基于結構特征和元模型的中文表格語義分析方法
2016-09-26 07:31:07張家銳
計算機應用與軟件 2016年3期
張家銳 張 涵
1(合肥學院計算機科學與技術系 安徽 合肥 230601)2(赫特福德大學生命與醫藥科學系 英國 赫特福德郡 AL10 9AB)
?
基于結構特征和元模型的中文表格語義分析方法
張家銳1張涵2
1(合肥學院計算機科學與技術系安徽 合肥 230601)2(赫特福德大學生命與醫藥科學系英國 赫特福德郡AL10 9AB)
針對現有技術對中文表格語義分析不夠全面的現實,提出基于結構特征和元模型的語義分析方法。使用具有公知性的一階謂詞函數Value(值函數)、Num(數量函數),結合偽編碼,對幾類最常見的中文表格進行語義分析,獲取了中文表格的表面語義、上下文語義、主-子表之間的限制語義、表附屬性對表格數據的附加語義、屬性值背后隱藏的關系語義。實例驗證的結果表明,結構特征和元模型是中文表格語義分析的有效方法,獲取的語義信息量和種類遠超目前的方法。
結構特征元模型一階謂詞函數表面語義上下文語義限制語義附加語義關系語義
0 引 言
中文表格是中文書面文本中最常見的元素之一,具有比普通文字語言更高的精確性和簡捷性,在很多領域相關的文本中,經常會使用表格來增強可閱讀性、可理解性。因此,對中文表格進行語義分析是中文自然語言理解中不可或缺的部分。中文表格人工理解很方便,機器辨識很困難。目前,對中文表格的語義分析,多數是將研究對象限定為Web頁面中基于HTML標簽的電子表格,方法大致有如下幾種[1]:內容樹[2,3]、基于本體使用隱馬爾可夫模型[4]、領域本體[5]、啟發式規則[6]、正則表達式匹配[7]、基于集成的半自動化方法[8]、人工解釋表格結構的半自動化方法[9],目的是通過語義抽取表格數據。在利用表格的半結構化特征來獲取其語義方面,楊海濤[10]按表頭的形態把表格分為:典型關系表格、可規范的關系表格、帶指標森林表頭的表格。賴中華[11]提出列分割、嵌套列表頭跨度識別、行分段、單位識別、表格展開方式識別和表格標題識別的表格結構識別方法,把表格的物理結構規整化到邏輯結構后解讀其語義。陳競波[12]運用報表數據語義對象化處理技術,對報表數據與報表結構進行解耦,將報表數據與其語義信息封裝成語義對象,并通過報表公式來描述數據對象之間的運算或約束關系。馮曉晨[13]的研究重點是表格屬性之間的關系(同義/概念分類/特性關系/值的類屬模式等)語義。尹文生[14]通過建立屬性取值的識別規則和語義脈絡樹來獲取表格的值語義。總之,目前的方法只對表格的表面語義(值語義)進行分析[10,11,13,14],雖然文獻[12]加入了表格的運算和約束語義,但表格的上下文語義、主-子表間的限制語義、表附屬性對表格的附加語義、表內屬性值之間的關系語義皆未被考慮。鑒于此,針對中文書面文本中幾類常見的中文表格,在以文獻[10,11]方法進行表格樣式解析的前提下,提出一種基于結構特征和元模型的中文表格語義分析方法,便于獲得中文表格更全面的語義,希望能部分彌補目前方法的不足。
1 常見的中文表格類型
中文表格雖然不像中文文本語句那樣豐富多彩、充滿限制和歧義,但其類別繁多、難以窮盡,所以至今也沒有一種標準的分類方法,本文僅面向應用中最典型、最常見的幾類中文表格進行研究。
定義1欄目的值與且僅與某一個屬性及其約束相關的表格為一維表格。如表1所示。
