嵌入注意力機制的深度可分離卷積SAR 目標識別
2024-07-20 00:00:00盧小華李愛軍
無線電工程 2024年5期
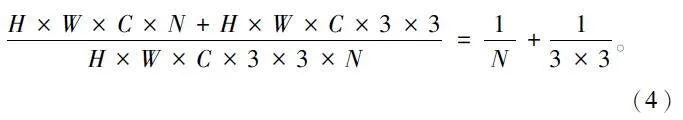


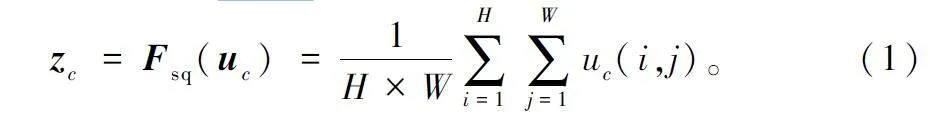
摘 要:深度可分離卷積(Depthwise Separable Convolution,DSC) 的應用使得深度學習的網絡模型輕量化。在此基礎上,提出了嵌入注意力機制的DSC 合成孔徑雷達(Synthetic Aperture Radar,SAR) 目標識別方法。通過將DSC 與注意力機制結合,提高網絡對目標重要特征的學習能力;將多個DSC 進行疊加和并聯,設計多尺度網絡模塊,增強不同深度網絡的特征提取能力;通過殘差連接緩解深層網絡的梯度彌散和梯度爆炸問題。使用公開數據集實驗表明,所提方法在網絡模型參數量較小的情況下,獲得99. 0% 的平均識別率,具有較強的識別優勢。
關鍵詞:合成孔徑雷達;目標識別;深度可分離卷積;注意力機制
中圖分類號:TN957 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3106(2024)05-1083-08
0 引言
合成孔徑雷達(Synthetic Aperture Radar,SAR)能夠發射微波信號,通過相干機制完成既定成像任務,其不受雨、雪、霧、霾等復雜天氣影響,具有全天時、全天候的成像優勢,在軍事、農業、環境、氣候等領域得到廣泛應用,是一種重要的探測手段[1-3];其中SAR 圖像自動目標識別(Automatic Target Recog-nition,ATR)作為關鍵技術之一,自20 世紀以來持續得到重點關注和研究[4]。
ATR 主要目的是確定目標類別,最初主要采用“特征提取+分類器設計”的模型識別框架。特征提取包括如散射點分布特征、投影變換特征和紋理特征等[5-6];分類器設計包括支持向量機、稀疏表示分類等[7-8]。隨著深度學習的迅猛發展,鑒于其強大的自動特征提取與分類性能,顯著提升了ATR 技術的性能[9-10],其中卷積神經網絡(ConvolutionalNeural Network,CNN)更是在ATR 領域成為研究熱點。文獻[11]使用卷積層代替全連接層,并擴充數據集獲得了99% 的識別率。文獻[12]利用數據增強技術擴增數據集,通過零相位成分分析預先提出目標特征,將該特征集再送入卷積網絡中,整體識別率達到98. 47% 。從上述文獻可以看出,由于深度學習模型是依靠數據驅動,其性能好壞較為依賴數據規模,因此往往會在原有數據集基礎上進行擴增,從而保證網絡能夠充分得到學習訓練。