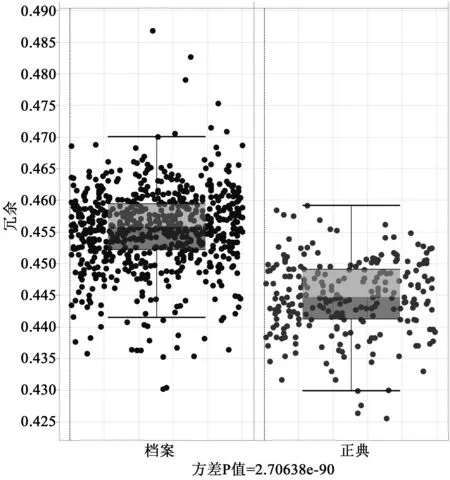
圖4.2 19世紀的冗余度:綜合圖本圖將圖4.1里的數(shù)據(jù)合為正典和檔案兩個子集。每個“方框”包括本組的兩個核心四分位值,分界線表示該組的中位值;從“方框”里冒出來的“胡須”代表兩個極端四分位值,外圍由圓點表示。
圖4.3 19世紀早期的極低冗余一個字也不重復(fù)的小說,其冗余為0而信息度100%——但這“信息”沒有價值,因為它會迅速變得無法理解。意義總是依靠重復(fù)和新意相結(jié)合:因此這些圖表內(nèi)的數(shù)字會在相當狹窄的區(qū)域內(nèi)震蕩。但這個區(qū)域內(nèi)的區(qū)別持久而顯著,這張對圖4.1左下角區(qū)域的放大圖能夠說明情況。
并不令人興奮,只是確認了一個常見觀點。*這已是第二次了:在圖1.2中,正典通常領(lǐng)先檔案15到20年,似乎“證明了”另一公認觀點:偉大作家開路,其他人跟上。接著,第二個問題。雖然阿爾吉-休伊特使冗余概念變得可操作(operationalized),產(chǎn)生了令人震驚的量化結(jié)果,但仍然不清楚我們能夠如何拆解全部數(shù)值、如何看待結(jié)果,明確哪些具體的詞組持續(xù)重現(xiàn),或從未重現(xiàn)。我們成功地測量了冗余,但還不能真正分析它:從項目開始時起,定量測量和定性闡釋之間的相互作用(interplay)就是研究工作的一個常量,而現(xiàn)在它出現(xiàn)了令人不安的背離(departure)。此處統(tǒng)計學(xué)上的顯著性似乎無法得出評論上的意義:從語料庫的每本小說中都抽出了100個最常見的二元詞組(bigram),形成了包含超過10萬個單元的電子表格“文本”,不可能“讀取”(圖4.4)。有個更技術(shù)性的方法:追蹤最常見結(jié)構(gòu)的衰減曲線,但同樣得不到結(jié)論。很常見的二元詞組(“there is”, “I am”, “to the”)在所有文本中的頻率非常相似,只有在曲線末端才有細微的變化痕跡。另外,每本小說的二元語言模型如此之多,其效果是通過數(shù)量巨大而極其微小的變化顯示出來的:例如,在66,500個詞的較短文本中,有66,499個二元詞組,其中約40,000個從未重復(fù)出現(xiàn)。雖然兩個文本共享的詞語相當多——至少3000到4000個——但共享的二元詞組往往少于1000個,不足以得到可靠的比較分析。
我們似乎給自己創(chuàng)造了個本地產(chǎn)的(home-grown)測不準原理:冗余測量得越精確,就越難以確定冗余到底“在哪里”。冗余運作的范圍無孔不入,看起來對書籍的命運有決定性作用。但整個過程發(fā)生在有意識閱讀層面下很深的地方,基本看不見。在未來,甚至有可能在比較近的將來,這個問題可以通過實驗心理學(xué)解決;同時,我們轉(zhuǎn)向詞匯變化的標準語言學(xué)測量方法,也就是類符/形符比(type token ratio, TTR)。*這是《朗文英語口語與筆語語法》(Longman Grammar of Written and Spoken English)定義的類符/形符比:“不同詞形或詞的類型數(shù)目同詞量或詞次之間的關(guān)系,稱為類符/形符比(或TTR)。類符/形符比是一個百分比,等于類型/詞次×100。” 見Biber, Johansson, Leech, Conrad, Finegan, Longman Grammar of Spoken and Written English, Harlow 1999, pp. 52-3.《朗文語法》研究了四種語域(對話、學(xué)術(shù)文章、小說、新聞)中的類符/形符比變化和三個樣本長度(100字、1000字、10,000字)。100字的片段,結(jié)果如下:對話63;學(xué)術(shù)文章70,小說73,新聞75。1000字的片段:對話30、學(xué)術(shù)文章40、小說46、新聞50。10,000字的片段:對話13、學(xué)術(shù)文章19、小說22、新聞28。注意,語域間的區(qū)別隨著片段長度的增加而急劇增強。到了10,000字,新聞的類符/形符比超過對話一倍以上,而在100字片段中僅僅高16%。我們選擇了10,000字的片段,這個長度既足以采集大量變化,也足夠短,可以直接分析。我們推斷,文本冗余越低,多樣性必然越高:凸面對凹面。我們會得到一幅圖,正好是圖4.2調(diào)轉(zhuǎn)。因此我們開始計算,結(jié)果就是圖4.5。
圖4.4 解讀二元詞組:數(shù)據(jù)的0.00003%圖4.1-4.2數(shù)據(jù)計算的電子表格的一部分。雖然二元詞組本身能完全確認,但幾乎不可能“闡釋”其意義,除非以統(tǒng)計學(xué)方式。這方面,瓦爾塞和阿爾吉-休伊特認為,二元詞組可與布羅代爾的“人口進程”和“利率變化”相比:都是無法在段落水平上理解的現(xiàn)象,而我們通常都是在這個層面進行解讀。
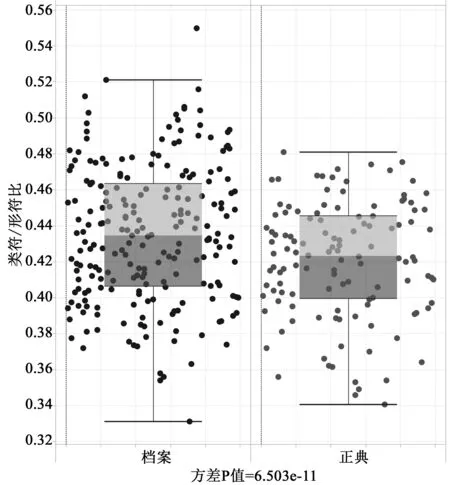
圖4.5 測量多樣性:類符/形符比綜合圖雖然此處兩個子集的區(qū)別比圖4.2要小得多,結(jié)果卻更驚人:4.2完全印證了我們對正典和檔案的預(yù)期,這個表卻完全否定了預(yù)期:正典的詞匯量并不比檔案更多樣,反倒少得多。(第5節(jié)第1個腳注說明了萊恩·霍伊舍確定類符/形符比的程序)。
圖4.2和圖4.5并排,產(chǎn)生如下悖論:從詞對(word pairs)角度查看全文(entire text),正典的重復(fù)遠遠低于檔案(因此也更多樣);從單個詞(single words)的角度查看一千個詞,則正典的多樣性低于檔案(因此也更重復(fù))。從現(xiàn)象本身來說,文本規(guī)模不同,表現(xiàn)也不同,這并不意外:之前的兩個手冊(“Style at the Scale of the Sentence”和“On Paragraphs”)恰好關(guān)注了這個問題。但那些案例中,不同的規(guī)模和完全不同的特征相聯(lián)系:句子同風(fēng)格,段落同主題(themes),諸如此類。而此處所測量的特征則關(guān)系緊密。從兩個詞到1000個,測量結(jié)果是怎么自己調(diào)轉(zhuǎn)的?此處的“怎么”表達的就是本意,并非絕望的呼號:具體而言,怎樣的文本機制能夠把第一種結(jié)果轉(zhuǎn)為第二種?
