基于鏈表結(jié)構(gòu)的啟發(fā)式屬性約簡(jiǎn)算法
2016-09-26 07:29:46梁寶華
計(jì)算機(jī)應(yīng)用與軟件 2016年3期
關(guān)鍵詞:區(qū)域
梁 寶 華
(巢湖學(xué)院計(jì)算機(jī)與信息工程學(xué)院 安徽 合肥 238000)
?
基于鏈表結(jié)構(gòu)的啟發(fā)式屬性約簡(jiǎn)算法
梁 寶 華
(巢湖學(xué)院計(jì)算機(jī)與信息工程學(xué)院安徽 合肥 238000)
屬性約簡(jiǎn)是粗糙集理論研究的主要內(nèi)容之一,正區(qū)域計(jì)算是多數(shù)屬性約簡(jiǎn)算法的關(guān)鍵。為了減少正區(qū)域的計(jì)算時(shí)間,提出基于鏈表存儲(chǔ)的正區(qū)域計(jì)算方法。將屬性值相同的數(shù)據(jù)存儲(chǔ)在鏈表同一結(jié)點(diǎn)對(duì)象中,收集過程中不斷刪除基數(shù)為1的子劃分,通過降低樣本數(shù)據(jù)的規(guī)模來減少計(jì)算耗時(shí),加速屬性約簡(jiǎn)。同時(shí),給出不可區(qū)分對(duì)象對(duì)數(shù)定義,并以此度量屬性重要性,設(shè)計(jì)一種高效的啟發(fā)式屬性約簡(jiǎn)方法。通過實(shí)例和實(shí)驗(yàn)與經(jīng)典約簡(jiǎn)算法進(jìn)行性能測(cè)試比較,結(jié)果證實(shí)該算法在時(shí)間和空間效果上切實(shí)有效、可行。
粗糙集屬性約簡(jiǎn)鏈表正區(qū)域不可區(qū)分對(duì)象對(duì)數(shù)
0 引 言
RoughSet作為一種處理不確定、不精確數(shù)據(jù)的有力數(shù)學(xué)工具[1],已廣泛應(yīng)用于機(jī)器學(xué)習(xí)、模式識(shí)別和數(shù)據(jù)挖掘等領(lǐng)域。屬性約簡(jiǎn)是RoughSet研究的核心問題之一,也是知識(shí)獲取的關(guān)鍵步驟。在保持區(qū)分能力不變的情況下,用較少屬性表示數(shù)據(jù)集的特征。現(xiàn)有的屬性約簡(jiǎn)算法有基于正區(qū)域?qū)傩约s簡(jiǎn)算法[2]、基于信息熵的約簡(jiǎn)算法[3]、基于差別矩陣的屬性約簡(jiǎn)算法[4,5]及其他啟發(fā)式屬性約簡(jiǎn)算法[6,7,12]。
多數(shù)屬性約簡(jiǎn)算法先對(duì)挖掘的決策表進(jìn)行簡(jiǎn)化,因?yàn)榇诉^程效率高低影響整個(gè)算法的時(shí)間和空間性能。目前,求簡(jiǎn)化決策表效率較高的算法有文獻(xiàn)[2]基于基數(shù)排序的屬性約簡(jiǎn)算法,時(shí)間復(fù)雜度為O(|C‖U|)、基于文獻(xiàn)[8]快速排序思想的屬性約簡(jiǎn)算法,時(shí)間復(fù)雜度為O(|C‖U‖log(U)|)。為了更進(jìn)一步縮短求解簡(jiǎn)化決策表時(shí)間,本文提出基于鏈表結(jié)構(gòu)的快速求正區(qū)域方法,比文獻(xiàn)[2]的算法效率略有提高。在求解屬性約簡(jiǎn)過程中,本文采用不可區(qū)分對(duì)象對(duì)數(shù)的函數(shù),作為衡量屬性重要性的依據(jù),既達(dá)到差別矩陣算法的直觀性、易理解性的優(yōu)點(diǎn),又避免了差別矩陣需大量空間存儲(chǔ)信息矩陣的缺點(diǎn),提高了時(shí)間和空間處理效率。
