基于主成分分析與GA-BP網絡的鐵路客運量預測研究
2017-03-08 08:32:23楊祺煊
軍事交通學院學報 2017年2期
關鍵詞:模型
楊祺煊
(軍事交通學院 研究生管理大隊,天津 300161)
● 基礎科學與技術 Basic Science & Technology
基于主成分分析與GA-BP網絡的鐵路客運量預測研究
楊祺煊
(軍事交通學院 研究生管理大隊,天津 300161)
針對鐵路客運量影響因素眾多、變量之間映射關系復雜的特點,使用主成分分析方法對客運量影響因素進行處理,降低相關變量維數,消除變量間的多重共線性關系,并將轉換后的變量輸入到基于GA-BP的神經網絡模型中,完成對于鐵路客運量的預測。仿真結果表明,該模型相較于BP神經網絡模型,具有更好的預測精度和更簡單的結構。
鐵路客運量預測;主成分分析;神經網絡
鐵路客運量預測是指對客運量的發展進行動態分析,并在定性基礎上進行定量計算。正確預測鐵路客運量,對國家的經濟發展格局和資源配置,以及對鐵路企業內部的投資結構、經營管理等都有重要作用[1]。但現實中的鐵路客運量呈現出較大的不確定性,在春運階段的表現尤其突出,相關預測誤差會使運力安排與各地區客流聚集程度不協調。由于客運量增長影響因素不僅包括人口結構、經濟社會發展水平、消費水平,還易受到突發事件的影響,如何通過相關影響因素的變化分析出可能出現的客運量異常變化,顯得十分重要。
預測精度和考慮的影響因素與使用的算法密切相關。常用的預測算法有時間序列法[2]、回歸分析法[3]、馬爾科夫預測法[4]、神經網絡方法[5-7]、組合預測方法[8]等。各種方法在樣本數據需求、預測精度、運算效率、預測偏差方面都有其各自的特點,而在數據處理方法上主要有標準化、小波分析、因子分析[9]、主成分分析等。本文將對鐵路客運量的影響因素進行PCA處理,分析提取主成分,在此基礎之上建立利用遺傳算法優化的BP神經網絡,對鐵路客運量進行預測。
1 PCA與GA-BP原理介紹
1.1 PCA原理介紹