阿爾吉-休伊特處理這個問題的方式是把所有的詞“翻譯”成詞性,這樣就以二元詞組的范疇而不是獨立單元重新表示冗余。例如“clever little”和“first cruel”,都變成了“形容詞—形容詞”,而“a condition”和“the kitchen”都成了“限定詞-名詞”,等等。用“語法冗余”重新計算,就可能確定哪些二元詞組在正典中最突出,哪些在檔案中最突出(圖4.6—4.7)。*這部分工作中,阿爾吉—休伊特使用了斯坦福的詞性標志器;括號里的縮寫(IN_NNP等)則是賓夕法尼亞大學(xué)Treebank項目使用的那些((https://www.cis.upenn.edu/~treebank)。
這一次,這兩個子語料庫顯現(xiàn)出重心迥異:檔案由名詞主導(dǎo),正典則分布著大量功能詞(連詞、限定詞、介詞)。檔案對頭銜津津樂道(count Goldstein, uncle Gerard),對地點和人物吹毛求疵(in Ireland, to Shelley),對專有名詞則通常很寬容(Hector’s lodgings, Shelburne upon),終于提供了解釋其高冗余的線索:“count Goldstein”和“Shelburne upon”可能不常出現(xiàn)在小說中,但如果出現(xiàn),這兩個詞可能會再次同時出現(xiàn),增加了文本的冗余;“iron will”和“color tints”等附加名詞這種結(jié)構(gòu)也是一樣。這并沒有為所有問題都提供答案,但這是個開始。接著,為了解決悖論的另一面,我們轉(zhuǎn)向了類符/形符比。

圖4.6 最突出的語法二元詞組:檔案

圖4.7 最突出的語法二元詞組:正典
5.“但我不能走開”(“But I couldn’t go away”)
要使用類符/形符比,第一件事是確定適于本語料庫的分析模式:庫中大多數(shù)小說重印于一兩個世紀前,難以光學(xué)識別,很可能令所有后續(xù)計算無效。在項目早期階段,萊恩·霍伊舍最早將大家的注意力引到類符/形符比上,他也找到了辦法,能同樣可靠地測量質(zhì)量參差不齊的文本。*霍伊舍首先創(chuàng)建了一個大型的小說英語詞典——232,845個不同詞匯——又將所有文本裁剪為1000個“字典詞匯”片段。(實際的片段將在1000到1500個字的區(qū)間內(nèi),具體字數(shù)取決于其中有多少個“非字典”詞匯——OCR,一次頻詞/hapax legomena等)。既然形符的數(shù)量固定在1000個,那么,區(qū)分每個1000字片段的類符數(shù)量就產(chǎn)生了以片段為基礎(chǔ)的分數(shù),其平均值能給出文本的類符/形符比。函數(shù)用兩個參數(shù)寫出來:“語言切片”(slice_len)[片段長度(設(shè)為1000)]和“強制英文”(force English)[是否包括大型英語詞典中未收錄的詞(設(shè)為False)]。設(shè)置“強制英文”,也就是排除所有非“英語”詞匯,這個參數(shù)背后的邏輯在于,如果沒有這個參數(shù),由于壞OCR,檔案將會有更高的類符/形符比。反過來,對強制英語的擔(dān)心在于,同樣的壞OCR會產(chǎn)生更低的類符/形符比:如果片段必須超過1500個“真正的”詞匯以便發(fā)現(xiàn)1000個英語詞匯,那么就可能偏向更短、更容易拼出的OCR詞匯,同時也是語言中最常見的詞匯,這樣就會降低類符/形符比。在這個項目中,這兩種不想要的結(jié)果似乎相互抵消了。一旦結(jié)果進來,我們首先注意低類符/形符比,看它具體的重復(fù)類別如何同阿爾吉-休伊特所計算的冗余比較。我們從圖4.6得知,低詞匯變化通常與正典文本相關(guān);確實,查德威克-希利文集整個語料庫的頻率大概在20%,而類符/形符比最低的500條片段中,頻率升到50%(盡管最高的500條也只有3.2)。得分最低的50個文本中,約一半來自查德威克-希利,其中有幾本兒童書籍,包括《愛麗絲鏡中奇遇記》(Alice,ThroughtheLookingGlass)、《水孩子》(TheWaterBabies)、《黑美人》(BlackBeauty)、《小爵爺方特洛伊》(LittleLordFauntleroy)、《小島之夜的娛樂》(Island’sNight’sEntertainments)等;10本特羅洛普(Trollope)的小說,包括《巴塞特的最后紀事》(TheLastChronicleofBarset)、《愛爾蘭人菲尼阿斯·芬》(PhineasFinntheIrishMember)、《你能原諒她嗎?》(CanyouForgiveHer)、《尤斯達斯的鉆石》(TheEustaceDiamonds)等;以及2本愛爾蘭小說:埃奇沃思(Edgeworth)的《拉特倫特古堡》(CastleRackrent)和塞繆爾·弗格森(Samuel Ferguson)的《湯姆神父與教皇》(FatherTomandthePope),《缺席者》(TheAbsentee)則相距不遠。這么混雜的書目并不特別能代表正典(不管這個詞是什么意思);更顯著的發(fā)現(xiàn)似乎是查德威克—希利的數(shù)值在整個世紀中一直很低(圖5.1),這趨勢還包括一些最偉大的19世紀文體家:奧斯汀所有作品都低于語料庫均值(《勸導(dǎo)》、《理智與情感》、《曼斯菲爾德公園》位于最低的20%);狄更斯(Dickens)所有作品低于均值(《小杜麗》、《雙城記》、《大衛(wèi)·科波菲爾》、《我們共同的朋友》、《荒涼山莊》和《遠大前程》位于最低的20%);喬治·艾略特(George Eliot)所有作品低于均值——而《亞當·貝德》有一段,其類符/形符比是整個世紀中最低的。
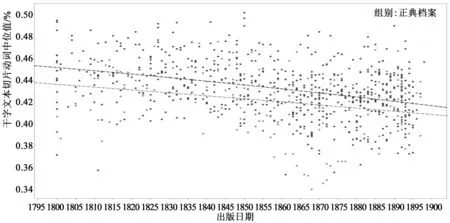
圖5.1 類符/形符比,1800—1900*上面的線條顯示的是檔案,下面的線條顯示的是正典。1860—1880年間,兒童讀物較為明顯地趨向低類符/形符比;但一般而言,正典和檔案的類符/形符比在整個19世紀都相當穩(wěn)定。
《亞當·貝德》得到這個結(jié)果比較奇怪,因為本書包含了艾略特對荷蘭繪畫的著名反思:一篇關(guān)于審美精確與多變的宣言,寫得特別精確而多變(圖5.2)。

圖5.2 “這稀少而珍貴的真實性特質(zhì)”
這一段落頭100個單詞的類符/形符比是79:比《朗文語法》討論的任何篇章都高,不論語域。但在小說的后面,艾略特的風(fēng)格轉(zhuǎn)向另一個極端(圖5.3)。

