基于GAN的流量檢測類不平衡問題
2024-02-22 00:00:00邵永運趙祉健孫可
沈陽師范大學學報(自然科學版) 2024年5期


摘要:針對異常流量檢測任務中存在的類不平衡問題,提出了一種基于生成式對抗網絡(generative adversarial networks,GAN)和時間卷積網絡(temporal convolutional network,TCN)的上采樣方法,該方法能夠有效增強少數類樣本的表示能力。將GAN網絡擴展為帶有梯度懲罰機制和條件輔助信息的Wasserstein生成對抗網絡CWGAN-gp,梯度懲罰機制通過在判別器的損失函數中加入懲罰項,約束判別器的梯度,提高了訓練的穩定性和生成效果。條件輔助信息使生成器能夠基于特定條件生成數據,增強了模型的靈活性。通過CWGAN-gp網絡生成器和判別器的對抗學習,生成高質量的數據。TCN幫助CWGAN-gp網絡捕捉到數據的長期依賴關系,從而更好地理解流量數據的動態特征。實驗證明,該方法在ozone_data、occupancy_data、CreditCard以及UNSW-NB15等數據集上的評估和實證研究中,均顯著提升了分類模型對少數類別的識別率,展現了該方法在不同場景下的有效性和魯棒性。
關鍵詞:生成對抗網絡; 時間卷積網絡; 異常檢測; 上采樣
中圖分類號:TP319文獻標志碼:A
doi:10.3969/j.issn.1673-5862.2024.05.005
Class imbalance problem in anomaly traffic detection based on GAN
SHAO Yongyun, ZHAO Zhijian, SUN Ke
(Software College, Shenyang Normal University, Shenyang 110034, China)
Abstract:
To address the class imbalance issue in anomaly traffic detection tasks, an upsampling method based on Generative Adversarial Networks (GAN) and Temporal Convolutional Networks (TCN) is proposed. This method effectively enhances the representation of minority class samples. The GAN framework is extended to a Wasserstein Generative Adversarial Network with Gradient Penalty (CWGAN-gp), incorporating a gradient penalty mechanism and conditional auxiliary information. The gradient penalty mechanism improves training stability and generation quality by constraining the gradient of the discriminator through a penalty term in its loss function. Conditional auxiliary information enables the