系泊作業系纜力大數據近似查詢預測方法
2017-04-06 02:53:42宋旭東陳啟剛蔡晨陽邱占芝宋麗芳
大連交通大學學報 2017年2期
關鍵詞:船舶
宋旭東,陳啟剛,蔡晨陽,邱占芝,宋麗芳
(1.大連交通大學 軟件學院,遼寧 大連 116028; 2. 中車大連機車車輛有限公司,遼寧 大連 116022; 3.大連科技學院 信息科學學院,遼寧 大連 116052) *
系泊作業系纜力大數據近似查詢預測方法
宋旭東1,陳啟剛1,蔡晨陽2,邱占芝1,宋麗芳3
(1.大連交通大學 軟件學院,遼寧 大連 116028; 2. 中車大連機車車輛有限公司,遼寧 大連 116022; 3.大連科技學院 信息科學學院,遼寧 大連 116052)*
開敞式碼頭系泊作業中,纜力是保證安全的一個重要指標.目前在系泊纜力預測主要集中在船舶與纜繩之間的物理變化上,采用的方法主要有觀測法、物理模型及數值模型等.提出一種以大量的歷史數據為驅動的預測方法,結合大數據MapReduce模型機制,使用近似查詢方法獲取與當前影響船舶纜力因素最接近的歷史纜力值;考慮到船舶纜力影響因素的所占比重不同,采用模糊數學的方法來確定各個因素的權值分配.仿真實驗表明方法的預測結果具有較高的可行性和實用性.
系纜力;大數據;近似查詢;預測方法
0 引言
船舶系纜力的影響因素十分復雜,既受風、浪、流等因素的影響,也受船型、作業狀態等參數的制衡.隨著船舶大型化和泊位深水化的日益發展,以及工程實踐中各種影響條件的千變萬化,單純的靠人為經驗等判斷船舶作業安全的狀態這是很難做到的,理想狀態下的數模計算和物模實驗[1-3]已經遠遠不能滿足系纜力方面理論和應用的進一步發展.
近似查詢技術在計算機科學領域是一個被關注的問題,它被廣泛的應用于各種領域,如互聯網、醫療衛生、數據挖掘、數據庫以及生物科學技術等[4-6].而傳統的查詢方法不能滿足數據因素不確定的條件,在此基礎上本文引入了模糊數學的概念,以確定各種因素之間的權重分配.在面對大量數據處理過程中,模糊近似查詢查詢技術不能很好的滿足要求,本文提出了一種在Hadoop平臺上結合近似查詢技術和模糊數學的方法,利用MapReduce并行處理模型解決了大量數據查詢和計算時間慢的問題,實現了對系泊碼頭船舶作業纜繩拉力值模糊近似查詢,對于船舶作業過程中的安全預警有著重要的支持作用.
1 大數據MapReduce處理模型
MapReduce模型是由Google在2003~2004年發表的兩篇論文中首次提出,其分布式并行編程模型在海量的數據中進行計算具有明顯的優勢,因此在學術界和工業界引起來了關注和使用[7].
MapReduce的基本思想是將一個大的數據分成若干個數據塊(datablock),每一個數據塊都會被分成成千上萬個數據集split.MapReduce定義了Map和Reduce兩個抽象的接口,Map會對每個提交上來的數據塊按行解析成鍵值對
MapReduce并行計算模型如圖1所示.
