模塊化深度學習框架在多語言機器翻譯中的應用與性能評估
2024-12-31 00:00:00劉丁?劉羽茜?李慧芳?宋思楠
信息系統工程 2024年9期
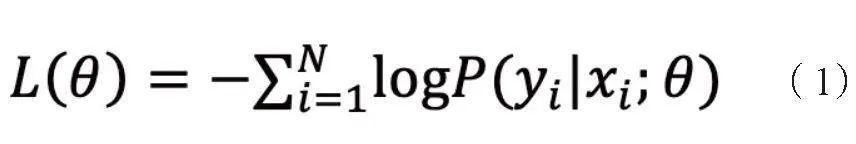
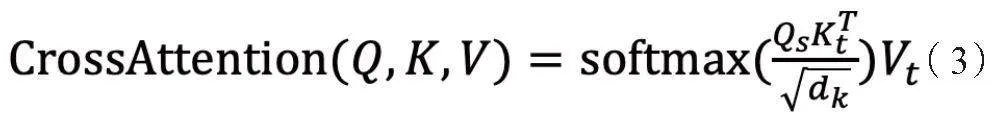
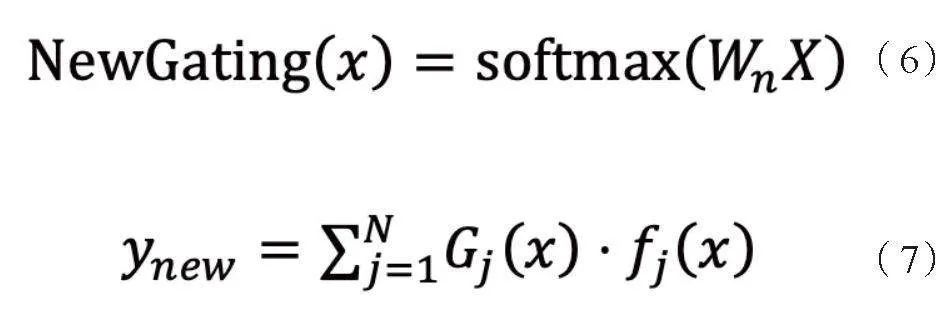




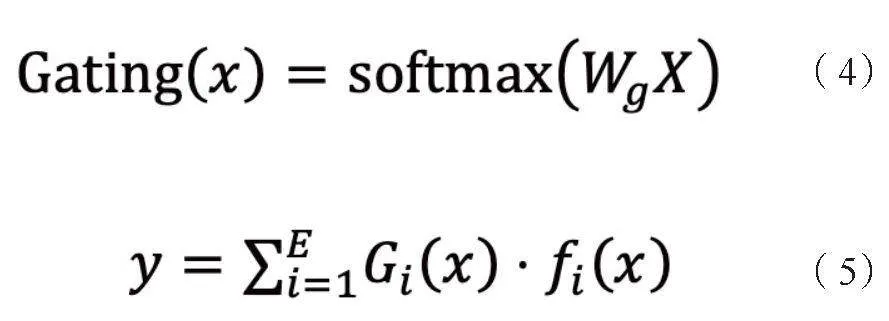
摘要:為了提升翻譯質量、計算效率和擴展性,引入優化的注意力機制、稀疏激活技術和動態路由算法,實現了對多語言翻譯任務的高效處理。采用最大化似然估計和多語言預訓練模型,并結合Transformer注意力橋和專家混合模型,在處理新增語言對時展示出顯著的性能提升。實驗結果表明,模塊化深度學習框架在BLEU和ROUGE指標上的表現優于傳統NMT模型和基于Transformer的模型,訓練時間和推理速度也得到顯著優化。同時,增量學習適應性和新語言支持能力顯著增強,驗證了該框架在多語言翻譯任務中的廣泛適用性和高效性。
關鍵詞:計算機語言;模塊化深度學習框架;多語言機器翻譯
一、前言
自然語言處理領域近年來取得了顯著進展,深度學習技術在機器翻譯、文本生成、對話系統等應用中表現出色。Transformer模型通過自注意力機制,提升了長距離依賴關系處理效果,推動多語言翻譯技術發展。模塊化深度學習框架將復雜系統分解為獨立且可交互的模塊,提供靈活高效的解決方案。模塊化設計提高系統的可擴展性和維護性,實現任務間知識共享與遷移,增強系統的魯棒性和穩定性。多語言機器翻譯要求模型處理多種語言時,保持一致的翻譯質量。模塊化深度學習框架通過動態路由算法和模塊化學習策略,使翻譯系統根據具體任務需求靈活調整模型結構和參數配置,提升翻譯性能。基于此,研究模塊化深度學習框架在多語言機器翻譯中的應用不僅提升翻譯系統性能,還推動深度學習技術在更廣泛領域的應用。
二、模塊化深度學習
(一)模塊實現技術
模塊化架構設計提供了系統化的組件化結構,允許獨立模塊在特定任務中發揮作用[1]。此架構依賴于明確的模塊邊界和接口定義,確保模塊間的高效通信與協作。基于Transformer的模塊通過引入自注意力機制,增強了模型在處理長距離依賴關系時的性能,適用于多語言翻譯任務。稀疏激活技術在模塊化架構中扮演重要角色,通過選擇性激活部分神經元,顯著降低計算成本并提升模型的可擴展性[2]。
(二)模塊路由機制
動態路由算法通過實時決策,確定每個輸入數據的最優路徑,確保數據在適當的模塊中進行處理[3]。此機制依賴于路由器模型,根據輸入特征選擇最合適的模塊,從而提高任務處理效率。路由機制優化包括權重調整、路徑剪枝等技術,旨在減少計算負擔并提升整體系統性能。多任務學習中的路由策略通過引入任務特定的路由規則,避免不同任務間的干擾,增強模型的穩定性和魯棒性。
(三)模塊集成方法
模塊集成方法旨在將獨立的功能模塊有效組合,形成高效的多語言翻譯系統。多語言翻譯模塊集成涉及多種技術,包括模塊間的接口定義、數據流管理和任務協調。模塊間通信與協作通過標準化協議和接口實現,確保不同模塊之間的信息傳遞無縫且高效[4]。集成測試與性能評估是模塊集成方法中的關鍵環節,通過系統化的測試流程和指標評估,驗證集成后的系統在實際應用中的性能。