1 相關(guān)概念
定義1一個(gè)信息系統(tǒng)IS=(U,A,V,f),其中U為所有挖掘?qū)ο蟮募希籄是所有屬性的集合,A=C∪D,C為條件屬性集,D為決策屬性集,V為全體屬性的值域集,f為U×A→V的信息函數(shù),定義f(x,a)為x在屬性a上的對(duì)應(yīng)值。若P?A,則不可分辨關(guān)系為:
IND(P)={(x,y)∈U×U|?a∈P,f(x,a)=f(y,a)},構(gòu)成U的一個(gè)劃分用U/IND(P)。
定義2給定決策表T=(U,A,V,f),對(duì)于任意子集X?U和不可分辨關(guān)系IND(P):
下近似:
(1)
上近似:
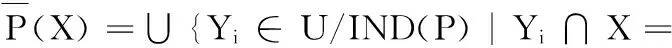
(2)
定義3決策表T=(U,A,V,f)中,P?C,D的P正區(qū)域記為:
(3)
定義4決策表T=(U,A,V,f)中,P?C,D的P負(fù)區(qū)域記為:
NEGP(D)=U′-POSP(D)
(4)
其中U′為簡(jiǎn)化后的無(wú)重復(fù)數(shù)據(jù)。
定義5[4]在簡(jiǎn)化決策表T′=(U′,C,D,V,f)中,決策表的分明矩陣(簡(jiǎn)稱簡(jiǎn)化分明矩陣)M′=mi,j,其元素定義如下:
(5)
性質(zhì)1設(shè)P?C,|U/Pi|=1,則U/Pi中的元素均屬于正區(qū)域POSP(D)。
證明:由IND(P)定義可知,若x1∈U,x2∈U∧f(x1,P)=f(x2,P),則x1、x2屬于同類劃分,若f(x1,D)=f(x2,D),則由POSP(D)定義可知,x1、x2屬于正區(qū)域元素,否則,屬于負(fù)區(qū)域元素。因?yàn)閨U/Pi|=1,所以,U/P的第i個(gè)劃分中只有一個(gè)元素,設(shè)此元素為x。假設(shè)x屬于負(fù)區(qū)域,則可找到另一元素y,使得f(x,P)=f(y,P)且f(x,D)≠f(y,D),但x∈U/Pi∧|U/Pi|=1,說明f(x,P)是唯一的,所以上述假設(shè)不成立,故x必屬于正區(qū)域元素。證畢。
2 快速計(jì)算正、負(fù)區(qū)域算法及其分析
2.1快速求正、負(fù)區(qū)域算法(算法1)
屬性約簡(jiǎn)過程,大體進(jìn)行三步:(1) 數(shù)據(jù)預(yù)處理,將數(shù)據(jù)離散化;(2) 將決策表簡(jiǎn)化(可得到相應(yīng)的正、負(fù)區(qū)域);(3) 屬性約簡(jiǎn)。由此可知,簡(jiǎn)化決策表是屬性約簡(jiǎn)過程的關(guān)鍵環(huán)節(jié)。若能得到有效的簡(jiǎn)化決策表,可減少約簡(jiǎn)的搜索空間。為了快速、有效得到簡(jiǎn)化決策表,很多學(xué)者做了相關(guān)研究,效果較好的有文獻(xiàn)[2,6]。其中,文獻(xiàn)[2]的基數(shù)排序算法每次對(duì)數(shù)據(jù)收集時(shí)未能將已區(qū)分對(duì)象進(jìn)行剪枝,后期約簡(jiǎn)未能充分利用前期結(jié)果,浪費(fèi)大量時(shí)間。