圖5.3 19世紀最重復(fù)的段落:《亞當·貝德》中海蒂的懺悔井號表示特定段落中有一個單詞被重復(fù),星號表示用于計算的“詞典”之外的單詞。這一段以及其他段落有些怪異之處,是斯坦福的解析器造成的,例如它會將否定詞縮寫,比如“couldn’t”末尾的“n’t”,當作單獨的詞。
艾略特的這個段落包括海蒂(Hetty)對黛娜(Dinah)的懺悔:回憶起在林中丟棄孩子,等待“它”死去(用她自己用的代詞)。但“等待”是個錯誤的詞(圖5.4)。

圖5.4 “但是我一直都能聽見它哭”
語法上來說,這些句子最引人注目的地方在于海蒂做主語的屈折動詞形式(inflected verb forms)潮水般涌來: I made haste…I could not hear… I got out… I was held fast… I couldn’t go away…I wanted… I sat… I was… I had… I couldn’t… 在敘事分析中,動詞形式通常被看作“動作”的指標——這很好理解。此處,語法和句法間存在刺耳的不和諧聲,這些動詞卻象征著癱瘓(paralysis):海蒂絕望地想要“走開”,但是不能。就像她無法離開事件的物理環(huán)境,她也不能放棄描述這一事件的詞語。她無法忘記:這就是重復(fù)的來源。更好的說法是:她既不能忘記,也不能真正說出發(fā)生了什么。這是教科書般的“重復(fù)”與“消解”(working through)對立的例子,她一再反復(fù)地說著同樣的內(nèi)容,因為她無法讓自己說出真正重要的事:“死”這個詞從沒重復(fù),僅僅在章節(jié)末尾拐彎抹角、令人誤導(dǎo)的結(jié)構(gòu)里出現(xiàn)了一次。*“But it was morning, for it kept getting lighter, and I turned back the way I’d come. I couldn’t help it, Dinah; it was the baby’s crying made me go——and yet I was frightened to death. I thought that man in the smock-frock ‘ud see me and know I put the baby there.” 注意,“死”如何指涉海蒂而非她的孩子。
為何重復(fù)?因為重創(chuàng)(trauma)已經(jīng)發(fā)生,重復(fù)是用語言來表達這種創(chuàng)痛的很好的方法:囚禁于自己的話語,而話語神秘的力量解釋了為什么盡管艾略特?zé)釔鄯治鲂缘募毠?jié),卻能夠?qū)懗稣麄€世紀中最具重復(fù)性的段落。其次,海蒂的懺悔也揭示了類符/形符比在本質(zhì)上口語(oral)的成分。緊隨艾略特的兩段詞匯密度最低的片段也是懺悔:埃奇沃思《倦怠》(Ennui)中換嬰兒一段*“I thought, how happy he would be if he had such a fine babby as you; dear; and you was a fine babby to be sure; and then I thought, how happy it would be for you, if you was in the place of the little lord: and then it came into my head, just like a shot, where would be the harm to change you?”以及特羅洛普《巴塞特的最后紀事》中愛的懺悔。*“You are so good and so true, and so excellent,-- such a dear, dear, dear friend, that I will tell you everything, so that you may read my heart. I will tell you as I tell mamma,-- you and her and no one else;-- for you are the choice friend of my heart. I can not be your wife because of the love I bear for another man”.同樣的低密度范圍內(nèi)我們還找到了一些章節(jié),出自兒童故事(其敘事者通常栩栩如生),愛爾蘭小說(專長模仿講話),和特羅洛普的無數(shù)小資產(chǎn)階級簡短對白的例子。*“Do you think that I am in earnest?” “Yes, I think you are in earnest.” “And do you believe that I love you with all my heart and all my strength and all my soul?” “Oh, John!” “But do you?” “I think you love me.” “Think!”以及審判的場景:《理查德·費瑞弗爾的磨難》(TheOrdealofRichardFeverel)、《中洛錫安之心》(TheHeartofMid-Lothian)、威廉·斯卡吉爾(William Scargill)的《無人委托的律師故事集》(TalesofaBrieflessBarrister);意識形態(tài)的沖撞:《享樂主義者馬利烏斯》(MariustheEpicurean);“快樂共產(chǎn)主義”的狂喜愿景:瑪麗·克里斯蒂(Mary Christie)的《勞拉女士》(LadyLaura)*“All are not equally happy; all can not be equally happy. But there is a sort of communism possible in happiness. The unhappy have a claim upon the happy; the happy have a debt towards the unhappy.” “But how can one share one’s happiness with others? It seems to me impossible. It is what I have most wished to do, but I see no way in which it can be done.” “In one sense certainly you can not share your happiness, and you can not give it away. It is essentially your own, a development of your being, a part of yourself that you may not alienate.”;以及對金錢的長篇謾罵:托馬斯·彭伯頓(Thomas Pemberton)的《一個很老的問題》(AVeryOldQuestion)。