多民族脫機手寫體漢字數(shù)據(jù)庫的設計與構建
2011-12-27 05:59:06鄭蕊蕊趙繼印于為民吳寶春
大連民族大學學報 2011年5期
關鍵詞:數(shù)據(jù)庫文本
鄭蕊蕊,趙繼印,李 敏,于為民,吳寶春
(大連民族學院信息與通信工程學院,遼寧大連 116605)
多民族脫機手寫體漢字數(shù)據(jù)庫的設計與構建
鄭蕊蕊,趙繼印,李 敏,于為民,吳寶春
(大連民族學院信息與通信工程學院,遼寧大連 116605)
設計并構建了一種記錄書寫者民族信息的手寫體漢字數(shù)據(jù)庫——大連民族學院DNU-Ⅰ型多民族脫機手寫體漢字數(shù)據(jù)庫。包括單字庫、行文本庫和段文本庫3個子庫。為少數(shù)民族漢字書寫特征分析、中文文檔的行切分、漢字的切分識別、中文文本的無切分識別、筆跡鑒別和簽名驗證等方面的研究奠定基礎,并提供算法的驗證平臺。同時介紹了字符識別數(shù)據(jù)庫的一般構建流程和數(shù)據(jù)庫圖像二值化、歸一化、行分割等預處理算法,為少數(shù)民族文字數(shù)據(jù)庫的構建提供了技術支撐。
脫機手寫體漢字識別;數(shù)據(jù)庫;少數(shù)民族;圖像處理
脫機手寫體漢字識別是字符識別領域的研究難點與熱點,涉及模式識別、圖像處理、統(tǒng)計理論等學科,呈現(xiàn)出綜合性的特點,在少數(shù)民族語言文字信息處理、辦公和教學自動化、銀行票據(jù)自動識別、郵政自動分揀等技術領域,都有著重要的理論意義和實用價值[1]。標準化的脫機手寫體漢字數(shù)據(jù)庫在字符識別研究中起關鍵作用:一方面,數(shù)據(jù)庫為識別算法提供大量的訓練樣本和測試樣本;另一方面,數(shù)據(jù)庫為不同識別算法的性能比較提供公共平臺,有利于公正客觀地對比實驗結果。因此,建立脫機手寫體漢字數(shù)據(jù)庫是研究脫機手寫體漢字識別技術的首要環(huán)節(jié)和基礎。
目前國內外的研究機構已建立并公開了4種脫機手寫體漢字數(shù)據(jù)庫,分別是ETL-8/ETL-9[2]、HCL2000[3]、HIT - MW[4]和 SCUT -COUCH2009[5]。ETL-8/ETL -9 字符數(shù)據(jù)庫由日本電子工業(yè)發(fā)展協(xié)會收集,包含日文、中文、拉丁文和數(shù)字的手寫和機器印刷字符,數(shù)據(jù)庫圖片有4種不同像素規(guī)格。該數(shù)據(jù)庫的不足是不包含書寫者信息,并且由于中文和日文的書寫習慣差異,該數(shù)據(jù)庫很少用于中文字符識別[4]。HCL2000是由北京郵電大學信息工程系研發(fā)的大規(guī)模脫機手寫漢字數(shù)據(jù)庫系統(tǒng)。該數(shù)據(jù)庫包含了三千多個一級漢字的1300個手寫漢字樣本和對應書寫者的個人信息,每個漢字樣本采用64×64個二值像素描述。HCL2000字庫是單字字庫,與日常手寫樣本仍存在巨大差別。SCUTCOUCH2009是華南理工大學開發(fā)的在線式大規(guī)模脫機手寫體漢字數(shù)據(jù)庫,通過PDA和智能手機的觸摸屏收集手寫樣本,不僅包含單字庫,還有拼音庫、單詞庫、繁體字庫和符號庫等。SCUTCOUCH2009漢字庫雖然包含單字和單詞,但沒有整段文檔,且不包括書寫者信息,仍未達到日常手寫文本的級別。HIT-MW數(shù)據(jù)庫由哈爾濱工業(yè)大學構建,是首個無監(jiān)督漢字文檔數(shù)據(jù)庫,書寫內容約200字左右,均選自《人民日報》,因此,HIT-MW數(shù)據(jù)庫中的手寫體樣本可以看作是真實的手寫體樣本。HIT-MW數(shù)據(jù)庫同時還包含了樣本書寫者的性別、年齡和職業(yè)信息。