表1單位及信息專管員基本信息表
單位蓋章:
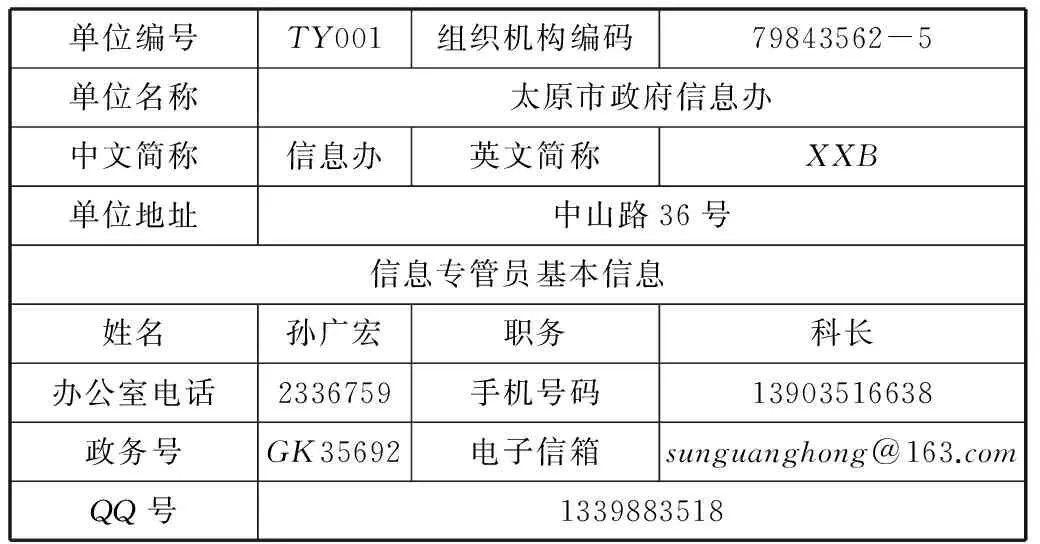
單位編號TY001組織機構編碼79843562-5單位名稱太原市政府信息辦中文簡稱信息辦英文簡稱XXB單位地址中山路36號信息專管員基本信息姓名孫廣宏職務科長辦公室電話2336759手機號碼13903516638政務號GK35692電子信箱sunguanghong@163.comQQ號1339883518
填表人:王擁軍填表日期:2014-04-08
定義2欄目的值與且僅與橫、縱兩個屬性及其約束相關,且這兩個屬性之間一般有“定語+名詞”或“定語+數詞”或“定語+量詞”構成關系的表格為二維表格。如表2所示。
表2某項目設備預算表
填表日期:2014年5月16日貨幣單位:元
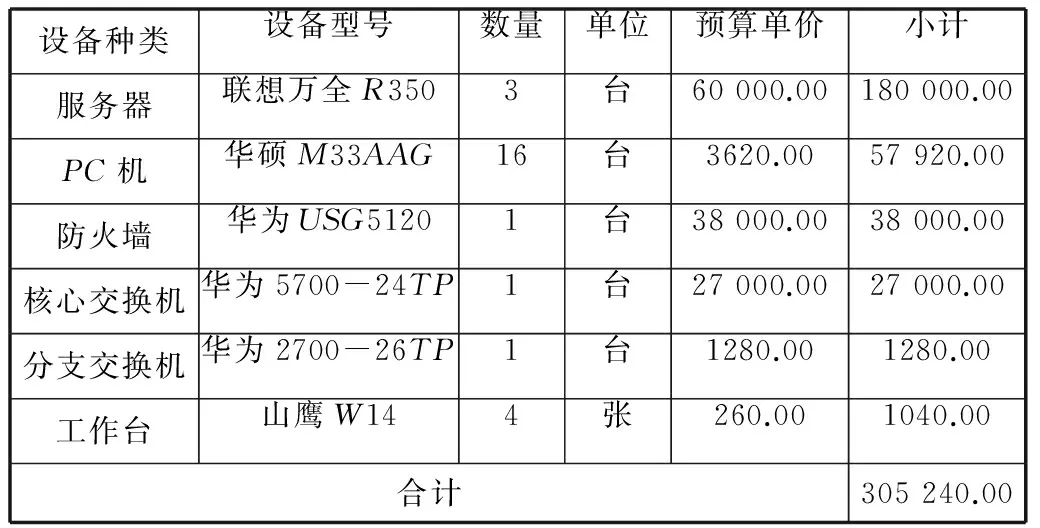
設備種類設備型號數量單位預算單價小計服務器聯想萬全R3503臺60000.00180000.00PC機華碩M33AAG16臺3620.0057920.00防火墻華為USG51201臺38000.0038000.00核心交換機華為5700-24TP1臺27000.0027000.00分支交換機華為2700-26TP1臺1280.001280.00工作臺山鷹W144張260.001040.00合計305240.00
定義3在一維表格中嵌入了另一個表格,該表格與被嵌入的表格之間構成了主-子(master-detail)關系,且一般被嵌入的表格是二維表格,此類表格稱為具有主-子關系的一維表格。如表3所示。
表3某公司員工信息表
填表日期:2014-07-01
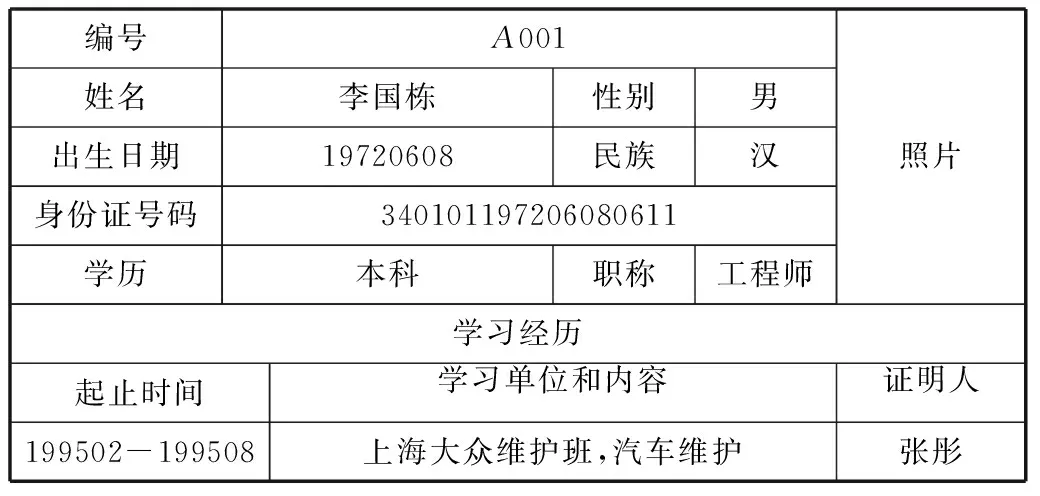
編號姓名出生日期身份證號碼學歷A001李國棟性別男19720608民族漢340101197206080611本科職稱工程師照片學習經歷起止時間學習單位和內容證明人199502-199508上海大眾維護班,汽車維護張彤

續表1
定義4在二維表格中嵌入了另一個表格,該表格與被嵌入的表格之間構成了主-子關系,同樣,被嵌入的表格一般也是二維表格。此類表格稱為具有主-子關系的二維表格。如表4和表5所示。
表4某集團公司月度考勤統計表
統計年月:2014年5月
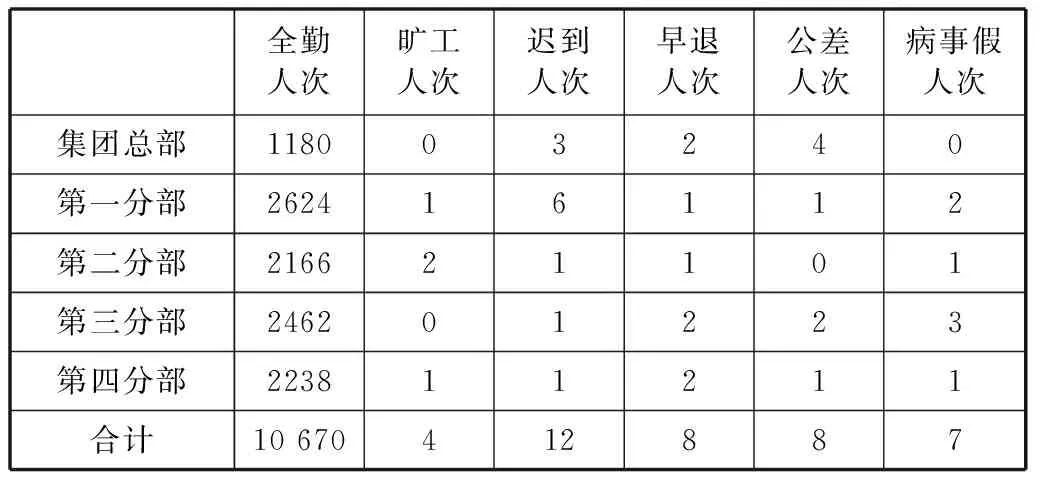
全勤人次曠工人次遲到人次早退人次公差人次病事假人次集團總部118003240第一分部262416112第二分部216621101第三分部246201223第四分部223811211合計10670412887
制表人:劉三保 制表日期:2014年6月1日
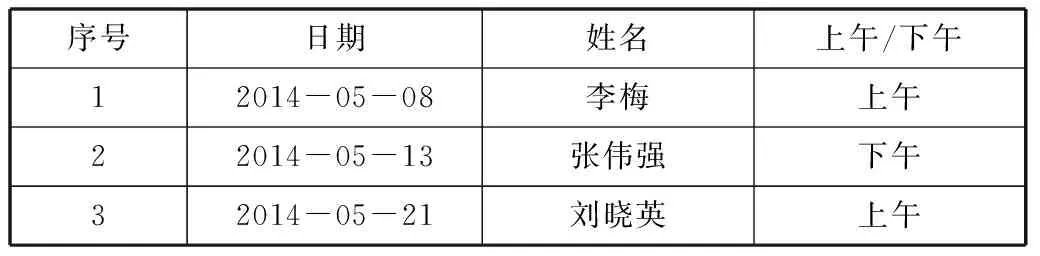
表5 集團總部2014年5月遲到人次清單
制表人:劉三保 制表日期:2014年6月1日
2 表格的結構特征
一個中文表格T可以用式(1)的六元組來表示:
T=
(1)
其中,Td為表序,即表格在文本中的序號,具有唯一性;Tn為表名,即表格的名稱;Tf為表附,反映表格的外部特征,它是若干<屬性,值>對所組成的集合,用FAi表示表附的第i個屬性,FVi表示FAi屬性的值,則:
Tf={
(2)
