基于ELKB日志管理系統的應用
2024-02-28 13:50:52郭翠娟李思佳
科學技術與工程 2024年3期
關鍵詞:優化
郭翠娟, 李思佳
(1.天津工業大學,天津市光電檢測技術與系統重點實驗室, 天津 300387;2.天津工業大學電子與信息工程學院, 天津 300387)
近年來,云平臺應用范圍越來越廣泛,連接的設備節點眾多[1-2],使得平臺產生的數據量呈爆發式增長。當云平臺監測到異常事件時,很難及時對故障進行排查,使得云平臺的運維工作面臨很大的挑戰。日志將平臺運行的所有重要事件及時用文本的形式記錄下來,充分利用日志信息,方便進行性能監控、故障診斷、系統運維等工作[3]。因此,日志成為云平臺安全問題管理的重要依據。現階段,云平臺日志數據源廣泛,存儲結構復雜,且對日志分析實時性要求較高[4]。原始的人工查詢和處理方式無法滿足實時性的需求,導致日志分析效率低下。
隨著實時分析技術的發展,各種日志管理工具相繼出現。例如,企業級日志分析軟件Splunk、Apache公司旗下的Flume系統[5],以及開源的日志管理組件ELK(數據搜索引擎Elasticsearch[6]、日志收集器Logstash以及可視化平臺Kibana三個開源工具名稱的縮寫)。相比較其他日志管理工具,ELK具備輕部署的特點,勝任于在海量數據中高效檢索數據,Logstash采集器提供數據采集過濾功能,Elasticsearch滿足海量數據的存儲需求,Kibana支持用戶定制個性化日志分析圖表。因此,ELK廣泛應用于實時日志分析監控和故障監測等相關領域。
文獻[7]使用ELK工具實時收集系統日志,并篩選與故障相關的日志數據在深度學習框架中進行模型訓練,最后達到對系統故障實時預測的目標。文獻[8]介紹了利用ELK框架、大數據Kafka技術和數據流引擎Flink技術設計并實現了一個實時的海量日志分析系統,并針對物聯網平臺時序日志提出一種深度學習方法來診斷平臺異常事件。文獻[9]通過Logstash采集器收集各個節點的日志數據,并統一進行過濾和預處理。為提高校園網平臺日志數據的存儲和查詢性能,采用Elasticsearch分布式架構實現對日志的存儲和檢索,最后通過Kibana可視化平臺進行日志的分析。文獻[10]研究使用Elasticsearch進行數據倉庫和地理傳感器數據的分析,提出一種在Elasticsearch中實現和查詢多維模型的方法,并通過大量實驗對比其查詢性能。以上應用場景中ELK系統表現出良好的分析效果,但ELK中重量級采集器Logstash在性能方面存在消耗資源較大的問題。