對(duì)數(shù)據(jù)存儲(chǔ)的常見形式有數(shù)組和鏈表,數(shù)組便于查找,找一個(gè)元素的時(shí)間復(fù)雜度為O(1),但數(shù)組不便于插入與刪除。對(duì)于有n個(gè)元素的數(shù)組來說,要?jiǎng)h除數(shù)組中第i個(gè)元素,為了節(jié)省空間,要騰出第i個(gè)位置的空間,由于數(shù)組間元素是連續(xù)存儲(chǔ)的,所以需將第i+1個(gè)后面的所有元素均依次向前移動(dòng)一個(gè)位置,然后刪除第n個(gè)元素所在的空間,平均時(shí)間復(fù)雜度為O(n/2)。若采用鏈表方式存儲(chǔ),刪除一個(gè)元素需O(1)時(shí)間即可。
在求正、負(fù)區(qū)域及簡(jiǎn)化決策表時(shí),對(duì)于U/P(P?C)的劃分中基數(shù)為1的子劃分對(duì)象為可區(qū)分對(duì)象,無(wú)需參與下一步的劃分過程,應(yīng)將此對(duì)象加入正區(qū)域集,并在U中刪除此對(duì)象。為了方便刪除操作,可利用鏈表的結(jié)構(gòu)特征,這樣可有效加速求簡(jiǎn)化決策表的進(jìn)度和減少搜索空間。算法1具體描述如下:
算法中涉及到的鏈表結(jié)點(diǎn)數(shù)據(jù)結(jié)構(gòu)為:
structList{
data;
//數(shù)據(jù)在條件屬性Ci上的取值
set;
//在Ci上取值data的數(shù)據(jù)集合
count;
//為集合set的數(shù)據(jù)個(gè)數(shù)
next;
//下一指針
}
輸入:U,C,D
輸出:簡(jiǎn)化決策表U′,POS,NEG
Step1初始化條件U′=U;POS=?,NEG=?;
Step2將決策表按條件屬性C1進(jìn)行劃分,將樣本在C1上取值相同的結(jié)點(diǎn)存儲(chǔ)同一子劃分中,并用鏈表List連接所有子劃分。
Step3for(i= 2 toi< |C|){
Step3.1將List中的每個(gè)結(jié)點(diǎn)元素,按條件屬性Ci劃分,同類的樣本編號(hào)放在同一結(jié)點(diǎn)的set中,若產(chǎn)生了新的加細(xì)劃分,則相應(yīng)產(chǎn)生新結(jié)點(diǎn)。
Step3.2連接鏈表,但要對(duì)子劃分基數(shù)為1的劃分加入POS中,且在List中刪除此結(jié)點(diǎn),實(shí)現(xiàn)剪枝。
Step4掃描鏈表List的每個(gè)結(jié)點(diǎn),若某結(jié)點(diǎn)的set中數(shù)據(jù)有D值不同的,則選擇set中第一個(gè)數(shù)據(jù)加入NEG,否則加入POS。
Step5POS并NEG得到簡(jiǎn)化決策表U′。
2.2算法1時(shí)間和空間復(fù)雜度分析
算法1的step1的時(shí)間復(fù)雜度為O(1);Step2的時(shí)間復(fù)雜度為O(|U|);Step3的時(shí)間復(fù)雜度為max(O((|C|-1)×(|U′|+|Ci|))),其中Step3.1的時(shí)間復(fù)雜度O(|U′|),由于U′在劃分過程中,不斷剪枝,所以|U′|≤|U|;Step3.2的時(shí)間復(fù)雜度為|Ci|;Step4的為O(|U′|),因?yàn)樽詈驦ist中鏈表的結(jié)點(diǎn)個(gè)數(shù)與簡(jiǎn)化決策表中的元素個(gè)數(shù)相同,掃描List每個(gè)結(jié)點(diǎn)所需時(shí)間為O(|U′|);Step5的為O(1),僅僅是將POS與NEG合并。
綜上所得,時(shí)間復(fù)雜度為:
O(|U|)+ O(|U′|)+max(O((|C|-1)×(|U′|+|Ci|)))
由于|U′|≤|U|,且|U′|越來越小,故時(shí)間復(fù)雜度為O(|C‖U|)。
算法所需的空間,鏈表中共有的結(jié)點(diǎn)數(shù)實(shí)現(xiàn)就是樣本按條件屬性C劃分得到的子劃分個(gè)數(shù),即O(|U/C|),而每個(gè)結(jié)點(diǎn)4個(gè)成員,其中data、count和next共需空間O(4×|U/C|),最終簡(jiǎn)化決策表空間O(|U/C‖C|),所以空間復(fù)雜度為max(O(4×|U/C|),O(|U/C‖C|))。
3 啟發(fā)式屬性約簡(jiǎn)算法
3.1屬性重要性度量
在進(jìn)行數(shù)據(jù)約簡(jiǎn)時(shí),通常先計(jì)算屬性重要性,并以此為啟發(fā)式信息選擇最易區(qū)分的屬性加入約簡(jiǎn)集。差別矩陣算法以對(duì)象間可區(qū)分的屬性出現(xiàn)的頻率作為依據(jù),選擇屬性,此類算法直觀、易理解,但需浪費(fèi)大量的空間。為此,許多學(xué)者關(guān)注于改進(jìn)差別矩陣[9-11],試圖減少差別矩陣元素。根據(jù)定義5可知,改進(jìn)差別矩陣表中,正區(qū)域中所有按D劃分屬于不同子劃分的數(shù)據(jù)進(jìn)行比較,所有負(fù)區(qū)域中的每個(gè)數(shù)據(jù)與正區(qū)域的每個(gè)數(shù)據(jù)進(jìn)行比較,但負(fù)區(qū)域中的所有數(shù)據(jù)相互間無(wú)需比較。與經(jīng)典的差別矩陣相比,元素個(gè)數(shù)大大減少,但數(shù)據(jù)量還是比較龐大。經(jīng)研究發(fā)現(xiàn),可借助差別矩陣的直觀性等優(yōu)點(diǎn),但無(wú)需建立差別矩陣方法。

(6)
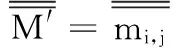
(7)
性質(zhì)2根據(jù)定義5的改進(jìn)差別矩陣,對(duì)于某具體的簡(jiǎn)化決策表,其差別矩陣中元素個(gè)數(shù)一定,設(shè)為Mcount,則:

(8)
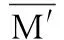
(9)

3.2啟發(fā)式屬性約簡(jiǎn)算法(算法2)
以不可區(qū)分對(duì)數(shù)DM(Ci)為啟發(fā)式信息,設(shè)計(jì)屬性約簡(jiǎn)算法(算法2),具體如下:
structDList{
data;
//數(shù)據(jù)在條件屬性Ci上的取值
List;
//在Ci上取值data的數(shù)據(jù)集合
count;
//為集合List中的數(shù)據(jù)個(gè)數(shù)
structDList*next;
//下一指針
}
輸入:簡(jiǎn)化決策表U′,POS,NEG
輸出:Core
Step1初始化C′=C,Core=?,Count=0;
Step2while(Count++<|C|‖DList!=NULL) {foreachCiinC′ {
Step2.1求U′/Ci,且用DList鏈表存儲(chǔ)每個(gè)子劃分且按D進(jìn)行劃分,再按條件屬性取不同值建立不同的List鏈表,并將List.count為0的結(jié)點(diǎn)刪除;
Step2.2計(jì)算DM(Ci);對(duì)DList.count數(shù)是0的結(jié)點(diǎn)剪枝。