Tb為表體,由表格中的橫、縱欄目的<屬性,值>對組成的集合,設橫欄有m行,縱欄有n列,m,n都是正整數,當m或n有一個為1時,表示一維表格。用x1,x2,…,xm表示橫欄屬性,y1,y2,…,yn表示縱欄屬性,Vij表示橫欄屬性xi、縱欄屬性yj對應的值,則:
Tb={
……
(3)
Tc是表格的上下文結構,包括狀態約束、時間約束、地點約束、人物約束、事件約束。
Tc={ StatusConstraint;TimeConstraint;LocationConstraint;PersonConstraint; ThingConstraint;SequenceConstraint }
(4)
其中,StatusConstraint為狀態約束,布爾型,為真(ture)表示該表格中的數據已經確認,否則未確認;TimeConstraint為時間約束,其值用SandE(starttime,endtime)來表示,描述表格數據僅在上述時間范圍內有效。如果starttime為空、endtime不為空表示自endtime之前有效;如果starttime不為空、endtime不為空表示在starttime和endtime時限內有效;如果starttime不為空、endtime為空表示自starttime開始生效。若starttime=endtime則表示時間點;LocationConstraint為地點約束,描述表格數據相關的發生地點,其值為自由文本;PersonConstraint為人物約束,描述表格數據相關的人物,其值為自由文本;ThingConstraint為事件約束,描述表格數據相關的事件,其值為自由文本;SequenceConstraint為屬性間的順序約束,即所標識的列序號在解讀語義時須依次進行。其值可表示為SC(y1,y2,…,yn)。
Tk是表格的鏈接點集合,通過鏈接點一個表格可以嵌入多個相關的子表格。
Tk={TL1,TL2,…,TLs}s是自然數
TLi={ EmbeddedTid;EmbeddedTname; VerifyConstraint;PrefixConstraint }
(5)
其中,EmbeddedTid為被嵌入的表格序號,實數;EmbeddedTname為被嵌入的表格名稱,自由文本;VerifyConstraint為驗證約束,是T對子表的整體約束,其值可以表示為Vij=RowNum(EmbeddedTid),表示序號為EmbeddedTid的子表行數必須等于T中Vij,如表1中有Vij=3=RowNum(4.2);PrefixConstraint為前綴約束,也是T對子表的整體約束,其值可以表示為Prefix(Vij,Td),表示Td子表中所有數據都需要加上前綴Vij。
3 屬性的元模型
為中文表格T的所有表附屬性、表體屬性分別設計一個元模型,用MDFi、MDBij對應表示第i個表附屬性、第i行第j列表體屬性,其中h、m、n取值范圍同上。
MDFi={ Type; Range; ColumnConstraint; RowConstraint }
(i=1,2,…,h)
(6)
其中,Type為該屬性對應的數據類型;Range為該屬性的取值范圍,如按GB/T 7408-2005執行;ColumnConstraint為列約束,該屬性值對表格的某一列施加約束,其值可以表示為CC(y1,y2,…,yn)+FVi,其中yj為表格的j列,j為小于等于n的正整數。(如表2中的“貨幣單位:元”對第5列、第6列的約束);RowConstraint為行約束,該屬性值對表格的某一行施加約束,其值可以表示為RC(x1,x2,…,xm)+FVi,其中xj為表格的j行,j為小于等于m的正整數。
