基于近紅外光譜與高斯過程的高粱單寧含量快速檢測
2024-09-11 00:00:00趙瑾熠陳爭光衣淑娟
分析化學 2024年7期
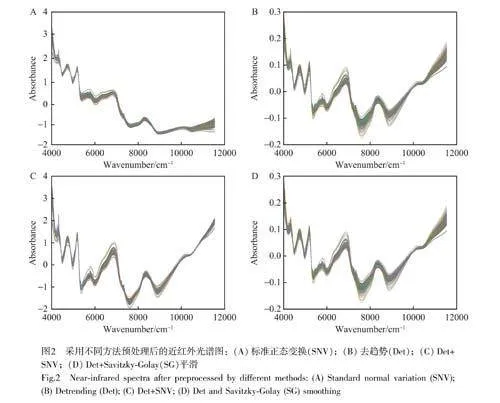


關鍵詞近紅外光譜;化學計量學;高粱單寧;高斯過程法;快速無損檢測
高粱是世界第五大糧食作物[1],也是我國重要的糧食作物之一[2]。高粱富含多種營養物質,在我國主要用作釀酒原料,而在國際市場主要用于飼料行業[3-4]。高粱作為釀酒原料時,籽粒中的單寧含量對產品品質具有決定性作用。這主要是由于單寧在釀酒過程中會產生丁香酸和丁香醛等風味物質,賦予白酒獨特的風味。同時,在發酵過程中,單寧還具有抑制有害微生物生長和提高出酒率的功效[5]。然而,單寧也是一種抗營養因子,味苦澀,具有收斂性。單寧可與蛋白質、糖類和金屬離子形成難以吸收的復合物,從而降低動物的攝食率,并影響營養物質的吸收利用率,但適量的單寧可以改善禽畜的生長性能,提高飼料的利用率[6-7]。因此,快速、高效和低成本地檢測高粱中的單寧含量對于高粱農業生產和質量控制至關重要。目前,高粱中單寧含量的檢測方法主要有人工經驗判別法和實驗室化學方法[8],人工經驗判別容易受主觀影響,效率低,難以形成統一的標準;實驗室化學方法操作繁瑣、費時費力,并且需要對樣品進行破壞性處理。近紅外光譜技術通過測量樣品在近紅外光譜范圍內的吸收和反射特性獲取樣品的化學信息,無需對樣品進行破壞性處理[9]。作為一種高效無損的檢測技術,近紅外光譜具有快速、無污染、無損傷和低成本等優點,并可以實現在線檢測[10]。
目前,研究人員已基于近紅外光譜構建了多種谷物養分預測模型,余松柏等[11]利用偏最小二乘回歸(Partial least squares regression, PLSR)模型對高粱的多個成分進行預測,采用多元散射校正(Multiplicativescatter correction, MSC)對采集的高粱光譜數據進行預處理,使用蒙特卡洛無信息變量消除法(Montecarlo-elimination of uninformative variables, MCUVE)選擇特征波長,建立的基于高粱完整籽粒的單寧PLSR回歸模型的預測集決定系數(Prediction set determination coefficient, RP 2 )為0.8841;使用MSC 結合Z-Score標準化進行預處理,使用反向區間偏最小二乘法選擇特征波長,建立的基于高粱粉末的單寧含量的PLSR 回歸模型的RP 2 為0.9414。盡管基于高粱粉末樣本的單寧含量預測模型精度高于基于高粱籽粒的模型,但是檢測過程需要破壞樣本。劉敏軒等[12]測定了60 份高粱籽粒的4 個部位以及整粒種子所組成的300 份樣本的6 種酚類物質的含量,其中,縮合單寧采用MSC 結合一階導數法(First derivative, FD)對光譜數據進行預處理,在此基礎上建立PLSR 模型,模型的RP 2 為0.9558。Dykes 等[13]對高粱籽粒的總酚、縮合單寧和3-脫氧花青素建立模型并進行預測,其中,縮合單寧的改進PLSR 模型的R2P 僅為0.81。Zhang 等[14]對葡萄果皮和種子中的單寧進行建模預測,分別使用MSC 結合支持向量機和Savitzky-Golay卷積平滑(Savitzky-golay smoothing, SG 平滑)結合PLS 建立果皮和種子的單寧預測模型, R2P 分別為0.8960 和0.9243。
