基于智能報表的政府數據利用模式探索
2024-08-17 00:00:00曹暉張亮
數字通信世界 2024年7期
摘要:隨著城市數字化的發展,城市運行所產生的政務數據進入快速增長模式。江寧區政府利用數據統計報表的方式,通過大數據分析對整個江寧區城市運行態勢進行全方位感知,從而為江寧區政府領導制定宏觀經濟政策和城市長期規劃提供重要依據。智能報表從政府業務人員的角度出發,將政府的業務需求進行抽象化處理,選擇有需要的數據和指標,避免無意義的數據共享,提升了數據共享的目的性和效率;通過低代碼技術,將各類政務數據進行靈活的排列和組合,能更好地展現數據之間的聯系,提升了數據利用的效率。
關鍵詞:城市數字化;智能報表;低代碼
doi:10.3969/J.ISSN.1672-7274.2024.07.075
中圖分類號:G 203 文獻標志碼:A 文章編碼:1672-7274(2024)07-0-04
Exploration of Government Data Utilization Model Based on Intelligent Reports
CAO Hui, ZHANG Liang
(Judicial and Legal Committee of Jiangning District Committee of the CPC, Nanjing 210000, China)
Abstract: With the development of urban digitization, the government data generated by urban operations has entered a rapid growth mode. The Jiangning District Government utilizes data statistics and reports to comprehensively perceive the overall urban operation situation of the entire Jiangning District through big data analysis, providing important basis for the leadership of the Jiangning District Government to formulate macroeconomic policies and long-term urban planning. Intelligent reporting starts from the perspective of government business personnel, abstracts government business needs, selects necessary data and indicators, avoids meaningless data sharing, and improves the purpose and efficiency of data sharing; By using low code technology, various types of government data can be flexibly arranged and combined, which can better display the connections between data and improve the efficiency of data utilization.