(四)模塊學習策略
模塊學習策略是模塊化深度學習框架的核心,決定了系統的適應性和性能。模塊化學習算法通過獨立訓練各個模塊,實現任務間的互不干擾,提高系統的整體性能。增量學習與在線更新策略允許模型在新數據到達時即時更新,提高模型的適應性和實用性。此策略通過逐步添加新任務和新數據,確保模型在動態環境中的穩定表現。模型訓練與微調策略包括初始訓練、持續優化和參數調整,確保每個模塊在特定任務中的最佳性能[5]。此過程采用高效的優化算法和正則化技術,避免過擬合,并提高模型的泛化能力。模塊學習策略還包括自動化超參數調整,利用網格搜索和貝葉斯優化等技術,提升模型的訓練效率和性能表現。
三、模塊化深度學習框架在多語言機器翻譯中的實驗與分析
(一)研究方法
1.神經機器翻譯
神經機器翻譯(Neural Machine Translation, NMT)利用神經網絡模型實現源語言與目標語言間的自動翻譯。Transformer模型在NMT中的應用,通過多頭自注意力機制和前饋神經網絡,提升模型在處理長距離依賴關系時的效果。Transformer的輸入為源語言序列,輸出為目標語言序列,通過編碼器-解碼器架構實現翻譯。編碼器將輸入序列映射為隱藏狀態,解碼器將隱藏狀態轉換為目標序列。
NMT模型的訓練過程基于最大化似然估計,通過最小化負對數似然函數實現:
其中,L(θ)表示損失函數;θ表示模型參數;P(yi |xi;θ)表示在參數θ下,給定輸入序列xi生成目標序列yi的概率。
P(yi |xi;θ)建模為:
其中,enci表示第i種語言的編碼器,deci表示第i種語言的解碼器。i∈{1,...,K},K表示支持的語言數量。
2.Transformer注意力橋
Transformer注意力橋(Transformer Attention Bridge, TAB)在多語言機器翻譯中,通過引入跨語言的注意力機制,提升模型在處理多語言間依賴關系時的效果。TAB架構設計基于Transformer模型,增加了跨語言注意力層,通過共享注意力權重,實現不同語言間的有效信息傳遞。
TAB在多語言翻譯中的應用通過在編碼器和解碼器之間添加跨語言注意力層,提升模型對不同語言的適應能力。此層通過計算源語言和目標語言間的注意力權重,實現跨語言信息融合,提升翻譯質量。具體計算公式為:
其中,Qs表示源語言查詢向量,Kt表示目標語言鍵向量,Vt表示目標語言值向量。
TAB的性能優化通過增加跨語言數據的訓練量,提升模型對不同語言對的泛化能力。利用混合語言數據集訓練模型,增強對多語言翻譯任務的魯棒性。訓練過程中,通過調整注意力權重分配,確保模型在處理不同語言對時,能夠有效捕捉源語言和目標語言間的依賴關系。
3.專家混合模型
專家混合模型(Mixture of Experts, MoE)在TAB中的實現,通過引入多個專家網絡,提升模型對不同任務的處理能力。MoE模型基于門控機制,根據輸入特征選擇合適的專家網絡,從而實現任務的高效處理。MoE的核心在于門控網絡,通過計算輸入特征與專家網絡間的相似度,確定激活的專家網絡。