有文獻在不擴充數據樣本前提下,通過改進網絡模型結構或遷移學習等方法,依然能夠取得較高的識別率[13-14]。文獻[13]使用改進的自編碼器網絡初始化網絡參數,再將參數移植到全CNN 中進行訓練,在不擴充訓練樣本情況下,平均準確率為98. 14% 。文獻[14]針對SAR 圖像特點設計網絡結構,采用L2范數作為代價函數以及使用Dropout 提高泛化性,在原有數據集樣本中實現了98. 10% 的識別率。
隨著CNN 向更深、更寬發展,同時帶來的梯度彌散和梯度爆炸問題阻礙了模型訓練效果,2016 年He 等[15]提出的深度殘差網絡(Deep Residual Net-works,ResNets)有效地緩解了該問題,SAR 圖像識別領域借鑒該模型也提出了許多優秀的識別方法[16-18]。然而隨著卷積層數量的進一步增加,參數量、計算量也隨之增加,使得模型學習訓練效率大大降低,對運行硬件的要求也大幅提高。因此輕量化網絡結構被設計出來,其中深度可分離卷積(DepthwiseSeparable Convolution,DSC)[19]是較為流行的一種輕量化網絡,其本質是將冗余信息進行更少的稀疏化表達[20],很大程度上提升了模型的推理速度。
綜上,為了實現網絡輕量化以及增加網絡深度的同時保持良好的特征提取能力,提出了嵌入注意力機制的DSC 識別方法。首先將不同數量的DSC進行疊加產生多個支路,形成多尺度效應,用來增強淺層網絡的特征提取能力;然后在每條支路上加入注意力機制模塊,提高網絡對目標重要特征的學習能力;最后通過殘差連接各個支路和輸入組成新的網絡模塊。利用該網絡模塊設計了20 層網絡模型,實驗使用Moving and Stationary Target Acquisitionand Recognition(MSTAR)數據集,在不增強數據情況下,對10 類目標型號識別率達到99. 0% ,相比于近年識別方法有著較強的優勢。
1 注意力機制
注意力機制最早應用于圖像領域,通常解釋為模仿人類在觀察整體環境時,專注于自己感興趣的事物而忽視其他無關事物的特征,因此在網絡中引入注意力機制,理論上能夠增強識別目標特征的權重,即對圖像中關鍵信息提高關注度,濾除無關或不重要的信息,從而提高網絡的學習效率。
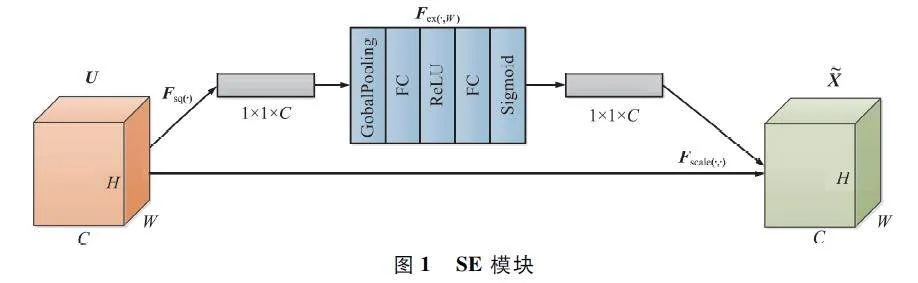
在眾多注意力機制模型中,Suqeeze-and-Excitation Module(SE)注意力機制[21]自2017 年被提出后經常運用在圖像分類、檢測、分割等領域。SE 模塊由壓縮部分(Squeeze )和激勵部分(Excitation)組成,如圖1 所示,其目的是通過一個權重矩陣,從通道域角度賦予圖像不同位置不同的權重,得到更重要的特征信息。壓縮部分將特征圖通過全局平均池化的方式,生成一個1 ×1 ×C 的向量,如式(1)所示,使每個通道都用一個數值表示,實現對特征圖U 全局低維壓縮,每個通道的值相當于獲得之前一個H×W 全局感受野。
