基于多智能體深度強化學習的多星觀測任務分配方法
2024-03-08 02:52:42王楨朗何慧群金云飛
上海航天 2024年1期
王楨朗,何慧群,周 軍,金云飛
(1.上海衛星工程研究所,上海 201109;2.上海航天技術研究院,上海 201109)
0 引言
由于衛星數量大量增加,導致衛星觀測任務需求也井噴式發展[1]。傳統集成大量功能的大型衛星被分解為多個單一功能的小型衛星,這些小型衛星具備較高的靈活性,并組成星群,可快速根據空間環境及任務變化調整自身情況,適應靈活任務需求[2-3]。這種情況下,會面臨集中式決策模式信息傳遞難度大、時間復雜度過高等問題。隨著邊緣計算的發展,帶來新的分布式決策模式,邊緣節點具有一定的算力,并有自主決策能力[4-5]。該模式更適應未來的復雜環境及多變的任務需求,更適合多星觀測任務分配。
可將上述問題理解為一個全局最優化問題,面對小規模問題時,采用確定性的精確算法,其問題規模變大后,會帶來更復雜的時空條件約束,增大求解難度,甚至無法求解[6]。
強化學習算法是一種不斷根據環境調整學習并受啟發的算法,智能體通過不斷地“試錯”與環境進行交互,獲得反饋并優化自身。隨著深度強化學習技術的發展應用,該算法在動態路由、通信鏈路分配、邊緣計算節點數據管理等領域取得了較為成功的應用[7-9]。在多星觀測系統中,將衛星看作決策智能體,并將觀測任務分配轉化為一個多智能體強化學習任務。
當前由于暫未有多智能體深度強化學習算法在多星觀測任務分配中的實際應用,因此本文做出以下工作[10]。
1)對多星觀測場景建模。
2)提出一個基于多智能體深度強化學習的多星觀測任務分配算法,在上述場景中解決分配問題。
3)設置對比算法,對比證明上述算法的優越性。
1 背景
1.1 多星觀測任務分配決策方式
集中式決策與分布式決策是當前2 種主要決策方式[11],在集中式決策場景中,存在一個中心決策節點來處理全局的信息,將決策好的序列分配給衛星執行。而分布式決策系統中不存在為系統統一進行決策的中心決策節點,各衛星的調度方案均由自身結合獲取的信息獨立決策集中式決策方案,往往由于系統復雜度高、信息過多導致決策時效性和質量下降。同時面對通信受限的場景時,由于信息傳遞不到位,造成信息獲取不全,可能會導致決策錯誤。
在多星觀測任務分配中,由于衛星數量多,響應時間要求高,且可能面對通信受限的場景,集中式決策難以得出最優解,因此采用分布式決策系統解決該問題。分布式系統的各個子模塊能按照自身獲取的信息及預先確定的內置規則自行決策,但這些系統不能實時更新決策規則,在多星觀測任務分配問題中,由于環境的動態性、任務的多樣性、約束的多樣性等原因,決策方案需要不斷進行自我調整,人為更新速度跟不上應用環境的變化。
作為一種端到端的人工智能方法,強化學習不需要頻繁地為新環境制定策略,其決策方案隨著智能體與環境的動態交互制定并不斷優化,且已被成功地應用于多個領域[12]。
1.2 多智能體深度強化學習
強化學習是近年發展起來的機器學習方法,通過讓智能體(Agent)與環境不斷交互,進而在獲得回報獎勵的過程中不斷學習并優化策略,達到獲得最大累積獎勵的目標。這一交互過程不斷重復,最終智能體通過收集的數據,達到最優的策略。與監督學習和無監督學習不同的是,強化學習的智能體在學習與交互過程中,沒有標準答案或事先制定的標簽,而是嘗試采取不同的行動來學習如何在給定的場景下獲得最大的獎勵。強化學習的框架如圖1所示。