文獻[11]針對Logstash采集器在CPU和內存資源方面有較大壓力的問題,提出采用輕量級采集器Beats來替代Logstash進行日志采集,并討論了Logstash解析日志的規則與方法,實現了日志采集的分析監控系統。文獻[12]為了提高智慧管廊云平臺的日志管理效率,分別使用Beats中的輕量級采集器Filebeat和Metricbeat進行日志文件和服務器性能數據的收集,實現了對服務器性能的監測,降低了系統的資源占用率。Filebeat是輕量級日志采集器,但在應用部署時,由于配置不合理或是無差異化的默認配置,也會造成非預期情況下資源耗盡的問題,導致平臺其他服務無法正常運行。Elasticsearch作為ELK系統的核心模塊,優化Elasticsearch節點的配置,可以使其獲得更優的查詢和檢索性能。
基于云平臺應用場景,為了解決Logstash的性能消耗問題,同時為減少數據傳輸環節和部署復雜度,在ELK架構基礎上使用輕量級采集器Filebeat取代Logstash實現日志收集功能,并提出調整采集器Filebeat基礎參數的方法。日志存儲過程部署Elasticsearch集群模式,并總結提出Elasticsearch節點的性能提高方法,在此基礎上通過Kibana可視化平臺搭建日志管理系統,以支撐云平臺日志運維和性能監控的工作。
1 基于ELKB的日志管理系統
1.1 日志管理系統的整體結構
一個完整的日志管理系統主要包括日志采集模塊,日志存儲模塊以及日志可視化模塊三個部分。基礎的ELK架構中,Logstash將搜集到的非結構化日志按照規則解析之后輸出至Elasticsearch。作為存儲和檢索日志的中央系統,Elasticsearch一方面接收日志采集模塊傳來的日志數據,另一方面配合Kibana完成日志可視化工作。由于Logstash既負責日志采集工作,又要完成日志解析的任務,使其消耗了極大的系統CPU和內存資源。相比Logstash采集器[13],Elastic公司推出的輕量級日志采集器Beats,占用系統資源極少,在低性能的設備節點中具有很大的優勢。Beats為采集不同的日志源提供了不同的采集器,比如日志文件采集器Filebeat、系統指標采集器Metricbeat。引入Beats之后的系統也被稱作ELKB架構。ELKB架構的日志處理流程如圖1所示。
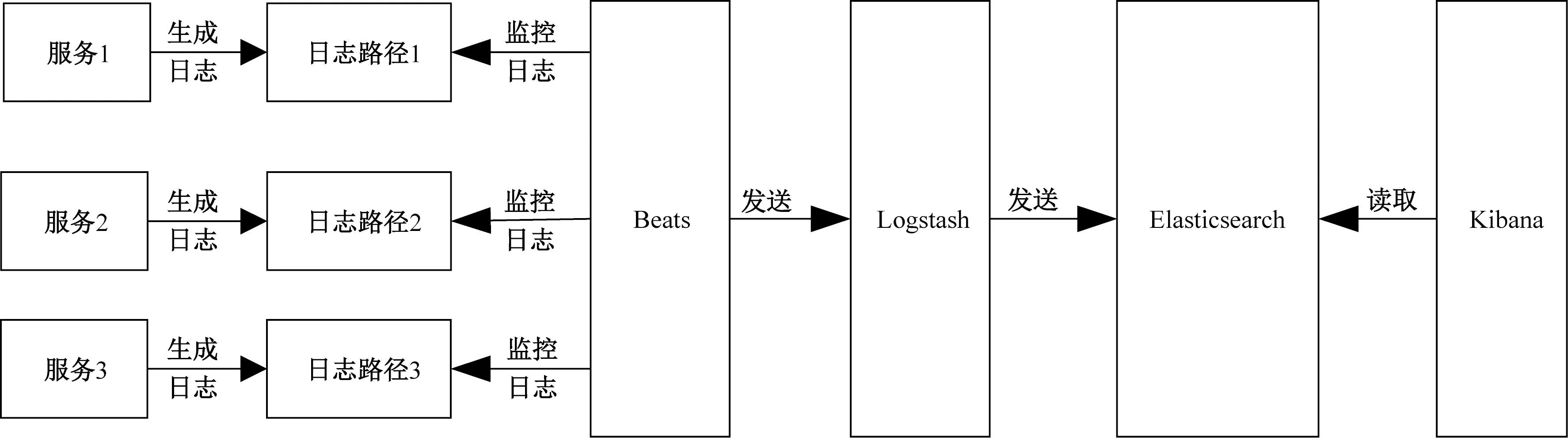
圖1 ELKB架構的日志處理流程圖Fig.1 Log processing flow chart of ELKB architecture
1.2 日志文件采集模塊