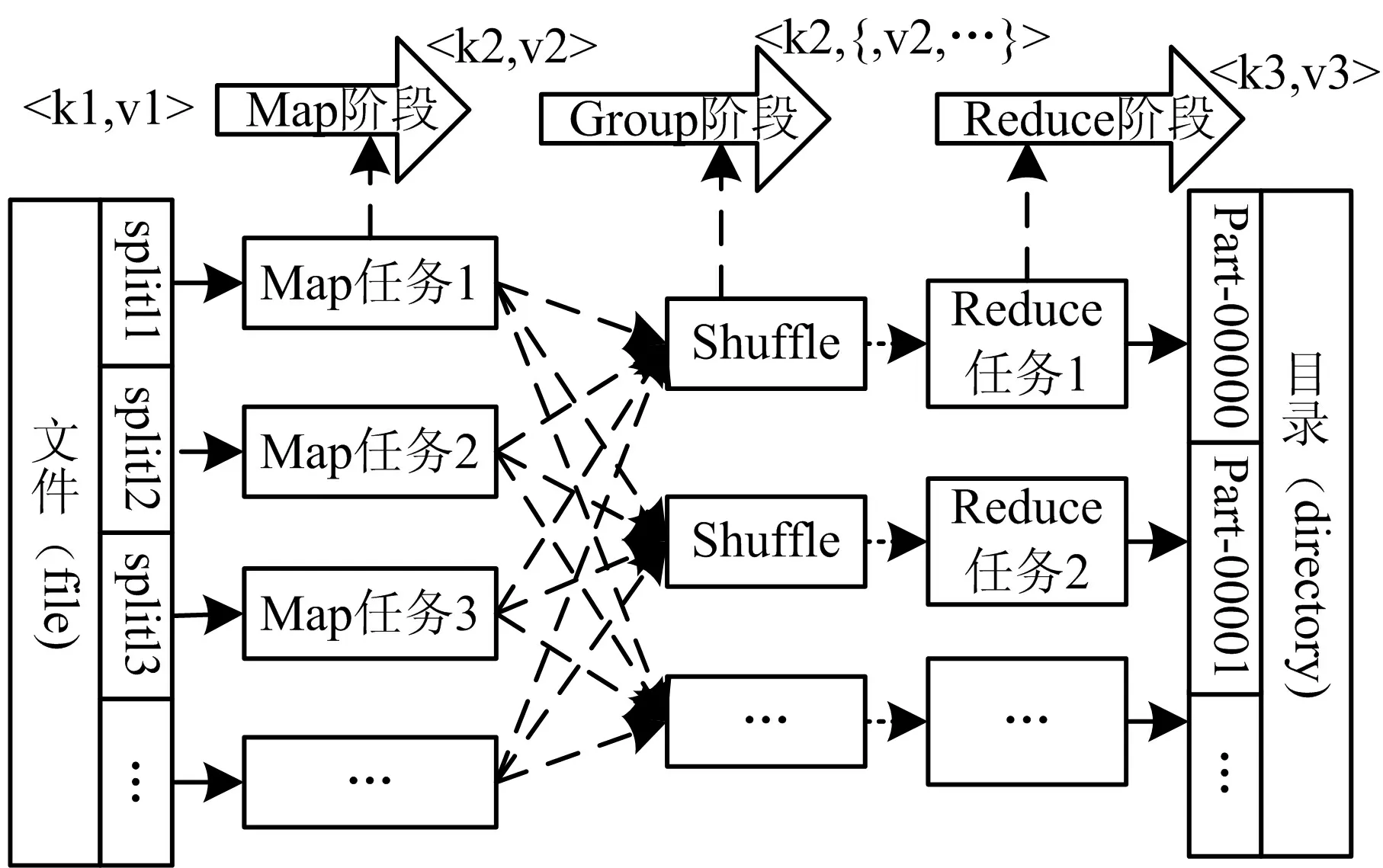
圖1 MapReduce并行計算模型
2 基于MapReduce的模糊近似查詢算法
本文研究的是基于大數據MapReduce對系泊纜力的模糊近似查詢預測方法,首先需要明確的是影響系泊纜力的風速、風向、流速、流向、波高等因素對纜力值所占的權重,然后根據模糊數學確定數據之間的歐氏距離值,最后將查找計算在并行框架中實現.
2.1 權重確定方法
假設x是討論域U中的任意一個元素,有一個關系式A(x) ∈[0,1]與之對應,這時A(x)稱之為x對A的隸屬度.當x在U中進行變換時,隸屬度A(x)越接近0,表示x屬于A的程度越低,隸屬度A(x)越接近1,表示x屬于A的程度越高.隸屬度函數是模糊數學中應用于模糊控制的關鍵因素之一,由于隸屬度函數的確定目前主要有模糊統計法、例證法、二元對比排序法以及本次使用的專家經驗法.
專家經驗法是根據專家的實際經驗給出模糊信息的處理算式或相應權系數值來確定隸屬函數的一種方法.風、浪、流、噸位等因素對于纜力值的影響有著直接的影響,對于其權值的確定,直接影響著數據查找的準確性.專家經驗法,在一定程度上避免了因個人不能客觀把握情況而導致結果失真.