主成分分析(principal component analysis, PCA)是多元統計分析中一種簡化數據、特征提取的方法。它通過分析樣本數據中方差最大的特征,將原變量的一系列線性組合成新的變量,使組合后的變量互不相關且最大限度保留原有變量信息。這里利用該方法對原始數據樣本進行處理,提取主成分,組合成新的輸入指標,再利用簡化后的數據集作為模型的輸入。
設有m個樣本,每個樣本有n維度,則整個樣本數據可表示為
式中單個樣本數據可表示為Xi=[xi1,xi2,…,xin],i=1,2,…,m。
PCA完整計算步驟如下:
(1)樣本數據均值化處理,以消除量綱的影響。
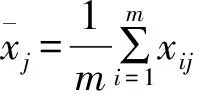
(2)矩陣分解。令X*=YTY,對X*求其特征值λj,特征向量vj。
式中:vj為Y的右奇異向量;σj為奇異值;uj為左奇異向量。
(3)選擇主成分個數。將奇異值σj從大到小排列,求其方差貢獻率ηj與累計方差貢獻率ηk。
一般來說,當ηk>0.95時,即視為包涵樣本的絕大部分信息,此時選取的主成分為前k個。
(4)數據變換。
1.2 GA-BP原理介紹
作為預測研究中重要的新興技術,神經網絡具有良好的自學習、自適應、分布式存儲等特性,在處理模式識別、非線性回歸及優化等問題時展現了較大的優勢。盡管如此,其自身也存在一些缺陷:由于BP算法的權值調整原則是基于誤差的梯度下降,這要求調整過程的每一步都取局部最優,因此,對于某些復雜的誤差曲面,BP網絡容易陷于局部極小點。此外,當網絡結構復雜、學習樣本數目較多時,網絡初始權值的取值對網絡收斂與否影響很大,而標準算法中隨機確定的初始權值,增加了預測結果的不確定性。因此這里使用遺傳算法對BP神經網絡初始權值進行篩選優化,目的在于利用其啟發式搜索能力排除掉不利于網絡收斂的初始權值,提高網絡尋優效率。
圖1所示的BP神經網絡中,X=(x1,x2,…,xn)T為網絡的輸入向量,x0=-1將隱含層閾值轉化為權值;H=(h1,h2,…,hm)T為隱含層輸出向量,h0=-1將輸出層閾值轉化為權值;Y=(y1,y2,…,yl)T為網絡的輸出向量,V=(V1,V2,…,Vm)為隱含層神經元權值,W=(W1,W2,…,Wl)輸出層神經元權值,期望輸出向量為T=(t1,t2,…,tl)T。