日志管理的第一步是進行日志采集,日志分散存儲在不同的服務器中,進行統一匯總后便于后續分析。日志采集端需要作用在日志產生端的服務器上,因此,需要確保日志采集器是輕量級的,不能占用過多的系統資源從而影響云平臺服務端本身的性能。基于ELKB架構基礎,主要利用日志文件采集器Filebeat實現日志的收集和傳送。Filebeat性能穩定,無依賴性,收集日志速度快,同時所占的系統資源極少,在低性能的設備節點中具有很大的優勢。
Filebeat采集器運行過程如圖2所示,首先Crawler負責管理和啟動各個輸入的Prospector,Prospector是探測器,負責解析輸入源,找到所有讀取的日志文件來源。每找到一個日志來源就會啟動一個采集器Harvester,然后按行讀取日志內容并輸出到指定目標。Registrar管理并記錄每個文件狀態,包括偏移量、文件名信息等。當Filebeat的服務中斷再次啟動后,Registrar及時恢復文件處理狀態,補傳中斷時期的日志變化,此方式保證了Filebeat不會丟失任何數據。Pipeline負責管理緩存消息。Output是輸出源,由配置文件指定輸出目標。
1.3 日志存儲檢索模塊
日志數據采集完成后,被傳輸至Elasticsearch做集中處理,該模塊負責對采集端發送的所有數據源進行持久化存儲,并支持日志的搜索和結構化查詢。Elasticsearch可以看作是非關系型數據庫[14],與關系型數據庫MySQL[15-16]的重要概念對比如表1所示。
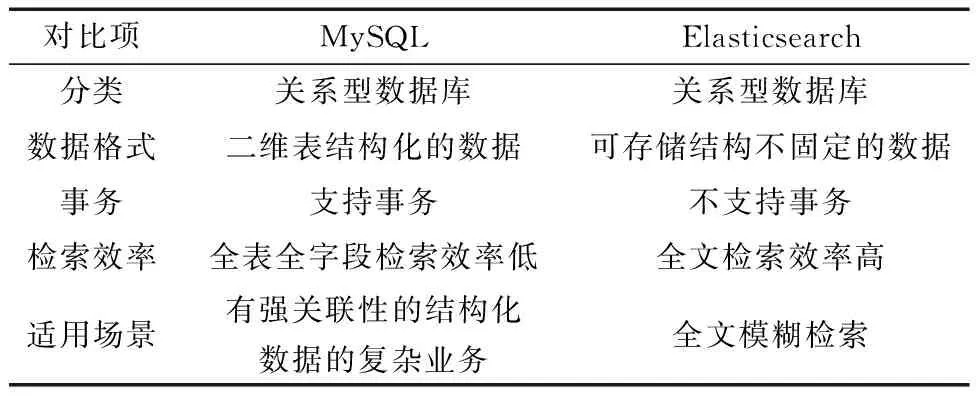
表1 Elasticsearch與MySQL的概念對比Table 1 Concept comparison between Elasticsearch and MySQL
從表1可以看出,Elasticsearch可存儲結構不固定的數據,比關系型數據庫更加適合處理非結構化的日志數據。Elasticsearch提供Index索引[17]服務,Index在空間邏輯上可以類比關系型數據庫中的Database,在物理上是一類文件的集合。Elasticsearch將每一個字段編入Index,所有查詢均基于Index完成。
1.4 日志可視化分析模塊
日志信息經過采集和存儲后,得到了統一的結構化數據,然后通過Kibana平臺對日志進行數據展示和查詢分析。Kibana提供友好的數據可視化平臺,支持用戶定制個性化的日志分析圖表,通過判斷并解析Elasticsearch中定義的Index索引名稱,建立直觀地圖表展示所需分析的日志詳細信息。Kibana的效果展示圖如圖3所示。
