定期維護書目數據中格式問題的有效方法
2009-09-02 06:43:52李湜清
河南圖書館學刊 2009年3期
李湜清
關鍵詞:CNMARC數據;數據檢查;批處理
摘 要:本文總結了書目數據庫中數據的來源及建立,詳盡地介紹通過計算機排序方式批檢查數據中的錯誤,以進一步提高書目數據的準確性和一致性。
中圖分類號:G254.3文獻標識碼:A 文章編號:1003-1588(2009)03-0104-03
書目數據庫是圖書館自動化建設的基礎和保障,也是文獻檢索網絡化、信息資源共享的重要依據,同時還是圖書館為讀者服務的重要途徑。館藏數據庫的質量直接代表了圖書館的基礎業務水平。書目數據的標準化、規范化、準確化、一致化是數據庫建設的核心問題,定期對數據庫中的數據進行批處理檢查維護可減少錯誤率,尤其是采用人工校對在前,批處理檢查在后兩者相互結合的方式,可以極大地降低書目數據中不必要的錯誤和不一致的著錄問題。作為圖書館的編目部門,應建立起一套書目數據的維護機制,將批處理維護工作納入日常工作之中。
以首都圖書館具體情況為例,本文所談到的關于批處理維護的數據主要指經人工審校進入總書目庫的數據,其中包括自建數據和套錄數據。經過人工審校過的數據一般不存在著錄方面的錯誤,如200字段題名責任者的選取著錄、各類附注字段詳細著錄、名稱標目的規范等,但是有不少不一致,不統一的地方,如自建數據與套錄數據中叢書與附注著錄的不一致,數據各字段相互對應點沒有著錄一致等問題。通過批處理檢查的方式可以快速全面地找到錯誤點,比起人工翻查數據審校費時、費力是占有絕對優勢的。
1 目前數據庫中存在的主要問題
1.1 叢書著錄不一致
叢書著錄一致性是最大的問題。首先,由于總書目庫中的數據是由自建數據與套錄數據共同組成的,審校人員也是分組的,所以就造成了對數據著錄理解不一樣、著錄不一致的問題;其次由于套錄數據主要是下載國家圖書館和幾大聯合編目中心數據,各家數據著錄本身就有不一致的問題存在。另外,還有一些比較模糊、難以界定的系列書也是當前編目人員在著錄225字段與300字段的疑難點。
1.2 數據中對應點的問題
圖書館的編目工作是一項非常重注專業技術和認真負責的工作,一條CNMARC數據小至幾百個字節,大至兩千多個字節,十幾項字段幾十個子字段確實需要編目員具備踏實的態度和高度的責任心。從數據檢查上來說,數據上的細節問題也是比較重要的,數據中的各字段中有許多與其它字段相互對應的地方,比如說210字段與102字段是相關字段;105字段與215字段、6字段都有相關的對應點。
1.3 對于主題字段的檢查
相對于數據中的格式檢查來說,主題字段的情況比較復雜,但是通過批處理校對,對于主題標引、分類還是可以發現一些一致性的問題。將600、601、602、605、606、607字段中的子字段$a$x$j$y$z分別抽取出來,并給予排序,可以校對出著錄錯誤的字段,例如600字段錯著為606字段等常規性問題,還可以將各字段的主題詞與分類號分別給予排序,查找出不規范的用詞和同類書著錄不一致的問題。
2 通過批處理檢查數據庫中錯誤的方法
我館的批處理數據方法主要是對進入總書庫的數據進行定期的檢查,一般每批的數據在一萬至兩萬種之間比較適宜。在檢查時,針對某一方面的問題將字段中的相關子字段按文本文件(TXT文件)抽取出來,導入至EXCLE表格中進行計算機排序。通過排序這種方法,檢查人員可以更直觀地檢查到出現的問題。
流程為:將要檢查的子字段抽取至TXT文件中→自建表格→工具→導入外部數據→導入數據→選擇我的信息源→選擇文件→導入→按檢查問題排序→檢查。
2.1 對子字段中固定內容的檢查方法
對于字段中有固定內容的子字段,通過一級排序方式是比較容易排查錯誤的。我館在批檢查時,主要有這些子字段:010字段的$a$b$d、102字段的$a、300字段的$a、305字段的$a、306字段的$a、307字段的$a、310字段的$a、905字段的$a、801字段的$a$b$c、905字段的$f。上述這些子字段可以一次性抽取至表格中的各個列中,由于各個子字段的檢查問題不相互對應,所以可以依次對每列中的內容進行排序檢查。以上述幾個子字段為例,抽取至表格中的形式如下:
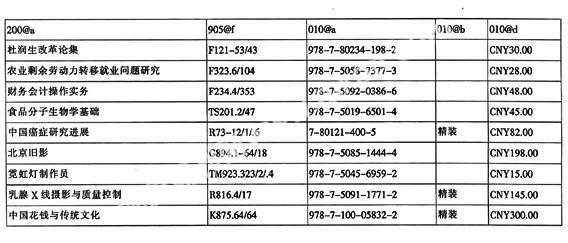
一級排序010@d后發現錯誤的表格:
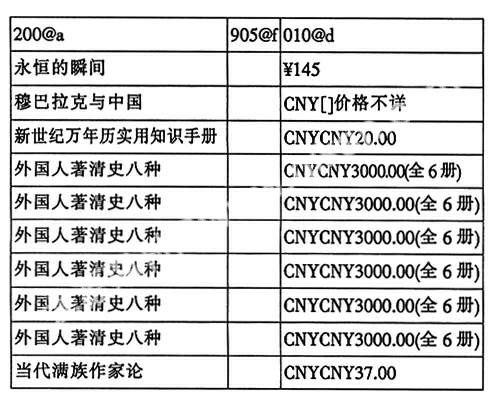
