顧客滿意度測評中的缺失值處理方法
2013-05-10 10:04:04趙富強
統計與決策 2013年6期
趙富強
(天津財經大學,天津300222)
1 缺失值產生的原因、方式及處理方法
缺失值(Missing Value)是指在進行問卷抽樣調查或實驗性研究中,應該從抽樣的樣本單元中得到而實際上卻由于種種原因而未得到所需的數據;也稱為缺失數據(Missing Data)。
在進行實驗性研究或問卷抽樣調查中,數據缺失現象經常發生,主要原因包括:①被調查者不愿提供調查所需要的信息;②不可人為控制的因素造成數據的缺失;③調研人員本身或調查系統的原因沒有收集到完全的信息;④信息填報匯總錯誤原因造成數據的缺失等。產生缺失數據原因多種多樣,實際工作中有時很難判斷和檢測缺失數據產生的機制與方式。為了認識和研究缺失的數據,從形式上將其分為單元缺失與項目缺失兩種。Little和Rubin定義了以下三種不同的數據缺失機制:完全隨機缺失(Missing Completely at Random,MCAR)、隨機缺失(Missing at Random,MAR)和不可忽略的缺失(Non-ignorable Missing,NIM)。整個缺失數據的推估過程中,缺失數據的情況表現為三種方式[1,2]:單變量缺失、單調缺失型和任意缺失型。
缺失值的處理方法主要包括刪除法(Deletion)、插補法(Imputation)和最大似然估計法(Maximum likelihood)[3]等。缺失值插補法包括:均值插補法(Mean Imputation)、隨機插補法和多重插補方法(Multiple Imputation,MI)等。
在文獻[4]中,Lohm?ller’s PLSX對缺失值的處理為:⑴如果所有的顯變量樣本值都缺失,那么該樣本無效,無法估計潛變量。⑵如果該塊的顯變量樣本值不全缺失,那么計算潛變量估計時,缺失的顯變量值由該顯變量的均值替代。⑶如果該潛變量估計值有缺失,那么計算內部估計時,缺失值由0替代。⑷權重的計算:①模式A(Mode A):權重根據公式計算;②模式B(Mode B):當沒有缺失值按照公式計算;有缺失值時,采用成對刪除法把對應的缺失樣本值刪除,即不考慮在內,然后利用公式來計算權重。
除了上述方法外,缺失值處理方法還有回歸或主成分法、最大似然估計法、相似反應模式算法(Similar Response Pattern Imputation)、EM算法(Expected Maximization Algorithm)和MCMC算法(Markov Chain Monte Carlo)等。
2 基于分類的缺失值處理方法
基于分類的缺失值處理方法是通過對被調查對象問卷分值的分析,選擇關鍵字段進行分類,然后使用上述的缺失值處理方法進行缺失值處理。主要包括:分類的均值插補法、分類的多重插補法和分類的K-means方法等。
均值插補法是用每個變量的均值取代該變量的缺失值。分類均值插補法是先對數據進行分類,然后同類中的缺失值進行均值插補;在一定程度上克服了均值插補法替代值過于凝集和容易扭曲目標變量分布的弱點,使替代值的分布與真值分布更為接近。
多重插補法由1987年由Dempster教授和美國哈佛大學Rubin教授提出。在2000年,Paul D.Allison[5]博士也對多重插補法進行了深入研究。它是一種用兩個或者更多的可得到的并且能反映數據本身分布概率的值來插補缺失或者不完善數據的一種方法。多重插補方法的主要思想是,給每個缺失值都構造m個估計值(m>1),這樣就產生出m個完全數據集,對每個完全數據集分別使用相同的方法進行處理,得到m個處理結果,最后再綜合這m個處理結果,最終得到對目標變量的估計。多重填補法使得被插補的缺失數據能夠接近“真實”。該方法主要應用于生物醫學、行為學和社會科學等領域,已成為處理缺失數據的最常用方法之一。而分類多重插補法是先對數據進行分類,然后同類中的缺失值進行多重插補;
分類K-means方法是先對數據進行分類,然后同類中的缺失值進行聚類中心值插補。
3 分類缺失值處理方法在滿意度測評中應用
以某食品公司為研究對象,以ACSI為測評模型,即包含6個潛變量,15個顯變量。數據的收集采取網上調查的方式進行,參與網上調查的用戶為252位,因此樣本量為252。
求解帶缺失值的顧客滿意度指數步驟如下:
(1)異常值處理。
所謂異常值是被調查顧客在回答問卷時,由于各種原因而選擇了“不知道”、“拒絕回答”以及“超出數值范圍”等選項時系統默認的值。問卷采用10分制,從1分到10分供被調查者選擇,且只能選擇一個。對被調查者不知道或拒絕的回答,在數據庫里進行了標識(98表示不知道;99表示拒絕;101表示從來不購買)。這些數據在進行處理時按照缺失值處理。