MDBij={Type; Range; RowColumnConstraint }
(i=1,2,…,m;j=1,2,…,n)
(7)
其中,Type為該屬性對應的數據類型;Range為值域,該屬性的取值范圍,如按GB/T7408-2005執行;RowColumnConstraint為屬性間的行列約束,其值可表示為RCC(Vab運算符Vuv運算符…Vdw關系符 Vij)。其中,a、b、u、v、d、w皆為正整數。
4 語義分析
本文將中文表格的語義擴展為:表面語義(包括“非值”部分和“值”部分)、上下文語義、主-子表間的限制語義、表附屬性對表格的附加語義、表內屬性值之間的關系語義。
對于給定的表格T,按照式(1)-式(7)構建表格的結構特征和屬性的元模型,利用一階謂詞演算中的函數和偽碼來進行中文表格的語義分析。
4.1表面語義
根據所構建的式(1)-式(3)的值,則有:
?T,?Td,Tn,Tf,Tb,Tk,h,m,n,s
Value(T,Td)∩Value(T,Tn)∩Num(T,Tf,h)∩
Num(T,R,m)∩Num(T,C,n)∩Num(T,Tk,s)
(8)
其中,Value(T,X)表示“表T的X屬性的值”,Num(T,R,Q)表示“表T的行數量是Q”,Num(T,C,Q)表示“表T的列數量是Q”。則上述謂詞公式表達了表面語義的“非值”部分:給定的中文表格T,其序號為Td,名稱為Tn,有h個附加屬性,有m行,有n列,有s個被嵌入的子表。
為了機器處理的效率,表面語義的“值”部分融合到以下語義中。
4.2上下文語義
ifTc.StatusConstraint=truethen"T的數據已經被確認"else"T的數據未被確認";
ifTc.TimeConstraint <>nullthen{
if(starttime <>nullandendtime =null)then"T的數據從starttime開始生效";
if(starttime =nullandendtime <>null)then"T的數據在endtime之前有效";
if(starttime <>nullandendtime <>null)then"T的數據在starttime和endtime之間有效";
}
ifTc.LocationConstraint <>nullthen"T的數據與地點Tc.LocationConstraint 相關";
ifTc.PersonConstraint <>nullthen"T的數據與人物Tc.PersonConstraint 相關";
ifTc.ThingConstraint <>nullthen"T的數據與事件Tc.ThingConstraint相關";
ifTc.SequenceConstraint <>nullthen"T的數據具有SC(y1,y2,…,yn)順序要求";
4.3主-子表間的限制語義
ifs<>0then
for(i=1tos) {
被嵌入的表格序號為TLi.EmbeddedTid;
被嵌入的表格名稱為TLi.EmbeddedTname;