圖3 Kibana效果展示圖Fig.3 Kibana effect display
2 Filebeat采集器基礎參數優化
Filebeat是輕量級日志采集器,但是在應用部署時,由于配置不合理或是無差異化的默認配置,也會造成非預期情況下CPU強占和內存耗盡的問題,導致平臺其他服務無法正常運行。因此,為降低采集器的資源占用,提高采集性能,對Filebeat掃描日志文件時的相關參數進行合理配置。通過配置文件filebeat.yml優化以下參數,Filebeat采集器參數優化信息如表2所示。
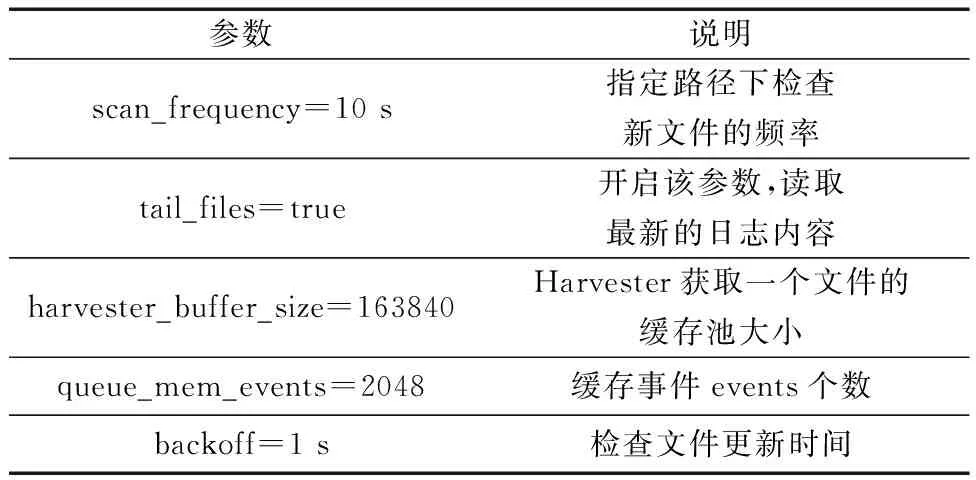
表2 Filebeat參數優化信息表Table 2 Filebeat parameter optimization information table
如表2所示,參數scan_frequency表示在指定路徑下檢查新文件的頻率,該參數會影響Filebeat采集器的計算能力,當設置時間過短時,內存使用率會增加。設置時間在5~15 s是合理的,本系統設置為10 s。將參數tail_files設置為true,保證采集器一直讀取最新的事件消息,不需要重復發送所有的內容,可以提高日志讀取效率。harvester_buffer_size參數表示獲取一個文件值的緩存池大小,默認值為16 384,本系統將緩存池的大小設置為163 840,即擴大為默認的十倍來應對高流量的日志寫入情況。queue_mem_events參數表示內存隊列的事件個數,Filebeat默認配置的緩存事件個數為4 096,緩存事件個數直接關系內存的占用量,本文將緩存事件個數降低一倍,設置為2 048,避免出現內存爆增的問題。backoff參數表示檢查文件更新的時間,將該參數設置為1 s,代表實時檢查文件的更新情況。
3 Elasticsearch性能優化
3.1 Elasticsearch集群配置
Elasticsearch作為日志管理系統的核心模塊,具備集中存儲和快速檢索數據的功能。Elasticsearch支持水平擴展,集群模式可以使服務更加穩定可靠,從整體上提高擴展性和數據吞吐率。構建集群模式的成員稱作節點,在Elasticsearch集群模式下,節點被劃分為主節點(Master)、數據節點(Data)和協調節點(Coordinate)。每個節點負責不同分工,其中,主節點負責創建或刪除索引文件、跟蹤集群節點等工作;數據節點負責保存數據分片;協調節點負責請求分發和結果的匯聚。