上述4種數(shù)據(jù)庫中,只有HCL2000和HITMW數(shù)據(jù)庫考慮到了書寫者個人信息的錄入,但都不包含書寫者的民族信息。中國是一個和諧統(tǒng)一的多民族國家,藏族、蒙古族、維吾爾和朝鮮族等少數(shù)民族不僅使用本民族的語言文字,還能夠熟練掌握漢字。我國在研究漢字識別的同時,也積極開展少數(shù)民族語言文字的識別與保護研究。漢字與少數(shù)民族文字在文字構成和書寫行款上有著或多或少的差異:例如,漢字沒有圈、點、曲線等筆畫,蒙文、藏文和維文卻包含大量這種結構元素;漢字目前多采用橫向的書寫方式,但是蒙文卻采用縱向的書寫方式。因此,少數(shù)民族同胞在使用漢字時,其母語文字會對漢字的書寫習慣產(chǎn)生影響。所以,在脫機手寫體漢字數(shù)據(jù)庫的構建中,不僅要考慮涵蓋更多的漢字樣本,還應考慮到樣本書寫者的民族信息。大連民族學院是國家民族事務委員會直屬的,以工科和應用學科為主的民族高等學校,現(xiàn)有在校學生擁有56個民族成份,少數(shù)民族學生占60%以上,能夠為研發(fā)多民族脫機手寫體漢字數(shù)據(jù)庫提供強有力的人員和技術保障。
1 數(shù)據(jù)庫樣本設計
目前,大連民族學院信息與通信工程學院已完成多民族脫機手寫體漢字數(shù)據(jù)庫的Ⅰ期數(shù)據(jù)庫(簡稱為DNU-Ⅰ)的構建,包括單字、行文本和段文本3個子數(shù)據(jù)庫,書寫者為大連民族學院的部分教師和在校學生。為構建脫機手寫體漢字數(shù)據(jù)庫首先必須規(guī)劃樣本采集策略,設計滿足要求的樣本采集卡。由于DNU-Ⅰ數(shù)據(jù)庫包含單字、行文本和段文本3個子庫,為了方便后續(xù)字符圖像預處理,設計兩種樣本采集卡,即單字采集卡和段文本采集卡,分別如圖1和圖2。單字采集卡選擇《百家姓》和《三字經(jīng)》的部分篇章作為書寫內容,供提取單字字符圖像使用。DNU-Ⅰ數(shù)據(jù)庫的段文本采集的書寫內容不同于HIT-MW數(shù)據(jù)庫:HIT-MW數(shù)據(jù)庫的書寫內容均來自《人民日報》;DNU-Ⅰ數(shù)據(jù)庫的段文本采集卡選擇《毛主席詩詞》和《牡丹亭》的部分篇章作為書寫內容,供提取行文本和段文本圖像使用。圖1和圖2的每種采集卡都包含書寫者姓名、性別、年齡、民族、學歷和職業(yè)等信息,在書寫者完全知情并同意的情況下完成樣本的采集。如圖3是兩種采集樣本實例。書寫者在完全自由的情況下完成樣本采集卡指定內容的書寫,因此會出現(xiàn)涂抹、文本行傾斜、斷句方式不同等現(xiàn)象,如圖4,這些都符合實 際書寫情況。

圖1 單字采集卡 圖2 段文本采集卡

圖3 樣本采集實例

圖4 樣本不同情況示例
2 圖像預處理
原始的采集樣本通過EPSON EXPRESSION 10000XL掃描儀在300dpi×300dpi的分辨率下掃描成RGB彩色模型的JPEG圖片。但這些圖像并不能直接用于字符識別的研究,需經(jīng)過彩色圖像的灰度化、灰度圖像的二值化、字符圖像歸一化、行分割等預處理。
2.1 灰度化和二值化
目前字符的特征提取方法主要針對灰度圖像和二值圖像。為了便于數(shù)據(jù)庫用戶對字符圖像進行去噪、細化、特征提取等處理,避免重復操作,必須對掃描的彩色圖像進行灰度化,對灰度圖像進行二值化處理。
RGB彩色圖像是一個包含紅、綠、藍三原色的3維數(shù)組。RGB彩色圖像轉換為灰度圖像的原理是將紅、綠、藍三種分量按照一定的比例換算成灰度值,如公式(1)所示:

式中,V代表灰度值,R代表紅色亮度值,G代表綠色亮度值,B代表藍色亮度值。