*“Money!” she cried derisively.” Money! What is money to the trouble which has torn my heart ever since I have been married! What is money to those who thirst for love! I never wanted money; without money I was strong and happy; since I have had it I have been weak and miserable. Money broke down my poor father, and it was for money that Percy married, deceived, and has forsaken fine. Thank God that the wretched money has gone”有的角色因為想要懇切熱情而太過嘮叨(《愛瑪》),或是因為需要反復(fù)演練證據(jù),例如《德拉庫拉》(Dracula)中的范·海爾辛(Val Helsing)。阿里森(Alison,本文作者之一)和杰瑪(Gemma,本文作者之一)的結(jié)論是,評分最低的(很多都屬于正典)千字片段和《朗文語法》中的對話正好屬于同一個區(qū)間,這很難說是偶然:朗文區(qū)間內(nèi)均值30,我們的500個最低得分的片段均值在27—33之間。
我們轉(zhuǎn)向類符/形符比是希望能引導(dǎo)我們回到某種文本分析中,我們沒有失望:低分值抓住了敘事結(jié)構(gòu)的關(guān)鍵方面,示意創(chuàng)痛、強度和口頭形態(tài)。那么高分值呢?
6.“炮眼里震動的大口徑加農(nóng)炮”(“Embrasures bristling with wide-mouthed cannon”)
圖6.1顯示了語料庫中類符/形符比最高的10本小說;圖6.2是分值最高的篇章,摘自愛德華·霍克(Edward Hawker)的《亞瑟·蒙塔古,又名孤身泛海》(ArthurMontague,or,AnOnlySonatSea)。

圖6.1 高類符/形符比,或檔案的勝利
如果正典優(yōu)越的社會地位總是和語言上的優(yōu)越相關(guān)聯(lián),——1997年諾貝爾文學(xué)家得主達里奧·福寫過一部劇,名叫《工人認識300字,老板認識1000字,所以他是老板》——那么正典作家的語言應(yīng)該比被遺忘的作家更富變化。然而,根據(jù)類符/形符比測量的詞匯豐富性,情況正相反。 “全部審美語言就包含在對膚淺的根本性拒絕中,”布爾迪厄?qū)懙溃骸啊炙椎摹髌?……以勾引的手法引發(fā)反感和嫌惡。”*Pierre Bourdieu, Distinction. A social critique of the judgment of taste, 1979, Harvard UP, 1984, p. 486.膚淺,霍克的語言?勾引?要說起來,正好相反。這種粗俗/優(yōu)雅的二分法永遠無法解釋檔案和高類符/形符比之間的聯(lián)系。我們必須往別處看。

圖6.2 19世紀重復(fù)最少的篇章 亞瑟·霍克的風(fēng)景描寫,類符/形符比為60,遠超《朗文語法》報告的相同長度片段的分數(shù)(小說為46,新聞為50)。
我們在語料庫語言學(xué)(corpus linguistics)里找到一個答案,這一研究中經(jīng)常發(fā)生這種事。這一次是“語域”(register)這個概念:道格拉斯·比伯(Douglas Biber)和蘇珊·康納德(Susan Conrad)在《語域,類型和風(fēng)格》(Register,Genre,andStyle)中描述過的信息(message)的“交際目標和情景語境”(communicative purposes and situational contexts)。*Douglas Biber and Susan Conrad, Register, Genre, and Style, Cambridge UP 2009, p. 2.在語域研究中,口頭和書面存在根本對立,公認英語中后者的類符/形符比遠高于前者。如果檔案的詞匯比正典豐富,原因在于檔案比正典更傾向于“書面”語域(照我們在之前部分看到的,正典對于“口頭”傳統(tǒng)要自如得多)。并不是說檔案中高類符/形符比的小說里口語(oral)段落(對話、演說、感嘆,等等)比較少;杰瑪關(guān)于口語話語(colloquial discourse)進展的著作顯示,它們甚至可能包含更多此類段落。問題在于其“口語”(spoken)段落具有明顯的“書面”(written)特質(zhì)。簡·韋斯特(Jane West)的《環(huán)游》(Ringrove)一書中有許多從排版上看是“言語”(speech)的語言,但是經(jīng)常包含了正式的長篇大論,聽上去更接近書面專題報告而不是口頭交流。*此處有一例,是對拜倫誤用其詩歌天賦的評論:“There is a deep condensation of thought, an appropriateness of diction, an elegance of sentiment, and an original glow of poetical imagery; ever happy in illustrating objects, or deepening impressions;-- which so fascinate our fancy and bewilder our judgment, that we lose sight of the nature of the deeds he narrates, and the real character of the actors.”