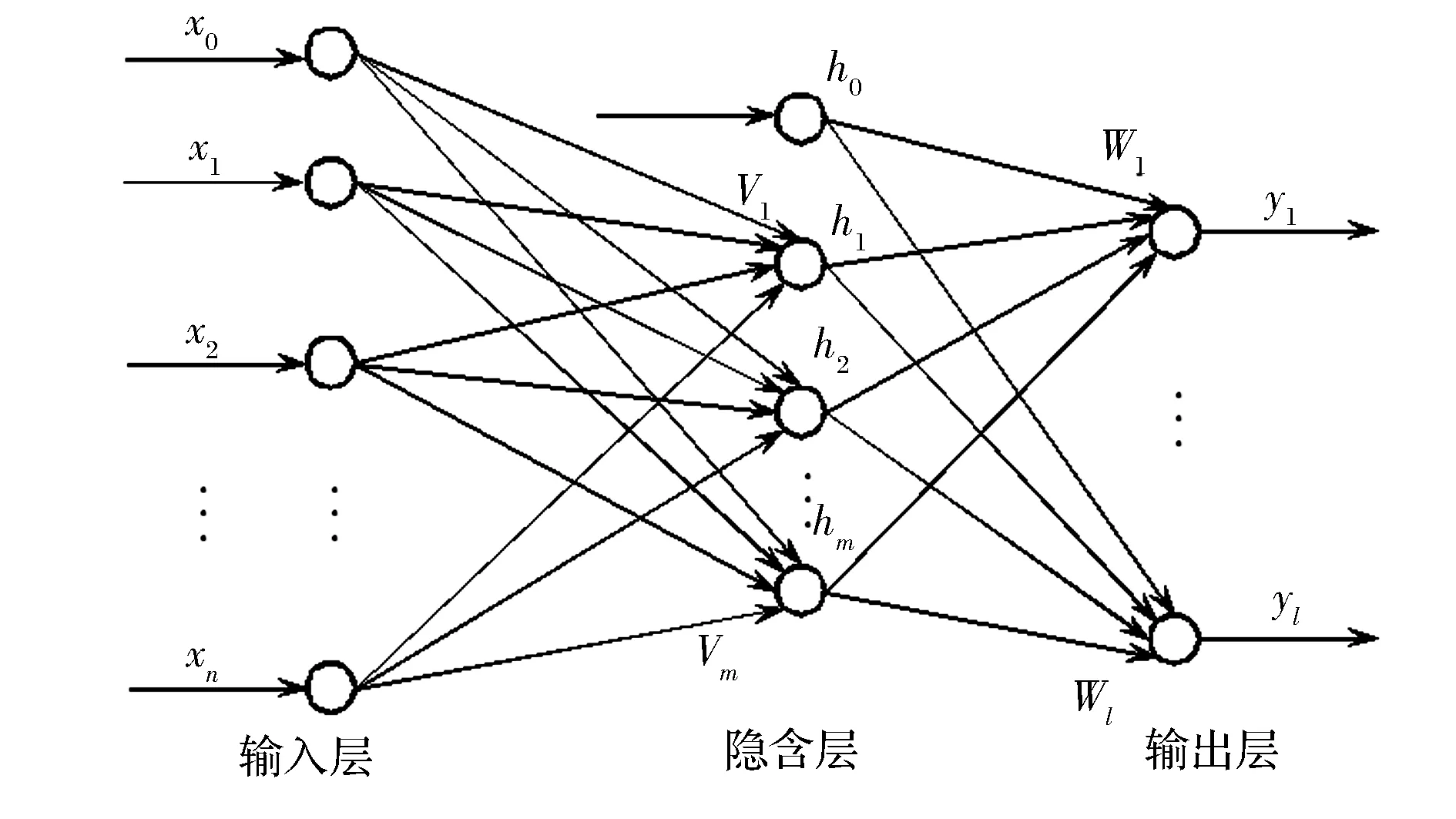
圖1 BP神經網絡拓撲結構
各層之間信號傳遞方式如下:從輸入層到隱含層:
hq=f(netq)q=1,2,…,m
從隱含層到輸出層:
yr=f(netr)r=1,2,…,l
基于遺傳算法優化的BP神經網絡運算過程如圖2所示。

圖2 GA-BP模型原理
2 天津鐵路客運量預測因素的選取與主成分分析
2.1 預測影響因子選取
鐵路客運量影響因素涉及面廣,根據相關文獻[10-12],綜合考慮區域經濟發展水平、產業結構、人口結構與消費、稅收情況等,選取以下13個指標作為客運量影響因素(見表1)。本文算例數據出自天津統計年鑒。
選取較多的影響因素是為了盡可能地保留并發現影響因素與客運量之間的隱含映射關系,但輸入矩陣規模的擴大,會導致網絡冗余。輸入變量間的多重共線性會導致網絡參數變化怪異,進而降低網絡泛化性能[3]。對輸入矩陣的主成分提
取,能在保留絕大部分數據信息量的同時盡可能降低輸入矩陣維數,以少數不相關的主成分作為維度對原始數據進行重新映射,將其投影到低維空間,作為神經網絡的輸入(如圖3所示)。

表 1 鐵路客運量的主要影響因素
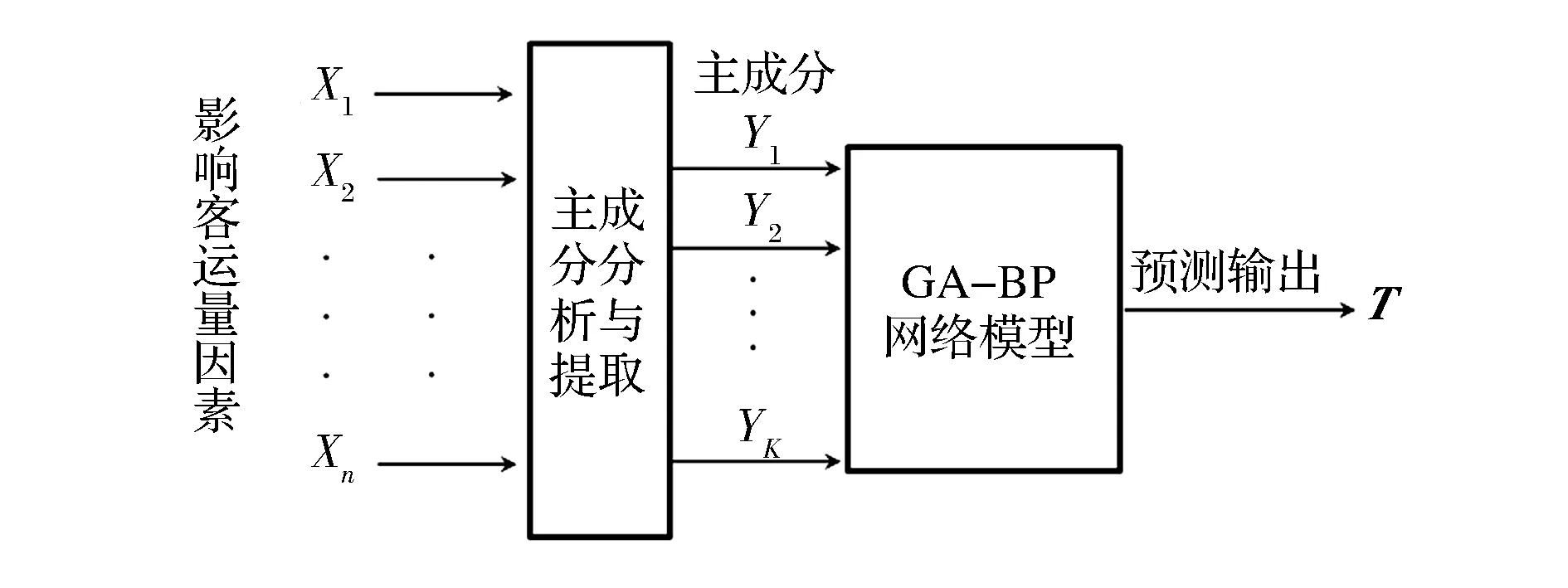
圖3 客運量預測模型
2.2 主成分分析與輸入變量提取
為去除輸入數據單位及量綱的差別,首先對數據進行均值化處理[13],然后求其協方差矩陣的特征根以及相應的特征向量,根據特征值的累計貢獻率篩選主成分(主要結果見表2)。
表2計算數據表明,特征值最大的主成分占有全部信息的98.8%,而前兩項主成分累計達到99%以上,符合選取標準[14],完全可以用前兩項主成分作為新的維度對原有數據進行映射。
由表3可知,區域GDP、第二和三產業產值、新增固定資產投資、營業稅、企業所得稅在第一主成分中占有較大載荷,即該主成分以較大程度反映了這方面特征。對于第二主成分,企業所得稅與個人所得稅則占據絕大部分比重。
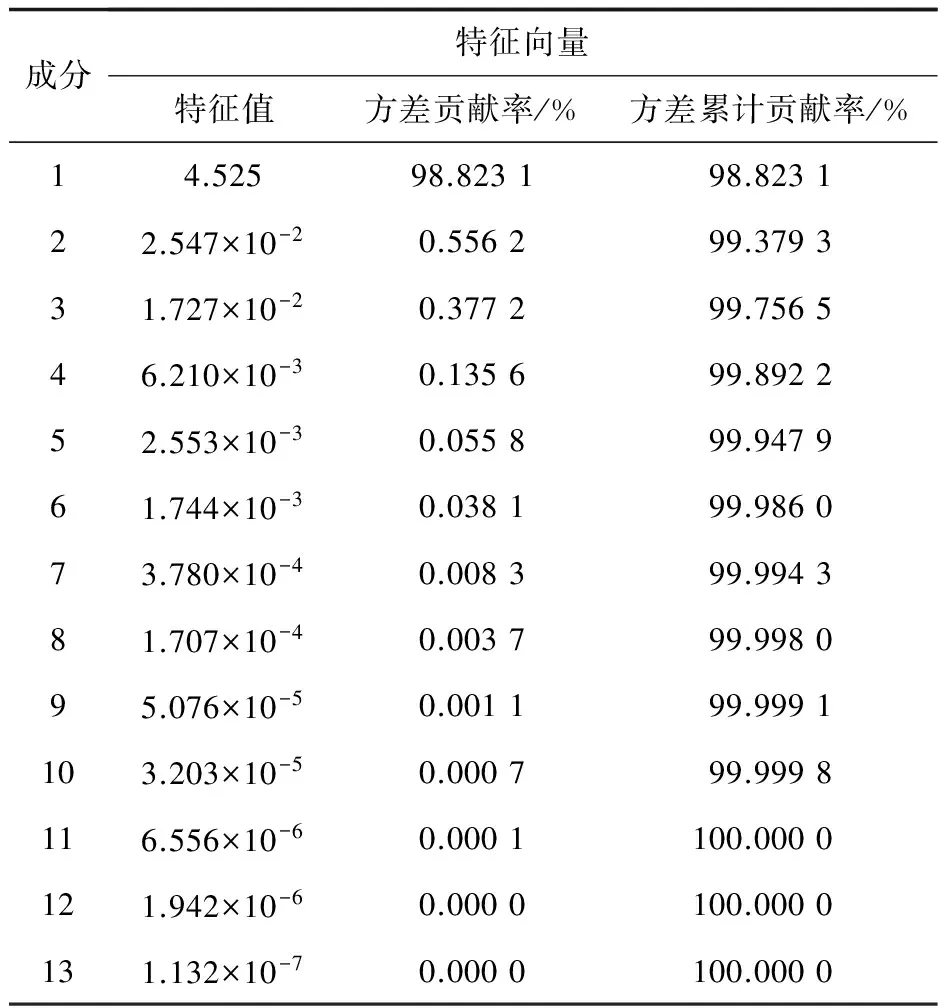