激勵部分則通過2 層全連接層完成,如式(2)所示。通過全連接層的W1 、W2 對向量z 進行處理,得到通道權重值s,其中不同數值表示對應通道的權重信息,賦予通道不同權重。
s = Fex(z,W) = σ(W2 δ(W1 z)), (2)
式中:σ 表示Sigmod 激活函數,δ 表示ReLU 激活函數。
2 層全連接層之間存在一個超參數r,向量z 經過第一層全連接層后維度由1×1×C 變為1×1×C / r,經過第二次全連接層后維度變回1×1×C,一般默認r = 16。
將權重向量s 對特征圖U 進行權重賦值,即將向量s 與特征圖U 對應通道相乘,得到壓縮激勵后的特征圖X ~ :
X~ = Fscale(uc ,sc ) = sc uc 。(3)
2 DSC
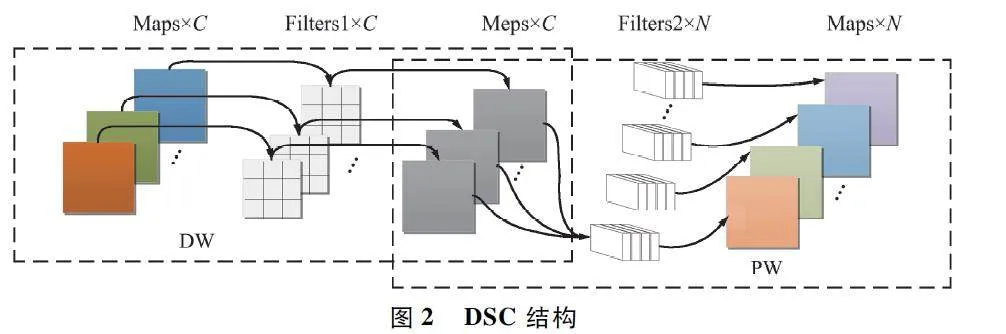
DSC 的主要思路是將普通卷積操作分解為2 個過程:深度卷積(Depthwise Convolution,DW)和點卷積(Pointwise Convolution,PW),結構如圖2 所示。其基本原理是首先使用DW 對每個輸入通道(輸入特征圖的深度)執行單個濾波器卷積;然后使用PW(1×1 卷積)用來創建逐DW 層的線性組合。假設輸入的特征圖通道為N,DW 對N 個通道的特征圖分別使用一個卷積核,且卷積核數量和特征圖通道數一致,所以經過DW 得到N 個通道的特征圖;PW實際是1×1 卷積,使用M 個1×1 卷積核對DW 處理后的特征圖進行卷積,最終得到M 個通道的特征圖。DSC 對2 層卷積層都使用了批量正則化(BatchNormalization ,BN)和線性整流函數(ReLU)作為非線性激活函數。
應用DSC 最主要的目的在于減少參數量,從整體上輕量化網絡模型。以使用3×3 卷積核為例,對于輸入長、寬和通道數為H ×W ×N 的特征圖,經過3×3 卷積核的DW 以及N 個卷積核的PW,參數量為H×W×C×3×3+H×W×C×N,而經過3×3 卷積核的標準卷積運算,參數量為H×W×C×3 ×3 ×N,二者相比(如式(4)所示),參數量減少了近1 / 9,從而達到提高訓練速度的目的。
3 嵌入注意力機制的DSC 識別框架
3. 1 嵌入注意力機制的深度可分離模塊
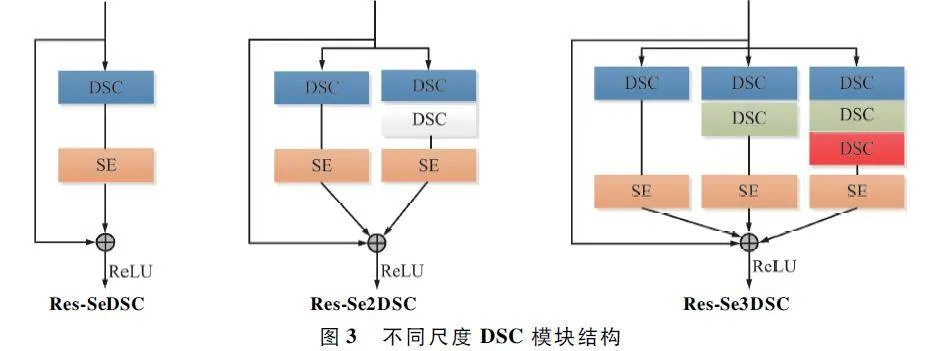