generator to produce data based on specific conditions, enhancing the model′s flexibility. Through adversarial learning between the CWGAN-gp generator and discriminator, high-quality data is generated. TCN assists the CWGAN-gp network in capturing the long-term dependencies of data, allowing for a better understanding of the dynamic characteristics of traffic data. Experimental results demonstrate that this method significantly improves the classification model′s ability to identify minority classes, as evidenced by evaluations and empirical studies on the ozone_data, occupancy_data, CreditCard, and UNSW-NB15 datasets. This showcases the effectiveness and robustness of the method in different scenarios.
Key words:
generative adversarial networks; temporal convolutional network; anomaly detection; oversampling
異常流量檢測任務主要面臨的挑戰是類不平衡問題,同時還需考慮數據的時序特性。在類不平衡的背景下,異常流量檢測數據中的類別分布可能存在嚴重偏斜,這會導致少數類別的樣本數量遠遠少于其他類別。解決這一挑戰需要在考慮時間相關性、趨勢性、周期性和季節性等特殊關系的同時,充分關注少數類別的學習和分類準確性,以確保模型對所有類別都有良好的泛化能力。目前針對異常流量的分類方法分為以下幾種:1)基于相似性度量的方法。如:動態時間規整(dynamic time warping,DTW)[1]、導數動態時間規整(derivative dynamic time warping,DDTW)[2],這些方法通過計算時間序列之間的相似性度量來進行分類。2)基于最大區分子序列的方法。如:Shapelets[3],該分類方法主要是從訓練數據中識別出具有顯著特征的子序列shapelet,再利用這些 shapelet 來比較和分類新的時間序列數據。3)基于深度學習的方法。卷積神經網絡(convolutional neural network,CNN)[4-5]、循環神經網絡(recurrent neural network,RNN)[6]以及Transformer[7]等深度學習模型可以進行時間序列分類任務。這幾大類算法雖然在模型性能上優于傳統的分類算法,但是會受到數據集規模的限制以及實驗環境的影響。