綜合考慮目前的服務器硬件配置,使用三臺CentOS服務器部署了Elasticsearch集群,并在每個節點上配置集群名稱(cluster.name)、節點名稱(node.name)、主節點(node.master)、數據節點(node.data)以及端口號(http.port)等信息。集群節點之間通過單播或組播的方式互相訪問和共享數據,當節點遵循同樣的規則時,獲得的信息是對等的,即配置相同集群名稱的節點自動加入到該集群。Elasticsearch集群節點配置方式如表3所示。
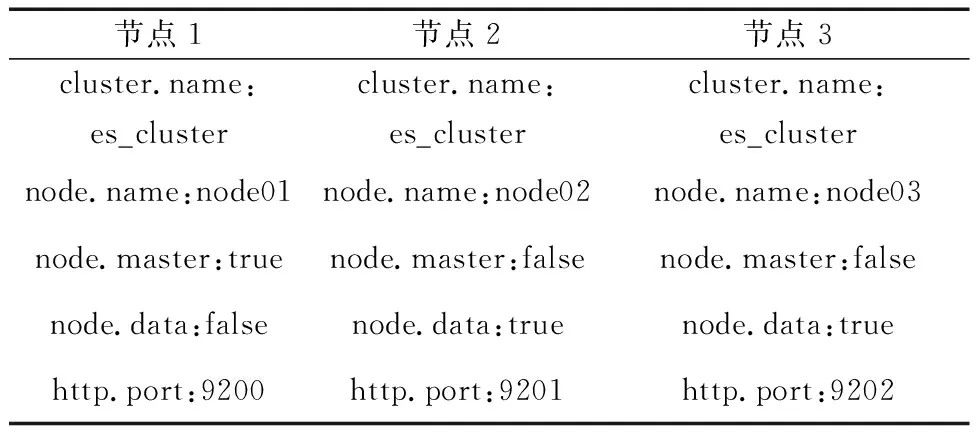
表3 Elasticsearch集群節點配置Table 3 Elasticsearch cluster node configuration
3.2 Elasticsearch集群節點性能優化
Elasticsearch集群包含多個node節點,其中每個node節點的數據分布結構如圖4所示。Elasticsearch將每個Index拆分后存儲在多個node節點上。Index又可以劃分為多個分片shard,其中的主分片用于存儲數據。shard又包含多個segment,每個segment都是一個倒排索引[18]。segment在數據輸入后創建,是不可變的,當編輯或刪除數據時會創建一個新的segment,并標記舊的segment為刪除狀態。
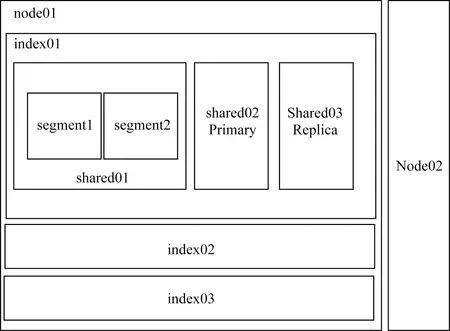
圖4 數據分布結構圖Fig.4 Data distribution structure
基于上述節點的數據分布結構,為進一步提升Elasticsearch在實際處理數據時的檢索性能,優化Elasticsearch集群的節點配置,可以使其獲得更優的查詢和檢索性能。
(1)刷新間隔優化。每當Elasticsearch接收到新的日志文檔,就將內容寫入到segment文件中,默認每秒刷新一次,產生一個新的segment數據段,當索引的文檔不斷增多時,會導致產生大量細小的segment,查詢性能隨之下降。因此,可適當增大刷新時間間隔,這樣可以大大降低segment文件生成的數量,同時可以保證在高并發場景下有較快的寫入性能。
(2)段合并優化。由于每次查詢索引都需要訪問當前所有的segment文件,隨著segment文件不斷生成,請求的響應速度會隨之下降。為解決這個問題,Elasticsearch通過歸并計算定時將零散的segment分段合并成較大的分段,即做段合并。當較大的segment文件被刷新到磁盤中時,被合并的segment文件隨之刪除,這樣索引中segment數量會大大降低,保證請求響應速度不會受到影響。在配置文件elasticsearch.yml中修改與段合并有關的參數,段合并相關參數值說明如表4所示。