本文提出的嵌入注意力機制的DSC 網絡,主要將DSC 模塊與SE 模塊結合在一起,減少參數量的同時提高重要特征權重,剔除冗余特征,增強特征提取的有效性;加入殘差連接,相當于對該模塊加入一個恒等映射,當某一層網絡對特征提取效果較差時,可通過該連接直接跳過進入下一次網絡訓練,因此添加的新網絡層至少不會使效果比原來差,可以較為穩定地通過加深層數來提高模型的效果,同時避免出現梯度彌散的問題。為了增強模型對淺層網絡的特征提取能力,實現多尺度特征提取的同時避免尺寸大的卷積核增加參數量,利用2 層DSC 的疊加代替5×5 的卷積核,利用3 層DSC 的疊加代替7×7 的卷積核,因此將只有1 個DSC 的模塊結構稱為Res-SeDSC,有2 個不同尺度DSC 的模塊結構稱為Res-Se2DSC,有3 個不同尺寸DSC 的模塊結構稱為Res-Se3DSC,如圖3 所示。
3. 2 嵌入注意力機制的DSC 識別框架
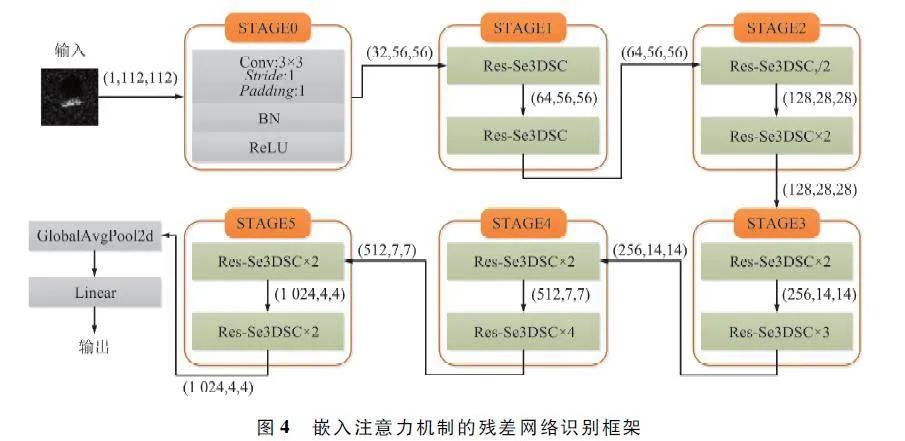
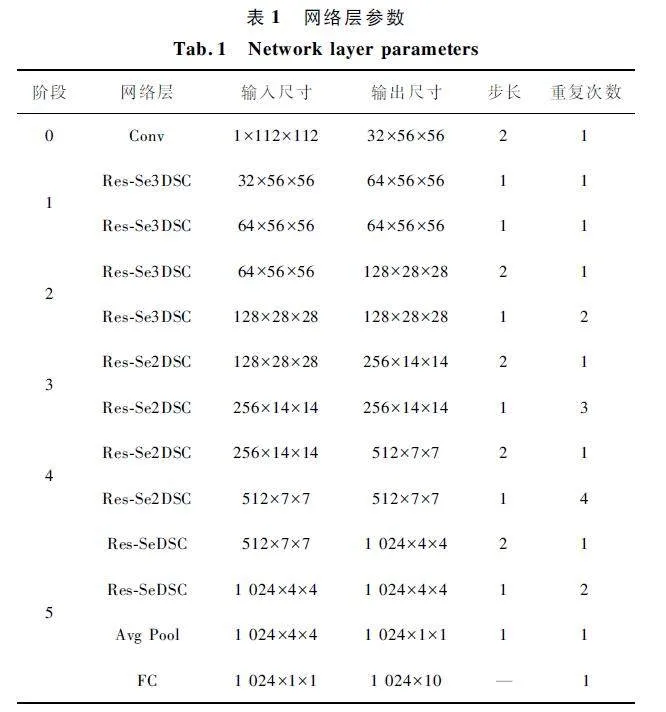
本文設計了20 層網絡架構,如圖4 所示。使用3×3 卷積核進行標準卷積運算,經過BN、ReLU 后,共使用17 個不同尺度的Res-SeDSC 模塊,經過一層全局平均池化層和一層全連接層,輸出識別類別,因此組成的識別模型稱為Res-SeXDSCnet。具體網絡層參數如表1 所示。
在特征圖尺寸減小一半時,卷積的步長選擇2,相當于一次下采樣;在特征圖尺寸不變時,卷積的步長選擇1。隨著特征圖尺寸減小,Res-SeXDSC 模型使用的尺度也隨之減少,主要是因為在淺層網絡中特征圖像素還較高,大尺度可充分提取不同深度的特征信息,而在低像素下感受野減小,大尺度提取到的信息效果差,從而降低網絡學習性能。同時,網絡采用負對數似然(Negative Log-Likelihood,NLL)損失函數以及Adaptive Moment Estimation(Adam)梯度下降方法共同優化調整網絡訓練,其中Adam 的主要優點在于在偏置校正后,每次迭代的學習率能夠保持在確定的范圍,使得參數變化比較平穩。
4 實驗結果及分析
4. 1 實驗數據與設置
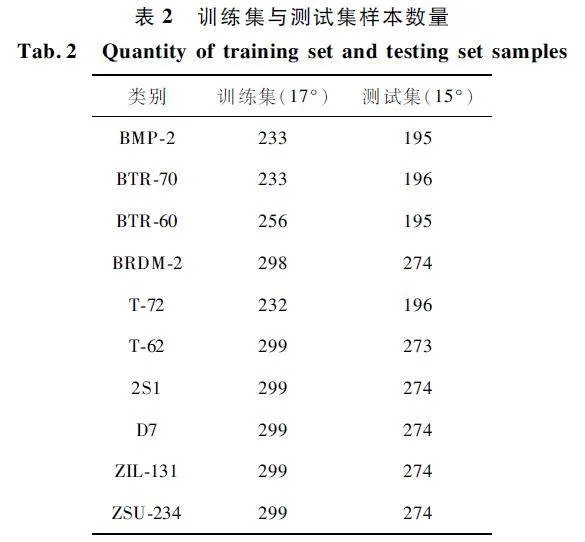
MSTAR 數據集是當前對SAR 圖像識別算法測試和評價最為有效的公開數據集之一,其包含10 類軍事車輛目標:BMP-2、BTR-70、T-72、T-62、BRDM-2、BTR-60、ZSU-234、D7、ZIL-131、2S1,表2 展示了來自17°和15°俯仰角每種類型樣本數量,其中將17°圖像數據作為訓練集,共2 747 個樣本,15°角度圖像數據作為測試集,共2 425 個樣本。在訓練過程中,網絡批處理塊大小(Batchsize)選取56,初始學習率為0. 001,迭代100 次,共進行10 次實驗,取平均識別率。