語言學(xué)上的保守肯定是許多檔案作品具有“書面”特質(zhì)的一個原因。威廉·諾思(Willian North)的《偽裝者》(Impostor)里有一段——其類符/形符比差不多位于語料庫的前1%——對這一點表達得很好:
近年來,除了上述自詡的(soi-disant)時髦垃圾,還有一股對低俗生活、俚語和各種粗鄙詞語的強烈嗜好混進了我們的美文(belleslettres)。狄更斯和恩斯沃思(Ainsworth)領(lǐng)頭,大群人跟隨其后……讓我們努力重建純粹的古典品味吧。
讓我們努力重建……安德伍德(Underwood)和賽勒斯(Sellers)在對聲望和風(fēng)格的研究中發(fā)現(xiàn),許多無名的書籍,“位于[模型]名單最底部……是懷著鼓舞人心或勸人為善的目的的”。*Underwood and Sellers, p. 14.這里也是如此:口語語域常見的“俚語和粗鄙詞語”冒犯了“純粹的古典品味”,而圖6.1里面那群作者則予以反擊,“提升”話語的語調(diào),具有書面語一樣的正式和嚴肅:許多名詞,許多形容詞,盡量少的屈折動詞形式(圖6.3-6.4-6.5)。*名詞和形容詞的高頻率把我們帶回第四部分結(jié)尾討論過的“語法二元詞組”:”形容詞—形容詞”、“名詞—形容詞”詞組。把那些結(jié)果和這一部分出現(xiàn)的情況相結(jié)合,我們最終就能在二元詞組的層次解決高冗余文本的悖論,并在類符/形符比的層次上解決高多樣性文本的悖論。“count Goldstein”和“uncle Gerard”這樣的二元詞組的“貼標簽”功能以及 “iron will:”和“clever little”這樣喋喋不休的陳詞濫調(diào),很容易在小說中自我重復(fù),因而提高了在這個范圍內(nèi)測到的冗余度;但是,即使是平庸的作者也不太可能在1000個單詞的窗口中重復(fù)“clever little”,因而能保持較高的類符/形符比。正典文本中常見的“限定性名詞”或者“前置限定詞”二元詞組的情況則相反:“the”是英文中最常見的詞,不可避免地會在1000字片段中重復(fù)數(shù)十遍,因此降低了其詞匯多樣性;但是既然緊跟這個冠詞的名詞會很容易變化,二元詞組層次上冗余也就維持相對較低。
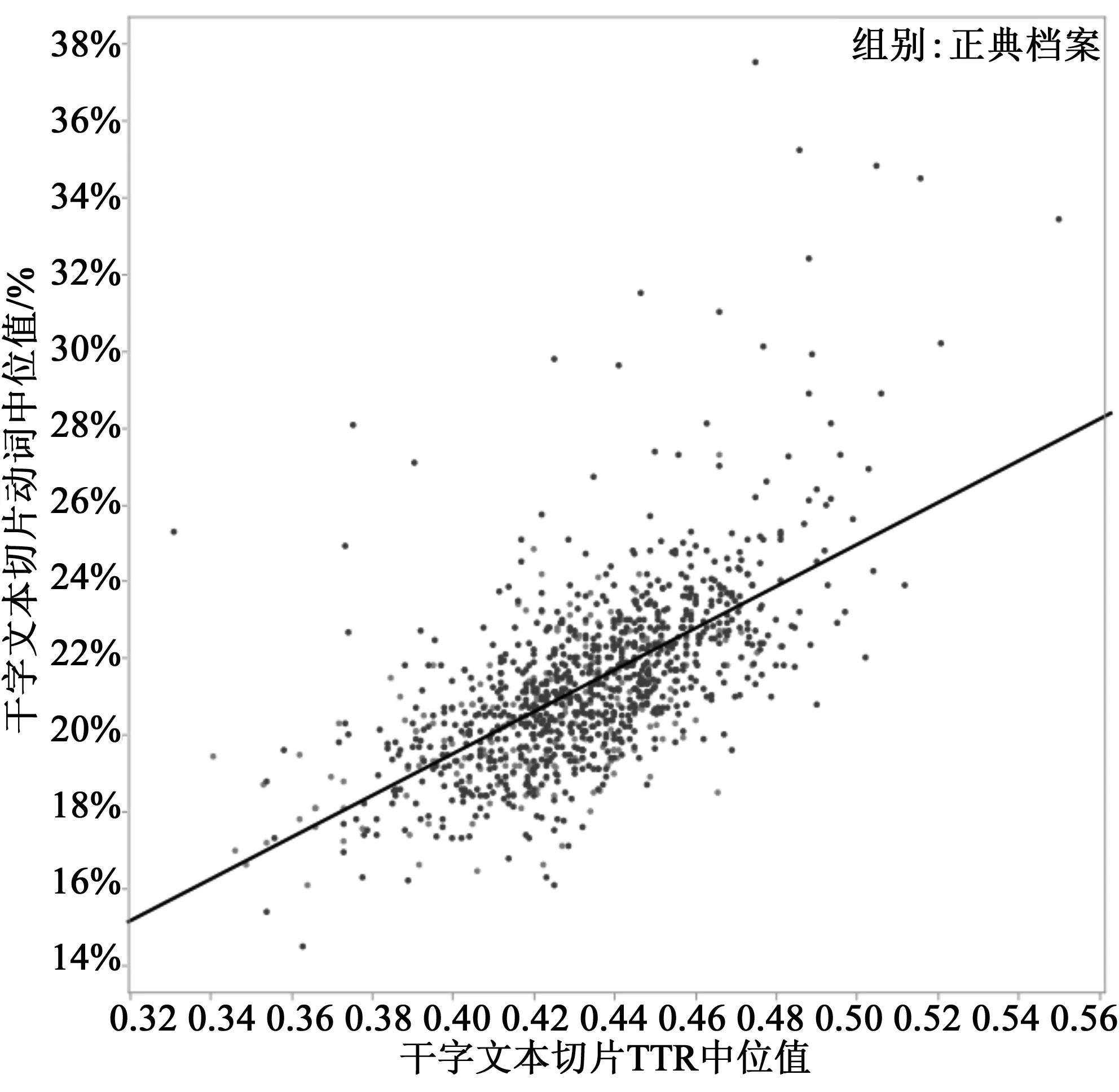
圖6.3 (左上)類符/形符比和名詞
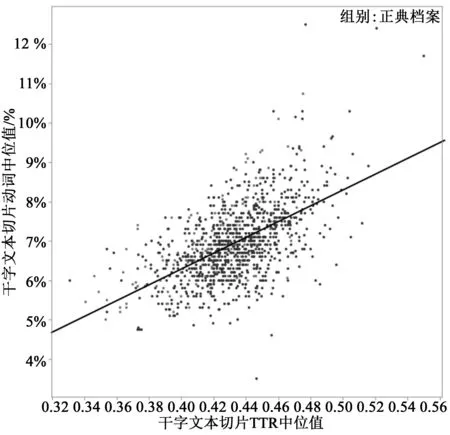
圖6.4 (右上)類符/形符比和形容詞
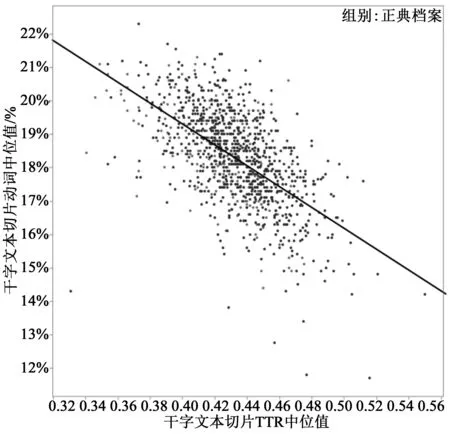
圖6.5 (右下)類符/形符比和動詞 圖6.2所示霍克的直布羅陀片段相比19世紀小說的平均水平,其形容詞(和分詞)頻率是后者的3倍,屈折動詞的頻率比后者低了3-4倍。相反,圖5.4中《亞當·貝德》片段有75個單詞,僅有4個名詞和1個形容詞:“hungry”。
到現(xiàn)在為止,我們解釋了高類符/形符比與書面語域間的密切關(guān)系,不嚴格地說,這種關(guān)系是風(fēng)格和意識形態(tài)選擇的結(jié)果。但其關(guān)聯(lián)還存在更中立的“功能性”原因。在語料庫語言學(xué)的發(fā)現(xiàn)當中,詞匯豐富最大化總是同新聞相聯(lián)系:《朗文語法》指出,這種話語需要“極高的名詞要素密度”(density of nominal elements)以便“指涉各種任務(wù)、地點、物體、事件等。”(53—54)新聞的豐富詞匯有雙重來源:第一,每條具體新聞內(nèi)在的必然獨特性;第二,條目與條目之間完全隔斷:每篇文章或通訊開始時,重復(fù)就被“重置為”近乎為零,而類符/形符比就此上升。這一雙重邏輯返回虛構(gòu)文本,帶來高類符/形符比:它們包括足夠的迥然相異的材料,并通過使用多種類型形式(generic forms)進一步強化其多樣性。有6本簡·韋斯特小說,其類符/形符比在語料庫的前3%,在她的24個分值最高的片段中,有17個引用了詩句。沒有詩句的情況下,她使用繁復(fù)的隱喻(“期待可怕的暴風(fēng)雨來臨,它將清理不健康的樹枝”),甚至模仿。*“First, Venus, queen of gentle devices! taught her prototype, lady Arabella, the use of feigned sighs, artificial tears, and Studied fainting: while Aesculapius descended from Olympus, and, assuming the form of a smart physician, stepped out of an elegant chariot, and on viewing the patient, after three sagacious nods, whispered to the trembling aunt, that the young lady’s disorder, being purely mental, was beyond the power of the healing art. Reduced to the dire alternative of resigning the fair sufferer to a husband or to the grave, the relenting lady Madelina did not long hesitate.” (Jane West, A Tale of the Times, 1799).