表4 段合并相關參數值說明表Table 4 Merge the relevant parameter value description table
(3)分片與副本設計。當Elasticsearch集群中某個節點發生故障時,該節點中存儲數據的分片將不可用,造成數據丟失的現象。為避免出現此情況,本文將每個主分片均復制一份副本分片保存在與主分片不同的集群節點上。當集群節點中的主分片不可用時,請求可以發往副本分片,副本分片檢測到主分片節點出現故障后,將副本分片提升為主分片,保證查詢服務正常可用。在配置文件elasticsearch.yml中設置相關分片與副本數量,如表5所示。

表5 索引分片個數說明表Table 5 The number of index fragment description table
(4)內存調優。Elasticsearch服務的運行涉及JVM堆內存,對JVM堆內存設置進行調整,可以提升Elasticsearch的運行性能。在安裝目錄下的jvm.option文件中進行配置,其中JVM的最大堆內存(-Xmx)和最小堆內存(-Xms)通常設置相同的值,且是總內存的一半,這樣既保證系統留有足夠的內存使用,又不會超過內存限制值的上限。假設容量是4 G的專用服務器,將JVM大小設置為2 G,避免了多余的性能消耗,可最大程度發揮JVM的性能。
4 系統性能測試與分析
4.1 環境搭建
按照3.1節設計的Elasticsearch集群結構,使用三臺CentOS服務器進行安裝部署,服務器的配置是:2核CPU,4 G內存,分別安裝日志組件Filebeat、Elasticsearch、Kibana來搭建日志管理系統,測試中采用的壓力測試工具是Apache Jmeter。各組件的配置版本如表6所示。
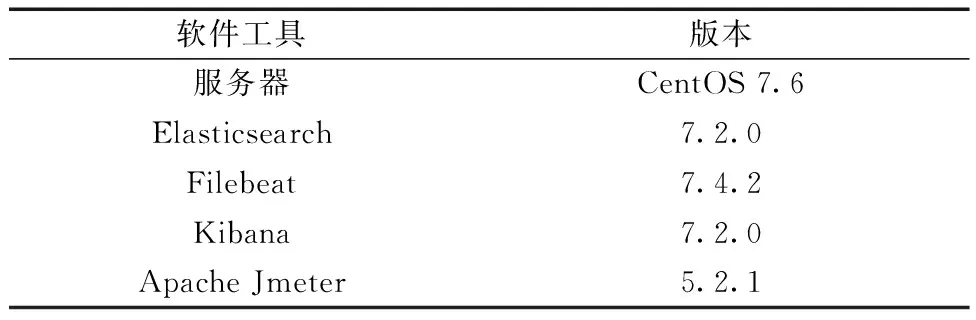
表6 組件工具配置表Table 6 Component tool configuration table
4.2 Filebeat采集器參數優化對比測試
為提高日志采集器Filebeat的性能,解決非預期情況下采集器的資源占用問題,對Filebeat掃描日志文件時的相關參數進行優化。下面記錄采集日志文件逐漸增加的情況下,Filebeat參數優化前后在系統中的內存占用百分比,測試結果如圖5所示。
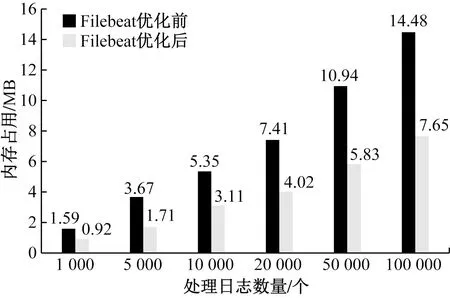