類不平衡問題指的是在一個分類任務中,不同類別的樣本數量差異較大,導致訓練模型時某些類別的樣本數量遠遠少于其他類別,從而影響了模型的性能和泛化能力[8]。解決此類問題的常見方法是使用重采樣技術,如通過SMOTE[9]算法和ADASYN[10]算法來生成少數類別的數據,以及使用編輯近鄰法(edited nearest neighbor,ENN) [11]來移除部分多數類別的數據。
傳統的重采樣技術往往無法準確地反映真實數據的分布特征。GAN通過對抗學習生成更為逼真的數據[12],從而解決異常流量檢測任務中存在的類不平衡問題。GAN通常包括一個生成器(G)和一個判別器(D),生成器負責生成類似于真實數據的樣本,而判別器則負責區分真實數據和生成的數據。通過不斷的對抗學習,生成器逐漸學習生成更為逼真的數據,但同時GAN面臨著訓練不穩定和模式崩潰等問題。因此,本文構建了一類結合CWGAN-gp與TCN的方法CWGAN-TCN,有效解決了異常流量檢測任務中的類不平衡問題。
1預備知識
1.1CGAN
生成對抗網絡的生成器接收隨機噪聲z作為輸入,并將其轉換為與原始真實數據分布相匹配的G(z)。判別器的輸入包括真實數據樣本以及生成器產生的樣本G(z),其任務是區分輸入的數據是真實數據還是生成數據。通過對抗訓練的方式,生成器能夠學習生成高質量的仿真數據,而判別器則學會有效地區分真實數據和生成數據。
條件生成式對抗網絡(conditional generative adversarial network,CGAN) 在GAN的基礎上增加了條件信息[13]。通過引入條件信息,CGAN 可以實現對生成數據的控制,使得生成器能夠按照所提供的條件信息生成特定類型或特征的數據。CGAN的生成器損失函數可表示為
L(G)=-Ez~pz(z),c~pc(c)[logD(G(z,c))](1)
其中:z是輸入噪聲;pz(z)是輸入噪聲分布;c是條件信息;pc(c)是條件信息分布;G(z,c)是生成器生成的樣本。
CGAN的判別器損失函數可表示為
L(D)=-Ex~pdata(x)[logD(x|c)]-Ez~pz(z),c~pc(c)[log(1-D(G(z,c)|c))](2)
其中:pdata(x)是真實樣本的分布;D(x|c)是給定條件下判別器對樣本x的判別概率。
1.2WGAN-gp
GAN在訓練過程中常會面臨梯度消失和模式崩潰等問題。梯度消失是在訓練過程中,由于判別器對生成器產生的樣本給出了極低的梯度,導致生成器無法有效地學習更新;模式崩潰是生成器傾向于只生成相似的樣本,而不是多樣性的輸出。Wasserstein生成對抗網絡(wasserstein generative adversarial network,WGAN)通過引入 Wasserstein 距離使得生成器和判別器的訓練過程更加有效[14]。Wasserstein 距離為
W(pdata,pg)=infγ∈∏(pdata,pg)E(x,y)-γ[d(x,y)](3)
其中:∏(pdata,pg)是真實數據分布pdata和生成數據分布pg的聯合分布概率;d(x,y)是距離函數。Wasserstein距離在衡量2個分布之間的距離時,即使這2個分布沒有重疊,它仍然能夠準確地反映它們之間的距離。
在引入Wasserstein距離后,Wasserstein生成對抗網絡需要滿足嚴格的連續性,即Lipschitz連續性。在WGAN-gp中引入了梯度懲罰機制(gradient penalty,GP),其作用就是強制判別器滿足Lipschitz連續性條件。梯度懲罰通過在判別器的損失函數中增加對判別器的梯度進行懲罰,從而迫使判別器輸出的梯度范數接近于1。這種約束條件確保了判別器的梯度不會爆炸,同時也間接地保證了判別器的Lipschitz常數不會過大,并滿足Lipschitz連續性條件,從而可得WGAN-gp的聯合目標函數如下:
minGmaxD(Ex~pdata(x)[D(x|c)]-Ez~pz(z)[D(G(z))]+λE-p
[(‖D()‖2-1)2])(4)
其中:G是生成器;D是判別器;pdata(x)是真實數據分布;pz(z)是隨機噪聲的先驗分布;是真實數據和生成數據的線性插值;p是線性插值分布;λ是梯度懲罰項的權重;D()是判別器在處的導數。
損失函數的目標是最小化G的目標函數同時最大化D的損失函數,使得生成器生成的數據分布接近真實數據的分布,且使判別器能更好地區分真實數據和生成數據。
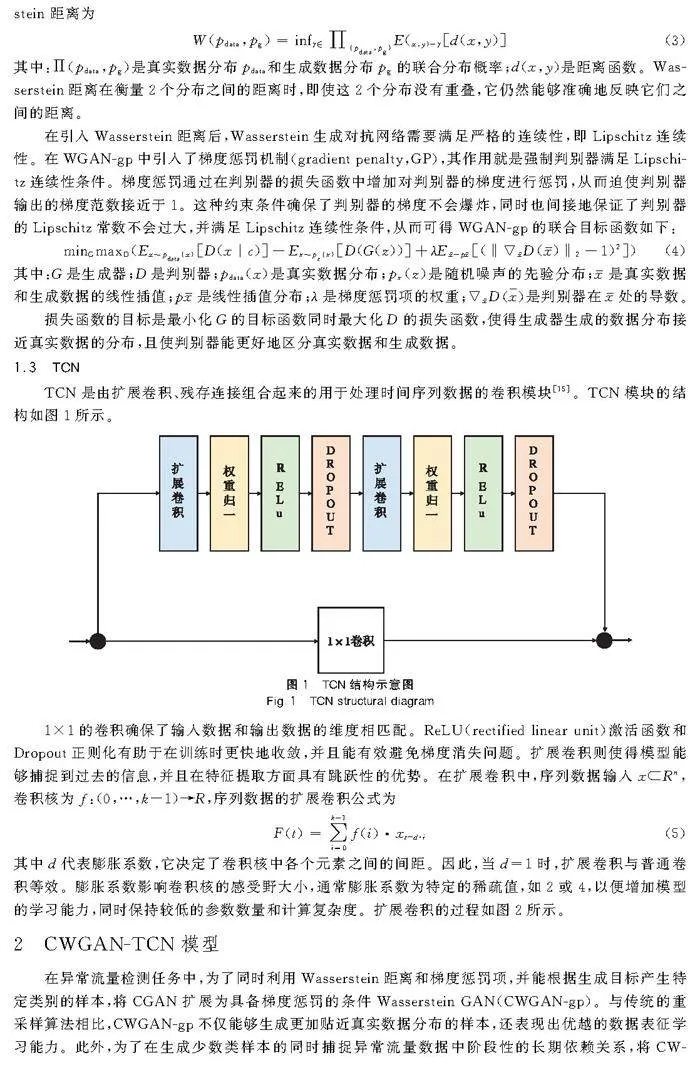
1.3TCN
TCN是由擴展卷積、殘存連接組合起來的用于處理時間序列數據的卷積模塊[15]。TCN模塊的結構如圖1所示。
1×1的卷積確保了輸入數據和輸出數據的維度相匹配。ReLU(rectified linear unit)激活函數和Dropout正則化有助于在訓練時更快地收斂,并且能有效避免梯度消失問題。擴展卷積則使得模型能夠捕捉到過去的信息,并且在特征提取方面具有跳躍性的優勢。在擴展卷積中,序列數據輸入xRn,卷積核為f:(0,…,k-1)→R,序列數據的擴展卷積公式為
F(t)=∑k-1i=0f(i)·xt-d·i(5)
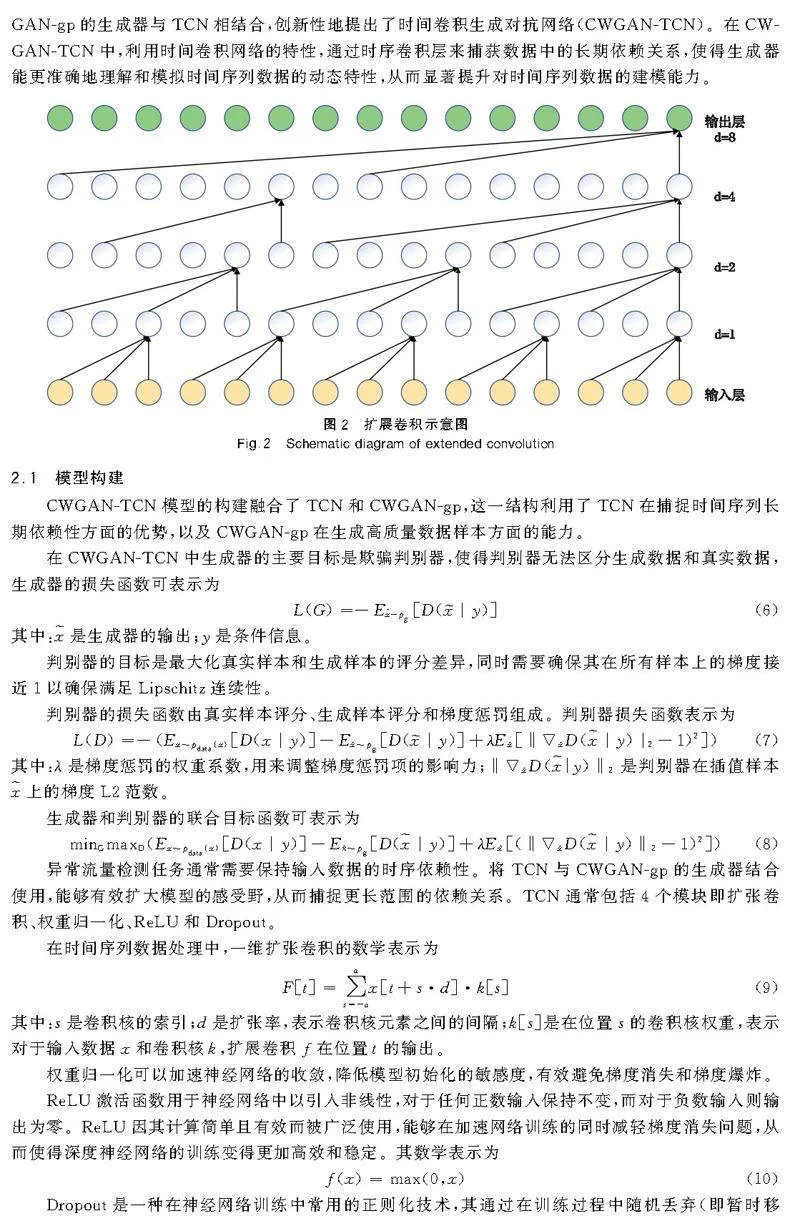
其中d代表膨脹系數,它決定了卷積核中各個元素之間的間距。因此,當d=1時,擴展卷積與普通卷積等效。膨脹系數影響卷積核的感受野大小,通常膨脹系數為特定的稀疏值,如2或4,以便增加模型的學習能力,同時保持較低的參數數量和計算復雜度。擴展卷積的過程如圖2所示。
2CWGAN-TCN模型
在異常流量檢測任務中,為了同時利用Wasserstein距離和梯度懲罰項,并能根據生成目標產生特定類別的樣本,將CGAN擴展為具備梯度懲罰的條件Wasserstein GAN(CWGAN-gp)。與傳統的重采樣算法相比,CWGAN-gp不僅能夠生成更加貼近真實數據分布的樣本,還表現出優越的數據表征學習能力。此外,為了在生成少數類樣本的同時捕捉異常流量數據中階段性的長期依賴關系,將CWGAN-gp的生成器與TCN相結合,創新性地提出了時間卷積生成對抗網絡(CWGAN-TCN)。在CWGAN-TCN中,利用時間卷積網絡的特性,通過時序卷積層來捕獲數據中的長期依賴關系,使得生成器能更準確地理解和模擬時間序列數據的動態特性,從而顯著提升對時間序列數據的建模能力。
2.1模型構建
CWGAN-TCN模型的構建融合了TCN和CWGAN-gp,這一結構利用了TCN在捕捉時間序列長期依賴性方面的優勢,以及CWGAN-gp在生成高質量數據樣本方面的能力。
在CWGAN-TCN中生成器的主要目標是欺騙判別器,使得判別器無法區分生成數據和真實數據,生成器的損失函數可表示為
L(G)=-E-pg[D(|y)](6)
其中:是生成器的輸出;y是條件信息。
判別器的目標是最大化真實樣本和生成樣本的評分差異,同時需要確保其在所有樣本上的梯度接近1以確保滿足Lipschitz連續性。
判別器的損失函數由真實樣本評分、生成樣本評分和梯度懲罰組成。判別器損失函數表示為
L(D)=-(Ex~pdata(x)[D(x|y)]-E~pg[D(|y)]+λE[‖
D(|y)|2-1)2])(7)
其中:λ是梯度懲罰的權重系數,用來調整梯度懲罰項的影響力;‖D(|y)‖2是判別器在插值樣本上的梯度L2范數。