表格T對TLi.EmbeddedTid子表的驗證約束為TLi.VerifyConstraint;
表格T對TLi.EmbeddedTid子表的前綴約束為TLi.PrefixConstraint;
}
4.4表附屬性對表格的附加語義
ifh<>0then
fori=1toh {
表附屬性FAi的值是FVi;
表附屬性FAi的數據類型為MDFi.Type;
表附屬性FAi的值域為MDFi.Range;
表附屬性FAi對T的列約束為MDFi.ColumnConstraint;
表附屬性FAi對T的行約束為MDFi.RowConstraint;
}
4.5表內屬性值之間的關系語義
fori=1tom {
forj=1ton {
表體橫欄屬性為xi、縱欄屬性為yj對應的值是Vij;
該表體屬性值的數據類型為MDBij.Type;
該表體屬性值的值域為MDBij.Range;
if(MDBij.RowColumnConstraint<>null)then
"值Vij隱含了RCC(Vab運算符Vuv運算符…Vdw關系符 Vij)關系";
if(MDFj.ColumnConstraint<>null)thenVij=Vij+MDFj.Co-lumnConstraint;
if(MDFi.RowConstraint<>null)thenVij=Vij+MDFi.RowConstraint);
}
}
5 實例應用
利用上述的語義分析方法,針對本文給定的四類典型的中文表格進行驗證。
表1的語義分析:
構建該表的結構特征和元模型:
Td=1;Tn=單位及信息專管員基本信息表;h=3;m=1;n=13; s=0;
Tf= {<單位蓋章,null>,<填表人,王擁軍>,<填表日期,2014-04-08>};
Tb= {<單位編號,TY001>,<組織機構編碼,79843562-5>,<單位名稱,太原市政府信息辦>,<中文簡稱,信息辦>,<英文簡稱,XXB>,<單位地址,中山路36號>,<信息專管員姓名,孫廣宏>,<信息專管員職務,科長>,<信息專管員辦公室電話,2336759>,<信息專管員手機號碼,13903516638>,<信息專管員政務號,GK35692>,<信息專管員電子信箱,sunguanghong@ 163.com>,<信息專管員QQ號,1339883518>};
Tc={
StatusConstraint=false;
TimeConstraint=null;
LocationConstraint=null;
PersonConstraint=null;
ThingConstraint=為配合全市信息化統一規劃,對各委辦局和信息專管員的基本信息進行采集;
SequenceConstraint=null}
s=0,故無須構建Tk。
屬性的元模型為:
MDF1={
Type=字符串;
Range=自由文本;
ColumnConstraint=null;
RowConstraint=null;}
MDF2={
Type=字符串;
Range=長度不超過五個漢字;
ColumnConstraint=null;
RowConstraint=null;}
MDF3={
Type=日期型;
Range=符合YYYY-MM-DD日期規范;
ColumnConstraint=null;
RowConstraint=null;}
MB11={
Type=字符串;
Range=TY+3位數字;