4. 2 算法特征提取效果
為展示嵌入注意力機制后對網絡特征提取的有效性,進行網絡特征可視化操作,為了增加對比,將注意力機制模塊取出,剩下DSC 的網絡結構,稱為Res-XDSCnet,使用同一數據集訓練至最佳。將圖4中的SAR 圖像分別輸入到2 個網絡中,為對比明顯,選擇Res-SeXDSCnet 與Res-XDSCnet 網絡中STAGE0 ~ STAGE2 三個階段的像素較高的特征圖進行對比,均取出前12 個通道的特征圖,如圖5 所示。可以看出,在STAGE0 中,由于都是同樣的卷積運算,得到的各通道特征圖基本上無差別;在STAGE1 和STAGE2 中,Res-SeXDSCnet 網絡的各個特征圖都有待識別目標的表達,說明網絡對于每個通道都進行了有效的學習,而Res-XDSCnet 網絡的各個特征圖差異較為明顯,有些特征圖上幾乎沒有待識別目標的特征表達(例如圖5(d)從左至右、從上至下第1、3、4、5、8、12 個特征圖)。由此可見,嵌入注意力機制模塊對于數據的特征提取更有效。
4. 3 算法性能對比與分析
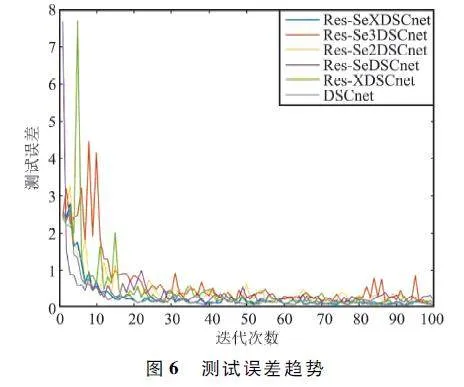
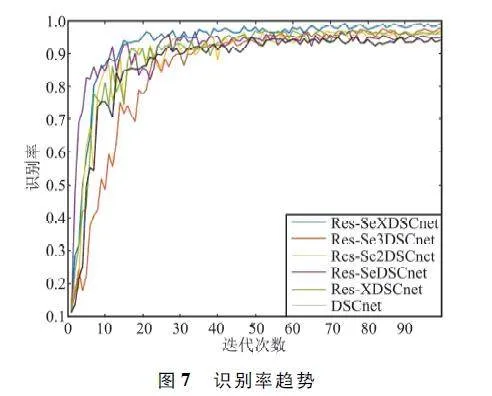
為對比嵌入注意力機制對學習效率的增強作用,使用Res-SeXDSCnet、Res-Se3DSCnet、Res-Se2DSCnet、Res-SeDSCnet、Res-XDSCnet 以及DSCnet進行試驗比對, 其中Res-Se3DSCnet、Res-Se2DSCnet、Res-SeDSCnet 分別代表僅使用Res-Se3DSC、Res-Se2DSC 和Res-SeDSC 模塊組成的網絡,DSCnet 代表僅使用DSC 模塊組成的網絡。測試誤差、識別率隨著迭代次數的變化趨勢如圖6 和圖7 所示。可以看出,本文方法收斂速度較快,僅經過20 次迭代后即獲得較高的識別率。
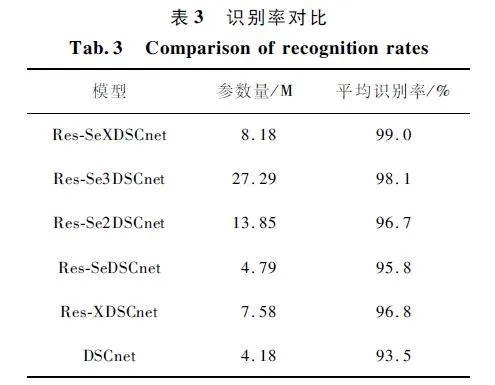
表3 展示了上述6 類模型的參數量和平均識別率。可以看出,Res-SeXDSCnet 由于注意力進機制以及多尺度的加持,識別率最高;相比于Res-SeDS-Cnet,多尺度應用能夠很好地提取目標特征,從而強化不同目標之間的差異;相比于僅使用Res-Se3DSC模塊的網絡,識別率平均高出0. 8% ,說明在低像素情況下再使用多種尺度進行特征提取效果將變差;相比于Res-XDSCnet,在SAR 圖像噪點較多的情況下,注意力機制能夠使網絡有效關注到目標特征,從而大大提高識別率,而且在加入注意力機制模塊后參數量增加不多,說明該網絡具有較強的優勢。