生成器和判別器的聯合目標函數可表示為
minGmaxD(Ex~pdata(x)[D(x|y)]-E~pg[D(|y)]+λE[(‖D(|y)‖2-1)2])(8)
異常流量檢測任務通常需要保持輸入數據的時序依賴性。將TCN與CWGAN-gp的生成器結合使用,能夠有效擴大模型的感受野,從而捕捉更長范圍的依賴關系。TCN通常包括4個模塊即擴張卷積、權重歸一化、ReLU和Dropout。
在時間序列數據處理中,一維擴張卷積的數學表示為
F[t]=∑as=-ax[t+s·d]·k[s](9)
其中:s是卷積核的索引;d是擴張率,表示卷積核元素之間的間隔;k[s]是在位置s的卷積核權重,表示對于輸入數據x和卷積核k,擴展卷積f在位置t的輸出。
權重歸一化可以加速神經網絡的收斂,降低模型初始化的敏感度,有效避免梯度消失和梯度爆炸。
ReLU激活函數用于神經網絡中以引入非線性,對于任何正數輸入保持不變,而對于負數輸入則輸出為零。ReLU因其計算簡單且有效而被廣泛使用,能夠在加速網絡訓練的同時減輕梯度消失問題,從而使得深度神經網絡的訓練變得更加高效和穩定。其數學表示為
f(x)=max(0,x)(10)
Dropout是一種在神經網絡訓練中常用的正則化技術,其通過在訓練過程中隨機丟棄(即暫時移除)網絡中的部分神經元(包括其連接)來防止模型過擬合。通過減少神經元之間復雜的共適應關系,可以提高網絡的泛化能力。其數學表示為
i=Bernoulli(p)·xi(11)
其中:Bernoulli是伯努利分布;p是神經元保留的概率;xi是輸入;i是Dropout之后的輸出。
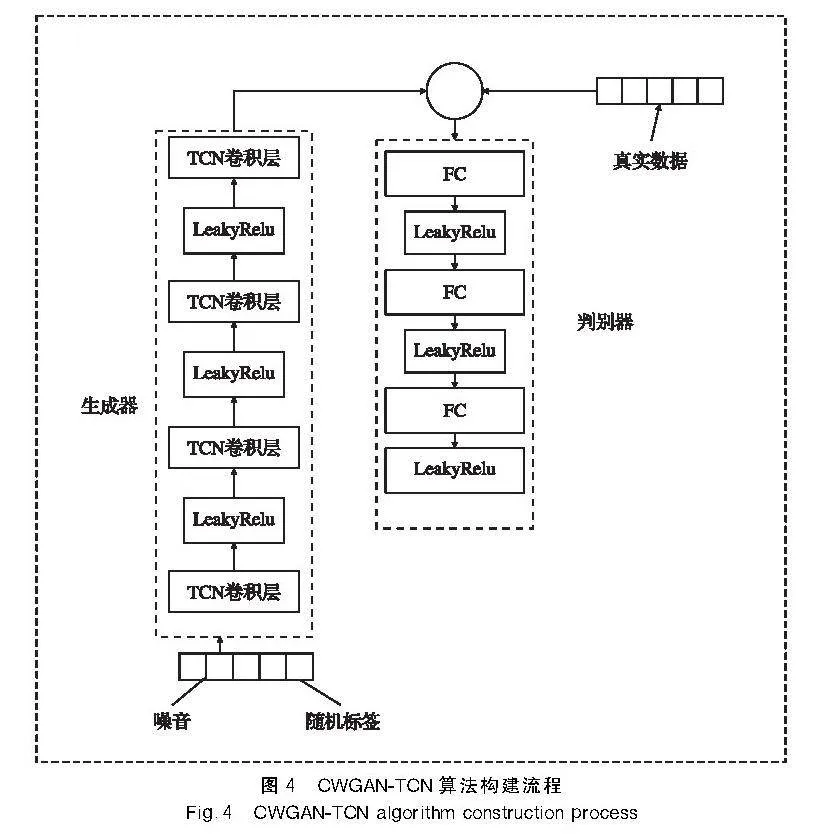
2.2模型結構
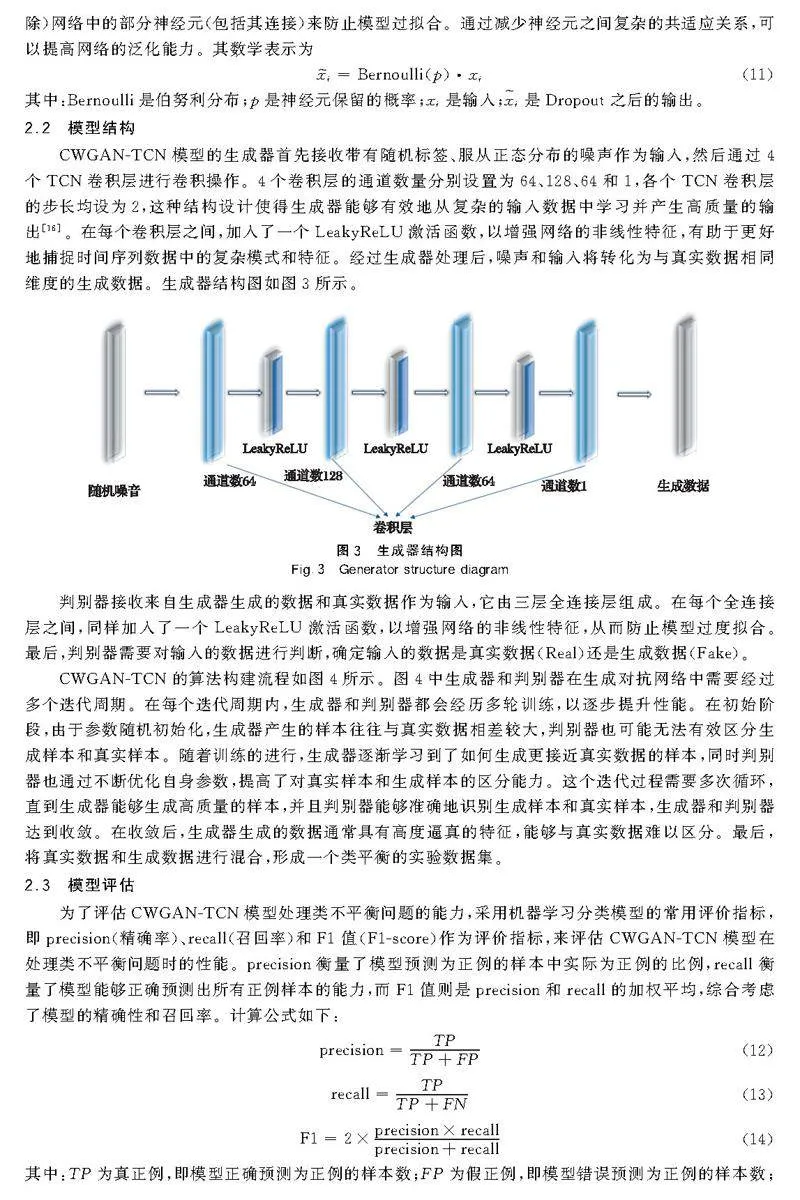
CWGAN-TCN模型的生成器首先接收帶有隨機標簽、服從正態分布的噪聲作為輸入,然后通過4個TCN卷積層進行卷積操作。4個卷積層的通道數量分別設置為64、128、64和1,各個TCN卷積層的步長均設為2,這種結構設計使得生成器能夠有效地從復雜的輸入數據中學習并產生高質量的輸出[16]。在每個卷積層之間,加入了一個LeakyReLU激活函數,以增強網絡的非線性特征,有助于更好地捕捉時間序列數據中的復雜模式和特征。經過生成器處理后,噪聲和輸入將轉化為與真實數據相同維度的生成數據。生成器結構圖如圖3所示。
判別器接收來自生成器生成的數據和真實數據作為輸入,它由三層全連接層組成。在每個全連接層之間,同樣加入了一個LeakyReLU激活函數,以增強網絡的非線性特征,從而防止模型過度擬合。最后,判別器需要對輸入的數據進行判斷,確定輸入的數據是真實數據(Real)還是生成數據(Fake)。
CWGAN-TCN的算法構建流程如圖4所示。
圖4中生成器和判別器在生成對抗網絡中需要經過多個迭代周期。在每個迭代周期內,生成器和判別器都會經歷多輪訓練,以逐步提升性能。在初始階段,由于參數隨機初始化,生成器產生的樣本往往與真實數據相差較大,判別器也可能無法有效區分生成樣本和真實樣本。隨著訓練的進行,生成器逐漸學習到了如何生成更接近真實數據的樣本,同時判別器也通過不斷優化自身參數,提高了對真實樣本和生成樣本的區分能力。這個迭代過程需要多次循環,直到生成器能夠生成高質量的樣本,并且判別器能夠準確地識別生成樣本和真實樣本,生成器和判別器達到收斂。在收斂后,生成器生成的數據通常具有高度逼真的特征,能夠與真實數據難以區分。最后,將真實數據和生成數據進行混合,形成一個類平衡的實驗數據集。