Keywords: urban digitization; intelligent reporting; low code
0 引言
江寧區政府統計報表是建立在江寧區十個街道、經濟開發區、區級職能部門日常工作統計數據基礎之上,經過數據的采集、比對、分析等一系列數據處理方式形成江寧區政務報表資產基礎目錄,通過對基礎報表的數值進行分析得出的結論是江寧區政府領導制定宏觀經濟政策和城市長期規劃的重要依據。傳統靜態報表設計與應用系統耦合度高、靈活性差,不能適應報表的動態需求變化。為提升江寧區政務數據的感知能力、處理能力、分析能力,實現自主構建多形態江寧區政府統計報表,提升對區級各業務部門數據統計和數據分析的支撐能力,同時在數據共享層面,向江寧區上層領導和決策部門以及社會相關團體、第三方機構提供高質量、高可用的報表數據,對推動江寧區政務數據共享體系和數據挖掘體系的構建具有重要意義。
1 政府大數據
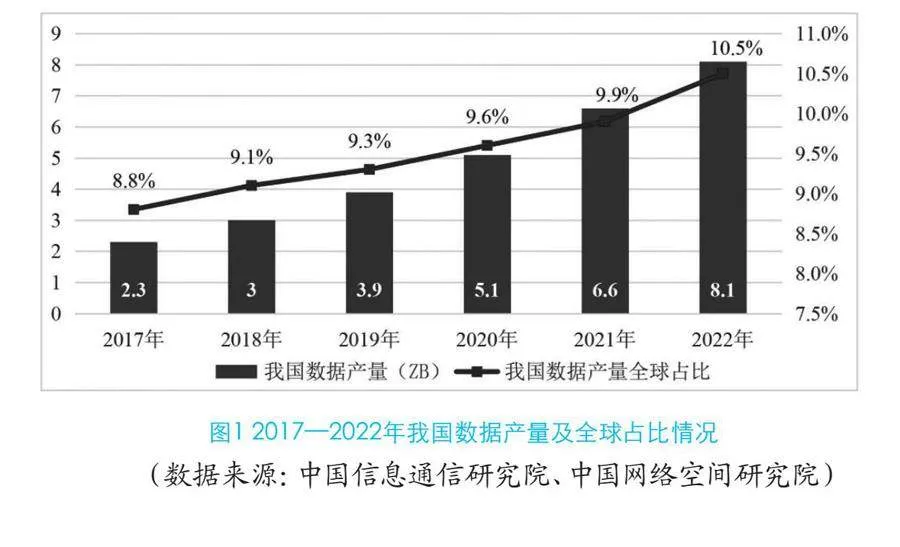
2022年我國數據總產量達8.1ZB左右,同比增長22.7%,全球占比高達10.5%,位居世界第二。截至2022年底,我國數據存儲量達724.5 EB左右,同比增長21.1%,全球占比達14.4%[1]。其中,政府數據占到了約80%。如圖1所示。
圖1 2017—2022年我國數據產量及全球占比情況
(數據來源:中國信息通信研究院、中國網絡空間研究院)
2 政府統計報表樣式
在政府日常使用的統計報表中,各類統計報表通常包括表單標題/名稱、表前注釋區、表單主體以及表尾注釋區等。
2.1 表單標題/名稱
作為表格統計的名稱,標題/名稱常包含對表格統計內容的主題性描述。
2.2 表前注釋區
用于對表格標題的補充說明或標題內容的全局注釋,包括統計調查對象或統計指標的分項標注,以及統計口徑、量綱單位和統計時間等信息的全局說明。
2.3 表單主體
表單主體是表格的“正文”,統計表單的數據項目集合,每個數據項還包括以下信息:數據項目標題,如數據類目、統計口徑、統計區域等;數據項目類型,如文本、數字等;數據項目的屬性,如數值區間、密級等。
2.4 表格注釋區
該模塊的作用是對表格的內容或者單個表字段進行說明,以及對表體單元格內容的局部注釋。
3 政府統計報表制作面臨的困難
政府統計報表可以幫助政府更好地了解、使用、挖掘數據價值,并把數據信息以安全可靠的方式呈現給政府用戶,作為政府運行數據常用的輸出方式,統計報表在政府信息平臺中起著重要的作用。
目前政府對統計報表需求量巨大,由于政府部門業務邏輯復雜、需求變化多、數據來源多等原因,造成政府統計報表結構復雜,表現在以下幾個方面:
3.1 業務邏輯復雜
政府內部業務邏輯復雜,部門職能交叉重合多,我國雖然在制度上構建了同質化的條塊組織架構,但其形成的條塊關系卻具有復雜性和多變性,條塊關系在不同層級政府中、在不同的治理背景下并不相同。一方面,在中國的大國治理中,職責同構的“條條”面臨資源稟賦與區域差異巨大的“塊塊”,在不同層級政府中形成的條塊關系可能并不相同。另一方面,從時間維度上看,條塊關系在不同的時期會呈現不同的樣態,這與當時的治理環境有很大的關系[2]。業務邏輯的復雜性體現在報表中就是報表邊框線規則復雜、表頭指標多、格子層套多,給報表制作和閱讀都造成很大的負擔,且維護難度大、靈活性差。
與普通關系型表單每行(列)只表達單層語義不同,政府統計報表需構建政務服務獨特的業務知識體系,在業務表集中,每張表之間、表與表之間的行列表頭存在大量的總分關系、同位關系、并列關系、上下級關系、組合關系等,具有復雜的、多層級嵌套的特點。