圖1 強化學習的框架Fig.1 Frame of reinforcement learning
深度強化學習結合深度學習及強化學習的優點,其數學基礎和建模工具是馬爾可夫決策過程[13](Markov Decision Process,MDP)。這使得其算法能夠更好地適應復雜、大規模、連續、離散、高維、時變、不準確、不確定等真實世界中的各種問題。
當環境中存在多個智能體交互時,即是一個多智能體系統[14](Multi-Agent System,MAS)。每個智能體都各自遵循強化學習的目標,且彼此競爭或協作,以最大化回報獎勵。由于在系統中,智能體之間彼此互相作用影響,因此需要考慮聯合動作對環境和策略制定的影響。與單智能體強化學習問題相比,其問題難度較高,兩者之間主要存在以下區別。
1)環境的不穩定性:智能體在做決策的同時,由于其他智能體也在采取動作,環境狀態會隨著每個智能體采取動作而做出相應改變。
2)智能體獲取信息的局限性:不一定能夠獲得全局的信息,智能體僅能獲取局部的觀測信息,但無法得知其他智能體的觀測信息、動作、獎勵等信息。
3)個體的目標一致性:各智能體的目標可能是最優的全局回報,也可能是各自局部回報的最優。
4)可拓展性:在大規模的多智能體系統中,會涉及高維度的狀態空間和動作空間,對模型表達能力和真實場景中的硬件算力有一定的要求。
近年來,較多研究均將訓練與執行過程拆分開來,采用策略-評論家算法(Actor-Critic,AC)來訓練模型,訓練階段通過價值網絡(Critic)獲取全局信息來訓練策略網絡(Actor),執行階段只留下Actor 網絡獨立根據自身獲取的信息選取動作執行。
2 多星觀測任務分配問題的馬爾科夫模型
多星觀測任務分配問題的模型構建是通過抽象多星觀測任務分配問題中的各要素,使其成為馬爾科夫決策過程中的狀態、動作、回報等,進而構建馬爾科夫決策模型,并在此基礎上進一步設計深度強化學習算法框架。
2.1 馬爾科夫過程
大部分強化學習算法均可解釋為馬爾科夫決策過程在場景中,智能體會根據當前時刻的環境狀態,通過內置策略,選取一個對應當前狀態的動作,執行動作后,改變當前環境并獲得回報獎勵,得到序 列:s0,a0,r1,s1,a1,r2,s2,a2,r3,…,sn-1,an-1,rn,sn,此序列t時刻的數據元組st,at,rt+1,st+1即是一個馬爾科夫決策過程。
馬爾科夫決策過程其下一個時刻的狀態只與當前時刻的狀態有關,可表示為
式中:Pr為狀態轉移函數;h為在時間t之前的任意時間;s為當前的觀測狀態空間;s′為下一時刻狀態。
在馬爾科夫決策過程中,動作執行后一定會造成當前狀態以一定概率向下一個狀態轉移,如圖2所示。