高斯過程回歸(Gaussian process regression, GPR)是一種非參數的統計建模方法,基于高斯過程(Gaussian process, GP)的概念,將數據點視為隨機變量,并假設數據點服從多元正態分布,通過對已觀測到的數據點進行建模,可以預測未觀測到的數據點的值,并估計其不確定性,還可通過選擇合適的核函數而適應不同類型的數據和問題,從而提高模型的預測性能。GPR 對高維度、小樣本的數據具有較強的處理能力,并具有容易實現、收斂性好和超參數自適應性等特點[15]。GPR 在許多實際問題中都表現出色,已被應用于機器學習、統計學和工程學等領域。李元等[16]提出了一種基于GPR 的絕緣紙老化分析算法,并獲得了較高的準確率。張韜等[17]提出使用蜻蜓算法優化GPR 對鋰電池健康狀態進行預測,結果表明,模型預測精度高,運算速度快,尤其在處理小樣本方面更具優勢。以上研究表明,基于GPR 建立高粱單寧預測模型具有可行性。
基于近紅外光譜分析技術的單寧含量快速檢測已有大量的研究報道,但這些研究的建模方法相對單一,多采用PLS 建模方法,模型在預測集上的性能仍有提升可能。為了建立高粱單寧的快速檢測模型,本研究利用近紅外光譜技術采集高粱光譜,使用多種預處理方法,過濾光譜中的噪聲信息。在預實驗的基礎上,選用無信息變量消除法(Elimination of uninformative variables, UVE)選擇特征波長,提取光譜中的有效信息。在優選核函數基礎上,建立GPR 回歸預測模型,并與PLSR 和支持向量機回歸(Support vectormachine regression, SVR)等模型對比。通過計算模型的決定系數(Coefficient of determination, R2)、均方根誤差(Root mean square error, RMSE)和相對分析誤差(Relative percent deviation, RPD),選擇最優方案,建立高粱單寧含量的高性能預測模型,為高粱中單寧的快速檢測提供了技術支持。
1 實驗部分
1.1 儀器與試劑
TANGO FT-NIR 近紅外光譜儀(德國Bruker 公司); UV-1800 紫外可見分光光度計(AOE 翱藝儀器上海有限公司);WH-71 電熱恒溫干燥箱(天津市泰斯特儀器有限公司);DM-50g 粉碎機(南京東邁科技儀器有限公司);雙杰JJ224BC 電子分析天平(常熟市雙杰測試儀器廠);MK-60 低速臺式離心機(湖南邁克爾實驗儀器有限公司);VM-210 漩渦振蕩器(群安科學儀器浙江有限公司);HJ-1 磁力攪拌器(金壇區西城新瑞儀器廠)。實驗用水為蒸餾水。
單寧酸和檸檬酸鐵銨(分析純,福晨天津化學試劑有限公司);8.0 g/L 氨溶液(分析純,以達科技泉州有限公司);75%二甲基甲酰胺溶液(分析純,中國石化公司)。
2 g/L 單寧酸溶液:稱取0.2 g 單寧酸溶于蒸餾水中,定容至100 mL;3.5 g/L 檸檬酸鐵銨:稱取0.35 g 檸檬酸鐵銨溶于蒸餾水中,定容至100 mL。
1.2 樣品采集與處理
本研究選取的高粱樣本為2022 年黑龍江八一農墾大學農學院收獲的高粱,包含65 個品種,共計305 個樣本。利用TANGO FTNIR 近紅外光譜儀先測得每個高粱樣本完整籽粒光譜數據后,將其粉碎,過40 目篩(篩孔直徑0.425 mm), 采用檸檬酸鐵銨法[18]測定單寧含量。
1.3 單寧含量測定
按國標(GBT 15686—2008)方法[18]對單寧含量進行測定。稱取適量高粱粉碎后的樣本,采用二甲基甲酰胺溶液提取高粱單寧,經離心后,取兩份上清液,其中一份加水、檸檬酸鐵銨溶液和氨溶液,另一份只加水和氨溶液(檸檬酸鐵銨溶液替換成等體積水),顯色后,以水為空白對照,采用分光光度計測定525 nm 處吸光度值,采用單寧酸標準品繪制標準曲線。
