基于Nutch的校園網信息檢索系統的研究與實現*
2010-10-18 08:10:42宋光慧郭建康
中國教育信息化 2010年15期
宋光慧,聶 琰,郭建康
(1.浙江大學寧波理工學院 信息與教育技術中心,浙江 寧波315100;
2.寧波大學科技學院理工學院計算機系,浙江寧波 315212)
基于Nutch的校園網信息檢索系統的研究與實現*
宋光慧1,聶 琰2,郭建康1
(1.浙江大學寧波理工學院 信息與教育技術中心,浙江 寧波315100;
2.寧波大學科技學院理工學院計算機系,浙江寧波 315212)
本文通過分析校園網內信息資源的特點,在Nutch搜索引擎的基礎上,構建了基于校園網各Web網站站內檢索和統一檢索平臺兩層體系結構的校園網信息檢索系統,有效地提高了檢索效果。
Nutch;信息檢索;搜索引擎;索引優化;漢語分詞;排序算法
目前校園網信息檢索主要采用兩種方式。一種方式是Web網站構筑站內搜索功能,采用數據庫查詢的方式進行。通常是通過匹配標題、作者、摘要等字段的關鍵字信息來實現信息檢索,由于受到數據庫性能、檢索效率等因素的影響不能實現基于匹配正文內容的檢索,從而導致搜索效果下降。該方式也無法實現校園網信息資源的整合和共享。另一種方式是將基于互聯網的搜索引擎技術應用于校園網,構建校園網搜索引擎,但校園網在應用環境、網站構建、鏈接結構等方面與互聯網有所不同,主要表現為各網站獨立性較強,網頁間鏈接稀疏;檢索目標與內容相關度、時間的關聯性較強,而與網頁被鏈接的數量關聯性較弱;文檔關鍵字重復度高,周期性出現。因此采用互聯網搜索引擎基于網頁鏈接分析技術的頁面評分與排序算法往往不能達到令用戶滿意的檢索效果。針對上述問題,本系統采用基于Nutch的開源搜索引擎技術,構建校園網信息檢索系統,從而提高檢索的廣度、速度和精度。
一、系統體系結構
Nutch是一個開源的、Java實現的Web搜索引擎,提供了構建搜索引擎所需的基本工具模塊,包括網絡爬蟲、文本分析、分詞工具、建立索引、搜索功能和結果過濾等,具有透明性高、易于理解和擴展性好等特點。本系統以MyEclipse8.0作為開發平臺,在Nutch搜索引擎的基礎上對其分詞模塊、索引模塊、搜索和排序模塊進行了二次開發,以適應校園網的具體應用環境。
校園網信息檢索系統體系結構分為兩層。下層面向各Web網站,基于Nutch構建站內文檔搜索引擎,建立各自網站的文檔索引并提供搜索功能,替代基于數據庫的檢索方式,從而提高檢索效果和效率;上層為面向校園網范圍的信息檢索平臺,通過對各個Web網站的索引進行合并和優化,來構建統一共享的檢索平臺,系統體系結構如圖1所示。
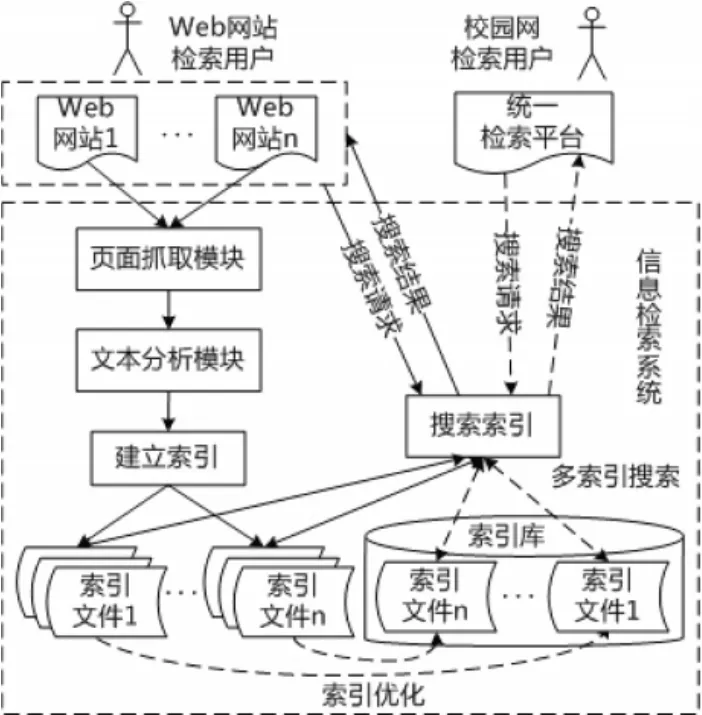
圖1系統體系結構
通過該體系結構在下層可以為各個Web網站提供全文信息檢索功能,既可以有效緩解各Web網站服務器的壓力,又可以提高網站的檢索性能。基于Nutch的搜索引擎對各Web網站的網頁進行抓取,經過文本分析與分詞處理后建立索引,校園網內每個Web網站都建立各自的索引文件,并為各自的Web網站用戶提供獨立的信息檢索功能。在上層系統通過對校園網內各Web網站索引文件的整合,經過索引優化后,實現對多索引的搜索功能,從而為校園網用戶提供統一的信息檢索平臺,并利用各Web網站用戶的檢索關鍵詞記錄建立智能輔助檢索關鍵詞庫,方便校園網用戶的使用。
二、系統主要功能模塊
1.漢語分詞模塊
信息檢索的基礎是文本分析,而文本分析在很大程度上依賴于分詞模塊對語言的處理。Nutch自帶的CJK分詞模塊對中文分詞的效率和準確度上不能滿足實際需要。為此,在對比了JE分詞、Paoding分詞和ICTCLAS分詞等多款中文分詞模塊后,Paoding分詞由于其開源性和良好的分詞效果被本系統采用,并通過Nutch的插件機制集成到系統當中。其原理是Nutch中的抽象類Analyzer類實現了配置和插入中文分詞模塊的接口,該抽象類中定義了一個公有的抽象方法tokenStream(String fieldName,Reader reader),返回的類型是TokenStream。Paoding分詞的分詞類返回類型也是 TokenStream,故只需將參數fieldName和reader作為Paoding分詞的輸入參數并將其結果返回給Analyzer類即可。
2.索引優化與多索引搜索