表2 各主成分特征值與方差貢獻
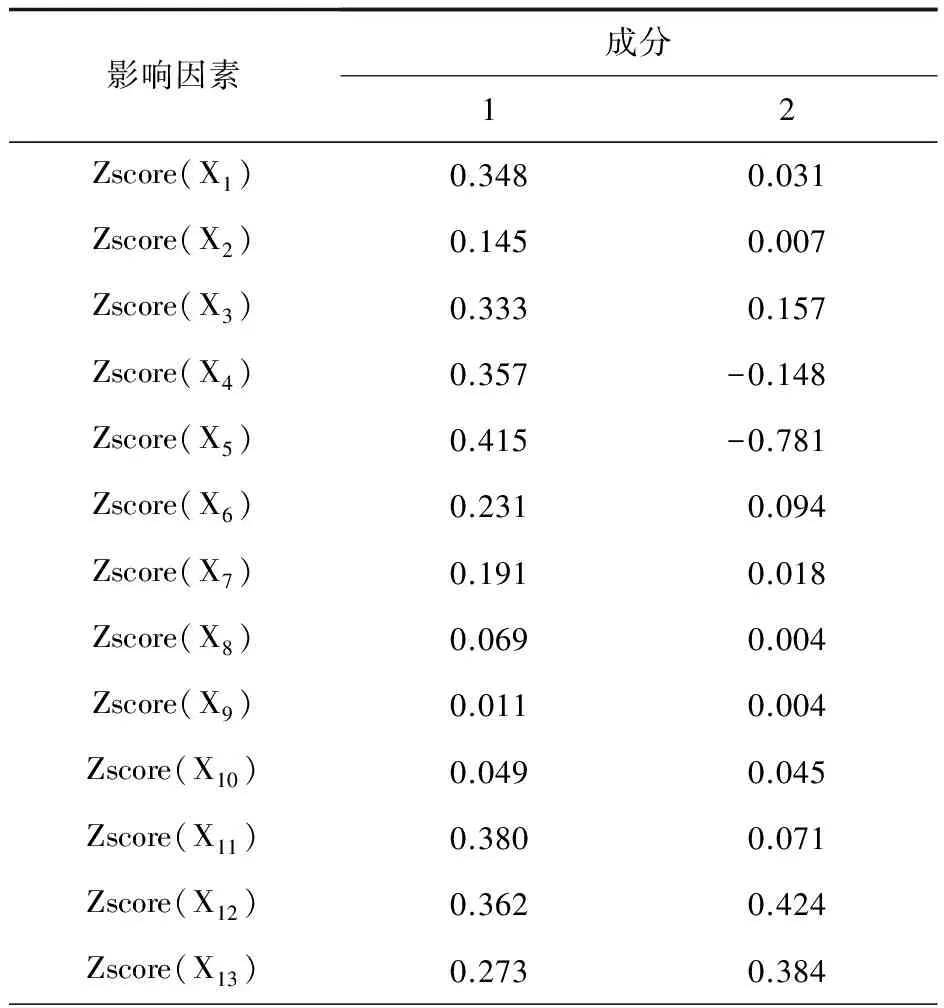
表3 各影響因素的因子載荷矩陣
2.3 PCA-GABP預測方法的結果分析
(1)有PCA處理和無PCA處理的模型遺傳收斂代數與誤差曲線。圖4、圖5所示為兩種GABP模型的預測誤差與遺傳代數曲線,其中神經網絡部分隱節點數同為4,相關參數相同,遺傳算法部分除個體長度外其余參數相同。可以看出,PCA處理過的模型無論是收斂代數、收斂速度、預測精度都優于非PCA模型。非PCA模型在遺傳收斂初始階段誤差加大,這與其較大的網絡參數數據相關。隨著遺傳代數的增加,誤差下降較為緩慢,網絡開銷較大。而PCA模型得益于較小的網絡規模,遺傳初始階段誤差就已經優于前者的最終誤差,且在第10代時完成收斂,收斂速度有很大提高。
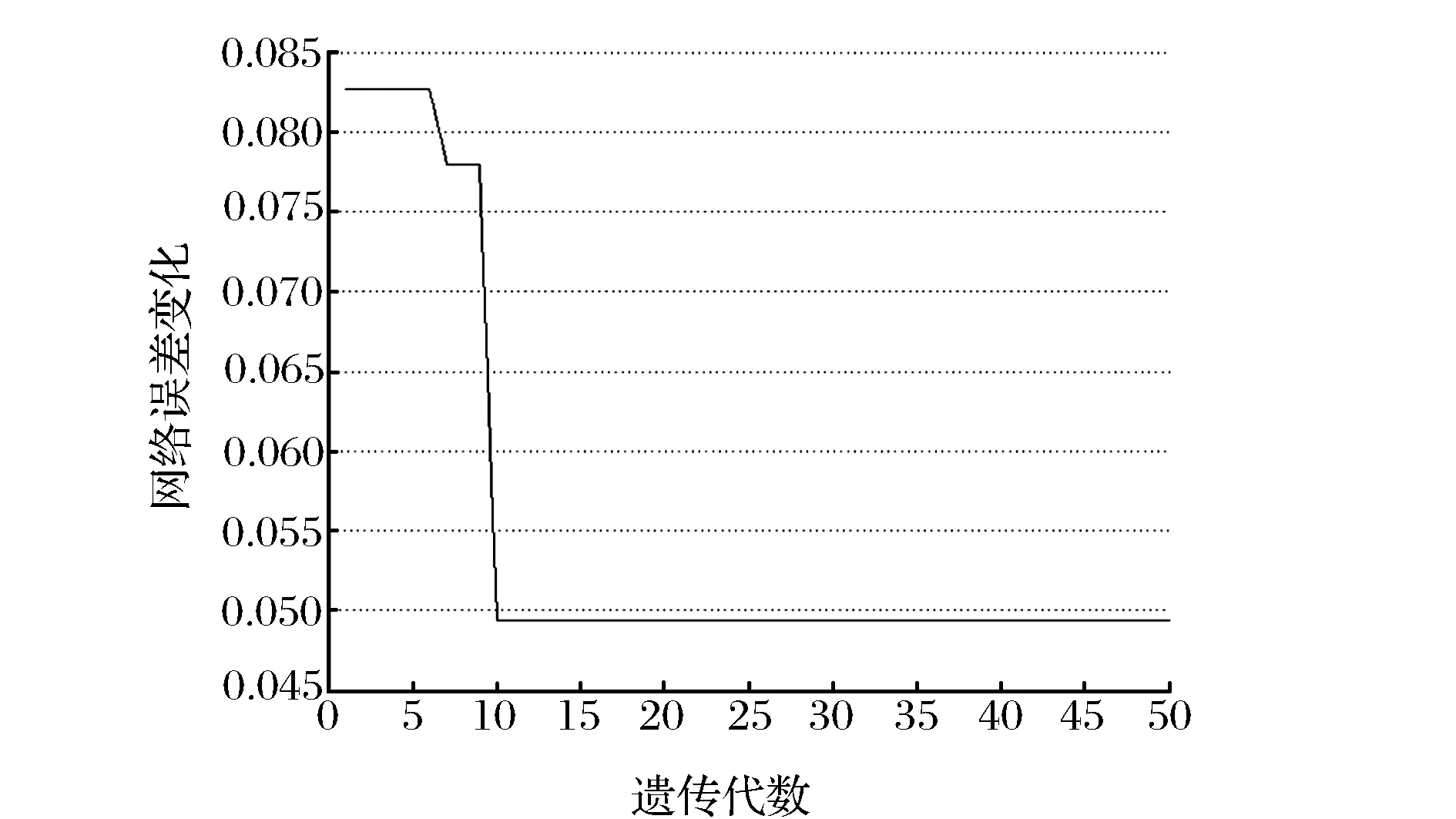
圖 4 PCA處理過的模型遺傳進化過程
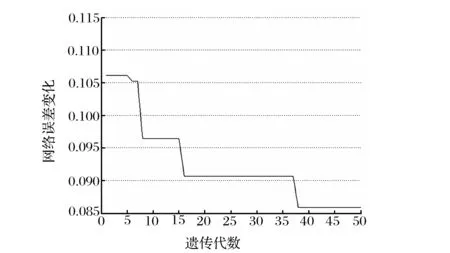
圖5 未經PCA處理的模型進化過程
(2)最優隱節點取值時訓練預測誤差圖。為考察PCA對于前饋網絡訓練情況與預測精度的影響,這里將兩種模型平均絕對誤差最小的結果加以比較。采用試湊法尋找網絡預測誤差最小時隱節點取值,仿真結果表明:基于PCA的網絡最優隱節點數為4;非PCA處理的網絡最優隱節點數為7。網絡訓練與預測情況如圖6所示。
在網絡訓練階段,PCA網絡與非PCA網絡差異不大,前者相對于實際值的偏差較為平均,而后者擬合值明顯偏大。在預測階段,PCA網絡更準確且誤差分布均勻;非PCA網絡預測誤差更大且顯著偏小。這說明在同等精度水平下,PCA能夠減少前饋網絡的誤差偏性,將誤差控制在實際值兩側。主要原因在于輸入數據維數的縮減,有利于神經網絡參數的優化迭代,使參數變化更加簡明有效;此外,主成分之間的相對獨立性會提高網絡效率,提高網絡識別能力。
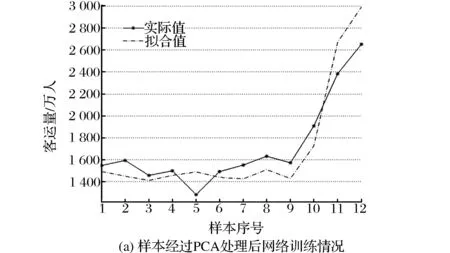
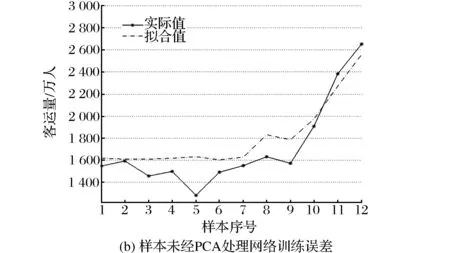