RowColumnConstraint=null;}
MB12={
Type=9位數字字符串;
Range=符合國家組織機構編碼及校驗規則;
RowColumnConstraint=null}
以下MB13至MB112類似,省略。
MB113={
Type=數字串;
Range=四至十位的數字;
RowColumnConstraint=null;}
可獲得如下語義:
(1) 表面語義
根據式(8)可以得到表面語義的“非值”部分:表的序號為“1”,表名為“單位及信息專管員基本信息表”,有3個附加屬性,有1行13列,沒有嵌入子表。
(2) 上下文語義
該表是“為配合全市信息化統一規劃,對各委辦局和信息專管員的基本信息進行采集”,但本表填報的信息尚未得到單位“確認”。
(3) 主-子表間的限制語義
無。
(4) 表附屬性對表格的附加語義
表附屬性值為:
單位蓋章=null,字符串,自由文本;
填表人=王擁軍,字符串,不超過五個漢字;
填表日期=2014-04-08,日期型,格式為YYYY-MM-DD;
附加語義:無。
(5) 表內屬性值之間的關系語義
表體屬性值為:
單位編號=TY001,字符串,格式為TY+3位數字;
組織機構編碼=79843562-5,9位數字字符串,符合國家組織機構編碼及校驗規則;
單位名稱=太原市政府信息辦,字符串,自由文本;
中文簡稱=信息辦,字符串,自由文本;
英文簡稱=XXB,字符串,自由文本;
單位地址=中山路36號,字符串,自由文本;
信息專管員姓名=孫廣宏,字符串,長度不超過五個漢字;
信息專管員職務=科長,字符串,符合國家職務編碼規范;
信息專管員辦公室電話=2336759,數字串,七位數字;
信息專管員手機號碼=13903516638,數字串,十位數字;
信息專管員政務號=GK35692,字符串,GK+5位數字,具有唯一性;
信息專管員電子信箱=sunguanghong@163.com,字符數字串,符合電子郵件地址規范;
信息專管員QQ號=1339883518,數字串,四至十位數字;
屬性值之間關系語義:無。
表2的語義分析:
限于篇幅,省略結構特征和元模型的構建過程,對于表格的表面語義的“值”部分也予以省略。
(1) 表面語義
表的序號為“2”,表名為“某項目設備預算表”,有2個附加屬性,有7行6列,沒有嵌入子表。
(2) 上下文語義
該表是“針對某項目設備預算制作的清單”,解讀該表時針對每一行按第1、2、3、4、5、6列順序進行,本表填報的信息已經“確認”。
(3) 主-子表間的限制語義
無。
(4) 表附屬性對表格的附加語義
表附屬性值:省略。
附加語義:表的第6、7列的限制量詞為“元”。
(5) 表內屬性值之間的關系語義
表體屬性值:省略。
屬性值之間關系語義:滿足V13×V15=V16;V23×V25=V26;V33×V35=V36;V43×V45=V46;V53×V55=V56;V63×V65=V66;V16+V26+V36+V46+V56+V66=V76。
表3的語義分析:
(1) 表面語義
表的序號為“3”,表名為“某公司員工信息表”,有1個附加屬性,有1行9列,有2個嵌入子表,表序分別為3.1和3.2。
(2) 上下文語義
該表“對公司所有員工的基本信息進行采集”,本表填報的信息已經“確認”,信息在2014年7月1日前有效。
(3) 主-子表間的限制語義