Step2.3計(jì)算Min(DM(Ci)),C′=C=Ck,
Core=Core∪CK//Ck為取值最小的條件屬性
}
}
Step3輸出Core;
算法2的主要時(shí)間用在求屬性重要度量方面。在求DM(Ci)時(shí),主要掃描DList鏈表,DList的長(zhǎng)度即為條件屬性Ci劃分所得的等價(jià)類數(shù)目|U′/Ci|,每個(gè)子劃分再按決策屬性D劃分,最好情況下是一個(gè)條件屬性就可將所有樣本區(qū)分,時(shí)間復(fù)雜度為:
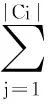
4 算法實(shí)例與實(shí)驗(yàn)分析
4.1算法實(shí)例
4.1.1求正、負(fù)區(qū)域及簡(jiǎn)化決策表過程
為進(jìn)一步說明上述算法原理,下面用表1所示的數(shù)據(jù)介紹算法運(yùn)行過程。
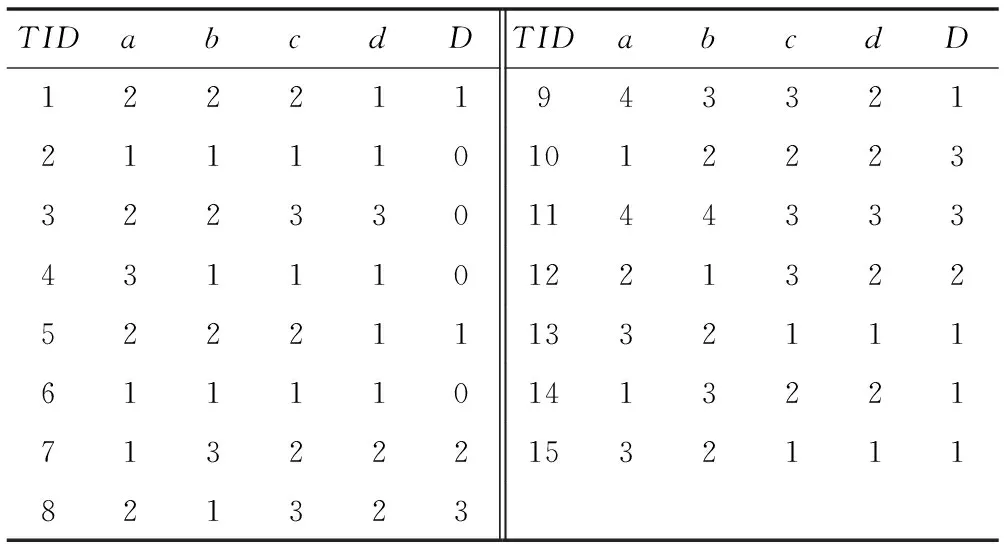
表1 決策表U
(1)POS=?,NEG=?;
(2)U/a分四類,構(gòu)成的DList鏈表為:
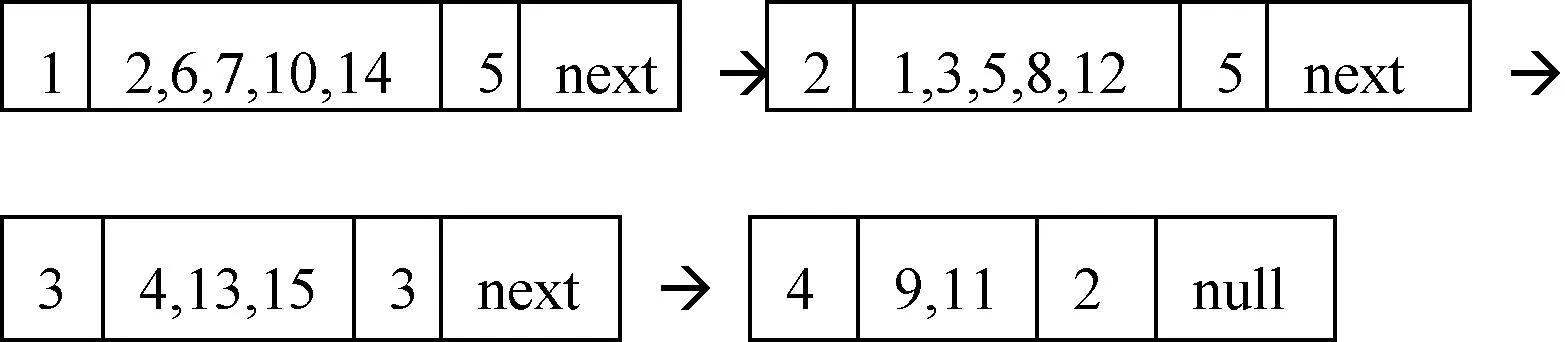
(3) 在(2)基礎(chǔ)上將各結(jié)點(diǎn)中的樣本按條件屬性b進(jìn)行劃分,并建立相應(yīng)的鏈表得到:
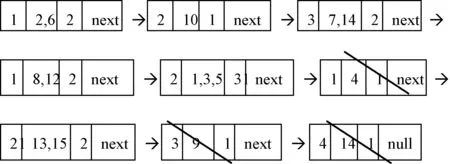
根據(jù)性質(zhì)1可知,U中的10、4、9、11數(shù)據(jù)已經(jīng)在鏈表中刪除,同時(shí)加入了POS中,即POS={4,9,10,11};
(4) 同理可得,繼續(xù)按條件屬性c、d劃分得到:

POS={3,4,9,10,11};
(5) 再將List中各結(jié)點(diǎn)的數(shù)據(jù)進(jìn)行按D值劃分,若有D值不同的,則將結(jié)點(diǎn)中的第一個(gè)數(shù)據(jù)樣本加入到NEG中,否則加入到POS中,得到NEG={7,8};POS={1,2,3,4,9,10,11,13};U′的樣本數(shù)據(jù)為{1,2,3,4,7,8,9,10,11,13},具體簡(jiǎn)化決策表如表2所示。

表2 簡(jiǎn)化決策表U′
對(duì)于決策表U,采用文獻(xiàn)[2]方法,每個(gè)條件屬性需按關(guān)鍵字收集,包括屬性共4個(gè),需比較次數(shù)60,移動(dòng)60次,得到U/C;最后再按決策屬性D不同值收集,將C值相同而D值不同的所有子劃分中第一個(gè)元素加入NEG,將C值相同且D值也相同的所有子劃分第一個(gè)元素加入POS中,需比較15次,10次移動(dòng),總共需145次。若采用本文算法1,按屬性a收集需15次比較,15次移動(dòng),再按屬性b、c和d收集,分別需比較次數(shù)11、10和10,共46次比較,移動(dòng)次數(shù)即為刪除結(jié)點(diǎn)次,故需5次;此時(shí),已有5個(gè)結(jié)點(diǎn)在POS中,再將U/C的5個(gè)子劃分中元素進(jìn)行比較,需5次比較5次移動(dòng)得到POS和NEG,共56次比較和移動(dòng)。
4.1.2屬性約簡(jiǎn)過程
在上述簡(jiǎn)化決策表、正負(fù)區(qū)域基礎(chǔ)上,建立DList鏈表得:
(1)DList(a):
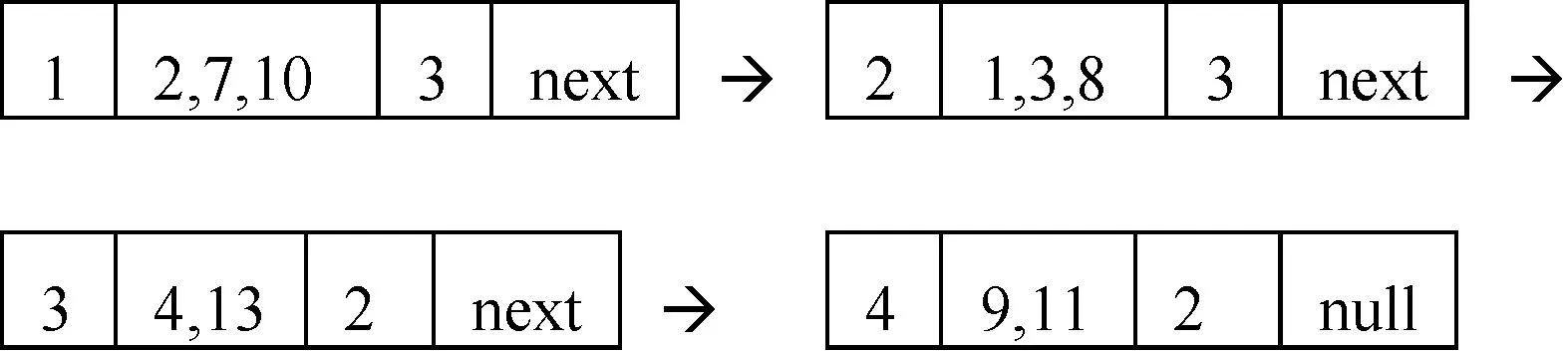