同時,政務報表的復雜性還體現在使用人員常常無法從中得到明確的關聯信息;使得數據流轉和共享存在巨大的阻礙。
3.2 報表數據源多
隨著政府信息化的發展,政府內部不同層級、不同部門都fAnmRCbFWQv7RUz+Jv/TWw==建設了很多信息化系統。政府統計報表的數據通常會來自多個不同的系統數據庫,數據的格式、數據質量都不相同。例如,對于常住人口的統計,有統計局、公安局、衛健部門、政法委等多個口徑,由于幾方數據基本來源于各自業務系統,系統本身設計存在巨大差異,數據的統計方式、統計目的和統計標準也各不相同,造成后續無法以統一的標準進行數據比對。
而且在政務大數據共享的推進過程中,存在著出于權力本位和自身惰性不愿共享、基于信息安全和風險考慮不敢共享、缺乏體制機制和技術支撐不能共享等問題,給報表制作造成很大的障礙。
3.3 需求變化較多
政府統計報表關聯了多個數據源,含有大量的數據。對數據統計通常根據政府部門的業務要求、時間要求、管理要求,需從不同口徑、不同視角對數據予以分析,需對數據進行邏輯計算,這種計算基本上都是跨行、跨組的,且對靈活性要求很高。傳統的數據報表定制研發是由軟件廠商或運維廠商設計、研發、部署和實施產生的,不僅靈活性差,且由于軟件廠商對政府各條專業線的細分知識和政策缺乏整體了解,在處理業務系統產生的大量數據時,很難有效地通過報表的形式實時、高效構建政府用戶所需數據集,對后續政府用戶從數據集中提取有效信息產生影響。
4 報表引擎在數字政府中的應用
智能報表是通過對數字政府具體業務場景的分析和政府使用者日常工作行為習慣的掌握,從分離業務過程與重新排列組合的角度出發,為政府實際使用者提供單純的業務層服務組合手段,讓用戶能夠從業務層面來直接描述其需求,使得系統能快速獲取使用者的意圖,從而提升數據共享利用的效率和數據獲取的準確度。
4.1 多源采集,促進多部門數據共享
為了提高系統的靈活性和擴展性,無縫透明對接底層業務數據,運用組件的先性進屏蔽內部所有技術細節,提供從數據字典、數據開發、機器學習、數據稽核到運維調度的所有功能,從而大幅降低使用門檻。為數十種不同的異構數據源提供豐富的連接處理能力,搭建高效的數據連接匯聚通道,促進融合管理,支撐數據挖掘與上層應用,形成高性能、安全可靠的數據涌流通道,按需搭建、快速獲取數據。
通過采用配置文件的方式,使用戶可以根據自己的需求定義數據源,然后選擇其中的屬性完成數據定義。通過關聯包含相應邏輯連接的數據庫字段,從數據庫中將數據取出來,形成可直接應用于模板設計的數據集,達到將多個源表的數據在同一單元內關聯展現的目的,實現報表數據集和數據源的分離,提升了政務數據共享的效率。
4.2 分離業務與IT資源,讓用戶專注業務需求
從政府用戶的角度出發,將用戶的業務需求進行抽象化處理,通過整合和提取現有的數據資源,得到面向政府用戶的業務層抽象服務資源;為政府用戶提供單純的業務層報表級和字段級組合手段,一鍵形成政府用戶想要的表單。
利用可視化技術和低代碼技術,以用戶的思考行為為基礎,在報表展示形式、展示內容、表頭組合和數據樣式等方面,可以根據用戶的需求進行界面、指標和報表的定制,滿足不同管理層級和崗位的需求,給予用戶最佳的使用路徑,提升智能化報表應用。
(1)表單設計。支持通過拖拽式編輯,供選項卡、主子表、富文本、部門選擇、日期選擇、視圖選擇、二維碼掃描、OCR識別多種功能控件供調用,同時平臺支持控件自定義拓展,不同部門用戶在同一平臺可結合自身業務需求自由添加及復用。