圖2 馬爾科夫決策過程Fig.2 Diagram of the MDP
用元組(s,a,r,p)表示一個卡爾科夫決策過程,a為策略中可以執行的動作空間;為在狀態s下執行決策動作a,并使過程從s狀態轉移到s′的狀態轉移概率為,并獲得回報。表達式為
狀態值函數表示在遵循某一策略情況下,轉移狀態與目標狀態相似程度的函數,可以反映當前策略的好壞。在策略π下的狀態值函數為
式中:V為狀態價值函數;γ為折扣函數;π為當前策略。
當馬爾科夫決策過程進行到一定程度轉移狀態非常接近目標狀態時,即可得出最優狀態值函數或最優動作值函數,并通過最優值函數推導獲得最優策略π*,最優策略π*的推導公式如下:
最優狀態值函數的一般形式如下:
式中:Rt為回報獎勵總和;rt+k為在狀態st+k時采用動作at+k后的回報獎勵值,并通過最大化回報獎勵求解最優策略π*和狀態值函數Vπ(s)。
2.2 MDP 模型構建
提取對多星任務的資源、任務、約束進行數學化抽象后的要素[15],再用馬爾科夫決策過程對其描述,得出以下過程:智能體在當前環境中獲取狀態s,依據自身制定的策略π選擇下一步要執行的動作a,執行過動作a后,動作影響會使環境狀態轉變至s′,并獲得獎勵回報r。多星觀測任務分配的MDP模型如圖3 所示。
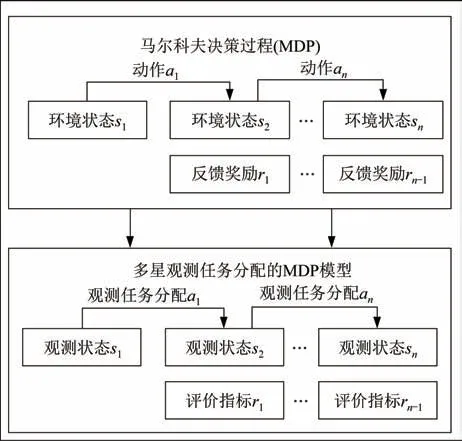
圖3 多星觀測任務分配的MDP 模型Fig.3 MDP model for multi-satellite observation task allocation
3 基于多智能體深度確定性策略梯度算法(MADDPG)的多星觀測任務分配算法
3.1 狀態空間設計
根據之前建立的MDP 模型,假設在時間t下,給定當前智能體i的輸入環境狀態為Sit,智能體根據自身策略輸出動作Ait,整個環境的環境狀態空間為St={S1t,S2t,…,Sit},多智能體的聯合動作集合為Ait={A1t,A2t,…,Ait},執行完當前動作獲得獎勵Rt,在多星觀測任務分配方法中,星群之間是完全合作關系,所以共享獎勵,可促進星群之間的合作,盡可能讓全局收益最大化。同時執行完動作后,智能體i所處的狀態Sit會以Pit(Sit|Sit+1,Ait)轉移到下一時刻t+1 的狀態Sit+1。
資源集中的智能體i在t時刻的狀態信息可用元組表示,其中(xi,yi,zi,vxi,vyi,vzi)為當前智能體的位置坐標以及速度矢量,(pi1,pi2,…,pin)為智能體各項能力數值的集合。
任務集中的子任務j在t時刻的狀態信息可用元組表示,其中(xj,yj,zj,vxj,vyj,vzj)為當前任務的位置坐標及速度矢量,為任務完成需要的各項指標數值的集合。
當智能體i與任務j的元組計算滿足可見性約束dij,如式(7)~式(12),以及衛星各項能力值pin與任務各項能力需求的比值Pbij時,如式(13),在滿足約束集要求時,Pbij越大說明該智能體i與任務j的匹配效果越好,在滿足可見性約束dij=1 時,可以進行任務分配。
式中:heij為Pbij的調節系數,如智能體i的能力系數都大于任務j對應的能力系數時,則認為當前分配效果好,將賦值為2,否則賦值為1/2。
3.2 動作空間設計
本文將多星觀測任務的資源分配設計歸結為對目標觀測的離散控制問題,其取值范圍為{a1,a2,…,an},n為目標數量,智能體i的動作決策表示:Ait=πi(·|Sit)。
3.3 獎勵函數設計
對智能體的回報獎勵函數進行以下設計:R為回報獎勵函數,式(15)中第1 項為任務與智能體兩者的能力匹配情況和的倒數,作為觀測執行質量的體現,其中ai為智能體i的決策結果,第2 項為未分配任務的懲罰值,其中k為固定參數,用于調整回報獎勵函數中的未分配任務對系統的影響程度,n0為未分配任務數。
在上述多星觀測任務分配場景中,因為智能體之間是完全協作的,因此共享一個回報獎勵值。
3.4 MADDPG 算法框架
在多智能體深度確定性策略梯度算法(Multi-Agent Deep Deterministic Policy Gradient,MADDPG)[16]中,每個智能體都有一組Actor和Critic,其根據觀測狀態si,輸出動作ai使智能體整體獲得最大回報獎勵;Critic 僅在進行中心化訓練階段使用,在訓練階段,Critic 根據Actor 輸出的動作,對動作進行評價分析,并反饋給Actor,實現Actor 的調優。
模型訓練的框圖如圖4 所示,圖中MADDPG 算法是由多個智能體分別實現一個深度確定性策略梯度算法[17](Deep Deterministic Policy Gradient,DDPG)組成,所有智能體i從環境獲取當前的觀測數據si后,其在線策略網絡(Online Actor,OA)根據si決策出動作ai,將其作為智能體i的動作輸出,多個智能體決策過后組成動作集合a,環境受到動作集合a的影響,更新當前狀態至s′,并反饋回報獎勵r={r1,r2,…,ri},之后將獲得的四元組(si,ai,ri,si′)存儲到經驗回放池[18](Experience Relay Pool,ERP)中,供下一步訓練需要。