2.3模型評估
為了評估CWGAN-TCN模型處理類不平衡問題的能力,采用機器學習分類模型的常用評價指標,即precision(精確率)、recall(召回率)和F1值(F1-score)作為評價指標,來評估CWGAN-TCN模型在處理類不平衡問題時的性能。precision衡量了模型預測為正例的樣本中實際為正例的比例,recall衡量了模型能夠正確預測出所有正例樣本的能力,而F1值則是precision和recall的加權平均,綜合考慮了模型的精確性和召回率。計算公式如下:
precision=TPTP+FP(12)
recall=TPTP+FN(13)
F1=2×precision×recallprecision+recall(14)
其中:TP為真正例,即模型正確預測為正例的樣本數;FP為假正例,即模型錯誤預測為正例的樣本數;FN表示假正例,即模型錯誤預測為負例的正例樣本數。
為了驗證CWGAN-TCN模型解決類不平衡問題的有效性和可靠性,選用ozone_data[17]、occupancy_data[18]和CreditCard[19]3個開源數據集,通過與Ada Boost (AB),Gradient Boosting (GB),Logistic Regression (LR),以及Support Vector Machines (SVM)4個分類器實驗結果進行對比分析。實驗首先在每個分類器上使用原始數據進行實驗評估,然后再使用由CWGAN-TCN模型擴充后的數據進行實驗評估,每次實驗重復10次,取平均值作為結果。
3個數據集的基本信息描述見表1。
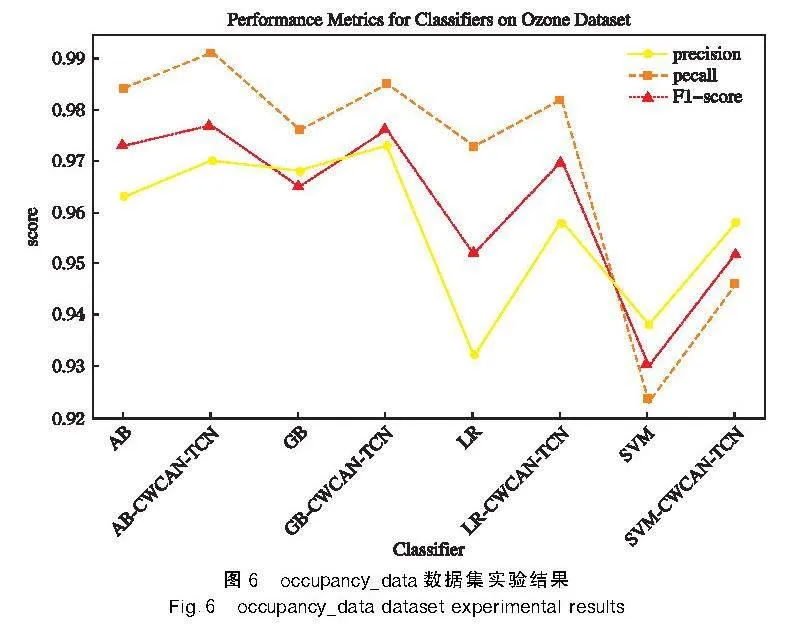
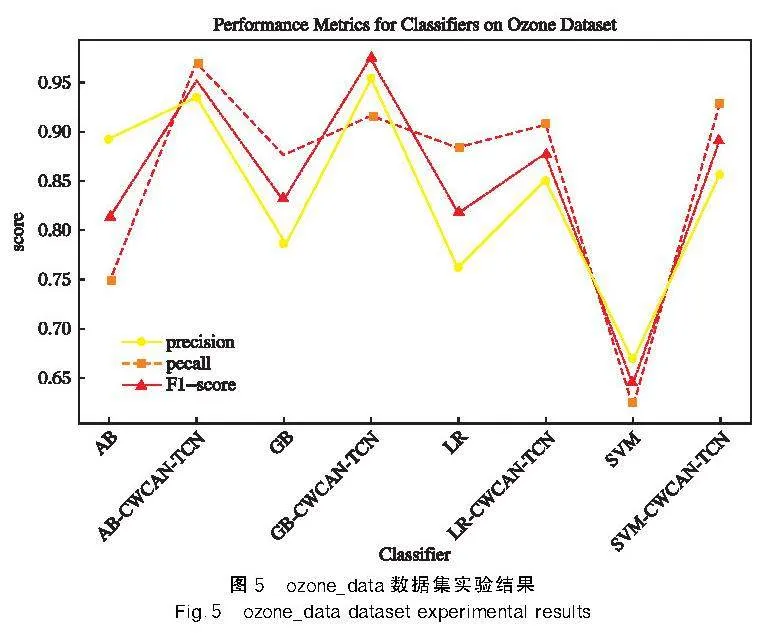
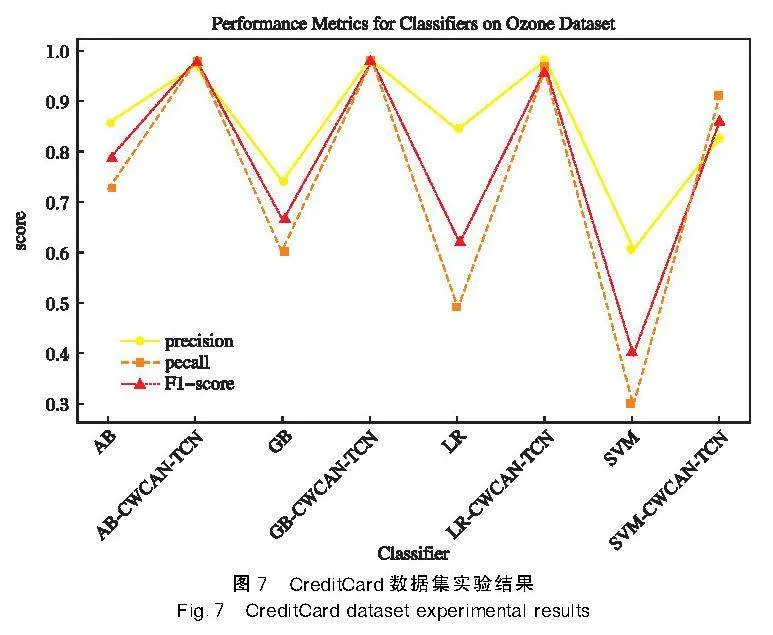
CWGAN-TCN模型在3個數據集的實驗對比結果如圖5~圖7所示。
結果顯示,使用 CWGAN-TCN 進行數據平衡后的數據集在不同的分類器上的表現均取得了顯著的性能提升。同時,數據不平衡度越高,分類器的性能越差,即能夠正確進行分類的能力越弱。通過使用 CWGAN-TCN 進行數據平衡,分類器的性能得到了改善。由此可見,CWGAN-TCN模型在處理不平衡數據集時具有很好的效果和應用潛力。
3實證研究
3.1數據描述
面對數據不平衡的情況,傳統的模型常常在檢測少數類時表現不佳。為了探索并改進入侵檢測模型,以更有效地應對數據不平衡問題,選擇采用澳大利亞新南威爾士大學提供的公開網絡入侵檢測數據集UNSW-NB15[20]進行實證分析。該數據集反映了真實網絡環境中的流量和攻擊行為,包含了多種特征,如源IP地址、目標IP地址、源端口、目標端口和協議類型等,以及每個網絡流量記錄的正常與異常狀態標簽。通過對該數據集的不平衡性、特征相關性、噪聲和缺失值等問題進行詳細分析,探索適用的數據不平衡處理方法,以提升入侵檢測的準確性和效率。該數據集共有49個特征,其中9個基本特征,40個數據特征。UNSW-NB15數據集的攻擊描述和不平衡度見表2。
3.2參數設置
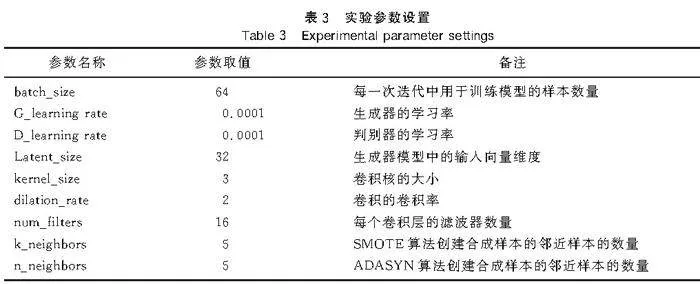
在實驗過程中,對每次實驗的參數變化和結果差異進行了詳細記錄。通過比較和分析這些差異,逐步調整實驗參數,最終確定了能夠使實驗結果達到最優狀態的參數設置。為確保實驗結果的可靠性與可重復性,重要參數的設置見表3。