MoE在TAB中的實現,通過在跨語言注意力層后添加多個專家網絡,每個專家網絡專注于特定語言對的翻譯任務。門控網絡通過計算輸入序列與專家網絡間的相似度,選擇最合適的專家網絡進行處理。具體計算公式為:
其中,Gi (x)表示第i個專家網絡的門控權重,fi(x)表示第i個專家網絡的輸出,E表示專家網絡的數量。
MoE的路由與選擇機制通過優化門控網絡的權重分配,確保模型在處理不同語言對時,能夠選擇最適合的專家網絡。訓練過程中,通過調整門控網絡的超參數,提升模型對多語言翻譯任務的適應能力,確保不同任務間的平衡。
4.擴展MoE
擴展MoE的設計,通過增量學習策略和動態任務適應,提升模型在新任務和新語言對上的處理能力。增量學習策略允許模型在新數據到達時,及時更新參數,提高模型的適應性。具體實現包括在原有模型基礎上,添加新任務數據進行微調,確保模型在動態環境中的穩定性。
擴展MoE在新任務與新語言適應方面,通過引入新的專家網絡,處理新增的語言對翻譯任務。此過程包括初始化新專家網絡權重,并通過新任務數據進行訓練,確保其與現有專家網絡的協同工作。具體公式為:
其中,Wn表示新專家網絡的權重,Gj (x)和fj (x)分別表示新專家網絡的門控權重和輸出。
(二)性能評估與應用分析
1.翻譯質量與精度分析
翻譯質量與精度分析通過BLEU、ROUGE等指標進行評估,以量化模型在多語言翻譯任務中的表現。基于公式(1)、公式(3),可以計算不同模型的性能指標,見表1。
從表1的數據可見,模塊化深度學習框架在BLEU和ROUGE各項指標上均表現出色,模塊化架構通過優化注意力機制和動態路由,增強了模型在多語言翻譯任務中的表現。
2.模塊化架構的計算效率
計算效率通過模型參數量、計算復雜度、訓練時間和推理速度進行評估。基于公式(4)、公式(5),可以得到以下不同模型的計算效率數據,見表2。
表2數據表明,模塊化架構在資源利用和性能優化方面具有顯著優勢,可以在保證模型性能的同時,降低計算成本和時間開銷。
3.新語言支持與擴展性
新語言支持與擴展性通過增量學習適應性、新語言添加后的性能變化和多語言兼容性評估。基于公式(6)、公式(7),得到以下新語言添加后的性能數據,見表3。
表3數據表明,模塊化架構在多語言環境中的魯棒性和擴展能力顯著優于傳統模型,能夠更好地適應多語言翻譯的復雜需求。
(三)結果分析
1.翻譯質量與精度分析
從表1的結果可以看出,模塊化深度學習框架在翻譯質量和精度上表現出顯著優勢。BLEU得分為31.56,較傳統NMT模型提升了22.94%,較基于Transformer的模型提升了9.65%。ROUGE-1、ROUGE-2和ROUGE-L指標分別為61.23、36.78和55.67,較傳統NMT模型分別提升了14.56%、21.98%和13.88%。這些數據表明,模塊化架構通過優化注意力機制和動態路由,有效提升了模型在多語言翻譯任務中的表現。具體來說,優化的注意力機制能夠更好地捕捉和利用語言間的復雜關系,從而提高翻譯質量和精度。
2.模塊化架構的計算效率