圖4 MADDPG 模型訓練的框Fig.4 Block diagram of MADDPG model training
在模型訓練的過程中,從經驗回放池中抽取小批量樣本(Sample Mini-Batch,SMB)訓練[19]。在線價值網絡(Online Critic,OC)會把當前的(s,a)={s1,s2,…,si|a1,a2,…,ai}作為輸入用于自身訓練,輸出一維的Q值Q(s,a),同時結合回放樣本的Q′(s,a)以時序差分誤差構建兩者的MSE 損失函數,并結合獎勵r利用梯度下降更新Online Critic 網絡的參數,再通過軟更新(Soft Update,SU)算法更新目標價值網絡(Target Critic,TC)的參數,進而實現對網絡參數的更新。在計算自身Actor 的前向傳播時,Online Actor 只將自身局部觀測到的s={s1,s2,…,si}作為其輸入,輸出一個確定的動作ai,同時計算時序差分誤差的MSE損失函數,并結合Q(s,a) 利用隨機梯度下降(Stochastic Gradient Descent,SGD)更新參數,再通過軟更新算法更新目標策略網絡(Target Actor,TA)的參數。
3.5 AC 網絡結構
智能體的Actor 網絡結構如圖5 所示,其包括輸入層、隱含層、Softmax 層、輸出層,以及激活函數。將智能體觀測到的自身與其他智能體和任務的信息作為觀測狀態si輸入,狀態si經神經網絡的處理后獲得的一維向量為對應每個動作選擇[20],并使用Gumbel-softmax 方法激活函數,得到選擇每個動作對應的概率pi,依此制定策略π,對應pi_max的動作ai作為智能體i在狀態si時的輸出結果。

圖5 Actor 網絡結構Fig.5 Diagram of the Actor network structure
智能體的Critic 網絡結構如圖6 所示,Critic 網絡分為輸入層、隱含層、輸出層及激活函數,將所有智能體的狀態信息s={s1,s2,…,si}和動作決策a={a1,a2,…,ai}作為輸入,經神經網絡處理后獲得一個一維向量,再通過這個向量計算所有智能體共享的回報獎勵值r={r1,r2,…,ri}。