圖5 Filebeat優化前后內存占用對比圖Fig.5 Comparison of memory footprint before and after Filebeat configuration
從圖5可以看出,當日志處理文件數量較少時,采集器配置前后內存占用率相差不大,但隨著日志數據量的不斷增加,優化后的采集器內存占用率明顯降低。當處理日志數量達到十萬數量級時,優化后的Filebeat比之前的內存占用率降低約47%。由此可知,優化后的Filebeat采集器在處理海量日志時具備更大的優勢。
4.3 Elasticsearch集群與單機吞吐率對比測試
為了測試日志存儲模塊的集群優化效果,在Elasticsearch數據庫中進行關鍵字查詢測試。通過測試工具ApacheBench創建多線程來模擬并發用戶訪問被測節點,并記錄相同配置下Elasticsearch集群模式和單機服務器的吞吐率變化情況。實驗進行關鍵字查詢的測試結果如圖6所示。
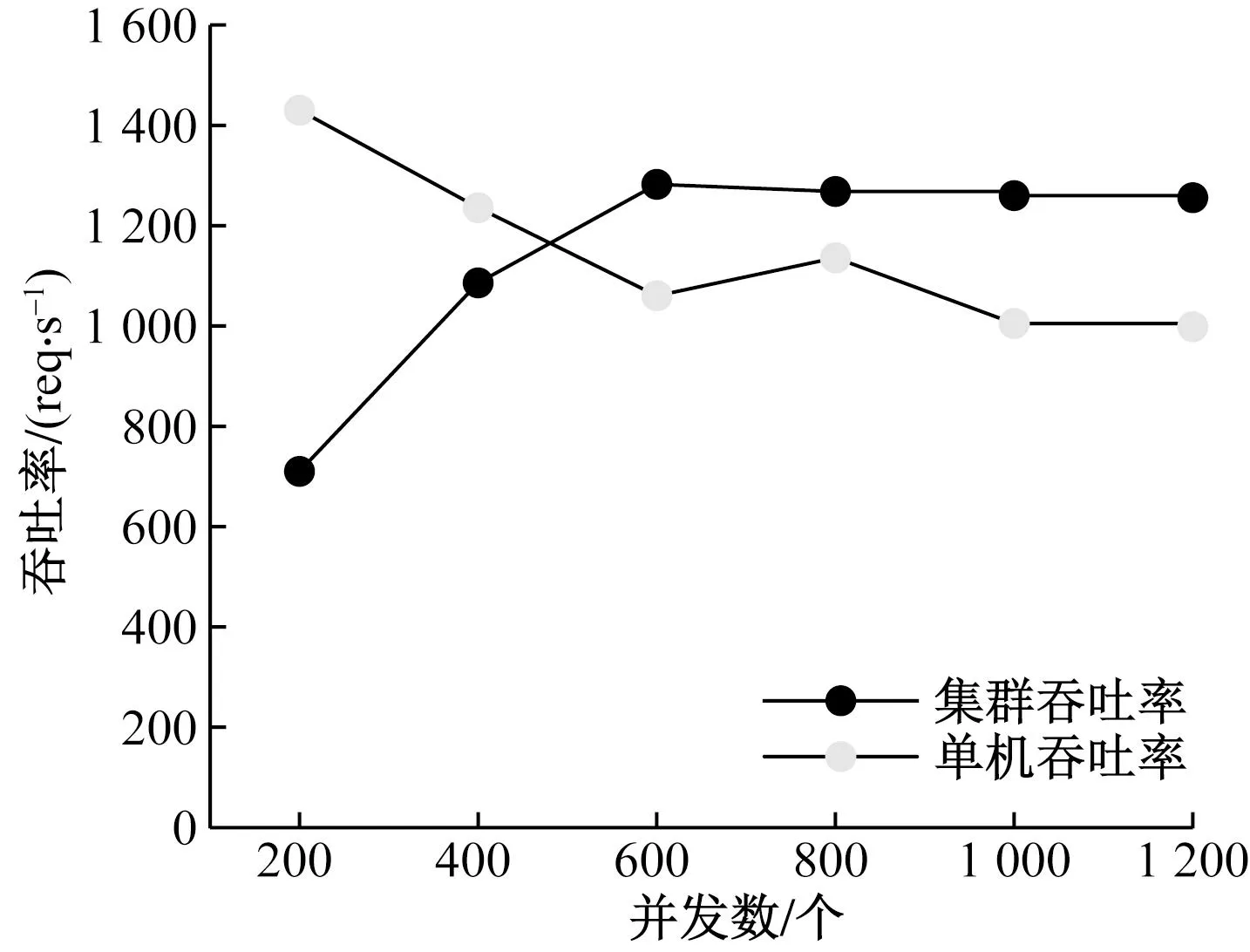
圖6 集群和單機吞吐率性能對比圖Fig.6 Comparison of throughput performance between cluster and stand-alone
從圖6中可以看出,在并發數量較小的情況下,集群的吞吐率低于單機服務器吞吐率,這是由于在并發數量較小的情況下,集群模式沒有發揮明顯的優勢。隨著并發數量的增長,單機的吞吐率逐漸降低,集群吞吐率呈線性增長趨勢,這代表集群服務的資源被充分利用,但受限于硬件條件,吞吐量會趨于平緩。在實驗測試中,單機吞吐率最終穩定在1 000 req/s左右,集群吞吐率穩定在1 250 req/s左右。因此,在相同硬件條件下,實驗結果表明Elasticsearch集群模式在進行并發數量較高的關鍵字查詢時數據的吞吐率性能更高,部署Elasticsearch集群模式可以更好地提高數據檢索效率。
4.4 Elasticsearch段合并前后索引內存對比測試
按照3.2節的段合并優化方法進行參數設置,并測試段合并優化前后日志數據索引所占用的內存情況。實驗中記錄了日志處理數量為5 000、10 000、15 000、20 000時的段合并前后索引內存占用情況,對比結果如圖7所示。
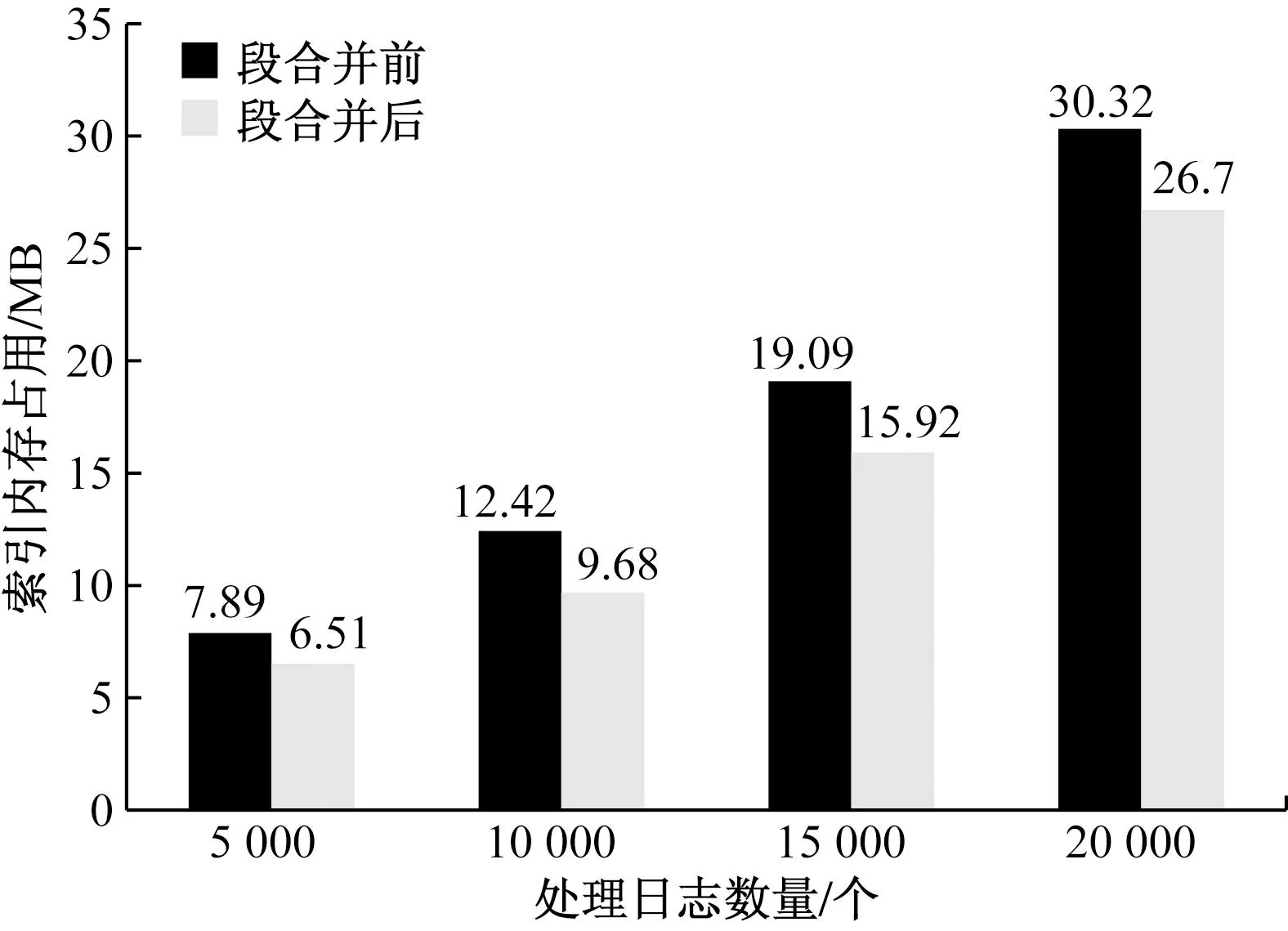
圖7 段合并前后內存占用統計圖Fig.7 The memory occupancy statistics before and after merging