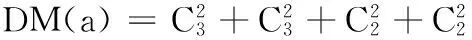
DList(b):
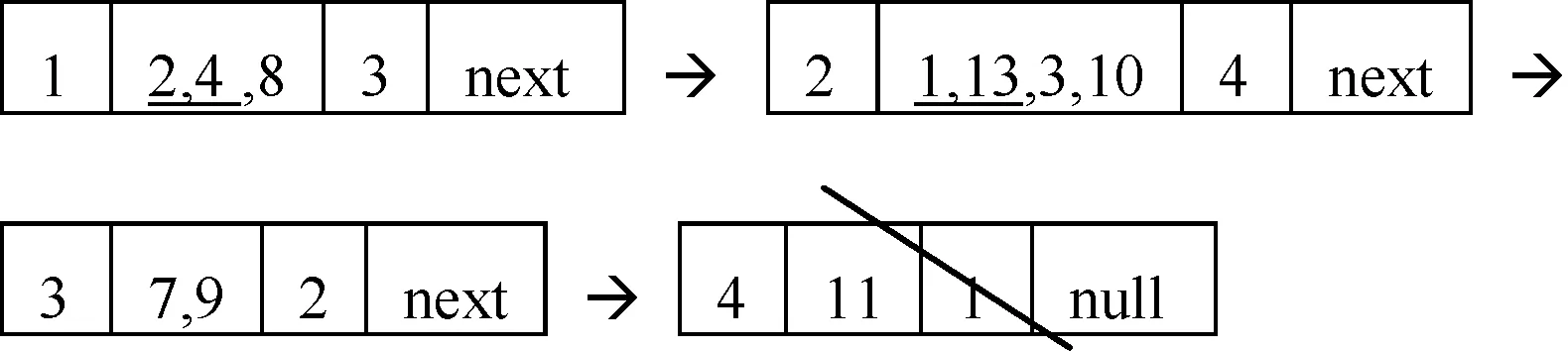
子劃分中帶下劃線的表明按D劃分屬于同類的。且最后一個(gè)結(jié)點(diǎn)被刪除,因?yàn)槠鋍ount為1。
DList(c):

DList(d):
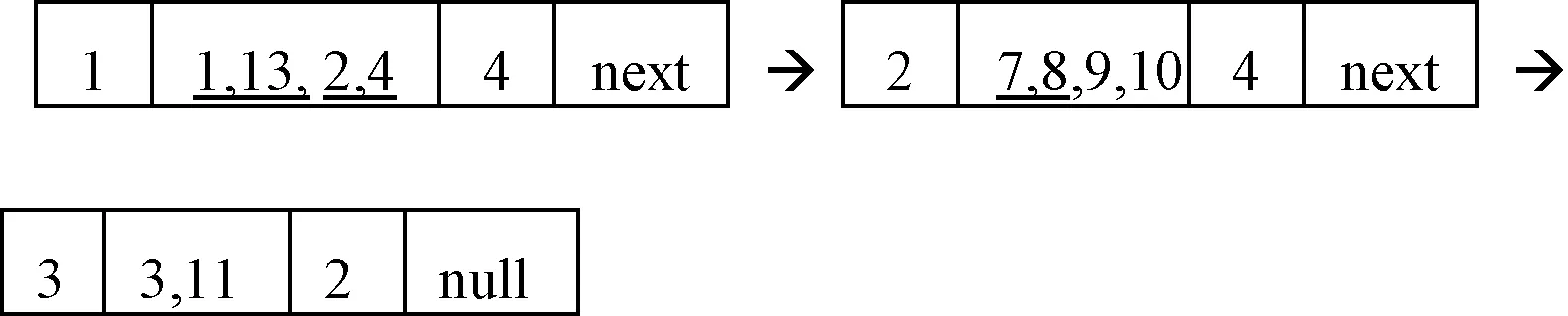
Min(DM(a),DM(b),DM(c),DM(d))=8,所以選a或b屬性加入Core。
(2) 設(shè)第一個(gè)選擇的屬性為b,則將DList(b)繼續(xù)按屬性a、c或d劃分,得到:



DM(b,d)= 0+0=0,所以將d加入Core,此時(shí)所有樣本已經(jīng)區(qū)分,故約簡(jiǎn)集為Core={b,d}。同理可得,其他約簡(jiǎn)集有{a,b,c}。
4.2實(shí)驗(yàn)分析
求解簡(jiǎn)化決策表、正負(fù)區(qū)域是屬性約簡(jiǎn)的關(guān)鍵環(huán)節(jié),現(xiàn)將算法[1]與文獻(xiàn)[2]算法進(jìn)行比較。在AMDAthlonⅡX2 2402.78GHz,RAM1.5G,VC6.0環(huán)境下編程,采用UCI數(shù)據(jù)庫(kù)中5個(gè)數(shù)據(jù)集為測(cè)試數(shù)據(jù)(D1:forestfires,D2:adult,D3:abalone,D4:mushroom,D5:poker_hand),其中正區(qū)域記錄數(shù)為Pi,負(fù)區(qū)域記錄數(shù)為Ni,簡(jiǎn)化表記錄數(shù)為Si),執(zhí)行過程中數(shù)據(jù)對(duì)比情況如表3所示。
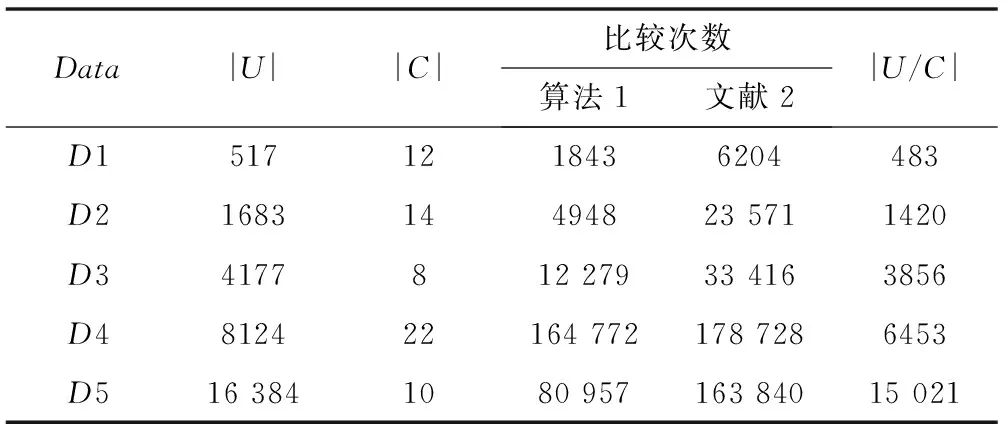
表3 求U/C記錄比較對(duì)照表
由表3可知,因選擇的各數(shù)據(jù)集除D1有少量重復(fù)數(shù)據(jù)外,其他的測(cè)試數(shù)據(jù)均無(wú)重復(fù)數(shù)據(jù),所以D2、D3、D4和D5數(shù)據(jù)簡(jiǎn)化前后無(wú)變化,且正區(qū)域的記錄數(shù)等于簡(jiǎn)化決策表的樣本數(shù)。雖然算法1與文獻(xiàn)[2]求正區(qū)域的時(shí)間復(fù)雜度均為O(|C‖U|),但算法1在求解時(shí)不斷剔除已區(qū)分的樣本。對(duì)于D2共15個(gè)屬性,收集過程中第2個(gè)屬性加入時(shí)已有107條數(shù)據(jù)可區(qū)分,第3個(gè)屬性加入時(shí)有1675條數(shù)據(jù)區(qū)分,到第4個(gè)屬性時(shí)已區(qū)分所有樣本,其余屬性就無(wú)需繼續(xù)比較,所用時(shí)間相當(dāng)于文獻(xiàn)[2]的1/5。對(duì)于D4,效果不明顯,將前10個(gè)屬性逐趟收集,幾乎沒有可區(qū)分對(duì)象,直至第21個(gè)屬性加入時(shí)有3764條數(shù)據(jù)已區(qū)分,導(dǎo)致求解效果不明顯。由此可看出,在按條件屬性不同值收集時(shí),若某屬性的加入能夠區(qū)分的樣本越多,采用算法1時(shí),求正、負(fù)區(qū)域的速度越快,因?yàn)樗惴?對(duì)已區(qū)分的樣本進(jìn)行修剪,不參加下次的運(yùn)算,減少搜索空間。