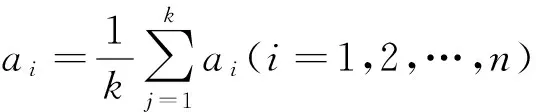
2.2 數據模糊近似計算
造成系泊纜力變化的因素主要有風、浪、流、噸位等,不同的影響因素其數值和單位不同,為了使其不在后續的查找匹配中出現某一因素產生較大的影響,使用歸一化對數據進行處理,去除掉量綱的影響,將不同的單位的數值進行格式化,使之在指定的范圍內(0~1).將定原始數據集為X={xi|xi∈R,i=1,2,…,n},歸一化后的數據集為
歷史數據會按行存放在文件中,假定每行的歷史數據集經過歸一化處理以后為D={di|di∈R,i=1,2,…,n},待預測影響因素數據集經過歸一化處理以后為C={ci|ci∈R,i=1,2,…,n},兩組數據之間的加權歐式距離可表示為
2.3 預測方法框架結構
系泊作業過程中在過去數據檢測中存儲了大量的歷史數據,每個被分解的數據塊可以單獨的在每個計算機上進行處理,很適合在MapReduce并行模型上進行計算[8].在規模集群上運行的MapReduce分布式編程模型計算處理過程可以抽象為Map和Reduce兩個函數,這兩個函數分別繼承了Hadoop中的Mapper和Reducer類,用戶只需要按照要求來實現這兩個類即可.其整體方法框架如圖2所示.
在數據采集以后,還需要根據船舶綁定纜繩的實際情況,在數據庫中選擇出適合當前情況的數據,對選擇出來的數據進行預處理,刷除那些數據不完全、檢測明顯不符合標準的數據,將規范的數據以供后續使用.
(1)在Map階段,將歷史存儲的數據文件作為預測方法的輸入文件,從程序輸入中讀取預測數據,這樣完成初始化操作;Map函數會按行讀取歷史數據,然后將歷史數據和預測數據進行歸一化處理,然后再計算這兩組數據的歐式距離,將計算的中間變量存儲在中間變量中,當計算完第二組歐式距離以后,把第一次的歐式距離值與第二次歐氏距離值進行比較,如果小,則中間變量存放第二次的歐式距離值,依次類推,直到計算完整個數據塊的歷史數據,將最后的歐氏距離值寫入鍵值對中,以供后續Reduce階段使用;