圖6 Critic 網絡結構Fig.6 Diagram of the Critic network structure
根據以下算法完成模型訓練后,各智能體根據制定的策略,獨立地在不同觀測狀態下選擇合適動作。
輸入初始化策略網絡參數θ={θ1,θ2,…,θM}和價值網絡參數?={?1,?2,…,?M}。
輸出訓練后的最優參數θ*,?*。
4 實驗
4.1 對比算法設置
為了證明基于上述設計的算法在建立的場景下具有有效性,選取DDPG 算法以及傳統隨機策略(Random)算法[21]作為對比算法。
4.2 實驗環境
本文設計了一個多星觀測任務分配場景,在該場景中,有一定數量的通信受到限制的衛星和任務節點,各衛星處于固定運行的軌道上,觀測任務目標節點隨機生成在WGS84 坐標下地面或近地空間的位置[22],此外每個衛星均擁有3 種類型能力,如分辨率、能源、最大可視距離等,能力數值根據正態分布隨機生成;對任務節點,也相應設置對這3 種能力的需求值,其大小根據正態分布隨機生成[23]。各衛星節點沒有中心決策節點對系統進行統一決策,各個衛星需自行根據觀測情況并結合自身策略選擇動作。由于該分配任務場景是完全協作的,所以各個衛星的動作回報獎勵將作為各智能體的獎勵,使得在協作的情況下,達到回報獎勵的全局最大化,并以此回報獎勵作為對算法性能的評估指標[24]。
本文算法采用Python 實現,硬件配置為1 臺Geforce RTX 4080 顯 卡、Intel-Corei7-12700KCPU的計算機,MADDPG 與DDPG 的網絡參數設定采用相同的配置,見表1。

表1 網絡超參數Tab.1 Hyperparameters of the network
4.3 實驗結果分析
采用MADDPG 算法時的回報獎勵曲線如圖7所示,橫縱坐標分別表示訓練回合數Epoch 及回報獎勵Reward。由圖7 可知,智能體獲得的回報獎勵值階梯式變化,最終穩定收斂在88 左右。在模型開始訓練階段,智能體獲得的回報獎勵波動較大,因為該階段智能體之間還未學會協同任務分配,導致其互相搶占相同任務,造成資源浪費。但由于不斷“試錯”,智能體在沒有中心決策節點的情況下,也逐漸分階段地學會了僅根據自身狀態和觀測信息的分布式協同任務分配策略。

圖7 采用MADDPG 算法訓練的智能體平均獎勵曲線Fig.7 Average reward curve of agents trained by the MADDPG algorithm
采用DDPG 算法解決多星觀測任務分配問題的訓練曲線如圖8 所示。由圖8 可知,采用該方法時,從訓練開始到結束回報獎勵的波動起伏較大。由于智能體之間不共享回報獎勵,導致其不是完全協作關系,并將彼此視為影響環境的因素,使得環境狀態難以穩定下來,最終造成算法難以收斂。

圖8 采用DDPG 算法訓練的智能體平均獎勵曲線Fig.8 Average reward curve of agents trained by the DDPG algorithm
采用Random 算法解決多星觀測任務分配問題的訓練曲線如圖9 所示。由圖9 可知,其大致收斂在65 左右,但比采用MADDPG 算法時收斂的回報獎勵低,采用MADDPG 算法解決多星觀測任務分配問題的效果更佳。

圖9 采用Random 算法訓練的平均獎勵曲線Fig.9 Average reward curve trained by the Random algorithm
5 結束語
在天基星座快速發展的當下,衛星及任務需求大量增加,空間環境復雜,傳統觀測任務分配方案難以適應未來需求,因此要求衛星有更強大的自主決策能力。
本文設計的基于MADDPG 算法的多星觀測任務分配算法,對動作空間的離散化改進動作空間選擇[25],設計了合適的回報獎勵函數優化決策方案,采用集中式訓練、分布式執行的模式,賦予衛星一定的自主決策能力[26]。在訓練階段,綜合全局信息開展訓練;在執行階段,衛星只需通過自身的觀測情況,即可做出決策,使其在通信受限的場景下也能進行觀測任務分配。實驗結果顯示,采用DDPG算法與Random 算法相比,采用MADDPG 訓練出來的各智能體收斂更穩定,且能獲得更高的回報獎勵,說明其具備更好的協同能力,其多星觀測任務分配方案效果更好。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