算法1的優(yōu)勢(shì)體現(xiàn)在求正區(qū)域上,在算法1的基礎(chǔ)上,利用算法2對(duì)數(shù)據(jù)進(jìn)行屬性約簡(jiǎn)。算法2利用了差別矩陣算法的直觀性、可理解性,但又沒有差別矩陣算法所需的大量空間,所以算法2的優(yōu)勢(shì)又表現(xiàn)在空間的開銷上。同樣,用D1-D5的數(shù)據(jù)進(jìn)行實(shí)驗(yàn),得到算法2、文獻(xiàn)[2]算法和文獻(xiàn)[10]算法進(jìn)行比較,如圖1所示。
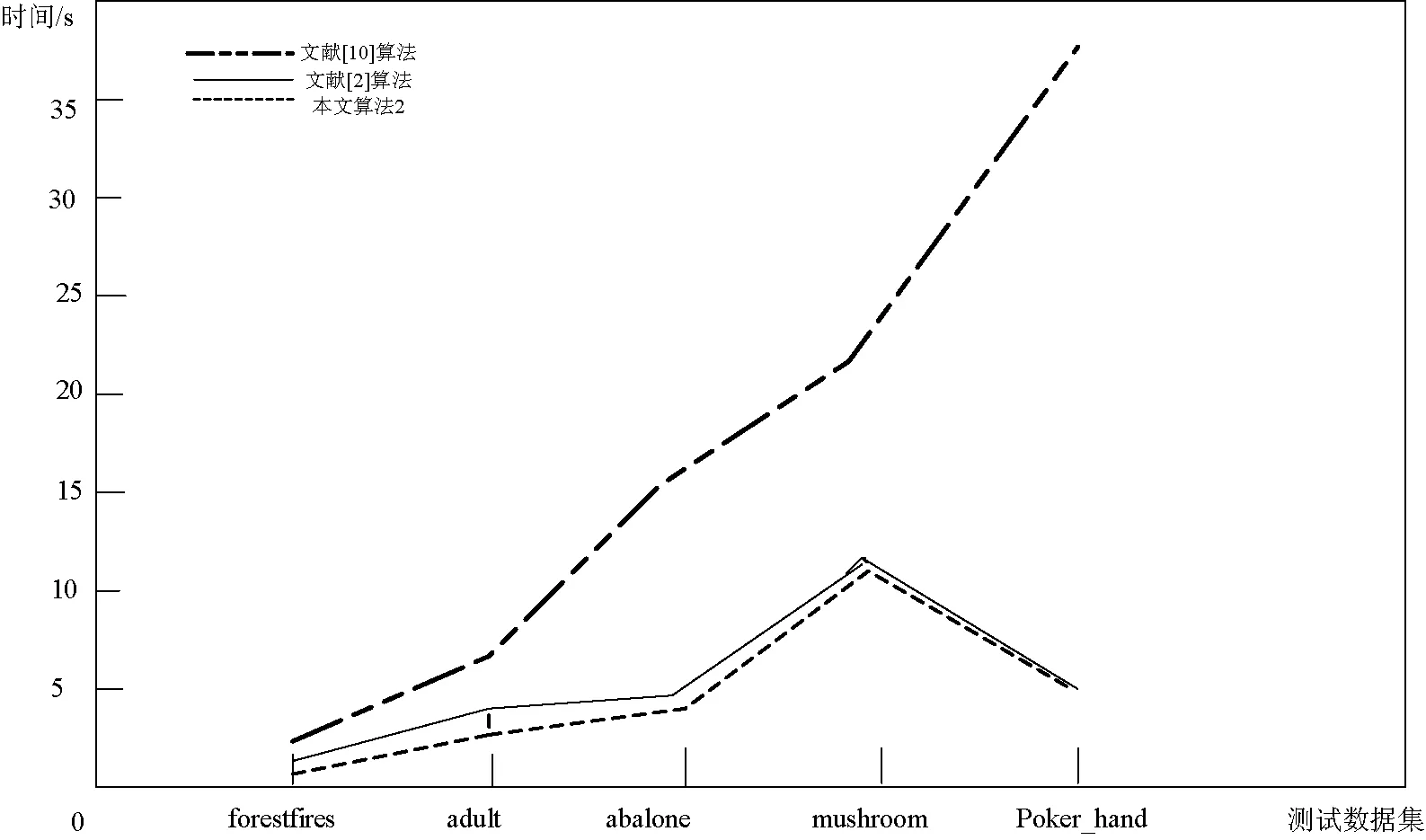
圖1 各種算法時(shí)間性能對(duì)比
由圖1可知,算法2比文獻(xiàn)[2]算法略有提高,是因?yàn)樵谟?jì)算正區(qū)域時(shí),能夠有效剔除已區(qū)分的樣本,且明顯較文獻(xiàn)[10]算法的約簡(jiǎn)時(shí)間效果好。從圖中還可得,當(dāng)|U|越大,且|C|越小時(shí),文獻(xiàn)[10]算法越顯得不足。在|U‖C|較小時(shí),算法2比文獻(xiàn)[2]算法挖掘時(shí)間效果顯示明確,但隨著數(shù)據(jù)對(duì)象個(gè)數(shù)及條件屬性個(gè)數(shù)增加,算法2的優(yōu)勢(shì)越來越不明顯。在對(duì)樣本D4、D5運(yùn)算時(shí),出現(xiàn)了挖掘時(shí)間呈下降趨勢(shì),而文獻(xiàn)[10]一起呈上升趨勢(shì),是因?yàn)槲墨I(xiàn)[10]的時(shí)間復(fù)雜度為O(|U|2|C|),它隨著|U|的增加,時(shí)間增速較文獻(xiàn)[2]和算法2要快。
空間上,算法2較文獻(xiàn)[10]也有優(yōu)勢(shì),具體如表4所示。

表4 多種算法空間占用比較
所示(Spacei為各算法所需空間,以MB為單位;RLi為各算法約簡(jiǎn)后的屬性個(gè)數(shù))。由表4可知,算法2在空間效果上比文獻(xiàn)[10]也有很大改觀。主要是因?yàn)槲墨I(xiàn)[10]需大量空間存儲(chǔ)二進(jìn)制的信息矩陣。
5 結(jié) 語(yǔ)
屬性約簡(jiǎn)過程中,正區(qū)域計(jì)算是很多屬性約簡(jiǎn)算法必不可少的一步。通過對(duì)正、負(fù)區(qū)域的計(jì)算,可得到簡(jiǎn)化決策表,剔除冗余數(shù)據(jù),加速屬性約簡(jiǎn)進(jìn)度。文獻(xiàn)[2]的基數(shù)排序算法雖然效率較高,但未能在求簡(jiǎn)化決策表過程中進(jìn)行剪枝,本文算法1可有效得到正、負(fù)域及簡(jiǎn)化決策表,且效率比文獻(xiàn)[2]的算法略高。在求屬性重要性度量時(shí),引入DM(Ci)概念,充分利用差別矩陣算法的直觀、易理解的優(yōu)點(diǎn),但又無(wú)需建立信息矩陣,大大減少存儲(chǔ)空間。但目前的這些算法,只是針對(duì)靜態(tài)數(shù)據(jù)庫(kù),而現(xiàn)實(shí)世界是不斷變化的,下一步是如何適應(yīng)動(dòng)態(tài)數(shù)據(jù)庫(kù)的屬性約簡(jiǎn)。
[1]PawlakZ.Roughsets[J].InternationalJournalofComputerandInformationScience,1982,11(5):341-356.