為了有效整合多個Web網站的索引文件,并作為整體提供給統一的信息檢索平臺,需要進行索引優化,使每個網站只生成一個索引文件。優化索引其實就是將多個索引文件合并成單個文件的過程,目的是減少索引文件的數量,并且能在搜索時減少讀取索引文件的時間。Nutch中的IndexWrite類提供了 optimize方法實現該優化操作。要使校園網用戶在輸入一個關鍵詞后,能夠得到全部Web網站的查找結果,就要對不同Web網站優化之后的索引文件進行檢索。利用Nutch中的MultiSearcher類可實現該功能,檢索結果會以一種指定的順序合并起來。
3.自定義文檔排序方法
根據Nutch自身的關鍵字相關度排序、索引順序排序和基于互聯網的PageRank引用機制排序都不能在校園網中取得很好的效果。在綜合考慮了網頁的時效性、訪問量和相關度等因素后,系統采用了自定義的排序機制,文檔內容相關度作為主要的排序依據,并通過激勵因子boost值來改變文檔的得分,從而調整文檔的出現順序。激勵因子boost=1+max(0,距本學年開始的發布時間)+頁面訪問量/平均訪問量。對于在頁面中無法抓取到發布時間和訪問量的情況,上述兩值別分按照0和平均值處理。由于boost值必須在建立文檔索引階段進行設置,所以目前系統每天進行一次校園網內網頁抓取并建立索引。
4.多文檔結構的支持
在校園網內,師生大量使用Word、Excel、PDF等文檔格式,因此檢索系統提供了對上述文檔的全文檢索功能。由于上述文檔并不是純文本格式,在處理時需要根據他們的特殊格式提取內容后再進行分析處理。在Java對Word、Excel的開源解決方案中,本系統采用了POI插件的方式;用PDFBox插件來實現對PDF文檔的讀取。
5.智能輔助搜索
系統的兩層體系結構能夠使位于上層的統一信息檢索平臺充分利用下層各Web網站的用戶檢索信息。對于使用Web網站站內檢索的用戶來說,通常都是熟悉該網站或與該網站內容相關性較大的用戶,他們的檢索記錄在經過一定的分析處理后,可作為知識庫來為統一信息檢索平臺提供智能的輔助檢索功能。
三、系統運行環境
系統整體采用Java語言實現,采用Windows平臺運行。但由于運行Nutch自帶的腳本命令需要Linux環境,所以必須首先安裝 Cygwin來模擬這種環境。為了確保Nutch1.0版本能夠正確運行,Java虛擬機需采用JDK 1.6以上的版本。系統采用Tomcat 6.0作為各級Web檢索平臺的容器。運行環境示意如圖2所示。
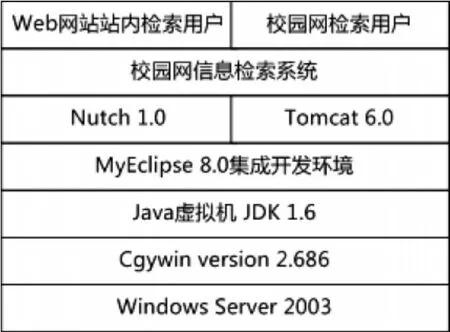
圖2 運行環境示意
四、結束語
基于Nutch的校園網信息檢索系統建設有效地解決了各Web網站全文信息檢索功能不足的問題,同時統一檢索平臺的搭建為校園網用戶提供了方便快捷的信息檢索通道,對校園信息化建設起了很好的推進作用。目前系統已經在站內搜索和統一檢索平臺兩個層面實現了基于關鍵字的檢索功能,排序算法也達到了預期的設計要求。今后工作的重點是在此系統基礎上對各種校園網資源進行整合、共享,提供對多種異構數據源的支持,使之成為一個綜合性應用平臺;同時在信息檢索技術的基礎上對校園網輿情監控技術進行深一步的研究。
[1]Otis Gospodneti,Erik Hatcher.Lucene in Action中文版[M].北京:電子工業出版社,2007.
[2]邱哲,符滔滔.發自己的搜索引擎[M].北京:人民郵電出版社,2007.
[3]馬志強等.校園網搜索引擎的研究與實現[J].北京機械工業學院學報,2007(22):12-15.
[4]李粵,安捷,李星.排序融合算法在校園網搜索引擎中的應用[J].大連理工大學學報,2005(45):257-260.
[5]蔡建超,郭一平,王亮.基于Lucene.Net校園網搜索引擎的設計與實現[J].計算機技術與發展,2006(11):73-80.
(編輯:金冉)
TP393.08
B
1673-8454(2010)15-0065-02
寧波市教育科學規劃研究課題(2010-YGH057)。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
新聞傳播(2016年18期)2016-07-19 10:12:06
現代計算機(2016年11期)2016-02-28 18:35:15
中國衛生(2015年12期)2015-11-10 05:13:38
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
河南科技(2014年11期)2014-02-27 14:10:19