(2)在Reduce階段,會接收來自各個Map的結果作為輸入,會將具有同一個key的鍵值對組成一組,交由一個Reduce函數處理,Reduce函數會從同一組value值中找到歐式距離最小的歷史數據,其中key為纜繩的數量,value為歷史影響因素數據和各個纜繩纜力的歷史檢測值.最后將這組歷史數據寫入HDFS文件中.
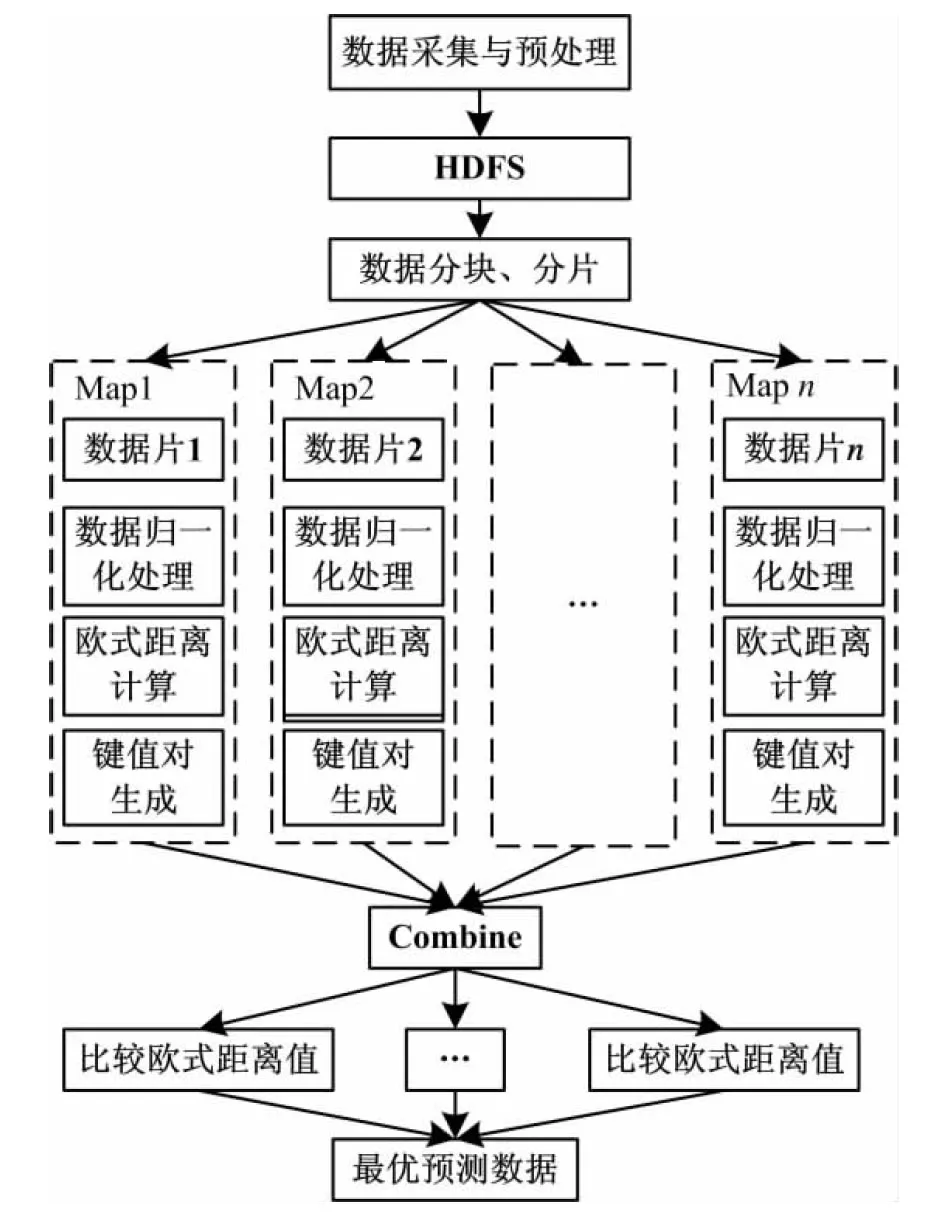
圖2 基于MapReduce模糊近似查詢框圖
在上述的Map和Reduce階段中,文本中的數據都是用便于保存的字符串格式存儲,在計算過程中需要多字符串進行轉換成適合計算的類型.
3 預測方法分析評價
3.1 分布式預測運行環境
分布式運行集群由4臺PC組成,其中1臺PC為NameNode,3臺PC為DataNode,硬件環境配置均為InterCorei5-3210M處理器,2GB內存,500GB硬盤;軟件環境為CentOS-7.0-1406、JDK1.6.0_20以及Hadoop-1.1.2.
3.2 運行結果分析
根據文獻[9]中關于系泊實測數據類型及其數據范圍進行數據仿真實驗,生成目標數據作為歷史數據共4 000 000行記錄,數據以文本格式存放,數據項之間使用Tab鍵進行分割.在歷史數據中每行數據包括影響系泊纜繩拉力的因素數據(風速、風向、流速、流向、波高、波向及載量)和一段時間以后的纜繩時間拉力數據.
實驗中將待預測環境動力等因素作為預測影響因素輸入,使用近似查詢方法獲取與當前影響船舶纜力因素最接近的歷史纜力值作為未來一段時間的系纜力為預測結果.


圖3 纜力目標值與預測值標準差折線圖
3.3 分析評價
從預測值和目標值的數據可以看出,處于船舶首尾兩個位置的纜繩1和纜繩8上的纜力值較大;處于船舶中間的首道纜和尾道纜位置的纜繩4和纜繩5所受的纜力值其次;處于船舶的首橫纜和尾橫纜位置的纜繩2、纜繩3、纜繩6和纜繩7所受的纜力值最小.在平均誤差中,受力較小的纜繩6誤差最小,說明其預測準確率最高,纜繩5誤差最大,說明其預測準確率最低.
從圖3可以看出目標值標準差和預測值標準差折線基本接近,纜繩5的目標與預測標準差相差最小,說明其纜力值波動較小;纜繩1的目標值與預測值標準差相差最大,說明其纜力值波動較大.