為對比不同算法之間的差異以及分析其原因,表4 展示了本文方法與文獻[12](ZCA+CNN)、文獻[13](FCNN+ICAE)、文獻[22](CNN+SVM)、文獻[23](CNN +SRC)、ResNet50 方法的對比。可以看出,ZCA+CNN 在提取了圖像一定特征的前提下再進行網絡學習,可能導致圖像部分信息缺失或使得網絡對特定特征學習并不良好,從而識別率有所下降,同時網絡層數不深、特征學習還不夠,FCNN+ICAE 也是類似問題;CNN + SVM 中卷積網絡僅有3 層,對目標訓練不充分導致輸出的目標特征沒有較強的差異性,輸入到SVM 中識別率也不佳;LeNet-5+CRC 則是將網絡特征輸入到機器學習方法中,利用了機器學習方法對樣本數量不敏感的特點,但由于LeNet5 淺層網絡訓練不充分的原因,其訓練得到的特征在可分性上也有所不足。另外本文與ResNet50 網絡在識別率上基本一樣,但由于參數量遠小于ResNet50 網絡,因此具有較強性能優勢。
為進一步對比上述方法的泛化能力,換成俯仰角為30°、45°的測試集,識別率如表5 所示。可以看出,隨著俯仰角的增大,識別率均降低,但本文方法依然保持較高的識別性能,說明該深度網絡具有較強的泛化能力。
5 結束語
提出了嵌入注意力機制的DSC 網絡的SAR 目標識別方法。該模型主要在DSC 網絡基礎上構建輕量化、有效的識別網絡,通過設計多尺度模塊,用小卷積核代替大卷積核,提取到不同深度的特征信息并縮減了網絡參數;利用注意力機制提高了對目標特征的權重。采用淺層網絡用大尺度、深層網絡用小尺度的方法設計網絡模型。在不擴充樣板數量的情況下,依然保持較高的識別率以及較強的泛化能力,可為其他SAR 目標識別和檢測提供輕量化網絡基礎。
參考文獻
[1] ZHOU Y S,WANG W,CHEN Z,et al. Highresolutionand Wideswath SAR Imaging Mode Using Frequency Diverse Planar Array [J]. IEEE Geoscience and RemoteSensing Letters,2020,18(2):1-5.
[2] WANG J,ZHANG X Z,LIU M M,et al. SAR Target Classification Using Multiaspect Multifeature CollaborativeRepresentation [J ]. Remote Sensing Letters,2020,11(8):720-729.
[3] 張陽,劉小芳,周鵬成. 改進Faster RCNN 的SAR 圖像船舶檢測技術[J ]. 無線電工程,2022,52 (12 ):2280-2287.