(2)數據模型(Data-Business)。數據建模是一種定義和分析數據的手段,在具體實現方面了采用基于“標簽+屬性”的方式進行數據管理模型的創建。標簽是一種數據特征,是根據數據的業務性質定義出來的,是構建數據畫像的核心要素,是將用戶數據提煉后生成的具有差異性特征的形容詞,按照生成方式,可分為統計類標簽、規則類標簽、機器學習類標簽。對同一個數據,可以打上多個標簽,同一數據上的標簽會隨著時間的推移而持續增加,同時也會讓數據畫像信息更加準確且完整。
在標簽特征建立后,為每個不同標簽自動/手動添加屬性,能夠更精準地描述事實和度量特征,屬性相較于標簽而言具有穩性定,其值可以在階段時間內保持不變或變化較小,同時屬性也可以根據具體的業務和查詢要求來決定是否要進行聚合(求和/運算)與分解(明細),也可以進行大小的比較和排序(如年齡、黨齡、納稅記錄等)。通過“標簽+屬性”的數據模型,為政務數據構建精準畫像,使業務人員能夠更精準、快速找到所需的結果,而不用花精力關心底層的數據庫邏輯、表關聯邏輯。
(3)流程配置。基于BPMN2.0規范的可視化流程設計模式,無論是標準的模板流程、新興的自由流程還是子流程嵌套,均能在Web頁面通過拖拉拽方式以圖形化+參數化的方式快速完成。
(3)權限管理。提供審批節點、審批路徑、審批人員、審批權限、審批時限、審批動作和審批通知等控制內核,以適應中國式流程管理模式和操作習慣。
(4)數據集成。提供多種方式幫助用戶實現與第三方系統的集成對接,支持將數據結果服務化的同時,再基于權限控制進行服務的共享,任一部門、任一業務人員可在許可范圍內進行數據服務的調用,在表單定制、模型定制的基礎上增加靈活性和擴展性,同時又不會因為數據的接入影響源數據及業務,所有數據服務可通過管理中心實時監管,安全便捷。
4.3 數據深度挖掘,提升決策水平
統計數據報表信息的深度挖掘是面向結構一致的統計數據集,在在數據讀取與集成的基礎上,采用報表引擎的方式,根據定義的報表主題及配置的算法,發現其中的相關關系以及探尋表與表之間的因果關系,從而進行多維度的統計評價與數據預測,以反映區域經濟發展情況、研究特定問題及支撐制定決策等。
報表引擎提供了豐富的數據分析和統計功能,用戶可以通過設置各種過濾條件和統計函數,對數據進行聚合和分析。這樣可以幫助用戶更好地理解數據背后的含義和趨勢,并提供預測和決策支持。用戶也可以根據實際需求,隨時調整報表主題及算法的定義語言,通過多維變量自綁定技術將多維變量引用方、多維變量及多維變量提供方在解析時進行自動多級綁定,當提供方數據發生變化時,根據綁定關系通知表達式引擎向引用方廣播數據變動通知消息,附帶表達式計算結果,從而可實現復雜的數據聯動邏輯[3]。報表引擎運行結束后,自動形成政府用戶所需的完整報表,當定義內容變化時,所需報表的格式和數據內容也會進行及時調整,提升了業務的靈活性、降低了政府用戶的使用成本。
5 結束語
智能報表系統在建設之始,錨定“整合數據資源,挖掘數據價值”,立足數據有效歸集、工具實效應用、輔助高效決策,打造貼近業務的報表工具平臺。通過技術與業務的關聯預設,使業務人員擺脫技術限制,基于業務即可實現多維報表樣式定制、指標定制、條件定制,并支持按權限的結果和有條件查詢/使用,優化了政府運行數據的利用方式。
參考文獻
[1] 劉云朋,盧貝.基于數字政府建設視角下的政務數據共享現實困境與對策研究[J].焦作大學學報,2024,38(2):61-64.
[2] 成婧.政府過程中的復雜性條塊關系及其產生邏輯——基于干部調配數據的觀察[J].公共行政評論,2023,16(1):181-196,200.
[3]張啟偉,劉海濤,尹洪苓,等.面向業務用戶的智能報表實現研究[J].電腦知識與技術,2022,18(28):109-112.