單寧含量(X)以干基中單寧酸的質量分數(%)表示,按式(1)計算。
其中, C 為從標準曲線中讀取的試樣提取液中單寧酸的濃度(g/L);M 為試樣的質量(g);H 為試樣的水分含量(%)。
1.4 水分測定
按國標GB 5009.3—2016[19]中的直接干燥法測定水分含量,通過干燥前后的稱量數值計算出水分的含量。水分含量按式(2)計算:
其中, H 為試樣中水分的含量(%);M1 和M2 分別為干燥前和干燥后試樣的質量(g)。
1.5 光譜采集
采用TANGO FT-NIR 近紅外光譜儀采集305 份高粱籽粒在11542~3940 cm?1 范圍的近紅外光譜,測量方式為漫反射和透射,分辨率為8 cm?1。掃描32 次獲得平均光譜。
1.6 數據處理
數據處理軟件為The Unscrambler X(10.4 版)、Matlab(R2021a 版本)和Microsoft Office Excel。
1.7 定量模型的構建
以高粱的單寧作為分析指標,分別采用去趨勢(Detrending, Det)、標準正態變換(Standard normalvariate transformation, SNV)、去趨勢組合標準正態變換和去趨勢組合SG 平滑對光譜數據進行預處理。使用蒙特卡洛交叉驗證法(Monte Carlo cross-validation, MCCV)結合GPR 建模對原始光譜進行異常樣本剔除。采用隨機法(Random selection, RS)按照8∶2 的比例將樣本集劃分為建模集和預測集。采用UVE選擇特征波長。建立基于GP 的高粱中單寧含量預測模型,并與偏最小二乘法(Partial least squares, PLS)和支持向量機(Support vector machine, SVM)回歸模型進行對比分析。通過對比不同模型的R2、RMSE和RPD 評價模型的性能。
1.8 建模方法
GPR 作為一種非參數的回歸方法,用于建模和預測數據的連續函數關系,適于處理高維數、小樣本和非線性等復雜問題。在給定樣本光譜數據分布的前提下, GPR 用于推斷對應樣本高粱單寧值的分布。所得分布函數的數學期望即為GPR 模型的預測結果。假設單寧值y 是高斯分布函數f(x),服從均值為m(x)、協方差為k(x, x′)的高斯過程分布,如式(3)所示:
其中,均值函數m(x)和協方差核函數k(x, x′)定義如下:
GPR 的關鍵是定義一個核函數,用于衡量不同數據點之間的相似性。核函數的選擇可根據問題的特點進行調整,常用的核函數有指數核函數、平方指數核函數、有理二次核函數和matern 核函數等[20]。通過核函數可以計算出觀測數據點之間的協方差矩陣,進而得到預測結果的均值和方差,在預實驗的基礎上,本研究采用的核函數為matern32 核,由matern 核函數的參數v=3/2 得到[21], v 的大小影響函數的光滑性, matern52 核由v=5/2 得到, matern32 核函數公式見式(6):
其中, x 和x′是輸入變量;σf2 是信號方差參數,用于控制局部相關性的程度;σl 是特征長度尺度參數,用于調節輸入變量之間的間隔;|| x ? x′||表示輸入變量之間的歐氏距離。
1.9 模型評價指標
1.9.1 決定系數