表3.1和3.2所有數據值都應冠以前綴“李國棟”。
(4) 表附屬性對表格的附加語義
表附屬性值:省略。
附加語義:無。
(5) 表內屬性值之間的關系語義
表體屬性值為:略
關系語義:無。
子表3.1和3.2的語義分析:省略。
表4和表5的語義分析:
(1) 表面語義
表的序號為“4”,表名為“某集團公司月度考勤統計表”,有3個附加屬性,有6行6列,有1個嵌入子表,表序為“5”。
(2) 上下文語義
該表“對集團所有員工按所在分部進行考勤匯總”,本表填報的信息已經“確認”,信息的有效性范圍為2014年5月1日至2014年5月31日。
(3) 主-子表間的限制語義
被嵌入的子表5的行數必須為3。
(4) 表附屬性對表格的附加語義
表附屬性值:省略。
附加語義:無。
(5) 表內屬性值之間的關系語義
表體屬性值為:略。
關系語義:
V11+V21+V31+V41+V51=V61;V12+V22+V32+V42+V52=V62;
V13+V23+V33+V43+V53=V63;V14+V24+V34+V44+V54=V64;
V15+V25+V35+V45+V55=V65;V16+V26+V36+V46+V56=V66。
對子表5的語義分析:省略。
6 語義質量評價
鄧敏等[15]基于CHENG[16]提出了準確性、一致性、完整性語義質量評價方法,孫翀等[17]提出了語義損失率的評價方法,還有基于語義擴散距離的評價方法。這些方法都是在假定研究對象的語義已經存在的前提下,進行某種運算(文獻[15]為綜合,文獻[16]為匯總)時,對運算前后語義的變化進行質量評價,而針對中文表格到底應該包含哪些語義尚未得到統一認知的情況下(這正是本文的研究目標之一),上述方法皆不可行。以下用本文中的四個實例來對比目前方法與本文方法所獲得的語義信息量,見表6所示。
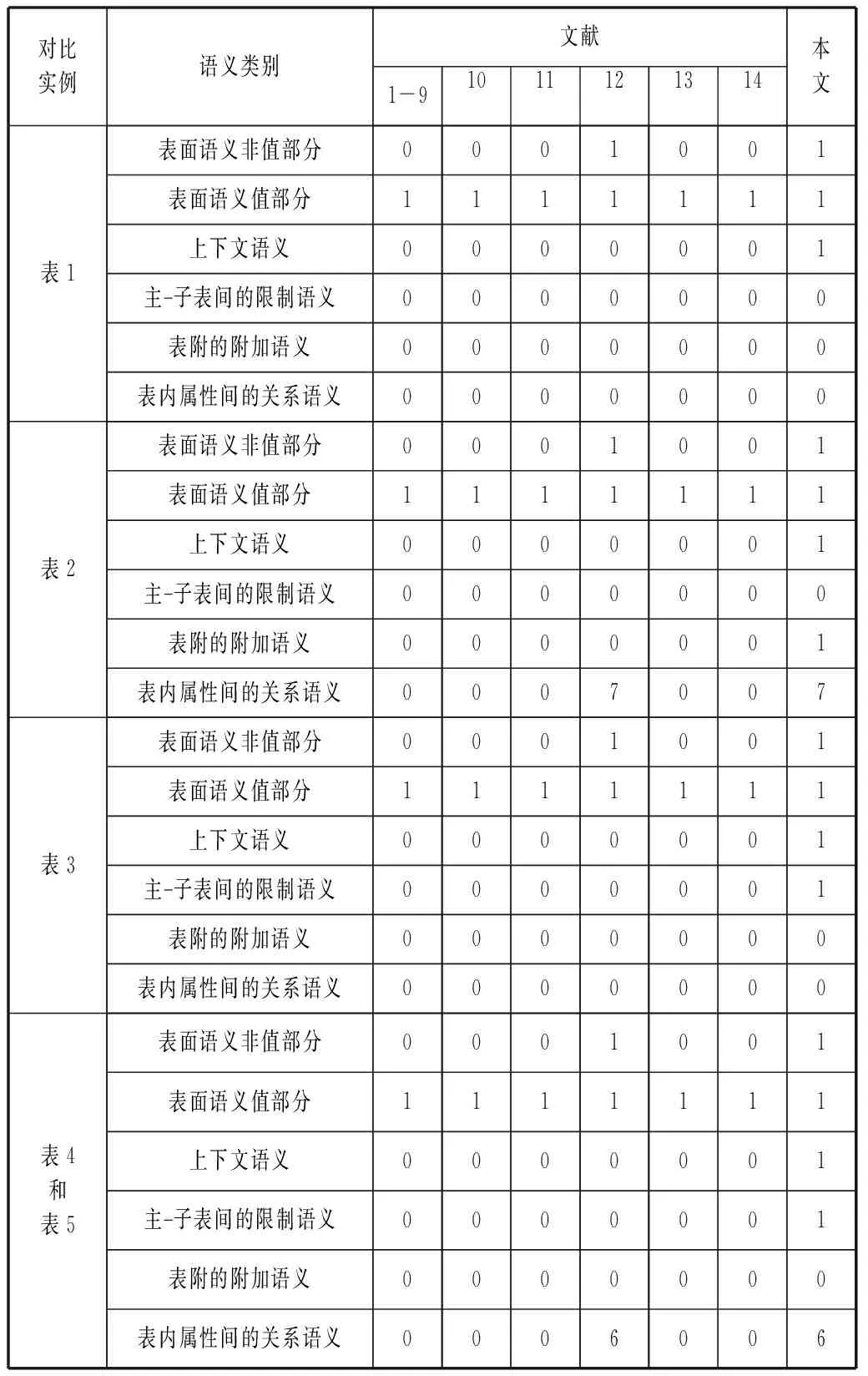
表6 各種方法所獲得的語義信息量比較
7 結 語
在實際情況中,中文表格的分類標準、語義范疇、是否領域相關等問題的認識并未得到統一,因此,面向常見的幾種表格類型,基于結構特征和元模型對中文表格進行了語義分析,思路清晰,算法簡單。較已有的方法,獲取了中文表格的表面語義(“值”和“非值”語義)、上下文語義、表附屬性的附加語義、主-子表之間的限制語義、表內屬性值間的關系語義,擴展了中文表格語義分析的范圍,豐富了語義信息量。
從本質上說,構建中文表格的結構特征和元模型的過程就是表格概化的過程,可看成槽填充表示法[18]的擴展,且具備對多層嵌套子表的遞歸分析能力。顯然,從結構特征和元模型中獲取中文表格語義的過程對語義是無損的,結果是無歧義的。不難看出,該方法也可用于中文表格的信息抽取。
[1] 范莉婭,肖田元.自動獲取HTML表格語義層次結構方法[J].清華大學學報(自然科學版),2007,47(10):1586-1590.
[2]LimSeungjin,NgYiukai.AnautomatedapproachforretrievinghierarchicaldatafromHTMLtables[C]//ProceedingsoftheEighthInternationalConferenceonInformationandKnowledgeManagement.KansasCity:ACM,1999: 466-474.