圖像的二值化是將灰度圖像通過選定的閾值將圖像灰度矩陣轉變成只有0或1的邏輯矩陣的方法。閾值的選取是圖像二值化的關鍵,對文檔的后續(xù)識別處理也有一定的影響。本文采用Otsu法[6]確定閾值。Otsu法的實質是通過迭代法尋找使圖像前景和背景兩類的類內方差最小的閾值。
2.2 歸一化
經(jīng)過二值化的圖像還需要歸一化為統(tǒng)一的規(guī)格。歸一化的尺寸一般由用戶根據(jù)算法需要自行確定,缺乏相應的準則。實踐中,許多研究者和同類數(shù)據(jù)庫都將單個字符圖像歸一化為64×64像素,因此本數(shù)據(jù)庫將單字庫中的字符歸一化為64×64像素大小的二值圖像。如圖5顯示了單字庫中“趙”字經(jīng)過灰度化、二值化和歸一化處理后的結果。如果數(shù)據(jù)庫用戶要研究字符圖像的歸一化方法,則直接選擇原始的掃描圖像即可。
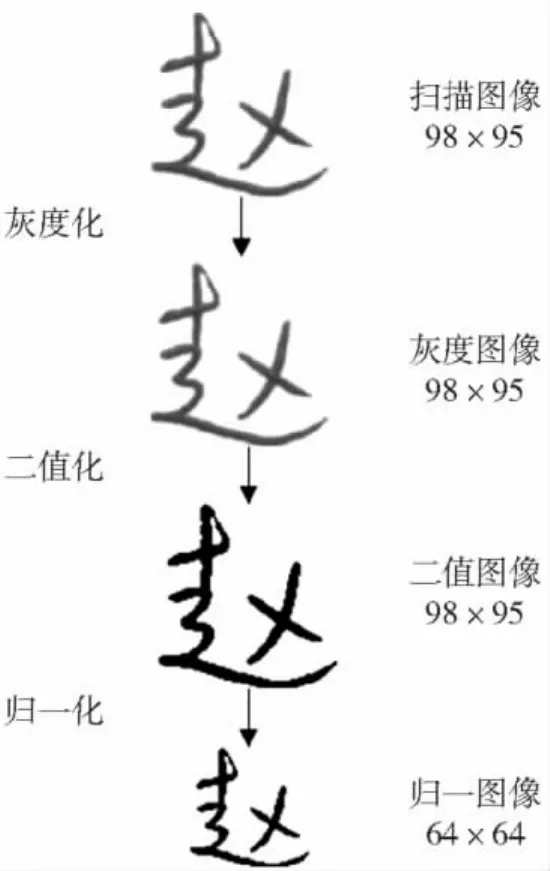
圖5 單字圖像預處理過程
2.3 行分割
行分割又稱行切分,是指將漢字以“行”為單位進行分割。漢字切分的研究建立在行文檔的基礎之上,行分割是漢字切分的前提條件。目前通用的行分割算法是投影法[7]。投影法首先對段文本圖像進行行像素點統(tǒng)計,找到全部為白色像素點的行,即為行與行之間的間隔,如圖6。但是由于會出現(xiàn)行文本相連接的情況導致行間隔不是全白像素,因此許多學者在投影法的基礎上,提出了相應的閾值算法,在某些特定規(guī)則下取得了較好的切分效果。本數(shù)據(jù)庫不僅提供段文本供用戶研究行分割算法,而且還提供行文本數(shù)據(jù)庫方便用于對字符分割的研究。因此需將數(shù)據(jù)庫的段文本掃描圖像分割成單獨的文本行,組成行文本數(shù)據(jù)庫。為了提高工作效率,采用Photoshop或“光影魔術手”等專業(yè)圖像處理軟件的圖像裁剪功能實現(xiàn)行分割,構建用于字符分隔的行文本數(shù)據(jù)庫,樣本如圖7。

圖6 投影法行分割示意圖

圖7 行文本數(shù)據(jù)庫樣本
3 結語
大連民族學院DNU-Ⅰ數(shù)據(jù)庫是具有自主知識產(chǎn)權的,唯一一個記錄了書寫者民族信息的脫機手寫體漢字識別數(shù)據(jù)庫。該數(shù)據(jù)庫包含單字數(shù)據(jù)庫、行文本數(shù)據(jù)庫和段文本數(shù)據(jù)庫3個子數(shù)據(jù)庫,每個數(shù)據(jù)庫有60個樣本,涵蓋了滿族、回族、維吾爾族、白族、土家族、壯族、蒙古族、彝族、苗族、哈尼族和朝鮮族等少數(shù)民族,少數(shù)民族書寫者共36人次,占總書寫人數(shù)的60%。該數(shù)據(jù)庫為研究不同民族的漢字書寫特征及影響識別率的相關因素提供了研究的基礎,應用領域主要集中在少數(shù)民族漢字書寫特征分析、中文文檔的行切分、漢字的切分識別、中文文本的無切分識別、標點識別、筆跡鑒別和簽名驗證等方面。本文還分析了字符圖像預處理的相關技術,為少數(shù)民族文字數(shù)據(jù)庫的構建提供必要的技術支撐。目前該數(shù)據(jù)庫已完成了Ⅰ期數(shù)據(jù)庫的構建,但是涵蓋的漢字范圍有待進一步擴充,目標是盡量完全覆蓋一級漢字,并涵蓋少量二級漢字。同時,還需擴大書寫者的范圍,特備是針對少數(shù)民族書寫者,目標是完全包含56個民族,并且加強少數(shù)民族書寫者的比重。
致 謝
感謝大連民族學院信息與通信工程學院通信094班、電子072班和機電信息工程學院自動化096班的同學為本數(shù)據(jù)庫建立提供手寫樣本。感謝信息與通信工程學院電子072班王純、王野和王路平同學所做的圖像處理工作。
[1]趙繼印,鄭蕊蕊,吳寶春,等.脫機手寫體漢字識別綜述[J].電子學報,2010,38(2):405 -415.