R2 是一種用于衡量模型對觀測數據擬合程度的指標,通常用于比較不同模型的性能。R2 值越大,模型性能越好,建模集和預測集的R2 的比值應控制在0.9~1.1 之間,小于0.9 表明模型存在欠擬合,大于1.1表明模型存在過擬合[22]。當R2=1.0 時,表明模型完美地預測了數據。在回歸分析過程中, R2 可評估模型的預測能力,并解釋變量對因變量的影響程度。R2 的計算公式如下:
其中, yi,actual 和yi,predicted 分別為第i 個樣本的真實值和預測值, yactual 為真實值的平均值, n 為樣本數。
1.9.2 均方根誤差
RMSE 表示預測值和實際觀測值之間的差值,用于測量模型的預測精度。RMSE 越小,模型精度越高,表明預測值與實際觀測值之間的差異越小。計算公式見式(8):
1.9.3 相對分析誤差
RPD 用于評估模型的預測能力。RPD 值越大,模型預測能力越好,當RPDlt;2.0 時,模型效果不理想;當2.03.0 時,模型能精準預測所測成分含量,可用于預測分析[24]。計算公式見式(9):
2 結果與討論
2.1 高粱化學值的測定結果
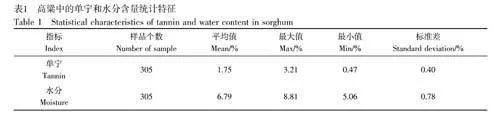
高粱中的單寧(干基)含量和水分含量的統計特征見表1。本研究中,單寧含量最低為0.47%,最高為3.21%,可以認為高粱單寧含量分布具有一定代表性。該結果與文獻[25]測得的高粱單寧含量分布(0.24%~4.76%)有一定的差異,這可能與高粱品種、土壤肥水和種植模式的差異有關[5]。
2.2 高粱的近紅外光譜圖
高粱完整籽粒的近紅外漫反射光譜如圖1 所示,在10075、8316、6821、5766、5186、4700、4321和4008 cm?1 處出現吸收峰。其中, 10075 cm?1 處為酚中O—H 的二級倍頻吸收峰;8316 cm?1 附近的吸收峰與甲基和亞甲基中的C—H 的二級倍頻有關;6821 cm?1 附近的吸收峰與醇中氫鍵鍵合的O—H 的一級倍頻相關;5766 cm?1 處的吸收峰為與芳環相連的甲基C—H 的反對稱和對稱伸縮振動一級倍頻的吸收峰;5186 cm?1 處為酚和醇中O—H 的合頻和C=O 的二級倍頻的組合頻吸收峰;4700 cm?1 處的吸收峰為芳烴C—C伸縮振動和C—H 伸縮振動的組合頻吸收峰;4321 cm?1 處為甲基、亞甲基和芳烴C—H的組合頻吸收峰;4050 cm?1 處為苯環C—H 的伸縮振動和彎曲振動的組合頻吸收峰。
2.3 預處理方法的選擇
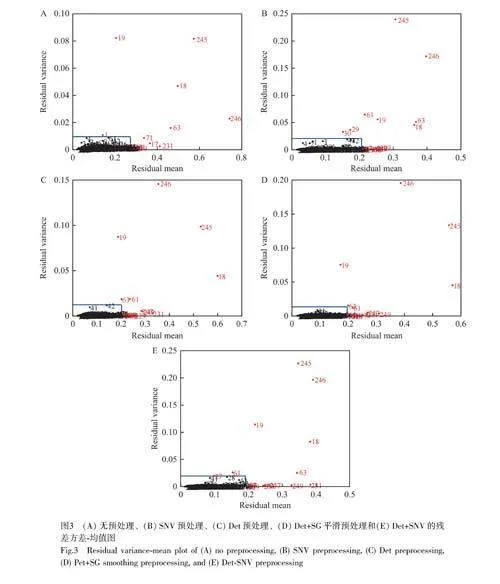
光譜中除了有用的化學信息外,還包含著大量的噪聲和無關信息,在前期預實驗基礎上,本研究采用多種光譜預處理方法,包括Det、SNV、去趨勢組合標準正態變換(Det+SNV)以及去趨勢組合SG 平滑(Det+SG)分別對光譜進行預處理。Det主要用于消除光譜的基線漂移,通過使用原始光譜減去多項式擬合出一條趨勢線,對光譜進行去趨勢處理;SG 平滑適用于消除不規則的隨機噪聲,通過選擇合適的窗口大小和多項式階數對光譜數據進行平滑處理,本研究選擇窗口大小為21,多項式階數為2;SNV 用于消除樣本顆粒大小、表面散射光以及光程變化等對近紅外光譜的影響,通過單個樣本光譜的標準偏差修正光譜的變化[26]。為了消除光譜的基線漂移和噪聲的影響,將Det 與SNV 和SG 結合,得到SNV、Det、Det+SNV 和Det+SG 4 個光譜預處理結果(圖2)。經預處理的光譜圖像相比原始光譜呈現出較高的光譜平滑度和集中性, Det+SG(圖2D)較Det(圖2B)的噪聲明顯減少, 7000~7500 cm?1 和5000~5500 cm?1 處的光譜噪聲波動消失,呈現出更高的平滑度。
2.4 異常值的剔除