[4] 郭煒煒,張增輝,郁文賢,等. SAR 圖像目標識別的可解釋性問題探討[J]. 雷達學報,2020,9(3):462-476.
[5] PPAPSON S,NARAYANAN R M. Classification via theShadow Region in SAR Imagery [J]. IEEE Transactionson Aerospace and Electronic Systems,2012,48 (2 ):969-980.
[6] 辛海燕,童有為. 結合多源特征與高斯過程模型的SAR 圖像目標識別[J]. 電訊技術,2021,61 (4 ):454-460.
[7] ZHAO Q,PREINCIP J C. Support Vector Machines forSAR Automatic Target Recognition[J]. IEEE Transactionson Aerospace and Electronic Systems,2001,37 (2 ):643-654.
[8] SUN Y G,DU L,WANG Y,et al. SAR Automatic TargetRecognition Based on Dictionary Learning and JointDynamic Sparse Representation [J ]. IEEE Geoscienceand Remote Sensing Letters,2016,13(12):1777-1781.
[9] ZHAO J P,GUO W W,ZHANG Z H,et al. A CoupledConvolutonal Neural Network for Small and Densely Clustered Ship Detection in SAR Images[J]. Science ChinaInformation Sciences,2019,62 (4 ):042301:1 -042301:16.
[10] 賀豐收,何友,劉準釓,等. 卷積神經網絡在雷達自動目標識別中的研究進展[J]. 電子與信息學報,2020,42(1):119-131.
[11] CHEN S,WANG H P,XU F,et al. Target ClassificationUsing the Deep Convolutional Networks for SAR Images[J]. IEEE Transactions on Geoscience and Remote Sensing,2016,54(8):4806-4817.
[12] 許強,李偉,占榮輝,等. 一種改進的卷積神經網絡SAR 目標識別算法[J]. 西安電子科技大學學報,2018,45(5):177-183.
[13] 喻玲娟,王亞東,謝曉春,等. 基于FCNN 和ICAE 的SAR 圖像目標識別方法[J]. 雷達學報,2018,7 (5):622-631.
[14] 林志龍,王長龍,胡永江,等. SAR 圖像目標識別的卷積神經網模型[J]. 中國圖象圖形學報,2018,23(11):1733-1741.
[15] HE K M,ZHANG X Y,REN S Q,et al. Deep ResidualLearning for Image Recognition [C]∥ IEEE Conferenceon Computer Vision and Pattern Recognition. Las Vegas:IEEE,2016:770-778.
[16] WANG J H,JIANG Y. A SAR Target Recognition Methodvia Combination of Multilevel Deep Features[J]. Computational Intelligence and Neuroscience,2021,2021:2392642.
[17] SHANG S S,LI G P,WANG G Z. Combining MultimodeRepresentations and ResNet for SAR Target Recognition[J]. Remote Sensing Letters,2021,12(6):614-624.
[18] 史寶岱,張秦,李瑤,等. 基于改進殘差注意力網絡的SAR 圖像目標識別[J]. 激光與光電子學進展,2021,58(8):114-122.
[19] HOWARD A G,ZHU M,CHEN B,et al. Mobilenets:Efficient Convolutional Neural Networks for Mobile Visionapplications[EB / OL]. (2017-04-17)[2023-05-11].https:∥arxiv. org / abs / 1704. 04861.
[20] 路文超,龐彥偉,何宇清,等. 基于可分離殘差模塊的精確實時語義分割[J]. 激光與光電子學進展,2019,56(5):97-107.
[21] HU J,SHEN L,SUN G. Squeezeandexcitation Networks[C]∥2018 IEEE / CVF Conference on Computer Visionand Pattern Recognition. Salt Lake City:IEEE,2018:7132-7141.
[22] 田壯壯,占榮輝,胡杰民,等. 基于卷積神經網絡的SAR 圖像目標識別研究[J]. 雷達學報,2016,5 (3):320-325.
[23] 馮新揚,邵超. 跨卷積網絡特征融合的SAR 圖像目標識別[J]. 系統仿真學報,2021,33(3):554-561.
作者簡介
盧小華 女,(1981—),碩士,講師。主要研究方向:數據挖掘。
李愛軍 女,(1964—),博士,教授。主要研究方向:數據挖掘。
基金項目:山西省教育廳教學改革創新項目(J2021865)