從圖7可以看出,通過設置段合并,使日志中索引內存占用明顯降低。分別統計段合并前后優化的百分比,可以得出內存優化百分比從11.9%到22.1%不等,表明段合并設置對Elasticsearch的索引內存優化效果顯著。
4.5 日志可視化分析
Kibana作為日志數據流的輸出端,以統計圖表的方式展示存儲在Elasticsearch中的索引數據。Kibana提供豐富的可視化組件,可以生成時序圖、區域圖、報表圖等常用統計圖表。首先進入Kibana主界面,點擊側面導航中的Discover進入Kibana的數據檢索頁面。選擇查詢的索引名稱,即在Elasticsearch中定義的索引字段,如圖8所示,設定索引檢索名稱為“filebeat-*”,可以檢索到符合該索引模式的日志數據。此外,Kibana提供任意時間范圍的日志查詢,在頁面右上角選擇查詢時間范圍,如“Last 15 minutes”,即篩選最近15 min收集的日志數據,方便對系統進行實時監控和維護。
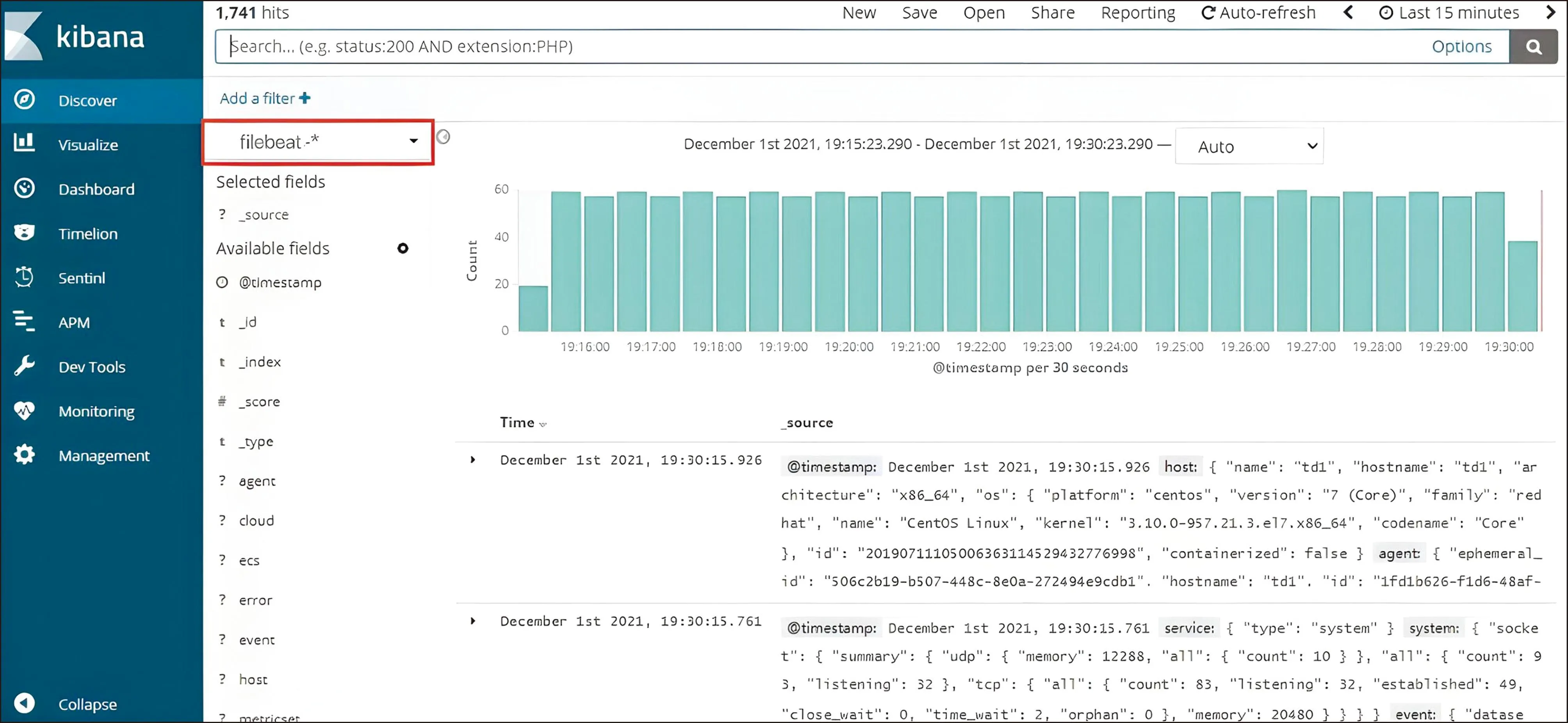
圖8 日志采集結果展示圖Fig.8 Kibana retrieval log data
5 結論
(1)以ELKB為基礎架構,基于云平臺應用對日志管理系統進行了研究及應用,并在服務器上完成采集器Filebeat、數據庫Elasticsearch、可視化平臺Kibana的部署工作。
(2)在日志文件采集模塊,提出對采集器Filebeat基礎參數進行調整的方法,包括提高緩存池容量、降低緩存文件個數等。實驗結果表明:當處理日志數量達到十萬數量級時,參數優化后的Filebeat在進行日志采集時,內存占用率與默認配置相比降低47%。由此可知,優化后的Filebeat采集器在處理海量日志時具備更大的優勢。
(3)在日志存儲檢索模塊,部署了Elasticsearch集群模式,提出Elasticsearch集群節點的性能提升方法,包括段合并優化策略。實驗結果表明:Elasticsearch集群模式在進行關鍵字查詢時數據的吞吐率高于單機服務器250 req/s,且段合并優化有效降低了日志的索引內存占用量,優化百分比從11.9%到22.1%不等。
(4)在日志可視化分析模塊,通過Kibana平臺搭建日志管理系統,用戶可通過自定義的方式將檢索出的日志數據通過條形圖、折線圖等圖表形式進行分析。
綜上,本文在日志采集、日志存儲檢索及日志可視化分析方面提供了可行的方法,有效提高了云平臺的日志運維效率。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