為了避免在實驗過程中因操作誤差造成的光譜異常或單寧含量檢測結果異常對模型的不利影響,以預處理后的光譜為輸入,使用MCCV 結合GPR 模型對樣品進行異常值剔除,在建模1000 次后,得到殘差方差-均值圖(圖3)。本研究取殘差均值和方差最大的15%的樣本的殘差均值的平均值和殘差方差的平均值作為閾值,將樣本殘差均值或殘差方差大于閾值的樣本識別為異常樣本。
2.5 特征波長選擇
近紅外光譜數據維度較高,包含有大量冗余信息。建模前進行特征選擇,可以減少冗余信息,降低維度,減少計算復雜度,縮短模型訓練時間,從而更好地利用近紅外光譜數據進行分析和預測。
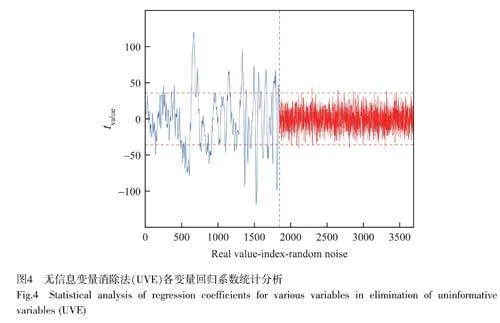
UVE 最初由Centner 等[27]提出,是一種基于回歸系數建立的波長變量選擇算法,將回歸系數的穩定性值作為波長變量重要性的衡量指標。首先對光譜數據中波長變量的穩定性值進行評價,然后根據每個波長的穩定性值(均值/方差)剔除對模型沒有貢獻的變量。相比于其它特征波長選擇算法, UVE 能夠更好地處理存在異常值和噪聲的數據,提高特征選擇的穩定性和可靠性。該方法不依賴于具體的統計分布假設,適應性強,并具有較好的魯棒性。
UVE 建模方法采用PLS 回歸, PLS 模型的主成分數設置為15,閾值為0.995,采用留一法交叉驗證。圖4 為各變量回歸系數統計分布,藍色實線為光譜變量矩陣的穩定性值,紅色實線為隨機噪聲,紅色水平虛線為通過閾值0.995 選出的臨界值,絕對值大于臨界值的波長為所選擇的波長。圖5 為UVE 所選波長(經Det-SG 和剔除異常樣本的光譜),共選取了662 個特征波長,占總波長的35.88%。每個波峰附近都有所選擇的波長,在4 個波峰(6821、5766、4700 和4321 cm?1)附近尤為聚集,其中, 6821 cm?1 附近的吸收峰與醇中氫鍵鍵合的O—H 的一級倍頻相關, 5766 cm?1 處為與芳環相連的甲基C—H 的反對稱和對稱伸縮振動一級倍頻的吸收峰;4700 cm?1 處的吸收峰為芳烴C—C 伸縮振動和C—H 伸縮振動的組合頻吸收峰;4321 cm?1 處為甲基、亞甲基和芳烴C—H 的組合頻吸收峰。
2.6 模型建立
數據預處理、剔除異常樣本和特征波長選擇后建立GPR 模型,核函數為matern32 核,重復建模1000 次取平均值,以保證評價指標的準確性,建模結果如表2 所示。
表2 中GPR 模型的RPD 值均大于3,因此,模型均可用于預測單寧含量。其中, Det-SG 和Det-SNV最優秀,并且兩個模型的RP 2 和RPD 值十分接近。Det-SG 的決定系數RP 2 略高于Det-SNV,但RPD 略低于Det-SNV,這表明Det-SG 相對于Det-SNV 更加穩定,模型預測性能的波動較小。在多次建模過程中, Det-SG 比Det-SNV 更加穩定,能夠提供更一致的預測精度,故建立在Det-SG 預處理和UVE 進行特征波長選擇結果的GPR 為最優模型,其建模集決定系數(RC 2)和RP 2 分別為0.9979 和0.9529,建模集和預測集R2 的比值為1.05,不存在過擬合和欠擬合, RPD 值為4.8453,大于3,說明模型可以精確預測單寧含量。
對比表2 可知,未經過光譜預處理的模型有輕微的過擬合現象,因此,光譜預處理能明顯提升模型性能[28],經過光譜預處理后,模型的RPD 大于4,模型的過擬合現象明顯改善。建立在兩種預處理方法上的模型性能與單一預處理方法基礎上的模型相比,性能僅略有提升[29]。4 種不同預處理方法對單寧含量預測模型影響不大。文獻[11]建立的基于高粱籽粒的單寧含量預測模型MSC-MCUVE-PLSR 的RP 2 為0.8841,而本研究建立的Det-SG-UVE-GPR 模型的RP 2 為0.9529,對于整粒高粱單寧的預測性能有明顯提升,可以更精準地預測整粒高粱中的單寧含量。