威廉·諾斯給《偽裝者》寫的前言半是文學(xué)批評,半是書面辯解,涉獵極廣,還包括一個附錄,收入了決定塞到自己所作“羅曼司”里的廣泛話題。*“通過引入文學(xué)評論、對政治和社會邪惡的嘲諷以及對有趣的科學(xué)事實的大眾闡釋,我希望增加羅曼司的趣味,我相信其中不會缺乏探險、情節(jié)和精心設(shè)置的人物。但時髦小說的日子已經(jīng)過去了。現(xiàn)在的時代是實用的,就算是小說家(當代的詩人)也必須符合這個模式。”托馬斯·霍普(Thomas Hope)則轉(zhuǎn)向政治預(yù)言,*“The time is at hand when all the tottering monuments of ignorance, credulity, and superstition, no longer protected by the foolish awe which they formerly inspired, shall strew the earth with their wrecks! Every where the young shoots of reason and liberty, starting from between the rents and crevices of the worn-out* fabrics of feudalism, are becoming too vigorous any longer to be checked: they soon will burst asunder the baseless edifices* of self-interest* and prejudice, which have so long impeded their growth. Religious inquisition, judicial torture, monastic seclusion, tyranny, oppression, fanaticism, and all the other relics of barbarism, are to be driven from the globe.” (Thomas Hope, Anastasius, or, Memoirs of a Greek, 1819).劉易斯·溫菲爾德(Lewis Wingfield)轉(zhuǎn)向半戲仿的建筑學(xué)題外話,*“a stately entrance hall in the most fashionable quarter of the metropolis, embellished with lofty Ionic columns of sham Sienna marble; in front of each a magnificent bust of sham bronze by Mr. NoUekins* on a pedestal of scagliola. From a heavily stuccoed* ceiling, wrought in the classic manner, depend six enormous lanterns in the Pagoda style, wreathed with gaping serpents. Along three sides there are rows of “em pire*” benches, covered with amber damask, on which are lolling a regiment of drowsy myrmidons in rich liveries*. Passing these glorious athletes, you enter an ante-room choked with chairs, sofas, settees*, whose florid gilding is heightened by scarlet cushions. Very beautiful. (Lewis Wingfield, Abigel Rowe. A Chronicle of the Regency, 1883).愛德華·杜羅斯(Edward Duros)轉(zhuǎn)向博學(xué)的古物研究,*“The shield, slung to his neck, bore no emblazonry, and his open baronet and pennon-less* lance argued him neither to have undergone the clapham, or knightly box on the ear (!); nor the osculum pads, which more gently signified the chivalric brotherhood. He was, however, well mounted and perfectly armed. Judging from his simple habergeon, and a silver crescent which he bore, more in the way of cognizance than as his own device, he might be pronounced a superior retainer in the service of some great feudatory.” (Edward Duros, Otterbourne; A Story of the English Marches, 1832).愛德華·霍克轉(zhuǎn)向自然主義的教導(dǎo)……