3.3實驗結果分析
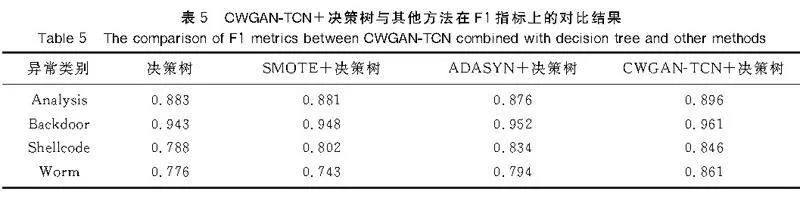
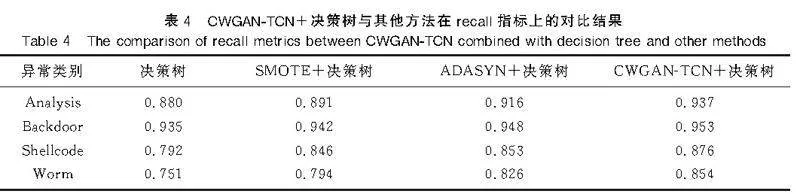
本實證研究采用決策樹作為分類器,對UNSW-NB15數據集進行實驗研究,并通過決策樹以及SMOTE、ADASYN、CWGAN-TCN擴充樣本的決策樹算法進行比較分析。實驗結果選取了正常類以及4個不平衡度較高的少數類(Analysis,Backdoor,Shellcode,Worm)的測試結果進行比較。每個方法分別進行10次實驗,取10次實驗的平均值為實驗結果(見表4、表5)。
在不平衡數據集上進行分類時,少量類的樣本個數較少,決策樹容易擬合部分特征,導致precision較高,而recall較低。在對少數類樣本進行擴充后,recall的提升更好地體現了擴充模型的性能。
由表4、表5可知,CWGAN-TCN方法有效地提升了決策樹分類器的性能。具體而言,在識別Analysis和Backdoor類別時,recall值分別提升了5.7%和1.8%,這超過了SMOTE算法和ADASYN算法的表現。而在識別Shellcode和Worm類別時,該方法取得了更好的效果,recall值分別提升了8.4%和10.3%。對于F1指標的分析顯示,在4個類別中,CWGAN-TCN算法均優于SMOTE算法和ADASYN算法,并且相較于原始的決策樹,分別提升了1.3%,1.8%,5.8%,8.5%。尤其是在識別Worm類別時,當ADASYN算法表現不佳、SMOTE算法比原始決策樹算法表現更弱時,CWGAN-TCN算法仍然展現出較好的效果。這表明CWGAN-TCN有效地解決了異常流量檢測分類問題中的類不平衡問題。
4結語
針對異常流量檢測中存在的類不平衡問題,本文提出了一種基于CWGAN-TCN的數據平衡方法。該方法旨在優化分類器對于少數類樣本的識別問題,從而提升傳統分類方法的性能。采用CWGAN-gp神經對抗網絡生成帶有標簽信息的數據,TCN模型幫助生成器和判別器更好地理解序列數據之間的關系和捕捉隱藏信息,能夠生成高質量的少數類別數據。在3個數據集(ozone_data、occupancy_data、CreditCard)上的對比實驗結果表明,傳統分類器在處理不平衡的數據集時效果不佳,使用CWGAN-TCN進行數據平衡后,precision、recall和F1值3個指標均有所提高。在UNSW-NB15數據集中的對比試驗結果表明,CWGAN-TCN在解決類不平衡問題時優于SMOTE算法和ADASYN算法,可以有效地提升模型對少數類的識別率。
致謝:感謝沈陽師范大學研究生項目支持經費專項資金資助項目(SYNUXJ2024055);沈陽師范大學研究生教育教學改革研究項目(YJSJG320240077)的支持。
參考文獻:
[1]KRAJCINOVIC D,FONSEKA G U.The continuous damage theory of brittle materials[J].J Appl Mech,1981,48(4):809-824. BERNDT D J,CLIFFORD J.Using dynamic time warping to find patterns in time series[C]//Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining.Seattle:AAAI Press,1994:359-370.