(2)數據標準化。
使得樣本值的均值為0、方差為1;
(3)缺失值處理。
通過對被調查對象問卷分值的分析,選擇滿意度字段進行分類,滿意度分值從1到10分,共分為十個類別。分別采用類均值插補法、分類多重插補法和分類K-means方法進行缺失值處理。
(4)利用PLS算法來估計模型中各個參數,反復迭代得到潛變量估計值。
(5)求出顧客滿意度指數。
根據第四步求得的權重系數,計算出顧客滿意度指數[1]。
圖1和圖2分別表示分類多重插補法在20%的缺失值比率下總體期望取值密度分布和總體期望缺失率與取值分布圖;僅給出了總體顧客期望的插補情況,顧客滿意度分類值為10,樣本量為112個,迭代次數為9次,插補效果滿意。
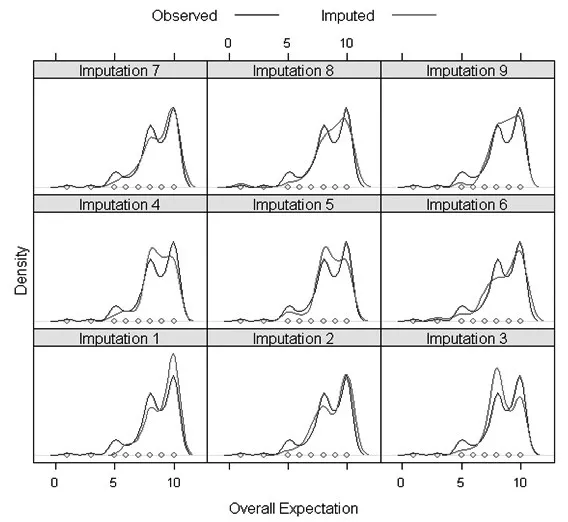
圖1 總體期望取值密度分布圖
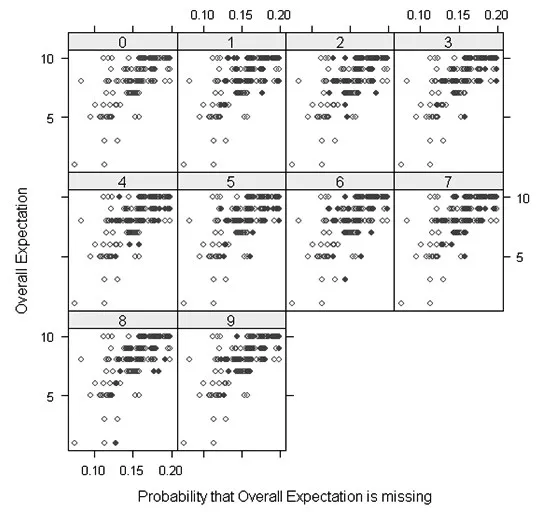
圖2 總體期望缺失率與取值分布圖
圖3 表示在不同缺失率下各種缺失值處理方法均方根誤差RMSE比較。其中,(a)圖表示均值插補與分類均值插補均方根誤差比較;(b)圖表示多重插補與分類的多重插補均方根誤差比較;(c)圖表示K-means與分類K-means均方根誤差比較,k的取值不同。
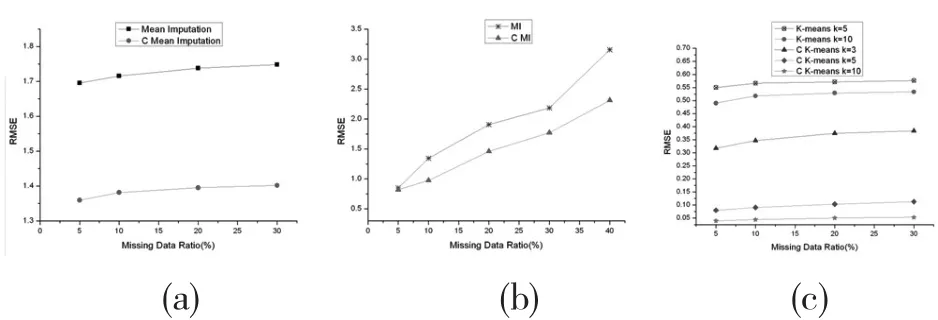
圖3 缺失率與RMSE關系圖
結果分析:通過實驗數據分析,三種基于分類的缺失值處理方法優于未采用分類的缺失值處理方法。其中分類K-means方法RMSE最小,如圖(c)所示;在K-means和分類K-means方法中,k的取值不同結果有差異,k值越大誤差越小。分類多重插補法誤差最大,如圖(b)所示(多重插補法缺失值比率超過50%后,RMSE值大于6。)。
在顧客滿意度測評中,對滿意度關鍵字段進行分類,進而采用相關的缺失值插補方法,即基于分類的缺失值處理方法是有效的。
4 結論與展望
通過對缺失值處理方法分析,提出基于分類的三種缺失值處理方法:分類的均值插補法、分類的多重插補法和分類的K-means方法;以某食品公司為研究對象,分析了帶缺失值的顧客滿意度指數測評步驟:異常值處理、數據標準化、缺失值處理等;對顧客滿意度測評常規模型進行帶缺失值的實證分析和評價,基于分類的三種缺失值處理方法優于均值插補法、多重插補法和K-means方法。但論文僅對顧客滿意度字段進行了分類研究,沒有考慮其它字段的分類情況、多個字段分類情況及各字段間關系等,這些是今后深入研究的問題。
[1]Wang Q H,Rao J N K.Empirical Likelihood for Linear Regression Models under Imputation for Missing Response[J].The Canadian Jour?nal Statistics,2001,29.
[2]Allison,Paul D.Missing Data Techniquesfor Structural Equation Mod?els[J].Journal of Abnormal Psychology,2003,112.
[3]Fatukasi,O.Kittler,J.Poh,N.Estimation of Missing Values in Multi?modal Biometric Fusion[J].Biometrics Theory Applications and Sys?tems,2008,9.
[4]Tenenhaus,M.,Vinzi,V.E.,Chatelin,Y.M.,Lauro,C.PLSPath Model?ing[J].Computational Statisticsand Data Analysis,2005,48(1).
[5]Allison,Paul D.Multiple Imputation for Missing Data:a Cautionary tale[J].Sociological Methodsand Research,2000,28.
猜你喜歡
工會博覽(2023年3期)2023-04-06 15:52:34
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小康(2021年7期)2021-03-15 05:29:03
活力(2019年19期)2020-01-06 07:34:38
雜文月刊(2019年15期)2019-09-26 00:53:54
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