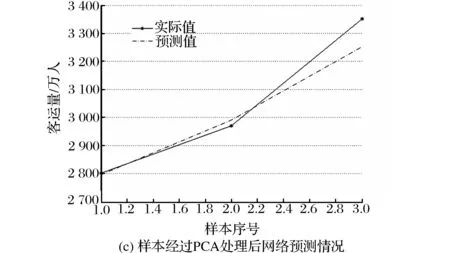
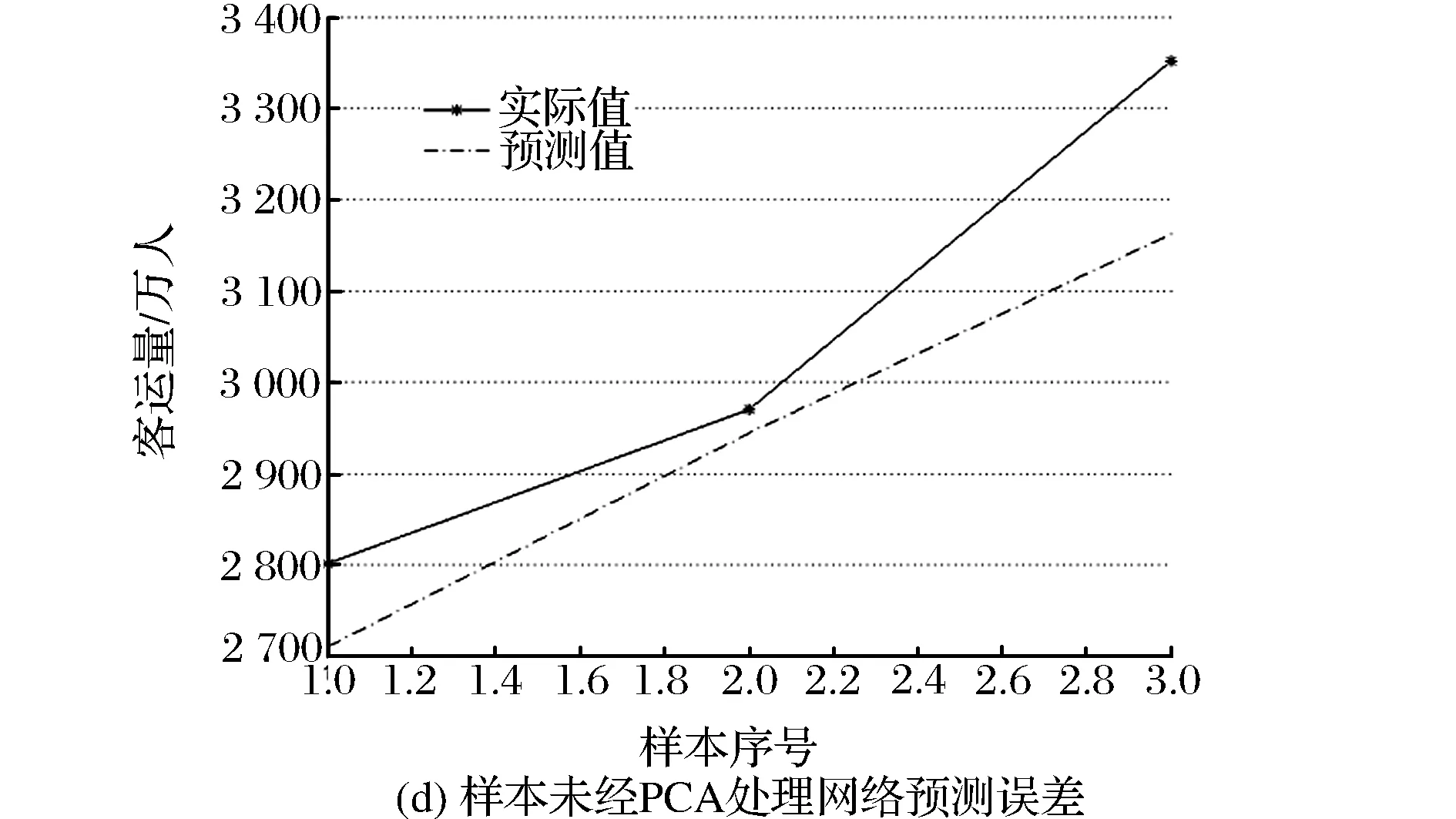
圖6 兩種模型訓練、預測誤差比較
3 基于PCA-GABP的天津鐵路客運量預測與評價
將PCA處理過的樣本輸入到網絡中,三層前饋網絡隱節點數為4,網絡結構為2-4-3;訓練次數epochs=1 000,學習速率lr=0.1;遺傳優化階段個體數目NIND=50,最大遺傳代數MAXGEN=50,交叉概率Px=0.8,初始變異概率Pm0=0.01,代溝GAP=0.95,選擇操作為隨機遍歷采樣,交叉操作采用單點交叉,變異操作使用離散變異算子;同時使用未經PCA處理的樣本作為GABP網絡輸入建立對比模型,遍歷實驗表明其最優隱節點數為7,網絡結構為13-7-3,其余參數不變。兩個模型使用1999—2010年數據作為訓練樣本,2011—2013年樣本作為預測樣本,預測結果及誤差分析見表4、表5、圖7。其中:MAE為平均絕對誤差,RMSE為均方根誤差。
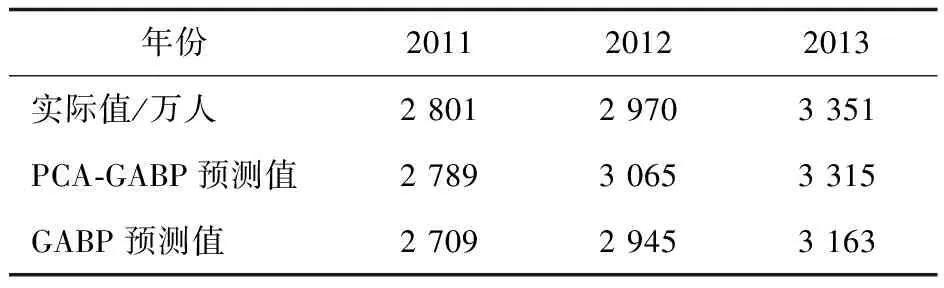
表4 兩種模型預測結果對比
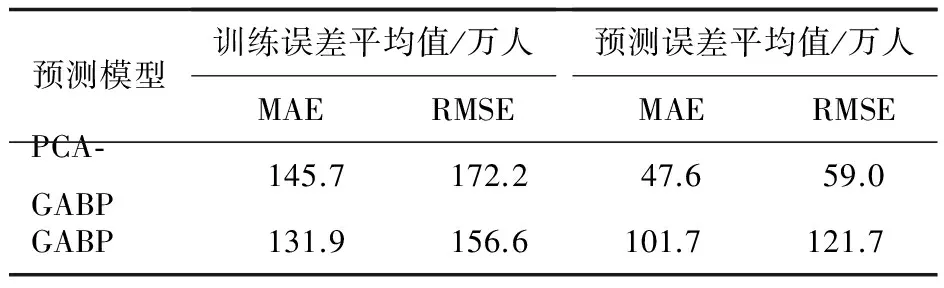
表 5 兩種模型訓練及預測誤差分析
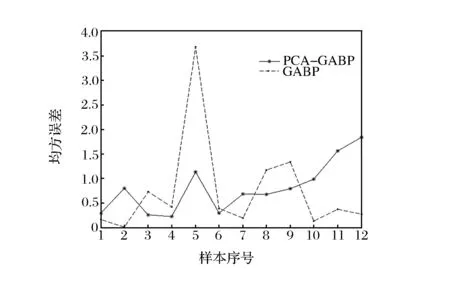
圖7 兩種模型訓練均方誤差比較
由表5可知,就訓練誤差而言,GA-BP比PCA-GABP擬合度更高,但其預測誤差則遠遠大于PCA模型。盡管非PCA方法平均擬合度較好,由圖7可以看出,個別點擬合偏差不穩定。訓練次數過多或訓練精度過高時,BP網絡存在過擬合的趨勢,可能導致網絡泛化能力減弱。這里輸入數據維度之間的冗余與線性關系,加上BP網絡基于經驗最小化的特點,會進一步降低其泛化能力[15]。若要減少過擬合的影響,就要控制訓練數據輸入次序與訓練迭代步數,這會使模型預測能力帶有較大的不確定性。相比之下,PCA-GABP模型由于其相對較少的輸入變量、簡單的網絡結構,因而在尋優速度與預測精度方面具有明顯優勢。