2.2 對子字段中對應點問題的檢查方法
對于字段中相關子字段排查一致性問題時,就要將問題所相對應的子字段一并抽取出來,通過二級或三級排序的方法進行檢查。我館所批檢查的對應子字段主要有:
100字段$a中第8-16位與210字段的$d$h、205字段的$a
102字段的$b與210字段的$a$c
105字段的$a與215字段的$c
106字段的$a與215字段的$d
200字段的$a、$e與517字段的$a
200字段的$d$z與510字段的$a、304字段的$a、312字段的$a
225字段的$a$h$i與461字段、462字段、300字段
200字段的$f$g與701字段、702字段、711、字段、712字段的$a$4
二級排序以102字段的$b與210字段的$a$c為例,相對應子字段抽取:
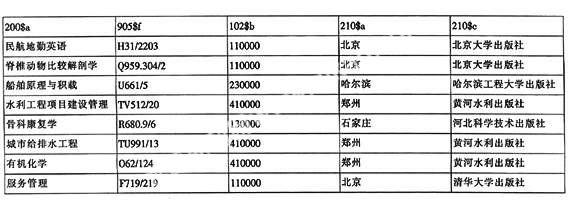
經102$b、210$a和210$c依次三級排序后檢出的問題:

2.3 對主題字段的檢查方法
相對于書目數據中批處理檢查這種方式,對主題和分類的檢查比起對格式的檢查就有很大的局限性。首先主題標引和分類是比較靈活多變,一條數據經常會出現兩個以上的標引字段;其次,同一主題字段的同一子字段會分入不同的大類中,與格式的固定對比是不同的。所以,我們在批處理主題標引和分類字段時,要按照大類號進行抽取,數據一次抽取在五至六萬條(一個表格最多存貯6萬行),然后按類號、書名和主題字段三級排序進行檢查,這樣既可以檢查出規范用詞,也可以查找到同一類、同一題名的分類標引情況。如,同一類號不同主題詞:
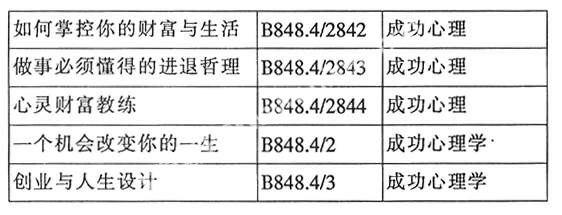
3 通過批處理審校檢查出的一些問題
對于做書目數據格式校對的工作人員來說,通過批校對可以既快速又全面地檢查數據中的錯誤點,不但節省時間和精力,而且從錯誤的查全率和查準率上都比人工校對要準確。以下列舉一些通過批校對在具體工作中發現的錯誤:
其一:
010 ##$a978-7-5006-8417-6$bCNY58.00
2001#$a民營經濟“試驗田”:溫州$9min ying jing ji“shi yan tian”:wen zhou$f盧建文著(010字段子字段著錄錯誤,通過一級排序校出)
其二:
010##$a978-7-5317-2373-8$b精裝$dCNY29.00
102##$aCN$b110000
2001#$a愛?配方$9ai?pei fang$f(美)戴安娜?德?盧卡著$g李永燦譯
210##$a哈爾濱$c北方文藝出版社$d2009
(102字段$b與210字段$a$c不對應,通過二級排序校出)
其三:
2001#$a宗教論$9zong jiao lun$f馮天策著
215 ##$a341$d21cm
(215子字段$a頁數無“頁”字)
2001#$a贏在深圳$9ying zai shen zhen$e陳志列的研祥創業之道$f樊榮編著
2252#$a中國制造系列
2001#$a化蛹為蝶$9hua yong wei die$e金蝶集團的成功之路$f田宏文編著
300##$a中國制造系列
(叢書與附注項著錄不一致的問題)
其四:
2001#$a信息霍亂$9xin xi huo luan$e世紀末的冷面殺手$f劉樹秀主編$g聶巧等編著
6060#$a互連網絡$x基本知識
6060#$a計算機犯罪
2001#$a暢游網絡世界$9chang you wang luo shi jie$f卓越文化編著
6060#$a互聯網絡$x基本知識
(主題詞改為用代關系,批處理替換)
4 小結
書目數據人工審校后進入總數據庫并不意味著大功告成,還要進行經常性的更新和維護。通過收集編目人員在平時使用過程中的反饋信息,定期對數據內容進行更新追加、維護和修改,從而可以極大地提高數據信息資源的質量。
參考文獻:
[1] 逯仰章.CNMARC的關聯字段[J].圖書館園地,2007,(3).
[2] 張智慧.中文圖書套錄編目中出現的問題及解決方法[J].圖書館工作與研究,2006,(6).
[3] 倪娟.CNMARC數據套錄問題之我見[J].科技情報開發與經濟,2007,(6).
[4] 陳曉蘭,張德云.論圖書館聯機聯合編目中套錄數據質量控制問題[J].圖書館,2008,(2).
[5] 陳艷茹.叢編字段標準化著錄淺析[J].農業圖書情報學刊,2007,(7).