不過例子已經(jīng)夠多。該做最后的反思了。
三、文學(xué)場域大型動力學(xué)(Large-Scale Dynamics in the Literary Field)
給已經(jīng)偏離最初目標很遠的項目“下結(jié)論”,這不容易。起初正典和檔案是研究目標,冗余和類符/形符比是調(diào)研手段;但是后來手段和目的的關(guān)系默默調(diào)轉(zhuǎn):正典和檔案移到討論邊緣,冗余和類符/形符比越來越占據(jù)了中央位置。這一轉(zhuǎn)換不在計劃內(nèi);有很長一段時間我們甚至沒有意識到這已經(jīng)發(fā)生。我們一直成月地琢磨二元詞組究竟“意味著”什么,到底為何它們能區(qū)分我們的文本;后來,阿里森和杰瑪引進了口頭與書面語域的問題后,我們甚至花費了更多時間在類符/形符比上,閱讀從未聽說過的小說的片段,里面充滿了井號、星號和諸如“傾斜”(acclivities)、“金鏈花”(laburnum)和“混合”(commingling)這樣的詞。怪哉。
為什么這么做?因為我們感到,研究類符/形符比能讓我們對“內(nèi)在”力量——與第三部分討論的“外部”力量不同——有所理解,它們塑造了文學(xué)場域。這是研究目標的又一次滑移:預(yù)設(shè)的正典和檔案的分界——斜線還在標題里——失去了不少關(guān)注,被重新納入大得多的視野中。有分寸地說,這還是與40年前布爾迪厄的軌跡有些相似之處:當時,他從對《感傷教育》(SentimentalEducation)及福樓拜(Flaubert)在19世紀法國文學(xué)的地位研究開始,開發(fā)出一個常規(guī)框架,福樓拜依然在場,但只是許多因素中的一個。這里也如此:正典和檔案依然“在”圖片里,有不同顏色標記;但現(xiàn)在,圖表的意義存在于加強對文學(xué)場域作為整體的了解。艾略特和霍克的例子顯示了風(fēng)格上的截然對立,但已經(jīng)不再讓我們想到正典和檔案,而是想到“口頭”和“書面”語域。焦點已經(jīng)轉(zhuǎn)移。
但我們和布爾迪厄的研究依然存在重大區(qū)別。對我們來說,文學(xué)場域的社會學(xué)不能僅僅停留在社會學(xué)上:它需要強大的形態(tài)學(xué)成分。這就是為什么冗余和(尤其是)類符/形符比變得如此重要:它們混合了定量和定性,這對于小說(fiction)的形態(tài)社會學(xué)十分完美,而后者正是我們的終極目標。回頭看,我們必須承認,目標已不可及——雖然靠近了一些。不可及,意思是當形態(tài)學(xué)與社會命運之間的聯(lián)系最強時——在冗余的情況中——二元詞組的形態(tài)單位本性難以把握,因果鏈難以建立;但相反的是,當這特質(zhì)允許作出豐富而顯明的分析時——在類符/形符比的情況中——關(guān)聯(lián)就減弱了,只有在極端案例中才確定無疑。同時,極端案例附近出現(xiàn)的兩種可見現(xiàn)象——得分最低的案例中角色聲音的強度以及另一極高分案例中敘述者文字話題的龐雜——打開了新的探尋路線,定量—定性的連續(xù)體清楚再現(xiàn),直接引向巴赫金(Bakhtin)小說理論的兩個關(guān)鍵概念:復(fù)調(diào)(polyphony)和雜語(heteroglossia)(綜合的文學(xué)外話語的“其他語言”,如政治審美地理建筑,等等。)通常,這兩個概念被認為是緊密聯(lián)系的(巴赫金自己似乎也這樣認為);但是瓦爾塞(Walser,本文作者之一)在最后一輪討論中指出,我們的發(fā)現(xiàn)揭示出,它們其實位于小說語域的相反區(qū)域:復(fù)調(diào)傾向于同正典文本相關(guān)聯(lián),而雜語同被遺忘的小說相關(guān)聯(lián)。雜語和失敗之間的接近尤為引人注目。對巴赫金而言,當小說與其他話語接觸,便創(chuàng)造性地轉(zhuǎn)變了后者,奪取其力量,強化了自己在文化體系中的核心地位。似乎用雜語不會出錯。但這恰好是小小的被遺忘作者軍團遭遇的事:同其他話語的遭遇有使之癱瘓的效果,產(chǎn)生了非虛構(gòu)散文的死氣沉沉的復(fù)制品,取代了對話體的生命力。只要事關(guān)能否留在英國文學(xué)體系中,這是非常糟糕的選擇。
那么是否說雜語是小說敘事結(jié)構(gòu)的潛在病態(tài)表現(xiàn)?“沒有什么事實……本身是病態(tài)的,”喬治·崗居朗(Georges Canguilhem)在他關(guān)于19世紀“常態(tài)”觀念的名作中寫道:“異常或突變本身并不病態(tài),只是表現(xiàn)出生命的其他可能形態(tài)。”*Georges Canguilhem, The Normal and the Pathological, 1966, New York 1989, p. 144.如果這一說法正確,那么使得霍克、諾思和杜羅斯注定無名的并非由于選擇雜語本身是個錯誤,而是因為雜語發(fā)生的國家和時代——生態(tài)系統(tǒng)——中,小說的形式正朝相反方向轉(zhuǎn)移:擰緊了內(nèi)在的敘事螺栓,而不是朝外部話語尋求靈感(在其他國家依然如此)。狄更斯盡管寫過大量關(guān)于議會的文字,其小說依然有出色的“口述性”(orality)。是這一具體的歷史機緣使得雜語的“其他語言”對生存不利。