4 與傳統神經網絡模型的比較
為探討該網絡模型與傳統神經網絡在客運量預測方面的性能,這里將廣義回歸神經網絡(generalized regression neural network, GRNN)、BP網絡和本文模型同時對算例進行預測,對比分析其性能優劣。以均方根誤差最小化為原則確定GRNN其最優光滑因子(Spread)為0.4,BP網絡最優隱節點數為31,GRNN網絡隱層中心由K-MEANS聚類確定,隱層至輸出層權值由最小二乘法確定,其余網絡參數同PCA-GABP模型一致。具體仿真結果見表6。
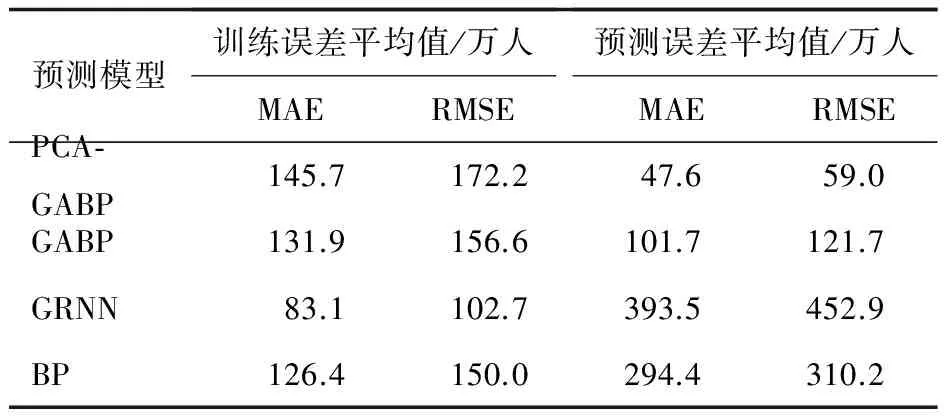
表6 不同網絡模型訓練及預測結果分析
由表6可知:沒有經過優化的BP網絡在訓練誤差上有一定的優勢,但在泛化性能上表現出較大劣勢,這是由于網絡誤差面的結構和學習算法特性使其容易陷于局部極小,且訓練結果還受到初始權值的影響,進而影響網絡性能。GRNN以結構簡單、訓練速度快等特點著稱,這里突出表現為較小的訓練誤差,但面對較多的輸入變量時,其經驗風險最小化的特點與過于簡單的學習算法會使其泛化性能較差。相比之下,結合了PCA方法的GABP網絡,在客運量預測方面表現出更強的泛化性能與較簡單的結構。
5 結 語
本文利用主成分分析技術對影響鐵路客運量的因素進行處理,將取出主成分并輸入到利用遺傳算法優化的BP網絡中,從而對客運量進行預測。實驗結果表明,該模型能有效降低輸入數據規模并且具有較好的訓練速度。不同模型的對比結果也說明該模型較一般網絡模型具有更好的預測精度,印證了其在客運量預測方面的優勢。由于這里使用的是各年份的數據,對于更細的客運量數據劃分如季度、月,該模型的預測能力尚不可知,有待繼續研究。
[1] 侯福均, 吳祈宗. BP神經網絡在鐵路客運市場時間序列預測中的應用[J]. 運籌與管理, 2003, 12 (4): 73-75.
[2] 潘迪夫,劉輝,李燕飛.風電場風速短期多步預測改進算法[J].中國電機工程學報, 2008, 28(26): 87-91.