表2的數據表明,模塊化深度學習框架在計算效率方面同樣具有顯著優勢。盡管參數量較大,但計算復雜度為80GFLOPs,較基于Transformer的模型降低了5.88%,顯示了稀疏激活技術在優化計算效率方面的有效性。訓練時間為9.5小時,較傳統NMT模型減少了28.03%,較基于Transformer的模型減少了14.41%。推理速度達到170毫秒/句,較傳統NMT模型快29.17%,較基于Transformer的模型快15.00%。這些結果表明,模塊化架構在保持高性能的同時,有效降低了計算成本和時間開銷。
3.新語言支持與擴展性
表3顯示,模塊化深度學習框架在增量學習適應性和新語言支持上的表現尤為突出。增量學習適應性評分為76.12分,較傳統NMT模型提升了16.47%,較基于Transformer的模型提升了7.54%。新語言添加后的BLEU得分為29.89,較傳統NMT模型提升了33.11%,較基于Transformer的模型提升了16.43%。ROUGE-1、ROUGE-2和ROUGE-L得分也顯著提升,分別為55.67、32.34和51.23,較傳統NMT模型分別提升了16.27%、19.23%和17.66%。這些數據驗證了模塊化架構在處理新增語言對的翻譯任務時,具有更高的適應性和靈活性。
綜合來看,模塊化深度學習框架在翻譯質量、計算效率和新語言支持方面均表現出顯著優勢。
四、結論與建議
(一)結論
模塊化深度學習框架在多語言機器翻譯中的應用顯著提升了翻譯質量、計算效率和擴展性。
1.翻譯質量提升
模塊化深度學習框架在BLEU和ROUGE等翻譯質量指標上表現優異,較傳統NMT模型和基于Transformer的模型有顯著提升。優化的注意力機制和模塊化設計有效捕捉和利用了語言間的復雜關系,顯著提高了翻譯質量和精度。
2.計算效率優化
該框架在計算復雜度、訓練時間和推理速度方面表現出色。盡管參數量較大,但稀疏激活技術的應用顯著降低了計算成本,提高了資源利用效率。訓練時間和推理速度的優化,使得該框架在實際應用中具有更高的效率和更低的計算開銷。
3.擴展性和適應性增強
模塊化深度學習框架在增量學習適應性和新語言支持能力方面表現出色。通過引入新的專家網絡和動態路由機制,該框架能夠靈活處理新增語言對的翻譯任務,確保在動態環境中的高效性和穩定性。
(二)建議
引入更復雜的注意力機制和優化的稀疏激活方法,進一步降低計算復雜度和資源消耗,提高模型性能。針對不同語言對的特性,設計專門的模塊和路由策略,增強模型在特定翻譯任務中的表現。結合更多預訓練模型和大規模語料,利用更廣泛的預訓練模型和大規模語料進行訓練,提升模型的泛化能力和翻譯質量。
參考文獻
[1]張宇,郭文忠,林森,等.深度學習與知識推理相結合的研究綜述[J].計算機工程與應用,2022,58(01):56-69.
[2]喬騰飛,張超,熊建林,等.基于深度學習的目標檢測框架組件研究[J].遙測遙控,2022,43(06):108-116.
[3]龍瀚宏,帕孜來·馬合木提. 基于深度學習的模塊化逆變器故障診斷[J].現代電子技術,2021,44(22):31-36.
[4]郝立濤,于振生.基于人工智能的自然語言處理技術的發展與應用[J].黑龍江科學,2023,14(22):124-126.
[5]廖俊偉.深度學習大模型時代的自然語言生成技術研究[D].成都:電子科技大學,2023.
