長(zhǎng)短時(shí)記憶神經(jīng)網(wǎng)絡(luò)模型改進(jìn)
2016-09-10 22:26:31唐寅
時(shí)代金融 2016年24期

【摘要】由于神經(jīng)網(wǎng)絡(luò)自身的高度自學(xué)習(xí)性,穩(wěn)定性以及抽象模擬能力,相比于統(tǒng)計(jì)學(xué)以及計(jì)量經(jīng)濟(jì)學(xué)中的數(shù)學(xué)模型,神經(jīng)網(wǎng)絡(luò)用于預(yù)測(cè)金融時(shí)間序列更具優(yōu)勢(shì)。本文在深入分析LSTM神經(jīng)網(wǎng)絡(luò)對(duì)股指進(jìn)行短期時(shí)間序列預(yù)測(cè)的可行性。
【關(guān)鍵詞】LSTM RNN 神經(jīng)網(wǎng)絡(luò) 股指預(yù)測(cè)
一、LSTM神經(jīng)網(wǎng)絡(luò)分析
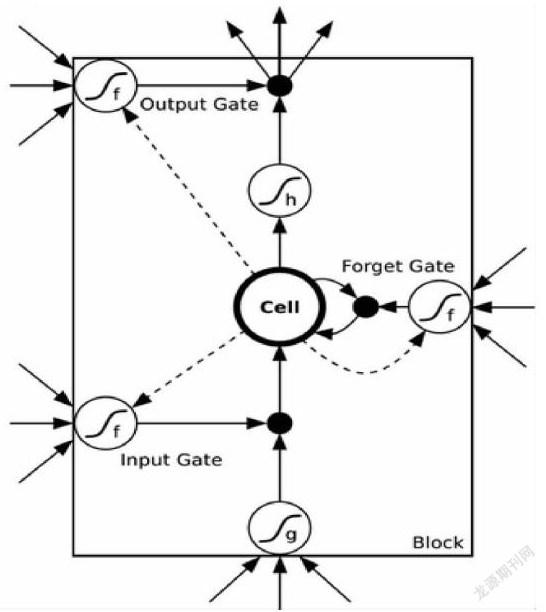
LSTM(長(zhǎng)短時(shí)記憶)神經(jīng)網(wǎng)絡(luò)是建立在RNN上的一種新型深度機(jī)器學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)。在這個(gè)模型中LSTM單元包含一個(gè)嘗試將信息儲(chǔ)存較久的存儲(chǔ)單元。這個(gè)記憶單元的入口被一些特殊的門控制,被控制的功能包括保存、寫入和讀取操作。這些門都是邏輯單元,它們負(fù)責(zé)在神經(jīng)網(wǎng)絡(luò)的其它部分與記憶單元連接的邊緣處設(shè)定權(quán)值。這個(gè)記憶單元是一個(gè)線型的神經(jīng)元,有自體內(nèi)部連接。具體來(lái)說(shuō)就是其在每一個(gè)神經(jīng)元內(nèi)部加入了三個(gè)門,分別是輸入門、輸出門和忘記門。用來(lái)選擇性記憶反饋的誤差函數(shù)隨梯度下降的修正參數(shù)。當(dāng)忘記門被打開(kāi)時(shí),自己連接權(quán)值為1,記憶單元將內(nèi)容寫入自身。當(dāng)忘記門輸出為0時(shí),記憶單元會(huì)清除之前的內(nèi)容。輸出門允許在輸出值為1的時(shí)候,神經(jīng)網(wǎng)絡(luò)的其它部分將內(nèi)容記入記憶單元,而輸入門則允許在輸出值為1的時(shí)候,神經(jīng)網(wǎng)絡(luò)的其它部分讀取記憶單元。模型結(jié)構(gòu)如下:
Cell,就是神經(jīng)元狀態(tài)的記憶,有個(gè)叫做state的參數(shù)來(lái)記錄狀態(tài)的。Forget Gate:將上一次神經(jīng)元的狀態(tài)選擇性遺忘修正參數(shù)。對(duì)于每個(gè)存儲(chǔ)單元,三套權(quán)重從輸入訓(xùn)練而得,包括先前時(shí)間步中完整的隱藏狀態(tài)。一個(gè)帶入到輸入節(jié)點(diǎn),在上圖的底部。一個(gè)帶入到忘記門,在最右側(cè)顯示。另一個(gè)帶入到輸出門,在頂部最左側(cè)的顯示。每個(gè)黑色節(jié)點(diǎn)與一個(gè)激活函數(shù)相關(guān)聯(lián),典型的激活函數(shù)為S型函數(shù)。單元中最中央的節(jié)點(diǎn)即內(nèi)部狀態(tài),并且以數(shù)量1為權(quán)重來(lái)跨越時(shí)間步,再反饋到本身。內(nèi)部狀態(tài)的自連接邊,被稱為恒定誤差傳送帶或CEC。
以前傳遞為例,輸入門來(lái)決定何時(shí)讓激活狀態(tài)傳入存儲(chǔ)單元cell,而輸出門決定何時(shí)讓激活傳出存儲(chǔ)單元,這些都是通過(guò)訓(xùn)練學(xué)習(xí)而確定的。最后忘記門用來(lái)學(xué)習(xí)是否記憶上一個(gè)神經(jīng)元狀態(tài)的全部或部分或完全遺忘。后傳遞也是同樣的道理,輸出門是在學(xué)習(xí)什么時(shí)候讓誤差流入存儲(chǔ)單元,而輸入門則學(xué)習(xí)什么時(shí)候讓它流出存儲(chǔ)單元,并傳到神經(jīng)網(wǎng)絡(luò)的其它部分。忘記門也是一樣。以下按照一般算法的計(jì)算順序來(lái)給出每個(gè)部分的公式:
帶下標(biāo)L的是跟Input Gate相關(guān)的,連向Input Gate包括:外面的輸入,來(lái)自Cell的那個(gè)虛線(虛線叫做peephole連接),帶H的是一個(gè)泛指,因?yàn)長(zhǎng)STM的一個(gè)重要特點(diǎn)就是其靈活性,cell之間可以互聯(lián),hidden units之間可以互聯(lián),所以這個(gè)H就是泛指這些連進(jìn)來(lái)的東西,可以看成是從外面連進(jìn)了的三條邊的一部分。
FORGET GATE:
后向傳播中的偏微分求導(dǎo)由于非常復(fù)雜,在這里就不贅述了,只要明白對(duì)每個(gè)門中經(jīng)過(guò)的參數(shù)求偏導(dǎo)是為了按梯度的方向進(jìn)行收斂并修正權(quán)值。
二、LSTM神經(jīng)網(wǎng)絡(luò)模型的優(yōu)勢(shì)及問(wèn)題
LSTM的出現(xiàn)的原因其實(shí)是因?yàn)镽NN轉(zhuǎn)換成超級(jí)長(zhǎng)的傳統(tǒng)神經(jīng)網(wǎng)絡(luò)后,利用BP反向傳播的時(shí)候,誤差會(huì)逐級(jí)減小,但由于展開(kāi)的太長(zhǎng)了,誤差需要?dú)w因到每一層每一個(gè)神經(jīng)元,這會(huì)導(dǎo)致整個(gè)訓(xùn)練過(guò)程無(wú)法逃離局部最優(yōu)解。LSTM正是解決了這個(gè)問(wèn)題,他將每一層的神經(jīng)元設(shè)計(jì)成具有多個(gè)“門”的結(jié)構(gòu),這使得誤差在傳播過(guò)程中,有些可以直接通過(guò)“門”,不用歸因于當(dāng)前神經(jīng)元,誤差就完好無(wú)損的直接通過(guò)到下一層了,因此收斂性很好。
三、LSTM神經(jīng)網(wǎng)絡(luò)模型的算法改進(jìn)
α學(xué)習(xí)速率是與誤差函數(shù)的一階導(dǎo)數(shù)相乘,來(lái)控制隨梯度下降的步長(zhǎng)的,雖然α是變化的但是每一次歸因?qū)τ诿總€(gè)自變量來(lái)說(shuō)是相同的。可以將α設(shè)為誤差函數(shù)的二階導(dǎo)數(shù),這樣以每一自變量下降的不同速度來(lái)隨梯度下降。這種改變的理論依據(jù)源于著名的數(shù)學(xué)理論擬牛頓法。
具體公式為:wn∈w=wold+H-1wold
這里的w為權(quán)值的向量矩陣,H-1為hessian矩陣,這里就是將學(xué)習(xí)速率α設(shè)為誤差函數(shù)的二階導(dǎo)數(shù),從而使每一個(gè)自變量(權(quán)值)下降的速度隨各自梯度下降,使模型收斂的更加準(zhǔn)確。
四、實(shí)證分析
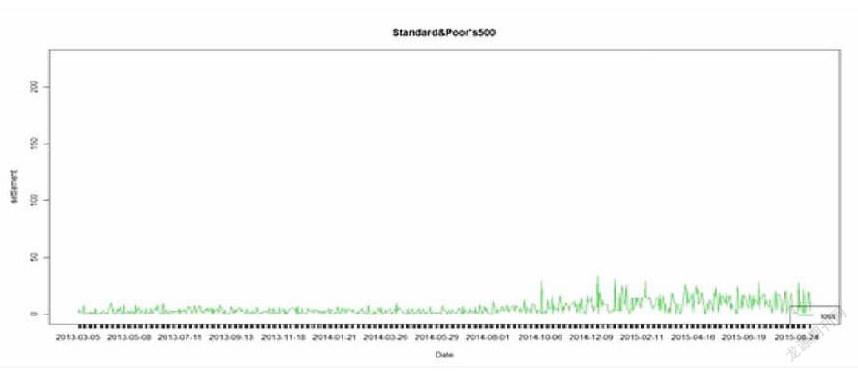
研究對(duì)象:選取日成交量最大的標(biāo)普500指數(shù)作為基礎(chǔ)研究對(duì)象來(lái)驗(yàn)證模型的準(zhǔn)確性,運(yùn)用LUA語(yǔ)言進(jìn)行編程,并以TORCH作為深度學(xué)習(xí)框架。進(jìn)行訓(xùn)練預(yù)測(cè)擬合圖形并計(jì)算誤差。
LSTM模型預(yù)測(cè)誤差均值為0.783%股指。模型收斂的更小,誤差更小,模型預(yù)測(cè)準(zhǔn)確。
參考文獻(xiàn)
[1]Andrej Karpathy.The Unreasonable Effectiveness of Recurrent Neural Networks[R].,2015.3.
[2]胡新辰.于LSTM的語(yǔ)義關(guān)系分類研究[M].哈爾濱工業(yè)大學(xué).2015.6.
[3]李小燕.灰色神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)模型的優(yōu)化研究[D].武漢理工大學(xué).2009.
作者簡(jiǎn)介:唐寅(1991-),男,漢族,貴州金沙人,現(xiàn)就讀于首都經(jīng)濟(jì)貿(mào)易大學(xué),碩士學(xué)位,研究方向:電子商務(wù)。