[3] 李曉剛,賈元華,敖谷昌.基于主成分分析的公路客運量預測模型研究[J]. 公路標準化, 2009(5): 77-81.
[4] 芮海田,吳群琪,袁華智,等. 基于指數平滑法和馬爾科夫模型的公路客運量預測方法[J]. 交通運輸工程學報, 2013, 13(4): 87-92.
[5] 王卓,王艷輝,賈利民,等. 改進的BP神經網絡在鐵路客運量時間序列預測中的應用[J]. 中國鐵道科學,2005,26(2): 127-131.
[6] 吳偉,符卓,王曉.運輸通道客運量預測方法[J].鐵道科學與工程學報,2012,9(5): 96-102.
[7] SPECHT D F. A general regression neural network[J]. IEEE Transactions on Neural Works, 1991, 2(6): 568-576.
[8] 劉純,范高鋒,王偉勝,等.風電場輸出功率的組合預測模型[J].電網技術, 2009, 33(13): 74-79.
[9] 王學仁,王松桂.實用多元統計分析[M].上海:上海科學技術出版社,1990:270-344.
[10] 姚新勝,蘇延川,孫金玲. 公路客運短期運量預測研究[J]. 公路交通科技, 2005, 22(11): 155-158.
[11] 陸化普.交通規劃理論與方法[M]. 北京: 清華大學出版社, 1998:47-59.
[12] 楊洋.基于運輸一體化的區域交通運輸需求預測研究[D]. 長春: 吉林大學, 2006.
[13] 徐雅靜, 汪遠征.主成分分析應用方法的改進[J].數學實踐與認識,2006, 36(6):68-75.
[14] SANDHYA S.神經網絡在應用科學和工程中的應用—從基本原理到復雜的模式識別[M].史曉霞,譯.北京:機械工業出版社,2009: 7.
[15] 周松林,茆美琴,蘇建徽.基于主成分分析與人工神經網絡的風電功率預測[J]. 電網技術,2011,35(9):128-132.
(編輯:史海英)
Prediction of Railway Passenger Volume Based on PCA and GA-BP Network
YANG Qixuan
(Postgraduate Training Brigade, Military Transportation University, Tianjin 300161, China)
Considering numerous factors influencing railway passenger volume and complex mapping relation among variables, the paper firstly deals with the influencing factors with PCA (principal component analysis) method and reduces the dimension of related variables to eliminate multiple co-linear relations between variables. Then, it enters the converted variables into neural network model based on GA-BP and predicts the railway passenger volume. The simulation result shows that this model is more accurate and simpler than BP neural network model.
railway passenger volume prediction; PCA (principal component analysis); neural network
2016-04-19;
2016-09-02.
楊祺煊(1991—),男,碩士研究生.
10.16807/j.cnki.12-1372/e.2017.02.021
U491
A
1674-2192(2017)02- 0084- 06
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