這一點上,回顧更久遠的歷史會有幫助。一段時間以前,古典學(xué)家尼可拉斯·霍茨伯格(Niklas Holzberg)寫了篇論文,其關(guān)鍵認知隱喻——“邊緣”(Fringe)——給古典小說研究領(lǐng)域留下了深刻的印記。*Niklas Holzberg, “The Genre: Novels proper and the Fringe”, 1996, in Gareth Schmeling, ed. The Novel in the Ancient World, revised ed., Brill, Boston-Leiden 2003.霍茨伯格用這個說法,意思是希臘和拉丁語“真正的小說”(novels proper)這個極小的群體周邊存在著大得多的文本群體,小說敘事的痕跡混雜著其他話語元素(史學(xué)、游記、哲學(xué)、政治教育、色情文學(xué)……),因而擴展了小說能達到的范圍。之后的20世紀中,——“真正的”小說生產(chǎn)力提高,形式多樣化,在一般文化中地位提升——“邊緣”的角色也相應(yīng)收縮。現(xiàn)代文學(xué)的學(xué)者們幾乎從來不曾費神想過這些。但事實上,邊緣從未消失:圖6.1中的作家就是其現(xiàn)代版本,他們話題泛濫,頗為怪異,這就是作品處于小說和其他話語之間邊界位置的典型征象。真正的問題在于,與此同時,邊界的形態(tài)學(xué)功能——為小說與其他話語之間的相遇提供良好地帶 ——變得更不確定。更早一個世紀前,如果一部小說談到精神自傳的細微差別、書信寫作的機制,或者“知覺”的中斷,仍有可能成為杰作,并且能產(chǎn)生次文類(subgenre):《天路歷程》(Pilgrim’sProgress)、《帕梅拉》(Pamela)、《項狄傳》(TristramShandy),甚至可能包括《威弗萊》,都有明顯的類似邊緣的痕跡。但是在19世紀發(fā)展過程中,——也許是腦力勞動分工的后果,擴大了虛構(gòu)和社會科學(xué)之間的距離,并使得二者的語言越來越難以互通(translatable)——雜語在小說敘事形式發(fā)展內(nèi)的角色變得成問題。這就是決定被遺忘的作家命運的因素。*同樣原因,從那一刻起,《白鯨》和《尤利西斯》這樣的雜語巨著不得不越來越快地遠離小說敘事發(fā)展的主軸,對非學(xué)院讀者的吸引力越來越低。
無論這是否也回答了最初的問題——關(guān)于檔案改變了我們對文學(xué)的認識——不由我們來說。能說的是,研究工作進行時,我們發(fā)現(xiàn)自己投入越來越多的時間給《環(huán)游》、 《偽裝者》以及《亞瑟·蒙塔古》;在少數(shù)幸運的時刻,我們感到,例如,《亞當·貝德》永遠無法提出的問題,這些書能提出。少數(shù)幸運時刻:要一直保持注意力在檔案上,這不容易。某種程度上,是那些著名作家——那些你已經(jīng)知道的事情——拖著你回到常規(guī)。某種程度上,是被遺忘的作者們令人煩惱的本質(zhì)迫使你面對:野心勃勃的理想的巨大殘骸,與文學(xué)史家習(xí)慣研究的風(fēng)景截然不同。學(xué)習(xí)心無傲慢地凝視殘骸——但同樣也并不懷著恭敬——這是新的數(shù)字檔案要求我們做到的;長期看,這也許是比計量本身更大的變化。
(責(zé)任編輯:陸曉芳)
2017-06-12
本項目由巴黎人文科學(xué)中心及梅隆基金會資助,與索邦大學(xué)OBVIL卓越實驗室計劃團隊合作進行。執(zhí)筆人為美國斯坦福大學(xué)(Stanford University)的馬克·阿爾吉-休伊特 (Mark Algee-Hewitt)、萊恩·霍伊舍 (Ryan Heuser)、弗蘭科·莫雷蒂(Franco Moretti)、漢娜·瓦爾塞 (Hannah Walser)和美國羅耀拉大學(xué)(Loyola University)的莎拉·阿里森 (Sarah Allison),以及德國馬克斯·普朗克研究所(Max Planck Institute for Empirical Aesthetics)的瑪麗莎·杰瑪 (Marissa Gemma)。
I0-05
A
1003-4145[2017]09-0046-17
譯者簡介:汪 蘅,畢業(yè)于北京大學(xué)英語系,自由譯者。
①"Canon/Archive. Large-scale Dynamics in the Literary Field," in (https://litlab.stanford.edu/LiteraryLabPamphlet11.pdf), accessed on November 18, 2016. Translated and Reprinted in Chinese with permission of Stanford Literary Lab and Mark Algee-Hewitt.
猜你喜歡
紅豆(2022年9期)2022-11-04 03:14:42
紅豆(2022年9期)2022-11-04 03:14:40
紅豆(2022年3期)2022-06-28 07:03:42
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
意林·全彩Color(2019年9期)2019-10-17 02:25:50
電子制作(2018年18期)2018-11-14 01:48:06
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
西南學(xué)林(2014年0期)2014-11-12 13:09:28