4 結論
針對系泊作業過程中纜繩纜力預測的問題,本文給出了基于大數據Hadoop平臺的數據模糊近似度預測方法,實現了在大量的歷史數據中根據當前檢測到的影響因素數據來預測一段時間后的纜力值.仿真實驗表面在大量的數據中通過模糊近似查找的方法可以匹配出與當前因素最接近的纜力值,并且在準確性和查詢速度上具有高效性,隨著數據量的越大越具有明顯的優勢.基于大數據平臺的系泊纜力預測方法在船舶作業過程中具有現實的意義.
[1]ZHOU DECAI , MIAO QUANMING. Nonlinear Characteristics Simulation of Mooring Lines and Fenders of Binding Ships in Model Tests [J]. Journal of Ship Mechanics, 2005, 9(6): 48-55.
[2]鄒志利, 張日向, 張寧川,等. 風浪流作用下系泊船系纜力和碰撞力的數值模擬[J]. 中國海洋平臺, 2002, 17(2):22-27.
[3]STOCKSTILL R L,BERGER R C. A three-dimensional numerical model forflow in a lock filling system[C]//ASCE. World Environmental and Water Resources Congress.U.S.:ASCE Press ,2009:2737- 2746.
[4]UYSAL M S, BEECKS C, SABINASZ D, et al. Large-scale Efficient and Effective Video Similarity Search[C]// Workshop on Large-scale & Distributed System for Information Retrieval. ACM, 2015:3-8.
[5]TSYMBAL A, MEISSNER E, KELM M, et al. Towards cloud-based image-integrated similarity search in big data[C]// 2014 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI). 2014:593-596.
[6]李昕, 孟祥福. 基于相似性推薦的電子商務Web數據庫關鍵字近似查詢方法[J]. 小型微型計算機系統, 2015(7):1487-1491.
[7]LAMMEL R. Google′s MapReduce Programming Model-Revisited[J]. Science of Computer Programming , 2008 ,70(1):1-30.
[8]SRIRAMA S N, JAKOVITS P, VAINIKKO E. Adapting scientific computing problems to clouds using MapReduce[J]. Future Generation Computer Systems, 2012, 28(1):184-192.
[9]郝慶龍. 超大型船舶系纜力實測研究[D]. 大連:大連海事大學, 2014.
Mooring Line Force Prediction Method based on Big Data Approximate Query
SONG Xudong1, CHEN Qigang1, CAI Chenyang2, QIU Zhanzhi1,SONG Lifang3
(1.Software Institute, Dalian Jiaotong University, Dalian 116028, China; 2. CRRC Dalian Co., Ltd, Dalian 116022, China; 3.School of Information Science, Dalian Institute of Science and Technology, Dalian 116052, China)
Mooring line force is an important indicator for mooring operation safety in the open wharf. The prediction method of the mooring line force focuses on the physical changes of the ship and the mooring lines. The prediction methods mainly include observation, physical model and data model. A data driven prediction method is provide, based on massive historical data. Using approximate query method and big data MapReduce model framework, mooring line force prediction value is obtained which is the similar mooring line force value of the closest force influencing factors. Considering the different weights of influencing factors, fuzzy mathematics method is used to determine the weights of influencing factors. Simulation results show that the prediction method has higher feasibility and practicability.
mooring line force; big data; approximate query; prediction method
1673- 9590(2017)02- 0117- 04
2016-03-01 基金項目:遼寧省自然科學基金資助項目(201602131);大連市科技計劃資助項目(2014A11GX006)
宋旭東(1969-),男,教授,博士,主要從事大數據、數據挖掘、智能算法、決策支持系統方面的研究 E- mail:xudongsong@126.com.
A
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:08:26
艦船科學技術(2022年14期)2022-09-22 03:07:40
機械工業標準化與質量(2022年6期)2022-08-12 02:07:42
艦船科學技術(2022年2期)2022-03-29 01:12:44
船舶(2021年4期)2021-09-07 17:32:22
小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22
船舶標準化工程師(2019年4期)2019-07-24 07:21:12
軍工文化(2017年12期)2017-07-17 06:08:06
中國船檢(2017年3期)2017-05-18 11:33:09
船海工程(2015年4期)2016-01-05 15:53:30