2.7 GPR 模型與其它模型的比較
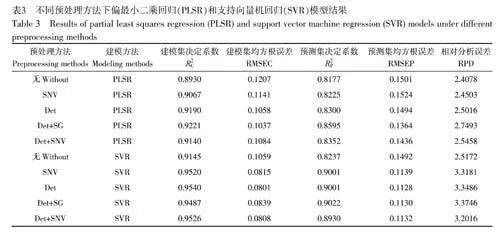
PLS 是化學計量學的經典方法,在近紅外光譜建模過程中廣泛應用[30-32];此外,近年來, SVM 在近紅外光譜建模方面取得了較好的效果[33-34]。為了說明GPR 模型的優勢,本研究選取在近紅外光譜和機器學習算法方面使用較多的PLS 和SVM 建立回歸模型,并與GPR 模型進行對比。其中, PLSR 模型通過計算RMSECV 的最小值選擇最優主成分數,并進行建模預測;SVR 模型使用徑向基核函數,通過網格尋優法尋找最優參數,并進行建模預測,重復建模200 次取平均值,建模結果見表3。
對比表2 和表3 可知, PLSR 模型的RPD 值在2.40~2.75 之間,均小于3,最優PLSR 模型的RP 2 和RPD 分別為0.8595 和2.7493,對于預測高粱單寧含量略顯牽強。SVR 模型的性能全面優于PLSR 模型,并且性能接近GPR 模型(表3)。預處理可以明顯提升模型的預測精度,經預處理后, SVM 模型RPD 值在3.31~3.41 之間,均大于3,因此,建立在預處理基礎上的SVM 模型可用于預測高粱單寧含量。在SVM模型性能參數方面,在4 種不同的預處理方法中, Det-SG 略顯優勢,其RP 2 和RPD 分別為0.9022 和3.3746,但其預測精度仍低于GPR 模型,建模過程耗時也遠長于GPR 模型。
綜合表2 和表3 可知,在相同的光譜預處理情況下, 3 種模型性能從高到低依次為GPRgt;SVRgt;PLSR,這與文獻[16-17]的研究結果類似。基于相同預處理方法(Det-SG)的GPR 模型的RPD 比PLSR 模型提升了76.24%,比SVR 模型提升了43.58%。這種預測準確度的不同可能是由于高粱近紅外光譜受到多種因素(如復雜的化學成分、光譜峰重疊、儀器和環境等)的影響,這些因素會導致光譜數據間存在復雜的非線性關系和復雜數據分布,而GPR 模型在處理非線性關系和復雜數據分布方面更具有優勢,采用核函數適應數據的非線性特征,不對數據進行特定假設。相對于PLSR 和SVR, GPR 模型可以提供對預測的不確定性估計,可更好地處理非相關的數據,提高預測性能。相比之下, PLSR 的建模能力受限于其線性假設,對于非線性關系的建模能力有限。SVR 雖然可用于解決小樣本、非線性和高維數據空間模式識別等問題,但對數據的分布和特征的敏感度較高,如果數據的分布不符合其假設或者特征不顯著,可能會影響其預測效果。所有PLSR 模型的RPD 均小于3,并且多種預處理方法相差不大,由此可見,預處理方法對于高粱單寧的PLSR 模型性能提升不明顯,而對GPR 和SVR 性能均有較大提升,這再次表明了PLSR 模型建模能力有限。
3 結論
采用近紅外光譜儀器結合化學計量學方法,建立了基于高粱完整籽粒的單寧的GPR 預測模型,對比PLSR 和SVR 兩種常用建模方法,本研究建立的GPR 高粱單寧預測模型準確度最高,建模結果有顯著優勢,其RPD 值較PLSR 和SVR 分別提升了76.24%和43.58%,模型性能大幅提升,可用于高粱單寧含量的快速檢測。相比于傳統的人工經驗判別法和實驗室化學方法,本方法檢測方便快捷且準確,能夠更好地為高粱中單寧的快速檢測提供技術支持。