[2]http://www.is.aist.go.jp/etlcdb/[OL].2008-11-14.
[3]郭軍,藺志青,張洪剛.一個新的脫機手寫漢字數(shù)據(jù)庫模型及其應用[J].電子學報,2000,28(5):115–116.
[4]SU Tonghua,ZHANG Tianwen,GUAN Dejun.HIT -MW Dataset for Offline Chinese Handwritten Text Recognition[C].Proceedings of the 10th International Workshop on Frontiers in Handwriting Recognition ,IWFHR,2006.
[5] JIN Lianwen,GAO Yan,LIU Guang,et al.SCUT -COUCH2009-a comprehensive online unconstrained Chinese handwriting database and benchmark evaluation[J].International Journal of Document Analysis and Recognition,2011,14(1):53-64.
[6]Otsu,N.A Threshold Selection Method from Gray -Level Histograms.IEEE Transactions on Systems,Man,and Cybernetics,1979,9(1):62 -66.
[7]于明,張彥云,薛翠紅,等.筆跡圖像中的單個漢字字符分割[J].計算機工程與應用,2010,46(9):180 -182.
DNU-Ⅰ Multi-national Offline Chinese Handwritten Database of Dalian Nationalities University
ZHENG Rui-rui,ZHAO Ji-yin,LI Min,YU Wei-min,WU Bao-chun
(College of Information & Communication Engineering,
Dalian Nationalities University,Dalian Liaoning,116605,China)
An offline Chinese handwritten characters and text database,DNU -Ⅰmulti-national offline Chinese handwritten database of Dalian Nationalities University,has been presented to record the writers’national information.Dalian Nationalities University has the copyright of the DNU - Ⅰdatabase.The DNU - Ⅰdatabase consists of 3 subsets,the single character dataset,the single line dataset and the paragraph dataset.Each sample of the DNU - Ⅰdatabase recorded the writer’s information,such as his or her name,nationality,gender and education.The proportion of writers from minority nationalities is 60%.The DNU-Ⅰdatabase can be used to conduct written features of minority nationalities,Chinese text line segmentation,Chinese characters segmentation,segmentation-free recognition,writer identification,signature verification and provide benchmark for algorithms comparison.Meanwhile,common construction procedures of character recognition database and the binarization,normalization,and line segmentation methods of character image pre-processing,which can provide technique support for minority nationalities’written languages,has been introuduceed.
Offline handwritten Chinese Recognition;database;minority nationality;image processing
TP391.1
A
1009-315X(2011)05-0502-05
2011-4-27;最后
2011-06-27
國家科技支撐計劃項目(2009BAH41B05);國家民委科研項目(10DL03);遼寧省教育廳項目(L2010094);中央高校基本科研業(yè)務費專項資金資助項目(DC10010103);大連民族學院人才引進科研啟動基金資助項目(20116203)。
鄭蕊蕊(1982-),女,河南開封人,講師,博士,主要從事智能圖像處理與模式識別研究。
(責任編輯 劉敏)
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
財經(jīng)(2017年15期)2017-07-03 22:40:49
財經(jīng)(2017年2期)2017-03-10 14:35:35
財經(jīng)(2016年15期)2016-06-03 07:38:02
財經(jīng)(2016年3期)2016-03-07 07:44:46
財經(jīng)(2016年6期)2016-02-24 07:41:51
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