[3]LIUJiexue,AOZhuoyun,ParkHH,etal.AnXMLapproachtosemanticallyextractdatafromHTMLtables[C]//DatabaseandExpertSystemsApplications,DEXA2005,LectureNotesinComputerScience3588.Heidelberg:SpringerBerlin,2005:696-705.
[4]YoshidaM,TorisawaK,TsujiiJ.Extractingattributesandtheirvaluesfromwebpages[C]//AntonacopoulosA,HuJianying.WebDocumentAnalysis:ChallengesandOpportunities.Singapore:WorldScientificPublishing,2003: 179-200.
[5]HsiaoShuling,ChouShihchun,ChangLuping.InformationextractionfromHTMLtablesbaseondomainontology[C]//InternationalConferenceonInformationandKnowledgeEngineering-IKE’03.LasVegas:CSREAPress,2003: 70-78.
[6]KimYeonseok,LeeKyongho.ExtractingtableinformationfromtheWeb[C]//DocumentAnalysisSystemsVI. 6thInternationalWorkshop,DAS2004,LectureNotesinComputerScience3163,2004:438-441.
[7] 張凱.基于本體的web信息集成若干關鍵技術研究[D].上海:復旦大學,2004.
[8]LiShijun,PENGZhiyong,LIUMengchi.ExtractionandintegrationinformationinHTMLtables[C]//FourthInternationalConferenceonComputerandInformationTechnology.Nanjing,China,2004:315-320.
[9]TanakaM,IshidaT.Ontologyextractionfromtablesontheweb[C]//ProceedingsoftheInternationalSymposiumonApplicationsonInternetinSAINT-06.Washington:IEEEComputerSociety,2006:284-290.
[10] 楊海濤.復雜表頭表格的關系模式表示[J].計算機工程,2011,37(2):49-54.
[11] 賴中華. 基于本體的金融年報語義網自動構建方法[D].哈爾濱工業大學,2008.
[12] 陳競波.基于語義的報表系統模型的應用研究[D].遼寧:遼寧工程技術大學,2010.
[13] 馮曉晨,張曉輝,邸瑞華.基于本體的電子表格數據到語義數據的轉換[J].計算機科學,2011,38(10):145-148.
[14] 尹文生.HTML表格語義脈絡分析方法:中國,200910272408[P]. 2011-05-04.
[15] 鄧敏,劉揚,程濤,等.地圖綜合中語義質量的度量方法研究[J].地理與地理信息科學,2008,24(5):11-15.
[16]ChengT,LIZL.Quantitativemeasuresforsemanticqualityofpolygongeneralization[J].Cartographica,2006,41(2):135-148.
[17] 孫翀,盧炎生.基于層次空間聚類的表語義匯總算法[J].計算機科學,2012,39(3):163-169.
[18] 馮志偉.自然語言處理簡明教程[M].上海:上海外語教育出版社,2012:516-517.
SEMANTICANALYSISMETHODFORTABLESINCHINESEBASEDONSTRUCTURALFEATURESANDMETA-MODEL
ZhangJiarui1ZhangHan2
1(Department of Computer Science and Technology,Hefei University,Hefei 230601,Anhui, China)2(Department of Life and Medical Science, University of Hertfordshire,Hatfield,AL10 9AB,UK)
InlightoftheactualityoflesscomprehensiveanalysisonsemanticsoftablesinChinesethecurrenttechniqueis,inthispaperwepresentthestructuralfeaturesandmeta-modelbasedsemanticsanalysismethod.Byusingthewell-knownfirst-orderpredicatecalculusfunctionsincludingValue(valuefunction)andNum(numberfunction),aswellascombiningpseudocode,weanalysethesemanticsofseveralkindsofthemostcommontablesinChineseandobtaintheirsurfacesemantics,contextsemantics,restrictsemanticsbetweenmastertableandsub-tables,additionalsemanticsofsubsidiarynatureoftableontabledata,andrelationshipsemanticsbehindtheattributevalue.Resultsofexampleverificationindicatethatthestructuralfeatureandmeta-modelaretheeffectivewayforanalysingthesemanticsoftablesinChinese,theacquiredinformationamountandcategoriesofsemanticsexceedfarthantheexistingmethods.
StructuralfeaturesMeta-modelFirstorderpredicatecalculusfunctionSurfacesemanticsContextsemanticsRestrictionsemanticsAdditionalsemanticsRelationshipsemantics
2014-10-08。科技部中小企業創新基金項目(11C26 213401181);校人才科研基金項目(14RC08)。張家銳,高工,主研領域:軟件建模,信息集成,數據挖掘。張涵,本科生。
TP311
ADOI:10.3969/j.issn.1000-386x.2016.03.020
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
當代修辭學(2010年1期)2010-01-23 06:35:10
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