[2] 徐章艷,劉作鵬.一個(gè)復(fù)雜度為的快速屬性約簡(jiǎn)算法[J].計(jì)算機(jī)學(xué)報(bào),2006,29(3):391-399.
[3] 王國(guó)胤,于洪,楊大春.基于條件信息熵的決策表約簡(jiǎn)[J].計(jì)算機(jī)學(xué)報(bào),2002,25(7):759-766.
[4] 楊明.一種基于改進(jìn)差別矩陣的屬性約簡(jiǎn)增量式更新算法[J].計(jì)算機(jī)學(xué)報(bào),2007,30(5):815-822.
[5] 錢文彬,楊炳儒,徐章艷,等.基于差別矩陣的不一致決策表規(guī)則獲取算法[J].計(jì)算機(jī)科學(xué),2013,40(6):215-218.
[6] 梁寶華,汪世義,蔡敏.基于順序表的啟發(fā)式屬性約簡(jiǎn)算法[J].計(jì)算機(jī)工程,2012,38(2):51-53.
[7] 張文修,米據(jù)生,吳偉志.不協(xié)調(diào)目標(biāo)信息系統(tǒng)的知識(shí)約簡(jiǎn)[J].計(jì)算機(jī)學(xué)報(bào),2003,26(1):12-18.
[8] 劉少輝,盛秋戩,吳斌,等.Rough集高效算法的研究[J].計(jì)算機(jī)學(xué)報(bào),2003,26(5):524-529.
[9] 葛浩,李龍澍,楊傳健.基于簡(jiǎn)化差別矩陣的增量式屬性約簡(jiǎn)[J].四川大學(xué)學(xué)報(bào):工程科學(xué)版,2013,45(1):116-124.
[10] 楊傳健,葛浩,李龍澍.垂直劃分二進(jìn)制可分辨矩陣的屬性約簡(jiǎn)[J].控制與決策,2013,28(4):563-569.
[11] 黃國(guó)順,曾凡智,陳廣義,等.基于區(qū)分能力的HU差別矩陣屬性約簡(jiǎn)算法[J].小型微型計(jì)算機(jī)系統(tǒng),2012,33(8):1800-1804.
[12] 葛浩,李龍澍,楊傳健.基于差別集的啟發(fā)式屬性約簡(jiǎn)算法[J].小型微型計(jì)算機(jī)系統(tǒng),2013,34(2):380-385.
HEURISTICSATTRIBUTEREDUCTIONALGORITHMBASEDONLISTSTRUCTURE
LiangBaohua
(Institute of Computer and Information Engineering,Chaohu University,Hefei 238000,Anhui,China)
Attributereductionisoneofmaincontentsinroughsettheoryresearch,andpositiveregioncalculationisthekeyofmostattributereductionalgorithms.Inordertoreducethetimeofpositiveregioncalculation,weproposedtheliststorage-basedpositiveregioncalculationmethod.Themethodstoresthedatawithsameattributevaluetosamenodedataoflist,duringthedatacollectingperiod,itcontinuouslydeletesthesubdivisionswith1astheircardinalnumber,byreducingthescaleofsampledataitdecreasescalculationtimeconsumptionandspeedsuptheattributereduction.Atthesametime,wegavethedefinitionofthenumberofpairsofindistinguishabledata,andusedittomeasureattributeimportance,anddesignedanefficientheuristicattributereductionalgorithm.Bytestingandcomparingtheperformancesofexamplesandexperimentswiththatofclassicalreductionalgorithm,theresultsprovedthatthismethodwaseffectiveandfeasibleintemporalandspatialeffects.
RoughsetAttributereductionListPositiveregionPairsnumberofindistinguishabledata
2014-10-15。國(guó)家自然科學(xué)基金項(xiàng)目(60573174);安徽省高等學(xué)校省級(jí)自然科學(xué)研究項(xiàng)目(KJ2013Z231)。梁寶華,副教授,主研領(lǐng)域:粗糙集,數(shù)據(jù)挖掘。
TP181
ADOI:10.3969/j.issn.1000-386x.2016.03.061
猜你喜歡
發(fā)明與創(chuàng)新·小學(xué)生(2021年3期)2021-03-25 11:48:49
科學(xué)(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學(xué)輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農(nóng)墾科技(2016年2期)2016-08-21 13:50:16
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
新疆財(cái)經(jīng)大學(xué)學(xué)報(bào)(2015年3期)2015-12-10 03:49:15