[2]SALVADOR S,CHAN P.Toward accurate dynamic time warping in linear time and space[J].Intell Data Anal,2007,11(5):561-580.
[3]GRABOCKA J,SCHILLING N,WISTUBA M,et al.Learning time-series shapelets[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.NewYork:ACM,2014:392-401.
[4]ZHENG Y,LIU Q,CHEN E,et al.Time series classification using multi-channels deep convolutional neural networks[C]//International Conference on Web-age Information Management.Cham:Springer International Publishing,2014:298-310.
[5]FAWAZ H I,FORESTIER G,WEBER J,et al.Deep learning for time series classification:A review[J].Data Min Knowl Discov,2019,33(4):917-963.
[6]SAK H,SENIOR A,BEAUFAYS F.Long short-term memory recurrent neural network architectures for large scale acoustic modeling[C]//Proceedings of INTERSPEECH 2014,15th Annual Conference of the International Speech Communication Association.Singapore:ISCA,2014:338-342.
[7]VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all you need[C]//Advances in Neural Information Processing Systems.Long Beach:Curran Associates,2017:5998-6008.
[8]BATISTA G E,PRATI R C,MONARD M C.A study of the behavior of several methods for balancing machine learning training data[J].ACM SIGKDD Explor Newsl,2004,6(1):20-29.
[9]CHAWLA N V,BOWYER K W,HALL L O,et al.SMOTE:Synthetic minority over-sampling technique[J].J Artif Intell Res,2002,16:321-357.
[10]HE H,BAI Y,GARCIA E A,et al.ADASYN:Adaptive synthetic sampling approach for imbalanced learning[C]//2008 IEEE International Joint Conference on Neural Networks.Hong Kong:IEEE,2008:1322-1328.
[11]YEN S J,LEE Y S.Cluster-based under-sampling approaches for imbalanced data distributions[J].Expert Syst Appl,2009,36(3):5718-5727.
[12]GOODFELLOW I,POUGET-ABADIE J,MIRZA M,et al.Generative adversarial nets[C]//Advances in Neural Information Processing Systems.Montreal:Curran Associates,2014:2672-2680.
[13]HONG W X,WANG Z Z,YANG M,et al.Conditional generative adversarial network for structured domain adaptation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:1335-1344.
[14]ARJOVSKY M,CHINTALA S,BOTTOU L.Wasserstein generative adversarial networks[C]//International Conference on Machine Learning.Sydney:PMLR,2017:214-223.
[15]LEA C,VIDAL R,REITER A,et al.Temporal convolutional networks:A unified approach to action segmentation[C]//Computer Vision-ECCV 2016 Workshops.Amsterdam:Springer International Publishing,2016:47-54.
[16]潘雪嬌,董紹江,朱朋,等.基于TCN和殘差自注意力的變工況下滾動軸承剩余壽命遷移預測[J].振動與沖擊,2024,43(1):145-152.
[17]ZHANG W X,LIU D,TIAN H Q,et al.Recurrent mapping of hourly surface ozone data (HrSOD) across China during 2005-2020 for ecosystem and human health risk assessment[J].Earth Syst Sci Data,2022,15:428-440.
[18]CANDANEDO L M,FELDHEIM V.Accurate occupancy detection of an office room from light,temperature,humidity and CO2 measurements using statistical learning models[J].Energy Build,2016,112:28-39.
[19]POZZOLO D A,BORACCHI G,CAELEN O,et al.Credit card fraud detection and concept-drift adaptation with delayed supervised information[C]//IEEE International Conference on Computational Intelligence and Data Mining(IJCNN).Louisville:IEEE,2015:1-8.
[20]MOUSTAFA N,SLAY J.UNSW-NB15:A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set)[C]//2015 Military Communications and Information Systems Conference (MilCIS).Canberra:IEEE,2015:1-6.
【責任編輯:溫學兵】
收稿日期:2024-05-23
基金項目:遼寧省社會科學規劃基金委托項目(L16WTB022)。
作者簡介:邵永運(1971—),男,遼寧大連人,沈陽師范大學教授,博士。
